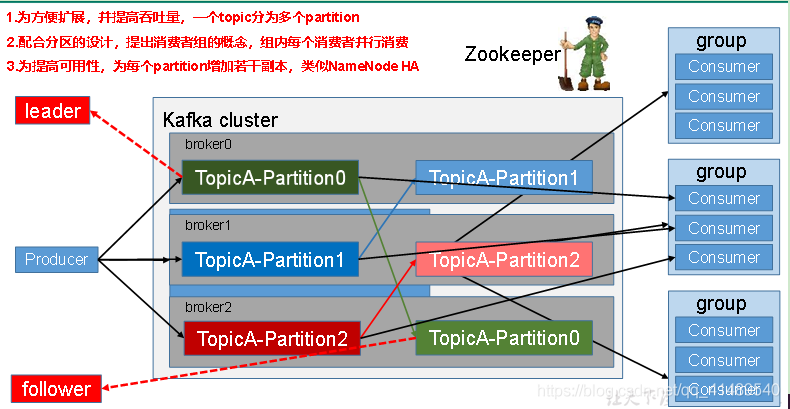
Producer(生产者)生产消息以Topic(主题)为单位进行存储.消费者组订阅主题消费内容.
Producer生产者写数据可能写到TopicA-Partition0 分区 ,也可能写到 TopicA-Partition1分区, 也可以指定只写到哪个分区也是可以的.如果你不指定写哪个分区,你只是指定写到TopicA主题,那么就会采取轮询的策略,把数据轮流放到TopicA主题下的所有分区里面.
为了方便我的消费,以及提高消费的速度,我们是有消费者组的概念,一个组可以有多个消费者线程,一个Group组可以同时订阅多个Topic主题,多个Group也可以同时订阅多个主题.
每个Group里面各有三个Consumer消费者,TopicA下的所有分区的数据都会分配到多个消费者线程上面. 同时是互斥的同一时刻一个主题只能由一个Group内的一个Consumer来消费 ,
同时一个Consumer可以同时消费多个主题的,就是我既可以拿TopicA-Partition0的数据,也可以拿TopicA-Partition1的数据.
不能一个Group里面的两个Consumer同时拿TopicA-Partition0里面的数据.这是不能允许的.
分区可以分散到多个Broker中的
多个Broker可以组成一个集群.
为了提高可用性,可以为分区增加副本,比如说TopicA-Partition0存到了Broker0和Broker2上.这样保证数据的可用性和安全性.
有了副本概念,客户端只能向Leader发送请求,比如说读取TopicA-Partition0的数据,就得看谁是Leader了, 假如说broker0是Leader,那么不管是Producer还是Consumer只能请求Leader角色的broker0机器, 然后broker2就是follower机器,它会发送fetch请求从leader角色的broker0机器上同步TopicA-Partition0数据.
另外Kafka集群需要借助Zookeeper的 ,你Broker运行期间需要给数据存到Zookeeper上的.比如说Topic叫什么名字,有多少分区等等,这些元数据都需要存到Zookeeper里面.

若有收获,就点个赞吧
0 人点赞
