夜莺介绍
夜莺是新一代国产智能监控系统。对云原生场景、传统物理机虚拟机场景,都有很好的支持,10分钟完成搭建,1小时熟悉使用,经受了滴滴生产环境海量数据的验证,希望打造国产监控的标杆之作,一起参与进来吧!
新版简介
Nightingale在2020.3.20发布v1版本,目前是v5版本,从这个版本开始,与Prometheus、Grafana、Telegraf、Datadog等生态做了协同集成,力争打造国内最好用的开源运维监控系统。
开源代码
💡💡💡💡💡 https://github.com/didi/nightingale💡💡💡💡💡
系统架构
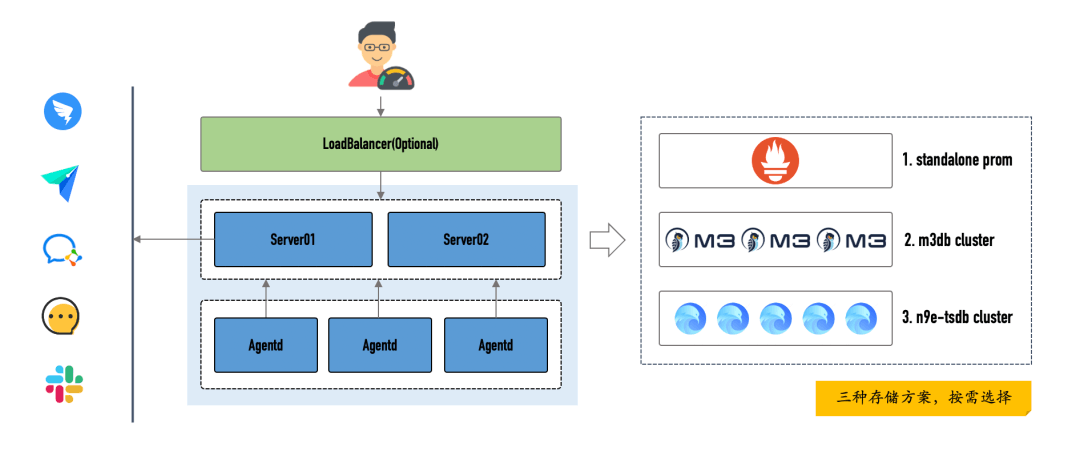
上图是一个集群版的示例,蓝色部分的两个模块:server和agentd,是夜莺的核心组件,相比之前的版本(v3版本10个模块)简单到发指,易于上手易于安装而且还无比强大。
用户访问侧的负载均衡可有可无,毕竟直接请求某个server的地址也可以看到页面,如果要用负载均衡,四层的、七层的都可以。
存储可插拔,支持不同的后端,直接集成了Prometheus的remote_read和remote_write协议,所以,如果某个存储支持remote_read和remote_write,那就可以直接被夜莺使用。测试尝鲜阶段或者生产环境量不大(比如设备小于1000台),存储可以选择Prometheus单机版;如果量挺大,对可靠性要求较高,可以选择M3DB;如果对数据精度要求不高,想存很久的数据,可以选择n9e-tsdb(不过n9e-tsdb还没开发完)。
告警消息发送,为了适配各种媒介,直接使用python脚本 etc/script/notify.py 来对接,毕竟,脚本代码是最灵活的,夜莺要发告警事件,就会调用这个脚本发送,所以,只要扩展这个脚本即可支持各种媒介。
关于采集
提供linux和windows的agentd,采集机器的cpu、内存、硬盘、网络、io等常规指标,服务端可以对不同的机器配置不同的进程、端口、插件、日志采集策略,对于各种中间件的指标采集,比如mysql、redis等的监控数据采集,内置到agentd里,这样一来,就可以非常方便的用这个all-in-one的agentd完成所有的采集了。但是,把各种中间件的采集能力都集成到agentd里,谈何容易,中间件少说也有数百种。特别是先期,agentd的采集能力肯定还没有那么完备,此时怎么办?简单,大家可以复用Telegraf或者Prometheus的采集能力,即:把Prometheus当做采集端。举例,假设现在使用M3DB做存储,整个架构就变成了:
Prometheus生态提供了各种exporter,Telegraf都可以作为一个exporter使用,部署一个Prometheus进程作为抓取器,抓取各种exporter的数据,完事写入M3DB,夜莺的服务端,就可以直接读取M3DB中的数据使用,可以在夜莺里看图、配置告警,当然了,也可以用Grafana来看图,更为炫酷。
