笔记内容选自慕课网《大数据开发工程师》体系课
9.1 什么是Spark?
- Spark是一个用于大规模数据处理的统一计算引擎
- 可以做MapReduce的离线数据计算
- 还可以做实时计算
- 还有实现类似Hive的SQL计算
- Spark中一个最重要的特性就是基于内存进行计算
- 从而让它的速度可以达到 MapReduce 的几十倍甚至上百倍
9.1.1 Spark的特点?
- Speed:速度快
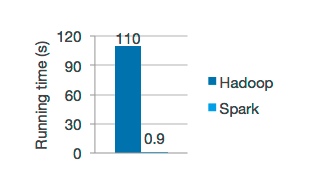
由于Spark是基于内存进行计算的,所以它的计算性能理论上可以比MapReduce快100倍
Spark使用最先进的DAG调度器、查询优化器和物理执行引擎,实现了高性能的批处理和流处理
注意:批处理其实就是离线计算,流处理就是实时计算,只是说法不一样罢了,意思是一样的
- Easy of Use:易用性

Spark的易用性主要体现在两个方面
1. 可以使用多种编程语言快速编写应用程序,例如Java、Scala、Python、R和SQL
2. Spark提供了80多个高阶函数,可以轻松构建Spark任务
- Generality:通用性
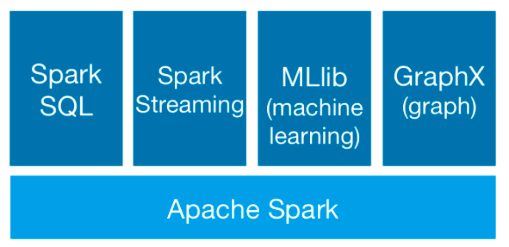
Spark提供了Core、SQL、Streaming、MLlib、GraphX等技术组件
可以一站式地完成大数据领域的离线批处理、SQL交互式查询、流式实时计算,机器学习、图计算等常见的任务
- Runs Everywhere:到处运行

你可以在Hadoop YARN、Mesos或Kubernetes上使用Spark集群
并且可以访问HDFS、Alluxio、Apache Cassandra、Apache HBase、Apache Hive和数百个其它数据源中的数据
9.1.2 Spark vs Hadoop
- 综合能力
- Spark是一个综合性质的计算引擎
- Hadoop既包含MapReduce(计算),还包含HDFS(存储)和YARN(资源管理)
- 计算模型
- Spark任务可以包含多个计算操作,轻松实现复杂迭代计算
- HadoopMap中ReduceReduce任务只包含Map和阶段Reduce阶段,不够灵活
- 处理速度
- Spark任务的数据是存放在内存中的
- 而 Hadoop中 Map Reduce 任务是基于磁盘的
9.1.3 Hadoop+Spark
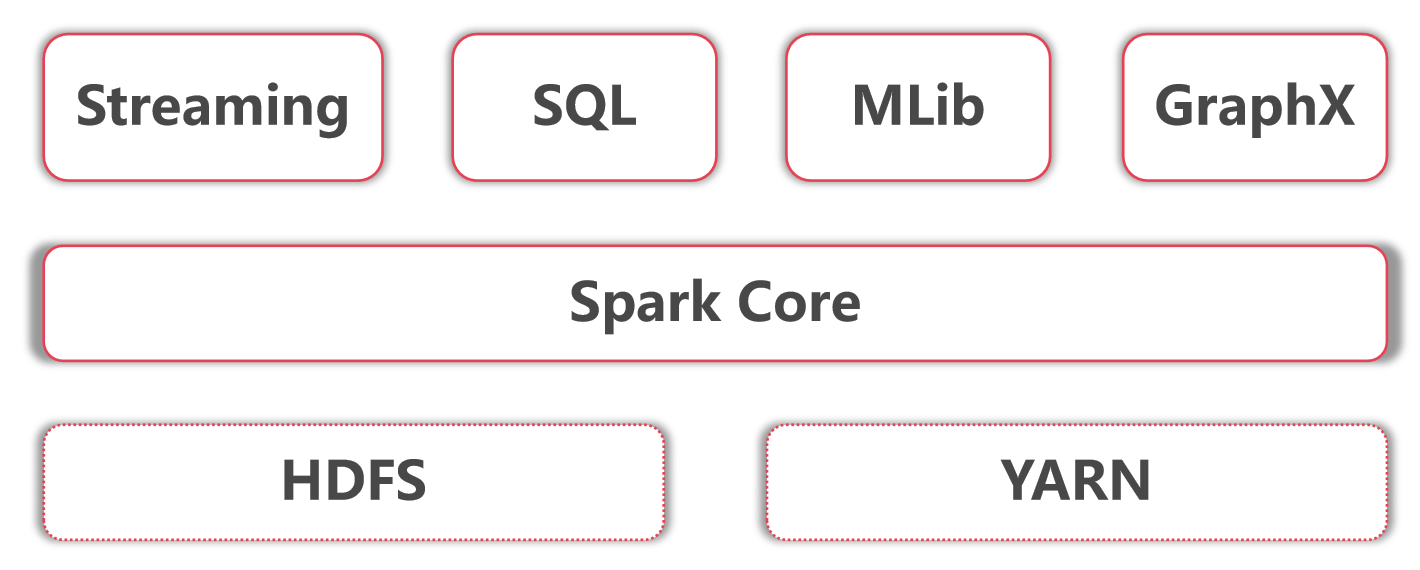
- 底层是Hadoop的HDFS和YARN
- Spark core指的是Spark的离线批处理
- Spark Streaming指的是Spark的实时流计算
- SparkSQL指的是Spark中的SQL计算
- Spark Mllib指的是Spark中的机器学习库,这里面集成了很多机器学习算法
- Spark GraphX是指图计算
9.1.4 Spark的应用场景
- 低延时的海量数据计算需求
- 这个说的就是针对Spark core的应用
