- Sharding-Sphere 核心功能使用
- shardingjdbc 分片策略
- 配置数据源,给数据源起名称
- 一个实体类对应两张表,覆盖
- 配置数据源具体内容,包含连接池,驱动,地址,用户名和密码
- 指定 course 表分布情况,配置表在哪个数据库里面,表名称都是什么 m1.course_1 , m1.course_2
- 指定 course 表里面主键 cid
- 生成策略 SNOWFLAKE
- 指定分片策略 约定 cid 值偶数添加到 course_1 表,如果 cid 是奇数添加到 course_2 表
- 打开sql打印功能
- 水平分库配置文件
- shardingjdbc 分片策略
- 配置数据源,给数据源起名称
- 水平分库,配置两个datasource
- 一个实体类对应两张表,覆盖
- 配置第一个数据源具体内容,包含连接池,驱动,地址,用户名和密码
- 配置第二个数据源具体内容,包含连接池,驱动,地址,用户名和密码
- 指定 course 表分布情况,配置表在哪个数据库里面,表名称都是什么 m1.course_1 , m1.course_2
- 指定 course 表里面主键 cid
- 生成策略 SNOWFLAKE
- 指定表分片策略 约定 cid 值偶数添加到 course_1 表,如果 cid 是奇数添加到 course_2 表
- 指定数据库分片策略 约定 user_id 是偶数添加 m1 ,是 奇数添加 m2
- 打开sql打印功能
- 添加第二个数据源
- 修改course表的路由规则
- 指定数据库分片策略 约定 user_id 是偶数添加 m1 ,是 奇数添加 m2
- 测试crud
- 配置主从复制
- 添加s0 datasource
- user_db的从服务器
Sharding-Sphere 核心功能使用
什么是Sharding-Sphere
- 一套开源的分布式数据库中间件解决方案
2、有三个产品:Sharding-JDBC 和 Sharding-Proxy
3、定位为关系型数据库中间件,合理在分布式环境下使用关系型数据库操作什么是分库分表
1、数据库数据量不可控的,随着时间和业务发展,造成表里面数据越来越多,如果再去对数 据库表 curd 操作时候,造成性能问题。
2、方案
1:从硬件上
3、方案
2:分库分表
为了解决由于数据量过大而造成数据库性能降低问题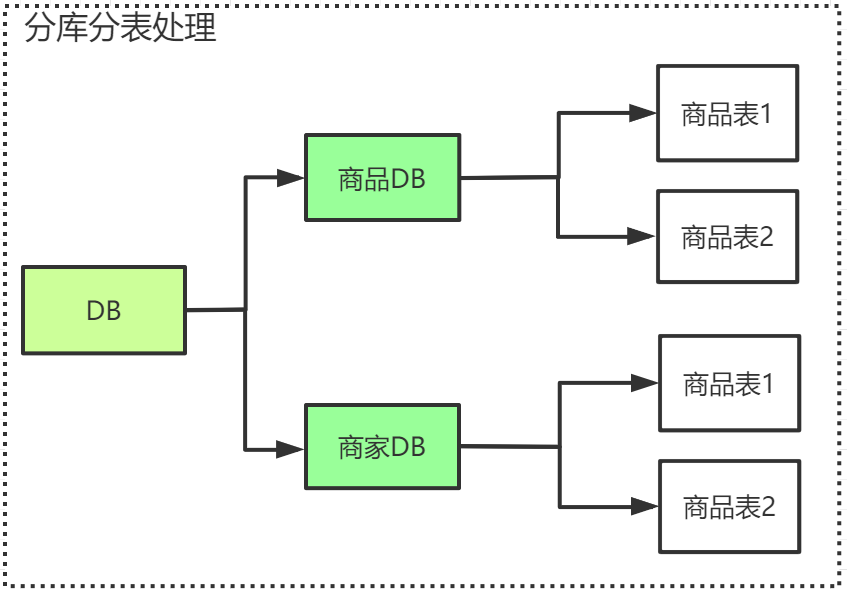
分库分表的策略
- 垂直拆分
a. 垂直分表:操作数据库中某张表,把这张表中一部分字段数据存到一张新表里面,再把这张表另一 部分字段数据存到另外一张表里面(即将一个表的字段分散到不同的表去)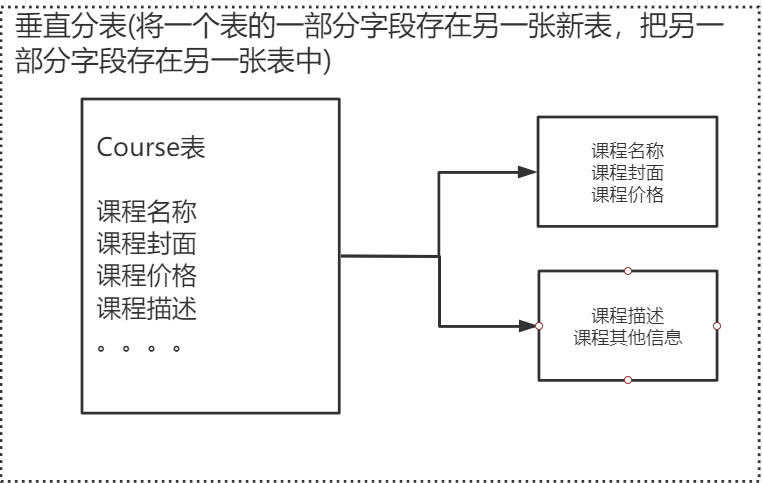
b.垂直分库:把单一数据库按照业务进行划分,不同的业务专门的数据库。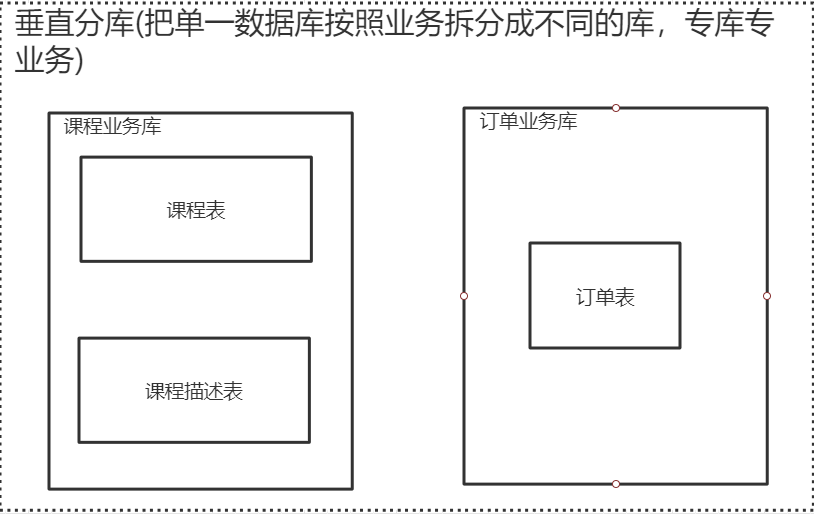
2. 水平拆分
a. 水平分表:在同一个数据库中,相同结构的表具有多张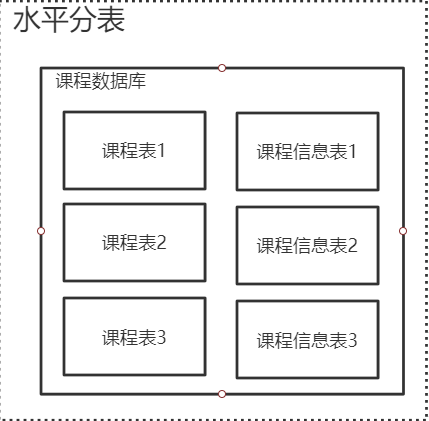
b.水平分库: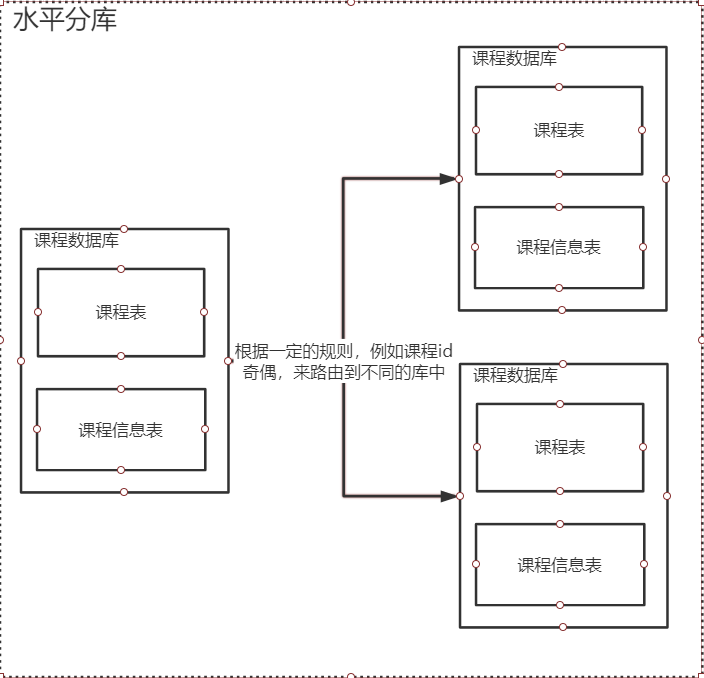
分库分表的应用和产生的问题
应用:
(1)在数据库设计时候考虑垂直分库和垂直分表
(2)随着数据库数据量增加,不要马上考虑做水平切分,首先考虑缓存处理,读写分离,使 用索引等等方式,如果这些方式不能根本解决问题了,再考虑做水平分库和水平分表
问题:
(1)跨节点连接查询问题(分页、排序)
(2)多数据源管理问题
什么是Sharding-JDBC
1、是轻量级的 java 框架,是增强版的 JDBC 驱动
2、Sharding-JDBC
(1)主要目的是:简化对分库分表之后数据相关操作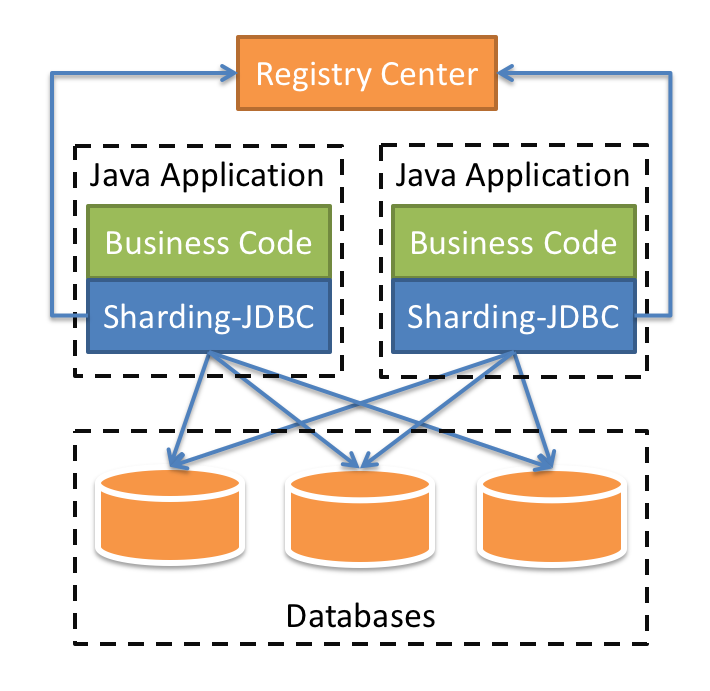
Sharding-JDBC水平分表
1. 导入pom依赖<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.20</version></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.0.0-RC1</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.0.5</version></dependency>
