一、原理解读
1、MySQL主从复制原理
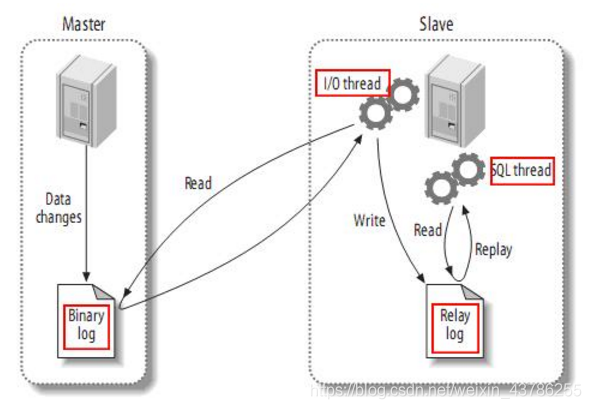
首先了解一下mysql主备复制原理:
(1)master主库将改变记录,发送到二进制文件(binary log)中
(2)slave从库向mysql Master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log)
(3)slave从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库
2、canal原理分析
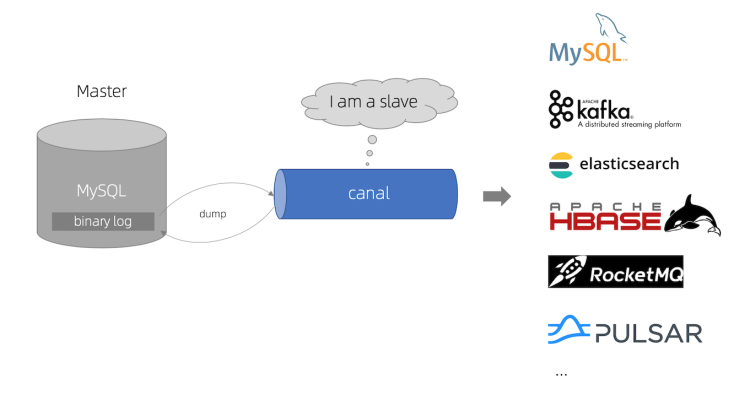
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
- 把MySQL的binlog设置为row模式以后,可以获取到执行的每一个Insert/Update/Delete的脚本,以及修改前和修改后的数据,基于这个特性,Canal就能高效的获取到MySQL数据的变更。
- 目前canal只能支持row模式的增量订阅(statement只有sql,没有数据,所以无法获取原始的变更日志)
二、Canal 流程分析
1、Canal Client 解析
(1)、循环拉取数据
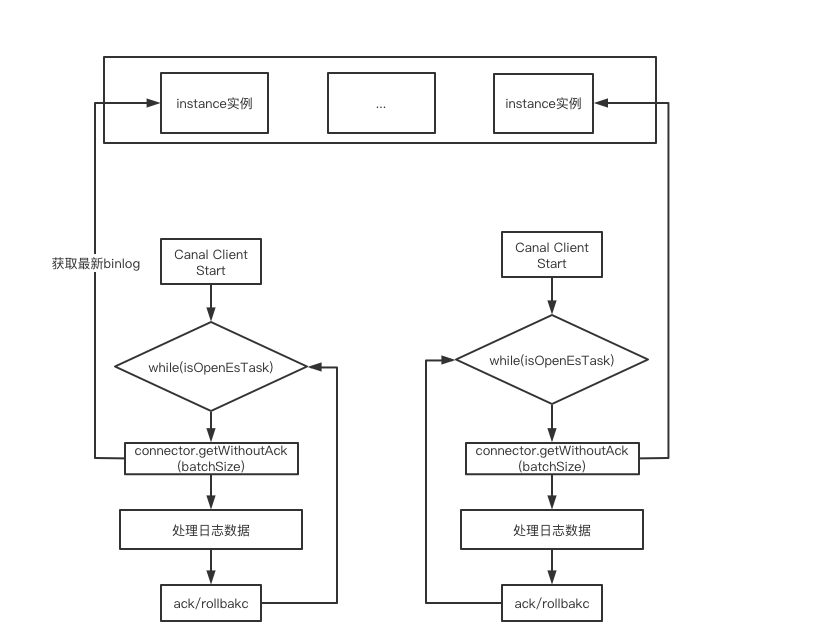
Canal Client启动后主动发起拉取请求,Canal Server启动后,如果没有canal client,那么canal server 不会去myql拉取binlog。Canal server接收到对应FETCH请求后才会模拟MySQL Slave去主节点拉取BinLog。通常Canal客户段是一个死循环,这样客户端一直调用get方法,服务端一直拉取binlog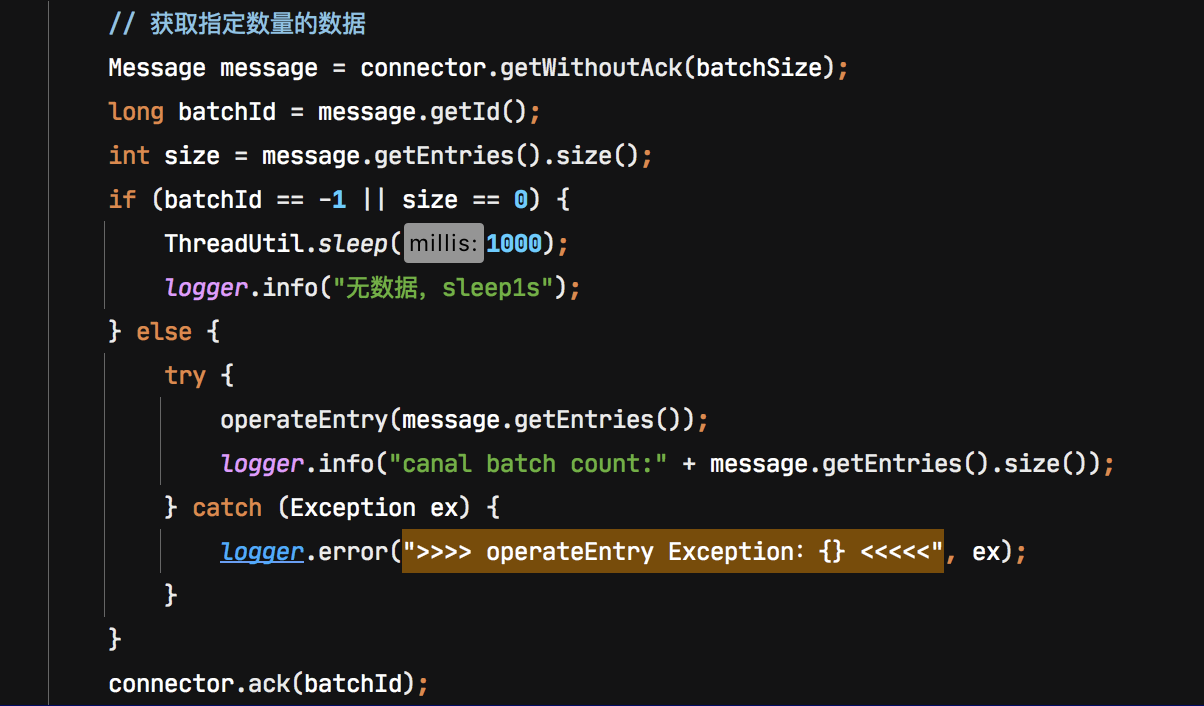
