一、聚簇索引
(InnoDB的索引模型)
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。但InnoDB的聚簇索引实际上在同一结构中保存了B-Tree索引和数据行。
当表有聚簇索引时,它的数据行实际上存放在索引的叶子页(leaf page)中。聚簇表示数据行和相邻的键值紧凑地存储在一起。
下图展示了聚簇索引中的记录是如何存放的,注意到,叶子页包含了行的全部数据,但是节点页只包含了索引列。
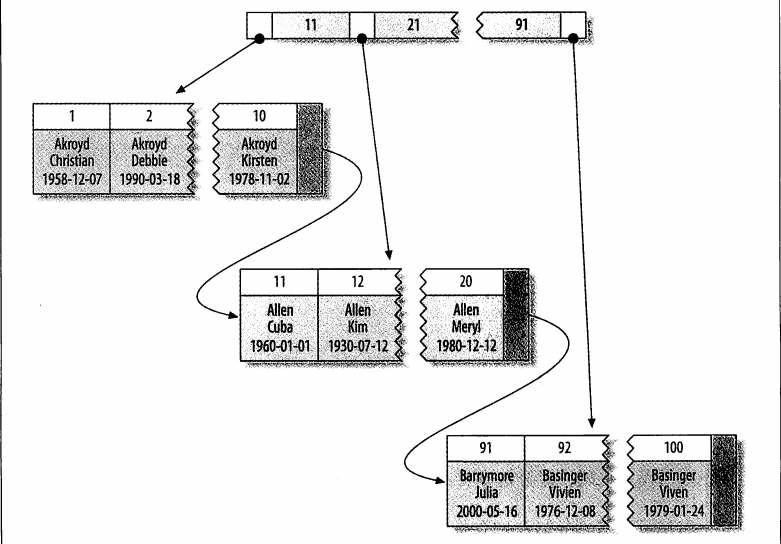
如果没有定义主键,InnoDB会选择一个唯一的非空索引代替,如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。
聚集的数据有一些重要的优点:
A:可以把相关数据保存在一起,如:实现电子邮箱时,可以根据用户ID来聚集数据,这样只需要从磁盘读取少量的数据页就能获取某个用户全部邮件,如果没有使用聚集索引,则每封邮件都可能导致一次磁盘IO
B:数据访问更快,聚集索引将索引和数据保存在同一个btree中,因此从聚集索引中获取数据通常比在非聚集索引中查找要快
C:使用覆盖索引扫描的查询可以直接使用页节点中的主键值
聚集索引的缺点:
A:聚簇数据最大限度地提高了IO密集型应用的性能,但如果数据全部放在内存中,则访问的顺序就没有那么重要了,聚集索引也没有什么优势了
B:插入速度严重依赖于插入顺序,按照主键的顺序插入是加载数据到innodb表中速度最快的方式,但如果不是按照主键顺序加载数据,那么在加载完成后最好使用optimize table命令重新组织一下表
C:更新聚集索引列的代价很高,因为会强制innodb将每个被更新的行移动到新的位置
D:基于聚集索引的表在插入新行,或者主键被更新导致需要移动行的时候,可能面临页分裂的问题,当行的主键值要求必须将这一行插入到某个已满的页中时,存储引擎会将该页分裂成两个页面来容纳该行,这就是一次页分裂操作,页分裂会导致表占用更多的磁盘空间
E:聚集索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候
F:二级索引可能比想象的更大,因为在二级索引的叶子节点包含了引用行的主键列。
G:二级索引访问需要两次索引查找,而不是一次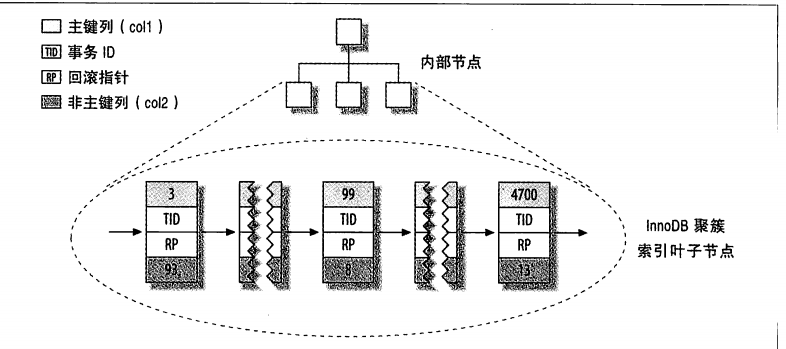
聚簇索引的每一个叶子节点都包含了主键值、事务ID、用于事务和MVCC的回滚指针以及所有的剩余列,如果主键是一个列前缀索引,InnoDB也会包含完整的主键列和剩下的其他列
二、联合索引
现在创建一个索引为bcd,bcd不是主键索引,是联合索引
explain select * from t1 where b1 >7
如果这样会走索引吗?但是它走的是全表进行扫描,它是可以走索引的。
它认为它走全表扫描更快,如果走索引还要进行7次回表。所以成本是大于走索引的。
explain select * from t1 where b1 >6
但是如果是>6就有可能走索引,因为回表的次数少了。
为什么进行回表,因为查的是select ,如果不是Select 呢?
我直接查询它索引存储的

select b from t1 有几次走法?
(1)全表扫描
(2)索引扫描(bcd索引)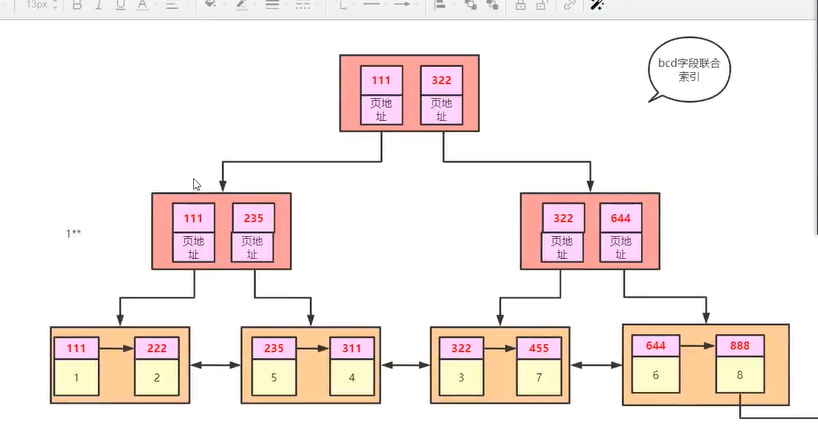
因为bcd索引扫描的时候,存储的数据是不完整的所以存储,所以存储的可能会多。

若有收获,就点个赞吧
0 人点赞