创建course_db数据库,并创建course_1,course_2两张表,建表SQL如上
创建实体类,以及Mapper
// 实体类@Datapublic class Course {private Long cid;private String cname;private Long userId;private String cStatus;}//Mapper@Repositorypublic interface CourseMapper extends BaseMapper<Course> {}
4. 配置SpringBoot
```
shardingjdbc 分片策略
配置数据源,给数据源起名称
spring.shardingsphere.datasource.names=m1
一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
配置数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/sharding-sphere?serverTimezone=GMT%2B8 spring.shardingsphere.datasource.m1.username=root spring.shardingsphere.datasource.m1.password=123456
指定 course 表分布情况,配置表在哪个数据库里面,表名称都是什么 m1.course_1 , m1.course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course_$->{1..2}
指定 course 表里面主键 cid
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
指定分片策略 约定 cid 值偶数添加到 course_1 表,如果 cid 是奇数添加到 course_2 表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid%2+1}
打开sql打印功能
spring.shardingsphere.props.sql.show=true
<a name="tMXyQ"></a>## 5. 编写测试用例```java@Testpublic void addCourse() {for (int i = 1; i <= 10; i++) {Course course = new Course();course.setCname("java" + i);course.setUserId(100L);course.setCStatus("Normal" + i);courseMapper.insert(course);}}@Testpublic void findCourse() {QueryWrapper<Course> wrapper = new QueryWrapper<>();wrapper.eq("cid", 474163991510253568L);Course course = courseMapper.selectOne(wrapper);System.out.println(course);}
- 测试结果
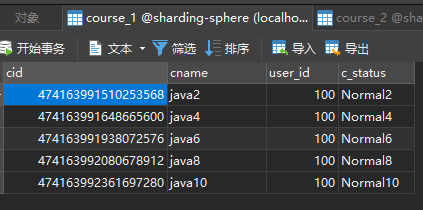
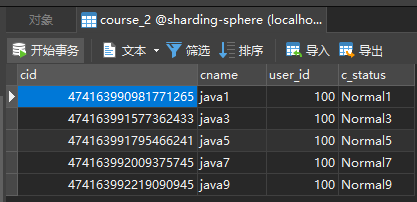
Sharding-JDBC实现水平分库
1. 创建两个数据库,分别为edu_db_1,edu_db_2,分别执行上述的db.sql文件,创建相应的表
2. 修改配置文件,设置水平分库的策略规则 ```水平分库配置文件
shardingjdbc 分片策略
配置数据源,给数据源起名称
水平分库,配置两个datasource
