服务器 监控 Prometheus
监控的重要性,相信大家都是非常有体会的,监控能力对于所有的软件系统来说也是必不可少的。有的监控能力是产品内置的,有的是基于 SaaS 提供的。监控是系统上线之后,保证系统稳定性的重要手段,运维的主要的工作入口就是监控和告警。随着云原生的广泛使用,以及最近这些年微服务体系的建设,各种业务系统的微服务化,部署规模,运维难度等因素对业务运行的可观测性要求是越来越高了。
在这个背景下,需要更好的利用监控,日志,链路等技术帮助平台和业务系统搭建可用的观测能力,结合观测性以及统一的告警能力就可以辅助打造出企业级的统一运维平台。接下来,就来聊聊监控的成熟技术 - Prometheus,以及分享一些使用 Prometheus 的方式方法。
1、为什么要使用 Prometheus
首先,Prometheus 是目前社区最热的开源监控告警解决方案,2016 年加入 CNCF (Cloud Native Computing Foundation),成为了继 Kubernetes 后的第二个明星项目。截止目前,最新版本 2.30,有超 5000 的代码合并请求,8967 次代码提交记录, github 的 star 已经达到了 38.8k。
相比较于老牌的监控告警解决方案,Prometheus 有如下优势:
- CNCF 已经毕业的明星产品;
- 对云原生的支持是所有监控方案里最好的;
- 几乎所有的云原生内置的监控能力都是基于 Prometheus;
- 已经被很多的公司采用,并得到了大规模使用验证;
- 部署方便,不依赖外部组件,能适用企业各种场景;
- 采集精度高,可以精确到 1~5 秒;
- 支持很多实用的计算函数;
- 可以快速集成社区已经成熟 exporter;
- 能跟 Grafana 很好的结合,绘制各种高大上的图;
