笔记内容选自慕课网《大数据开发工程师》体系课
4.1 分布式计算介绍
4.1.1 传统的计算方式
- 如果数据量大,传输速度慢的原因
- 一个是磁盘io(磁盘读写操作)
- 一个是网络io(网络传输)
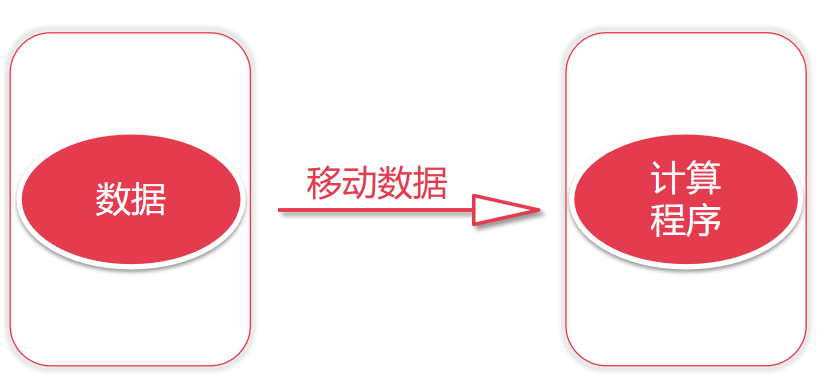
4.1.2 新型的移动计算
- 把计算程序移动到mysql上面去执行
- 从而节省网络io
- 只有一个磁盘io
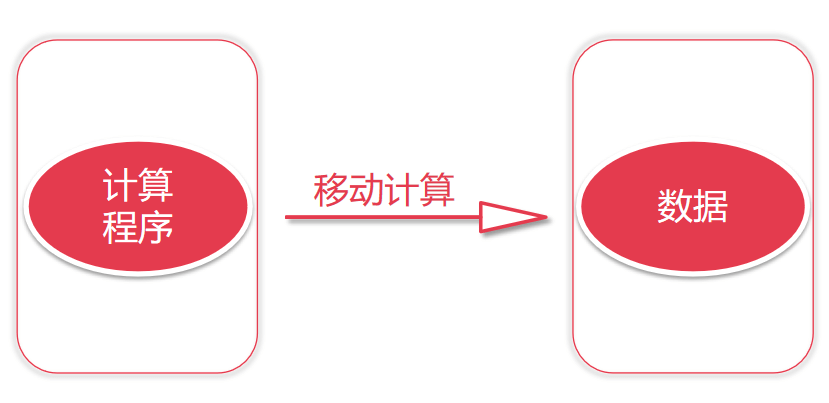
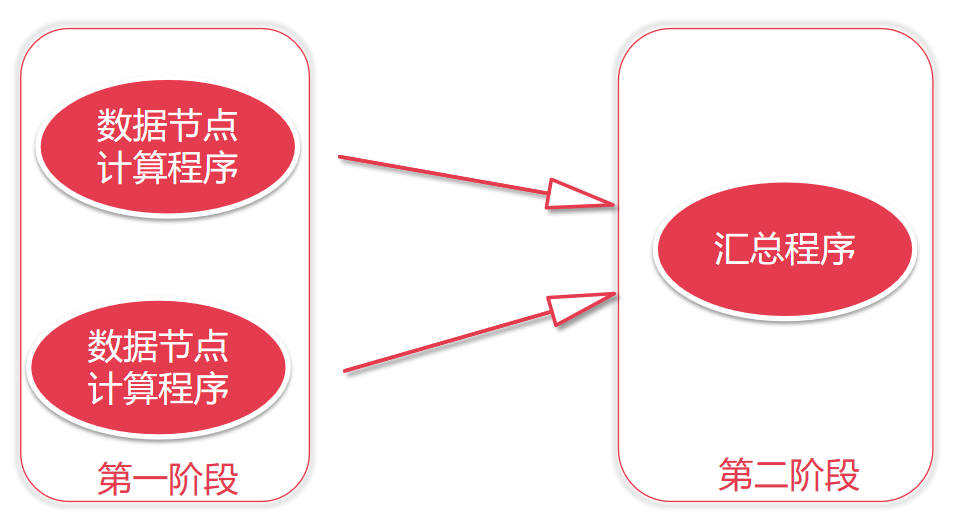
4.1.3 目前的分布式计算
- 对移动计算来进行多个汇总
- 对每个节点上面的数据进行局部计算
- 对每个节点上面计算的局部结果进行最终全局汇总
4.2 MapReduce执行流程
4.2.1 流程图分析
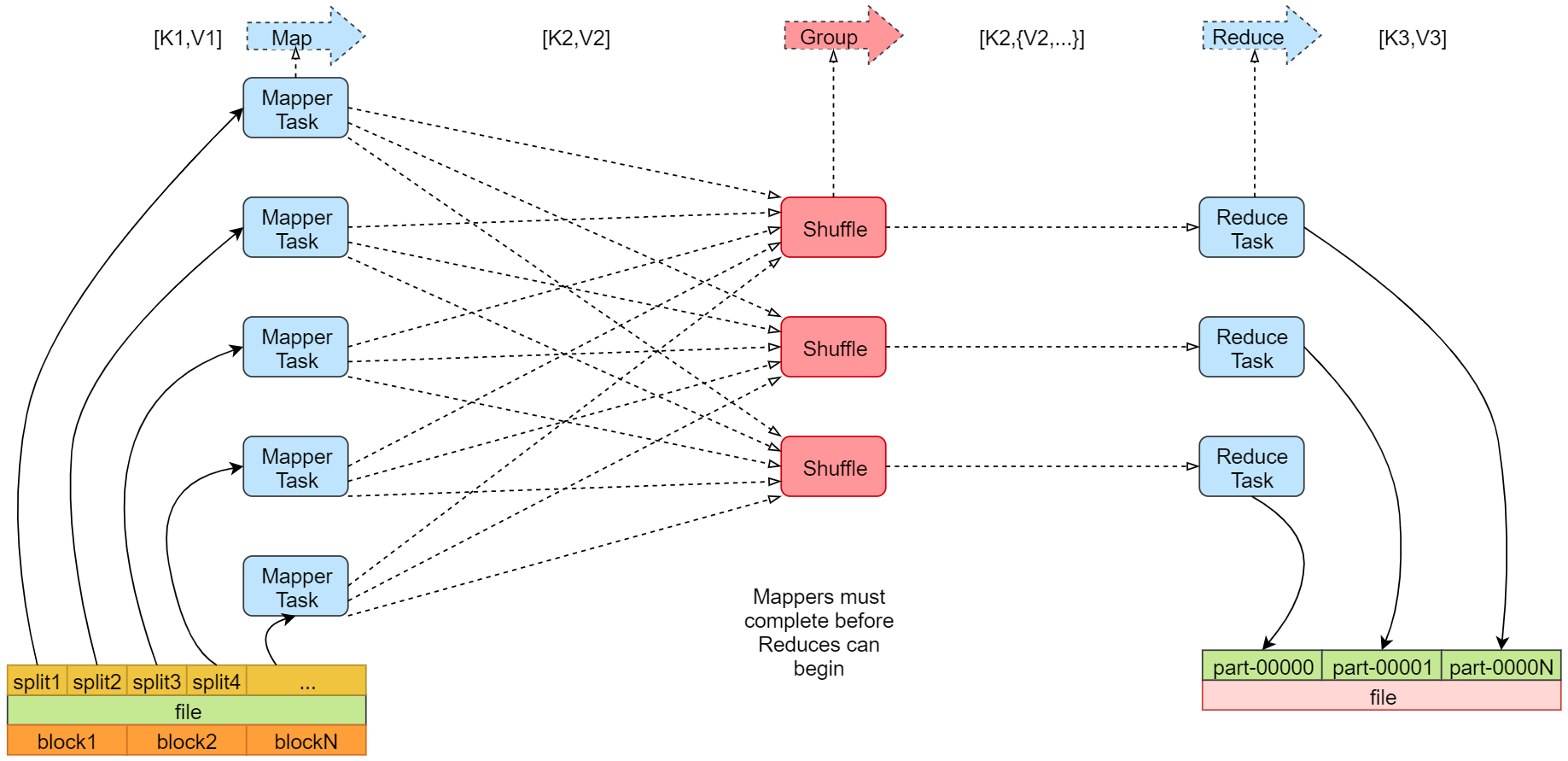
- MapReduce,分为两个任务步骤
- Map Task对应的是mapper类
- Reduce Task对应的是reducer类
- 左下角是一个待计算的文件
- 当文件容量大于默认128MB,就会对文件的真正切分,block块是文件的物理切分,在磁盘上是真实存在的
- split是逻辑划分,不是对文件真正的切分,默认情况下我们可以认为一个split的大小和一个block的大小是一样的
- 实际上是一个split会产生一个Map Task
- 右下角是一个最终结果文件
- Reduce会把结果数据汇总输出到hdfs上,这里有三个Reduce Task,就产生了3个文件,最终合并成一个结果文件
Map和Reduce的输入、输出
- map的输入是(k1,k1),输出是(k2,k2)
- reduce的输入是(k2,k2),输出是(k3,k3)
- 注意:为什么在这是1,2,3呢?