spring.shardingsphere.datasource.names=m1,m2一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true配置第一个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/edu_db_1?serverTimezone=GMT%2B8 spring.shardingsphere.datasource.m1.username=root spring.shardingsphere.datasource.m1.password=123456配置第二个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.m2.url=jdbc:mysql://localhost:3306/edu_db_2?serverTimezone=GMT%2B8 spring.shardingsphere.datasource.m2.username=root spring.shardingsphere.datasource.m2.password=123456指定 course 表分布情况,配置表在哪个数据库里面,表名称都是什么 m1.course_1 , m1.course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{1..2}.course_$->{1..2}指定 course 表里面主键 cid
spring.shardingsphere.sharding.tables.course.key-generator.column=cid生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE指定表分片策略 约定 cid 值偶数添加到 course_1 表,如果 cid 是奇数添加到 course_2 表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid%2+1}
指定数据库分片策略 约定 user_id 是偶数添加 m1 ,是 奇数添加 m2
spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=user_id spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
打开sql打印功能
spring.shardingsphere.props.sql.show=true
主要修改内容为:
spring.shardingsphere.datasource.names=m1,m2
添加第二个数据源
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.m2.url=jdbc:mysql://localhost:3306/edu_db_2?serverTimezone=GMT%2B8 spring.shardingsphere.datasource.m2.username=root spring.shardingsphere.datasource.m2.password=123456
修改course表的路由规则
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{1..2}.course_$->{1..2}
指定数据库分片策略 约定 user_id 是偶数添加 m1 ,是 奇数添加 m2
spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=user_id spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
<a name="qtIUA"></a>## 3.编写测试用例测试水平分库情况```javapublic void addCourseDb() {for (int i = 0; i < 20; i++) {Course course = new Course();course.setCname("javaDemo1");course.setUserId((long)(i + 1));course.setCStatus("Normal1");courseMapper.insert(course);}}@Testpublic void findCourseDb() {QueryWrapper<Course> objectQueryWrapper = new QueryWrapper<>();objectQueryWrapper.eq("user_id", 111L);objectQueryWrapper.eq("cid", 474167742677647361L);Course course = courseMapper.selectOne(objectQueryWrapper);System.out.println(course);}
