一、概念解释:
缓存穿透:
一个查询请求查询了一个根本不存在(数据库中不存在)的数据,因为数据库中不存在这个数据,所以一般情况下,对应的缓存中也不会有这个数据。所以当这种不存在的请求大量来临时,将会穿透缓存层(因为缓存查不到),直接到达数据库中查询。这样导致每次的请求都会直接打到DB上,失去了缓存保护DB的意义。
缓存击穿(缓存失效)
在使用缓存中,都会给缓存设置一个过期时间,防止DB中的数据修改而缓存中的数据不修改造成的长时间的数据不一致问题。但是通常我们设置的过期时间都是一个相同的数值,这就有可能导致,同一时间内,大量的缓存失效,而此时也有大量的请求,直接打到DB中,导致DB的压力过大。
缓存雪崩
因为缓存挂了,导致所有的请求都直接去请求DB了,导致DB压力过大,进而可能产生宕机,从而无法对外提供服务。
热点缓存Key重建
假设有某些缓存中的值,是热点数据,例如秒杀列表页面中的商品。在进行秒杀预热的时候,会事先将这些Key提前缓存到缓存层,并设置过期时间。假设在秒杀过程中,这个key的时间过期了,此时,将会有大量的请求去请求DB,尝试将DB中的值查询出来,设置到缓存中。将会导致DB的压力过大。
二、解决方案
缓存穿透:
通过上述的描述可以知道,缓存穿透就是查询了一个不存在的数据,而这种查询一般是由于以下两种情况导致的
- 程序Bug导致(传参错误或数据错误)
- 黑客攻击,恶意伪造一堆不存在的数据来请求
解决方案:
- 缓存空对象,并设置一个过期时间
在第一次查询数据结束之后,即使查询结果为null,也将这个null值设置到缓存中,并添加一个过期时间(防止日后真的有这个数据),再后续的查询中就可以直接将这个null值返回,而不会进入DB查询。
- BloomFilter(布隆过滤器)
BloomFilter底层是一个巨大的BitMap,会根据预计的个数,以及误差率(后面有),创建一个对应大小的Bit数组。当往布隆过滤器中添加一个Key时,会进行多次的Hash运算(不同的hash算法),再对Bit数组的大小进行取模,取得对应的Bit数组的下标(hash(key)&length),将这个Bit位设置为1。多次hash运算完成之后,会设置Bit数组中的多个Index为1,当查询某个Key存不存在时,会执行相同的hash算法,判断对应的Index下标的值是否为1,只要有一个index为0,说明这个Key肯定不存在。但是如果全部为1,这个key不一定存在(因为存在hash冲突,可能不同的key算出的index相同)。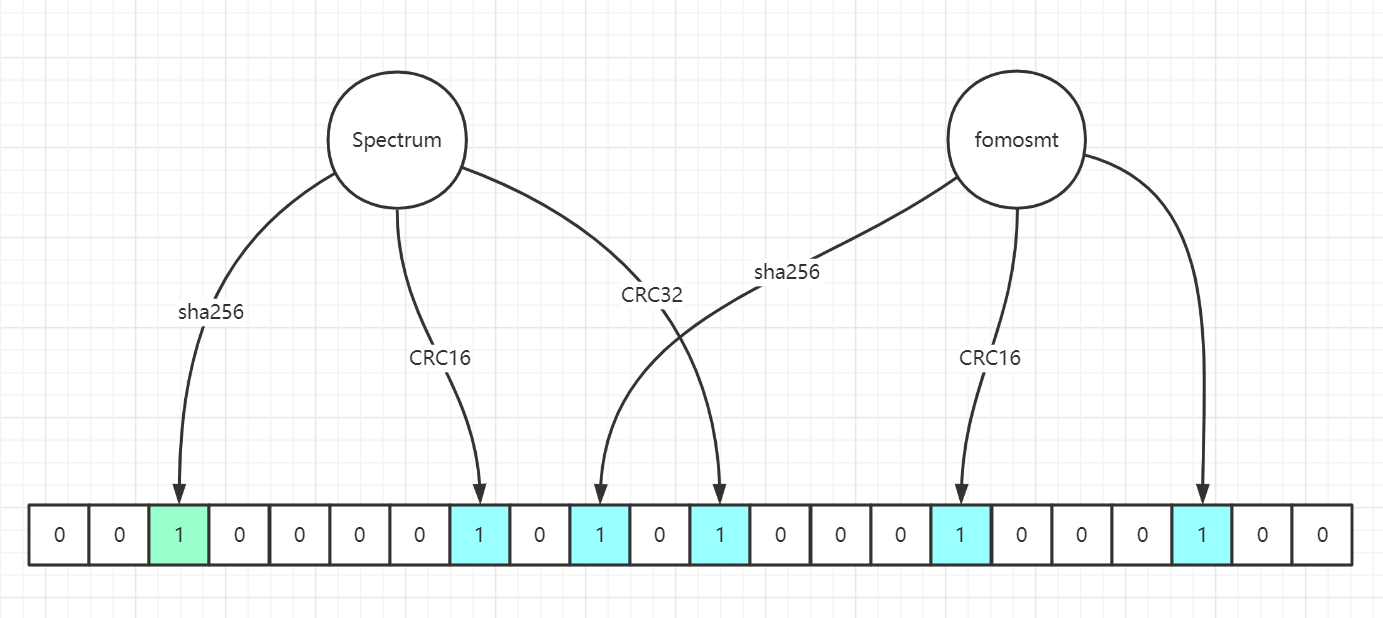
缓存击穿(缓存失效)