- 低延时SQL交互查询需求
- 这个说的就是针对Spark SQL的应用
- 准实时(秒级)海量数据计算需求
- 这个说的就是针对Spark Streaming的应用
9.1.5 Spark集群安装部署
- 下载地址:https://archive.apache.org/dist/spark/
- Standalone:独立集群
- ON YARN:共用 Hadoop集群资源【推荐使用】
进入目录
cd spark-2.4.3-bin-hadoop2.7/conf
给配置改名
mv spark-env.sh.template spark-env.sh
修改配置
vi spark-env.sh … export JAVA_HOME=/data/soft/jdk1.8 export HADOOP_CONF_DIR=/data/soft/hadoop-3.2.0/etc/hadoop
配置SPARK_HOME环境变量
vi /etc/profile … export JAVA_HOME=/data/soft/jdk1.8 export HADOOP_HOME=/data/soft/hadoop-3.2.0 export HIVE_HOME=/data/soft/apache-hive-3.1.2-bin export SPARK_HOME=/data/soft/spark-2.4.3-bin-hadoop2.7 export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$SPARK_HOME/bin:$PATH
source /etc/profile
切换bigdata01启动Hadoop集群
[root@bigdata01 soft]# /data/soft/hadoop-3.2.0/sbin/start-all.sh
切换bigdata04客户端节点,启动spark
cd /data/soft/spark-2.4.3-bin-hadoop2.7 [root@bigdata04 spark-2.4.3-bin-hadoop2.7]# bin/spark-submit —class org.apache.spark.examples.SparkPi —master yarn —deploy-mode cluster examples/jars/spark-examples_2.11-2.4.3.jar 2
- 访问:[http://bigdata01:8088/cluster](http://bigdata01:8088/cluster)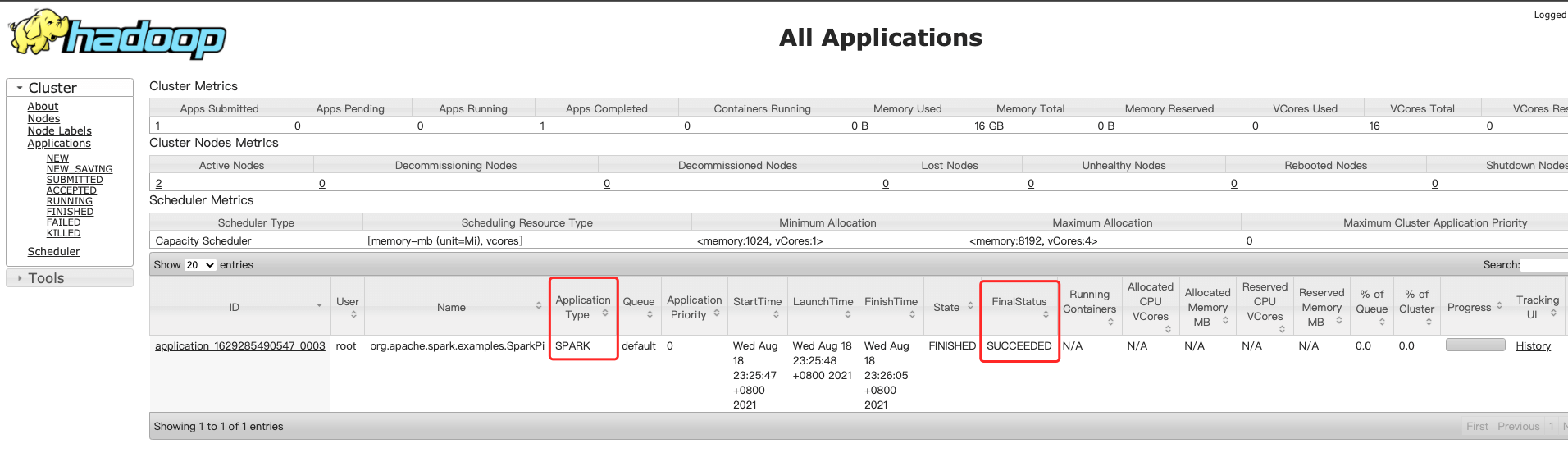<a name="nL8Xi"></a>## 9.2 Spark的底层实现<a name="UU260"></a>### 9.2.1 Spark的工作原理1. 首先通过Spark客户端**提交任务到Spark集群**1. 然后Spark任务在执行的时候会**读取数据源HDFS中的数据**,**将数据加载到内存中**,**转化为RDD**1. 