哦对了,应用程序的APM监控,v5也可以支持,两个手段:1、用Prometheus的埋点SDK;2、用Statsd的埋点SDK,agentd中已经内置了Statsd协议的接收端口。具体可以参考官网的数据采集章节。
关于告警
夜莺服务端提供两套告警引擎,可以用Nightingale的,比较简单直观,无非就是配置某个监控数据满足某个阈值就告警,也支持直接编写promql,略复杂一些,会更灵活。这个功能是很多用户心心念念的功能,满足你们啦~
在v5里边,告警之后只会发一条,不会重复发送(之前的版本会每个周期都生成事件,导致事件太多饱受诟病),直到恢复,告警恢复的时候会发一条恢复通知。告警认领、告警升级、留观时长、告警收敛、告警合并等功能都砍掉了,未来会单独做一个事件管理的模块来增强事件管理的能力。
关于看图
历史数据查看,夜莺还是会内置这个能力,还是会有即时看图和监控大盘,而且监控大盘还支持变量,这样相同功能的监控大盘,全局只需要做一套即可,简单灵活。夜莺的大盘显示效果不如Grafana好看,所以大家也可以直接使用Grafana看图,v5的存储可以使用Prometheus、M3DB等,这些存储都是可以直接对接Grafana的,非常方便。夜莺不会再单独做一个Grafana的DataSource插件了。
资源管理
之前的夜莺版本,资源管理使用树形结构,非常直观,但是理解成本确实会高一些。v5尝试了一种新方案,使用前缀匹配的资源分组,类似Open-Falcon和Zabbix,可以为设备建立分组,非常直观简单,比如n9e.server这个分组下面,放置夜莺的服务端机器,n9e.mysql这个分组下面,放置夜莺的数据库机器。这些分组上面都可以绑定一些采集策略,分组下面的所有设备资源都生效。但是假设,有个采集插件不但要在n9e.server分组的机器上生效,还要在n9e.mysql分组的机器上生效,难道要配置两次?那就太麻烦了!怎么办?
在v5里,可以创建一个n9e.的分组,下面不需要绑定机器,直接在n9e.这个分组上配置采集策略(配置的时候勾选前缀匹配那个复选框),这个采集策略就会同时生效到前缀是n9e.的分组上,显然,n9e.server和n9e.mysql这俩分组都是以n9e.作为前缀的,所以,这俩分组下面的机器就都生效了。其实是一种变相的树形结构,这种组织方式称为classpath,据说aws内部就是用的这种方式。
关于权限
权限这块,大幅简化了,系统内置了Admin、Standard、Guest三个角色,Admin就是啥都能干,Standard除了不能创建、修改、删除其他用户,绝大部分功能也是都可以干,Guest顾名思义就是访客,只有浏览权限,没有写权限。
相比v4及之前的版本,现在的权限体系是非常简单的,但是功能确实不如之前的强大,之所以这么取舍,是考虑这几点:1、这样简单易于上手;2、v5砍掉了脚本执行相关的功能,权限控制可以不用那么细粒度了;3、夜莺毕竟只是一个监控系统,没有太强的权限控制的诉求。
写在最后
总体来看,夜莺v5版本更多的是开放协同,专注监控告警!

若有收获,就点个赞吧
0 人点赞
