索引的本质
- 索引是帮助MySQL高效获取数据的排好序的数据结构。
- 索引存储在文件里
- 索引结构
- 二叉树(红黑树)
- HASH
- BTREE
索引存储在哪里? 磁盘
如果不通过加索引,读取一行就需要进行一次I/O操作
(1)底层为什么用BTREE
1、用红黑树进行查询,当我们搜索6的时候,需要3次IO,如果我们有100万行数据,那太深了。(树的高度,随着数据量的增大会增大)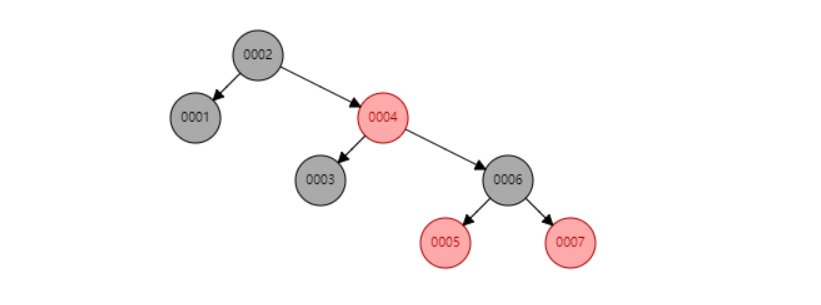
2、BTREE
当我们查找6的时候,只需要查询2次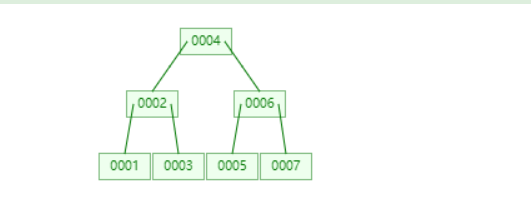
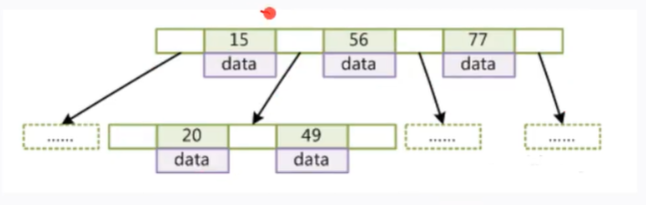
(2)B-Tree的特点
- 度(Degree)-节点的数据存储个数
- 叶节点具有相同的深度
- 叶节点的指针为空
- 节点中的数据Key从左到右递增排列
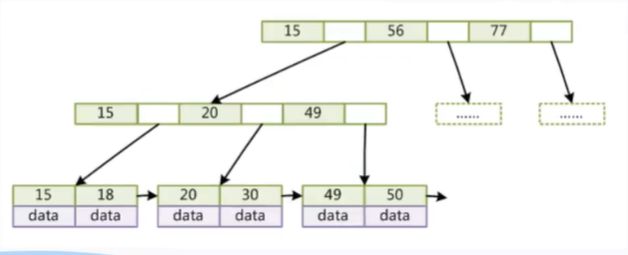
(3)B+Tree(B-Tree变种)
- 非叶子节点不存储data,只存储key,可以增大度
- 叶子节点不存储指针
- 顺序访问指针,提高区间访问的性能
(4)B 树和B+树的区别?
- B+树的非叶子节点只存储key,B树的非叶子节点既有key又有value
- B+树的叶子节点存储数据,并且多了指针(范围查询 eg: col>20)
(5)存储引擎对应的索引结构
数据引擎都是形容数据库表的
MyIsam索引实现(非聚集)
.frm 存储的是这个表的结构
.mYd 存储的是这个表的数据
.myi 存储的是这个表的索引
MyISAM索引文件和数据文件是分离的。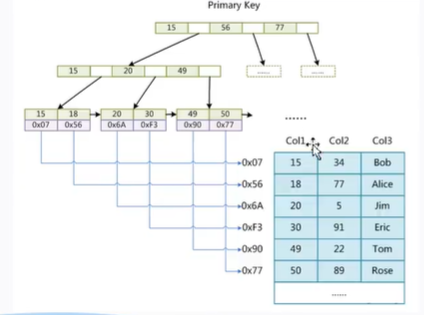
InnoDB(索引实现)聚集 **
**
.frm表的结构
.ibd表的数据+索引
为什么存储在一个里面呢?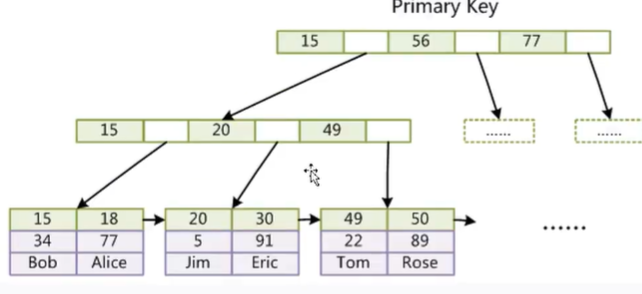
这样的话就不用拿到索引key找另一个文件找value了。
- 表数据文件本身就是按B+Tree组织的一个索引结构文件
- 聚集索引-叶节点包含了完整的数据记录
- 为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?(使用UUID使树的高度更高,UUID不是自增的还有更改以前的结构)
- 为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省内存空间)
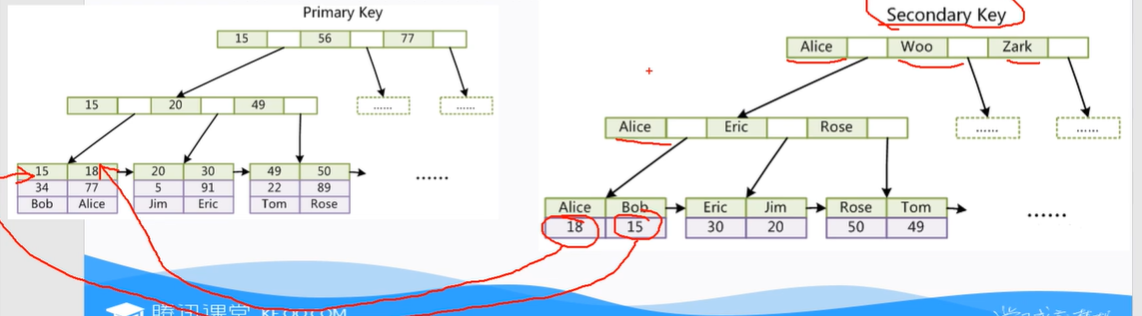
(6)为什么B+树value都存储在叶子节点
一个页为16k,这样一个存储的索引就会更多了。
(7)为什么Mysql页为16k?