根据上面的描述可以得出,缓存击穿就是:同一时间内有大量的Key失效,这种情况常出现于批量操作中,进行批量操作时,一般都会设置同一个时间。所以解决方法为将缓存的过期时间设置为一个随机数,指定在某个时间范围内,让这些缓存不会在同一时间内失效,就可以极大的避免上述的这种情况。伪代码如下:
public String get(String key) {String cache = redis.get(key);if(cache == null) {String value = mysql.get(key);int expireTime = new Random().nextInt(300) + 300;redis.set(key,value, expireTime);cache = value;}return cache;}
缓存雪崩
缓存雪崩,就是缓存层崩了,导致请求都到了数据库层,数据库层抗不住并发,导致数据库挂了,数据库挂了,导致Java服务无法堆外提供访问,造成了一连串的雪崩效应。为了解决这种情况,可以从根本上进行解决
- 让缓存层高可用,使用Redis-Cluster/Redis-Sentinel架构,使得Redis集群可以高可用
- 不让那么大的并发请求一次性过来,采用Alibaba Sentinel,或者Netflix Hystrix组件,进行限流。当流量超过阈值时,返回对应的默认提示信息,给前端一个友好的提示。
- 提前预估缓存层挂了之后后端服务能够支撑的并发量,以及可以出现的问题。。。。
热点缓存Key重建
缓存Key是一个热点Key时,当此Key失效时,会有大量的线程去查询数据库,将其放入缓存中,导致数据库的压力突增。在这种情况下,可以使用互斥锁,让同一个时间内只有一个线程能够去查询数据库,其他线程等住。但因为是分布式场景,所以,需要借助Redis/Zookeeper这些中间件,来实现一个分布式锁,保证在多机环境下,只有一个线程可以去重建缓存。伪代码如下:
public String get(String key) {String cache = redis.get(key);if(cache == null) {boolean result = redis.setnx("mutexKey:" + key, Thread.currentTread(), 180);// 拿到锁的,去查询mysql,设置缓存if(result) {cache = mysql.get(key);redis.set(key,cache, time);redis.delete("mutexKey:" + key);} else {// 没有的,Sleep一下,再去重新获取缓存。Thread.sleep(50);get(key);}}return cache;}