Sharding-JDBC实现垂直分库
1. 创建数据库和表(创建user_db数据库和t_user表)
2. 修改配置文件,设置水平分库的策略规则
# 垂直分库配置文件# shardingjdbc 分片策略# 配置数据源,给数据源起名称# 水平分库,配置两个datasourcespring.shardingsphere.datasource.names=m1,m2,m0# 一个实体类对应两张表,覆盖spring.main.allow-bean-definition-overriding=true# 配置第一个数据源具体内容,包含连接池,驱动,地址,用户名和密码spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/edu_db_1?serverTimezone=GMT%2B8spring.shardingsphere.datasource.m1.username=rootspring.shardingsphere.datasource.m1.password=123456# 配置第二个数据源具体内容,包含连接池,驱动,地址,用户名和密码spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.m2.url=jdbc:mysql://localhost:3306/edu_db_2?serverTimezone=GMT%2B8spring.shardingsphere.datasource.m2.username=rootspring.shardingsphere.datasource.m2.password=123456# 配置第三个数据源具体内容,包含连接池,驱动,地址,用户名和密码spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/user_db?serverTimezone=GMT%2B8spring.shardingsphere.datasource.m0.username=rootspring.shardingsphere.datasource.m0.password=123456# 配置 user_db 数据库里面 t_user 专库专表spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=m$->{0}.t_user# 指定user表的主键user_idspring.shardingsphere.sharding.tables.t_user.key-generator.column=user_idspring.shardingsphere.sharding.tables.t_user.key-generator.type=SNOWFLAKE# 指定user表的分库分表策略spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column=user_idspring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression=t_user# 指定 course 表分布情况,配置表在哪个数据库里面,表名称都是什么 m1.course_1 , m1.course_2spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{1..2}.course_$->{1..2}# 指定 course 表里面主键 cidspring.shardingsphere.sharding.tables.course.key-generator.column=cid# 生成策略 SNOWFLAKEspring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE# 