(2)、数据处理
等这批数据处理完后,执行ack/rollback操作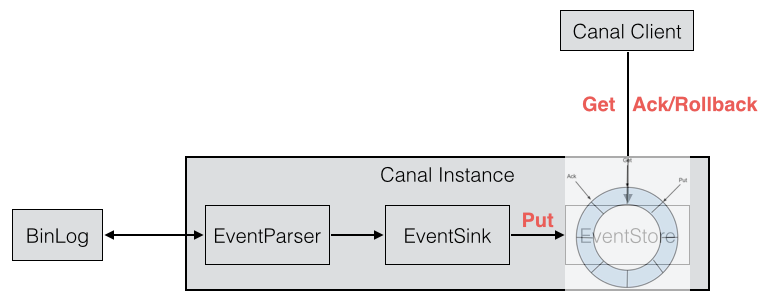
2、Canal Server 解析
(1)、Canal Server架构
canal server是canal的基本部署实例,在实现上一个canal server 部署实例由多个binlog数据通道实例组成的。
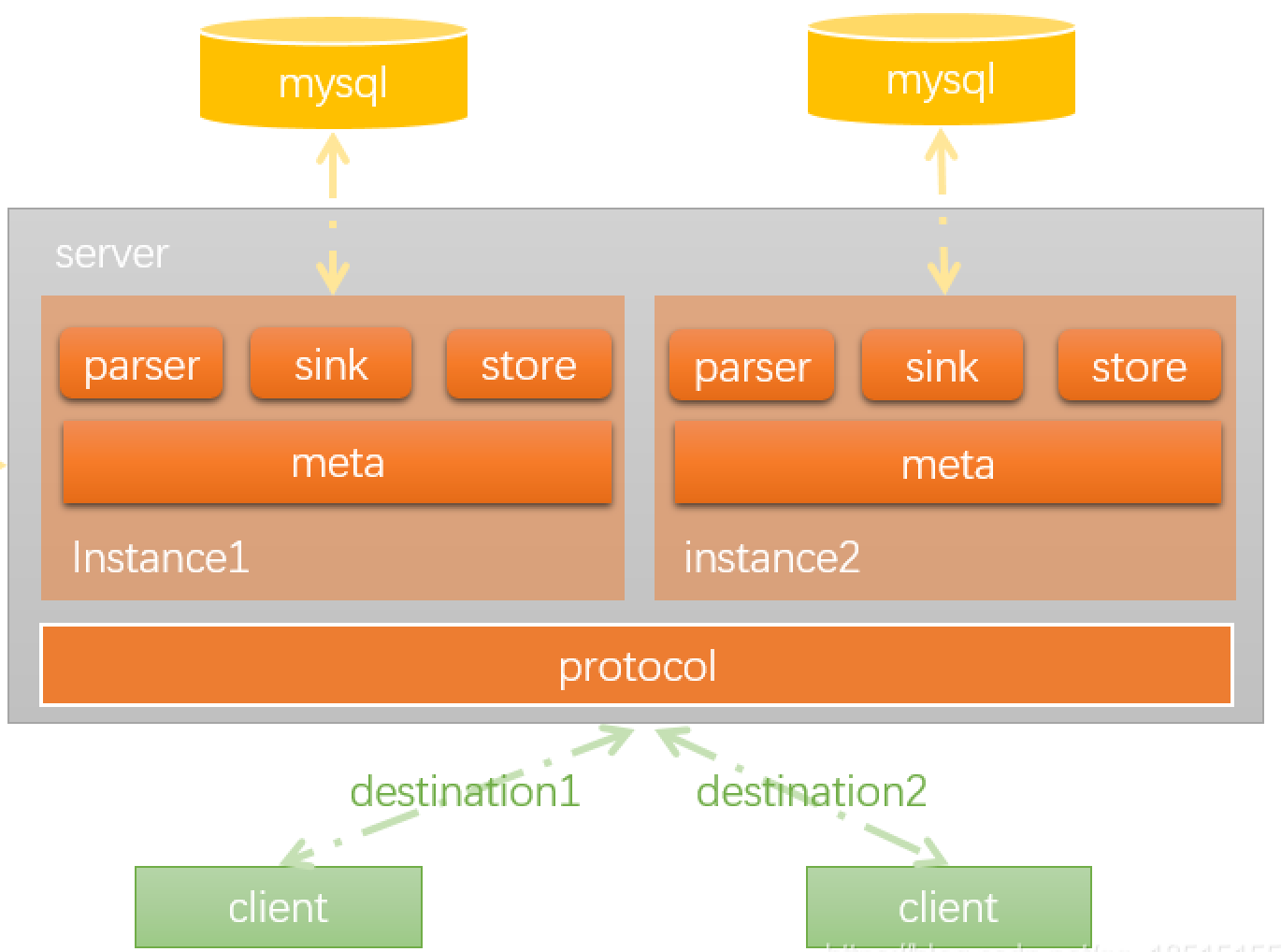
说明:
- protocol 模块 client和server模块之间的通信协议
- canal server就是一个jvm运行实例,
- server代表一个Canal运行实例,对应于一个jvm instance对应于一个数据队列(1个server对应1..n个instance)
- 因为在 TCP 模式下,一个 instance 只能有一个 canal client 订阅,即使同时有多个 canal client 订阅相同的 instance, 也只会有一个 canal client 成功获取 binlog, 所以 canal server 写死 clientId = 1001. 也正是因为一个 instance 只有一个 canal client, 所以 canal server 将 binlog 位点信息维护在了 instance 级别,即 conf/content/meta.dat 文件中
- 在 TCP 模式下 canal server 主要提供了两个功能
(1) 维护 mysql binlog position 信息,目的是作为 dump 的请求参数,这也是 canal server 唯一保存的数据
(2) 对客户端提供接口以查询 binlog
(2)、instance模块:
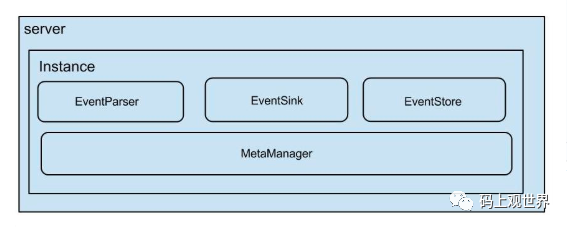
- eventParser
数据源接入,模拟slave协议和master进行交互,协议解析,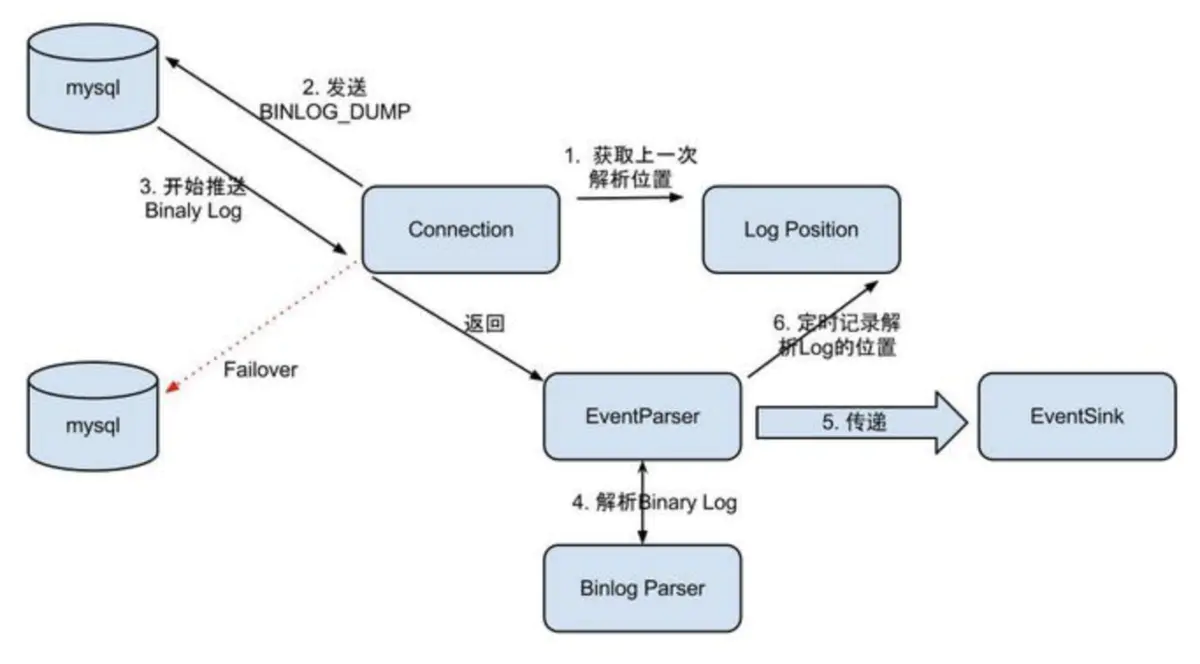
对应的解析过程为:
1: Connection获取上一次解析成功的位置 (如果第一次启动,则获取初始指定的位置或者是当前数据库的binlog位点)
2: Connection建立链接,发送BINLOG_DUMP指令
3: Mysql开始推送Binaly Log
4: 接收到的Binaly Log的通过Binlog parser进行协议解析,补充一些特定信息
5: 传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功
6: 存储成功后,定时记录Binaly Log位置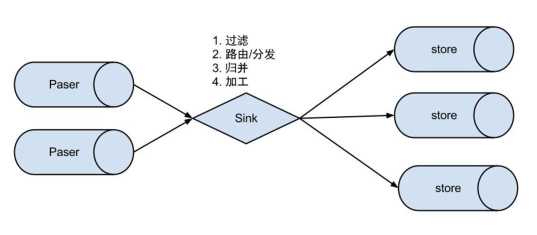 [
[
](https://blog.csdn.net/zhou12314/article/details/88916643)
- eventSink
Parser和Store链接器,进行数据过滤,加工,分发的工作
具体可分为:
数据过滤:支持通配符的过滤模式,表名、字段内容等
数据路由/分发:解决1:n (1个parser对应多个store的模式)
数据归并:解决n:1 (多个parser对应1个store)
数据加工:在进入store之前进行额外的处理,比如join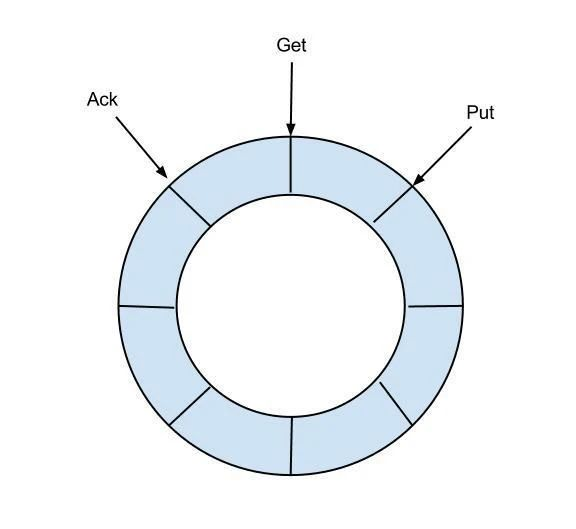 [
[
](https://blog.csdn.net/zhou12314/article/details/88916643)
- eventStore(数据存储)
put:Sink模块进行数据存储的最后一次写入位置(同步写入数据的cursor)
