笔记内容选自慕课网《大数据开发工程师》体系课
12.1 什么是Flink?
- Flink是一个开源的分布式,高性能,高可用,准确的流处理框架
- Flink支持流(Stream)处理和批(Batch)处理
- 对于flink而言,它是一个流处理框架,批处理只是流处理的一个极限特例而已
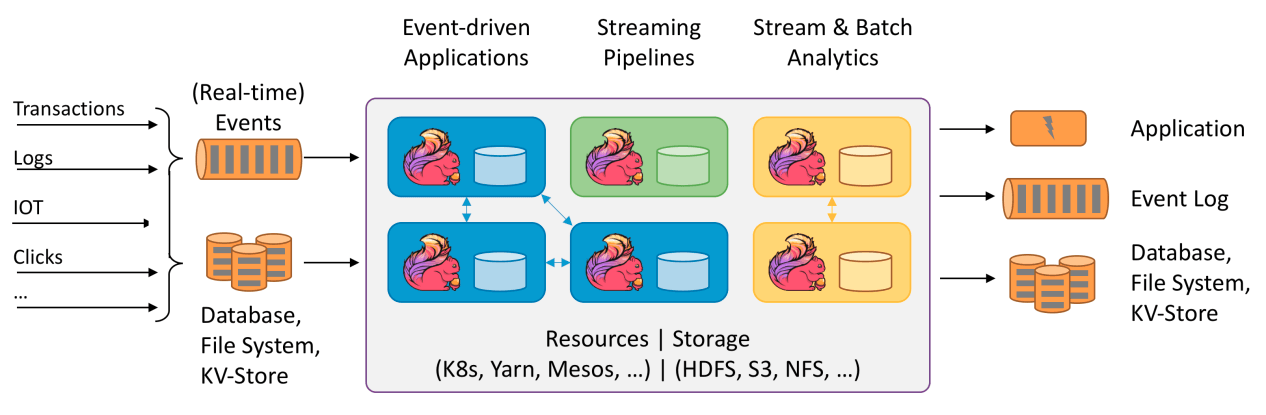
12.1.1 Flink流程图
- 左边是数据源
- 这些数据是实时产生的一些日志,或者是数据库、文件系统、kv存储系统中的数据
- 中间是Flink
- 负责对数据进行处理
- 右边是目的地
- Flink可以将计算好的数据输出到其它应用中,或者存储系统中
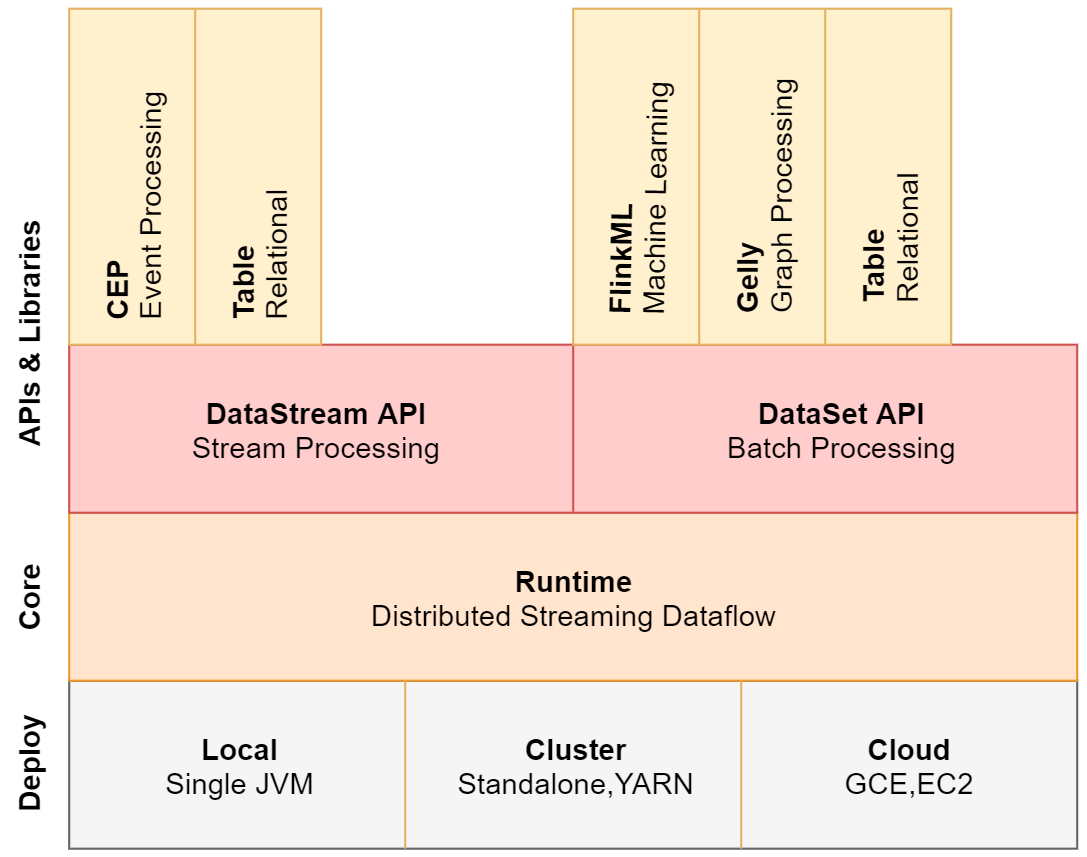
12.1.2 Flink架构图
- Deploy:部署层
- 支持local,和集群(standalone,yarn),也支持在云上部署
- Core:核心层
- flink的核心,分布式的流处理引擎
- Apis&Libraries:开发层
- 主要有两大块API,DataStram API和DataSet API,分别做流处理和批处理
- DataStram API
- 支持复杂事件处理
- 支持table操作
- 支持SQL操作
- DatasetAPI
- 支持flinkML机器学习
- 支持Gelly图计算
- 支持table操作
- 支持SQL操作
- Flink生态圈
- 实时计算
- 离线计算
- 机器学习
- 图计算
- Table计算
