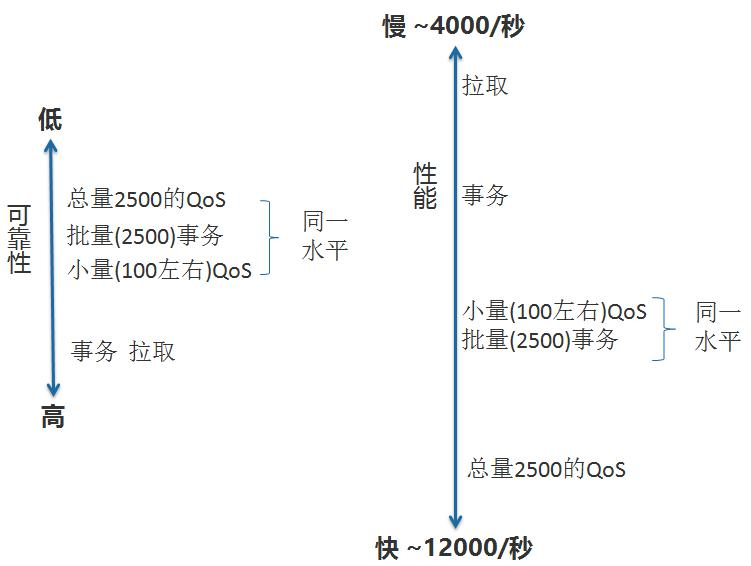
可靠性
如果我们采用事务和拉取的话,它的可靠性是非常高的,因为用事务的话,你去消费的时候我RabbitMQ从消费者里面拿到一条消息我采用事务的话,我属于一个代码里面try catch 我的可靠性肯定是非常高的.
除此之外,为什么我们小量和批量和总量的可靠性是同一水平呢?
因为对于批量来说,中间一旦有一个消息处理有问题的话其实你拉取2500或者是100等等,其实它们的水平是一个水平的. 就是你批量操作的时候,你try catch发现异常了,你肯定要对批量的数据进行处理,100和2500只是业务的复杂度不同而已,对于可靠性的话是同一水平的.
性能
我们进行消费的时候可以采取拉取的方式,拉取就是在阻塞的等待,拉取的可靠性很高,我们消费者去RabbitMQ拉取的时候,拉一条的时候,消费者只有处理完了,整个在里面进行对应的阻塞了,所以拉取的时候可靠性是很高的.
拉取的时候也可以加上事务,但是速度非常慢.
如果你要提高获取从RabbitMQ获取的速度的话,你肯定要走批量获取,包括数据库处理也是一样的.
(一)消息的获得方式(防止重复拉取)
消费者进行消息消费的时候,无论是拉取方式还是推送方式,都需要进行ACK的消息确认,不然的话就会出现消息重复的现象.
ACK机制是消费者接收到MQ的消息之后会发送给MQ一条ACK,告诉MQ我已经消费了,然后MQ内部会把这个数据删除掉,不然的话,A消费者消费完了MQ还有数据,那么B消费者就又能获取MQ里面的数据,这样的话就会出现消息重复的现象.
拉取 Get
| 案例:ZJJ_RabbitMQ_2019/11/04_18:28:45_sv9yv |
|---|
我们在做消费者的时候是避免去拉取的,在拉取的时候就像网络通讯一样,必须要使用while true的循环,因为我不知道这条消息什么时候到我们的RabbitMQ里面来,所以进行while true 等待,一旦数据拿到了我再进行对应的处理.
while true 意味着消费者需要经常在这里去做一些无用的事情.
一般情况下 我们不会使用这种拉取的方案.,我们会使用推送的方案,推送的方式更实时.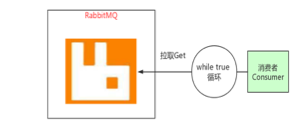
推送 Consume
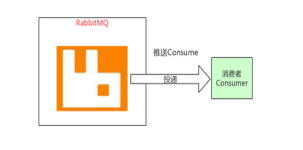
消费者会有一个订阅队列,这个消息只要到中间的一个队列中间来了,那么就投递给消费者.所以说一般情况下我们玩消费者我们是避免使用拉取方式的.我们鼓励使用推送的方式.