然后针**对RDD调用一些高阶函数对数据进行处理**, 中间可以**调用多个高阶函数**1. 此时经过flatmap计算之后,**前面RDD的数据传输到后面节点上面这个过程是不需要经过shuffle的**,可以**通过网络直接拷贝过去**1. **RDD节点是一一对应的**,如节点1的数据拷贝→节点4,节点2的数据拷贝→节点51. 最终把计算出来的**结果数据写到HDFS中**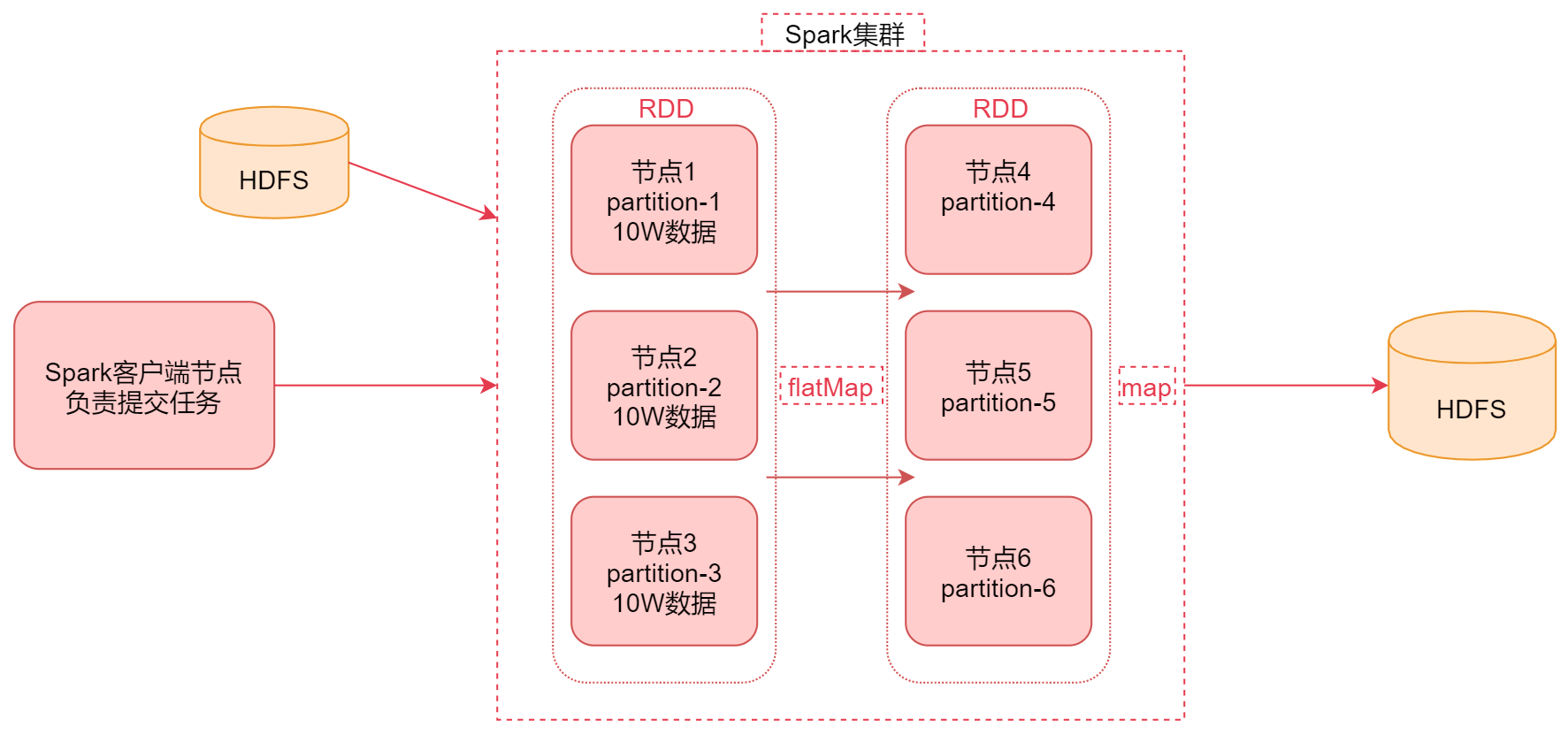<a name="e7atm"></a>### 9.2.2 什么是RDD?- RDD通常通过Hadoop上的文件- 即**HDFS文件进行创建**- 也可以**通过程序中的集合来创建**- 还可以**通过其他数据源创建**- RDD是Spark提供的核心抽象- 全称为 **Resillient Distributed Dataset**- 即 **弹性分布式数据集**- RDD的特点- **弹性**- RDD数据默认情况下存放在内存中,但是在**内存资源不足时**, Spark也会**自动将RDD数据写入磁盘**- **分布式**- RDD在抽象上来说**是一种元素数据的集合**,它是**被分区的**,**每个分区分布在集群中的不同节点上**,从而让RDD中的数据**可以被并行操作**- **容错性**- RDD最重要的特性就是提供了容错性,可以**自动从节点失败中恢复过来**<a name="rLrSL"></a>### 9.2.3 Spark架构相关进程- Driver- 编写的Spark程序由Driver进程负责执行- Driver进程所在的节点可以是Spark集群的某一个节点或者就是我们提交Spark程序的客户端节点- Master- 集群的主节点中启动的进程- 主要负责集群资源的管理和分配,还有集群的监控等- Worker- 集群的从节点中启动的进程- 主要负责启动其它进程来执行具体数据的处理和计算任务- Executor- 由Worker负责启动的进程- 主要为了执行数据处理和计算- Task- 由Executor负责启动的线程- 它主要负责执行数据处理和计算,它是真正干活的- flatmap、map那些任务具体执行的时候,最终就会转化成这种Task<a name="X4g5q"></a>### 9.2.4 Spark架构原理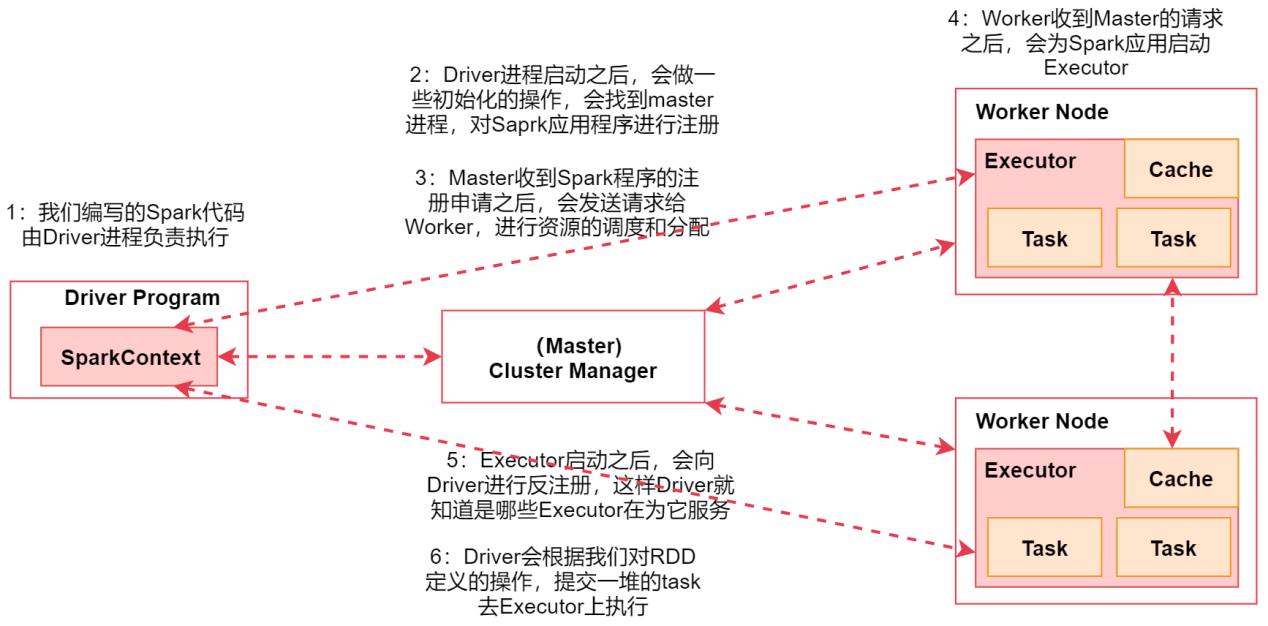1. 首先我们在spark的客户端机器上通过driver进程执行我们的Spark代码 当我们通过spark-submit脚本提交Spark任务的时候Driver进程就启动了。1. Driver进程启动之后,会做一些初始化的操作,会找到集群master进程,对Spark应用程序进行注册1. 