- SQL计算
- Flink和Spark有点像,但是底层计算引擎是有本质区别的
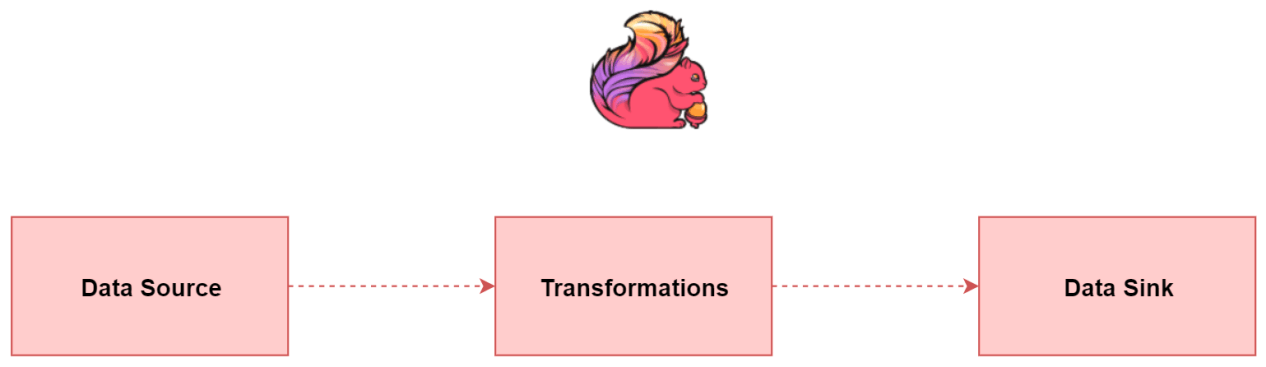
12.1.3 Flink三大核心组件
- Data Source
- 数据源(负责接收数据)
- Transformations
- 算子(负责对数据进行处理)
- Data Sink
- 输出组件(负责把计算好的数据输出到其它存储介质中)
12.1.4 Flink的流处理与批处理
- 在大数据处理领域,批处理和流处理一般被认为是两种不同的任务
- 一个大数据框架一般会被设计为 只能处理其中一种任务
- 不同的计算引擎处理不同的任务
- Storm只支持流处理任务
- MapReduce、Spark只支持批处理任务
- Spark Streaming支持流处理「特例」
- Spark Streaming 采用了一种 micro-batch 的架构
- 就是把输入的数据流切分成细粒度的batch,并为每一个batch提交一个批处理的Spark任务
- 所以Spark Streaming本质上执行的还是批处理任务
- 和Storm这种流式的数据处理方式是完全不同的
- Flink通过灵活的执行引擎,支持批处理和流处理
- 流处理系统与批处理系统最大的不同在于节点之间的数据传输方式
- 流处理系统,其节点间数据传输的标准模型是
- 当一条数据被处理完成后,序列化到缓存中,然 后立刻通过网络传输到下一个节点,由下一个节点继续处理
- 典型的一条一条实时处理
- 批处理系统,其节点间数据传输的标准模型是