- 这个主要是为了区分数据,方便理解,没有其它含义,这是我们人为定义的
假设有一个文件,文件里有两行内容
- 第一行:hello you
- 第二行:hello me
- 我想统计文件中每个单词出现的总次数(**WordCount**)案例
4.2.2 MapReduce之Map阶段分析
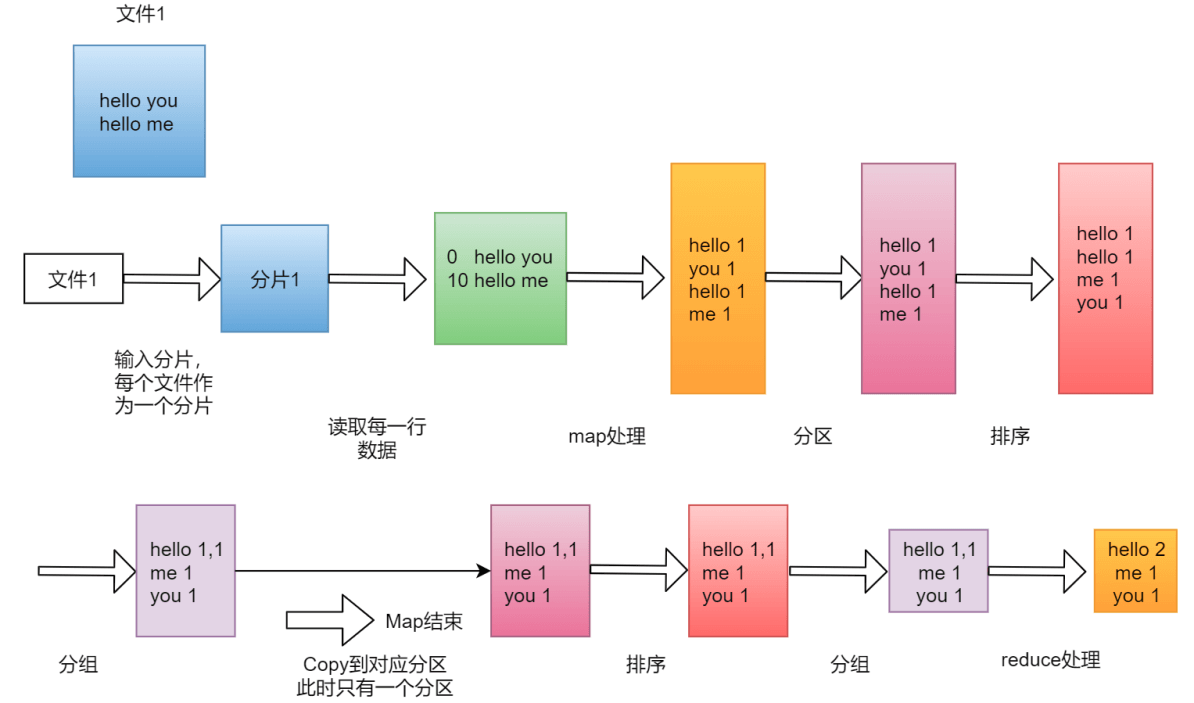
单文件分析
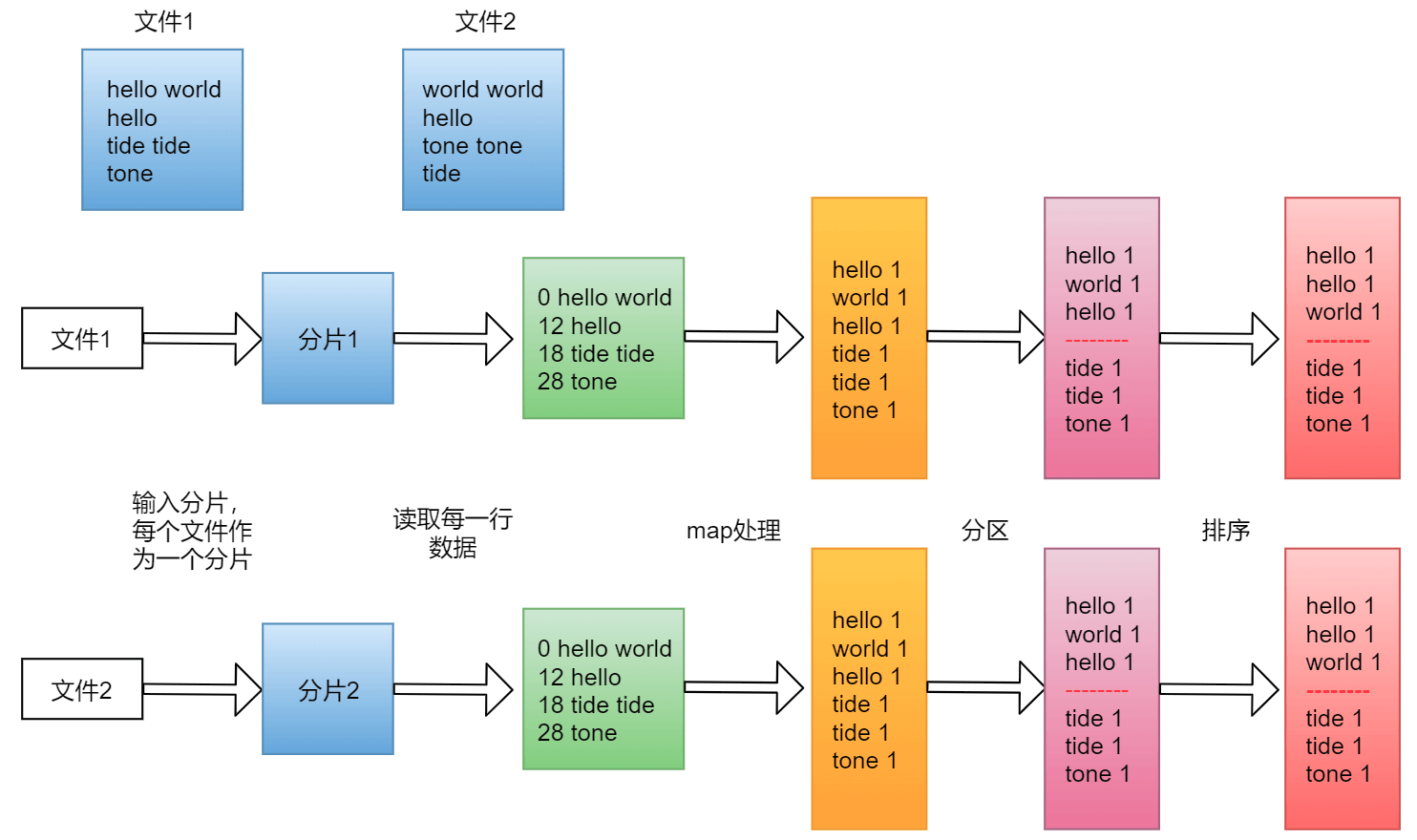
多文件分析
第一步:按内存偏移量对句子规划
框架会把输入文件(夹)划分为很多InputSplit(Split),默认情况下,每个HDFS的Block对应一个InputSplit。再通过RecordReader类,把每个InputSplit解析成一个一个的
<0,hello you>
<10,hello me>
「注意:map第一次执行会产生<0,hello you>,第二次执行会产生<10,hello me>,并不是执行一次就 获取到这两行结果了,因为每次只会读取一行数据」
第二步:对句子里的单词拆分且记录出现次数
框架调用 Mapper 类中的 map(…) 函数, map 函数的输入是
针对<0,hello you>执行这个逻辑之后的结果就是
针对<10,hello me>执行这个逻辑之后的结果是
**
第三步:考虑分区到那个Reduce任务
框架对map函数输出的
「注意:当map任务完成的局部计算的局部结果,需要把数据给到指定的reduce任务,如果业务简单则进行全局的汇总,就不需要进行分区,一个redeuce任务就可以搞定,如果你的业务逻辑比较复杂,需要进行分区,那么就会产生多个reduce任务了, 那么这个时候,map任务输出的数据到底给哪个reduce使用?这个就需要划分一下,要不然就乱套了。 假设有两个reduce,map的输出到底给哪个reduce,如何分配,这是一个问题。 这个问题,由分区来完成。 map输出的那些数据到底给哪个reduce使用,这个就是分区干的事了。」
_
第四步:对单词进行排序和分组
框架对每个分区中的数据,都会按照k2进行排序、分组。分组指的是相同k2的v2分成一个组。
先按照k2排序
然后按照k2进行分组,把相同k2的v2分成一个组
第五步:可选的组合器
Combiner可以翻译为组合器,组合器是什么意思呢?在刚才的例子中,最终是要在reduce端计算单词出现的总次数的,所以其实是可以在map端提前执行reduce的计算逻辑,先对在map端对单词出现的次数进行局部求和操作,这样就可以减少 map 端到 reduce 端数据传输的大小,这就是组合器的好处,当然了,并不是所有场景都可以使用组合器,针对求平均值之类的操作就不能使用组合器了,否则最终计算的结果就不准确了
第六步:导出数据
框架会把map task输出的
至此,整个map阶段执行结束
「注意:MapReduce 程序是由 map 和 reduce 这两个阶段组成的, 但是 reduce 阶段不是必须的, 也就是说有的 mapreduce任务只有map阶段,reduce主要是做最终聚合的,如果这个需求是不需要聚合操作,直接对数据做过滤处理就行了,那也就意味着数据经过map阶段处理完就结束了,所以如果reduce阶段不存在的话,map的结果是可以直接保存到HDFS中的」
_
因为(WordCount)需要句子截取单词,并且记录次数,所以需要reduce阶段的
4.2.3 MapReduce之Reduce阶段分析
多文件分析

第一步:导入数据
框架对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。这个过程 称作shuffle,针对我们这个需求,只有一个分区,所以把数据拷贝到reduce端之后还是老样子
第二步:合并,排序和分组
对多个map任务中相同分区的数据进行合并,排序,分组,可是之前在map中已经做了排序、分组,这边也做这些操作重复吗?
不重复,因为map端是局部的操作 reduce端是全局的操作 之前是每个map任务内进行排序,是有序的,但是多个map任务之间就是无序的了。
不过针对这个需求只有一个map任务一个分区,所以最终的结果还是老样子
第三步:在reduce函数里编写业务逻辑
框架调用Reducer类中的reduce方法,reduce方法的输入是
第四步:导出数据
框架把reduce的输出结果保存到HDFS中
hello 2
me 1
you 1
至此,整个reduce阶段结束。
4.3 实战:WordCount案例开发
4.3.1 Java代码实现
import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;/*** @description: 单词统计* @projectName: db_hadoop* @since: com.chaunceyi.mr* @author: JavaCx* @createTime: 2021/8/9 4:50 下午** 需求:读取hdfs上的hello.txt文件,计算文件中每个单词出现的总次数需求;* 原始文件hello.txt内容如下* hello you* hello me** 输出文件结果为* hello 2* you 1* me 1*/public class WordCountJob {/*** 组装Job=Map+Reduce*/public static void main(String[] args) {try {// 第一个参数:文件名,第二个参数:路径if (args.length!