消息的应答
前面说过,消费者收到的每一条消息都必须进行确认。消息确认后,RabbitMQ 才会从队列删除这条消息,RabbitMQ 不会为未确认的消息设置超时时间,它判断此消息是否需要重新投递给消费者的唯一依据是消费该消息的消费者连接是否已经断开。这么设计的原因是 RabbitMQ 允许消费者消费一条消息的时间可以很久很久。
自动确认
消费者在声明队列时,可以指定 autoAck 参数,当 autoAck=true 时,一旦消费者接收到了消息,就视为自动确认了消息。如果消费者在处理消息的过程中,出了错,就没有什么办法重新处理这条消息,所以我们很多时候,需要在消息处理成功后,再确认消息,这就需要手动确认。
手动确认
当 autoAck=false 时,RabbitMQ 会等待消费者显式发回 ack 信号后才从内存(和磁盘,如果是持久化消息的话)中移去消息。否则,RabbitMQ 会在队列中消息被消费后立即删除它。
采用消息确认机制后,只要令 autoAck=false,消费者就有足够的时间处理消息(任务),不用担心处理消息过程中消费者进程挂掉后消息丢失的问题,因为 RabbitMQ 会一直持有消息直到消费者显式调用 basicAck 为止。
当 autoAck=false 时,对于 RabbitMQ 服务器端而言,队列中的消息分成了两部分:一部分是等待投递给消费者的消息;一部分是已经投递给消费者,但是还没有收到消费者 ack 信号的消息。如果服务器端一直没有收到消费者的 ack 信号,并且消费此消息的消费者已经断开连接,则服务器端会安排该消息重新进入队列,等待投递给下一个消费者(也可能还是原来的那个消费者)。
通过运行程序,启动两个消费者 A、B,都可以收到消息,但是其中有一个消费者 A 不会对消息进行确认,当把这个消费者 A 关闭后,消费者 B 又会收到本来发送给消费者 A 的消息。所以我们一般使用手动确认的方法是,将消息的处理放在 try/catch 语句块中,成功处理了,就给 RabbitMQ 一个确认应答,如果处理异常了,就在 catch 中,进行消息的拒绝,如何拒绝,参考消息的拒绝章节。
QoS 预取模式
| 案例:ZJJRabbitMQ_2019/11/05 8:05:00_9ais2 |
|---|
预取模式类似于批量的模式,效率还是比较高的.
预取模式和批量确认模式他们的消息应答一定不是自动确认的,因为你自动确认的话,是没有办法批量的(如果你自动确认了,MQ内部一条一条的给你确认了),所以,预取模式和批量确认模式的消息的应答一定是手动确认的.
在确认消息被接收之前,消费者可以预先要求接收一定数量的消息,在处理完一定数量的消息后,批量进行确认。如果消费者应用程序在确认消息之前崩溃,则所有未确认的消息将被重新发送给其他消费者。所以这里存在着一定程度上的可靠性风险。
这种机制一方面可以实现限速(将消息暂存到 RabbitMQ 内存中)的作用,一方面可以保证消息确认质量(比如确认了但是处理有异常的情况)。
注意:消费确认模式必须是非自动 ACK 机制(这个是使用 baseQos 的前提条件,否则会 Qos 不生效),然后设置 basicQos 的值;另外,还可以基于consume 和 channel 的粒度进行设置(global)。
basicQos 方法参数详细解释:
prefetchSize:最多传输的内容的大小的限制,0 为不限制,但据说 prefetchSize 参数,rabbitmq 没有实现。
prefetchCount:会告诉 RabbitMQ 不要同时给一个消费者推送多于 N 个消息,即一旦有 N 个消息还没有 ack,则该 consumer 将 block 掉,直到有消息
ack
global:true\false 是否将上面设置应用于 channel,简单点说,就是上面限制是 channel 级别的还是 consumer 级别。
如果同时设置 channel 和消费者,会怎么样?AMQP 规范没有解释如果使用不同的全局值多次调用 basic.qos 会发生什么。 RabbitMQ 将此解释为意味着两个预取限制应该彼此独立地强制执行; 消费者只有在未达到未确认消息限制时才会收到新消息。
channel.basicQos(10, false); // Per consumer limit
channel.basicQos(15, true); // Per channel limit
channel.basicConsume(“my-queue1”, false, consumer1);
channel.basicConsume(“my-queue2”, false, consumer2);
也就是说,整个通道加起来最多允许 15 条未确认的消息,每个消费者则最多有 10 条消息。
QOS和批量确认区别
QOS自己内部实现了类似于批量的功能,你可以理解为优化版的批量确认,QOS用起来很简单,如果你自己走批量的话,你代码量很大,逻辑复杂,如果你要用QOS的话,逻辑简单,就是定义下多少条一预取出来.