当Master收到Spark程序的注册申请之后,会发送请求给Worker,进行资源的调度和分配1. Worker收到Master的请求之后,会为Spark应用启动Executor进程会启动一个或者多个Executor,具体启动多少个,会根据你的配置来启动1. Executor启动之后,会向Driver进行反注册,这样Driver就知道哪些Executor在为它服务了1. Driver会根据我们对RDD定义的操作,提交一堆的task去Executor上执行task里面执行的其实就是具体的map、flatMap这些操作<a name="E74RI"></a>## 9.3 Spark上手体验<a name="lx27N"></a>### 9.3.1 WordCount For Scala- 计算每个单词出现的次数<a name="LkqQj"></a>#### 1、准备数据```basicvi hello.txthello youhello me
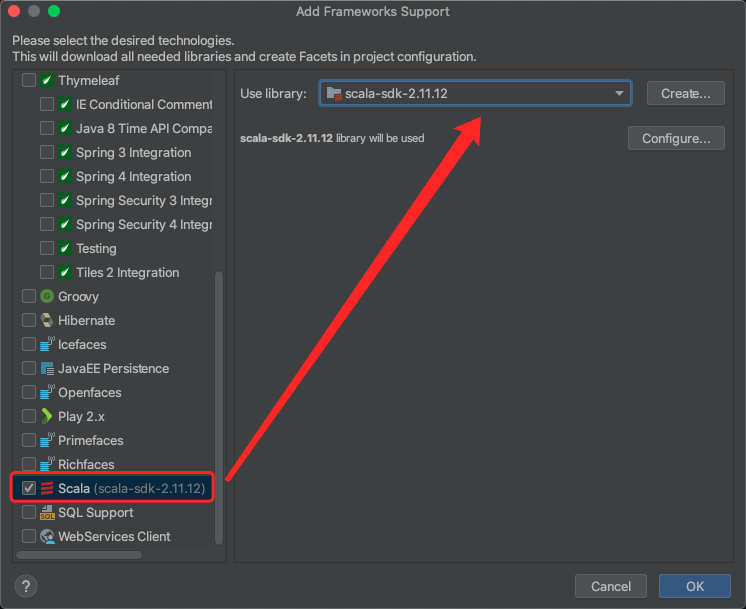
2、创建空的Maven项目,引入Scala
3、引入依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.4.3</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.68</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>2.4.3</version></dependency>
4、编写Scala操作spark的代码
package com.jade.scala
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:单词计数
* Created by xuwei
*/
object WordCountScala {
def main(args: Array[String]): Unit = {
//第一步:创建SparkContext
val conf = new SparkConf()
conf.setAppName("WordCountScala")//设置任务名称
.setMaster("local")//local表示在本地测试执行
val sc = new SparkContext(conf)
//第二步:加载数据
var path = "/Users/angel/Desktop/data/hello.txt"
if(args.length==1){
path = args(0)
}
val linesRDD = sc.textFile(path)
//第三步:对数据进行切割,把一行数据切分成一个一个的单词
val wordsRDD = linesRDD.flatMap(_.split(" "))
//第四步:迭代words,将每个word转换为(word,1)这种形式
val pairRDD = wordsRDD.map((_,1))
//第五步:根据key(其实就是word)进行分组聚合统计
val wordCountRDD = pairRDD.reduceByKey(_ + _)
//第六步:将结果打印到控制台
//注意:只有当任务执行到这一行代码的时候,任务才会真正开始执行计算
//如果任务中没有这一行代码,前面的所有算子是不会执行的