- 当一条数据被处理完成后,序列化到缓存中, 并不会立刻通过网络传输到下一个节点
- 当缓存写满的时候,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点
- 这两种数据传输模式是两个极端
- 对应的是流处理系统对低延迟的要求和批处理系统对高吞吐量的要求
- 流处理系统,其节点间数据传输的标准模型是
- Flink的执行引擎采用了一种十分灵活的方式,从而支持了这两种数据传输模型
- Flink以固定的缓存块为单位进行网络数据传输,用户可以通过缓存块超时值指定缓存块的传输时机
- 如果缓存块的超时值为0,则Flink的数据传输方式类似前面所说的流处理系统的标准模型,此时系统可以获 得最低的处理延迟
- 如果缓存块的超时值为无限大,则Flink的数据传输方式类似前面所说的批处理系统的标准模型,此时系 统可以获得最高的吞吐量
- 这样就比较灵活了,其实底层还是流式计算模型,批处理只是一个极限特例而已
- Flink以固定的缓存块为单位进行网络数据传输,用户可以通过缓存块超时值指定缓存块的传输时机
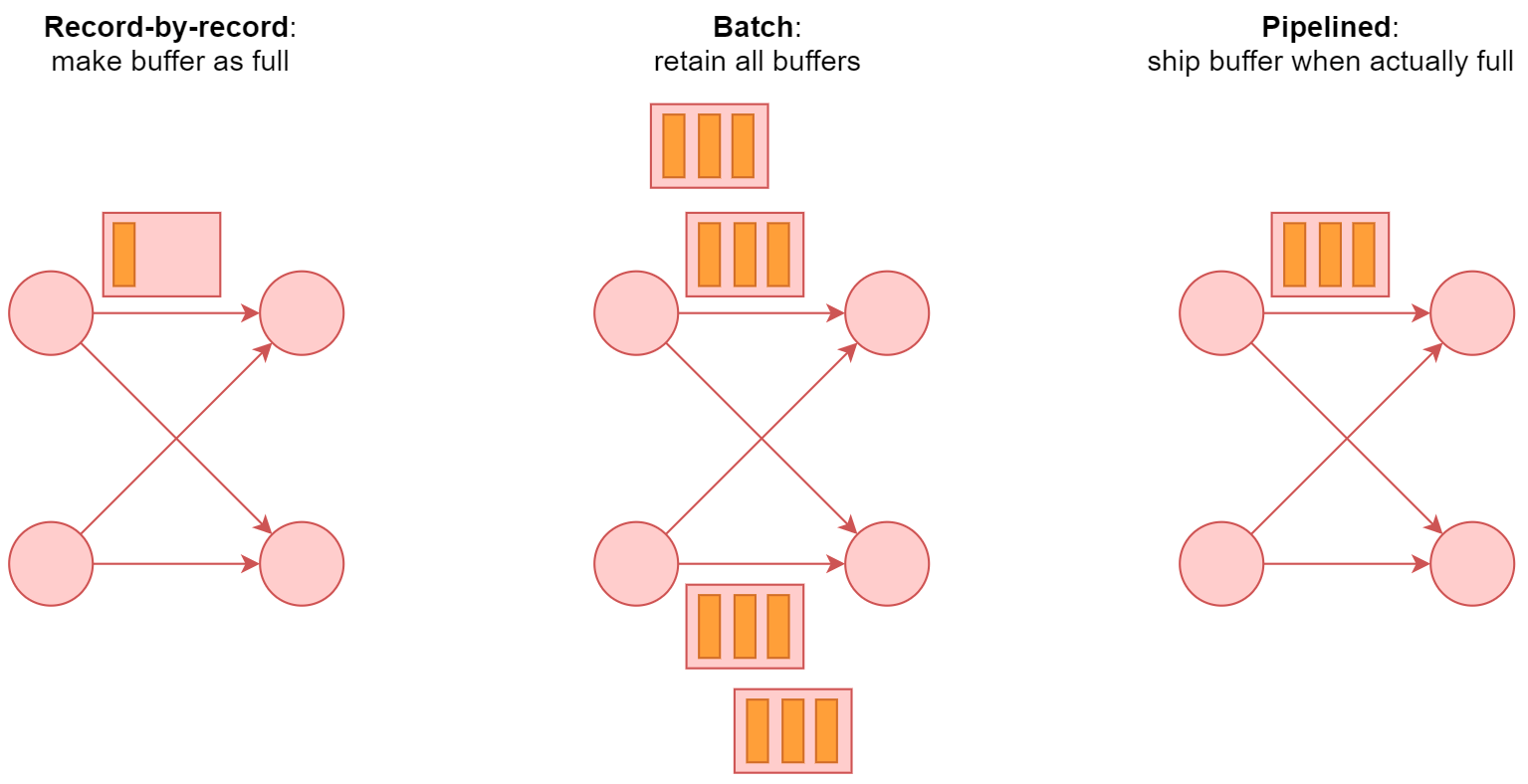
- 如图中显示的三种数据传输模型
- 第一个
- 一条一条处理
- 第二个
- 一批一批处理
- 第三个
- 按照缓存块进行处理,缓存块可以无限小,也可以无限大,这样就可以同时支持流处理和批处理了
- 第一个
12.1.5 流处理对比图
- Native
- 表示来一条数据处理一条数据
