- 1. RNN架构解析
- 2. RNN经典案例
- 获取常用字符数量
n_letters = len(all_letters) - all_categories形如: [“English”,…,”Chinese”]
all_categories = [] - 读取指定路径下的txt文件, 使用glob,path中可以使用正则表达式
for filename in glob.glob(data_path + ‘*.txt’):
# 获取每个文件的文件名, 就是对应的名字类别
category = os.path.splitext(os.path.basename(filename))[0]
# 将其逐一装到all_categories列表中
all_categories.append(category)
# 然后读取每个文件的内容,形成名字列表
lines = readLines(filename)
# 按照对应的类别,将名字列表写入到category_lines字典中
category_lines[category] = lines - 查看类别总数
n_categories = len(all_categories)
print(“n_categories:”, n_categories) - 随便查看其中的一些内容
print(category_lines[‘Italian’][:5]) - [[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0.]]])
def lineToTensor(line):
“””将人名转化为对应onehot张量表示, 参数line是输入的人名”””
# 首先初始化一个0张量, 它的形状(len(line), 1, n_letters)
# 代表人名中的每个字母用一个1 x n_letters的张量表示.
tensor = torch.zeros(len(line), 1, n_letters)
# 遍历这个人名中的每个字符索引和字符
for li, letter in enumerate(line):
# 使用字符串方法find找到每个字符在all_letters中的索引
# 它也是我们生成onehot张量中1的索引位置
tensor[li][0][all_letters.find(letter)] = 1
# 返回结果
return tensor - GRU与传统RNN的外部形式相同, 都是只传递隐层张量, 因此只需要更改预定义层的名字
- 定义隐层的最后一维尺寸大小
n_hidden = 128 - 输出尺寸为语言类别总数n_categories
output_size = n_categories - num_layer使用默认值, num_layers = 1
- 初始化一个三维的隐层0张量, 也是初始的细胞状态张量
hidden = c = torch.zeros(1, 1, n_hidden) - 设置学习率为0.005
learning_rate = 0.005 - 绘制损失对比曲线, 训练耗时对比柱张图
# 创建画布0
plt.figure(0)
# 绘制损失对比曲线
plt.plot(all_losses1, label=”RNN”)
plt.plot(all_losses2, color=”red”, label=”LSTM”)
plt.plot(all_losses3, color=”orange”, label=”GRU”)
plt.legend(loc=’upper left’) - 创建画布1
plt.figure(1)
x_data=[“RNN”, “LSTM”, “GRU”]
y_data = [period1, period2, period3]
# 绘制训练耗时对比柱状图
plt.bar(range(len(x_data)), y_data, tick_label=x_data) - 从io工具包导入open方法
from io import open
# 用于字符规范化
import unicodedata
# 用于正则表达式
import re
# 用于随机生成数据
import random
# 用于构建网络结构和函数的torch工具包
import torch
import torch.nn as nn
import torch.nn.functional as F
# torch中预定义的优化方法工具包
from torch import optim
# 设备选择, 我们可以选择在cuda或者cpu上运行你的代码
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”) - 选择带有指定前缀的语言特征数据作为训练数据
eng_prefixes = (
“i am “, “i m “,
“he is”, “he s “,
“she is”, “she s “,
“you are”, “you re “,
“we are”, “we re “,
“they are”, “they re “
) - 通过output_lang.n_words获取目标词汇总数,与hidden_size和dropout_p一同传入AttnDecoderRNN类中
# 得到解码器对象attn_decoder1
attn_decoder1 = AttnDecoderRNN(hidden_size, output_lang.n_words, dropout_p=0.1).to(device) - 设置迭代步数
n_iters = 75000
# 设置日志打印间隔
print_every = 5000
1. RNN架构解析
1.1 认识RNN模型
学习目标
- 了解什么是RNN模型.
- 了解RNN模型的作用.
- 了解RNN模型的分类.
什么是RNN模型
- RNN(Recurrent Neural Network), 中文称作循环神经网络, 它一般以序列数据为输入, 通过网络内部的结构设计有效捕捉序列之间的关系特征, 一般也是以序列形式进行输出.
- 一般单层神经网络结构:
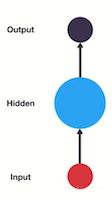
- RNN单层网络结构:
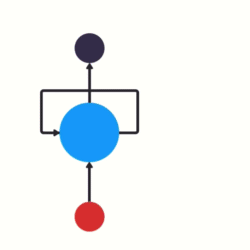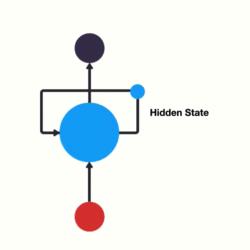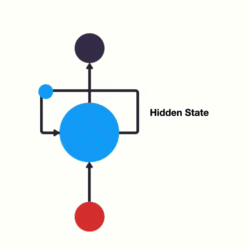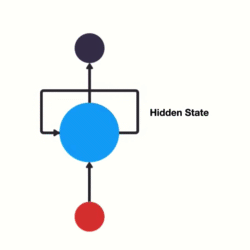
- 以时间步对RNN进行展开后的单层网络结构:

- RNN的循环机制使模型隐层上一时间步产生的结果, 能够作为当下时间步输入的一部分(当下时间步的输入除了正常的输入外还包括上一步的隐层输出)对当下时间步的输出产生影响.
RNN模型的作用
- 因为RNN结构能够很好利用序列之间的关系, 因此针对自然界具有连续性的输入序列, 如人类的语言, 语音等进行很好的处理, 广泛应用于NLP领域的各项任务, 如文本分类, 情感分析, 意图识别, 机器翻译等.
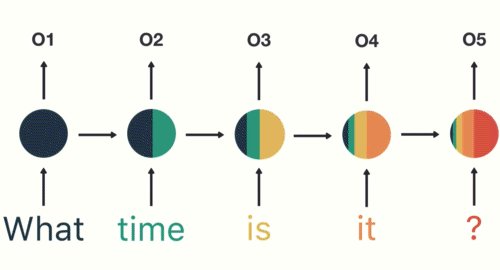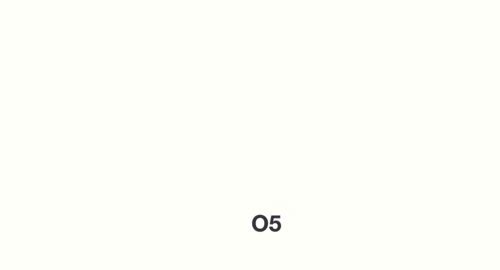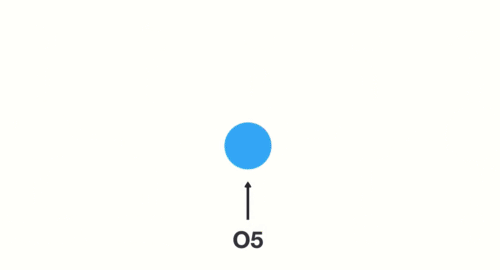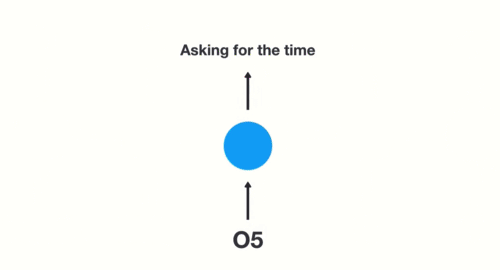
- 下面我们将以一个用户意图识别的例子进行简单的分析:

- 第一步: 用户输入了”What time is it ?”, 我们首先需要对它进行基本的分词, 因为RNN是按照顺序工作的, 每次只接收一个单词进行处理.

- 第二步: 首先将单词”What”输送给RNN, 它将产生一个输出O1.
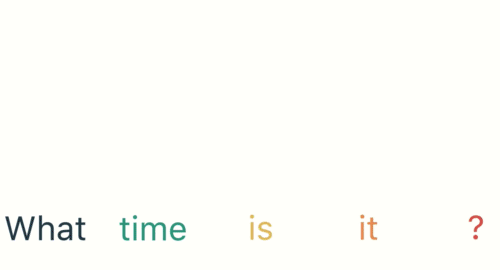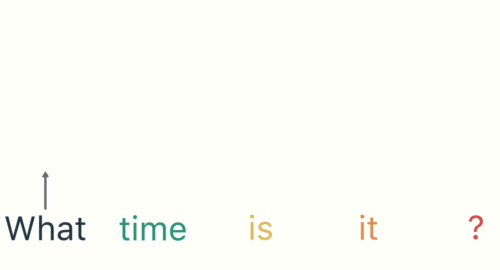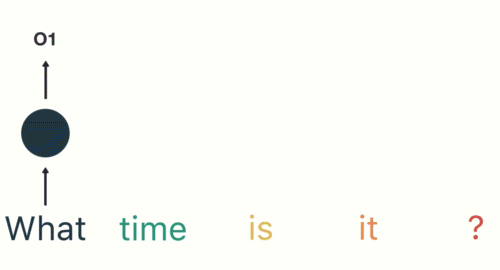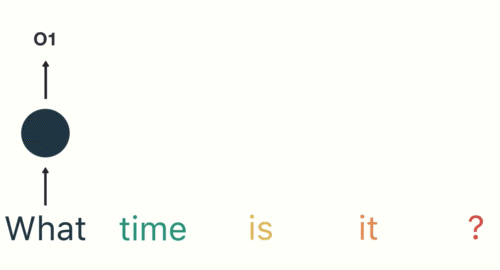
- 第三步: 继续将单词”time”输送给RNN, 但此时RNN不仅仅利用”time”来产生输出O2, 还会使用来自上一层隐层输出O1作为输入信息.
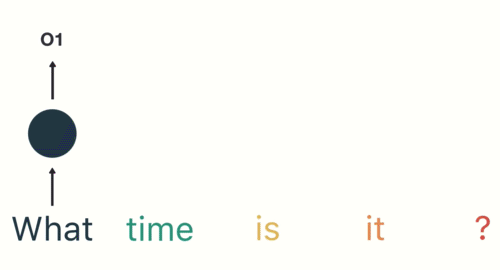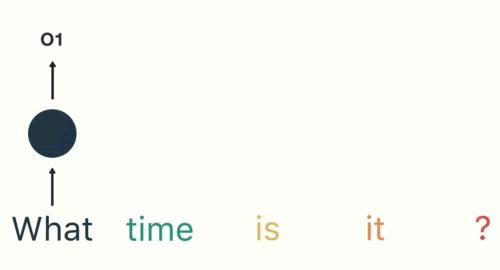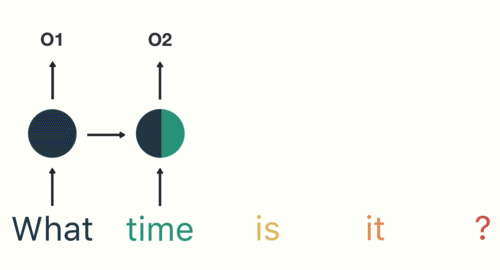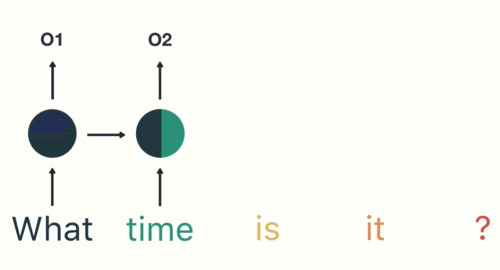
- 第四步: 重复这样的步骤, 直到处理完所有的单词.
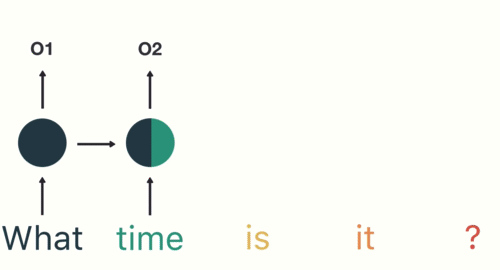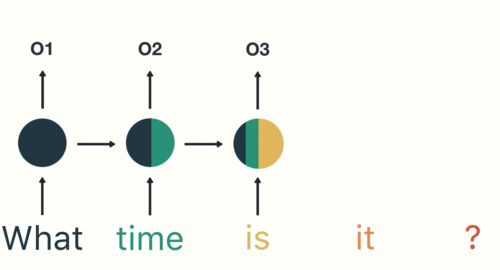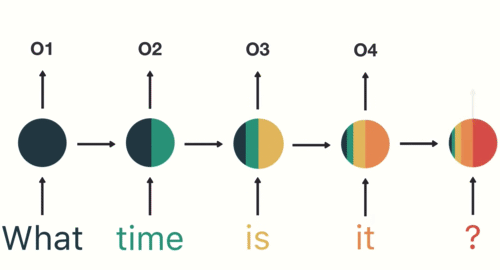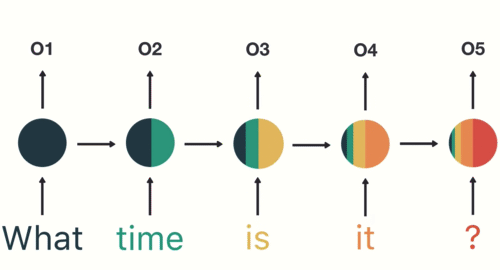
- 第五步: 最后,将最终的隐层输出O5进行处理来解析用户意图.
RNN模型的分类
- 这里我们将从两个角度对RNN模型进行分类. 第一个角度是输入和输出的结构, 第二个角度是RNN的内部构造.
- 按照输入和输出的结构进行分类:
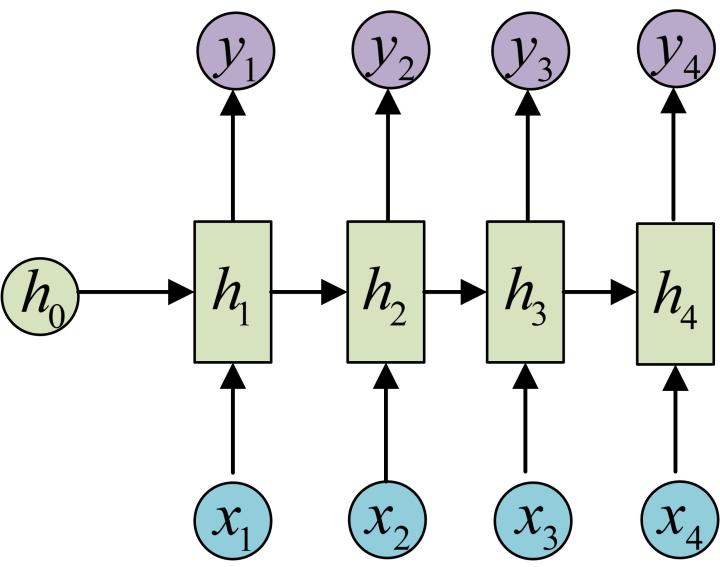
- N vs N - RNN
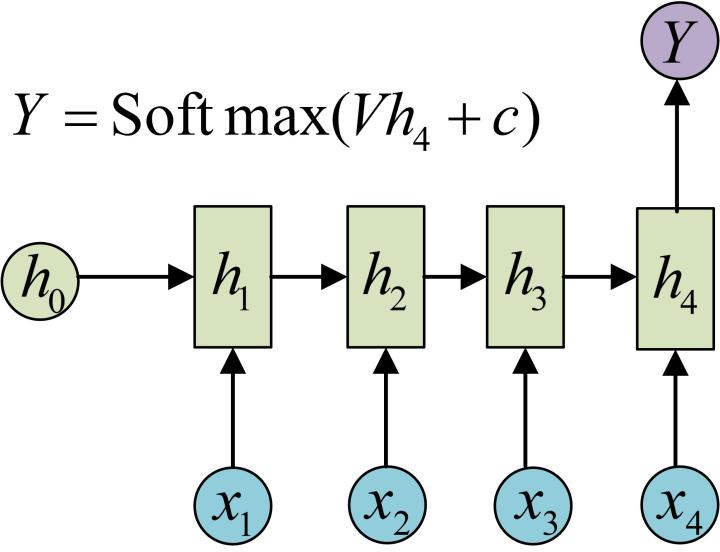
- N vs 1 - RNN
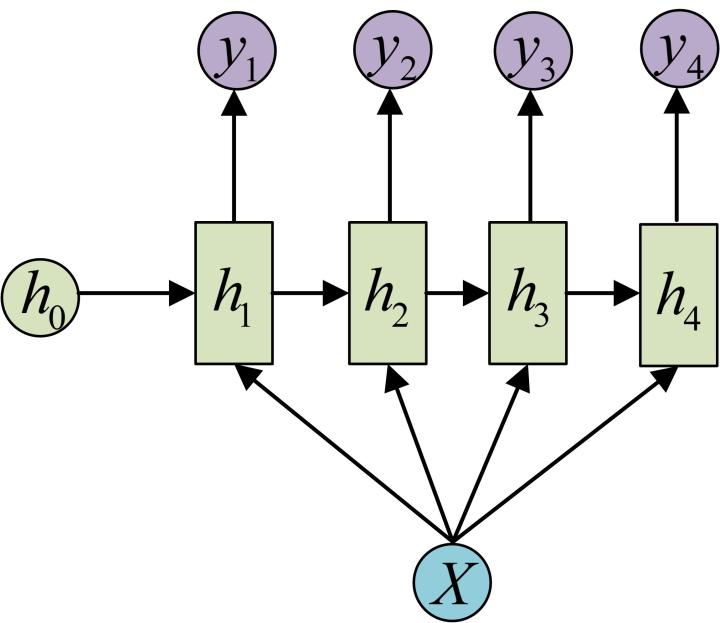
- 1 vs N - RNN
- N vs M - RNN
- 按照RNN的内部构造进行分类:
- 传统RNN
- LSTM
- Bi-LSTM
- GRU
- Bi-GRU
- N vs N - RNN:
- 它是RNN最基础的结构形式, 最大的特点就是: 输入和输出序列是等长的. 由于这个限制的存在, 使其适用范围比较小, 可用于生成等长度的合辙诗句.
- N vs 1 - RNN:
- 有时候我们要处理的问题输入是一个序列,而要求输出是一个单独的值而不是序列,应该怎样建模呢?我们只要在最后一个隐层输出h上进行线性变换就可以了,大部分情况下,为了更好的明确结果, 还要使用sigmoid或者softmax进行处理. 这种结构经常被应用在文本分类问题上.
- 1 vs N - RNN:
- 如果输入不是序列而输出为序列的情况怎么处理呢?我们最常采用的一种方式就是使该输入作用于每次的输出之上. 这种结构可用于将图片生成文字任务等.
- N vs M - RNN:
- 这是一种不限输入输出长度的RNN结构, 它由编码器和解码器两部分组成, 两者的内部结构都是某类RNN, 它也被称为seq2seq架构. 输入数据首先通过编码器, 最终输出一个隐含变量c, 之后最常用的做法是使用这个隐含变量c作用在解码器进行解码的每一步上, 以保证输入信息被有效利用.
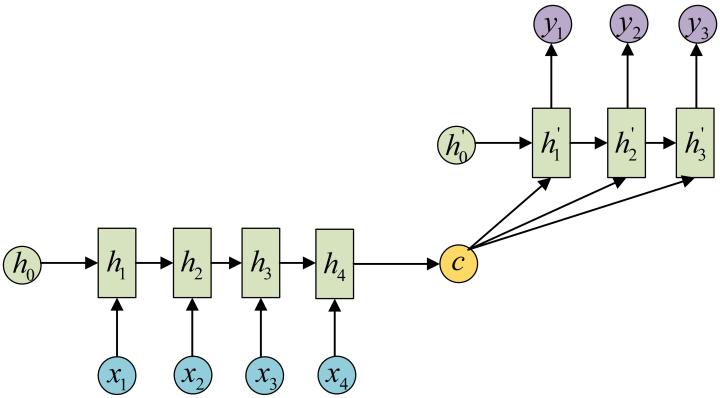
- seq2seq架构最早被提出应用于机器翻译, 因为其输入输出不受限制,如今也是应用最广的RNN模型结构. 在机器翻译, 阅读理解, 文本摘要等众多领域都进行了非常多的应用实践.
- 关于RNN的内部构造进行分类的内容我们将在后面使用单独的小节详细讲解.
小节总结
- 学习了什么是RNN模型:
- RNN(Recurrent Neural Network), 中文称作循环神经网络, 它一般以序列数据为输入, 通过网络内部的结构设计有效捕捉序列之间的关系特征, 一般也是以序列形式进行输出.
- RNN的循环机制使模型隐层上一时间步产生的结果, 能够作为当下时间步输入的一部分(当下时间步的输入除了正常的输入外还包括上一步的隐层输出)对当下时间步的输出产生影响.
- 学习了RNN模型的作用:
- 因为RNN结构能够很好利用序列之间的关系, 因此针对自然界具有连续性的输入序列, 如人类的语言, 语音等进行很好的处理, 广泛应用于NLP领域的各项任务, 如文本分类, 情感分析, 意图识别, 机器翻译等.
