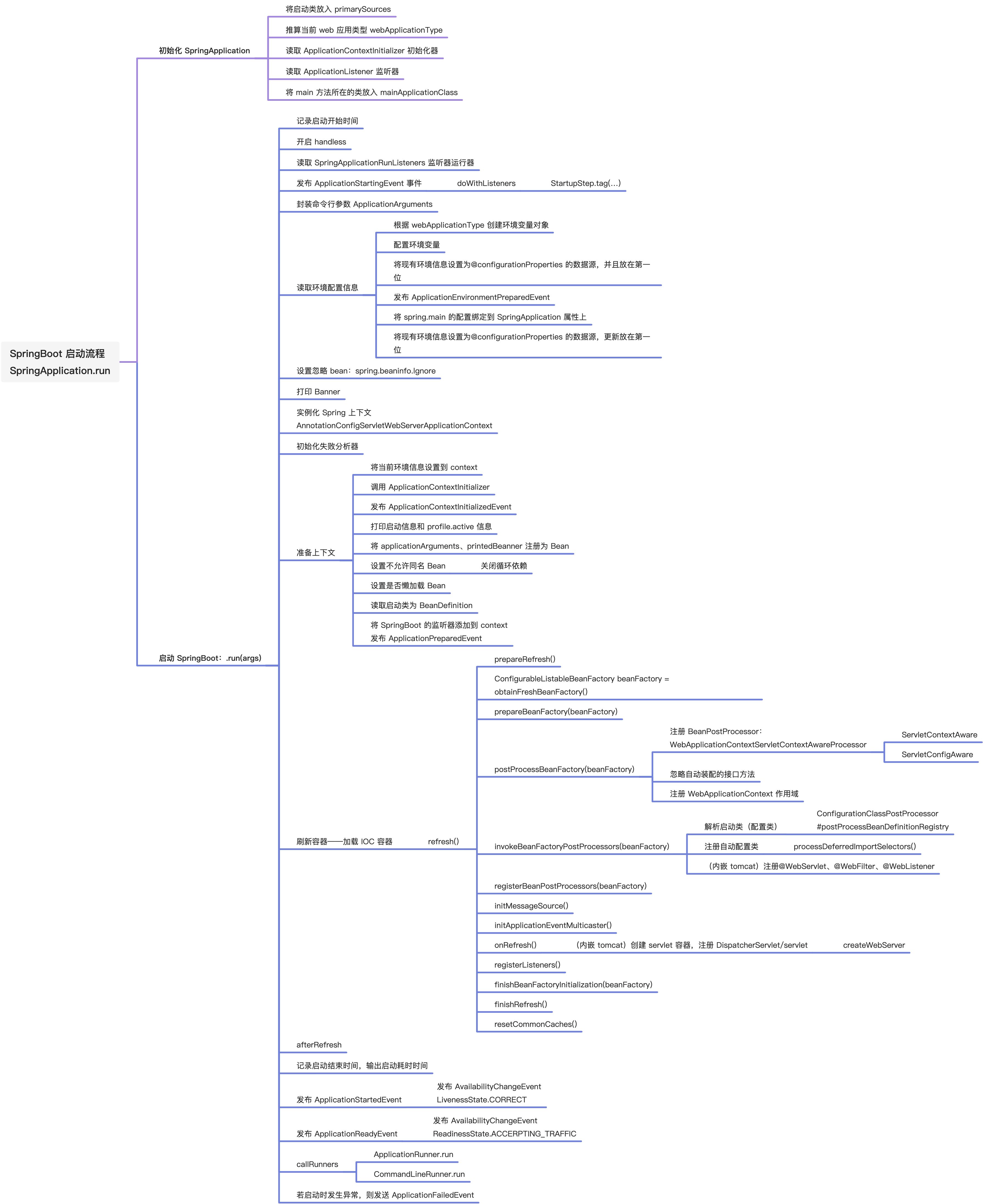
Spring Boot 启动原理思维导图
SpringBoot 如何通过 jar 启动?