wordCountRDD.foreach(wordCount=>println(wordCount._1+"--"+wordCount._2))
//第七步:停止SparkContext
sc.stop()
}
}
5、关键步骤具体分析
//第二步:加载数据
val linesRDD = sc.textFile("D:\\hello.txt")
linesRDD中的数据是这样的:
hello you
hello me
//第三步:对数据进行切割,把一行数据切分成一个一个的单词
val wordsRDD = linesRDD.flatMap(_.split(" "))
wordsRDD中的数据是这样的:
hello
you
hello
me
//第四步:迭代words,将每个word转换为(word,1)这种形式
val pairRDD = wordsRDD.map((_,1))
pairRDD中的数据是这样的:
(hello,1)
(you,1)
(hello,1)
(me,1)
//第五步:根据key(其实就是word)进行分组聚合统计
val wordCountRDD = pairRDD.reduceByKey(_ + _)
wordCountRDD中的数据是这样的:
(hello,2)
(you,1)
(me,1)
9.3.2 WordCount For Java
package com.jade.java;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* 需求:单词计数
* Created by xuwei
*/
public class WordCountJava {
public static void main(String[] args) {
//第一步:创建JavaSparkContext
SparkConf conf = new SparkConf();
conf.setAppName("WordCountJava").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
//第二步:加载数据
String path = "/Users/angel/Desktop/data/hello.txt";
if(args.length==1){
path = args[0];
}
JavaRDD<String> linesRDD = sc.textFile(path);
//第三步:对数据进行切割,把一行数据切分成一个一个的单词
//注意:FlatMapFunction的泛型,第一个参数表示输入数据类型,第二个表示是输出数据类型
JavaRDD<String> wordsRDD = linesRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
//第四步:迭代words,将每个word转换为(word,1)这种形式
//注意:PairFunction的泛型,第一个参数是输入数据类型