指定表分片策略 约定 cid 值偶数添加到 course_1 表,如果 cid 是奇数添加到 course_2 表spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cidspring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid%2+1}# 指定数据库分片策略 约定 user_id 是偶数添加 m1 ,是 奇数添加 m2spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=user_idspring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}#打开sql打印功能spring.shardingsphere.props.sql.show=true
主要修改如下的配置
spring.shardingsphere.datasource.names=m1,m2,m0# 配置第三个数据源具体内容,包含连接池,驱动,地址,用户名和密码spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/user_db?serverTimezone=GMT%2B8spring.shardingsphere.datasource.m0.username=rootspring.shardingsphere.datasource.m0.password=123456# 配置 user_db 数据库里面 t_user 专库专表spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=m$->{0}.t_user# 指定user表的主键user_idspring.shardingsphere.sharding.tables.t_user.key-generator.column=user_idspring.shardingsphere.sharding.tables.t_user.key-generator.type=SNOWFLAKE# 指定user表的分库分表策略spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column=user_idspring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression=t_user
- 测试用例
@Testpublic void addUserDb(){User user = new User();user.setUsername("lucy");user.setUstatus("a");userMapper.insert(user);}
Sharding-JDBC操作公共表
- 何为公共表
l 存储固定数据的表,数据很少发生变化,查询时候经常进行关联
l 在每个数据库中创建出相同结构的表
2. 在每个库中添加相同的表结构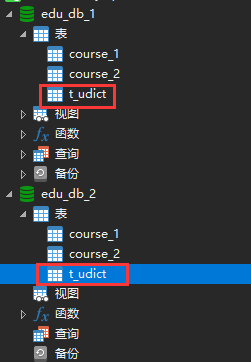
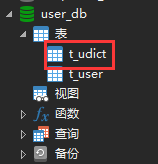
3. 添加配置文件信息# 配置公共表的信息spring.shardingsphere.sharding.broadcast-tables=t_udictspring.shardingsphere.sharding.tables.t_udict.key-generator.column=dict_idspring.shardingsphere.sharding.tables.t_udict.key-generator.type=SNOWFLAKE
- 编写测试代码
```java
// 实体类
@Data
@TableName(value = “t_udict”)
public class Udict {
private Long dictId;
private String ustatus;
private String uvalue;
}
// Mapper
@Repository