使用 -jar 参数时,后面的参数是 jar 文件的名字;该 jar 文件中包含的是 class 和资源文件;在 mainfest 文件中有 Main-Class 的定义;Main-Class 指定了整个应用的启动类;
Start-Class 指定的是代码中的唯一类,也是真正的应用启动类
jar 包目录结构:
spring-boot-learn-0.0.1-SNAPSHOT├── META-INF│ └── MANIFEST.MF├── BOOT-INF│ ├── classes│ │ └── 应用程序类│ └── lib│ └── 第三方依赖jar└── org└── springframework└── boot└── loader└── springboot启动程序
META-INF 内容:
Manifest-Version: 1.0Implementation-Title: spring-learnImplementation-Version: 0.0.1-SNAPSHOTStart-Class: com.zrk.ApplicationSpring-Boot-Classes: BOOT-INF/classes/Spring-Boot-Lib: BOOT-INF/lib/Build-Jdk-Spec: 1.8Spring-Boot-Version: 2.1.5.RELEASECreated-By: Maven Archiver 3.4.0Main-Class: org.springframework.boot.loader.JarLauncher
Archive 概念:
- archive 即归档文件,在 linux 下比较常见
- 通常就是一个 tar/zip 格式的压缩包
- jar 是 zip 格式
SpringBoot 抽象了 Archive 的概念;一个 Archive 可以是 jar,可以是一个文件目录,可以抽象为统一访问资源的逻辑层;源码如下:
public interface Archive extends Iterable<Archive.Entry> {// 获取该归档的urlURL getUrl() throws MalformedURLException;// 获取jar!/META-INF/MANIFEST.MF或[ArchiveDir]/META-INF/MANIFEST.MFManifest getManifest() throws IOException;// 获取jar!/BOOT-INF/lib/*.jar或[ArchiveDir]/BOOT-INF/lib/*.jarList<Archive> getNestedArchives(EntryFilter filter) throws IOException;}
SpringBoot jar 应用启动流程解析
- SpringBoot 应用打包后,生成一个 Fat jar,包含了应用依赖的 jar 包和 SpringBoot loader 相关的类
- Fat jar 的启动 Main 函数是 JarLauncher,它负责创建一个 LaunchedURLClassLoader 来加载/lib 下面的 jar,并以一个新线程启动应用的 Main 函数
那么,ClassLoader 是如何读取到 Resource,又有哪些能力? 查找资源和读取资源的能力;对应 api
public URL findResource(String name)public InputStream getResourceAsStream(String name)
SpringBoot 构造 LaunchedURLClassLoader 时,传递了一个 URL[] 数组,数组里是 lib 目录下的 jar 的 URL;对于一个 URL,JDK 或者 ClassLoader 读取其内容流程如下:
- LaunchedURLClassLoader.loadClass
- URL.getContent()
- URL.openConnection()
- Handler.openConnection(URL)
最终调用的是 JarURLConnection 的 getInputStream() 函数:
//org.springframework.boot.loader.jar.JarURLConnection@Overridepublic InputStream getInputStream() throws IOException {connect();if (this.jarEntryName.isEmpty()) {throw new IOException("no entry name specified");}return this.jarEntryData.getInputStream();}
从一个 URL,到最终读取到 URL 里的内容,整个过程是比较复杂的:
- SpringBoot 注册了一个 Handler 来处理”jar:”这种协议的 URL
- SpringBoot 扩展了 JarFile 和 JarURLConnection,内部处理 jar in jar 的情况
- 在处理多重 jar in jar 的 URL 时,SpringBoot 会循环处理,并缓存已经加载到的 JarFile
- 对于多重 jar in jar,实际上是解压到了临时目录来处理
- 在获取 URL 的 InputStream 时,最终获得到的是 JarFile 里的 JarEntryData
URLClassLoader 是如何 getResource 的呢?
URLClassLoader 在构造时,有 URL[] 数组参数,它内部会用这个数组来构造一个 URLClassPath:URLClassPath ucp = new URLClassPath(urls);在 URLClassPath 内部会为这些 urls 都构造一个 Loader,然后在 getResource 时会重这些 Loader 里一个个去尝试获取;若获取成功,则包装为一个 Resource:
Resource getResource(final String name, boolean check) {final URL url;try {url = new URL(base, ParseUtil.encodePath(name, false));} catch (MalformedURLException e) {throw new IllegalArgumentException("name");}final URLConnection uc;try {if (check) {URLClassPath.check(url);}uc = url.openConnection();InputStream in = uc.getInputStream();if (uc instanceof JarURLConnection) {/* Need to remember the jar file so it can be closed* in a hurry.*/JarURLConnection juc = (JarURLConnection)uc;jarfile = JarLoader.checkJar(juc.getJarFile());}} catch (Exception e) {return null;}return new Resource() {public String getName() { return name; }public URL getURL() { return url; }public URL getCodeSourceURL() { return base; }public InputStream getInputStream() throws IOException {return uc.getInputStream();}public int getContentLength() throws IOException {return uc.getContentLength();}};}JarURLConnection juc = (JarURLConnection)uc;

若有收获,就点个赞吧
0 人点赞