channel.basicQos(15, true); // 15条一 预取出来.
(二)消费者中的事务(了解)
使用方法和生产者一致
假设消费者模式中使用了事务,并且在消息确认之后进行了事务回滚,会是什么样的结果?
结果分为两种情况:
1. autoAck=false 手动应对的时候是支持事务的,也就是说即使你已经手动确认了消息已经收到了,但 RabbitMQ 对消息的确认会等事务的返回结果,再做最终决定是确认消息还是重新放回队列,如果你手动确认之后,又回滚了事务,那么以事务回滚为准,此条消息会重新放回队列;
2. autoAck=true 如果自动确认为 true 的情况是不支持事务的,也就是说你即使在收到消息之后在回滚事务也是于事无补的,队列已经把消息移除了。
(三)消息的拒绝
| 案例:ZJJRabbitMQ_2019/11/05 9:23:36_sqmca |
|---|
消费者进行消费的时候其实是可以拒绝的,拒绝的方式有两种Reject和Nack,这两种方式是差不多的.
1.Reject 和 Nack
Reject只能一条消息一条消息的拒绝,Nack可以一批一批的拒绝,
消息确认可以让 RabbitMQ 知道消费者已经接受并处理完消息。但是如果消息本身或者消息的处理过程出现问题怎么办?需要一种机制,通知RabbitMQ,这个消息,我无法处理,请让别的消费者处理。这里就有两种机制,Reject 和 Nack。
Reject 在拒绝消息时,可以使用 requeue 标识,告诉 RabbitMQ 是否需要重新发送给别的消费者。如果是 false 则不重新发送,一般这个消息就会被RabbitMQ 丢弃。Reject 一次只能拒绝一条消息。如果是 true 则消息发生了重新投递。
Nack 跟 Reject 类似,只是它可以一次性拒绝多个消息。也可以使用 requeue 标识,这是 RabbitMQ 对 AMQP 规范的一个扩展。
无论是使用 Reject 方式还是 Nack 方式,当 requeue参数设置为 true 时,消息发生了重新投递。当 requeue 参数设置为 false 时,消息丢失了。
requeue=true
如果在消息拒绝的时候,如果参数为requeue=true的话,意味着消息可以重新投递,这样消息就会重写进入到队列里面让其它的消费者来使用.
如果requeue=false的话,消息拒绝完了消息就丢失了,不会进入到队列里面去.