- 以一个用户意图识别的例子对RNN的运行过程进行简单的分析:
- 第一步: 用户输入了”What time is it ?”, 我们首先需要对它进行基本的分词, 因为RNN是按照顺序工作的, 每次只接收一个单词进行处理.
- 第二步: 首先将单词”What”输送给RNN, 它将产生一个输出O1.
- 第三步: 继续将单词”time”输送给RNN, 但此时RNN不仅仅利用”time”来产生输出O2, 还会使用来自上一层隐层输出O1作为输入信息.
- 第四步: 重复这样的步骤, 直到处理完所有的单词.
- 第五步: 最后,将最终的隐层输出O5进行处理来解析用户意图.
- 学习了RNN模型的分类:
- 这里我们将从两个角度对RNN模型进行分类. 第一个角度是输入和输出的结构, 第二个角度是RNN的内部构造.
- 按照输入和输出的结构进行分类:
- N vs N - RNN
- N vs 1 - RNN
- 1 vs N - RNN
- N vs M - RNN
- N vs N - RNN:
- 它是RNN最基础的结构形式, 最大的特点就是: 输入和输出序列是等长的. 由于这个限制的存在, 使其适用范围比较小, 可用于生成等长度的合辙诗句.
- N vs 1 - RNN:
- 有时候我们要处理的问题输入是一个序列,而要求输出是一个单独的值而不是序列,应该怎样建模呢?我们只要在最后一个隐层输出h上进行线性变换就可以了,大部分情况下,为了更好的明确结果, 还要使用sigmoid或者softmax进行处理. 这种结构经常被应用在文本分类问题上.
- 1 vs N - RNN:
- 如果输入不是序列而输出为序列的情况怎么处理呢?我们最常采用的一种方式就是使该输入作用于每次的输出之上. 这种结构可用于将图片生成文字任务等.
- N vs M - RNN:
- 这是一种不限输入输出长度的RNN结构, 它由编码器和解码器两部分组成, 两者的内部结构都是某类RNN, 它也被称为seq2seq架构. 输入数据首先通过编码器, 最终输出一个隐含变量c, 之后最常用的做法是使用这个隐含变量c作用在解码器进行解码的每一步上, 以保证输入信息被有效利用.
- seq2seq架构最早被提出应用于机器翻译, 因为其输入输出不受限制,如今也是应用最广的RNN模型结构. 在机器翻译, 阅读理解, 文本摘要等众多领域都进行了非常多的应用实践.
- 按照RNN的内部构造进行分类:
- 传统RNN
- LSTM
- Bi-LSTM
- GRU
- Bi-GRU
- 关于RNN的内部构造进行分类的内容我们将在后面使用单独的小节详细讲解.
1.2 传统RNN模型
学习目标
- 了解传统RNN的内部结构及计算公式.
- 掌握Pytorch中传统RNN工具的使用.
- 了解传统RNN的优势与缺点.
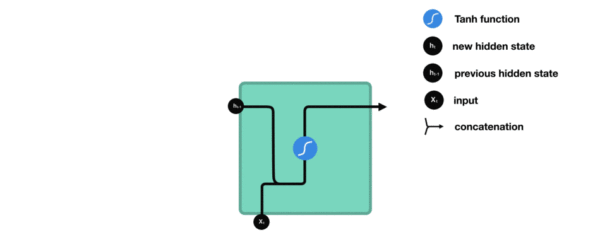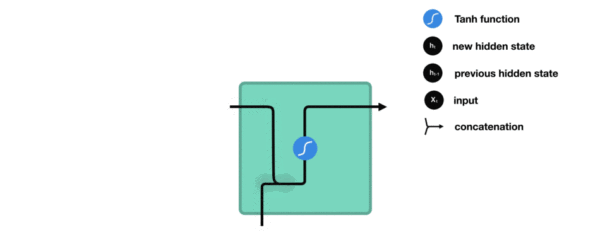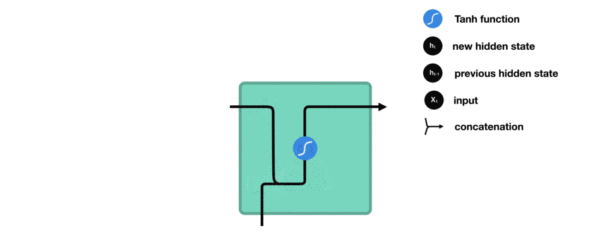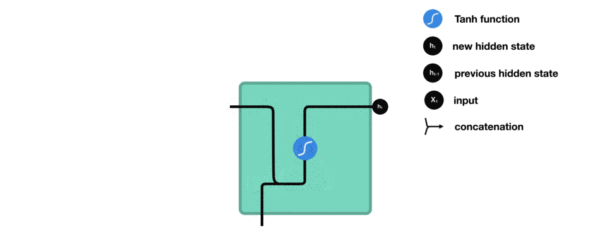
传统RNN的内部结构图
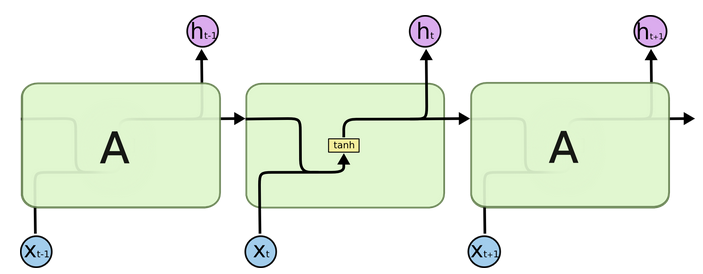
- 结构解释图:

- 内部结构分析:
- 我们把目光集中在中间的方块部分, 它的输入有两部分, 分别是h(t-1)以及x(t), 代表上一时间步的隐层输出, 以及此时间步的输入, 它们进入RNN结构体后, 会”融合”到一起, 这种融合我们根据结构解释可知, 是将二者进行拼接, 形成新的张量[x(t), h(t-1)], 之后这个新的张量将通过一个全连接层(线性层), 该层使用tanh作为激活函数, 最终得到该时间步的输出h(t), 它将作为下一个时间步的输入和x(t+1)一起进入结构体. 以此类推.
- 内部结构过程演示:
- 根据结构分析得出内部计算公式:
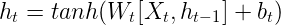
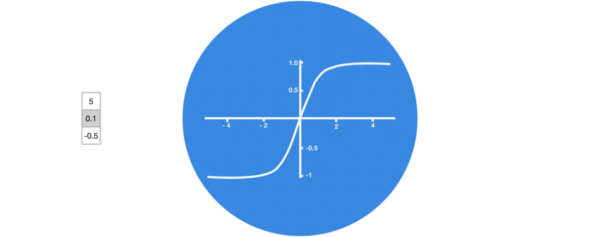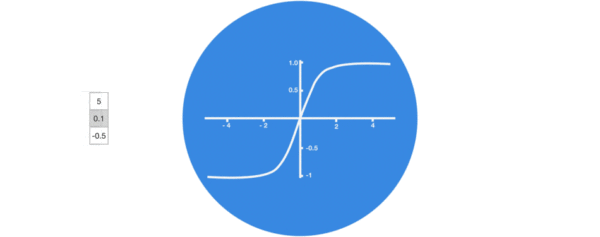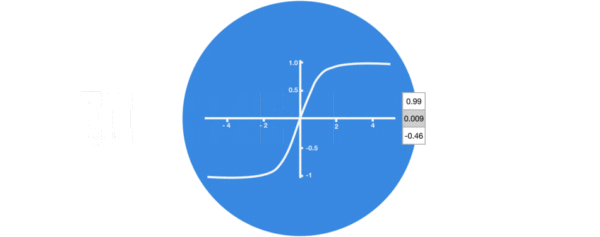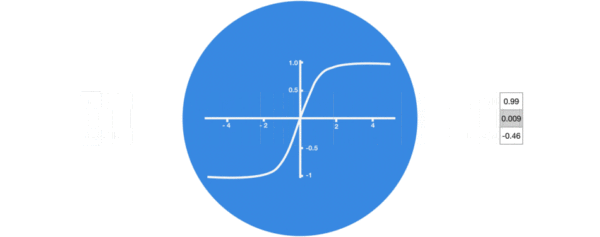
- 激活函数tanh的作用:
- 用于帮助调节流经网络的值, tanh函数将值压缩在-1和1之间.
- Pytorch中传统RNN工具的使用:
- 位置: 在torch.nn工具包之中, 通过torch.nn.RNN可调用.
- nn.RNN类初始化主要参数解释:
- input_size: 输入张量x中特征维度的大小.
- hidden_size: 隐层张量h中特征维度的大小.
- num_layers: 隐含层的数量.
- nonlinearity: 激活函数的选择, 默认是tanh.
- nn.RNN类实例化对象主要参数解释:
- input: 输入张量x.
- h0: 初始化的隐层张量h.
- nn.RNN使用示例:
# 导入工具包
>>> import torch
>>> import torch.nn as nn
>>> rnn = nn.RNN(5, 6, 1)
>>> input = torch.randn(1, 3, 5)
>>> h0 = torch.randn(1, 3, 6)
>>> output, hn = rnn(input, h0)
>>> output
tensor([[[ 0.4282, -0.8475, -0.0685, -0.4601, -0.8357, 0.1252],
[ 0.5758, -0.2823, 0.4822, -0.4485, -0.7362, 0.0084],
[ 0.9224, -0.7479, -0.3682, -0.5662, -0.9637, 0.4938]]],
grad_fn=
hn
tensor([[[ 0.4282, -0.8475, -0.0685, -0.4601, -0.8357, 0.1252],
[ 0.5758, -0.2823, 0.4822, -0.4485, -0.7362, 0.0084],
[ 0.9224, -0.7479, -0.3682, -0.5662, -0.9637, 0.4938]]],
grad_fn=)
- 传统RNN的优势:
- 由于内部结构简单, 对计算资源要求低, 相比之后我们要学习的RNN变体:LSTM和GRU模型参数总量少了很多, 在短序列任务上性能和效果都表现优异.
- 传统RNN的缺点:
- 传统RNN在解决长序列之间的关联时, 通过实践,证明经典RNN表现很差, 原因是在进行反向传播的时候, 过长的序列导致梯度的计算异常, 发生梯度消失或爆炸.
- 什么是梯度消失或爆炸呢?
- 根据反向传播算法和链式法则, 梯度的计算可以简化为以下公式:
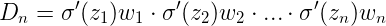
- 其中sigmoid的导数值域是固定的, 在[0, 0.25]之间, 而一旦公式中的w也小于1, 那么通过这样的公式连乘后, 最终的梯度就会变得非常非常小, 这种现象称作梯度消失. 反之, 如果我们人为的增大w的值, 使其大于1, 那么连乘够就可能造成梯度过大, 称作梯度爆炸.
- 梯度消失或爆炸的危害:
- 如果在训练过程中发生了梯度消失,权重无法被更新,最终导致训练失败; 梯度爆炸所带来的梯度过大,大幅度更新网络参数,在极端情况下,结果会溢出(NaN值).
小节总结
- 学习了传统RNN的结构并进行了分析;
- 它的输入有两部分, 分别是h(t-1)以及x(t), 代表上一时间步的隐层输出, 以及此时间步的输入, 它们进入RNN结构体后, 会”融合”到一起, 这种融合我们根据结构解释可知, 是将二者进行拼接, 形成新的张量[x(t), h(t-1)], 之后这个新的张量将通过一个全连接层(线性层), 该层使用tanh作为激活函数, 最终得到该时间步的输出h(t), 它将作为下一个时间步的输入和x(t+1)一起进入结构体. 以此类推.
- 根据结构分析得出了传统RNN的计算公式.
- 学习了激活函数tanh的作用:
- 用于帮助调节流经网络的值, tanh函数将值压缩在-1和1之间.
- 学习了Pytorch中传统RNN工具的使用:
- 位置: 在torch.nn工具包之中, 通过torch.nn.RNN可调用.
- nn.RNN类初始化主要参数解释:
- input_size: 输入张量x中特征维度的大小.
- hidden_size: 隐层张量h中特征维度的大小.
- num_layers: 隐含层的数量.
- nonlinearity: 激活函数的选择, 默认是tanh.
- nn.RNN类实例化对象主要参数解释:
- input: 输入张量x.
- h0: 初始化的隐层张量h.
- 实现了nn.RNN的使用示例, 获得RNN的真实返回结果样式.
- 学习了传统RNN的优势:
- 由于内部结构简单, 对计算资源要求低, 相比之后我们要学习的RNN变体:LSTM和GRU模型参数总量少了很多, 在短序列任务上性能和效果都表现优异.
- 学习了传统RNN的缺点:
- 传统RNN在解决长序列之间的关联时, 通过实践,证明经典RNN表现很差, 原因是在进行反向传播的时候, 过长的序列导致梯度的计算异常, 发生梯度消失或爆炸.
- 学习了什么是梯度消失或爆炸:
- 根据反向传播算法和链式法则, 得到梯度的计算的简化公式:其中sigmoid的导数值域是固定的, 在[0, 0.25]之间, 而一旦公式中的w也小于1, 那么通过这样的公式连乘后, 最终的梯度就会变得非常非常小, 这种现象称作梯度消失. 反之, 如果我们人为的增大w的值, 使其大于1, 那么连乘够就可能造成梯度过大, 称作梯度爆炸.
- 梯度消失或爆炸的危害:
- 如果在训练过程中发生了梯度消失,权重无法被更新,最终导致训练失败; 梯度爆炸所带来的梯度过大,大幅度更新网络参数,在极端情况下,结果会溢出(NaN值).
1.3 LSTM模型
学习目标
- 了解LSTM内部结构及计算公式.
- 掌握Pytorch中LSTM工具的使用.
- 了解LSTM的优势与缺点.
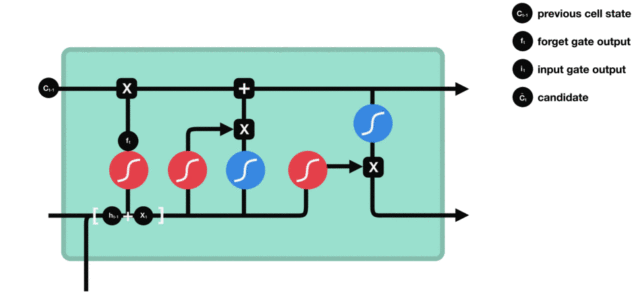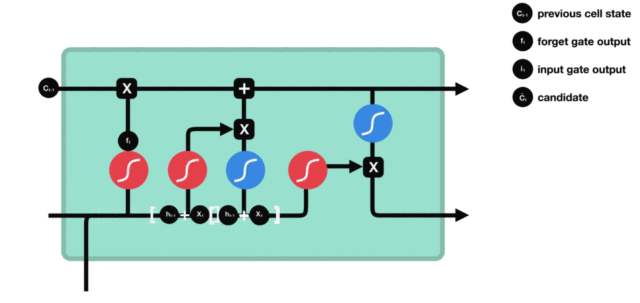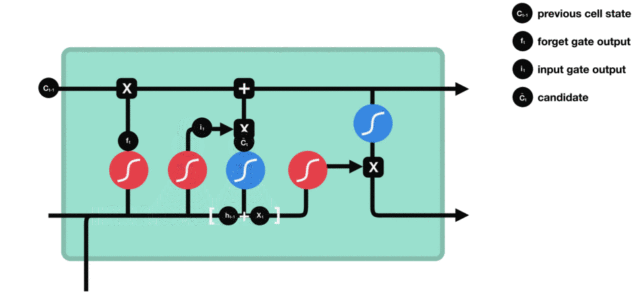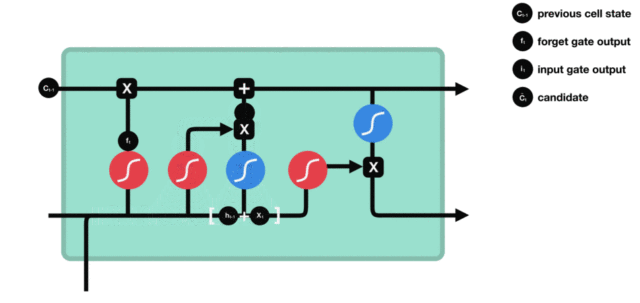
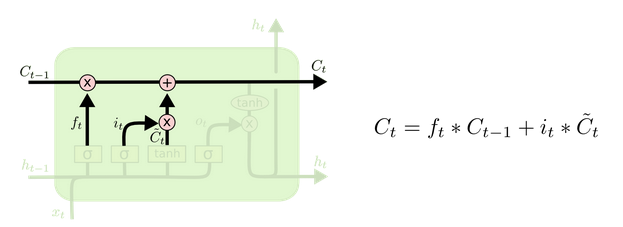
- LSTM(Long Short-Term Memory)也称长短时记忆结构, 它是传统RNN的变体, 与经典RNN相比能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时LSTM的结构更复杂, 它的核心结构可以分为四个部分去解析:
- 遗忘门
- 输入门
- 细胞状态
- 输出门
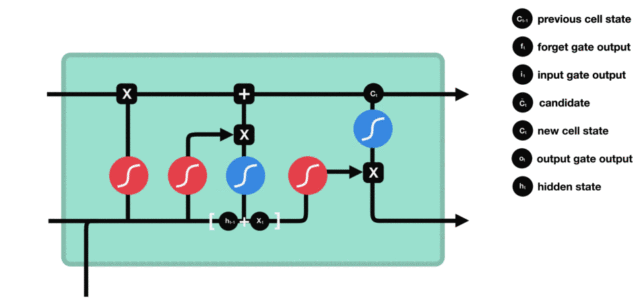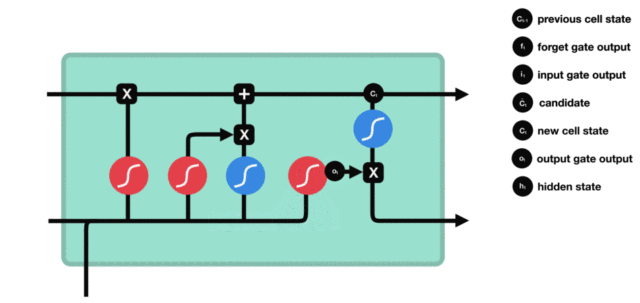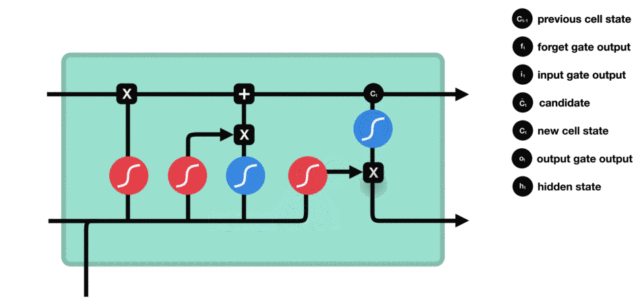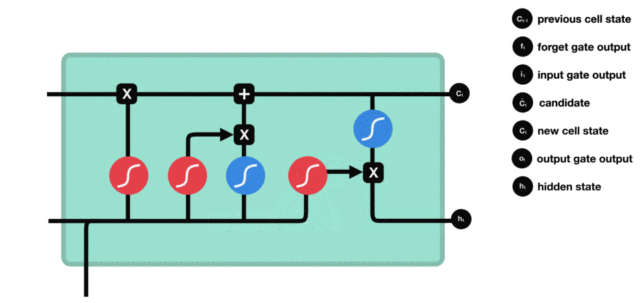
LSTM的内部结构图
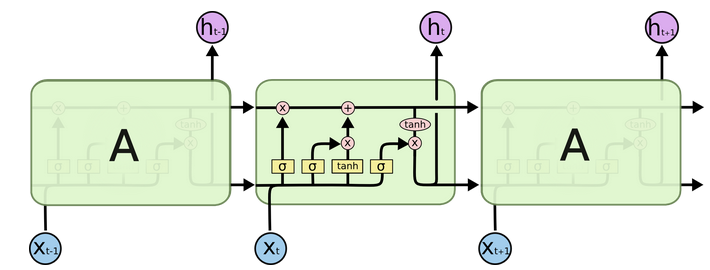
- 结构解释图:

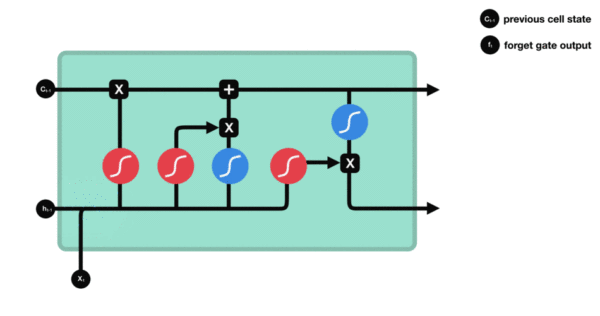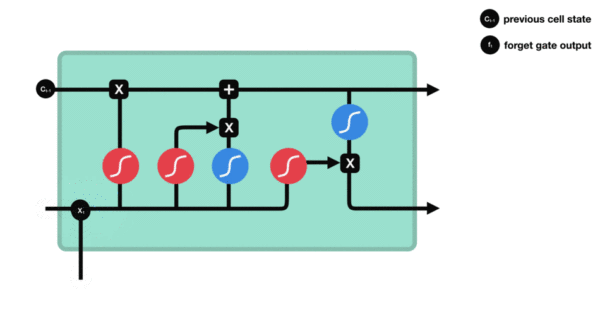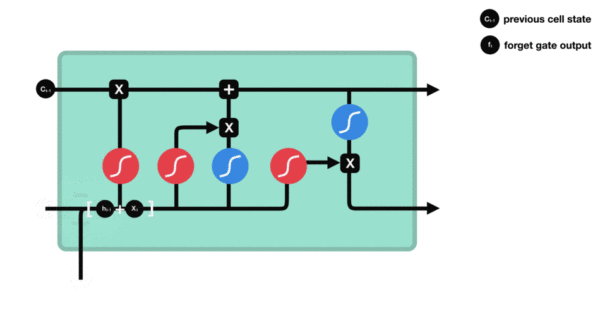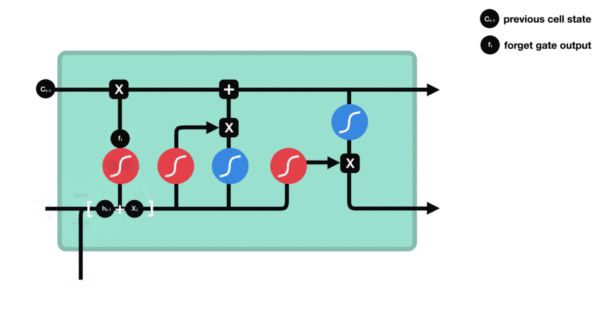
- 遗忘门部分结构图与计算公式:
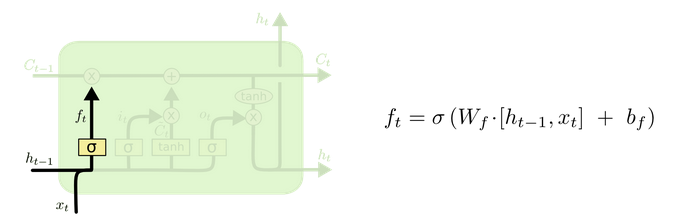
- 遗忘门结构分析:
- 与传统RNN的内部结构计算非常相似, 首先将当前时间步输入x(t)与上一个时间步隐含状态h(t-1)拼接, 得到[x(t), h(t-1)], 然后通过一个全连接层做变换, 最后通过sigmoid函数进行激活得到f(t), 我们可以将f(t)看作是门值, 好比一扇门开合的大小程度, 门值都将作用在通过该扇门的张量, 遗忘门门值将作用的上一层的细胞状态上, 代表遗忘过去的多少信息, 又因为遗忘门门值是由x(t), h(t-1)计算得来的, 因此整个公式意味着根据当前时间步输入和上一个时间步隐含状态h(t-1)来决定遗忘多少上一层的细胞状态所携带的过往信息.
