(1)索引是什么
数据本身之外,数据库还维护着一个满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,
这样就可以在这些数据结构的基础上实现高级查找算法,这种数据结构就是索引
索引是帮助MySQL高效获取数据的数据结构,可以得到索引的本质:索引是数据结构
排好序的快速查找数据结构
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。
我们平常所说的索引,如果没有特别指明,都是指B树(多路搜索树,并不一定是二叉的)结构组织的索引,其中聚集索引,次要索引,复合索引,前缀索引
唯一索引默认都是使用B+树索引,统称索引。
(2)索引的目的
(3)索引类型
(4)索引优势
1、大大减少了服务器需要扫描的数据量。
2、索引可以帮助服务器避免排序和临时表。
3、索引可以将随机I/o变成顺序I/o。
(5)索引劣势
实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占空间的。
虽然索引大大提高了查询速度,同时确会降低更新表的速度,如对表进行INSERT、UPDATE、DELETE。
因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段。
都会调整因为更新所带来的键值变化后的索引信息。
(6) InnoDB的索引模型
主键索引(聚集索引)
其实就是叶子节点的索引和真实的值存储在一个节点中,也就是数据文件和索引文件在一起存放
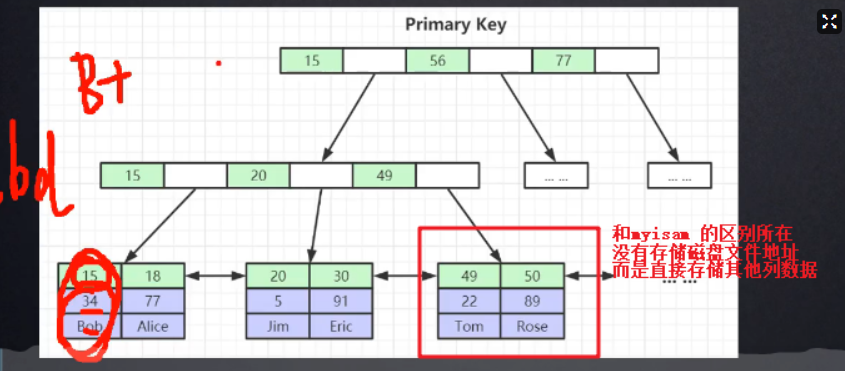
非主键索引采用的是非聚集索引
回表:
为什么建议InnoDB表必须创建一个主键,并且推荐使用整型的自增主键?
- 如果我们不创建主键,mysql会在底层帮我查找一个不重复的列,作为聚集索引,但是如果没有发现有唯一的列,那么mysql底层会帮我们创建一个默认的版本列来作为聚集索引,所以说mysql的innoDB的每一章表一定会并且只有一个聚集索引。
为什么不推荐使用uuid而推荐使用自增的?
长度问题:
比较查询的效率更高,占用的资源更少,每一页占用的空间小,可以放更多的关键字,以降低B+树的高度
而且B+树的叶子节点之间是双向链表对于范围查找效率很快排序问题
如果是自增,那么永远都是新创建节点,如果不是自增,就会造成节点分裂。性能降低
索引底层原理:
我们创建一个表并且指定主键,插入一些字段,执行查询发现
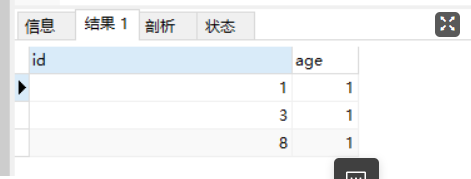
在底层页中的存储是按照顺序存储的,所以在查询的时候查询到4的时候就不继续往下查询。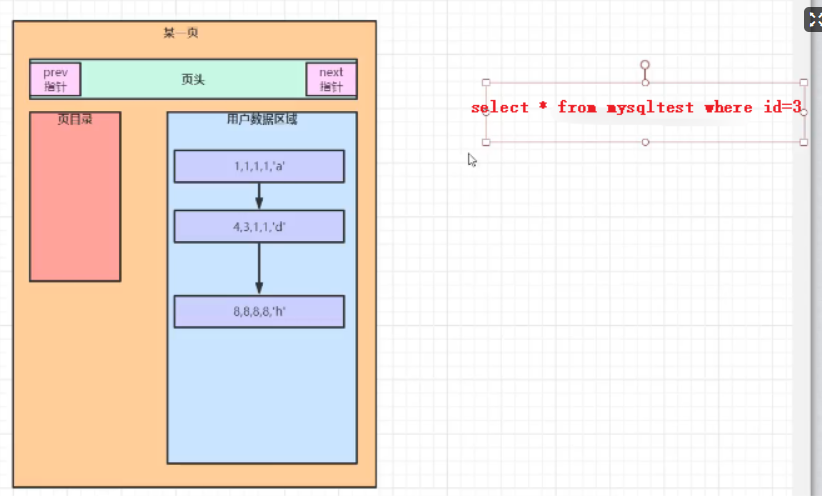
如果没有页目录就会有一个问题就是如果查询id=2000,那么就会一直遍历下去。
这个时候就会根据页目录中的节点来查找对应的节点,效率有所提升,但是这个时候如果页越来越多,就变成了一个长链表,效率还是低。