消息队列中有 10 条消息,有三个消费者,有两个消费可以正常消费消息,有一个消费进行消息的拒绝,同时设置 requeue 参数设置为 true,我们来看下具体的过程。
1.三个消费者订阅一个队列,消息使用轮询的方式进行发送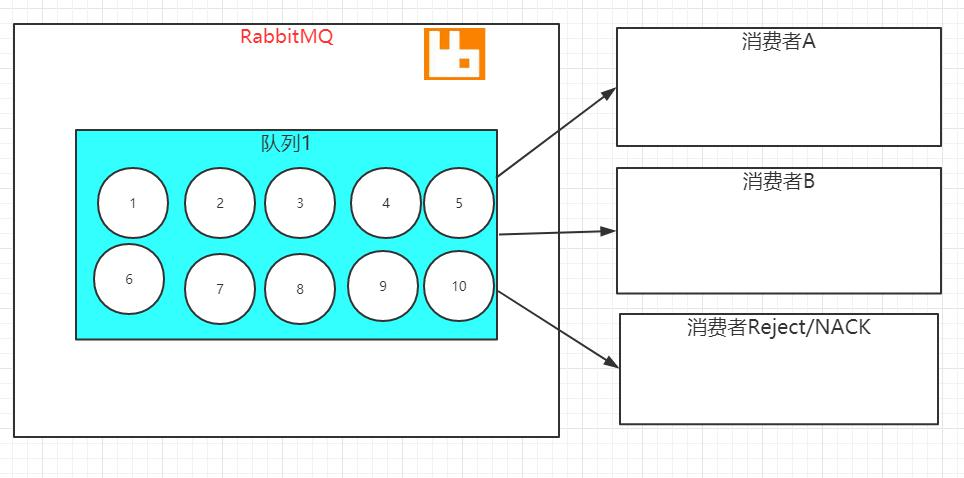
2.有一个消费者拒绝消息,同时 requeue 参数设置为 true,消息准备进行重新投递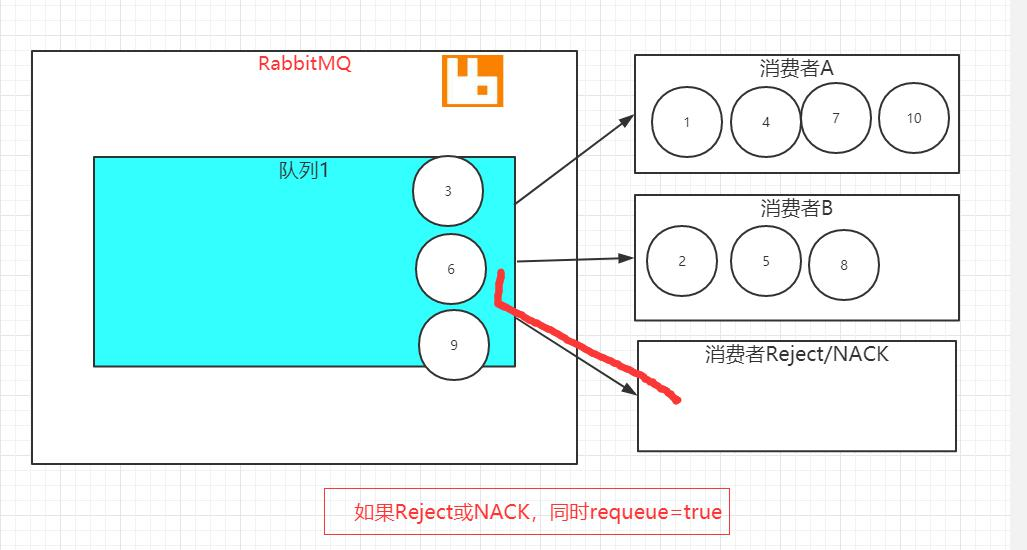
3.再使用消息轮询的方式,把三条消息方便发送至三个消费者,其中又会发生一次消息拒绝和消息的重新投递。
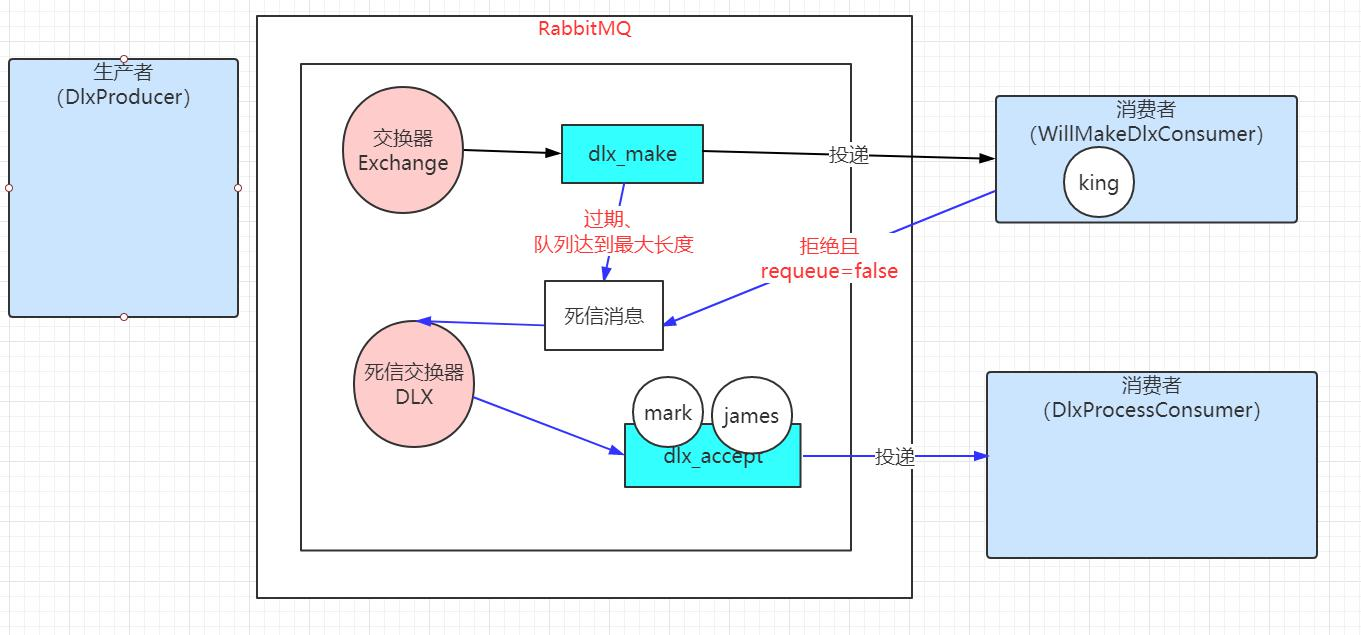
2.死信交换器 DLX
| 案例:ZJJ_RabbitMQ_2019/11/05_10:01:48_pu44n |
|---|