//第二个是输出tuple中的第一个参数类型,第三个是输出tuple中的第二个参数类型
//注意:如果后面需要使用到....ByKey,前面都需要使用mapToPair去处理
JavaPairRDD<String, Integer> pairRDD = wordsRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
//第五步:根据key(其实就是word)进行分组聚合统计
JavaPairRDD<String, Integer> wordCountRDD = pairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
//第六步:将结果打印到控制台
wordCountRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tup) throws Exception {
System.out.println(tup._1+"--"+tup._2);
}
});
//第七步:停止SparkContext
sc.stop();
}
}
9.3.3 Spark任务的三种提交方式
- 直接在idea中执行,方便在本地环境调试代码
- 使用 spark-submit,提交到集群执行【实际工作中使用】
- 使用 spark-shell,方便在集群环境调试代码
1、在maven添加打包插件
<build>
<plugins>
<!-- java编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!-- scala编译插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.1.6</version>
<configuration>
<scalaCompatVersion>2.11</scalaCompatVersion>
<scalaVersion>2.11.12</scalaVersion>
</configuration>
<executions>
<execution>
<id>compile-scala</id>
<phase>compile</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>test-compile-scala</id>
<phase>test-compile</phase>
<goals>
<goal>add-source</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 打包插件 -->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2、过滤掉依赖打包
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.68</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.3</version>