三、缓存与数据库的数据不一致问题
问题描述:
场景一、双写不一致
场景描述:假设如下的两个线程,线程1先执行写数据库,将数据修改为Data1,修改完成之后,执行更新缓存,但是可能由于某些原因(例如GC等各种原因)导致线程1更新缓存的时机延后了,此时线程2来了,将数据修改为Data2,并立即执行了更新缓存,此时(thread2执行完毕时),缓存中的数据为Data2,然后此时thread1活过来了,执行了更新缓存,将缓存更新为了Data1。而此时数据库中的值是Data2,而缓存中为Data1,造成了两边数据的不一致。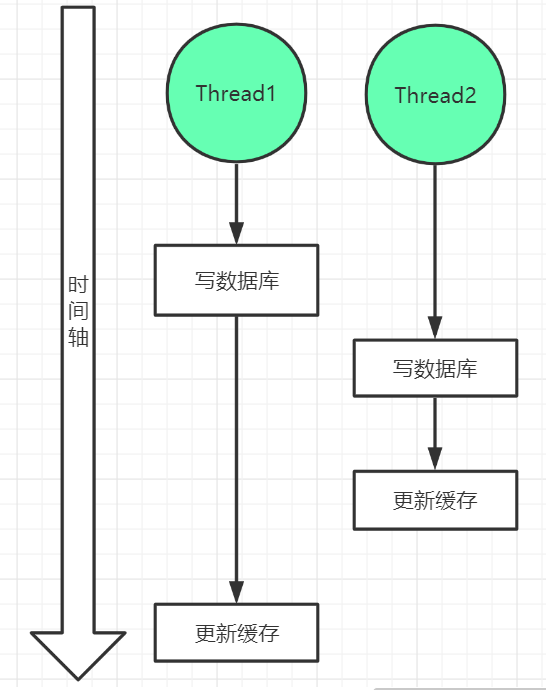
场景二、并发读写不一致
场景描述:根据上面那种情况,可能有人会说,我写完数据库,将缓存中的值给删除掉,等下下次读请求的时候,再从数据库中拿取最新的值,更新到缓存中不就行了?针对于这种情况,就是这种场景下的,读写并发存在的情况。
线程1执行写数据库,改成5,删除缓存,执行结束,此时数据库data = 5。此时线程3过来了,先查询缓存,因为缓存被删除了,查询为null,所以进而去数据库中进行查询,查询出来data = 5,理论上应该立即更新缓存,但是由于各种原因(GC啊,线程调度啊等)thread3被阻塞了,没有执行更新缓存的操作,此时线程2来了,执行了更新数据库data = 3,并删除了缓存(此时没有缓存,删不删无所谓),此时数据库 data = 3。此时线程3活过来了,执行了更新缓存 data = 5(因为线程3查询出来是data = 5),而此时数据库 data =3,缓存data = 5,又不一致了。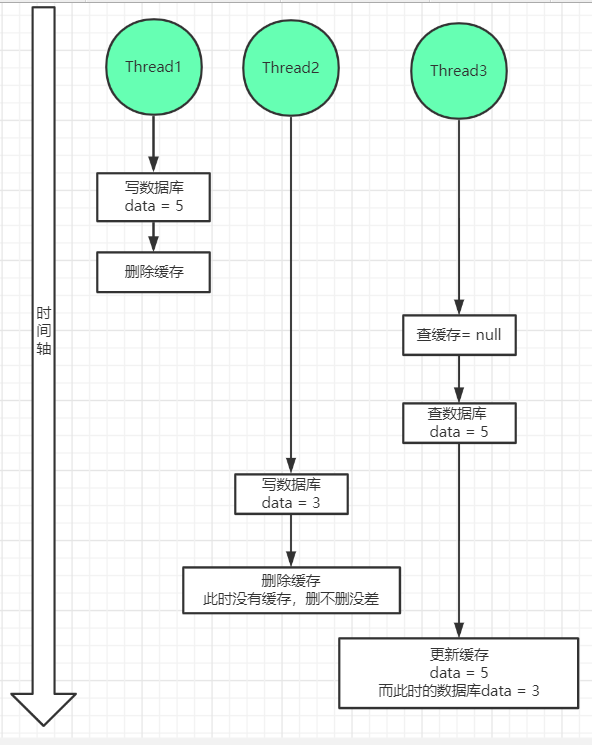
总之,同时使用缓存与数据库,必然会产生数据库与缓存中数据不一致的情况。常用的解决办法有如下几种。
- 对于个人数据(个人订单等)这种并发程度不高的数据,不需要考虑这种问题,给缓存上一个对应的过期时间,即可。
- 对于业务上能容忍短时间的缓存数据不一致(如商品名称,商品分类菜单等),即使并发量很高。在缓存加上过期时间依然可以解决大部分业务对于缓存的要求。
- 对于大多数场景(读多写少)的情况下,可以采用ReadWriteLock,保证读写以及写写请求互斥,进行排队。读读不需要排队。
- 使用Canal中间件,来订阅BinLog,通过BinLog中的数据来更新缓存(BinLog有序,根据mysql事务的先后顺序来生成BinLog)。

若有收获,就点个赞吧
0 人点赞