- 遗忘门内部结构过程演示:
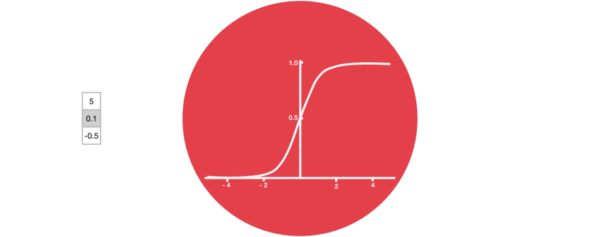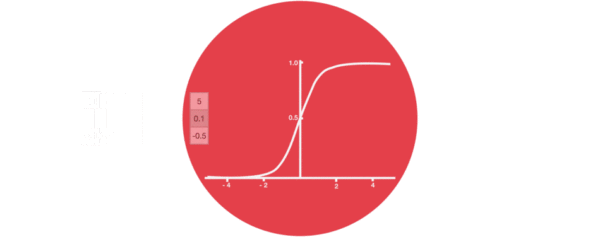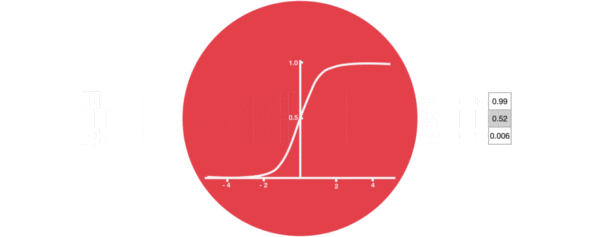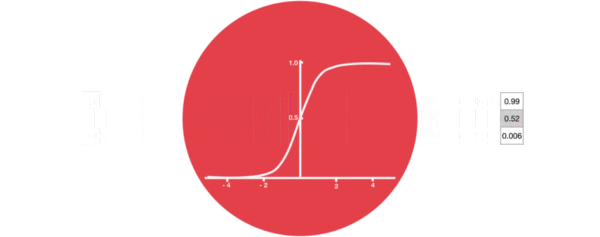
- 激活函数sigmiod的作用:
- 用于帮助调节流经网络的值, sigmoid函数将值压缩在0和1之间.
- 输入门部分结构图与计算公式:
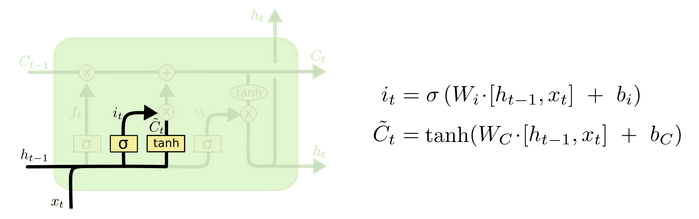
- 输入门结构分析:
- 我们看到输入门的计算公式有两个, 第一个就是产生输入门门值的公式, 它和遗忘门公式几乎相同, 区别只是在于它们之后要作用的目标上. 这个公式意味着输入信息有多少需要进行过滤. 输入门的第二个公式是与传统RNN的内部结构计算相同. 对于LSTM来讲, 它得到的是当前的细胞状态, 而不是像经典RNN一样得到的是隐含状态.
- 输入门内部结构过程演示:
- 细胞状态更新图与计算公式:
- 细胞状态更新分析:
- 细胞更新的结构与计算公式非常容易理解, 这里没有全连接层, 只是将刚刚得到的遗忘门门值与上一个时间步得到的C(t-1)相乘, 再加上输入门门值与当前时间步得到的未更新C(t)相乘的结果. 最终得到更新后的C(t)作为下一个时间步输入的一部分. 整个细胞状态更新过程就是对遗忘门和输入门的应用.
- 细胞状态更新过程演示:
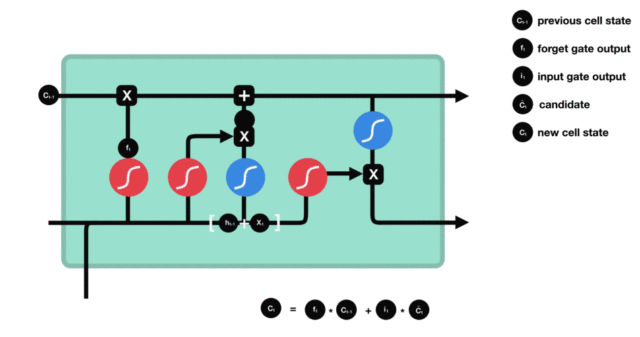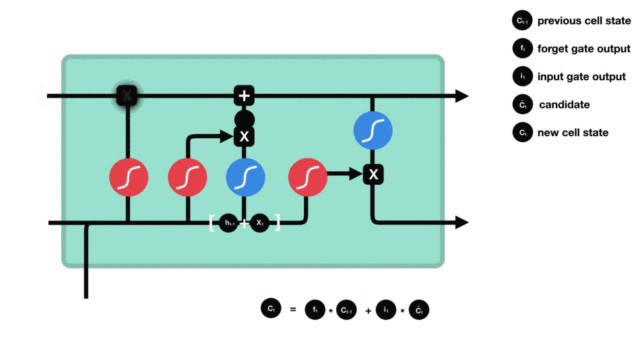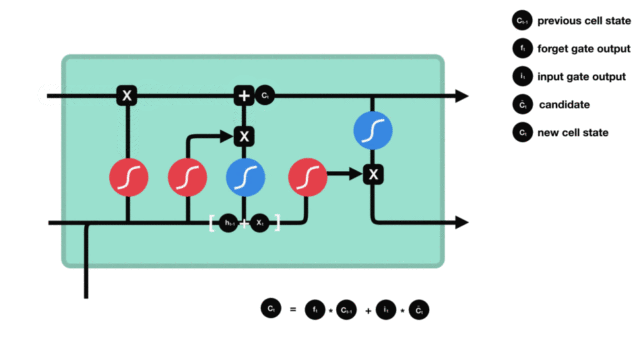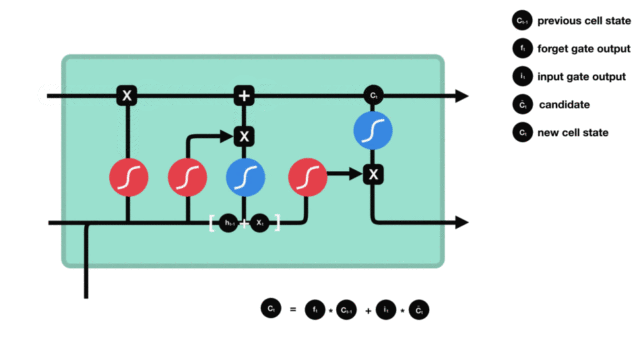
- 输出门部分结构图与计算公式:
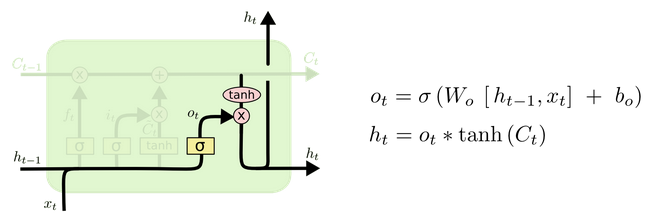
- 输出门结构分析:
- 输出门部分的公式也是两个, 第一个即是计算输出门的门值, 它和遗忘门,输入门计算方式相同. 第二个即是使用这个门值产生隐含状态h(t), 他将作用在更新后的细胞状态C(t)上, 并做tanh激活, 最终得到h(t)作为下一时间步输入的一部分. 整个输出门的过程, 就是为了产生隐含状态h(t).
- 输出门内部结构过程演示:
- 什么是Bi-LSTM ?
- Bi-LSTM即双向LSTM, 它没有改变LSTM本身任何的内部结构, 只是将LSTM应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出.
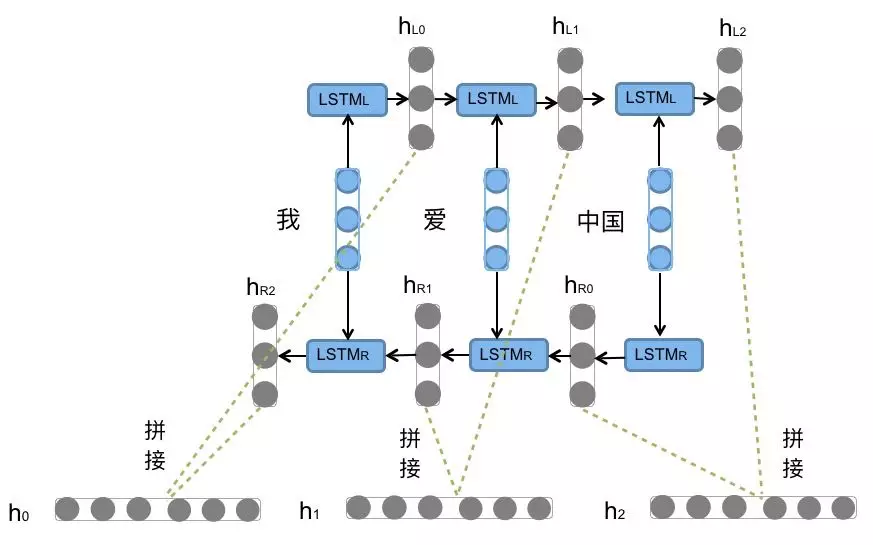
- Bi-LSTM结构分析:
- 我们看到图中对”我爱中国”这句话或者叫这个输入序列, 进行了从左到右和从右到左两次LSTM处理, 将得到的结果张量进行了拼接作为最终输出. 这种结构能够捕捉语言语法中一些特定的前置或后置特征, 增强语义关联,但是模型参数和计算复杂度也随之增加了一倍, 一般需要对语料和计算资源进行评估后决定是否使用该结构.
- Pytorch中LSTM工具的使用:
- 位置: 在torch.nn工具包之中, 通过torch.nn.LSTM可调用.
- nn.LSTM类初始化主要参数解释:
- input_size: 输入张量x中特征维度的大小.
- hidden_size: 隐层张量h中特征维度的大小.
- num_layers: 隐含层的数量.
- bidirectional: 是否选择使用双向LSTM, 如果为True, 则使用; 默认不使用.
- nn.LSTM类实例化对象主要参数解释:
- input: 输入张量x.
- h0: 初始化的隐层张量h.
- c0: 初始化的细胞状态张量c.
- nn.LSTM使用示例:
# 定义LSTM的参数含义: (input_size, hidden_size, num_layers)
# 定义输入张量的参数含义: (sequence_length, batch_size, input_size)
# 定义隐藏层初始张量和细胞初始状态张量的参数含义:
# (num_layers * num_directions, batch_size, hidden_size)
import torch.nn as nn
>>> import torch
>>> rnn = nn.LSTM(5, 6, 2)
>>> input = torch.randn(1, 3, 5)
>>> h0 = torch.randn(2, 3, 6)
>>> c0 = torch.randn(2, 3, 6)
>>> output, (hn, cn) = rnn(input, (h0, c0))
>>> output
tensor([[[ 0.0447, -0.0335, 0.1454, 0.0438, 0.0865, 0.0416],
[ 0.0105, 0.1923, 0.5507, -0.1742, 0.1569, -0.0548],
[-0.1186, 0.1835, -0.0022, -0.1388, -0.0877, -0.4007]]],
grad_fn=)
>>> hn
tensor([[[ 0.4647, -0.2364, 0.0645, -0.3996, -0.0500, -0.0152],
[ 0.3852, 0.0704, 0.2103, -0.2524, 0.0243, 0.0477],
[ 0.2571, 0.0608, 0.2322, 0.1815, -0.0513, -0.0291]],
[[ 0.0447, -0.0335, 0.1454, 0.0438, 0.0865, 0.0416],<br /> [ 0.0105, 0.1923, 0.5507, -0.1742, 0.1569, -0.0548],<br /> [-0.1186, 0.1835, -0.0022, -0.1388, -0.0877, -0.4007]]],<br /> grad_fn=<StackBackward>)<br />>>> cn<br />tensor([[[ 0.8083, -0.5500, 0.1009, -0.5806, -0.0668, -0.1161],<br /> [ 0.7438, 0.0957, 0.5509, -0.7725, 0.0824, 0.0626],<br /> [ 0.3131, 0.0920, 0.8359, 0.9187, -0.4826, -0.0717]],[[ 0.1240, -0.0526, 0.3035, 0.1099, 0.5915, 0.0828],<br /> [ 0.0203, 0.8367, 0.9832, -0.4454, 0.3917, -0.1983],<br /> [-0.2976, 0.7764, -0.0074, -0.1965, -0.1343, -0.6683]]],<br /> grad_fn=<StackBackward>)
- LSTM优势:
- LSTM的门结构能够有效减缓长序列问题中可能出现的梯度消失或爆炸, 虽然并不能杜绝这种现象, 但在更长的序列问题上表现优于传统RNN.
- LSTM缺点:
- 由于内部结构相对较复杂, 因此训练效率在同等算力下较传统RNN低很多.
小节总结
- LSTM(Long Short-Term Memory)也称长短时记忆结构, 它是传统RNN的变体, 与经典RNN相比能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时LSTM的结构更复杂, 它的核心结构可以分为四个部分去解析:
- 遗忘门
- 输入门
- 输出门
- 细胞状态
- 遗忘门结构分析:
- 与传统RNN的内部结构计算非常相似, 首先将当前时间步输入x(t)与上一个时间步隐含状态h(t-1)拼接, 得到[x(t), h(t-1)], 然后通过一个全连接层做变换, 最后通过sigmoid函数进行激活得到f(t), 我们可以将f(t)看作是门值, 好比一扇门开合的大小程度, 门值都将作用在通过该扇门的张量, 遗忘门门值将作用的上一层的细胞状态上, 代表遗忘过去的多少信息, 又因为遗忘门门值是由x(t), h(t-1)计算得来的, 因此整个公式意味着根据当前时间步输入和上一个时间步隐含状态h(t-1)来决定遗忘多少上一层的细胞状态所携带的过往信息.
- 输入门结构分析:
- 我们看到输入门的计算公式有两个, 第一个就是产生输入门门值的公式, 它和遗忘门公式几乎相同, 区别只是在于它们之后要作用的目标上. 这个公式意味着输入信息有多少需要进行过滤. 输入门的第二个公式是与传统RNN的内部结构计算相同. 对于LSTM来讲, 它得到的是当前的细胞状态, 而不是像经典RNN一样得到的是隐含状态.
- 细胞状态更新分析:
- 细胞更新的结构与计算公式非常容易理解, 这里没有全连接层, 只是将刚刚得到的遗忘门门值与上一个时间步得到的C(t-1)相乘, 再加上输入门门值与当前时间步得到的未更新C(t)相乘的结果. 最终得到更新后的C(t)作为下一个时间步输入的一部分. 整个细胞状态更新过程就是对遗忘门和输入门的应用.
- 输出门结构分析:
- 输出门部分的公式也是两个, 第一个即是计算输出门的门值, 它和遗忘门,输入门计算方式相同. 第二个即是使用这个门值产生隐含状态h(t), 他将作用在更新后的细胞状态C(t)上, 并做tanh激活, 最终得到h(t)作为下一时间步输入的一部分. 整个输出门的过程, 就是为了产生隐含状态h(t).
- 什么是Bi-LSTM ?
- Bi-LSTM即双向LSTM, 它没有改变LSTM本身任何的内部结构, 只是将LSTM应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出.
- Pytorch中LSTM工具的使用:
- 位置: 在torch.nn工具包之中, 通过torch.nn.LSTM可调用.
- LSTM优势:
- LSTM的门结构能够有效减缓长序列问题中可能出现的梯度消失或爆炸, 虽然并不能杜绝这种现象, 但在更长的序列问题上表现优于传统RNN.
- LSTM缺点:
- 由于内部结构相对较复杂, 因此训练效率在同等算力下较传统RNN低很多.
1.4 GRU模型
学习目标
- 了解GRU内部结构及计算公式.
- 掌握Pytorch中GRU工具的使用.
- 了解GRU的优势与缺点.
- GRU(Gated Recurrent Unit)也称门控循环单元结构, 它也是传统RNN的变体, 同LSTM一样能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时它的结构和计算要比LSTM更简单, 它的核心结构可以分为两个部分去解析:
- 更新门
- 重置门
GRU的内部结构图和计算公式
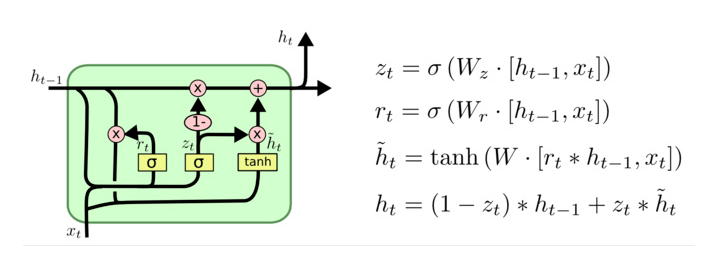
- 结构解释图:

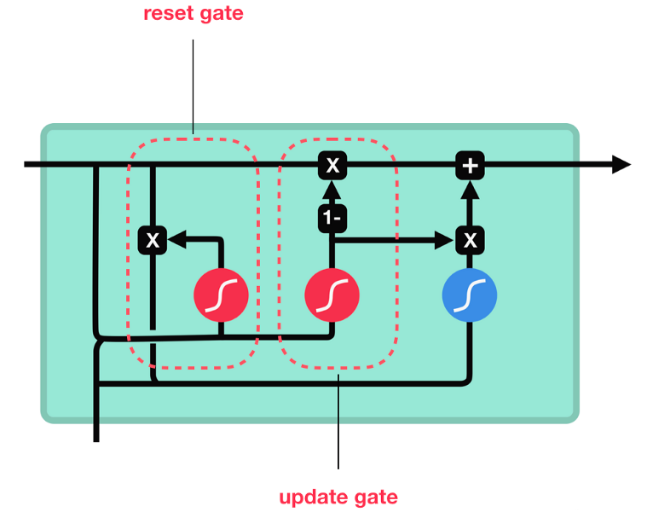
- GRU的更新门和重置门结构图:
- 内部结构分析:
- 和之前分析过的LSTM中的门控一样, 首先计算更新门和重置门的门值, 分别是z(t)和r(t), 计算方法就是使用X(t)与h(t-1)拼接进行线性变换, 再经过sigmoid激活. 之后重置门门值作用在了h(t-1)上, 代表控制上一时间步传来的信息有多少可以被利用. 接着就是使用这个重置后的h(t-1)进行基本的RNN计算, 即与x(t)拼接进行线性变化, 经过tanh激活, 得到新的h(t). 最后更新门的门值会作用在新的h(t),而1-门值会作用在h(t-1)上, 随后将两者的结果相加, 得到最终的隐含状态输出h(t), 这个过程意味着更新门有能力保留之前的结果, 当门值趋于1时, 输出就是新的h(t), 而当门值趋于0时, 输出就是上一时间步的h(t-1).