get:数据订阅获取的最后一次提取位置(同步获取的数据的cursor)
ack:数据消费成功的最后一次消费位置
metaManager(增量订阅&消费信息管理器)
主要用于保存Parser组件、CanalServer(即本文中提到的NettyServer)、Canal Instances的meta数据,其中Parser组件涉及到的binlog position、CanalServer与消费者交互时ACK的Cursor信息、instance的集群运行时信息等。具体元数据信息
订阅信息,即是否有消费着订阅binlog.每个Client消费游标信息,即消费进度每个Client消费批次信息,根据批次获取此批次的开始游标,结束游标#将元数据存存储到zk中ZooKeeperMetaManager#将元数据存储到内存中MemoryMetaManager#组合memory + zookeeper的使用模式MixedMetaManager:#基于定时刷新的策略的mixed实现PeriodMixedMetaManager#先写内存,然后定时刷新数据到FileFileMixedMetaManager:
(3)、Binlog日志解析
binlog数据通道实例由Parser、Sink和store模块组成,完成binlog的解析、过滤和存储一整条链路功能。跟binlog数据通道的关系为: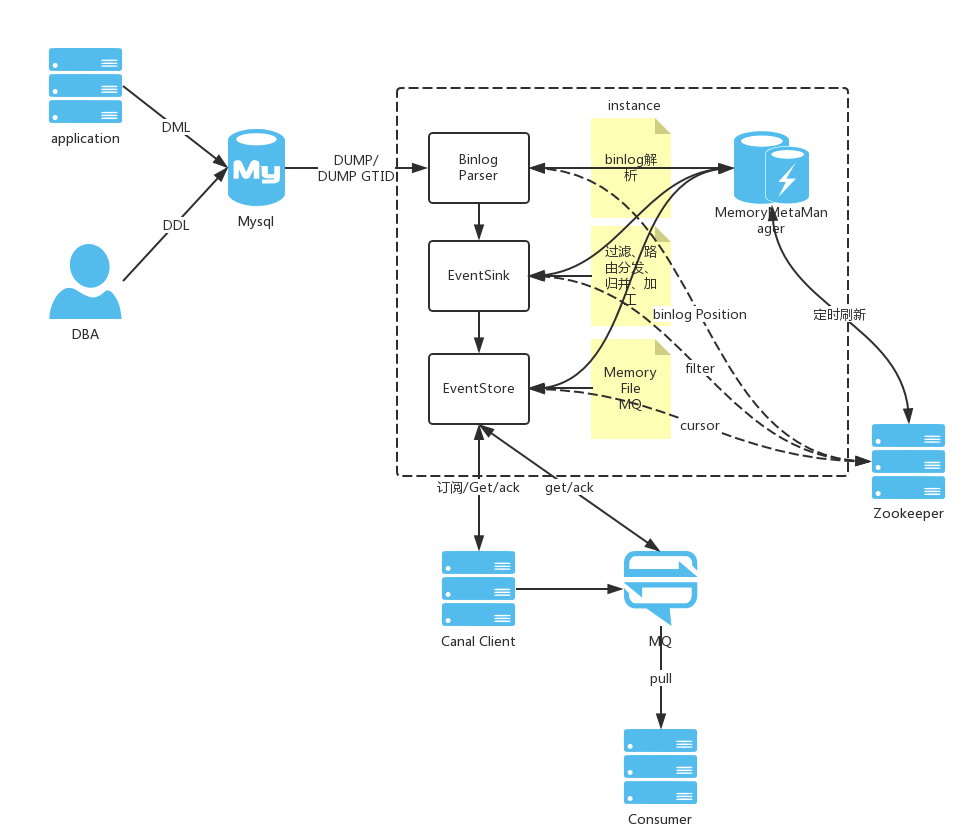
Canal Client 与Canal Server之间是C/S模式的通信。 canal server服务端基于Netty tcp协议的,canal client服务基于NIO开发
三、Canal Server工作流程和BinLog寻找过程分析
1、Canal工作流程分析
(1)、启动