- 可根据自身业务快速自定义 metrics;
- 定义了适用各种场景的数据类型;
2、Prometheus 架构
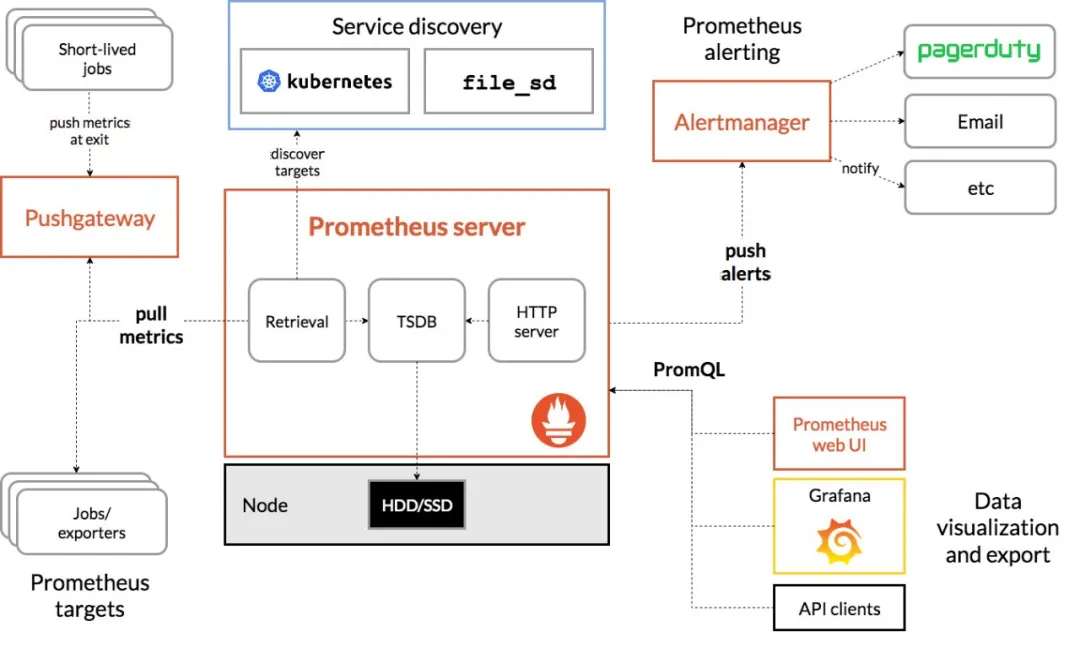
以上是 Prometheus 的架构图,它主要分为三个部分:采集层、数据处理层、数据查询层采集层
数据的采集之前,首先需要解决的是采集目标是怎样知道的,Prometheus 提供了比较丰富的采集目标发现机制,比如基于配置文件的发现机制,基于 Kubernetes 的发现机制等等。对于数据采集的方式,主要分为两种方式,一种是 exporter 的 pull 机制,是指应用本身暴露能获取监控指标能力的接口,或者特定能采集应用数据的 exporter,然后 Prometheus server 通过访问 exporter 获取到监控数据信息,这种方式是主流的使用方式,也就是 pull 模式。另一种是通过 Push Gateway 的 push 机制,是用户主动将数据推送到 Push Gateway 组件,然后 Prometheus server 通过 Push Gateway 获取到数据,这种是比较传统的 push 模式。数据处理层
数据处理层主要是指 Prometheus server 本身,主要分为三个部分,Retrieval 负责定时去暴露监控指标的目标上抓取数据,Storage 负责将数据写入磁盘,promQL 暴露查询数据的 http server 能力。同时他也会根据告警规则,一旦达到阈值,那么就会向 Alertmanager 推送告警信息,然后由 Alertmanager 对接到外部平台,将应用异常信息推送给用户。数据查询层