- Bi-GRU与Bi-LSTM的逻辑相同, 都是不改变其内部结构, 而是将模型应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出. 具体参见上小节中的Bi-LSTM.
- Pytorch中GRU工具的使用:
- 位置: 在torch.nn工具包之中, 通过torch.nn.GRU可调用.
- nn.GRU类初始化主要参数解释:
- input_size: 输入张量x中特征维度的大小.
- hidden_size: 隐层张量h中特征维度的大小.
- num_layers: 隐含层的数量.
- bidirectional: 是否选择使用双向LSTM, 如果为True, 则使用; 默认不使用.
- nn.GRU类实例化对象主要参数解释:
- input: 输入张量x.
- h0: 初始化的隐层张量h.
- nn.GRU使用示例:
>>> import torch
>>> import torch.nn as nn
>>> rnn = nn.GRU(5, 6, 2)
>>> input = torch.randn(1, 3, 5)
>>> h0 = torch.randn(2, 3, 6)
>>> output, hn = rnn(input, h0)
>>> output
tensor([[[-0.2097, -2.2225, 0.6204, -0.1745, -0.1749, -0.0460],
[-0.3820, 0.0465, -0.4798, 0.6837, -0.7894, 0.5173],
[-0.0184, -0.2758, 1.2482, 0.5514, -0.9165, -0.6667]]],
grad_fn=
>>> hn
tensor([[[ 0.6578, -0.4226, -0.2129, -0.3785, 0.5070, 0.4338],
[-0.5072, 0.5948, 0.8083, 0.4618, 0.1629, -0.1591],
[ 0.2430, -0.4981, 0.3846, -0.4252, 0.7191, 0.5420]],
[[-0.2097, -2.2225, 0.6204, -0.1745, -0.1749, -0.0460],<br /> [-0.3820, 0.0465, -0.4798, 0.6837, -0.7894, 0.5173],<br /> [-0.0184, -0.2758, 1.2482, 0.5514, -0.9165, -0.6667]]],<br /> grad_fn=<StackBackward>)
- GRU的优势:
- GRU和LSTM作用相同, 在捕捉长序列语义关联时, 能有效抑制梯度消失或爆炸, 效果都优于传统RNN且计算复杂度相比LSTM要小.
- GRU的缺点:
- GRU仍然不能完全解决梯度消失问题, 同时其作用RNN的变体, 有着RNN结构本身的一大弊端, 即不可并行计算, 这在数据量和模型体量逐步增大的未来, 是RNN发展的关键瓶颈.
小节总结
- GRU(Gated Recurrent Unit)也称门控循环单元结构, 它也是传统RNN的变体, 同LSTM一样能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时它的结构和计算要比LSTM更简单, 它的核心结构可以分为两个部分去解析:
- 更新门
- 重置门
- 内部结构分析:
- 和之前分析过的LSTM中的门控一样, 首先计算更新门和重置门的门值, 分别是z(t)和r(t), 计算方法就是使用X(t)与h(t-1)拼接进行线性变换, 再经过sigmoid激活. 之后重置门门值作用在了h(t-1)上, 代表控制上一时间步传来的信息有多少可以被利用. 接着就是使用这个重置后的h(t-1)进行基本的RNN计算, 即与x(t)拼接进行线性变化, 经过tanh激活, 得到新的h(t). 最后更新门的门值会作用在新的h(t),而1-门值会作用在h(t-1)上, 随后将两者的结果相加, 得到最终的隐含状态输出h(t), 这个过程意味着更新门有能力保留之前的结果, 当门值趋于1时, 输出就是新的h(t), 而当门值趋于0时, 输出就是上一时间步的h(t-1).
- Bi-GRU与Bi-LSTM的逻辑相同, 都是不改变其内部结构, 而是将模型应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出. 具体参见上小节中的Bi-LSTM.
- Pytorch中GRU工具的使用:
- 位置: 在torch.nn工具包之中, 通过torch.nn.GRU可调用.
- GRU的优势:
- GRU和LSTM作用相同, 在捕捉长序列语义关联时, 能有效抑制梯度消失或爆炸, 效果都优于传统RNN且计算复杂度相比LSTM要小.
- GRU的缺点:
- GRU仍然不能完全解决梯度消失问题, 同时其作用RNN的变体, 有着RNN结构本身的一大弊端, 即不可并行计算, 这在数据量和模型体量逐步增大的未来, 是RNN发展的关键瓶颈.
1.5 注意力机制
学习目标
- 了解什么是注意力计算规则以及常见的计算规则.
- 了解什么是注意力机制及其作用.
- 掌握注意力机制的实现步骤.
- 什么是注意力:
- 我们观察事物时,之所以能够快速判断一种事物(当然允许判断是错误的), 是因为我们大脑能够很快把注意力放在事物最具有辨识度的部分从而作出判断,而并非是从头到尾的观察一遍事物后,才能有判断结果. 正是基于这样的理论,就产生了注意力机制.
- 什么是注意力计算规则:
- 它需要三个指定的输入Q(query), K(key), V(value), 然后通过计算公式得到注意力的结果, 这个结果代表query在key和value作用下的注意力表示. 当输入的Q=K=V时, 称作自注意力计算规则.
- 常见的注意力计算规则:
- 将Q,K进行纵轴拼接, 做一次线性变化, 再使用softmax处理获得结果最后与V做张量乘法.
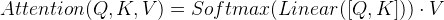
- 将Q,K进行纵轴拼接, 做一次线性变化后再使用tanh函数激活, 然后再进行内部求和, 最后使用softmax处理获得结果再与V做张量乘法.
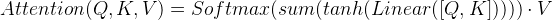
- 将Q与K的转置做点积运算, 然后除以一个缩放系数, 再使用softmax处理获得结果最后与V做张量乘法.
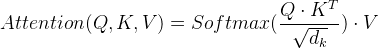
- 说明:当注意力权重矩阵和V都是三维张量且第一维代表为batch条数时, 则做bmm运算.bmm是一种特殊的张量乘法运算.
- bmm运算演示:
# 如果参数1形状是(b × n × m), 参数2形状是(b × m × p), 则输出为(b × n × p)
>>> input = torch.randn(10, 3, 4)
>>> mat2 = torch.randn(10, 4, 5)
>>> res = torch.bmm(input, mat2)
>>> res.size()
torch.Size([10, 3, 5])
什么是注意力机制
- 注意力机制是注意力计算规则能够应用的深度学习网络的载体, 同时包括一些必要的全连接层以及相关张量处理, 使其与应用网络融为一体. 使用自注意力计算规则的注意力机制称为自注意力机制.
- 说明: NLP领域中, 当前的注意力机制大多数应用于seq2seq架构, 即编码器和解码器模型.
注意力机制的作用
- 在解码器端的注意力机制: 能够根据模型目标有效的聚焦编码器的输出结果, 当其作为解码器的输入时提升效果. 改善以往编码器输出是单一定长张量, 无法存储过多信息的情况.
- 在编码器端的注意力机制: 主要解决表征问题, 相当于特征提取过程, 得到输入的注意力表示. 一般使用自注意力(self-attention).
注意力机制实现步骤
- 第一步: 根据注意力计算规则, 对Q,K,V进行相应的计算.
- 第二步: 根据第一步采用的计算方法, 如果是拼接方法,则需要将Q与第二步的计算结果再进行拼接, 如果是转置点积, 一般是自注意力, Q与V相同, 则不需要进行与Q的拼接.
- 第三步: 最后为了使整个attention机制按照指定尺寸输出, 使用线性层作用在第二步的结果上做一个线性变换, 得到最终对Q的注意力表示.
- 常见注意力机制的代码分析:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Attn(nn.Module):
def init(self, querysize, keysize, value_size1, value_size2, output_size):
“””初始化函数中的参数有5个, query_size代表query的最后一维大小
key_size代表key的最后一维大小, value_size1代表value的导数第二维大小,
value = (1, value_size1, value_size2)
value_size2代表value的倒数第一维大小, output_size输出的最后一维大小”””
super(Attn, self).__init()
# 将以下参数传入类中
self.query_size = query_size
self.key_size = key_size
self.value_size1 = value_size1
self.value_size2 = value_size2
self.output_size = output_size
# 初始化注意力机制实现第一步中需要的线性层.<br /> self.attn = nn.Linear(self.query_size + self.key_size, value_size1)# 初始化注意力机制实现第三步中需要的线性层.<br /> self.attn_combine = nn.Linear(self.query_size + value_size2, output_size)def forward(self, Q, K, V):<br /> """forward函数的输入参数有三个, 分别是Q, K, V, 根据模型训练常识, 输入给Attion机制的<br /> 张量一般情况都是三维张量, 因此这里也假设Q, K, V都是三维张量"""# 第一步, 按照计算规则进行计算, <br /> # 我们采用常见的第一种计算规则<br /> # 将Q,K进行纵轴拼接, 做一次线性变化, 最后使用softmax处理获得结果<br /> attn_weights = F.softmax(<br /> self.attn(torch.cat((Q[0], K[0]), 1)), dim=1)# 然后进行第一步的后半部分, 将得到的权重矩阵与V做矩阵乘法计算, <br /> # 当二者都是三维张量且第一维代表为batch条数时, 则做bmm运算<br /> attn_applied = torch.bmm(attn_weights.unsqueeze(0), V)# 之后进行第二步, 通过取[0]是用来降维, 根据第一步采用的计算方法, <br /> # 需要将Q与第一步的计算结果再进行拼接<br /> output = torch.cat((Q[0], attn_applied[0]), 1)# 最后是第三步, 使用线性层作用在第三步的结果上做一个线性变换并扩展维度,得到输出<br /> # 因为要保证输出也是三维张量, 因此使用unsqueeze(0)扩展维度<br /> output = self.attn_combine(output).unsqueeze(0)<br /> return output, attn_weights
- 调用:
query_size = 32
key_size = 32
value_size1 = 32
value_size2 = 64
output_size = 64
attn = Attn(query_size, key_size, value_size1, value_size2, output_size)
Q = torch.randn(1,1,32)
K = torch.randn(1,1,32)
V = torch.randn(1,32,64)
out = attn(Q, K ,V)
print(out[0])
print(out[1])
- 输出效果:
tensor([[[ 0.4477, -0.0500, -0.2277, -0.3168, -0.4096, -0.5982, 0.1548,
-0.0771, -0.0951, 0.1833, 0.3128, 0.1260, 0.4420, 0.0495,
-0.7774, -0.0995, 0.2629, 0.4957, 1.0922, 0.1428, 0.3024,
-0.2646, -0.0265, 0.0632, 0.3951, 0.1583, 0.1130, 0.5500,
-0.1887, -0.2816, -0.3800, -0.5741, 0.1342, 0.0244, -0.2217,
0.1544, 0.1865, -0.2019, 0.4090, -0.4762, 0.3677, -0.2553,
-0.5199, 0.2290, -0.4407, 0.0663, -0.0182, -0.2168, 0.0913,
-0.2340, 0.1924, -0.3687, 0.1508, 0.3618, -0.0113, 0.2864,
-0.1929, -0.6821, 0.0951, 0.1335, 0.3560, -0.3215, 0.6461,
0.1532]]], grad_fn=
tensor([[0.0395, 0.0342, 0.0200, 0.0471, 0.0177, 0.0209, 0.0244, 0.0465, 0.0346,
0.0378, 0.0282, 0.0214, 0.0135, 0.0419, 0.0926, 0.0123, 0.0177, 0.0187,
0.0166, 0.0225, 0.0234, 0.0284, 0.0151, 0.0239, 0.0132, 0.0439, 0.0507,
0.0419, 0.0352, 0.0392, 0.0546, 0.0224]], grad_fn=
- 更多有关注意力机制的应用我们将在案例中进行详尽的理解分析.
小节总结
- 学习了什么是注意力计算规则:
- 它需要三个指定的输入Q(query), K(key), V(value), 然后通过计算公式得到注意力的结果, 这个结果代表query在key和value作用下的注意力表示. 当输入的Q=K=V时, 称作自注意力计算规则.
- 常见的注意力计算规则:
- 将Q,K进行纵轴拼接, 做一次线性变化, 再使用softmax处理获得结果最后与V做张量乘法.
- 将Q,K进行纵轴拼接, 做一次线性变化后再使用tanh函数激活, 然后再进行内部求和, 最后使用softmax处理获得结果再与V做张量乘法.
- 将Q与K的转置做点积运算, 然后除以一个缩放系数, 再使用softmax处理获得结果最后与V做张量乘法.
- 学习了什么是注意力机制:
- 注意力机制是注意力计算规则能够应用的深度学习网络的载体, 同时包括一些必要的全连接层以及相关张量处理, 使其与应用网络融为一体. 使自注意力计算规则的注意力机制称为自注意力机制.
- 注意力机制的作用:
- 在解码器端的注意力机制: 能够根据模型目标有效的聚焦编码器的输出结果, 当其作为解码器的输入时提升效果. 改善以往编码器输出是单一定长张量, 无法存储过多信息的情况.
- 在编码器端的注意力机制: 主要解决表征问题, 相当于特征提取过程, 得到输入的注意力表示. 一般使用自注意力(self-attention).
- 注意力机制实现步骤:
- 第一步: 根据注意力计算规则, 对Q,K,V进行相应的计算.
- 第二步: 根据第一步采用的计算方法, 如果是拼接方法,则需要将Q与第二步的计算结果再进行拼接, 如果是转置点积, 一般是自注意力, Q与V相同, 则不需要进行与Q的拼接.
- 第三步: 最后为了使整个attention机制按照指定尺寸输出, 使用线性层作用在第二步的结果上做一个线性变换, 得到最终对Q的注意力表示.
- 学习并实现了一种常见的注意力机制的类Attn.
2. RNN经典案例
2.1 使用RNN模型构建人名分类器
- 学习目标:
- 了解有关人名分类问题和有关数据.
- 掌握使用RNN构建人名分类器实现过程.
- 关于人名分类问题:
- 以一个人名为输入, 使用模型帮助我们判断它最有可能是来自哪一个国家的人名, 这在某些国际化公司的业务中具有重要意义, 在用户注册过程中, 会根据用户填写的名字直接给他分配可能的国家或地区选项, 以及该国家或地区的国旗, 限制手机号码位数等等.
- 人名分类数据:
- 数据下载地址: https://download.pytorch.org/tutorial/data.zip
- 数据文件预览:
- data/
- names/
Arabic.txt
Chinese.txt
Czech.txt
Dutch.txt
English.txt
French.txt
German.txt
Greek.txt
Irish.txt
Italian.txt
Japanese.txt
Korean.txt
Polish.txt
Portuguese.txt
Russian.txt
Scottish.txt
Spanish.txt
Vietnamese.txt
- Chiness.txt预览:
Ang
Au-Yong
Bai
Ban
Bao
Bei
Bian
Bui
Cai
Cao
Cen
Chai
Chaim
Chan
Chang
Chao
Che
Chen
Cheng
- 整个案例的实现可分为以下五个步骤:
- 第一步: 导入必备的工具包.
- 第二步: 对data文件中的数据进行处理,满足训练要求.
- 第三步: 构建RNN模型(包括传统RNN, LSTM以及GRU).
- 第四步: 构建训练函数并进行训练.
- 第五步: 构建评估函数并进行预测.
- 第一步: 导入必备的工具包
- python版本使用3.6.x, pytorch版本使用1.3.1
pip install torch==1.3.1
# 从io中导入文件打开方法
from io import open
# 帮助使用正则表达式进行子目录的查询
import glob
import os
# 用于获得常见字母及字符规范化
import string
import unicodedata
# 导入随机工具random
import random
# 导入时间和数学工具包
import time
import math
# 导入torch工具
import torch
# 导入nn准备构建模型
import torch.nn as nn
# 引入制图工具包
import matplotlib.pyplot as plt
- 第二步: 对data文件中的数据进行处理,满足训练要求.
- 获取常用的字符数量:
# 获取所有常用字符包括字母和常用标点
all_letters = string.ascii_letters + “ .,;’”
获取常用字符数量
n_letters = len(all_letters)
print(“n_letter:”, n_letters)
- 输出效果:
n_letter: 57
- 字符规范化之unicode转Ascii函数:
# 关于编码问题我们暂且不去考虑
# 我们认为这个函数的作用就是去掉一些语言中的重音标记
# 如: Ślusàrski —-> Slusarski
def unicodeToAscii(s):
return ‘’.join(
c for c in unicodedata.normalize(‘NFD’, s)
if unicodedata.category(c) != ‘Mn’
and c in all_letters
)
- 调用:
s = “Ślusàrski”
a = unicodeToAscii(s)
print(a)
- 输出效果:
Slusarski
- 构建一个从持久化文件中读取内容到内存的函数:
data_path = “./data/name/“
def readLines(filename):
“””从文件中读取每一行加载到内存中形成列表”””
# 打开指定文件并读取所有内容, 使用strip()去除两侧空白符, 然后以’\n’进行切分
lines = open(filename, encoding=’utf-8’).read().strip().split(‘\n’)
# 对应每一个lines列表中的名字进行Ascii转换, 使其规范化.最后返回一个名字列表
return [unicodeToAscii(line) for line in lines]
- 调用:
# filename是数据集中某个具体的文件, 我们这里选择Chinese.txt
filename = data_path + “Chinese.txt”
lines = readLines(filename)
print(lines)
- 输出效果:
lines: [‘Ang’, ‘AuYong’, ‘Bai’, ‘Ban’, ‘Bao’, ‘Bei’, ‘Bian’, ‘Bui’, ‘Cai’, ‘Cao’, ‘Cen’, ‘Chai’, ‘Chaim’, ‘Chan’, ‘Chang’, ‘Chao’, ‘Che’, ‘Chen’, ‘Cheng’, ‘Cheung’, ‘Chew’, ‘Chieu’, ‘Chin’, ‘Chong’, ‘Chou’, ‘Chu’, ‘Cui’, ‘Dai’, ‘Deng’, ‘Ding’, ‘Dong’, ‘Dou’, ‘Duan’, ‘Eng’, ‘Fan’, ‘Fei’, ‘Feng’, ‘Foong’, ‘Fung’, ‘Gan’, ‘Gauk’, ‘Geng’, ‘Gim’, ‘Gok’, ‘Gong’, ‘Guan’, ‘Guang’, ‘Guo’, ‘Gwock’, ‘Han’, ‘Hang’, ‘Hao’, ‘Hew’, ‘Hiu’, ‘Hong’, ‘Hor’, ‘Hsiao’, ‘Hua’, ‘Huan’, ‘Huang’, ‘Hui’, ‘Huie’, ‘Huo’, ‘Jia’, ‘Jiang’, ‘Jin’, ‘Jing’, ‘Joe’, ‘Kang’, ‘Kau’, ‘Khoo’, ‘Khu’, ‘Kong’, ‘Koo’, ‘Kwan’, ‘Kwei’, ‘Kwong’, ‘Lai’, ‘Lam’, ‘Lang’, ‘Lau’, ‘Law’, ‘Lew’, ‘Lian’, ‘Liao’, ‘Lim’, ‘Lin’, ‘Ling’, ‘Liu’, ‘Loh’, ‘Long’, ‘Loong’, ‘Luo’, ‘Mah’, ‘Mai’, ‘Mak’, ‘Mao’, ‘Mar’, ‘Mei’, ‘Meng’, ‘Miao’, ‘Min’, ‘Ming’, ‘Moy’, ‘Mui’, ‘Nie’, ‘Niu’, ‘OuYang’, ‘OwYang’, ‘Pan’, ‘Pang’, ‘Pei’, ‘Peng’, ‘Ping’, ‘Qian’, ‘Qin’, ‘Qiu’, ‘Quan’, ‘Que’, ‘Ran’, ‘Rao’, ‘Rong’, ‘Ruan’, ‘Sam’, ‘Seah’, ‘See ‘, ‘Seow’, ‘Seto’, ‘Sha’, ‘Shan’, ‘Shang’, ‘Shao’, ‘Shaw’, ‘She’, ‘Shen’, ‘Sheng’, ‘Shi’, ‘Shu’, ‘Shuai’, ‘Shui’, ‘Shum’, ‘Siew’, ‘Siu’, ‘Song’, ‘Sum’, ‘Sun’, ‘Sze ‘, ‘Tan’, ‘Tang’, ‘Tao’, ‘Teng’, ‘Teoh’, ‘Thean’, ‘Thian’, ‘Thien’, ‘Tian’, ‘Tong’, ‘Tow’, ‘Tsang’, ‘Tse’, ‘Tsen’, ‘Tso’, ‘Tze’, ‘Wan’, ‘Wang’, ‘Wei’, ‘Wen’, ‘Weng’, ‘Won’, ‘Wong’, ‘Woo’, ‘Xiang’, ‘Xiao’, ‘Xie’, ‘Xing’, ‘Xue’, ‘Xun’, ‘Yan’, ‘Yang’, ‘Yao’, ‘Yap’, ‘Yau’, ‘Yee’, ‘Yep’, ‘Yim’, ‘Yin’, ‘Ying’, ‘Yong’, ‘You’, ‘Yuan’, ‘Zang’, ‘Zeng’, ‘Zha’, ‘Zhan’, ‘Zhang’, ‘Zhao’, ‘Zhen’, ‘Zheng’, ‘Zhong’, ‘Zhou’, ‘Zhu’, ‘Zhuo’, ‘Zong’, ‘Zou’, ‘Bing’, ‘Chi’, ‘Chu’, ‘Cong’, ‘Cuan’, ‘Dan’, ‘Fei’, ‘Feng’, ‘Gai’, ‘Gao’, ‘Gou’, ‘Guan’, ‘Gui’, ‘Guo’, ‘Hong’, ‘Hou’, ‘Huan’, ‘Jian’, ‘Jiao’, ‘Jin’, ‘Jiu’, ‘Juan’, ‘Jue’, ‘Kan’, ‘Kuai’, ‘Kuang’, ‘Kui’, ‘Lao’, ‘Liang’, ‘Lu’, ‘Luo’, ‘Man’, ‘Nao’, ‘Pian’, ‘Qiao’, ‘Qing’, ‘Qiu’, ‘Rang’, ‘Rui’, ‘She’, ‘Shi’, ‘Shuo’, ‘Sui’, ‘Tai’, ‘Wan’, ‘Wei’, ‘Xian’, ‘Xie’, ‘Xin’, ‘Xing’, ‘Xiong’, ‘Xuan’, ‘Yan’, ‘Yin’, ‘Ying’, ‘Yuan’, ‘Yue’, ‘Yun’, ‘Zha’, ‘Zhai’, ‘Zhang’, ‘Zhi’, ‘Zhuan’, ‘Zhui’]
- 构建人名类别(所属的语言)列表与人名对应关系字典:
# 构建的category_lines形如:{“English”:[“Lily”, “Susan”, “Kobe”], “Chinese”:[“Zhang San”, “Xiao Ming”]}
category_lines = {}
all_categories形如: [“English”,…,”Chinese”]
all_categories = []
读取指定路径下的txt文件, 使用glob,path中可以使用正则表达式
for filename in glob.glob(data_path + ‘*.txt’):
# 获取每个文件的文件名, 就是对应的名字类别
category = os.path.splitext(os.path.basename(filename))[0]
# 将其逐一装到all_categories列表中
all_categories.append(category)
# 然后读取每个文件的内容,形成名字列表
lines = readLines(filename)
# 按照对应的类别,将名字列表写入到category_lines字典中
category_lines[category] = lines
查看类别总数
n_categories = len(all_categories)
print(“n_categories:”, n_categories)
随便查看其中的一些内容
print(category_lines[‘Italian’][:5])
- 输出效果:
n_categories: 18
[‘Abandonato’, ‘Abatangelo’, ‘Abatantuono’, ‘Abate’, ‘Abategiovanni’]
- 将人名转化为对应onehot张量表示:
# 将字符串(单词粒度)转化为张量表示,如:”ab” —->
# tensor([[[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0.]],
[[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0.]]])