=2){System.exit(100);}// 指定Job需要的配置参数Configuration conf = new Configuration();// 创建一个JobJob job = Job.getInstance(new Configuration());//注意了:这一行必须设置,否则在集群中执行的时候是找不到WordCountJob这个类的job.setJarByClass(WordCountJob.class);// 指定输入路径(可以是文件,也可以是目录)FileInputFormat.setInputPaths(job,new Path(args[0]));// 指定输出路径(只能指定一个不存在的目录)FileOutputFormat.setOutputPath(job,new Path(args[1]));//指定map相关的代码job.setMapperClass(MyMapper.class);//指定k2的类型job.setMapOutputKeyClass(Text.class);//指定v2的类型job.setMapOutputValueClass(LongWritable.class);//指定reduce相关的代码job.setReducerClass(MyReducer.class);//指定k3的类型job.setOutputKeyClass(Text.class);//指定v3的类型job.setOutputValueClass(LongWritable.class);//提交jobjob.waitForCompletion(true);} catch (Exception e) {e.printStackTrace();}}public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{/*** @Description: Map阶段* @author: JavaCx* @paramsName: [k1, v1, context]* @return: void* @date: 2021/8/9 5:19 下午*/@Overrideprotected void map(LongWritable k1, Text v1, Context context)throws IOException, InterruptedException {// k1代表的是每一行数据的行首偏移量,v1代表的是每一行内容// 对获取到的每一行数据进行切割,把单词切割出来String[] words = v1.toString().split(" ");// 迭代切割出来的单词数据for (String word : words) {Text k2 = new Text(word);LongWritable v2 = new LongWritable(1L);// 把<k2,v2>写出去context.write(k2, v2);}}}public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{/*** @Description: Reduce阶段* 针对<k2,{v2...}>的数据进行累加求和,并且最终把数据转化为k3,v3写出去** @author: JavaCx* @paramsName: [k2, v2s, context]* @return: void* @date: 2021/8/9 5:24 下午*/@Overrideprotected void reduce(Text k2, Iterable<LongWritable> v2s,Context context)throws IOException, InterruptedException {// 创建一个sum变量,保存v2s的和long sum = 0L;// 对v2s中的数据进行累加求和for (LongWritable v2 : v2s) {sum += v2.get();}// 组成k3,v3Text k3 = k2;LongWritable v3 = new LongWritable(sum);// 把结果写出去context.write(k3, v3);}}}
4.3.2 maven配置打Jar包
<dependencies>
<!--hadoop的依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
<!--provided表示这个依赖只在编译的时候,执行或者打jar包的时候都不使用-->
<scope>provided</scope>
</dependency>
<!--log4j的依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.10</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.10</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!-- compiler插件, 设定JDK版本 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<encoding>UTF-8</encoding>
<source>1.8</source>
<target>1.8</target>
<showWarnings>true</showWarnings>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