这个时候就会先根据页目录中的节点来查找对应的节点,效率有所提升,但是这个时候如果页越来越多越就变成了一个个长链表。
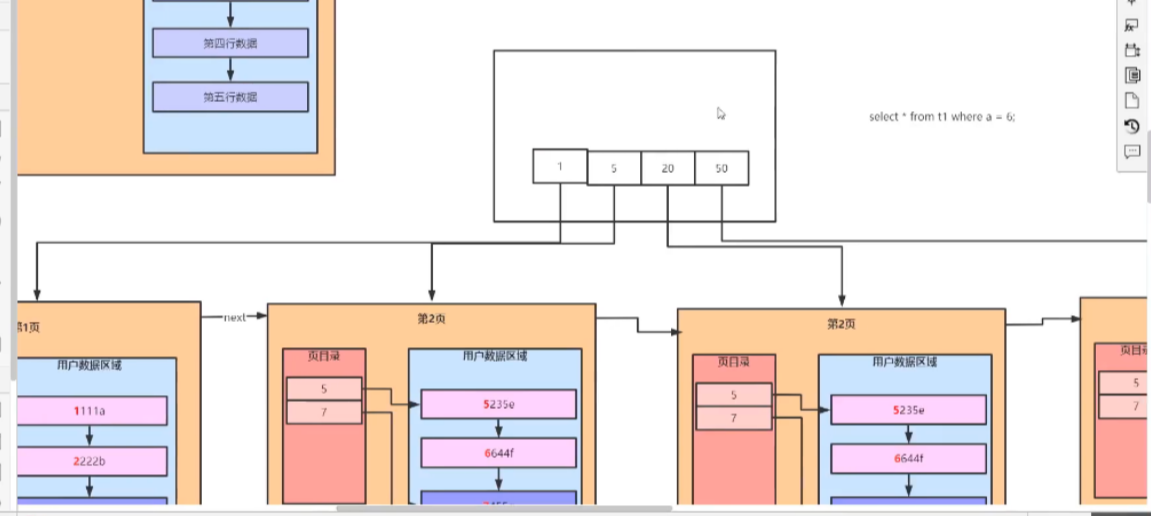
最终的效果: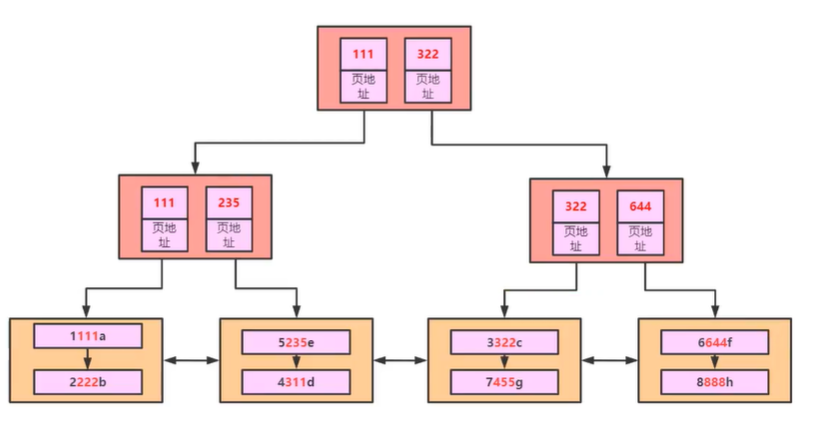
这样就和索引对应上了,也就形成了B+树
B+树的特点:
- 排好序的
- 叶子节点的值在非叶子节点中都是冗余存在的,但是不是全部冗余,只是冗余一部分(索引)
所以说叶子节点其实存储的是 “page页”
什么是走索引什么是全表扫描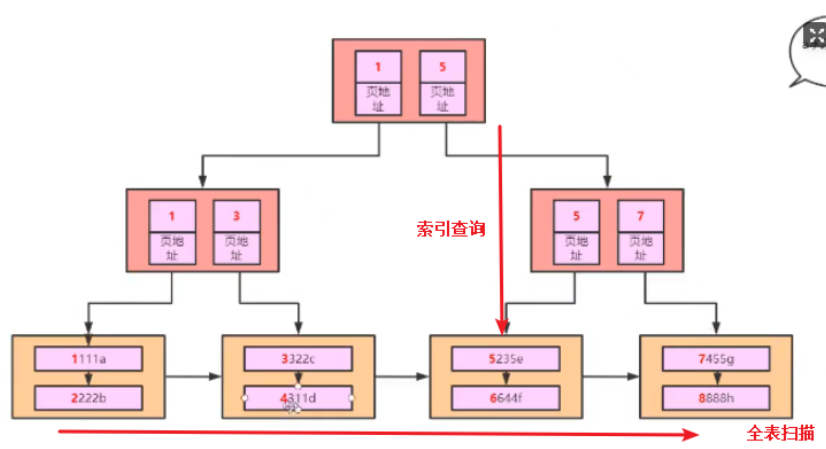
**
而我现在按照bcd进行建立索引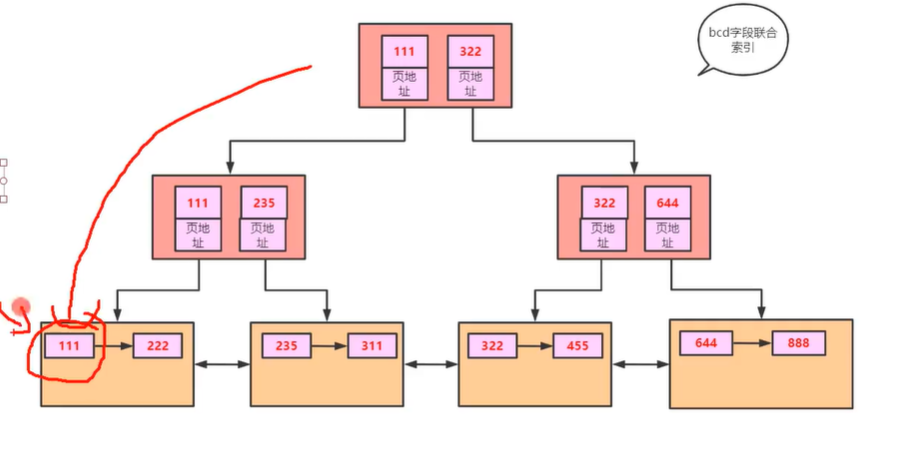
叶子节点只存储查询的值,如果我用select * 就会很不满足,如果全部记录在里面也不好,因为会和其他索引形成的冗余数据。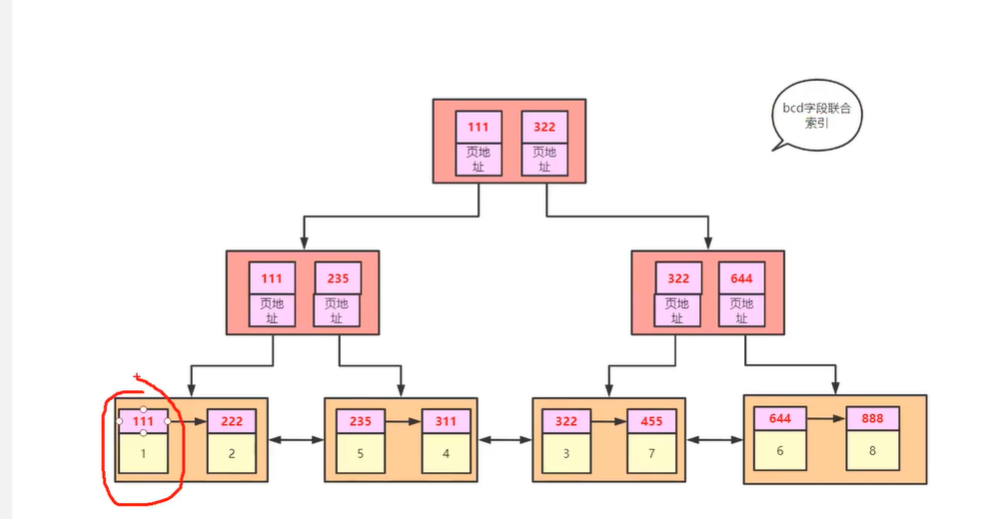
如果我们把主键的id弄上,就可以了。
利用主键去查找,然后这个过程就叫回表。
(6) mysql索引分类
1、单值索引
2、唯一索引
3、复合索引
即一个索引包含多个列。
4、基本语法

(7)索引的结构
BTree索引
检索原理: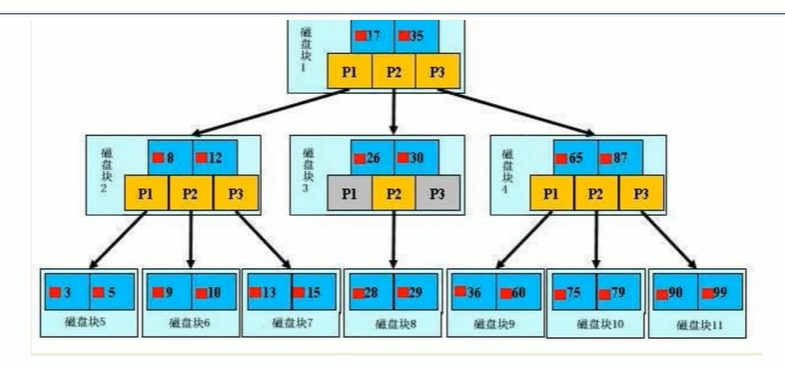
【初始化介绍】
一颗b+树,浅蓝色的块我们称之为一个磁盘块,我们看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示)
如果磁盘块1包含数据项17和35,包含指针p1、p2、P3.
p1表示小于17的磁盘块,p2表示在17和35之间的磁盘块,p3表示大于35的磁盘块
真实的数据存在于子叶子节点即3/5/9/10/13/15/28/29/36/60/75/79/90/99
非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17/35并不真实存在于数据表中
(8) 哪些情况下是可以创建索引的
1、主键自动建立唯一索引
2、频繁作为查询条件的字段应该创建索引
3、查询中与其它表关联的字段,外键关系建立索引
4、频繁更新的字段不适合创建索引 - 因为每次更新不单单是更新记录还是更新索引
5、Where条件里用不到的字段不创建索引
6、单键/组合索引的选择问题,who?(在高并发下倾向创建组合索引)
7、查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
8、查询中统计或者分组字段
(9)哪些情况下不需要创建索引的
1、表记录太少
2、经常增删改表
3、数据重复且分布平均的表字段,因此应该只为最经常查询和最经常排序的数据列建立索引
注意:如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
(10) 注意
1、假删除索引
(1)为了数据分析
(2)为了索引
2、为什么增删慢
因为还要创建索引

若有收获,就点个赞吧
0 人点赞