def lineToTensor(line):
“””将人名转化为对应onehot张量表示, 参数line是输入的人名”””
# 首先初始化一个0张量, 它的形状(len(line), 1, n_letters)
# 代表人名中的每个字母用一个1 x n_letters的张量表示.
tensor = torch.zeros(len(line), 1, n_letters)
# 遍历这个人名中的每个字符索引和字符
for li, letter in enumerate(line):
# 使用字符串方法find找到每个字符在all_letters中的索引
# 它也是我们生成onehot张量中1的索引位置
tensor[li][0][all_letters.find(letter)] = 1
# 返回结果
return tensor
- 调用:
line = “Bai”
line_tensor = lineToTensor(line)
print(“line_tensot:”, line_tensor)
- 输出效果:
line_tensot: tensor([[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]],
[[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,<br /> 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,<br /> 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,<br /> 0., 0., 0., 0., 0., 0.]],[[0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,<br /> 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,<br /> 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,<br /> 0., 0., 0., 0., 0., 0.]]])
- 第三步: 构建RNN模型
- 构建传统的RNN模型:
# 使用nn.RNN构建完成传统RNN使用类
class RNN(nn.Module):
def init(self, inputsize, hiddensize, output_size, num_layers=1):
“””初始化函数中有4个参数, 分别代表RNN输入最后一维尺寸, RNN的隐层最后一维尺寸, RNN层数”””
super(RNN, self).__init()
# 将hidden_size与num_layers传入其中
self.hidden_size = hidden_size
self.num_layers = num_layers
# 实例化预定义的nn.RNN, 它的三个参数分别是input_size, hidden_size, num_layers<br /> self.rnn = nn.RNN(input_size, hidden_size, num_layers)<br /> # 实例化nn.Linear, 这个线性层用于将nn.RNN的输出维度转化为指定的输出维度<br /> self.linear = nn.Linear(hidden_size, output_size)<br /> # 实例化nn中预定的Softmax层, 用于从输出层获得类别结果<br /> self.softmax = nn.LogSoftmax(dim=-1)def forward(self, input, hidden):<br /> """完成传统RNN中的主要逻辑, 输入参数input代表输入张量, 它的形状是1 x n_letters<br /> hidden代表RNN的隐层张量, 它的形状是self.num_layers x 1 x self.hidden_size"""<br /> # 因为预定义的nn.RNN要求输入维度一定是三维张量, 因此在这里使用unsqueeze(0)扩展一个维度<br /> input = input.unsqueeze(0)<br /> # 将input和hidden输入到传统RNN的实例化对象中,如果num_layers=1, rr恒等于hn<br /> rr, hn = self.rnn(input, hidden)<br /> # 将从RNN中获得的结果通过线性变换和softmax返回,同时返回hn作为后续RNN的输入<br /> return self.softmax(self.linear(rr)), hndef initHidden(self):<br /> """初始化隐层张量"""<br /> # 初始化一个(self.num_layers, 1, self.hidden_size)形状的0张量 <br /> return torch.zeros(self.num_layers, 1, self.hidden_size)
- torch.unsqueeze演示:
>>> x = torch.tensor([1, 2, 3, 4])
>>> torch.unsqueeze(x, 0)
tensor([[ 1, 2, 3, 4]])
>>> torch.unsqueeze(x, 1)
tensor([[ 1],
[ 2],
[ 3],
[ 4]])
- 构建LSTM模型:
# 使用nn.LSTM构建完成LSTM使用类
class LSTM(nn.Module):
def init(self, inputsize, hiddensize, output_size, num_layers=1):
“””初始化函数的参数与传统RNN相同”””
super(LSTM, self).__init()
# 将hidden_size与num_layers传入其中
self.hidden_size = hidden_size
self.num_layers = num_layers
# 实例化预定义的nn.LSTM<br /> self.lstm = nn.LSTM(input_size, hidden_size, num_layers)<br /> # 实例化nn.Linear, 这个线性层用于将nn.RNN的输出维度转化为指定的输出维度<br /> self.linear = nn.Linear(hidden_size, output_size)<br /> # 实例化nn中预定的Softmax层, 用于从输出层获得类别结果<br /> self.softmax = nn.LogSoftmax(dim=-1)def forward(self, input, hidden, c):<br /> """在主要逻辑函数中多出一个参数c, 也就是LSTM中的细胞状态张量"""<br /> # 使用unsqueeze(0)扩展一个维度<br /> input = input.unsqueeze(0)<br /> # 将input, hidden以及初始化的c传入lstm中<br /> rr, (hn, c) = self.lstm(input, (hidden, c))<br /> # 最后返回处理后的rr, hn, c<br /> return self.softmax(self.linear(rr)), hn, cdef initHiddenAndC(self): <br /> """初始化函数不仅初始化hidden还要初始化细胞状态c, 它们形状相同"""<br /> c = hidden = torch.zeros(self.num_layers, 1, self.hidden_size)<br /> return hidden, c
- 构建GRU模型:
# 使用nn.GRU构建完成传统RNN使用类
GRU与传统RNN的外部形式相同, 都是只传递隐层张量, 因此只需要更改预定义层的名字
class GRU(nn.Module):
def init(self, inputsize, hiddensize, output_size, num_layers=1):
super(GRU, self).__init()
self.hidden_size = hidden_size
self.num_layers = num_layers
# 实例化预定义的nn.GRU, 它的三个参数分别是input_size, hidden_size, num_layers<br /> self.gru = nn.GRU(input_size, hidden_size, num_layers)<br /> self.linear = nn.Linear(hidden_size, output_size)<br /> self.softmax = nn.LogSoftmax(dim=-1)def forward(self, input, hidden):<br /> input = input.unsqueeze(0)<br /> rr, hn = self.gru(input, hidden)<br /> return self.softmax(self.linear(rr)), hndef initHidden(self):<br /> return torch.zeros(self.num_layers, 1, self.hidden_size)
- 实例化参数:
# 因为是onehot编码, 输入张量最后一维的尺寸就是n_letters
input_size = n_letters
定义隐层的最后一维尺寸大小
n_hidden = 128
输出尺寸为语言类别总数n_categories
output_size = n_categories
num_layer使用默认值, num_layers = 1
- 输入参数:
# 假如我们以一个字母B作为RNN的首次输入, 它通过lineToTensor转为张量
# 因为我们的lineToTensor输出是三维张量, 而RNN类需要的二维张量
# 因此需要使用squeeze(0)降低一个维度
input = lineToTensor(‘B’).squeeze(0)
初始化一个三维的隐层0张量, 也是初始的细胞状态张量
hidden = c = torch.zeros(1, 1, n_hidden)
- 调用:
rnn = RNN(n_letters, n_hidden, n_categories)
lstm = LSTM(n_letters, n_hidden, n_categories)
gru = GRU(n_letters, n_hidden, n_categories)
rnn_output, next_hidden = rnn(input, hidden)
print(“rnn:”, rnn_output)
lstm_output, next_hidden, c = lstm(input, hidden, c)
print(“lstm:”, lstm_output)
gru_output, next_hidden = gru(input, hidden)
print(“gru:”, gru_output)
- 输出效果:
rnn: tensor([[[-2.8822, -2.8615, -2.9488, -2.8898, -2.9205, -2.8113, -2.9328,
-2.8239, -2.8678, -2.9474, -2.8724, -2.9703, -2.9019, -2.8871,
-2.9340, -2.8436, -2.8442, -2.9047]]], grad_fn=
lstm: tensor([[[-2.9427, -2.8574, -2.9175, -2.8492, -2.8962, -2.9276, -2.8500,
-2.9306, -2.8304, -2.9559, -2.9751, -2.8071, -2.9138, -2.8196,
-2.8575, -2.8416, -2.9395, -2.9384]]], grad_fn=
gru: tensor([[[-2.8042, -2.8894, -2.8355, -2.8951, -2.8682, -2.9502, -2.9056,
-2.8963, -2.8671, -2.9109, -2.9425, -2.8390, -2.9229, -2.8081,
-2.8800, -2.9561, -2.9205, -2.9546]]], grad_fn=
- 第四步: 构建训练函数并进行训练
- 从输出结果中获得指定类别函数:
def categoryFromOutput(output):
“””从输出结果中获得指定类别, 参数为输出张量output”””
# 从输出张量中返回最大的值和索引对象, 我们这里主要需要这个索引
top_n, top_i = output.topk(1)
# top_i对象中取出索引的值
category_i = top_i[0].item()
# 根据索引值获得对应语言类别, 返回语言类别和索引值
return all_categories[category_i], category_i
- torch.topk演示:
>>> x = torch.arange(1., 6.)
>>> x
tensor([ 1., 2., 3., 4., 5.])
>>> torch.topk(x, 3)
torch.return_types.topk(values=tensor([5., 4., 3.]), indices=tensor([4, 3, 2]))
- 输入参数:
# 将上一步中gru的输出作为函数的输入
output = gru_output
# tensor([[[-2.8042, -2.8894, -2.8355, -2.8951, -2.8682, -2.9502, -2.9056,
# -2.8963, -2.8671, -2.9109, -2.9425, -2.8390, -2.9229, -2.8081,
# -2.8800, -2.9561, -2.9205, -2.9546]]], grad_fn=
- 调用:
category, category_i = categoryFromOutput(output)
print(“category:”, category)
print(“category_i:”, category_i)
- 输出效果:
category: Portuguese
category_i: 13
- 随机生成训练数据:
def randomTrainingExample():
“””该函数用于随机产生训练数据”””
# 首先使用random的choice方法从all_categories随机选择一个类别
category = random.choice(all_categories)
# 然后在通过category_lines字典取category类别对应的名字列表
# 之后再从列表中随机取一个名字
line = random.choice(category_lines[category])
# 接着将这个类别在所有类别列表中的索引封装成tensor, 得到类别张量category_tensor
category_tensor = torch.tensor([all_categories.index(category)], dtype=torch.long)
# 最后, 将随机取到的名字通过函数lineToTensor转化为onehot张量表示
line_tensor = lineToTensor(line)
return category, line, category_tensor, line_tensor
- 调用:
# 我们随机取出十个进行结果查看
for i in range(10):
category, line, category_tensor, line_tensor = randomTrainingExample()
print(‘category =’, category, ‘/ line =’, line, ‘/ category_tensor =’, category_tensor)
- 输出效果:
category = French / line = Fontaine / category_tensor = tensor([5])
category = Italian / line = Grimaldi / category_tensor = tensor([9])
category = Chinese / line = Zha / category_tensor = tensor([1])
category = Italian / line = Rapallino / category_tensor = tensor([9])
category = Czech / line = Sherak / category_tensor = tensor([2])
category = Arabic / line = Najjar / category_tensor = tensor([0])
category = Scottish / line = Brown / category_tensor = tensor([15])
category = Arabic / line = Sarraf / category_tensor = tensor([0])
category = Japanese / line = Ibi / category_tensor = tensor([10])
category = Chinese / line = Zha / category_tensor = tensor([1])
- 构建传统RNN训练函数:
# 定义损失函数为nn.NLLLoss,因为RNN的最后一层是nn.LogSoftmax, 两者的内部计算逻辑正好能够吻合.
criterion = nn.NLLLoss()
设置学习率为0.005
learning_rate = 0.005
def trainRNN(category_tensor, line_tensor):
“””定义训练函数, 它的两个参数是category_tensor类别的张量表示, 相当于训练数据的标签,
line_tensor名字的张量表示, 相当于对应训练数据”””
# 在函数中, 首先通过实例化对象rnn初始化隐层张量<br /> hidden = rnn.initHidden()# 然后将模型结构中的梯度归0<br /> rnn.zero_grad()# 下面开始进行训练, 将训练数据line_tensor的每个字符逐个传入rnn之中, 得到最终结果<br /> for i in range(line_tensor.size()[0]):<br /> output, hidden = rnn(line_tensor[i], hidden)# 因为我们的rnn对象由nn.RNN实例化得到, 最终输出形状是三维张量, 为了满足于category_tensor<br /> # 进行对比计算损失, 需要减少第一个维度, 这里使用squeeze()方法<br /> loss = criterion(output.squeeze(0), category_tensor)# 损失进行反向传播<br /> loss.backward()<br /> # 更新模型中所有的参数<br /> for p in rnn.parameters():<br /> # 将参数的张量表示与参数的梯度乘以学习率的结果相加以此来更新参数<br /> p.data.add_(-learning_rate, p.grad.data)<br /> # 返回结果和损失的值<br /> return output, loss.item()
- torch.add演示:
>>> a = torch.randn(4)
>>> a
tensor([-0.9732, -0.3497, 0.6245, 0.4022])
>>> b = torch.randn(4, 1)
>>> b
tensor([[ 0.3743],
[-1.7724],
[-0.5811],
[-0.8017]])
>>> torch.add(a, b, alpha=10)
tensor([[ 2.7695, 3.3930, 4.3672, 4.1450],
[-18.6971, -18.0736, -17.0994, -17.3216],
[ -6.7845, -6.1610, -5.1868, -5.4090],
[ -8.9902, -8.3667, -7.3925, -7.6147]])
- 构建LSTM训练函数:
# 与传统RNN相比多出细胞状态c
def trainLSTM(category_tensor, line_tensor):
hidden, c = lstm.initHiddenAndC()
lstm.zero_grad()
for i in range(line_tensor.size()[0]):
# 返回output, hidden以及细胞状态c
output, hidden, c = lstm(line_tensor[i], hidden, c)
loss = criterion(output.squeeze(0), category_tensor)
loss.backward()
for p in lstm.parameters():<br /> p.data.add_(-learning_rate, p.grad.data)<br /> return output, loss.item()
- 构建GRU训练函数:
# 与传统RNN完全相同, 只不过名字改成了GRU
def trainGRU(category_tensor, line_tensor):
hidden = gru.initHidden()
gru.zero_grad()
for i in range(line_tensor.size()[0]):
output, hidden= gru(line_tensor[i], hidden)
loss = criterion(output.squeeze(0), category_tensor)
loss.backward()
for p in gru.parameters():<br /> p.data.add_(-learning_rate, p.grad.data)<br /> return output, loss.item()
- 构建时间计算函数:
def timeSince(since):
“获得每次打印的训练耗时, since是训练开始时间”
# 获得当前时间
now = time.time()
# 获得时间差,就是训练耗时
s = now - since
# 将秒转化为分钟, 并取整
m = math.floor(s / 60)
# 计算剩下不够凑成1分钟的秒数
s -= m * 60
# 返回指定格式的耗时
return ‘%dm %ds’ % (m, s)
- 输入参数:
# 假定模型训练开始时间是10min之前
since = time.time() - 10*60
- 调用:
period = timeSince(since)
print(period)
- 输出效果:
10m 0s
- 构建训练过程的日志打印函数:
# 设置训练迭代次数
n_iters = 1000
# 设置结果的打印间隔
print_every = 50
# 设置绘制损失曲线上的制图间隔
plot_every = 10
def train(train_type_fn):
“””训练过程的日志打印函数, 参数train_type_fn代表选择哪种模型训练函数, 如trainRNN”””
# 每个制图间隔损失保存列表
all_losses = []
# 获得训练开始时间戳
start = time.time()
# 设置初始间隔损失为0
current_loss = 0
# 从1开始进行训练迭代, 共n_iters次
for iter in range(1, n_iters + 1):
# 通过randomTrainingExample函数随机获取一组训练数据和对应的类别
category, line, category_tensor, line_tensor = randomTrainingExample()
# 将训练数据和对应类别的张量表示传入到train函数中
output, loss = train_type_fn(category_tensor, line_tensor)
# 计算制图间隔中的总损失
current_loss += loss
# 如果迭代数能够整除打印间隔
if iter % print_every == 0:
# 取该迭代步上的output通过categoryFromOutput函数获得对应的类别和类别索引
guess, guess_i = categoryFromOutput(output)