4.3.3 执行Clean命令和Package
4.3.5 拷贝jar到Hadoop
4.3.6 准备测试数据
# 创建hello.txt
cd /data/soft/hadoop-3.2.0
vi hello.txt
# 设置数据内容
hello you
hello me
# 把数据上传到hdfs
hdfs dfs -mkdir /test
hdfs dfs -put hello.txt /test
hdfs dfs -ls /test
# 开始启动WordCount程序
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.chaunceyi.mr.WordCountJob /test/hello.txt /out
- hadoop:表示使用hadoop脚本提交任务,其实在这里使用yarn脚本也是可以的,从hadoop2开始,支持使用yarn,不过也兼容hadoop1,也可以继续使用hadoop脚本,所以在这里使用哪个都可以,具体就看你个人的喜好了
- jar:表示执行jar包
- db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar:指定具体的jar包路径信息
- com.chaunceyi.mr.WordCountJob:指定要执行的mapreduce代码的全路径
- /test/hello.txt:指定mapreduce接收到的第一个参数,代表的是输入路径
- /out:指定mapreduce接收到的第二个参数,代表的是输出目录,这里的输出目录必须是不存在 的,MapReduce程序在执行之前会检测这个输出目录,如果存在会报错,因为它每次执行任务都需 要一个新的输出目录来存储结果数据
4.3.7 查看执行情况
任务提交到集群上面之后,可以在shell窗口中看到如下日志信息,最终map执行到100%,reduce执行 到100%,说明任务执行成功了。
2021-08-09 18:24:26,964 INFO mapreduce.Job: map 0% reduce 0%
2021-08-09 18:24:32,045 INFO mapreduce.Job: map 100% reduce 0%
2021-08-09 18:24:38,122 INFO mapreduce.Job: map 100% reduce 100%
也可以到web界面中查看任务执行情况:http://bigdata01:8088/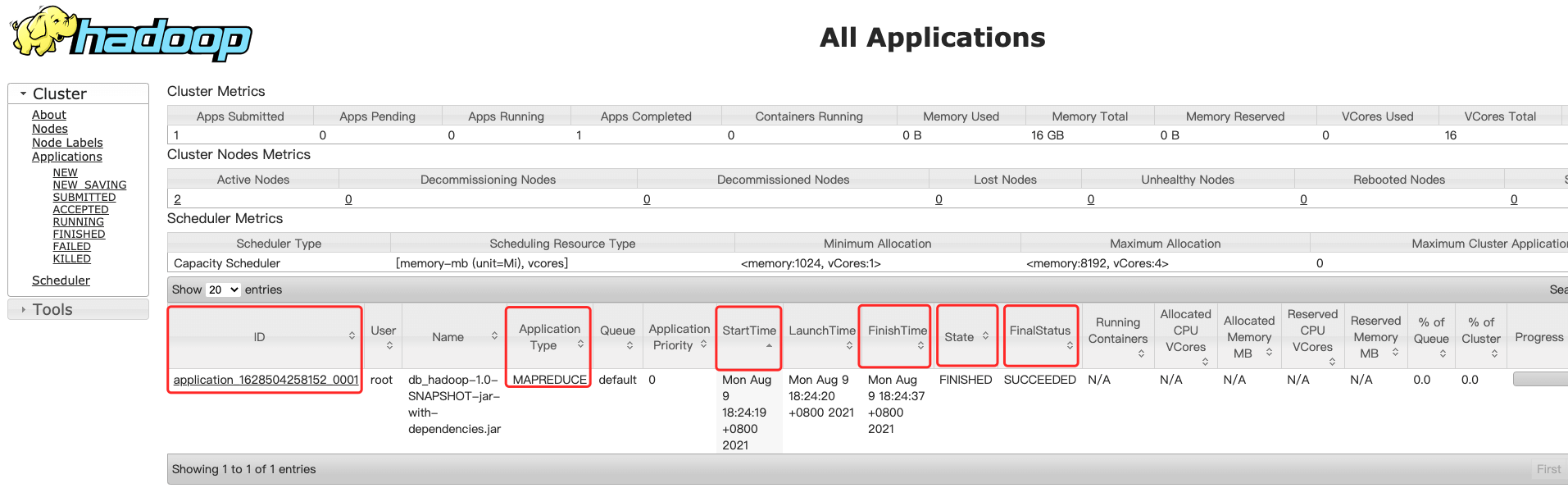
4.3.8 查看输出结果
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /out
Found 2 items
-rw-r--r-- 2 root supergroup 0 2021-08-09 18:24 /out/_SUCCESS
-rw-r--r-- 2 root supergroup 19 2021-08-09 18:24 /out/part-r-00000
「注意:__在out输出目录中,_SUCCESS是一个标记文件,有这个文件表示这个任务执行成功了
part-r-00000是具体的数据文件,如果有多个reduce任务会产生多个这种文件,多个文件的话会按照从0开始编号,00001,00002等等
part 后面的 r 表示这个结果文件是 reduce 步骤产生的, 如果一个 mapreduce 只有 map阶段没有reduce阶段,那么产生的结果文件是part-m-00000__」
4.4 MapReduce任务日志查看
4.4.1 开启Yarn日志聚合功能
- 把散落在NodeManager节点上的日志统一收集管理,方便查看日志
- 启动historyserver进程才可以查看访问
- 修改yarn-site.xml文件
```c
停止集群
/data/soft/hadoop-3.2.0/sbin/stop-all.sh修改配置文件
cd /data/soft/hadoop-3.2.0/etc/hadoop vi yarn-site.xml …yarn.log-aggregation-enable true yarn.log.server.url http://bigdata01:19888/jobhistory/logs/
拷贝给其他两个子节点
scp -rq yarn-site.xml bigdata02:/data/soft/hadoop-3.2.0/etc/hadoop/ scp -rq yarn-site.xml bigdata03:/data/soft/hadoop-3.2.0/etc/hadoop/
启动集群
/data/soft/hadoop-3.2.0/sbin/start-all.sh
给三台主从服务器都启动historyserver进程,并放置后台运行
cd /data/soft/hadoop-3.2.0 bin/mapred —daemon start historyserver
<a name="RmpEs"></a>
### 4.4.2 Java代码添加些日志信息
```java
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* @description: 单词统计
* @projectName: db_hadoop
* @since: com.chaunceyi.mr
* @author: JavaCx