<scope>provided</scope>
</dependency>
3、注释Java和Scala代码中的本地测试方法
//local表示在本地测试执行
//.setMaster("local")
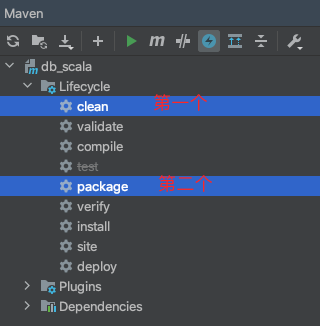
4、打包编译
5、创建文件夹,上传包
[root@bigdata04 /]# mkdir /data/soft/sparkjars
6、编写Spark-Submit脚本
[root@bigdata04 sparkjars]# vi wordCountJob.sh
spark-submit \
--class com.jade.scala.WordCountScala \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--num-executors 1 \
db_scala-1.0-SNAPSHOT-jar-with-dependencies.jar \
hdfs://bigdata01:9000/test/hello.txt
7、切换bigdata01启动Hadoop集群和historyserver进程
[root@bigdata01 ~]# /data/soft/hadoop-3.2.0/sbin/start-all.sh
[root@bigdata01 ~]# /data/soft/hadoop-3.2.0/bin/mapred --daemon start historyserver
[root@bigdata02 ~]# /data/soft/hadoop-3.2.0/bin/mapred --daemon start historyserver
[root@bigdata03 ~]# /data/soft/hadoop-3.2.0/bin/mapred --daemon start historyserver
8、切换bigdata04启动脚本
[root@bigdata04 sparkjars]# sh -x wordCountJob.sh
9、查看结果
- 访问:http://bigdata01:8088/cluster/apps
- 任务会被提交到YARN集群中,可以看到任务执行成功了
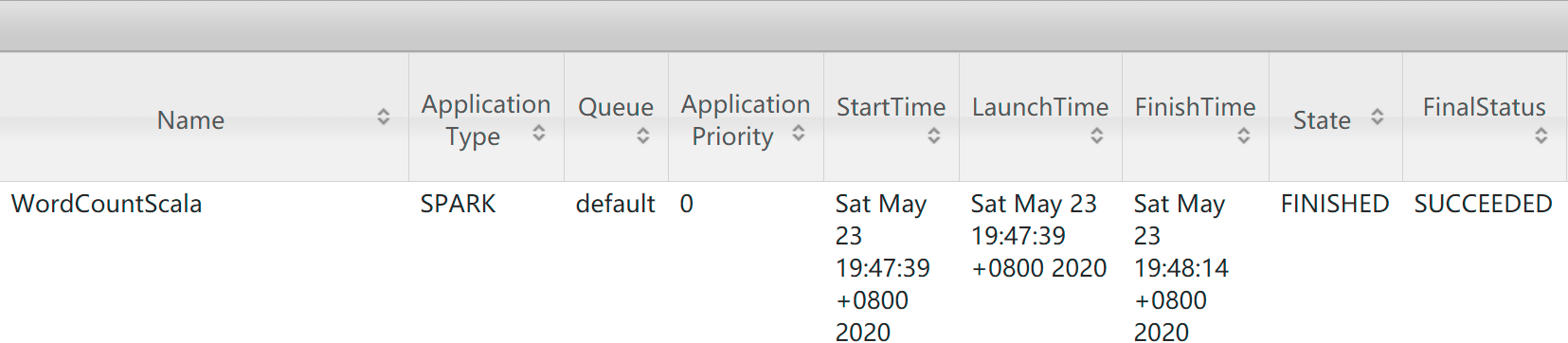
9.3.4 Spark提交任务之Spark-Shell
- 使用Local模式开启本地集群
- 使用on yarn模式,「比较常用」
1、local模式
[root@bigdata04 /]# spark-shell
2021-08-20 18:39:22,969 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://bigdata04:4040
Spark context available as 'sc' (master = local[*], app id = local-1629455973389).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_202)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