启动入口类com.alibaba.otter.canal.deployer.CanalLauncher ,在这里直接运行 main 方法即可运行 canal ,和在 /canal/bin/startup.sh 中效果一样。
(2)、确定 binlog first position
(3)、将 first position 赋值给 last position 保存在内存中
(4)、将 schema 缓存到 conf/content/h2.mv.db 文件中
(5)、接收canal client的 查询请求。 canal client启动,connect()—->connector.subscribe—>connector.getWithoutAck()
(6)、canal server 在收到 canal client 查询请求之后,以内存中的 last position 作为参数向 mysql server 发送 dump 请求
(7) 如果存在比 last position 更新的 binlog, canal server 会收到 mysql server 的返回数据,然后将其转换为 Message 数据结构返回给 canal client
(8)、canal client ack。canal server 在收到 canal client 确认请求之后,更新内存中的 last position 并同步保存到 conf/content/meta.dat 文件中,在 logs/content/meta.log 文件中打印日志
2、BinLog寻找过程分析
Binlog的寻找过程可能场景:
- instance第一次启动
- 发生数据库主备切换
- canal server HA情况下的切换
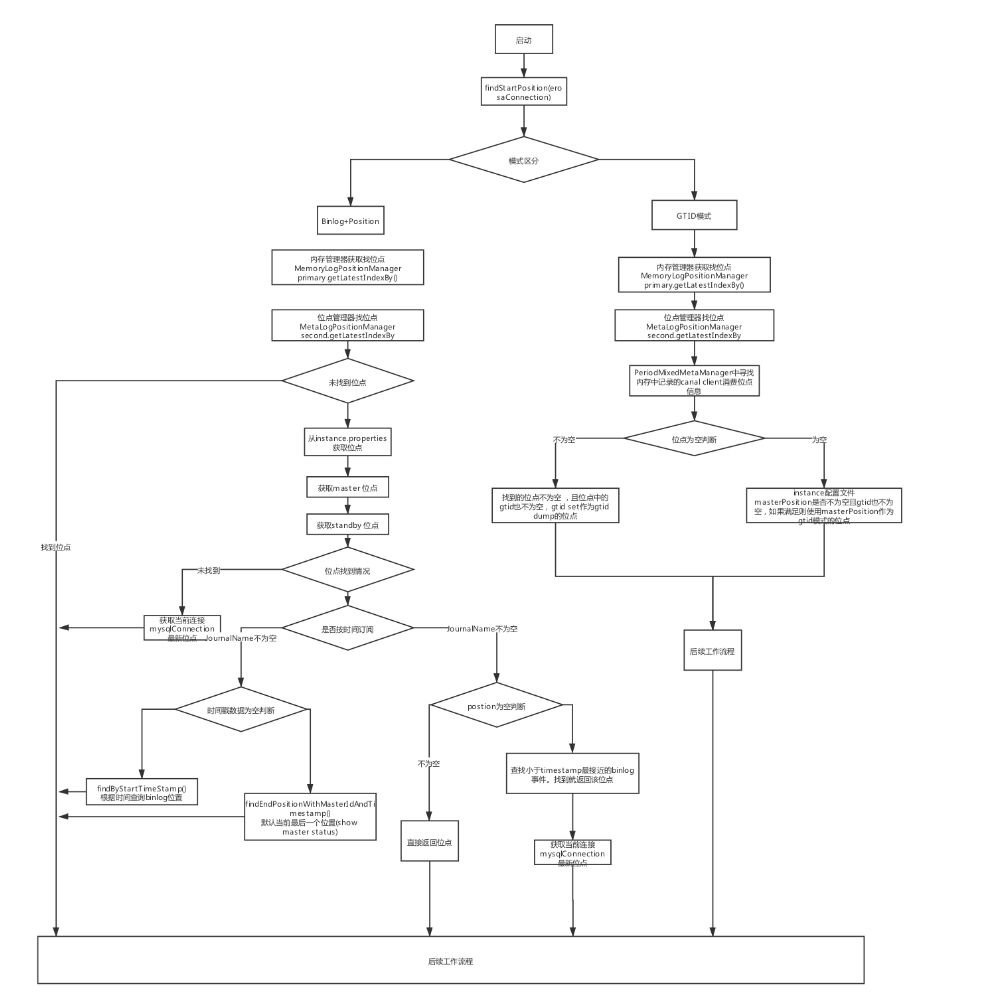
GTID位点的逻辑为