* @createTime: 2021/8/9 4:50 下午
*
* 需求:读取hdfs上的hello.txt文件,计算文件中每个单词出现的总次数需求;
* 原始文件hello.txt内容如下
* hello you
* hello me
*
* 输出文件结果为
* hello 2
* you 1
* me 1
*/
public class WordCountJob {
/**
* 组装Job=Map+Reduce
*/
public static void main(String[] args) {
try {
// 第一个参数:文件名,第二个参数:路径
if (args.length!=2){
System.exit(100);
}
// 指定Job需要的配置参数
Configuration conf = new Configuration();
// 创建一个Job
Job job = Job.getInstance(new Configuration());
//注意了:这一行必须设置,否则在集群中执行的时候是找不到WordCountJob这个类的
job.setJarByClass(WordCountJob.class);
// 指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job,new Path(args[0]));
// 指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
//指定reduce相关的代码
job.setReducerClass(MyReducer.class);
//指定k3的类型
job.setOutputKeyClass(Text.class);
//指定v3的类型
job.setOutputValueClass(LongWritable.class);
//提交job
job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* @Description: Map阶段
* @author: JavaCx
* @paramsName: [k1, v1, context]
* @return: void
* @date: 2021/8/9 5:19 下午
*/
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
// 日志信息
logger.info("This is Log:<k1,v1>=<"+k1.get()+","+v1.toString()+">");
// k1代表的是每一行数据的行首偏移量,v1代表的是每一行内容
// 对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
// 迭代切割出来的单词数据
for (String word : words) {
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
// 把<k2,v2>写出去
context.write(k2, v2);
}
}
}
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
Logger logger = LoggerFactory.getLogger(MyReducer.class);
/**
* @Description: Reduce阶段
* 针对<k2,{v2...}>的数据进行累加求和,并且最终把数据转化为k3,v3写出去
*
* @author: JavaCx
* @paramsName: [k2, v2s, context]
* @return: void
* @date: 2021/8/9 5:24 下午
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s,Context context)
throws IOException, InterruptedException {
// 创建一个sum变量,保存v2s的和
long sum = 0L;
// 对v2s中的数据进行累加求和
for (LongWritable v2 : v2s) {
sum += v2.get();
// 日志信息
logger.info("This is Log:<k2,v2>=<"+k2.toString()+","+v2.get()+">");
}
// 组成k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
// 日志信息
logger.info("This is Log:<k3,v3>=<"+k3.toString()+","+v3.get()+">");
// 把结果写出去
context.write(k3, v3);
}
}
}
4.4.3 打包测试运行
# 开始启动WordCount程序,输出目录必须是不存在的才能启动成功
cd /data/soft/hadoop-3.2.0
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.chaunceyi.mr.WordCountJob /test/hello.txt /out1
4.4.4 Web界面查日志

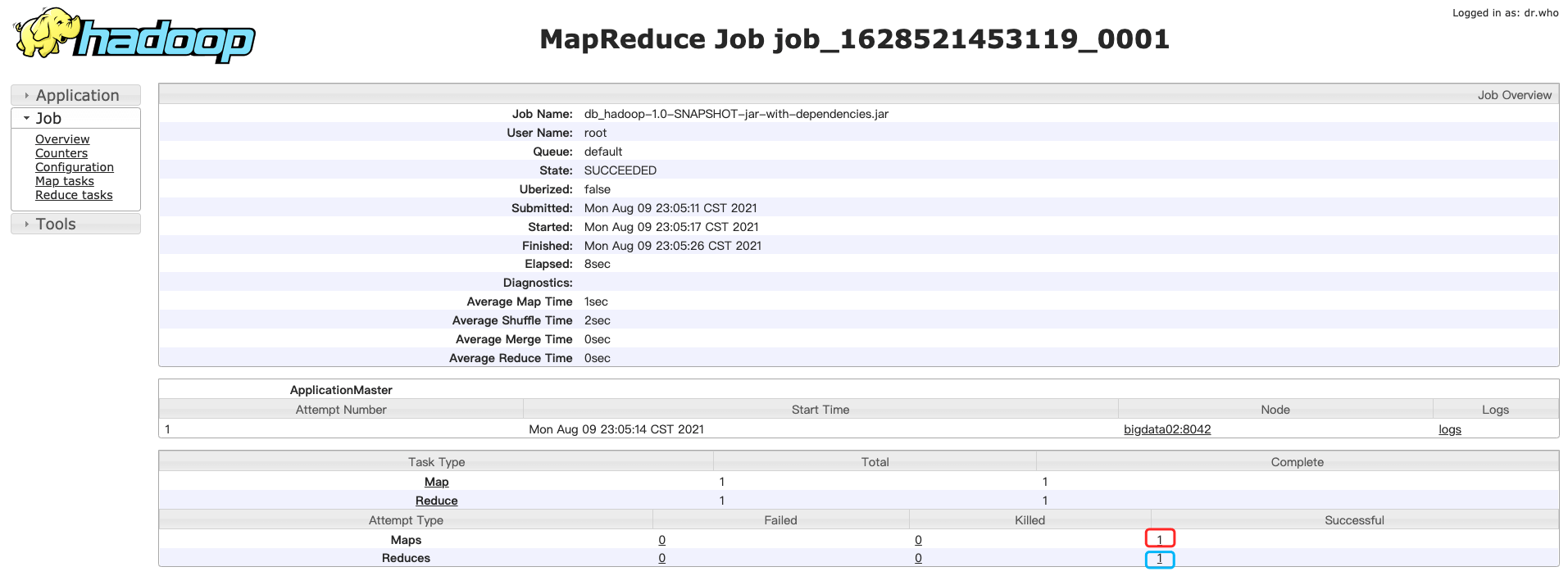

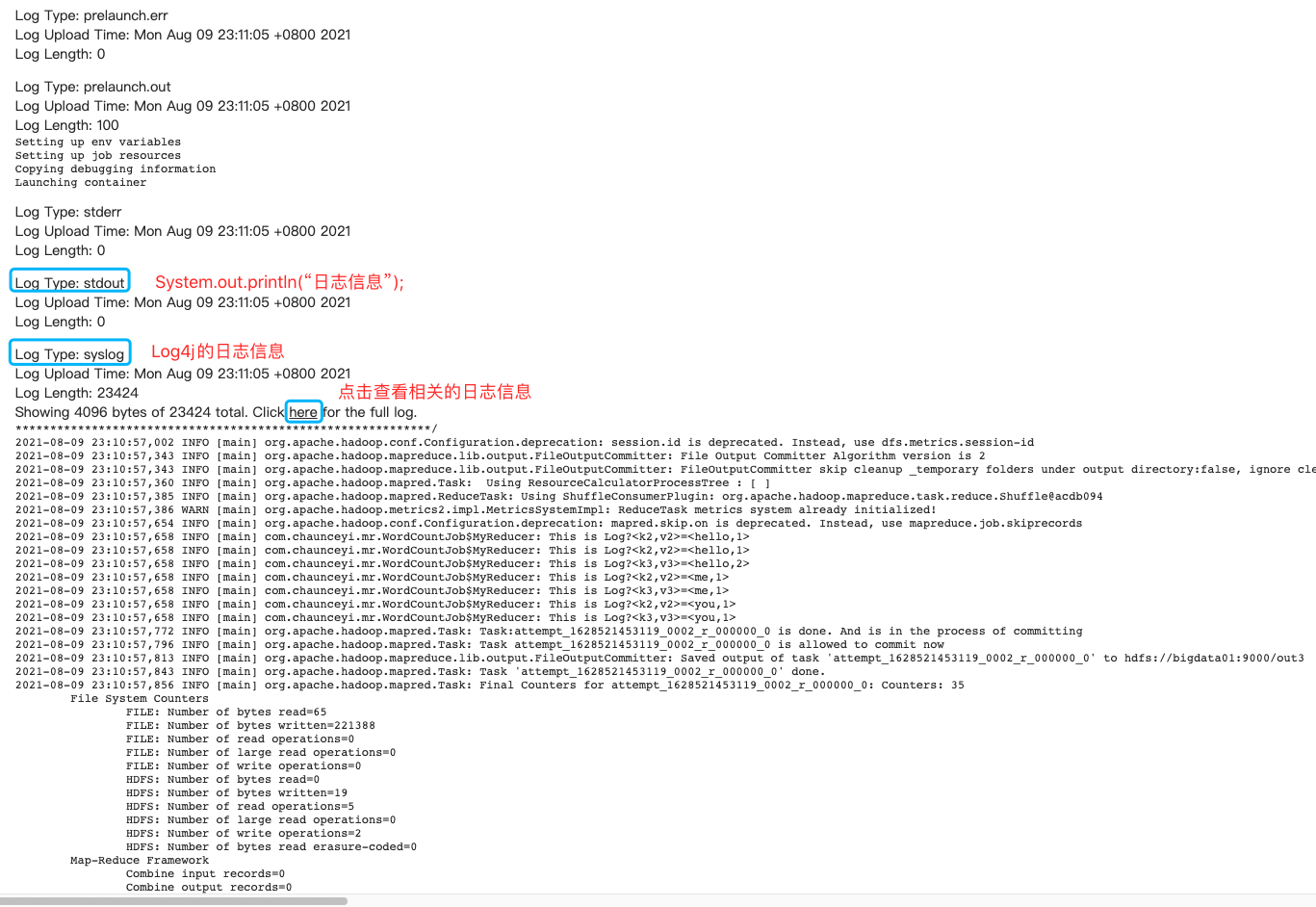