数据查询层是指,可以通过 Prometheus UI 访问 Prometheus server 能力。或者结合 Grafana,将 Prometheus 作为数据源接入,在 Grafana 自定义模版,以图表的方式展示应用指标的状态变化,以便于更加直观地观测应用的变化。3、Prometheus数据类型有哪些?
Counter (只增不减的计数器)、 Gauge (可增可减的仪表盘)、 Summary (分析数据分布情况) 以及 Histogram (分析数据分布情况)。Counter
社区:A counter is a cumulative metric that represents a single monotonically increasing counter whose value can only increase or be reset to zero on restart. For example, you can use a counter to represent the number of requests served, tasks completed, or errors.
Counter 一个累加指标数据,这个值随着时间只会逐渐的增加,比如程序完成的总任务数量,运行错误发生的总次数。常见的还有交换机中 snmp 采集的数据流量也属于该类型,代表了持续增加的数据包或者传输字节累加值。Gauge
社区:A gauge is a metric that represents a single numerical value that can arbitrarily go up and down.
Gauge 代表了采集的一个单一数据,这个数据可以增加也可以减少,比如 CPU 使用情况,内存使用量,硬盘当前的空间容量等等。Summary & Histogram
场景:在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统API调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10ms 之间的请求数有多少,而 10~20ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram 和 Summary 都是为了能够解决这样问题的存在。通过 Histogram 和 Summary 类型的监控指标,可以快速了解监控样本的分布情况。4、企业监控需求怎样借助社区力量?
开箱即用的社区 exporter,如使用 node_exporter,就可以轻松采集主机信息,如下图所示: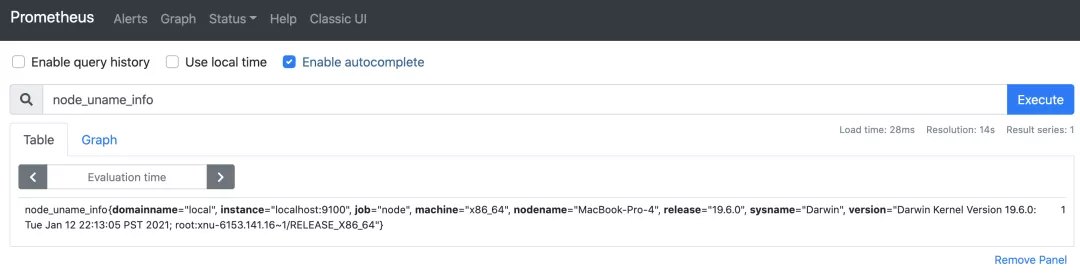
更多 exporter 使用,可以参考:https://prometheus.io/docs/instrumenting/exporters/#third-party-exporters
对于社区没有 exporter 支持的,可以自己实现 exporter 的方式,来完成系统监控能力。
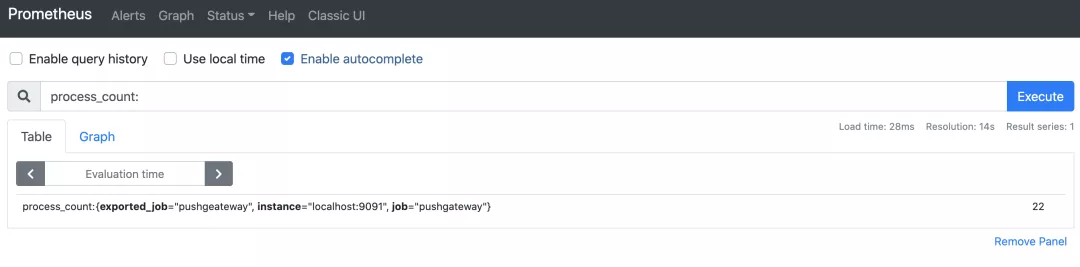
对于需要兼容传统 push 方式的 metrics 收集,可以使用 Push Gateway,将数据推送到 Push Gateway,即可快速实现指标采集,以下为采集本机进程数的脚本实现,如下图所示: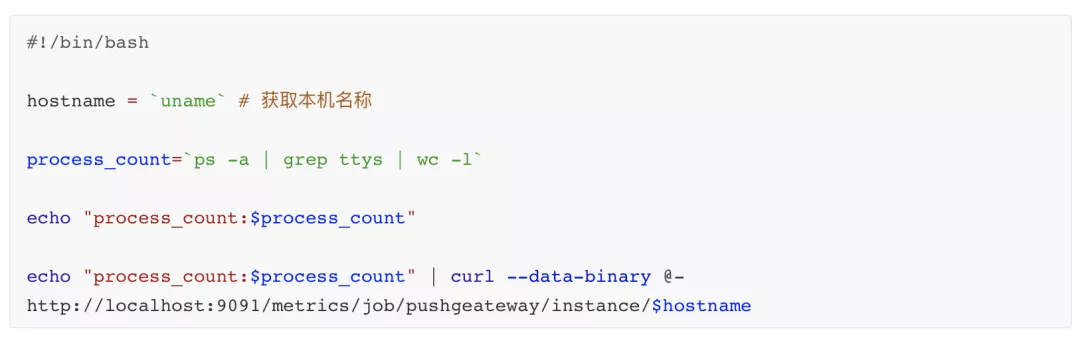
5、云原生平台 - 监控能力体系
以下就以一个云原生平台自身监控能力建设为例,展示如何利用 Prometheus 构建云原生可观测能力。需求来源
云原生监控所需要的能力是,能监控平台所管理的不同类型集群,如 OCP (Openshift Container Platform)、Kubernetes。监控指标需要涵盖集群整体资源使用情况、集群组件运行状态、集群主机运行状态、命名空间的资源使用情况、运行在集群上的应用的运行情况、应用所包含的容器组的运行情况等。
