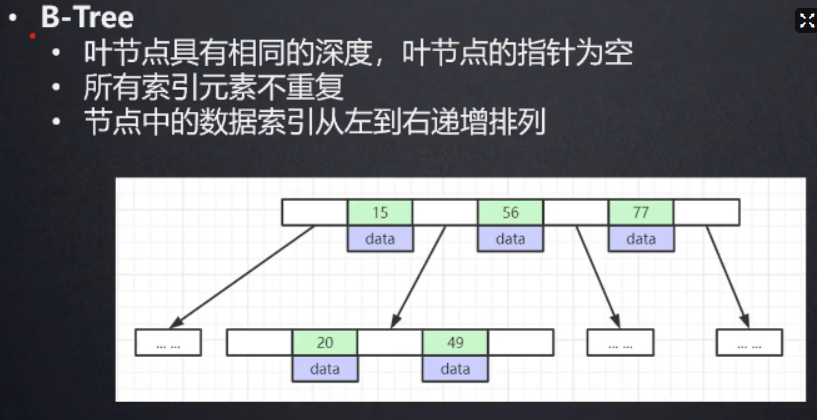
B 树
B树的出现为了弥合不同的存储级别之间的访问速度上的巨大差异,实现高效的I/O,平衡二叉树的查找效率是非常高的,并可以通过降低树的深度来提高查找的效率。但是当数据量非常大,树的存储的元素数量是有限的,这样会导致二叉查找树结构由于树的深度过大而造成磁盘I/O读写过于频繁,进而导致查询效率低下。另外数据量过大会导致内存空间不够容纳平衡二叉树所有结点的情况。B树是解决这个问题的很好的结构。
概念
B树 是一种自平衡数据结构,它维护有序数据并允许以对数时间进行搜索,顺序访问,插入和删除。B树是二叉树的一般化,因为节点可以有两个以上的子节点。与其他自平衡二进制搜索树不同,B树非常适合读取和写入相对较大的数据块(如光盘)的存储系统。它通常用于数据库和文件系统。
B+树
B+树的特征:
- 有m个子树的中间节点包含有M个元素(B树中是K-1个元素),每个元素不保存数据,只用来索引。
- 所有的叶子节点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序连接(而B树的叶子节点并没有包含全部需要查找的信息);
- 所有的非终端节点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字
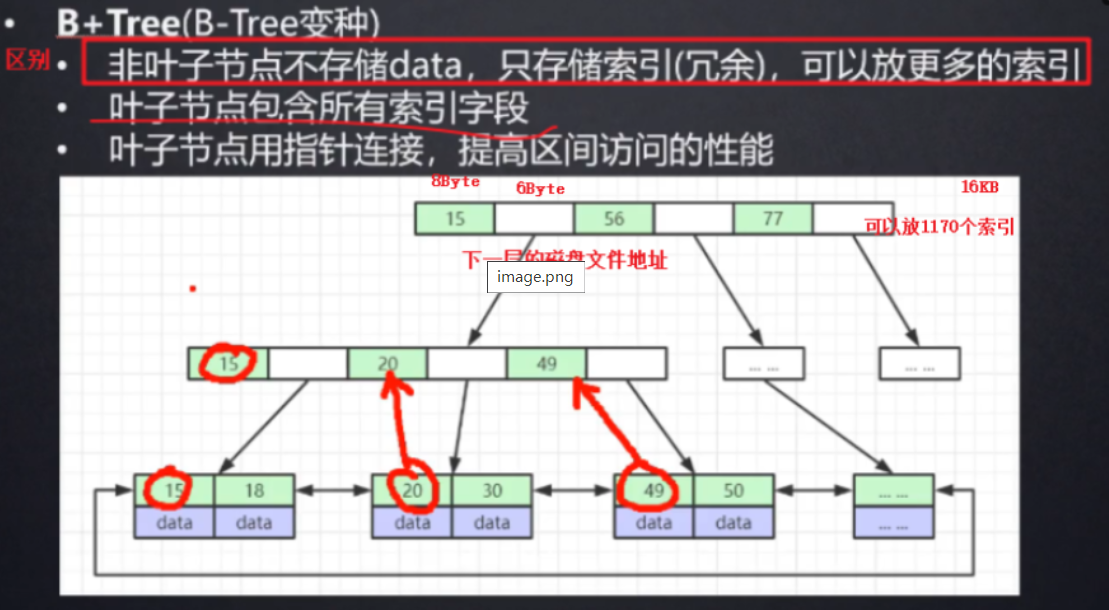
查找的过程:
先将根节点放到内存然后去定位,到15~56之间 然后定位到次节点 ,将 次节点读取到内存,在内存内部做对比,找到叶子界面
(只有将节点读取到内存有效率消耗,但是在内存中最对比消耗几乎为0 )
有一个问题: 那为什么不把所有的索引都放在根节点一块读到内存?
因为每一个节点的大小都是有限制的:
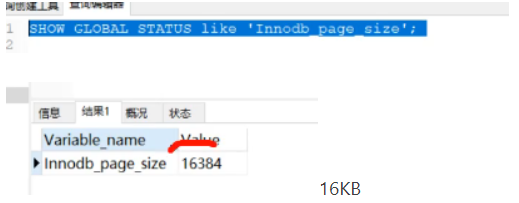
其实在高版本下 非叶子节点其实都是存储在内存中的
说一下B树和B+树的区别:
- B树的叶子节点之间没有双向指针,没有关联,所以范围查找不方便,效率低
- B+树中虽然有冗余索引,但是他的非叶子节点不存储数据,而B树的每个节点都存储数据的,导致同样大小的节点可以存储的索引值就比较少,这样树的高度就很高,查询效率低(树的节点越少,查询效率越高)
(1)为什么说B+树比B树更适合数据库索引
(1)B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了;、
(2)B+树查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当;
(3)B+树便于范围查询(最重要的原因)
B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的

若有收获,就点个赞吧
0 人点赞