# 然后和真实的类别category做比较, 如果相同则打对号, 否则打叉号.
correct = ‘✓’ if guess == category else ‘✗ (%s)’ % category
# 打印迭代步, 迭代步百分比, 当前训练耗时, 损失, 该步预测的名字, 以及是否正确
print(‘%d %d%% (%s) %.4f %s / %s %s’ % (iter, iter / n_iters * 100, timeSince(start), loss, line, guess, correct))
# 如果迭代数能够整除制图间隔<br /> if iter % plot_every == 0:<br /> # 将保存该间隔中的平均损失到all_losses列表中<br /> all_losses.append(current_loss / plot_every)<br /> # 间隔损失重置为0<br /> current_loss = 0<br /> # 返回对应的总损失列表和训练耗时<br /> return all_losses, int(time.time() - start)
- 开始训练传统RNN, LSTM, GRU模型并制作对比图:
# 调用train函数, 分别进行RNN, LSTM, GRU模型的训练
# 并返回各自的全部损失, 以及训练耗时用于制图
all_losses1, period1 = train(trainRNN)
all_losses2, period2 = train(trainLSTM)
all_losses3, period3 = train(trainGRU)
绘制损失对比曲线, 训练耗时对比柱张图
# 创建画布0
plt.figure(0)
# 绘制损失对比曲线
plt.plot(all_losses1, label=”RNN”)
plt.plot(all_losses2, color=”red”, label=”LSTM”)
plt.plot(all_losses3, color=”orange”, label=”GRU”)
plt.legend(loc=’upper left’)
创建画布1
plt.figure(1)
x_data=[“RNN”, “LSTM”, “GRU”]
y_data = [period1, period2, period3]
# 绘制训练耗时对比柱状图
plt.bar(range(len(x_data)), y_data, tick_label=x_data)
- 传统RNN训练日志输出:
5000 5% (0m 16s) 3.2264 Carr / Chinese ✗ (English)
10000 10% (0m 30s) 1.2063 Biondi / Italian ✓
15000 15% (0m 47s) 1.4010 Palmeiro / Italian ✗ (Portuguese)
20000 20% (1m 0s) 3.8165 Konae / French ✗ (Japanese)
25000 25% (1m 17s) 0.5420 Koo / Korean ✓
30000 30% (1m 31s) 5.6180 Fergus / Portuguese ✗ (Irish)
35000 35% (1m 45s) 0.6073 Meeuwessen / Dutch ✓
40000 40% (1m 59s) 2.1356 Olan / Irish ✗ (English)
45000 45% (2m 13s) 0.3352 Romijnders / Dutch ✓
50000 50% (2m 26s) 1.1624 Flanagan / Irish ✓
55000 55% (2m 40s) 0.4743 Dubhshlaine / Irish ✓
60000 60% (2m 54s) 2.7260 Lee / Chinese ✗ (Korean)
65000 65% (3m 8s) 1.2075 Rutherford / English ✓
70000 70% (3m 23s) 3.6317 Han / Chinese ✗ (Vietnamese)
75000 75% (3m 37s) 0.1779 Accorso / Italian ✓
80000 80% (3m 52s) 0.1095 O’Brien / Irish ✓
85000 85% (4m 6s) 2.3845 Moran / Irish ✗ (English)
90000 90% (4m 21s) 0.3871 Xuan / Chinese ✓
95000 95% (4m 36s) 0.1104 Inoguchi / Japanese ✓
100000 100% (4m 52s) 4.2142 Simon / French ✓ (Irish)
- LSTM训练日志输出:
5000 5% (0m 25s) 2.8640 Fabian / Dutch ✗ (Polish)
10000 10% (0m 48s) 2.9079 Login / Russian ✗ (Irish)
15000 15% (1m 14s) 2.8223 Fernandes / Greek ✗ (Portuguese)
20000 20% (1m 40s) 2.7069 Hudecek / Polish ✗ (Czech)
25000 25% (2m 4s) 2.6162 Acciaio / Czech ✗ (Italian)
30000 30% (2m 27s) 2.4044 Magalhaes / Greek ✗ (Portuguese)
35000 35% (2m 52s) 1.3030 Antoschenko / Russian ✓
40000 40% (3m 18s) 0.8912 Xing / Chinese ✓
45000 45% (3m 42s) 1.1788 Numata / Japanese ✓
50000 50% (4m 7s) 2.2863 Baz / Vietnamese ✗ (Arabic)
55000 55% (4m 32s) 3.2549 Close / Dutch ✗ (Greek)
60000 60% (4m 54s) 4.5170 Pan / Vietnamese ✗ (French)
65000 65% (5m 16s) 1.1503 San / Chinese ✗ (Korean)
70000 70% (5m 39s) 1.2357 Pavlik / Polish ✗ (Czech)
75000 75% (6m 2s) 2.3275 Alves / Portuguese ✗ (English)
80000 80% (6m 28s) 2.3294 Plamondon / Scottish ✗ (French)
85000 85% (6m 54s) 2.7794 Water / French ✗ (English)
90000 90% (7m 18s) 0.8021 Pereira / Portuguese ✓
95000 95% (7m 43s) 1.4374 Kunkel / German ✓
100000 100% (8m 5s) 1.2792 Taylor / Scottish ✓
- GRU训练日志输出:
5000 5% (0m 22s) 2.8182 Bernard / Irish ✗ (Polish)
10000 10% (0m 48s) 2.8966 Macias / Greek ✗ (Spanish)
15000 15% (1m 13s) 3.1046 Morcos / Greek ✗ (Arabic)
20000 20% (1m 37s) 1.5359 Davlatov / Russian ✓
25000 25% (2m 1s) 1.0999 Han / Vietnamese ✓
30000 30% (2m 26s) 4.1017 Chepel / German ✗ (Russian)
35000 35% (2m 49s) 1.8765 Klein / Scottish ✗ (English)
40000 40% (3m 11s) 1.1265 an / Chinese ✗ (Vietnamese)
45000 45% (3m 34s) 0.3511 Slusarski / Polish ✓
50000 50% (3m 59s) 0.9694 Than / Vietnamese ✓
55000 55% (4m 25s) 2.3576 Bokhoven / Russian ✗ (Dutch)
60000 60% (4m 51s) 0.1344 Filipowski / Polish ✓
65000 65% (5m 15s) 1.4070 Reuter / German ✓
70000 70% (5m 37s) 1.8409 Guillory / Irish ✗ (French)
75000 75% (6m 0s) 0.6882 Song / Korean ✓
80000 80% (6m 22s) 5.0092 Maly / Scottish ✗ (Polish)
85000 85% (6m 43s) 2.4570 Sai / Chinese ✗ (Vietnamese)
90000 90% (7m 5s) 1.2006 Heel / German ✗ (Dutch)
95000 95% (7m 27s) 0.9144 Doan / Vietnamese ✓
100000 100% (7m 50s) 1.1320 Crespo / Portuguese ✓
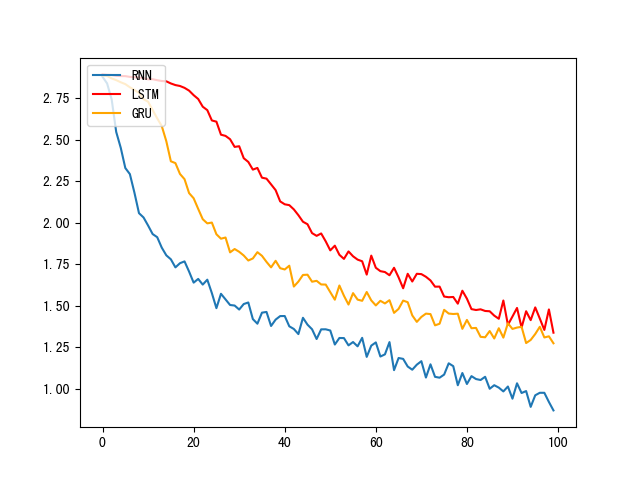
- 损失对比曲线:
- 损失对比曲线分析:
- 模型训练的损失降低快慢代表模型收敛程度, 由图可知, 传统RNN的模型收敛情况最好, 然后是GRU, 最后是LSTM, 这是因为: 我们当前处理的文本数据是人名, 他们的长度有限, 且长距离字母间基本无特定关联, 因此无法发挥改进模型LSTM和GRU的长距离捕捉语义关联的优势. 所以在以后的模型选用时, 要通过对任务的分析以及实验对比, 选择最适合的模型.
- 训练耗时对比图:
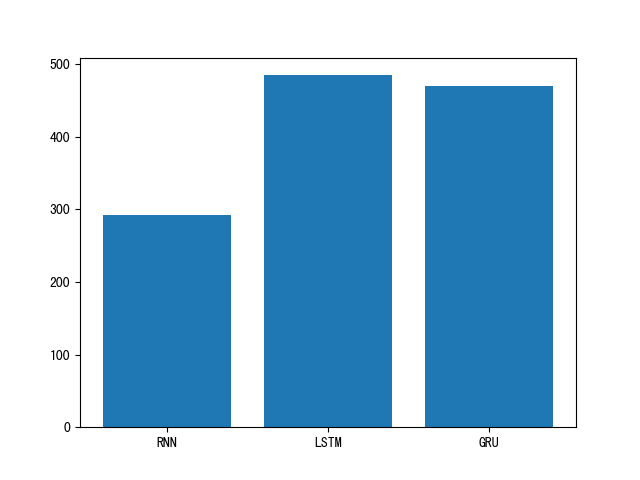
- 训练耗时对比图分析:
- 模型训练的耗时长短代表模型的计算复杂度, 由图可知, 也正如我们之前的理论分析, 传统RNN复杂度最低, 耗时几乎只是后两者的一半, 然后是GRU, 最后是复杂度最高的LSTM.
- 结论:
- 模型选用一般应通过实验对比, 并非越复杂或越先进的模型表现越好, 而是需要结合自己的特定任务, 从对数据的分析和实验结果中获得最佳答案.
- 第五步: 构建评估函数并进行预测
- 构建传统RNN评估函数:
def evaluateRNN(line_tensor):
“””评估函数, 和训练函数逻辑相同, 参数是line_tensor代表名字的张量表示”””
# 初始化隐层张量
hidden = rnn.initHidden()
# 将评估数据line_tensor的每个字符逐个传入rnn之中
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
# 获得输出结果
return output.squeeze(0)
- 构建LSTM评估函数:
def evaluateLSTM(line_tensor):
# 初始化隐层张量和细胞状态张量
hidden, c = lstm.initHiddenAndC()
# 将评估数据line_tensor的每个字符逐个传入lstm之中
for i in range(line_tensor.size()[0]):
output, hidden, c = lstm(line_tensor[i], hidden, c)
return output.squeeze(0)
- 构建GRU评估函数:
def evaluateGRU(line_tensor):
hidden = gru.initHidden()
# 将评估数据line_tensor的每个字符逐个传入gru之中
for i in range(line_tensor.size()[0]):
output, hidden = gru(line_tensor[i], hidden)
return output.squeeze(0)
- 输入参数:
line = “Bai”
line_tensor = lineToTensor(line)
- 调用:
rnn_output = evaluateRNN(line_tensor)
lstm_output = evaluateLSTM(line_tensor)
gru_output = evaluateGRU(line_tensor)
print(“rnn_output:”, rnn_output)
print(“gru_output:”, lstm_output)
print(“gru_output:”, gru_output)
- 输出效果:
rnn_output: tensor([[-2.8923, -2.7665, -2.8640, -2.7907, -2.9919, -2.9482, -2.8809, -2.9526,
-2.9445, -2.8115, -2.9544, -2.9043, -2.8016, -2.8668, -3.0484, -2.9382,
-2.9935, -2.7393]], grad_fn=
gru_output: tensor([[-2.9498, -2.9455, -2.8981, -2.7791, -2.8915, -2.8534, -2.8637, -2.8902,
-2.9537, -2.8834, -2.8973, -2.9711, -2.8622, -2.9001, -2.9149, -2.8762,
-2.8286, -2.8866]], grad_fn=
gru_output: tensor([[-2.8781, -2.9347, -2.7355, -2.9662, -2.9404, -2.9600, -2.8810, -2.8000,
-2.8151, -2.9132, -2.7564, -2.8849, -2.9814, -3.0499, -2.9153, -2.8190,
-2.8841, -2.9706]], grad_fn=
- 构建预测函数:
def predict(input_line, evaluate, n_predictions=3):
“””预测函数, 输入参数input_line代表输入的名字,
n_predictions代表需要取最有可能的top个”””
# 首先打印输入
print(‘\n> %s’ % input_line)
# 以下操作的相关张量不进行求梯度<br /> with torch.no_grad():<br /> # 使输入的名字转换为张量表示, 并使用evaluate函数获得预测输出<br /> output = evaluate(lineToTensor(input_line))# 从预测的输出中取前3个最大的值及其索引<br /> topv, topi = output.topk(n_predictions, 1, True)<br /> # 创建盛装结果的列表<br /> predictions = []<br /> # 遍历n_predictions<br /> for i in range(n_predictions):<br /> # 从topv中取出的output值<br /> value = topv[0][i].item()<br /> # 取出索引并找到对应的类别<br /> category_index = topi[0][i].item()<br /> # 打印ouput的值, 和对应的类别<br /> print('(%.2f) %s' % (value, all_categories[category_index]))<br /> # 将结果装进predictions中<br /> predictions.append([value, all_categories[category_index]])
- 调用:
for evaluate_fn in [evaluateRNN, evaluateLSTM, evaluateGRU]:
print(“-“*18)
predict(‘Dovesky’, evaluate_fn)
predict(‘Jackson’, evaluate_fn)
predict(‘Satoshi’, evaluate_fn)
- 输出效果
—————————
> Dovesky
(-0.58) Russian
(-1.40) Czech
(-2.52) Scottish
Jackson
(-0.27) Scottish
(-1.71) English
(-4.14) FrenchSatoshi
(-0.02) Japanese
(-5.10) Polish
(-5.42) Arabic
—————————Dovesky
(-1.03) Russian
(-1.12) Czech
(-2.22) PolishJackson
(-0.37) Scottish
(-2.17) English
(-2.81) CzechSatoshi
(-0.29) Japanese
(-1.90) Arabic
(-3.20) Polish
—————————Dovesky
(-0.44) Russian
(-1.55) Czech
(-3.06) PolishJackson
(-0.39) Scottish
(-1.91) English
(-3.10) PolishSatoshi
(-0.43) Japanese
(-1.22) Arabic
(-3.85) Italian
- 小节总结:
- 学习了关于人名分类问题: 以一个人名为输入, 使用模型帮助我们判断它最有可能是来自哪一个国家的人名, 这在某些国际化公司的业务中具有重要意义, 在用户注册过程中, 会根据用户填写的名字直接给他分配可能的国家或地区选项, 以及该国家或地区的国旗, 限制手机号码位数等等.
- 人名分类器的实现可分为以下五个步骤:
- 第一步: 导入必备的工具包.
- 第二步: 对data文件中的数据进行处理,满足训练要求.
- 第三步: 构建RNN模型(包括传统RNN, LSTM以及GRU).
- 第四步: 构建训练函数并进行训练.
- 第五步: 构建评估函数并进行预测.
- 第一步: 导入必备的工具包
- python版本使用3.6.x, pytorch版本使用1.3.1
- 第二步: 对data文件中的数据进行处理,满足训练要求
- 定义数据集路径并获取常用的字符数量.
- 字符规范化之unicode转Ascii函数unicodeToAscii.
- 构建一个从持久化文件中读取内容到内存的函数readLines.
- 构建人名类别(所属的语言)列表与人名对应关系字典
- 将人名转化为对应onehot张量表示函数lineToTensor
- 第三步: 构建RNN模型
- 构建传统的RNN模型的类class RNN.
- 构建LSTM模型的类class LSTM.
- 构建GRU模型的类class GRU.
- 第四步: 构建训练函数并进行训练
- 从输出结果中获得指定类别函数categoryFromOutput.
- 随机生成训练数据函数randomTrainingExample.
- 构建传统RNN训练函数trainRNN.
- 构建LSTM训练函数trainLSTM.
- 构建GRU训练函数trainGRU.
- 构建时间计算函数timeSince.
- 构建训练过程的日志打印函数train.得到损失对比曲线和训练耗时对比图.
- 损失对比曲线分析:
- 模型训练的损失降低快慢代表模型收敛程度, 由图可知, 传统RNN的模型收敛情况最好, 然后是GRU, 最后是LSTM, 这是因为: 我们当前处理的文本数据是人名, 他们的长度有限, 且长距离字母间基本无特定关联, 因此无法发挥改进模型LSTM和GRU的长距离捕捉语义关联的优势. 所以在以后的模型选用时, 要通过对任务的分析以及实验对比, 选择最适合的模型.
- 训练耗时对比图分析:
- 模型训练的耗时长短代表模型的计算复杂度, 由图可知, 也正如我们之前的理论分析, 传统RNN复杂度最低, 耗时几乎只是后两者的一半, 然后是GRU, 最后是复杂度最高的LSTM.
- 结论:
- 模型选用一般应通过实验对比, 并非越复杂或越先进的模型表现越好, 而是需要结合自己的特定任务, 从对数据的分析和实验结果中获得最佳答案.
- 第五步: 构建评估函数并进行预测
- 构建传统RNN评估函数evaluateRNN.
- 构建LSTM评估函数evaluateLSTM.
- 构建GRU评估函数evaluateGRU.
- 构建预测函数predict.
2.2 使用seq2seq模型架构实现英译法任务
- 学习目标:
- 更深一步了解seq2seq模型架构和翻译数据集.
- 掌握使用基于GRU的seq2seq模型架构实现翻译的过程.
- 掌握Attention机制在解码器端的实现过程.
- seq2seq模型架构:
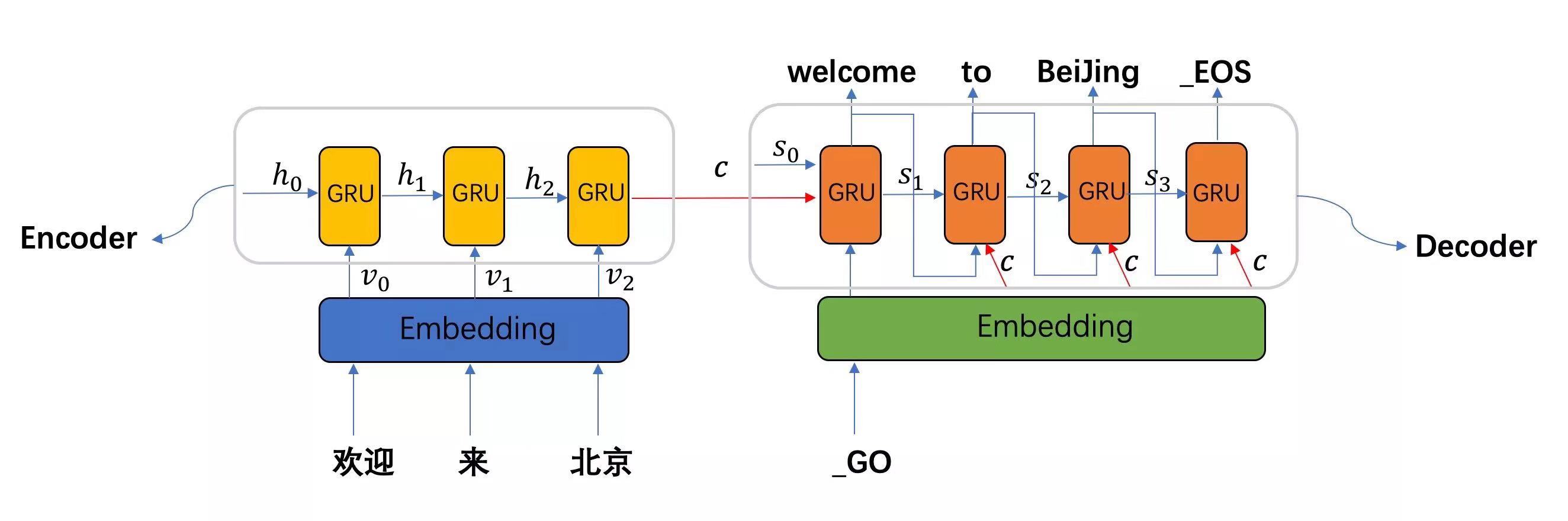
- seq2seq模型架构分析:
- 从图中可知, seq2seq模型架构, 包括两部分分别是encoder(编码器)和decoder(解码器), 编码器和解码器的内部实现都使用了GRU模型, 这里它要完成的是一个中文到英文的翻译: 欢迎 来 北京 —> welcome to BeiJing. 编码器首先处理中文输入”欢迎 来 北京”, 通过GRU模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量c, 接着解码器将使用这个中间语义张量c以及每一个时间步的隐层张量, 逐个生成对应的翻译语言.
- 翻译数据集:
- 下载地址: https://download.pytorch.org/tutorial/data.zip
- 数据文件预览:
- data/
- eng-fra.txt
She feeds her dog a meat-free diet. Elle fait suivre à son chien un régime sans viande.
She feeds her dog a meat-free diet. Elle fait suivre à son chien un régime non carné.
She folded her handkerchief neatly. Elle plia soigneusement son mouchoir.
She folded her handkerchief neatly. Elle a soigneusement plié son mouchoir.
She found a need and she filled it. Elle trouva un besoin et le remplit.
She gave birth to twins a week ago. Elle a donné naissance à des jumeaux il y a une semaine.
She gave him money as well as food. Elle lui donna de l’argent aussi bien que de la nourriture.
She gave it her personal attention. Elle y a prêté son attention personnelle.
She gave me a smile of recognition. Elle m’adressa un sourire indiquant qu’elle me reconnaissait.
She glanced shyly at the young man. Elle a timidement jeté un regard au jeune homme.
She goes to the movies once a week. Elle va au cinéma une fois par semaine.
She got into the car and drove off. Elle s’introduisit dans la voiture et partit.
- 基于GRU的seq2seq模型架构实现翻译的过程:
- 第一步: 导入必备的工具包.
- 第二步: 对持久化文件中数据进行处理, 以满足模型训练要求.
- 第三步: 构建基于GRU的编码器和解码器.
- 第四步: 构建模型训练函数, 并进行训练.
- 第五步: 构建模型评估函数, 并进行测试以及Attention效果分析.