需求分析
根据需求,需要的是多集群管理能力下,能查看集群的监控信息。所以可以将监控能力划分为如下的监控粒度,同时拓展了平台组件监控能力,即本云原生自身平台所包含的组件的运行情况,也就会有如下图所示的结构。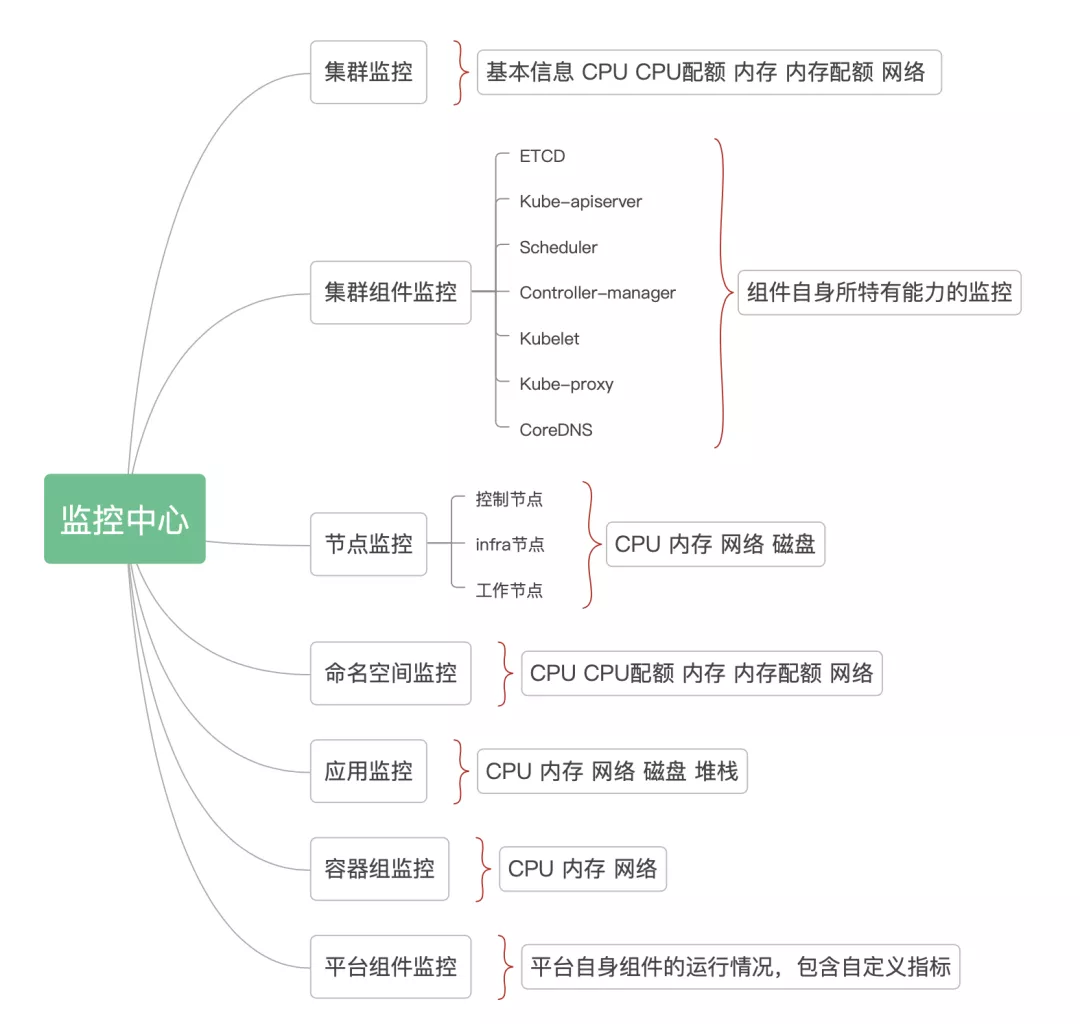
云原生平台引入 Prometheus
云原生平台 需要异构多种类型集群的监控,并且要自定义 Grafana 模版。因为每种类型集群的架构设计是不同的,所包含的组件也是不同的,如 OCP 相对于 Kubernetes 来说,Scheduler 和 Controller Manager 是在一个组件中的。这就需要针对每种类型集群,根据集群组件所暴露不同指标键值,使用不同的模版。
当然,如果是 Prometheus 联邦将多个类型集群监控数据汇总到一个 Prometheus,那么只需要一个 Grafana 接入 Prometheus 汇聚层即可。如果需要将多个数据源接入到一个 Grafana,也是可以的,在这种条件下,就需要平台制定数据源名称规则,在数据查询时,传入数据源属性。
云原生平台已有设计是一个类型的集群拥有一个 Grafana 属性,需要建设的主要能力是集群监控。在纳管集群时,需要在集群中安装云原生平台自定义的监控模版。对于集群本身的监控,形成了自己的指标说明文档,针对模版图展示,提供了中文化的界面,方便用户查看监控图表。
所以结合现有情况,方案如下: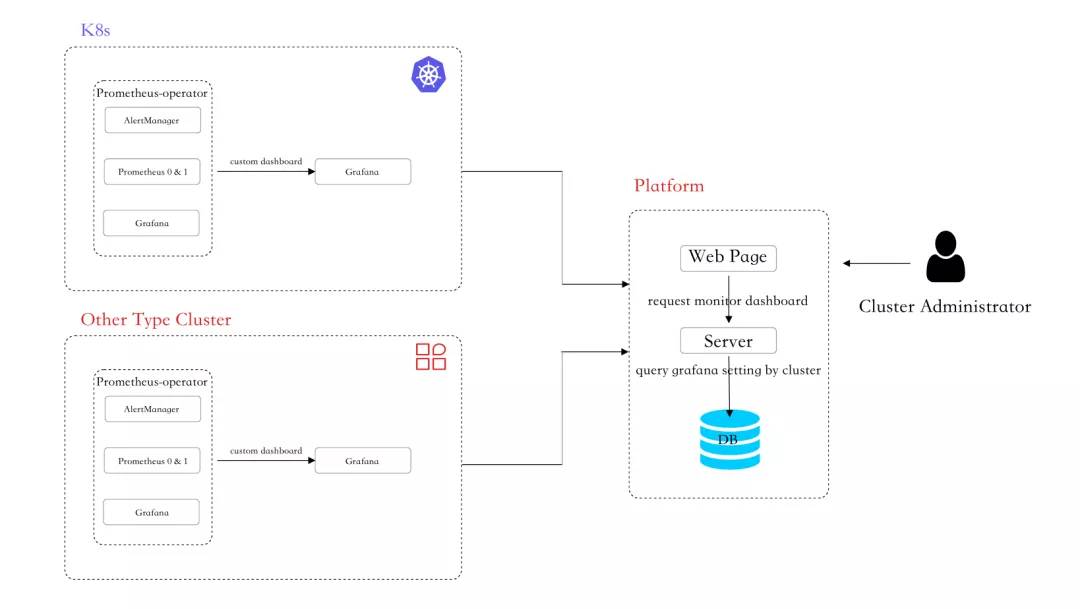
用户访问的时序图