如果使用消息拒绝机制,同时 requeue 参数设置为 false 时,消息丢失了,这点作为程序员我们不能忍。所以 RabbitMQ 作为一个高级消息中间件,提出了死信交换器的概念,死信,意思就是死了的信息。这种交换器专门处理死了的信息(被拒绝可以重新投递的信息不能算死的)。
死信交换器是 RabbitMQ 对 AMQP 规范的一个扩展,往往用在对问题消息的诊断上(主要针对消费者),还有延时队列的功能。
| 消息变成死信一般是以下三种情况: 1. 消息被拒绝,并且设置 requeue 参数为 false 2. 消息过期(默认情况下 Rabbit 中的消息不过期,但是可以设置队列的过期时间和消息的过期时间以达到消息过期的效果) 3. 队列达到最大长度,队列满了.(一般当设置了最大队列长度或大小并达到最大值时),最先进去的那一条会变成死信消息. |
|---|
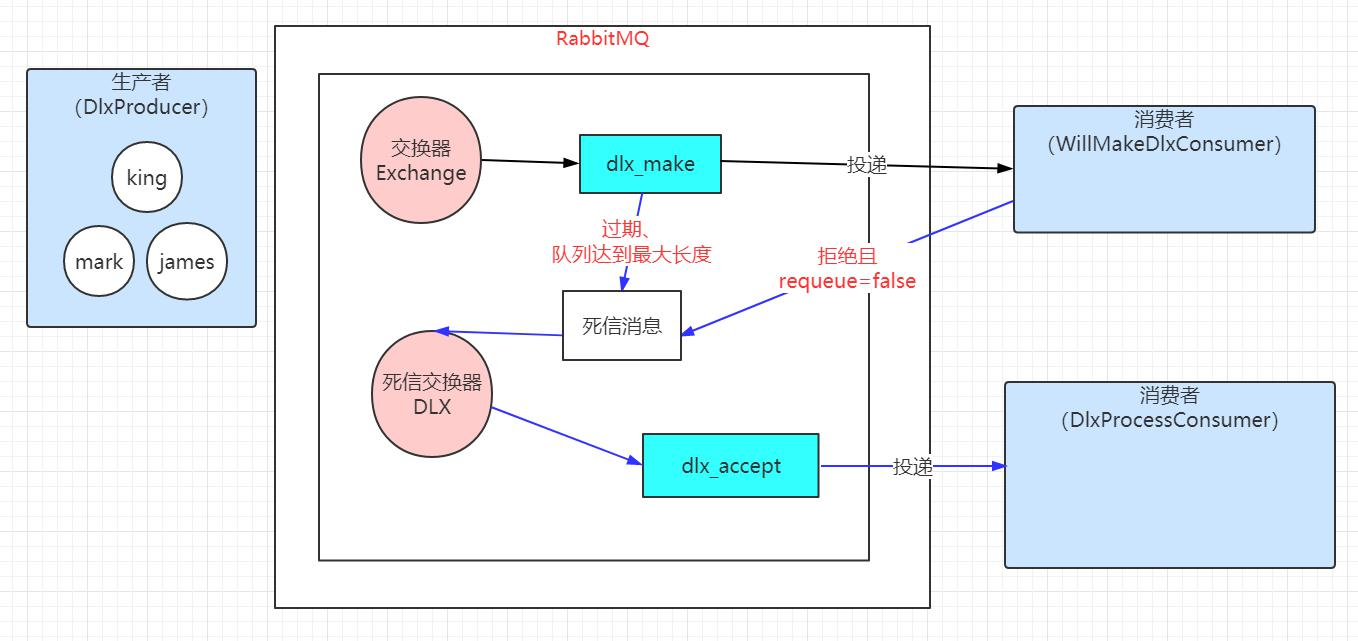
死信交换器仍然只是一个普通的交换器,创建时并没有特别要求和操作。在创建队列的时候,声明该交换器将用作保存被拒绝的消息即可,相关的参数是 x-dead-letter-exchange。
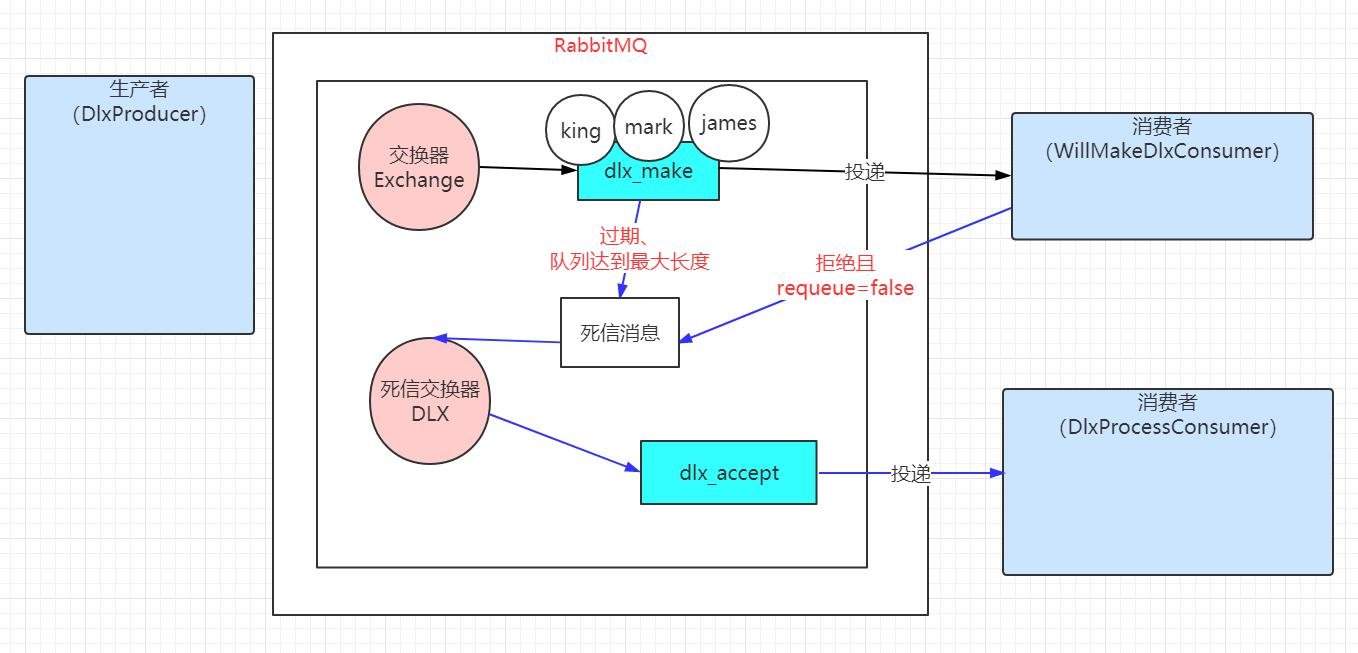
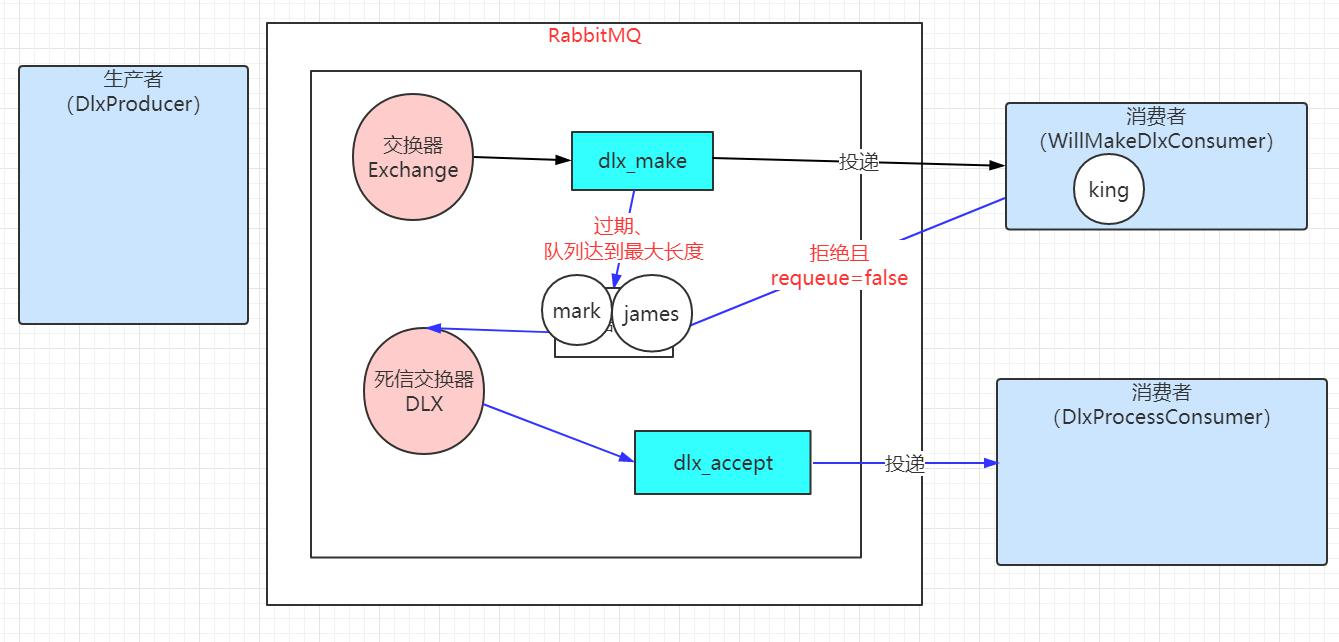
通过运行程序可以看到,生产者DlxProducer产生了 3 条消息,分别是 king,mark,james,消费者 WillMakeDlxConsumer 都拒绝了两条消息(mark 和 james),
同时设置 requeue 参数为 false,这样这两条消息会被作为死信消息,同时在主交换器中,绑定对应的死信交换器,这样死信消息会通过死信交换器投递
到对应绑定的死信队列上(dlx_accept), 这样 DlxProcessConsumer 消费者就能看到消息的消费,同时这样死信消息还是保持原有的路由键。
如果是我们还想做点其他事情,我们可以在死信交换的时候改变死信消息的路由键,具体的相关的参数是 x-dead-letter-routing-key。
和备用交换器的区别
1、备用交换器是主交换器无法路由消息,那么消息将被路由到这个新的备用交换器,而死信交换器则是接收过期或者被拒绝的消息。
2、备用交换器是在声明主交换器时发生联系,而死信交换器则声明队列时发生联系。
场景分析:备用交换器一般是用于生产者生产消息时,确保消息可以尽量进入 RabbitMQ,而死信交换器主要是用于消费者消费消息的万不一失性的场景(比如消息过期,队列满了,消息拒绝且不重新投递)
应用场景
死信交换器结合消息过期机制一般用在”限时订单”业务场景.

若有收获,就点个赞吧
0 人点赞