- 第一步: 导入必备的工具包
- python版本使用3.6.x, pytorch版本使用1.3.1
pip install torch==1.3.1
从io工具包导入open方法
from io import open
# 用于字符规范化
import unicodedata
# 用于正则表达式
import re
# 用于随机生成数据
import random
# 用于构建网络结构和函数的torch工具包
import torch
import torch.nn as nn
import torch.nn.functional as F
# torch中预定义的优化方法工具包
from torch import optim
# 设备选择, 我们可以选择在cuda或者cpu上运行你的代码
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
第二步: 对持久化文件中数据进行处理, 以满足模型训练要求
- 将指定语言中的词汇映射成数值:
# 起始标志
SOS_token = 0
# 结束标志
EOS_token = 1
class Lang:
def init(self, name):
“””初始化函数中参数name代表传入某种语言的名字”””
# 将name传入类中
self.name = name
# 初始化词汇对应自然数值的字典
self.word2index = {}
# 初始化自然数值对应词汇的字典, 其中0,1对应的SOS和EOS已经在里面了
self.index2word = {0: “SOS”, 1: “EOS”}
# 初始化词汇对应的自然数索引,这里从2开始,因为0,1已经被开始和结束标志占用了
self.n_words = 2
def addSentence(self, sentence):<br /> """添加句子函数, 即将句子转化为对应的数值序列, 输入参数sentence是一条句子"""<br /> # 根据一般国家的语言特性(我们这里研究的语言都是以空格分个单词)<br /> # 对句子进行分割,得到对应的词汇列表<br /> for word in sentence.split(' '):<br /> # 然后调用addWord进行处理<br /> self.addWord(word)def addWord(self, word):<br /> """添加词汇函数, 即将词汇转化为对应的数值, 输入参数word是一个单词"""<br /> # 首先判断word是否已经在self.word2index字典的key中<br /> if word not in self.word2index:<br /> # 如果不在, 则将这个词加入其中, 并为它对应一个数值,即self.n_words<br /> self.word2index[word] = self.n_words<br /> # 同时也将它的反转形式加入到self.index2word中<br /> self.index2word[self.n_words] = word<br /> # self.n_words一旦被占用之后,逐次加1, 变成新的self.n_words<br /> self.n_words += 1
- 实例化参数:
name = “eng”
- 输入参数:
sentence = “hello I am Jay”
- 调用:
engl = Lang(name)
engl.addSentence(sentence)
print(“word2index:”, engl.word2index)
print(“index2word:”, engl.index2word)
print(“n_words:”, engl.n_words)
- 输出效果:
word2index: {‘hello’: 2, ‘I’: 3, ‘am’: 4, ‘Jay’: 5}
index2word: {0: ‘SOS’, 1: ‘EOS’, 2: ‘hello’, 3: ‘I’, 4: ‘am’, 5: ‘Jay’}
n_words: 6
- 字符规范化:
# 将unicode转为Ascii, 我们可以认为是去掉一些语言中的重音标记:Ślusàrski
def unicodeToAscii(s):
return ‘’.join(
c for c in unicodedata.normalize(‘NFD’, s)
if unicodedata.category(c) != ‘Mn’
)
def normalizeString(s):
“””字符串规范化函数, 参数s代表传入的字符串”””
# 使字符变为小写并去除两侧空白符, z再使用unicodeToAscii去掉重音标记
s = unicodeToAscii(s.lower().strip())
# 在.!?前加一个空格
s = re.sub(r”([.!?])”, r” \1”, s)
# 使用正则表达式将字符串中不是大小写字母和正常标点的都替换成空格
s = re.sub(r”[^a-zA-Z.!?]+”, r” “, s)
return s
- 输入参数:
s = “Are you kidding me?”
- 调用:
nsr = normalizeString(s)
print(nsr)
- 输出效果:
are you kidding me ?
- 将持久化文件中的数据加载到内存, 并实例化类Lang
data_path = ‘../Downloads/data/eng-fra.txt’
def readLangs(lang1, lang2):
“””读取语言函数, 参数lang1是源语言的名字, 参数lang2是目标语言的名字
返回对应的class Lang对象, 以及语言对列表”””
# 从文件中读取语言对并以/n划分存到列表lines中
lines = open(data_path, encoding=’utf-8’).\
read().strip().split(‘\n’)
# 对lines列表中的句子进行标准化处理,并以\t进行再次划分, 形成子列表, 也就是语言对
pairs = [[normalizeString(s) for s in l.split(‘\t’)] for l in lines]
# 然后分别将语言名字传入Lang类中, 获得对应的语言对象, 返回结果
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
- 输入参数:
lang1 = “eng”
lang2 = “fra”
- 调用:
input_lang, output_lang, pairs = readLangs(lang1, lang2)
print(“input_lang:”, input_lang)
print(“output_lang:”, output_lang)
print(“pairs中的前五个:”, pairs[:5])
- 输出效果:
inputlang: <__main__.Lang object at 0x11ecf0828>
outputlang: <__main.Lang object at 0x12d420d68>
pairs中的前五个: [[‘go .’, ‘va !’], [‘run !’, ‘cours !’], [‘run !’, ‘courez !’], [‘wow !’, ‘ca alors !’], [‘fire !’, ‘au feu !’]]
- 过滤出符合我们要求的语言对:
# 设置组成句子中单词或标点的最多个数
MAX_LENGTH = 10
选择带有指定前缀的语言特征数据作为训练数据
eng_prefixes = (
“i am “, “i m “,
“he is”, “he s “,
“she is”, “she s “,
“you are”, “you re “,
“we are”, “we re “,
“they are”, “they re “
)
def filterPair(p):
“””语言对过滤函数, 参数p代表输入的语言对, 如[‘she is afraid.’, ‘elle malade.’]”””
# p[0]代表英语句子,对它进行划分,它的长度应小于最大长度MAX_LENGTH并且要以指定的前缀开头
# p[1]代表法文句子, 对它进行划分,它的长度应小于最大长度MAX_LENGTH
return len(p[0].split(‘ ‘)) < MAX_LENGTH and \
p[0].startswith(eng_prefixes) and \
len(p[1].split(‘ ‘)) < MAX_LENGTH
def filterPairs(pairs):
“””对多个语言对列表进行过滤, 参数pairs代表语言对组成的列表, 简称语言对列表”””
# 函数中直接遍历列表中的每个语言对并调用filterPair即可
return [pair for pair in pairs if filterPair(pair)]
- 输入参数:
# 输入参数pairs使用readLangs函数的输出结果pairs
- 调用:
fpairs = filterPairs(pairs)
print(“过滤后的pairs前五个:”, fpairs[:5])
- 输出效果:
过滤后的pairs前五个: [[‘i m .’, ‘j ai ans .’], [‘i m ok .’, ‘je vais bien .’], [‘i m ok .’, ‘ca va .’], [‘i m fat .’, ‘je suis gras .’], [‘i m fat .’, ‘je suis gros .’]]
- 对以上数据准备函数进行整合, 并使用类Lang对语言对进行数值映射:
def prepareData(lang1, lang2):
“””数据准备函数, 完成将所有字符串数据向数值型数据的映射以及过滤语言对
参数lang1, lang2分别代表源语言和目标语言的名字”””
# 首先通过readLangs函数获得input_lang, output_lang对象,以及字符串类型的语言对列表
input_lang, output_lang, pairs = readLangs(lang1, lang2)
# 对字符串类型的语言对列表进行过滤操作
pairs = filterPairs(pairs)
# 对过滤后的语言对列表进行遍历
for pair in pairs:
# 并使用input_lang和output_lang的addSentence方法对其进行数值映射
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
# 返回数值映射后的对象, 和过滤后语言对
return input_lang, output_lang, pairs
- 调用:
input_lang, output_lang, pairs = prepareData(‘eng’, ‘fra’)
print(“input_n_words:”, input_lang.n_words)
print(“output_n_words:”, output_lang.n_words)
print(random.choice(pairs))
- 输出效果:
input_n_words: 2803
output_n_words: 4345
pairs随机选择一条: [‘you re such an idiot !’, ‘quelle idiote tu es !’]
- 将语言对转化为模型输入需要的张量:
def tensorFromSentence(lang, sentence):
“””将文本句子转换为张量, 参数lang代表传入的Lang的实例化对象, sentence是预转换的句子”””
# 对句子进行分割并遍历每一个词汇, 然后使用lang的word2index方法找到它对应的索引
# 这样就得到了该句子对应的数值列表
indexes = [lang.word2index[word] for word in sentence.split(‘ ‘)]
# 然后加入句子结束标志
indexes.append(EOS_token)
# 将其使用torch.tensor封装成张量, 并改变它的形状为nx1, 以方便后续计算
return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)
def tensorsFromPair(pair):
“””将语言对转换为张量对, 参数pair为一个语言对”””
# 调用tensorFromSentence分别将源语言和目标语言分别处理,获得对应的张量表示
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
# 最后返回它们组成的元组
return (input_tensor, target_tensor)
- 输入参数:
# 取pairs的第一条
pair = pairs[0]
- 调用:
pair_tensor = tensorsFromPair(pair)
print(pair_tensor)
- 输出效果:
(tensor([[2],
[3],
[4],
[1]]),
tensor([[2],
[3],
[4],
[5],
[1]]))
- 第三步: 构建基于GRU的编码器和解码器
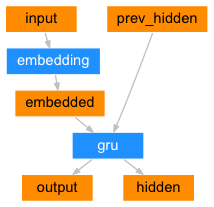
- 构建基于GRU的编码器
- 编码器结构图:
- 构建基于GRU的编码器
class EncoderRNN(nn.Module):
def init(self, inputsize, hiddensize):
“””它的初始化参数有两个, input_size代表解码器的输入尺寸即源语言的
词表大小,hidden_size代表GRU的隐层节点数, 也代表词嵌入维度, 同时又是GRU的输入尺寸”””
super(EncoderRNN, self).__init()
# 将参数hidden_size传入类中
self.hidden_size = hidden_size
# 实例化nn中预定义的Embedding层, 它的参数分别是input_size, hidden_size
# 这里的词嵌入维度即hidden_size
# nn.Embedding的演示在该代码下方
self.embedding = nn.Embedding(input_size, hidden_size)
# 然后实例化nn中预定义的GRU层, 它的参数是hidden_size
# nn.GRU的演示在该代码下方
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):<br /> """编码器前向逻辑函数中参数有两个, input代表源语言的Embedding层输入张量<br /> hidden代表编码器层gru的初始隐层张量"""<br /> # 将输入张量进行embedding操作, 并使其形状变为(1,1,-1),-1代表自动计算维度<br /> # 理论上,我们的编码器每次只以一个词作为输入, 因此词汇映射后的尺寸应该是[1, embedding]<br /> # 而这里转换成三维的原因是因为torch中预定义gru必须使用三维张量作为输入, 因此我们拓展了一个维度<br /> output = self.embedding(input).view(1, 1, -1)<br /> # 然后将embedding层的输出和传入的初始hidden作为gru的输入传入其中, <br /> # 获得最终gru的输出output和对应的隐层张量hidden, 并返回结果<br /> output, hidden = self.gru(output, hidden)<br /> return output, hiddendef initHidden(self):<br /> """初始化隐层张量函数"""<br /> # 将隐层张量初始化成为1x1xself.hidden_size大小的0张量<br /> return torch.zeros(1, 1, self.hidden_size, device=device)
- 实例化参数:
hidden_size = 25
input_size = 20
- 输入参数:
# pair_tensor[0]代表源语言即英文的句子,pair_tensor[0][0]代表句子中
的第一个词
input = pair_tensor[0][0]
# 初始化第一个隐层张量,1x1xhidden_size的0张量
hidden = torch.zeros(1, 1, hidden_size)
- 调用:
encoder = EncoderRNN(input_size, hidden_size)
encoder_output, hidden = encoder(input, hidden)
print(encoder_output)
- 输出效果:
tensor([[[ 1.9149e-01, -2.0070e-01, -8.3882e-02, -3.3037e-02, -1.3491e-01,
-8.8831e-02, -1.6626e-01, -1.9346e-01, -4.3996e-01, 1.8020e-02,
2.8854e-02, 2.2310e-01, 3.5153e-01, 2.9635e-01, 1.5030e-01,
-8.5266e-02, -1.4909e-01, 2.4336e-04, -2.3522e-01, 1.1359e-01,
1.6439e-01, 1.4872e-01, -6.1619e-02, -1.0807e-02, 1.1216e-02]]],
grad_fn=
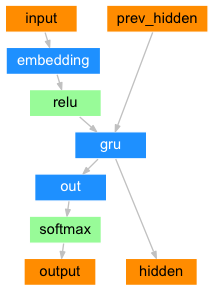
- 构建基于GRU的解码器
- 解码器结构图:
class DecoderRNN(nn.Module):
def init(self, hiddensize, outputsize):
“””初始化函数有两个参数,hidden_size代表解码器中GRU的输入尺寸,也是它的隐层节点数
output_size代表整个解码器的输出尺寸, 也是我们希望得到的指定尺寸即目标语言的词表大小”””
super(DecoderRNN, self).__init()
# 将hidden_size传入到类中
self.hidden_size = hidden_size
# 实例化一个nn中的Embedding层对象, 它的参数output这里表示目标语言的词表大小
# hidden_size表示目标语言的词嵌入维度
self.embedding = nn.Embedding(output_size, hidden_size)
# 实例化GRU对象,输入参数都是hidden_size,代表它的输入尺寸和隐层节点数相同
self.gru = nn.GRU(hidden_size, hidden_size)
# 实例化线性层, 对GRU的输出做线性变化, 获我们希望的输出尺寸output_size
# 因此它的两个参数分别是hidden_size, output_size
self.out = nn.Linear(hidden_size, output_size)
# 最后使用softmax进行处理,以便于分类
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):<br /> """解码器的前向逻辑函数中, 参数有两个, input代表目标语言的Embedding层输入张量<br /> hidden代表解码器GRU的初始隐层张量"""<br /> # 将输入张量进行embedding操作, 并使其形状变为(1,1,-1),-1代表自动计算维度<br /> # 原因和解码器相同,因为torch预定义的GRU层只接受三维张量作为输入<br /> output = self.embedding(input).view(1, 1, -1)<br /> # 然后使用relu函数对输出进行处理,根据relu函数的特性, 将使Embedding矩阵更稀疏,以防止过拟合<br /> output = F.relu(output)<br /> # 接下来, 将把embedding的输出以及初始化的hidden张量传入到解码器gru中<br /> output, hidden = self.gru(output, hidden)<br /> # 因为GRU输出的output也是三维张量,第一维没有意义,因此可以通过output[0]来降维<br /> # 再传给线性层做变换, 最后用softmax处理以便于分类<br /> output = self.softmax(self.out(output[0]))<br /> return output, hiddendef initHidden(self):<br /> """初始化隐层张量函数"""<br /> # 将隐层张量初始化成为1x1xself.hidden_size大小的0张量<br /> return torch.zeros(1, 1, self.hidden_size, device=device)
- 实例化参数:
hidden_size = 25
output_size = 10
- 输入参数:
# pair_tensor[1]代表目标语言即法文的句子,pair_tensor[1][0]代表句子中的第一个词
input = pair_tensor[1][0]
# 初始化第一个隐层张量,1x1xhidden_size的0张量
hidden = torch.zeros(1, 1, hidden_size)
- 调用:
decoder = DecoderRNN(hidden_size, output_size)
output, hidden = decoder(input, hidden)
print(output)
- 输出效果:
tensor([[-2.3554, -2.3551, -2.4361, -2.2158, -2.2550, -2.6237, -2.2917, -2.2663,
-2.2409, -2.0783]], grad_fn=
- 构建基于GRU和Attention的解码器
- 解码器结构图:
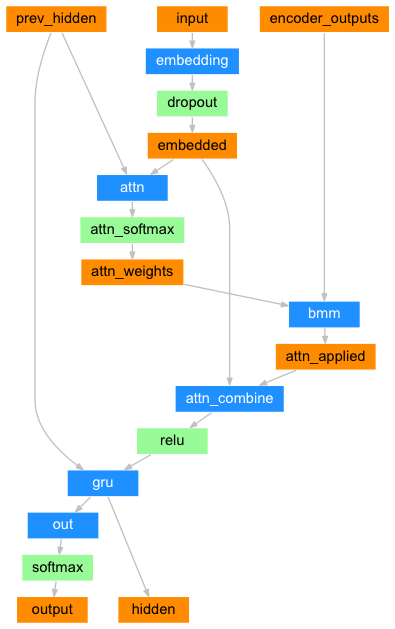
class AttnDecoderRNN(nn.Module):
def init(self, hiddensize, outputsize, dropout_p=0.1, max_length=MAX_LENGTH):
“””初始化函数中的参数有4个, hidden_size代表解码器中GRU的输入尺寸,也是它的隐层节点数
output_size代表整个解码器的输出尺寸, 也是我们希望得到的指定尺寸即目标语言的词表大小
dropout_p代表我们使用dropout层时的置零比率,默认0.1, max_length代表句子的最大长度”””
super(AttnDecoderRNN, self).__init()
# 将以下参数传入类中
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
# 实例化一个Embedding层, 输入参数是self.output_size和self.hidden_size<br /> self.embedding = nn.Embedding(self.output_size, self.hidden_size)<br /> # 根据attention的QKV理论,attention的输入参数为三个Q,K,V,<br /> # 第一步,使用Q与K进行attention权值计算得到权重矩阵, 再与V做矩阵乘法, 得到V的注意力表示结果.<br /> # 这里常见的计算方式有三种:<br /> # 1,将Q,K进行纵轴拼接, 做一次线性变化, 再使用softmax处理获得结果最后与V做张量乘法<br /> # 2,将Q,K进行纵轴拼接, 做一次线性变化后再使用tanh函数激活, 然后再进行内部求和, 最后使用softmax处理获得结果再与V做张量乘法<br /> # 3,将Q与K的转置做点积运算, 然后除以一个缩放系数, 再使用softmax处理获得结果最后与V做张量乘法# 说明:当注意力权重矩阵和V都是三维张量且第一维代表为batch条数时, 则做bmm运算.# 第二步, 根据第一步采用的计算方法, 如果是拼接方法,则需要将Q与第二步的计算结果再进行拼接, <br /> # 如果是转置点积, 一般是自注意力, Q与V相同, 则不需要进行与Q的拼接.因此第二步的计算方式与第一步采用的全值计算方法有关.<br /> # 第三步,最后为了使整个attention结构按照指定尺寸输出, 使用线性层作用在第二步的结果上做一个线性变换. 得到最终对Q的注意力表示.# 我们这里使用的是第一步中的第一种计算方式, 因此需要一个线性变换的矩阵, 实例化nn.Linear<br /> # 因为它的输入是Q,K的拼接, 所以输入的第一个参数是self.hidden_size * 2,第二个参数是self.max_length<br /> # 这里的Q是解码器的Embedding层的输出, K是解码器GRU的隐层输出,因为首次隐层还没有任何输出,会使用编码器的隐层输出<br /> # 而这里的V是编码器层的输出<br /> self.attn = nn.Linear(self.hidden_size * 2, self.max_length)<br /> # 接着我们实例化另外一个线性层, 它是attention理论中的第四步的线性层,用于规范输出尺寸<br /> # 这里它的输入来自第三步的结果, 因为第三步的结果是将Q与第二步的结果进行拼接, 因此输入维度是self.hidden_size * 2<br /> self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)<br /> # 接着实例化一个nn.Dropout层,并传入self.dropout_p<br /> self.dropout = nn.Dropout(self.dropout_p)<br /> # 之后实例化nn.GRU, 它的输入和隐层尺寸都是self.hidden_size<br /> self.gru = nn.GRU(self.hidden_size, self.hidden_size)<br /> # 最后实例化gru后面的线性层,也就是我们的解码器输出层.<br /> self.out = nn.Linear(self.hidden_size, self.output_size)def forward(self, input, hidden, encoder_outputs):<br /> """forward函数的输入参数有三个, 分别是源数据输入张量, 初始的隐层张量, 以及解码器的输出张量"""# 根据结构计算图, 输入张量进行Embedding层并扩展维度<br /> embedded = self.embedding(input).view(1, 1, -1)<br /> # 使用dropout进行随机丢弃,防止过拟合<br /> embedded = self.dropout(embedded)# 进行attention的权重计算, 哦我们呢使用第一种计算方式:<br /> # 将Q,K进行纵轴拼接, 做一次线性变化, 最后使用softmax处理获得结果<br /> attn_weights = F.softmax(<br /> self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)# 然后进行第一步的后半部分, 将得到的权重矩阵与V做矩阵乘法计算, 当二者都是三维张量且第一维代表为batch条数时, 则做bmm运算<br /> attn_applied = torch.bmm(attn_weights.unsqueeze(0),<br /> encoder_outputs.unsqueeze(0))# 之后进行第二步, 通过取[0]是用来降维, 根据第一步采用的计算方法, 需要将Q与第一步的计算结果再进行拼接<br /> output = torch.cat((embedded[0], attn_applied[0]), 1)# 最后是第三步, 使用线性层作用在第三步的结果上做一个线性变换并扩展维度,得到输出<br /> output = self.attn_combine(output).unsqueeze(0)# attention结构的结果使用relu激活<br /> output = F.relu(output)# 将激活后的结果作为gru的输入和hidden一起传入其中<br /> output, hidden = self.gru(output, hidden)# 最后将结果降维并使用softmax处理得到最终的结果<br /> output = F.log_softmax(self.out(output[0]), dim=1)<br /> # 返回解码器结果,最后的隐层张量以及注意力权重张量<br /> return output, hidden, attn_weightsdef initHidden(self):<br /> """初始化隐层张量函数"""<br /> # 将隐层张量初始化成为1x1xself.hidden_size大小的0张量<br /> return torch.zeros(1, 1, self.hidden_size, device=device)
- 实例化参数:
hidden_size = 25
output_size = 10
- 输入参数:
input = pair_tensor[1][0]
hidden = torch.zeros(1, 1, hidden_size)
# encoder_outputs需要是encoder中每一个时间步的输出堆叠而成
# 它的形状应该是10x25, 我们这里直接随机初始化一个张量
encoder_outputs = torch.randn(10, 25)
- 调用:
decoder = AttnDecoderRNN(hidden_size, output_size)
output, hidden, attn_weights= decoder(input, hidden, encoder_outputs)
print(output)
- 输出效果:
tensor([[-2.3556, -2.1418, -2.2012, -2.5109, -2.4025, -2.2182, -2.2123, -2.4608,
-2.2124, -2.3827]], grad_fn=
- 第四步: 构建模型训练函数, 并进行训练
- 什么是teacher_forcing?