- 集群管理员在安装集群时,将自定义的 Grafana 安装到集群中,并配置 Prometheus-operator 安装的 Prometheus server 作为 Grafana 的数据源;
- 集群管理员访问云原生平台,纳管集群,根据对应集群安装的 Grafana,填写 Grafana 根地址,作为集群属性;
- 云原生UI提交集群信息到云原生服务端,服务端验证集群信息,并验证 Grafana 访问可达性;
- 云原生服务端验证信息后,将数据做持久化存储;
- 用户访问云原生平台监控中心,选择纳管集群查看监控信息;
- 云原生 UI 根据用户界面选择,向服务端发送请求;
- 服务端根据集群标识获取对应的集群 Grafana 属性,并根据用户查询参数,转换为 Grafana 模版访问地址;
- 云原生 UI 根据服务端返回的 Grafana 地址,访问获取到自定义模版,界面展示;

云原生平台监控中心
集群概览
如集群概览监控信息,展示集群当前 CPU 内存使用情况、最近 CPU 使用、 CPU 配额、 内存使用、 内存配额,并且在集群整体概览下,以命名空间为维度,如下图所示。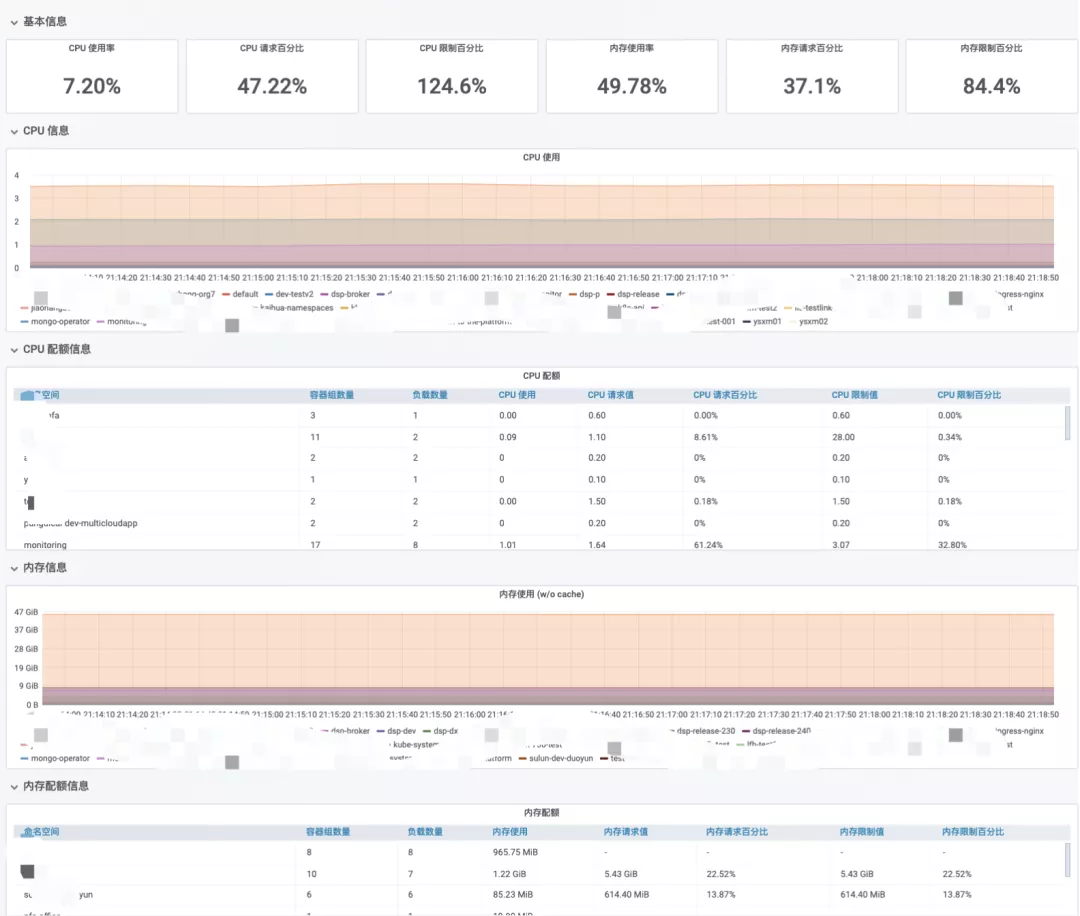
集群组件监控
如集群组件监控,根据集群下拉选择要查看的集群组件,即可查看组件监控信息,以下为 Kubernetes 类型集群中的 controller manager 组件监控信息,除了基本的如 CPU、内存、存储的监控信息,还包括了组件特有信息,如队列的监控信息。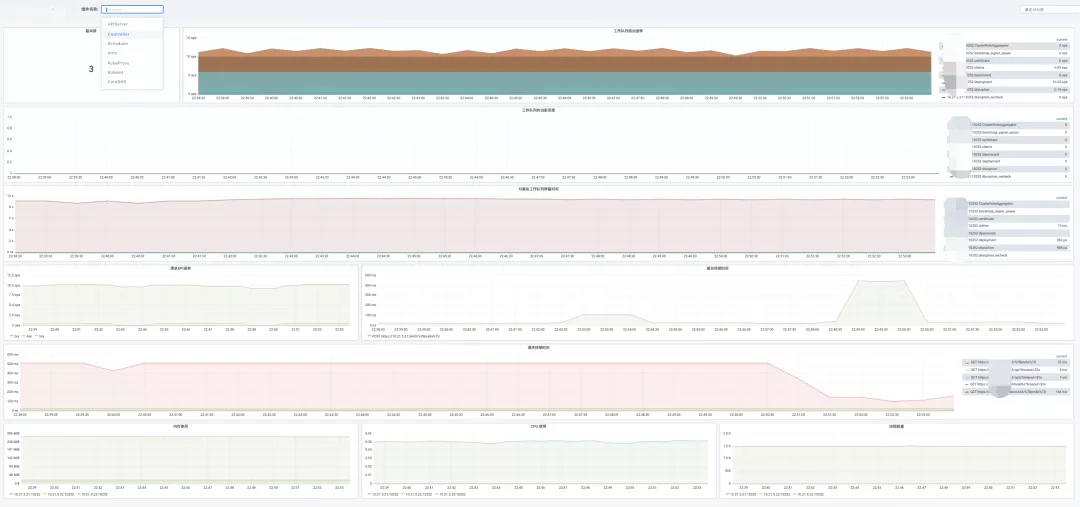
平台组件监控
如平台组件监控,主要展示的是自身组件的一些基本信息,如启动时间,CPU 使用,内存使用,堆栈信息,如下图所示: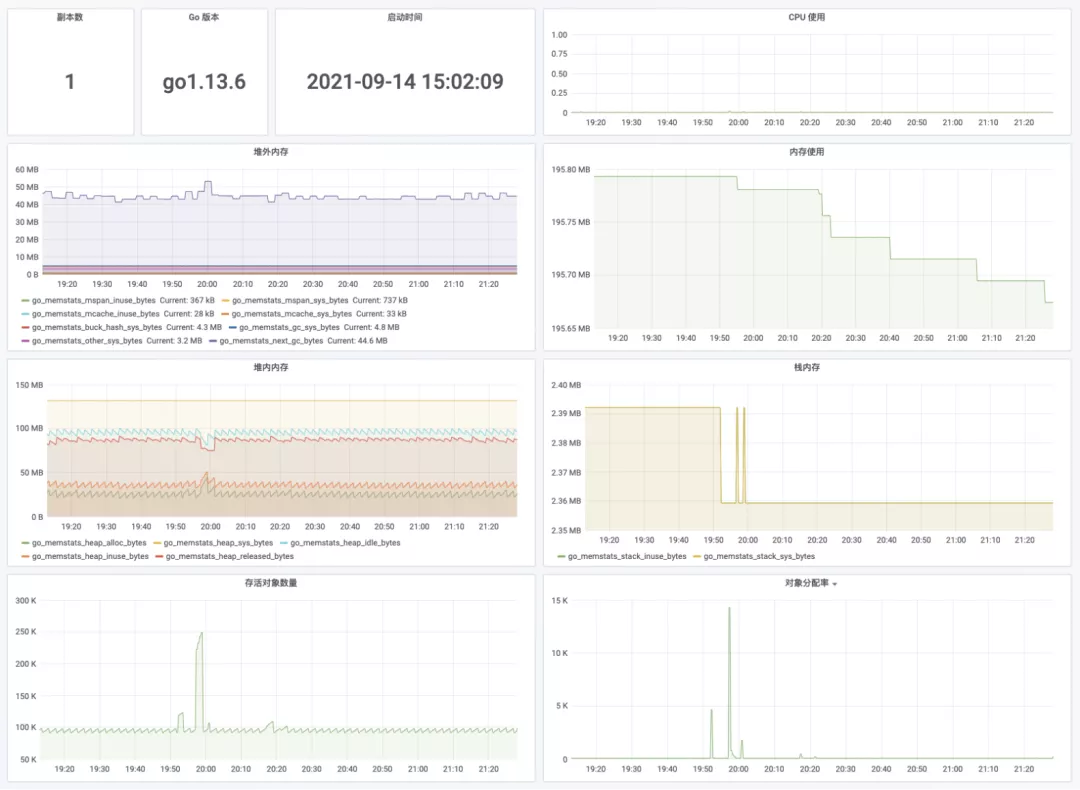
6、应用如何实现监控能力?