假设我们一行数据大小为1K,那么一页就能存16条数据,也就是一个叶子节点能存16条数据;再看非叶子节点,假设主键ID为bigInt类型,那么长度为8B,指针大小为Innodb源码中为6B,一共就是14B,那么一页就可以存16k/14 = 1170个(主键+指针)
那么一颗高度为2的B+树能存储的数据为117016 =18720条,一颗高度为3的B+树能存储的数据为:11701170*16=21902400(千万级条)
(8)聚簇索引和非聚簇索引的区别
都是B+树的数据结构
聚簇索引:将数据存储与索引放到了一块、并且是按照一定的顺序组织的,找到索引也就找到了数据,数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻存放在磁盘上的。
非聚簇索引: 叶子节点不存储数据、存储的是数据行地址,也就是说根据索引查找到数据行的位置再去磁盘查找数据,这个就有点类似一本书的目录,比如我们要找第三章第一节,那我们先在这个目录里面找,找到对应的页码后再看文章。
优势:
1、查询通过聚簇索引可以直接获取数据、相比非聚簇索引需要第二次查询(非覆盖索引的情况下)效率要高
2、聚簇索引对于范围查询的效率很高,因为其数据是按照大小排列的
3、聚簇索引适合用在排序的场合,非聚簇索引不适合
劣势:
1、维护索引很昂贵,特别是插入新行或主键被更新导致要分页的时候,建议在大量插入新行后,选在负载较低的时间段,通过OPTIMIZE TABLE 优化表,
2、表因为使用UUID作为主键,使数据存储稀疏,这就会出现聚簇索引有可能比全表扫描更慢,索引建议使用int的auto_increment作为主键
3、如果主键比较大的话,那辅助索引将会变的更大,因为辅助索引的叶子存储的是主键值,通过长的主键值,会导致非也自及诶单占用占更多的物理空间。
(9)InnoDB和MyISM中索引的区别(为什么MyISM进行大数据量排序更好)?
InnoDB中一定有主键,主键一定是聚簇索引,不手动设置,则会使用unique索引,没有unique索引,则会使用数据库内部的一个行的隐藏id来当作主键索引。在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引,辅助索引叶子节点存储的不再是行的物理位置,而是主键值。
MyISM使用的是非聚簇索引,没有聚簇索引,非聚簇索引的两颗B+树看上去没有什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助索引B+树存储了辅助键,表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键索引无需访问主键的索引树。
如果涉及到大数据量的排序、全表扫描、Count之类的操作的话,还是MyISAM占优势些,因为索引所占空间小,这些操作是需要在内存中完成的。
索引最前缀原理
联合索引的底层存储结构长什么样?
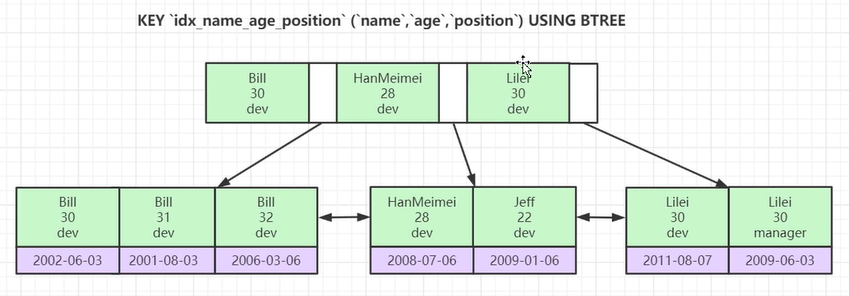
联合索引也是建好序的,是你建联合索引的顺序从左到右。
为什么如果只查询age和position不会走索引了?
可以从图中看出name是已经排好序的,age是根据name排好序的再次进行排序,但是如果查询的话,会发现age并不是全部进行排好序的,那么就相当于全表查询了。
索引的基本原理
就是把无序的数据变成有序的查询
1、把创建了索引的列的内容进行排序
2、对排序结果生成倒排表
3、在倒排表内容上拼上数据地址链
4、在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据

若有收获,就点个赞吧
0 人点赞