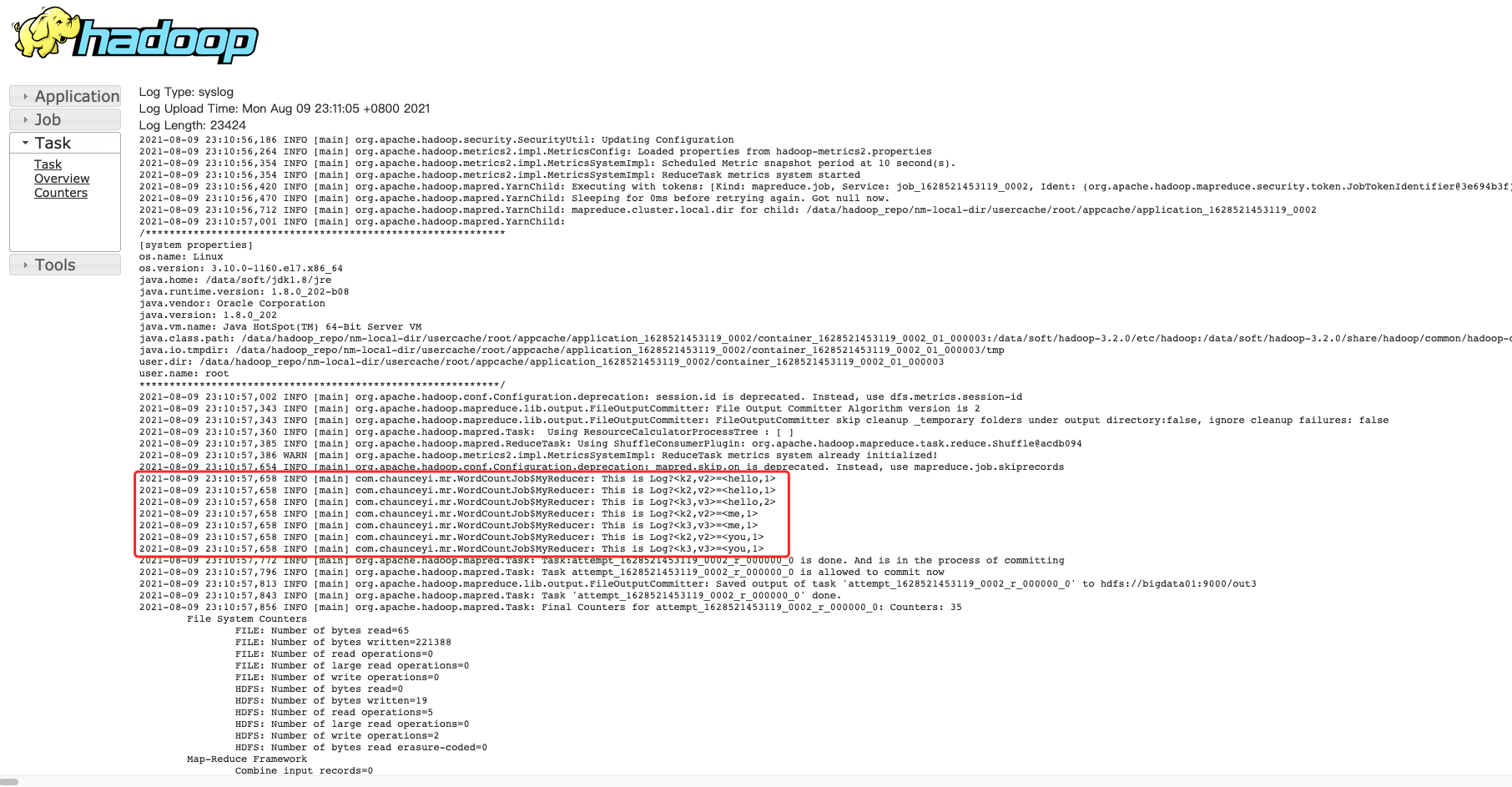
4.4.5 控制台查看日志「面试」
# 日志信息杂多,可输出文件拖拽到桌面查看
[root@bigdata01 hadoop-3.2.0]# yarn logs -applicationId application_1628521453119_0002
************************************************************/
2021-08-09 23:10:52,430 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
2021-08-09 23:10:52,765 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: File Output Committer Algorithm version is 2
2021-08-09 23:10:52,765 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2021-08-09 23:10:52,780 INFO [main] org.apache.hadoop.mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2021-08-09 23:10:52,913 INFO [main] org.apache.hadoop.mapred.MapTask: Processing split: hdfs://bigdata01:9000/test/hello.txt:0+19
2021-08-09 23:10:53,005 INFO [main] org.apache.hadoop.mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
2021-08-09 23:10:53,005 INFO [main] org.apache.hadoop.mapred.MapTask: mapreduce.task.io.sort.mb: 100
2021-08-09 23:10:53,005 INFO [main] org.apache.hadoop.mapred.MapTask: soft limit at 83886080
2021-08-09 23:10:53,005 INFO [main] org.apache.hadoop.mapred.MapTask: bufstart = 0; bufvoid = 104857600
2021-08-09 23:10:53,005 INFO [main] org.apache.hadoop.mapred.MapTask: kvstart = 26214396; length = 6553600
2021-08-09 23:10:53,043 INFO [main] org.apache.hadoop.mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2021-08-09 23:10:53,072 INFO [main] com.chaunceyi.mr.WordCountJob$MyMapper: This is Log?<k1,v1>=<0,hello you>
2021-08-09 23:10:53,072 INFO [main] com.chaunceyi.mr.WordCountJob$MyMapper: This is Log?<k1,v1>=<10,hello me>
2021-08-09 23:10:53,086 INFO [main] org.apache.hadoop.mapred.MapTask: Starting flush of map output
2021-08-09 23:10:53,086 INFO [main] org.apache.hadoop.mapred.MapTask: Spilling map output
2021-08-09 23:10:53,086 INFO [main] org.apache.hadoop.mapred.MapTask: bufstart = 0; bufend = 51; bufvoid = 104857600
2021-08-09 23:10:53,086 INFO [main] org.apache.hadoop.mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214384(104857536); length = 13/6553600
2021-08-09 23:10:53,093 INFO [main] org.apache.hadoop.mapred.MapTask: Finished spill 0
2021-08-09 23:10:53,128 INFO [main] org.apache.hadoop.mapred.Task: Task:attempt_1628521453119_0002_m_000000_0 is done. And is in the process of committing
2021-08-09 23:10:53,172 INFO [main] org.apache.hadoop.mapred.Task: Task 'attempt_1628521453119_0002_m_000000_0' done.