先到primary中寻找canal server中dump下来的binlog event最新位点(内存中 ),找不到就到secondary中寻找canal client成功消费位点。如果找到了就判断位点的gtid是否为空,如果为空则说明以前不是gtid模式,则不支持gtid模式,继续步骤二。如果上述找不到位点,则判断masterPosition是否不为空,且gtid也不为空,如果满足则使用masterPosition作为gtid模式的位点。
Binlog+Position位点
如果binlog filename+position存在,则直接作为dump位点,否则根据timestamp确定。如果最终根据binlog filename,position,timestamp确定不了位点,则使用当前mysqlConnection连接的数据库的binlog最后一个位置作为dump位点
四、高可用
1、Canal Server HA高可用
canal server负责本实例上的所有数据通道的可用性,采用pull的消费模型供canal客户端读取消息。在部署上面,可以单独部署,在生产环境上,建议采用HA高可用部署方案: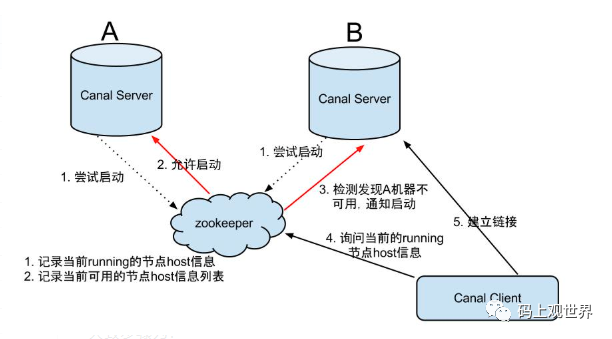
大致步骤为:
- canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
- 创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态
- 一旦zookeeper发现canal server A创建的节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance.
- canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect.
Canal Client的方式和Canal server方式类似,也是利用Zookeeper的抢占EPHEMERAL节点的方式进行控制。