- Mirco-Batch
- 表示划分小批,一小批一小批的处理数据
- 组合式
- 表示是基础API,例如实现一个求和操作都需要写代码实现,比较麻烦,代码量会比较多
- 声明式
- 表示提供的是封装后的高阶函数,例如filter、count等函数,可以直接使用,比较方便,代码量 比较少 | 产品 | Storm | SparkStreaming | Flink | | —- | —- | —- | —- | | 模型 | Native | Mirco-Batch | Native | | API | 组合式 | 声明式 | 声明式 | | 语义 | At-least-once | Exectly-once | Exectly-once | | 容错机制 | Ack | Checkpoint | Checkpoint | | 状态管理 | 无 | 基于DStream | 基于操作 | | 延时 | LOW | Medium | Low | | 吞吐量 | Low | High | High |
12.1.6 实时计算框架如何选择
- 需要关注流数据是否需要进行状态管理
- 消息语义是否有特殊要求At-least-once或者Exectly-once
- 小型独立的项目,需要低延迟的场景,建议使用Storm
- 如果项目中已经使用了Spark,并且秒级别的实时处理可以满足需求,建议使用SparkStreaming
- 要求消息语义为Exectly-once,数据量较大,要求高吞吐低延迟,需要进行状态管理,建议选择Flink

若有收获,就点个赞吧
0 人点赞