2021-08-09 23:10:53,178 INFO [main] org.apache.hadoop.mapred.Task: Final Counters for attempt_1628521453119_0002_m_000000_0: Counters: 28
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=221443
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=120
HDFS: Number of bytes written=0
HDFS: Number of read operations=3
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=51
Map output materialized bytes=65
Input split bytes=101
Combine input records=0
Spilled Records=4
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=76
CPU time spent (ms)=440
Physical memory (bytes) snapshot=186044416
Virtual memory (bytes) snapshot=2517041152
Total committed heap usage (bytes)=123215872
Peak Map Physical memory (bytes)=186044416
Peak Map Virtual memory (bytes)=2517041152
File Input Format Counters
Bytes Read=19
2021-08-09 23:10:53,288 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping MapTask metrics system...
2021-08-09 23:10:53,288 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system stopped.
2021-08-09 23:10:53,289 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system shutdown complete.
End of LogType:syslog
***********************************************************************
# 过滤一下打印日志
[root@bigdata01 hadoop-3.2.0]# yarn logs -applicationId application_1628521453119_0002 | grep k3,v3
2021-08-09 23:24:29,077 INFO client.RMProxy: Connecting to ResourceManager at bigdata01/192.168.53.100:8032
2021-08-09 23:10:57,658 INFO [main] com.chaunceyi.mr.WordCountJob$MyReducer: This is Log?<k3,v3>=<hello,2>
2021-08-09 23:10:57,658 INFO [main] com.chaunceyi.mr.WordCountJob$MyReducer: This is Log?<k3,v3>=<me,1>
2021-08-09 23:10:57,658 INFO [main] com.chaunceyi.mr.WordCountJob$MyReducer: This is Log?<k3,v3>=<you,1>
4.5 停止Hadoop集群中的任务
如果一个mapreduce任务处理的数据量比较大的话,这个任务会执行很长时间,可能几十分钟或者几个 小时都有可能,假设一个场景,任务执行了一半了我们发现我们的代码写的有问题,需要修改代码重新提 交执行,这个时候之前的任务就没有必要再执行了,没有任何意义了,最终的结果肯定是错误的,所以我 们就想把它停掉,要不然会额外浪费集群的资源,如何停止呢? 我在提交任务的窗口中按ctrl+c是不是就可以停止? 注意了,不是这样的,我们前面说过,这个任务是提交到集群执行的,你在提交任务的窗口中执行ctrl+c 对已经提交到集群中的任务是没有任何影响的。 我们可以验证一下,执行ctrl+c之后你再到yarn的8088界面查看,会发现任务依然存在。 所以需要使用hadoop集群的命令去停止正在运行的任务 使用yarn application -kill命令,后面指定任务id即可
[root@bigdata01 hadoop-3.2.0]# yarn application -kill application_1628521453119_0002
4.6 MapReduce程序扩展
- 禁用Reduce,只执行Map阶段 ```java import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.slf4j.Logger; import org.slf4j.LoggerFactory;
/**
- @description: 单词统计
- @projectName: db_hadoop
- @since: com.chaunceyi.mr
- @author: JavaCx
- @createTime: 2021/8/9 4:50 下午 *
- 需求:读取hdfs上的hello.txt文件,计算文件中每个单词出现次数需求;
- 原始文件hello.txt内容如下
- hello you
- hello me *
- 输出文件结果为
- hello 1
- you 1
- hello 1
me 1 / public class WordCountJob { /*
组装Job=Map */ public static void main(String[] args) { try {
// 第一个参数:文件名,第二个参数:路径 if (args.length!=2){ System.exit(100); } // 指定Job需要的配置参数 Configuration conf = new Configuration(); // 创建一个Job Job job = Job.getInstance(new Configuration()); //注意了:这一行必须设置,否则在集群中执行的时候是找不到WordCountJob这个类的 job.setJarByClass(WordCountJob.class); // 指定输入路径(可以是文件,也可以是目录) FileInputFormat.setInputPaths(job,new Path(args[0])); // 指定输出路径(只能指定一个不存在的目录) FileOutputFormat.setOutputPath(job,new Path(args[1])); //指定map相关的代码 job.setMapperClass(MyMapper.class); //指定k2的类型 job.setMapOutputKeyClass(Text.class); //指定v2的类型 job.setMapOutputValueClass(LongWritable.class); // 禁用Reduce job.setNumReduceTasks(0); //提交job job.waitForCompletion(true);} catch (Exception e) {
e.printStackTrace();} } public static class MyMapper extends Mapper
- @Description: Map阶段
- @author: JavaCx
- @paramsType: [org.apache.hadoop.io.LongWritable, org.apache.hadoop.io.Text, org.apache.hadoop.mapreduce.Mapper
- @paramsName: [k1, v1, context]
- @return: void
@date: 2021/8/9 5:19 下午 */ @Override protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {// 日志信息 logger.info(“This is Log:
// k1代表的是每一行数据的行首偏移量,v1代表的是每一行内容 // 对获取到的每一行数据进行切割,把单词切割出来 String[] words = v1.toString().split(“ “); // 迭代切割出来的单词数据 for (String word : words) {
Text k2 = new Text(word); LongWritable v2 = new LongWritable(1L); // 把<k2,v2>写出去 context.write(k2, v2);} } } } ```
4.7 MapReduce执行过程和源码剖析
能力不够,先暂时空着
4.8 MapReduce的性能优化
4.8.1 后起之秀
在实际工作中很少用MapReduce代码实现,因为后面会学到个大数据框架Hive,它支持SQL且底层会把SQL转化为MapReduce执行,从而不需要写一行代码
4.8.2 小文件问题
「注意:Hadoop的HDFS和MapReduce都是针对大数据文件来设计的,在小文件的处理上不但 效率低下,而且十分消耗内存资源 针对HDFS而言,每一个小文件在namenode中都会占用150字节的内存空间,最终会导致集群中虽然存 储了很多个文件,但是文件的体积并不大,这样就没有意义了。
针对MapReduce而言,每一个小文件都是一个Block,都会产生一个InputSplit,最终每一个小文件都会 产生一个map任务,这样会导致同时启动太多的Map任务,Map任务的启动是非常消耗性能的,但是启 动了以后执行了很短时间就停止了,因为小文件的数据量太小了,这样就会造成任务执行消耗的时间还没 有启动任务消耗的时间多,这样也会影响MapReduce执行的效率
针对这个问题,解决办法通常是选择一个容器,将这些小文件组织起来统一存储,HDFS提供了两种类型的 容器,分别是SequenceFile 和 MapFile__」
_
1、SequeceFile
- SequeceFile 是 Hadoop 提供的一种二进制文件
- 优点
- 这种二进制文件直接将
- 这种二进制文件直接将
- 缺点
- 多个小文件需要合并,最终合并的文件会比较大
- 合并后不方便查看,需要代码遍历里每个小文件
- 它就像是个压缩包,而且里面内容是无序状态
- 优点
2、数据准备

3、代码实现
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import java.io.File;
/**
* 小文件解决方案之SequenceFile
*/
public class SmallFileSeq {
public static void main(String[] args) throws Exception{
//生成SequenceFile文件
write("/Users/angel/Desktop/Data","/seqFile");
//读取SequenceFile文件
read("/seqFile");
}
/**
* 生成SequenceFile文件
* @param inputDir 输入目录-windows目录
* @param outputFile 输出文件-hdfs文件
* @throws Exception
*/
private static void write(String inputDir,String outputFile) throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//获取操作HDFD的对象
FileSystem fileSystem = FileSystem.get(conf);
//删除HDFS上的输出文件
fileSystem.delete(new Path(outputFile),true);
//构造opts数组,有三个元素
/*
第一个是输出路径【文件】
第二个是key的类型
第三个是value的类型
*/
SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{
SequenceFile.Writer.file(new Path(outputFile)),