- 它是一种用于序列生成任务的训练技巧, 在seq2seq架构中, 根据循环神经网络理论,解码器每次应该使用上一步的结果作为输入的一部分, 但是训练过程中,一旦上一步的结果是错误的,就会导致这种错误被累积,无法达到训练效果, 因此,我们需要一种机制改变上一步出错的情况,因为训练时我们是已知正确的输出应该是什么,因此可以强制将上一步结果设置成正确的输出, 这种方式就叫做teacher_forcing.
- 什么是teacher_forcing?
- teacher_forcing的作用:
- 能够在训练的时候矫正模型的预测,避免在序列生成的过程中误差进一步放大.
- teacher_forcing能够极大的加快模型的收敛速度,令模型训练过程更快更平稳.
- 构建训练函数:
# 设置teacher_forcing比率为0.5
teacher_forcing_ratio = 0.5
def train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=MAX_LENGTH):
“””训练函数, 输入参数有8个, 分别代表input_tensor:源语言输入张量,target_tensor:目标语言输入张量,encoder, decoder:编码器和解码器实例化对象
encoder_optimizer, decoder_optimizer:编码器和解码器优化方法,criterion:损失函数计算方法,max_length:句子的最大长度”””
# 初始化隐层张量<br /> encoder_hidden = encoder.initHidden()# 编码器和解码器优化器梯度归0<br /> encoder_optimizer.zero_grad()<br /> decoder_optimizer.zero_grad()# 根据源文本和目标文本张量获得对应的长度<br /> input_length = input_tensor.size(0)<br /> target_length = target_tensor.size(0)# 初始化编码器输出张量,形状是max_lengthxencoder.hidden_size的0张量<br /> encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)# 初始设置损失为0<br /> loss = 0# 循环遍历输入张量索引<br /> for ei in range(input_length):<br /> # 根据索引从input_tensor取出对应的单词的张量表示,和初始化隐层张量一同传入encoder对象中<br /> encoder_output, encoder_hidden = encoder(<br /> input_tensor[ei], encoder_hidden)<br /> # 将每次获得的输出encoder_output(三维张量), 使用[0, 0]降两维变成向量依次存入到encoder_outputs<br /> # 这样encoder_outputs每一行存的都是对应的句子中每个单词通过编码器的输出结果<br /> encoder_outputs[ei] = encoder_output[0, 0]# 初始化解码器的第一个输入,即起始符<br /> decoder_input = torch.tensor([[SOS_token]], device=device)# 初始化解码器的隐层张量即编码器的隐层输出<br /> decoder_hidden = encoder_hidden# 根据随机数与teacher_forcing_ratio对比判断是否使用teacher_forcing<br /> use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False# 如果使用teacher_forcing<br /> if use_teacher_forcing:<br /> # 循环遍历目标张量索引<br /> for di in range(target_length):<br /> # 将decoder_input, decoder_hidden, encoder_outputs即attention中的QKV, <br /> # 传入解码器对象, 获得decoder_output, decoder_hidden, decoder_attention<br /> decoder_output, decoder_hidden, decoder_attention = decoder(<br /> decoder_input, decoder_hidden, encoder_outputs)<br /> # 因为使用了teacher_forcing, 无论解码器输出的decoder_output是什么, 我们都只<br /> # 使用‘正确的答案’,即target_tensor[di]来计算损失<br /> loss += criterion(decoder_output, target_tensor[di])<br /> # 并强制将下一次的解码器输入设置为‘正确的答案’<br /> decoder_input = target_tensor[di]else:<br /> # 如果不使用teacher_forcing<br /> # 仍然遍历目标张量索引<br /> for di in range(target_length):<br /> # 将decoder_input, decoder_hidden, encoder_outputs传入解码器对象<br /> # 获得decoder_output, decoder_hidden, decoder_attention<br /> decoder_output, decoder_hidden, decoder_attention = decoder(<br /> decoder_input, decoder_hidden, encoder_outputs)<br /> # 只不过这里我们将从decoder_output取出答案<br /> topv, topi = decoder_output.topk(1)<br /> # 损失计算仍然使用decoder_output和target_tensor[di]<br /> loss += criterion(decoder_output, target_tensor[di])<br /> # 最后如果输出值是终止符,则循环停止<br /> if topi.squeeze().item() == EOS_token:<br /> break<br /> # 否则,并对topi降维并分离赋值给decoder_input以便进行下次运算<br /> # 这里的detach的分离作用使得这个decoder_input与模型构建的张量图无关,相当于全新的外界输入<br /> decoder_input = topi.squeeze().detach()# 误差进行反向传播<br /> loss.backward()<br /> # 编码器和解码器进行优化即参数更新<br /> encoder_optimizer.step()<br /> decoder_optimizer.step()# 最后返回平均损失<br /> return loss.item() / target_length
- 构建时间计算函数:
# 导入时间和数学工具包
import time
import math
def timeSince(since):
“获得每次打印的训练耗时, since是训练开始时间”
# 获得当前时间
now = time.time()
# 获得时间差,就是训练耗时
s = now - since
# 将秒转化为分钟, 并取整
m = math.floor(s / 60)
# 计算剩下不够凑成1分钟的秒数
s -= m * 60
# 返回指定格式的耗时
return ‘%dm %ds’ % (m, s)
- 输入参数:
# 假定模型训练开始时间是10min之前
since = time.time() - 10*60
- 调用:
period = timeSince(since)
print(period)
- 输出效果:
10m 0s
- 调用训练函数并打印日志和制图:
# 导入plt以便绘制损失曲线
import matplotlib.pyplot as plt
def trainIters(encoder, decoder, n_iters, print_every=1000, plot_every=100, learning_rate=0.01):
“””训练迭代函数, 输入参数有6个,分别是encoder, decoder: 编码器和解码器对象,
n_iters: 总迭代步数, print_every:打印日志间隔, plot_every:绘制损失曲线间隔, learning_rate学习率”””
# 获得训练开始时间戳
start = time.time()
# 每个损失间隔的平均损失保存列表,用于绘制损失曲线
plot_losses = []
# 每个打印日志间隔的总损失,初始为0<br /> print_loss_total = 0 <br /> # 每个绘制损失间隔的总损失,初始为0<br /> plot_loss_total = 0# 使用预定义的SGD作为优化器,将参数和学习率传入其中<br /> encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)<br /> decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)# 选择损失函数<br /> criterion = nn.NLLLoss()# 根据设置迭代步进行循环<br /> for iter in range(1, n_iters + 1):<br /> # 每次从语言对列表中随机取出一条作为训练语句<br /> training_pair = tensorsFromPair(random.choice(pairs))<br /> # 分别从training_pair中取出输入张量和目标张量<br /> input_tensor = training_pair[0]<br /> target_tensor = training_pair[1]# 通过train函数获得模型运行的损失<br /> loss = train(input_tensor, target_tensor, encoder,<br /> decoder, encoder_optimizer, decoder_optimizer, criterion)<br /> # 将损失进行累和<br /> print_loss_total += loss<br /> plot_loss_total += loss# 当迭代步达到日志打印间隔时<br /> if iter % print_every == 0:<br /> # 通过总损失除以间隔得到平均损失<br /> print_loss_avg = print_loss_total / print_every<br /> # 将总损失归0<br /> print_loss_total = 0<br /> # 打印日志,日志内容分别是:训练耗时,当前迭代步,当前进度百分比,当前平均损失<br /> print('%s (%d %d%%) %.4f' % (timeSince(start),<br /> iter, iter / n_iters * 100, print_loss_avg))# 当迭代步达到损失绘制间隔时<br /> if iter % plot_every == 0:<br /> # 通过总损失除以间隔得到平均损失<br /> plot_loss_avg = plot_loss_total / plot_every<br /> # 将平均损失装进plot_losses列表<br /> plot_losses.append(plot_loss_avg)<br /> # 总损失归0<br /> plot_loss_total = 0# 绘制损失曲线<br /> plt.figure() <br /> plt.plot(plot_losses)<br /> # 保存到指定路径<br /> plt.savefig("./s2s_loss.png")
- 输入参数:
# 设置隐层大小为256 ,也是词嵌入维度
hidden_size = 256
# 通过input_lang.n_words获取输入词汇总数,与hidden_size一同传入EncoderRNN类中
# 得到编码器对象encoder1
encoder1 = EncoderRNN(input_lang.n_words, hidden_size).to(device)
通过output_lang.n_words获取目标词汇总数,与hidden_size和dropout_p一同传入AttnDecoderRNN类中
# 得到解码器对象attn_decoder1
attn_decoder1 = AttnDecoderRNN(hidden_size, output_lang.n_words, dropout_p=0.1).to(device)
设置迭代步数
n_iters = 75000
# 设置日志打印间隔
print_every = 5000
- 调用:
# 调用trainIters进行模型训练,将编码器对象encoder1,码器对象attn_decoder1,迭代步数,日志打印间隔传入其中
trainIters(encoder1, attn_decoder1, n_iters, print_every=print_every)
- 输出效果:
3m 35s (5000 6%) 3.4159
7m 12s (10000 13%) 2.7805
10m 46s (15000 20%) 2.4663
14m 23s (20000 26%) 2.1693
18m 6s (25000 33%) 1.9303
21m 44s (30000 40%) 1.7601
25m 23s (35000 46%) 1.6207
29m 8s (40000 53%) 1.4973
32m 44s (45000 60%) 1.3832
36m 22s (50000 66%) 1.2694
40m 6s (55000 73%) 1.1813
43m 51s (60000 80%) 1.0907
47m 29s (65000 86%) 1.0425
51m 10s (70000 93%) 0.9955
54m 48s (75000 100%) 0.9158
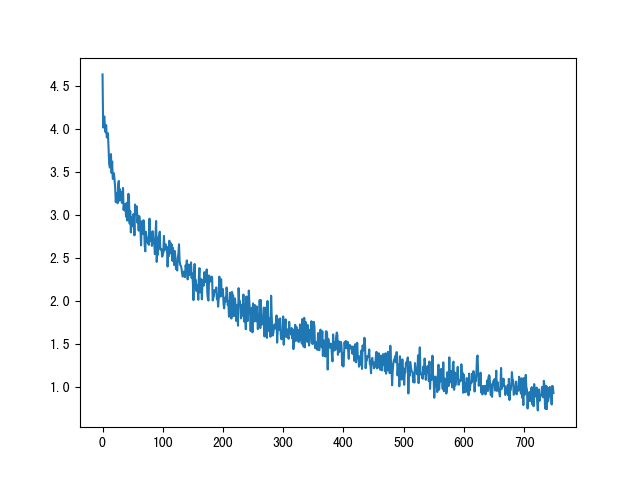
- 损失下降曲线:
- 损失曲线分析:
- 一直下降的损失曲线, 说明模型正在收敛, 能够从数据中找到一些规律应用于数据.
第五步: 构建模型评估函数, 并进行测试以及Attention效果分析.
- 构建模型评估函数:
def evaluate(encoder, decoder, sentence, max_length=MAX_LENGTH):
“””评估函数,输入参数有4个,分别是encoder, decoder: 编码器和解码器对象,
sentence:需要评估的句子,max_length:句子的最大长度”””
# 评估阶段不进行梯度计算<br /> with torch.no_grad():<br /> # 对输入的句子进行张量表示<br /> input_tensor = tensorFromSentence(input_lang, sentence)<br /> # 获得输入的句子长度<br /> input_length = input_tensor.size()[0]<br /> # 初始化编码器隐层张量<br /> encoder_hidden = encoder.initHidden()# 初始化编码器输出张量,是max_lengthxencoder.hidden_size的0张量<br /> encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)# 循环遍历输入张量索引<br /> for ei in range(input_length):<br /> # 根据索引从input_tensor取出对应的单词的张量表示,和初始化隐层张量一同传入encoder对象中<br /> encoder_output, encoder_hidden = encoder(input_tensor[ei],<br /> encoder_hidden)<br /> #将每次获得的输出encoder_output(三维张量), 使用[0, 0]降两维变成向量依次存入到encoder_outputs<br /> # 这样encoder_outputs每一行存的都是对应的句子中每个单词通过编码器的输出结果<br /> encoder_outputs[ei] += encoder_output[0, 0]# 初始化解码器的第一个输入,即起始符<br /> decoder_input = torch.tensor([[SOS_token]], device=device)<br /> # 初始化解码器的隐层张量即编码器的隐层输出<br /> decoder_hidden = encoder_hidden# 初始化预测的词汇列表<br /> decoded_words = []<br /> # 初始化attention张量<br /> decoder_attentions = torch.zeros(max_length, max_length)<br /> # 开始循环解码<br /> for di in range(max_length):<br /> # 将decoder_input, decoder_hidden, encoder_outputs传入解码器对象<br /> # 获得decoder_output, decoder_hidden, decoder_attention<br /> decoder_output, decoder_hidden, decoder_attention = decoder(<br /> decoder_input, decoder_hidden, encoder_outputs)# 取所有的attention结果存入初始化的attention张量中<br /> decoder_attentions[di] = decoder_attention.data<br /> # 从解码器输出中获得概率最高的值及其索引对象<br /> topv, topi = decoder_output.data.topk(1)<br /> # 从索引对象中取出它的值与结束标志值作对比<br /> if topi.item() == EOS_token:<br /> # 如果是结束标志值,则将结束标志装进decoded_words列表,代表翻译结束<br /> decoded_words.append('<EOS>')<br /> # 循环退出<br /> breakelse:<br /> # 否则,根据索引找到它在输出语言的index2word字典中对应的单词装进decoded_words<br /> decoded_words.append(output_lang.index2word[topi.item()])# 最后将本次预测的索引降维并分离赋值给decoder_input,以便下次进行预测<br /> decoder_input = topi.squeeze().detach()<br /> # 返回结果decoded_words, 以及完整注意力张量, 把没有用到的部分切掉<br /> return decoded_words, decoder_attentions[:di + 1]
- 随机选择指定数量的数据进行评估:
def evaluateRandomly(encoder, decoder, n=6):
“””随机测试函数, 输入参数encoder, decoder代表编码器和解码器对象,n代表测试数”””
# 对测试数进行循环
for i in range(n):
# 从pairs随机选择语言对
pair = random.choice(pairs)
# > 代表输入
print(‘>’, pair[0])
# = 代表正确的输出
print(‘=’, pair[1])
# 调用evaluate进行预测
output_words, attentions = evaluate(encoder, decoder, pair[0])
# 将结果连成句子
output_sentence = ‘ ‘.join(output_words)
# < 代表模型的输出
print(‘<’, output_sentence)
print(‘’)
- 调用:
# 调用evaluateRandomly进行模型测试,将编码器对象encoder1,码器对象attn_decoder1传入其中
evaluateRandomly(encoder1, attn_decoder1)
- 输出效果:
> i m impressed with your french .
= je suis impressionne par votre francais .
< je suis impressionnee par votre francais .
i m more than a friend .
= je suis plus qu une amie .
< je suis plus qu une amie .she is beautiful like her mother .
= elle est belle comme sa mere .
< elle est sa sa mere .you re winning aren t you ?
= vous gagnez n est ce pas ?
< tu restez n est ce pas ?he is angry with you .
= il est en colere apres toi .
< il est en colere apres toi .you re very timid .
= vous etes tres craintifs .
< tu es tres craintive .
- Attention张量制图:
sentence = “we re both teachers .”
# 调用评估函数
output_words, attentions = evaluate(
encoder1, attn_decoder1, sentence)
print(output_words)
# 将attention张量转化成numpy, 使用matshow绘制
plt.matshow(attentions.numpy())
# 保存图像
plt.savefig(“./s2s_attn.png”)
- 输出效果:
[‘nous’, ‘sommes’, ‘toutes’, ‘deux’, ‘enseignantes’, ‘.’, ‘
- Attention可视化:
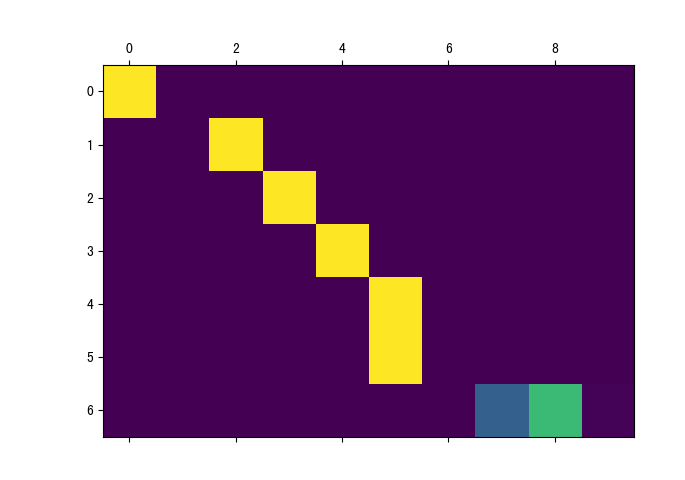
- 分析:
- Attention图像的纵坐标代表输入的源语言各个词汇对应的索引, 0-6分别对应[“we”, “re”, “both”, “teachers”, “.”, “”], 纵坐标代表生成的目标语言各个词汇对应的索引, 0-7代表[‘nous’, ‘sommes’, ‘toutes’, ‘deux’, ‘enseignantes’, ‘.’, ‘’], 图中浅色小方块(颜色越浅说明影响越大)代表词汇之间的影响关系, 比如源语言的第1个词汇对生成目标语言的第1个词汇影响最大, 源语言的第4,5个词对生成目标语言的第5个词会影响最大, 通过这样的可视化图像, 我们可以知道Attention的效果好坏, 与我们人为去判定到底还有多大的差距. 进而衡量我们训练模型的可用性.
- 小节总结:
- seq2seq模型架构分析:
- 从图中可知, seq2seq模型架构, 包括两部分分别是encoder(编码器)和decoder(解码器), 编码器和解码器的内部实现都使用了GRU模型, 这里它要完成的是一个中文到英文的翻译: 欢迎 来 北京 —> welcome to BeiJing. 编码器首先处理中文输入”欢迎 来 北京”, 通过GRU模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量c, 接着解码器将使用这个中间语义张量c以及每一个时间步的隐层张量, 逐个生成对应的翻译语言.
- seq2seq模型架构分析:
- 基于GRU的seq2seq模型架构实现翻译的过程:
- 第一步: 导入必备的工具包.
- 第二步: 对持久化文件中数据进行处理, 以满足模型训练要求.
- 第三步: 构建基于GRU的编码器和解码器.
- 第四步: 构建模型训练函数, 并进行训练.
- 第五步: 构建模型评估函数, 并进行测试以及Attention效果分析.
- 第一步: 导入必备的工具包
- python版本使用3.6.x, pytorch版本使用1.3.1
- 第二步: 对持久化文件中数据进行处理, 以满足模型训练要求
- 将指定语言中的词汇映射成数值
- 字符规范化
- 将持久化文件中的数据加载到内存, 并实例化类Lang
- 过滤出符合我们要求的语言对
- 对以上数据准备函数进行整合, 并使用类Lang对语言对进行数值映射
- 将语言对转化为模型输入需要的张量
- 第三步: 构建基于GRU的编码器和解码器
- 构建基于GRU的编码器
- 构建基于GRU的解码器
- 构建基于GRU和Attention的解码器
- 第四步: 构建模型训练函数, 并进行训练
- 什么是teacher_forcing: 它是一种用于序列生成任务的训练技巧, 在seq2seq架构中, 根据循环神经网络理论,解码器每次应该使用上一步的结果作为输入的一部分, 但是训练过程中,一旦上一步的结果是错误的,就会导致这种错误被累积,无法达到训练效果, 因此,我们需要一种机制改变上一步出错的情况,因为训练时我们是已知正确的输出应该是什么,因此可以强制将上一步结果设置成正确的输出, 这种方式就叫做teacher_forcing.
- teacher_forcing的作用: 能够在训练的时候矫正模型的预测,避免在序列生成的过程中误差进一步放大. 另外, teacher_forcing能够极大的加快模型的收敛速度,令模型训练过程更快更平稳.
- 构建训练函数train
- 构建时间计算函数timeSince
- 调用训练函数并打印日志和制图
- 损失曲线分析: 一直下降的损失曲线, 说明模型正在收敛, 能够从数据中找到一些规律应用于数据
- 第五步: 构建模型评估函数, 并进行测试以及Attention效果分析
- 构建模型评估函数evaluate
- 随机选择指定数量的数据进行评估
- 进行了Attention可视化分析
_

若有收获,就点个赞吧
0 人点赞