Prometheus 对主流语言实现了客户端库的封装,通过客户端库,企业可以根据自己的业务需求,实现不同维度,适合自身应用业务的监控体系。实践分享一下,Golang 和 Python 开发语言来构建监控能力的方法。
Golang 客户端库构建监控能力
社区案例代码
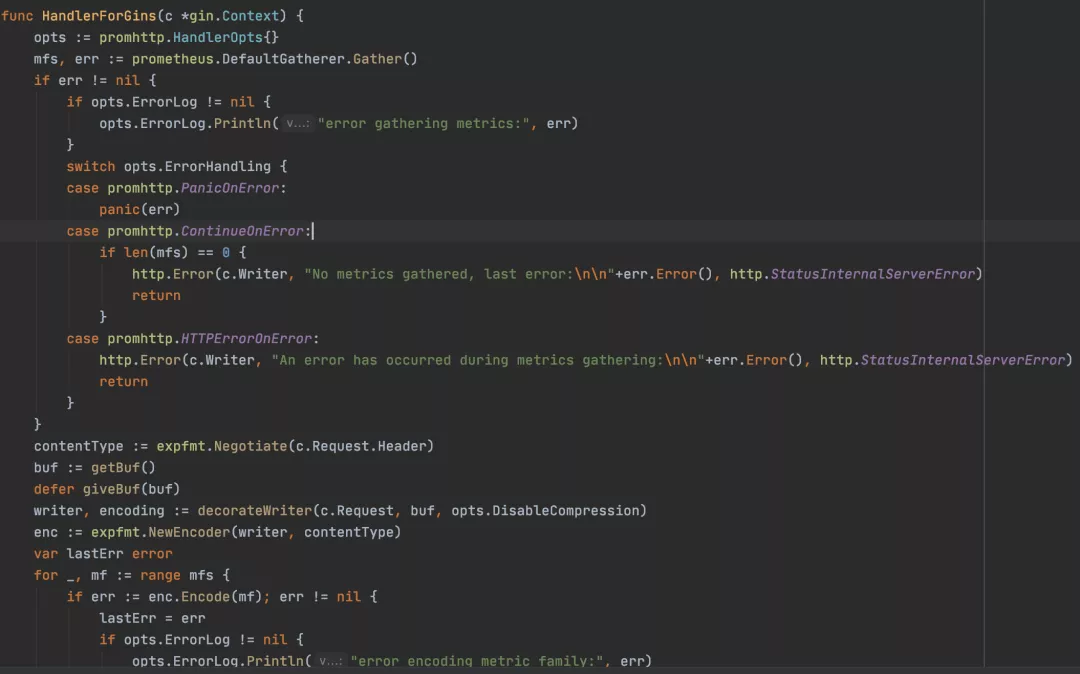
Golang 应用程序构建监控能力,用到的客户端主要是 client_golang,示例代码如下图所示,详细使用见https://github.com/prometheus/client_golang
案列代码
Python 客户端库构建监控能力
社区代码案例
Python 应用程序构建监控能力,pip 安装客户端包后,导入包,即可快速自定义监控指标。同时,客户端还对 WSGI、ASGI 等做了特定支持。如果使用 Push Gateway,可以使用 “push_to_gateway” 方法,指定 Push Gateway 地址和端口,即可将数据 Push 到 Push Gateway。