SequenceFile.Writer.keyClass(Text.class),
SequenceFile.Writer.valueClass(Text.class)
};
//创建了一个writer实例
SequenceFile.Writer writer = SequenceFile.createWriter(conf, opts);
//指定需要压缩的文件的目录
File inputDirPath = new File(inputDir);
if(inputDirPath.isDirectory()){
//获取目录中的文件
File[] files = inputDirPath.listFiles();
//迭代文件
for (File file: files) {
//获取文件的全部内容
String content = FileUtils.readFileToString(file, "UTF-8");
//获取文件名
String fileName = file.getName();
Text key = new Text(fileName);
Text value = new Text(content);
//向SequenceFile中写入数据
writer.append(key,value);
}
}
writer.close();
}
/**
* 读取SequenceFile文件
* @param inputFile SequenceFile文件路径
* @throws Exception
*/
private static void read(String inputFile) throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//创建阅读器
SequenceFile.Reader reader = new SequenceFile.Reader(conf, SequenceFile.Reader.file(new Path(inputFile)));
Text key = new Text();
Text value = new Text();
//循环读取数据
while(reader.next(key,value)){
//输出文件名称
System.out.print("文件名:"+key.toString()+",");
//输出文件内容
System.out.println("文件内容:"+value.toString()+"");
}
reader.close();
}
}
4、MapFile
- MapFile是排序后的SequenceFile,MapFile由两部分组成,分别是index和data
- 优点
- index 作为文件的数据索引,主要记录了每个 Record 的 key 值, 以及该 Record 在文件中的偏移位置
- 在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件位置
- 相对SequenceFile而言,MapFile的检索效率是高效的
- 缺点
- 会消耗一部分内存来存储index数据
- 优点
5、代码实现
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.MapFile;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import java.io.File;
/**
* 小文件解决方案之MapFile
*/
public class SmallFileMap {
public static void main(String[] args) throws Exception{
//生成MapFile文件
write("/Users/angel/Desktop/Data","/mapFile");
//读取MapFile文件
read("/mapFile");
}
/**
* 生成MapFile文件
* @param inputDir 输入目录-windows目录
* @param outputDir 输出目录-hdfs目录
* @throws Exception
*/
private static void write(String inputDir,String outputDir) throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//获取操作HDFD的对象
FileSystem fileSystem = FileSystem.get(conf);
//删除HDFS上的输出文件
fileSystem.delete(new Path(outputDir),true);
//构造opts数组,有两个元素
/*
第一个是key的类型
第二个是value的类型
*/
SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{
MapFile.Writer.keyClass(Text.class),
MapFile.Writer.valueClass(Text.class)
};
//创建了一个writer实例
MapFile.Writer writer = new MapFile.Writer(conf, new Path(outputDir), opts);
//指定需要压缩的文件的目录
File inputDirPath = new File(inputDir);
if(inputDirPath.isDirectory()){
//获取目录中的文件
File[] files = inputDirPath.listFiles();
//迭代文件
for (File file: files) {
//获取文件的全部内容
String content = FileUtils.readFileToString(file, "UTF-8");
//获取文件名
String fileName = file.getName();
Text key = new Text(fileName);
Text value = new Text(content);
//向SequenceFile中写入数据
writer.append(key,value);
}
}
writer.close();
}
/**
* 读取MapFile文件
* @param inputDir MapFile文件路径
* @throws Exception
*/
private static void read(String inputDir)throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//创建阅读器
MapFile.Reader reader = new MapFile.Reader(new Path(inputDir),conf);
Text key = new Text();
Text value = new Text();
//循环读取数据
while(reader.next(key,value)){
//输出文件名称
System.out.print("文件名:"+key.toString()+",");
//输出文件内容
System.out.println("文件内容:"+value.toString()+"");
}
reader.close();
}
}
6、查看存储情况
[root@bigdata01 ~]# hdfs dfs -ls /mapFile
Found 2 items
-rw-r--r-- 3 angel supergroup 387 2021-08-10 10:28 /mapFile/data
-rw-r--r-- 3 angel supergroup 202 2021-08-10 10:28 /mapFile/index
4.8.3 MapReduce计算SequeceFile
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* 需求:使用MapReduce读取和计算SequenceFile文件
*/
public class WordCountJobSeq {
/**
* Map阶段
*/
public static class MyMapper extends Mapper<Text, Text,Text,LongWritable>{
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* 需要实现map函数
* 这个map函数就是可以接收<k1,v1>,产生<k2,v2>
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(Text k1, Text v1, Context context)
throws IOException, InterruptedException {
//输出k1,v1的值
logger.info("This is Log:<k1,v1>=<"+k1.toString()+","+v1.toString()+">");
//k1 代表的是每一行数据的行首偏移量,v1代表的是每一行内容
//对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
//迭代切割出来的单词数据
for (String word : words) {
//把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
//把<k2,v2>写出去
context.write(k2,v2);
}
}
}
/**
* Reduce阶段
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
Logger logger = LoggerFactory.getLogger(MyReducer.class);
/**
* 针对<k2,{v2...}>的数据进行累加求和,并且最终把数据转化为k3,v3写出去
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context)
throws IOException, InterruptedException {
//创建一个sum变量,保存v2s的和
long sum = 0L;
//对v2s中的数据进行累加求和
for(LongWritable v2: v2s){
//输出k2,v2的值
logger.info("This is Log:<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
}
//组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
//输出k3,v3的值
logger.info("This is Log:<k3,v3>=<"+k3.toString()+","+v3.get()+">");
// 把结果写出去
context.write(k3,v3);
}
}
/**
* 组装Job=Map+Reduce
*/
public static void main(String[] args) {
try{
if(args.length!=2){
//如果传递的参数不够,程序直接退出
System.exit(100);
}
//指定Job需要的配置参数
Configuration conf = new Configuration();
//创建一个Job
Job job = Job.getInstance(conf);
//注意了:这一行必须设置,否则在集群中执行的时候是找不到WordCountJob这个类的
job.setJarByClass(WordCountJobSeq.class);
//指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job,new Path(args[0]));
//指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
//设置输入数据处理类,选择SequeceFile小文件输入
job.setInputFormatClass(SequenceFileInputFormat.class);
//指定reduce相关的代码
job.setReducerClass(MyReducer.class);
//指定k3的类型
job.setOutputKeyClass(Text.class);
//指定v3的类型
job.setOutputValueClass(LongWritable.class);
//提交job
job.waitForCompletion(true);
}catch(Exception e){
e.printStackTrace();
}
}
}
4.8.4 数据倾斜问题

若有收获,就点个赞吧
0 人点赞