Canal 在Zookeeper的存储结构如下: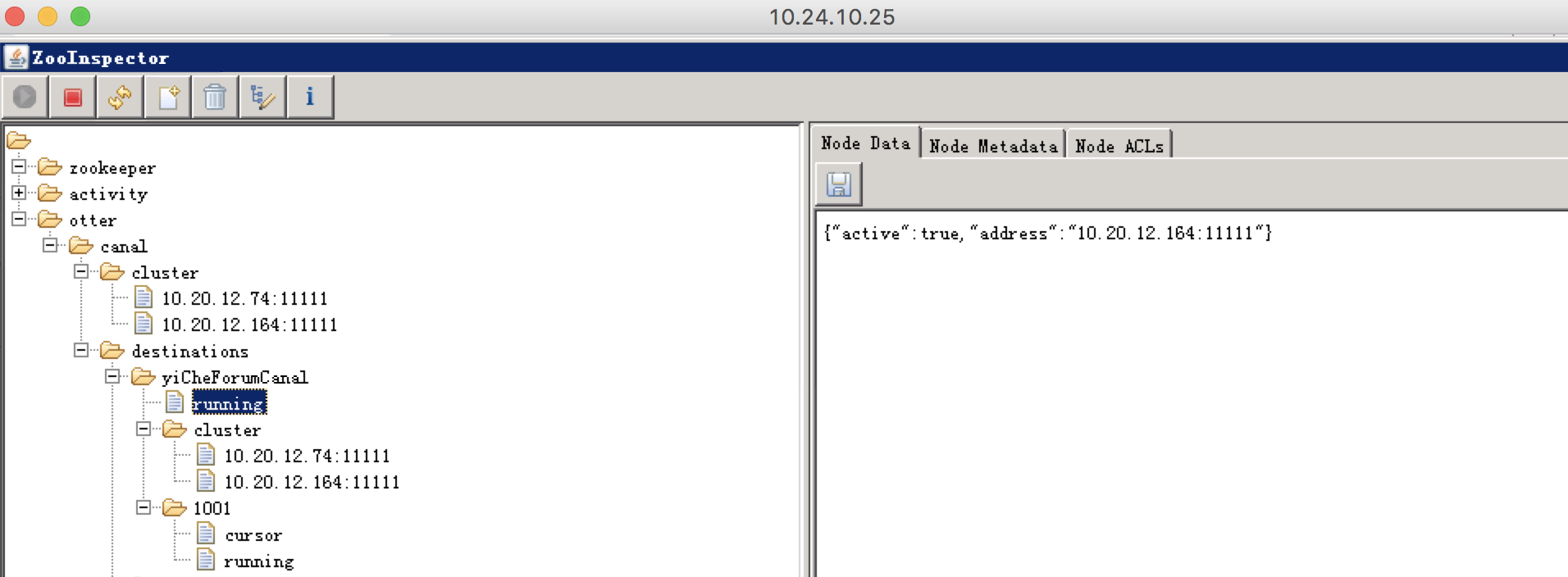
yiCheForumCanal #实例子名称
running #当前正在运行的Canal Server服务器
cluster #canal server列表
1001 #canal client 信息
cursor #当前消费的binlog位点
running #当前正在运行的canal client服务器
2、BinLog + Postion 和GTID的比较
如果MySQL使用VIP是去HA,当MYSQL发生主从切换的时候,canal会可能会报错,因为和备机上的binlog和position对不上。这就需要开启数据库GTID模式。如果是基于GTID去拉binlog,应该就能解决这个问题。
instance.properties修改配置 canal.instance.gtidon=true
修改配置后,主从切换时,failover切换重试后,canal server重连到新的Master,以GTID去拉取binlog,继续数据同步
3、Mysql HA主从切换时 Canal Server failover
五、使用分析(避坑)
1、高可用部署时 使用default.xml
(1)、memory-instance.xml
所有的组件(parser , sink , store)都选择了内存版模式,记录位点的都选择了memory模式,重启后又会回到初始位点进行解析
特点:速度最快,依赖最少(不需要zookeeper)
场景:一般应用在quickstart,或者是出现问题后,进行数据分析的场景,不应该将其应用于生产环境
(2)、file-instance.xml
所有的组件(parser,sink,store)都选择了基于file持久化模式,注意,不支持HA机制。