public interface UdictMapper extends BaseMapper
{
}
测试crud
// insert
@Test
public void addDict() {
Udict udict = new Udict();
udict.setUstatus(“a”);
udict.setUvalue(“已启用”);
udictMapper.insert(udict);
}
// delete
@Test
public void deleteDict() {
QueryWrapper
<a name="YqMze"></a>## Shareding-JDBC实现读写分离1. 读写分离的概念<br />为了保证数据库的稳定性,数据库基本都采用双机热备的功能,也就是,一台数据库服务器,对外提供增删改的业务功能,另一台数据库服务器,对外提供读操作的业务功能。<br />原理,让主库Master处理事务性强(增,删,改)操作,让从库(slave)处理Select(查)的操作<br />读写分离的原理<br />主从复制:当主库有写入的操作(insert/update/delete),将会写入binlog,从库通过binlog获取主库的操作,进行同步<br />读写分离:insert/update/delete主库,select从库<br />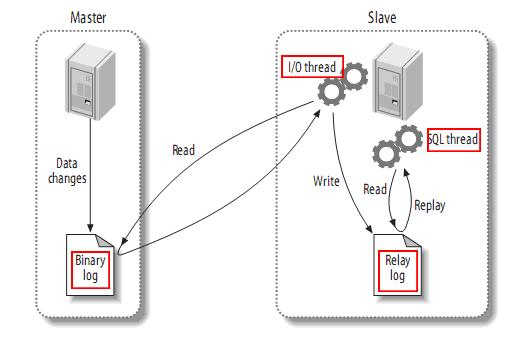<br />Sharding-JDBC通过SQL语句的语义解析,实现读写分离的过程,不会进行数据的同步。<br />2.MySQL配置读写分离<br />详见:[MySQL 主从复制搭建](https://www.yuque.com/zhanyifan-rkxpe/grf7g5/hzu3ne)<br />3.配置读写分离策略
配置主从复制
添加s0 datasource
spring.shardingsphere.datasource.names=m1,m2,m0,s0
user_db的从服务器
spring.shardingsphere.datasource.s0.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.s0.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.s0.url=jdbc:mysql://192.168.137.131:3306/user_db?serverTimezone=GMT%2B8 spring.shardingsphere.datasource.s0.username=root spring.shardingsphere.datasource.s0.password=123456 spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0 spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names=s0 spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=ds0.t_user
4. 编写测试用例测试读写分离```java@Testpublic void addUser() {User user = new User();user.setUsername("read write");user.setUstatus("a");userMapper.insert(user);}@Testpublic void findUser() {QueryWrapper<User> wrapper = new QueryWrapper<>();// 设置 userid 值wrapper.eq("user_id",465508031619137537L);User user = userMapper.selectOne(wrapper);System.out.println(user);}
- 测试结果
添加:往m0库中进行添加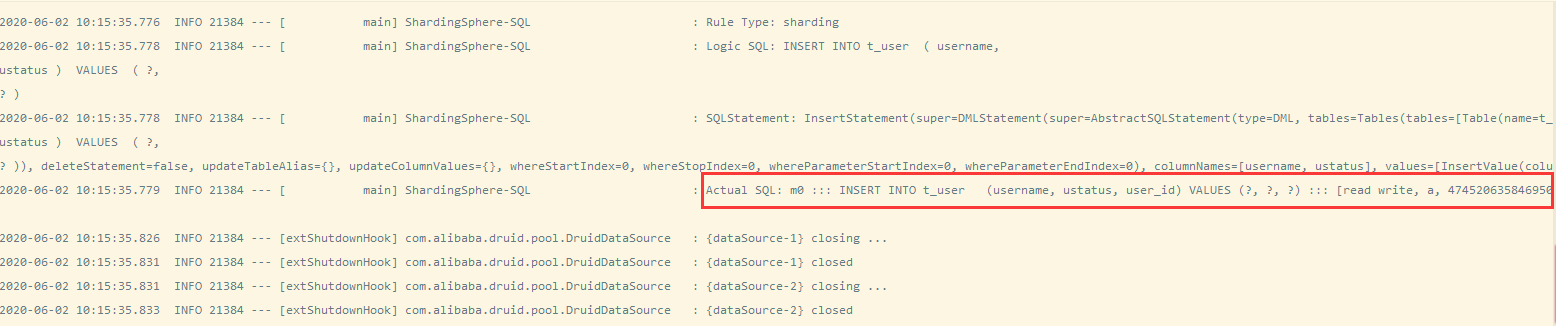
查询:往s0库中进行查询,从而达到一个读写分离的效果。
最终结果,符合上述配置文件中描述的,写请求往m0,读请求往s0.

若有收获,就点个赞吧
0 人点赞