更多详细使用可以参考 (https://github.com/prometheus/client_python)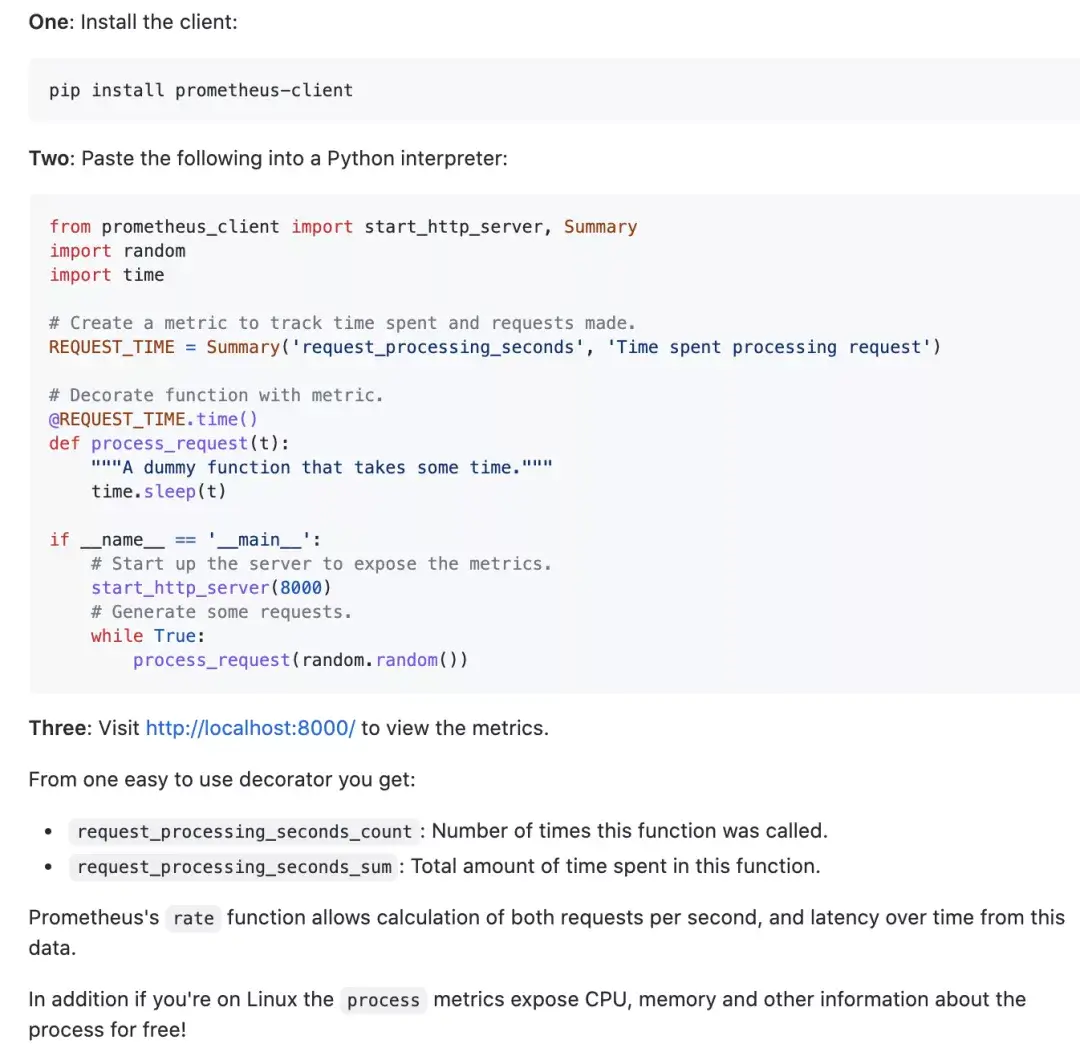
案例代码

7、社区发展
Prometheus 能力已经慢慢为大家所熟知,基于社区各种成熟的 exporter,企业能快速集成,开箱即用。同时在云原生领域还有一些和 Prometheus 密切相关的技术,比如为了更加方便的安装和使用 Prometheus,社区发起了 Prometheus Operator 的项目, 比如为了解决 Prometheus 的高可用性,社区引入了 Thanos 和 Prometheus Federation 方案。除此之外,观测性方向的技术和方案也在不断的发展,其中,具有代表性的就是 OpenTelemetry,其中也涵盖了 metrics 相关的能力,但是这些能力和 Prometheus 本身是可以互补的,共同打造社区完整的可观测性方案和能力。

若有收获,就点个赞吧
0 人点赞