特点:支持单机持久化,
场景: 生产环境,无HA需求,简单可用
(3)、default-instance.xml
store选择了内存模式,其余的parser/sink依赖的位点管理选择了持久化模式,目前持久化的方式主要是写入zookeeper,保证数据集群共享. (需注意,下载解压后,默认使用的是file-instance.xml ,如果使用HA需调整为instance.xml)
特点:支持HA
场景:生产环境,集群化部署.
(4)、group-instance.xml
主要针对需要进行多库合并时,可以将多个物理instance合并为一个逻辑instance,提供客户端访问。
2、canal 宕机后 cannot find start position
原因:修改了配置或者Canal宕机时间过长,导致meta.dat中保存的binlog位点信息和数据库的位点不一致,导致canal抓取不到数据库的binlog数据
解决: 删除meta.dat文件,再重启Canal Server。此时已经丢失了一切的数据,需要进行手动同步数据
3、tsdb启用后,新增字段导致的异常错误
错误: Caused by: com.alibaba.otter.canal.parse.exception.CanalParseException: column size is not match for table:{table_name}
canal.instance.tsdb.enable = true #instance.xml配置中默认开启tsdb功能
默认开启了tsdb功能,也就会通过h2数据库缓存解析的表结构,但在实际情况下,如果上游变更了表结构,h2数据库对应的缓存不会更新,网上建议可以关闭tsdb功能,设置为false
4、GTID模式下Canal Server 主从切换

若有收获,就点个赞吧
0 人点赞