2、On Yarn模式
[root@bigdata04 /]# spark-shell --master yarn --deploy-mode client
2021-08-20 19:09:10,832 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
2021-08-20 19:09:19,176 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
Spark context Web UI available at http://bigdata04:4040
Spark context available as 'sc' (master = yarn, app id = application_1629453518219_0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_202)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
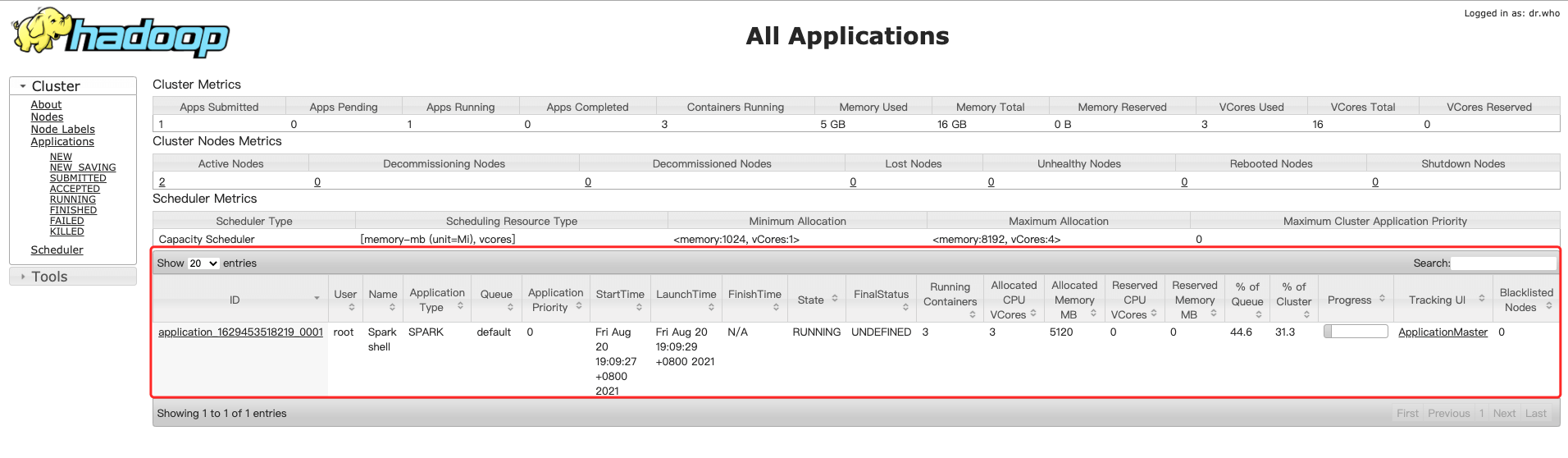
- 这个时候执行的代码就是在YARN上执行的了
```scala
scala> val linesRDD = sc.textFile(“/test/hello.txt”)
linesRDD: org.apache.spark.rdd.RDD[String] = /test/hello.txt MapPartitionsRDD[1] at textFile at
:24
scala> val wordsRDD = linesRDD.flatMap(_.split(“ “))
wordsRDD: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at
scala> val pairRDD = wordsRDD.map((_,1))
pairRDD: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at
scala> val wordCountRDD = pairRDD.reduceByKey( + )
wordCountRDD: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at
scala> wordCountRDD.foreach(wordCount=>println(wordCount._1+”—“+wordCount._2)) [Stage 0:> (0 [Stage 0:===================> (1 [Stage 0:=======================================> (2
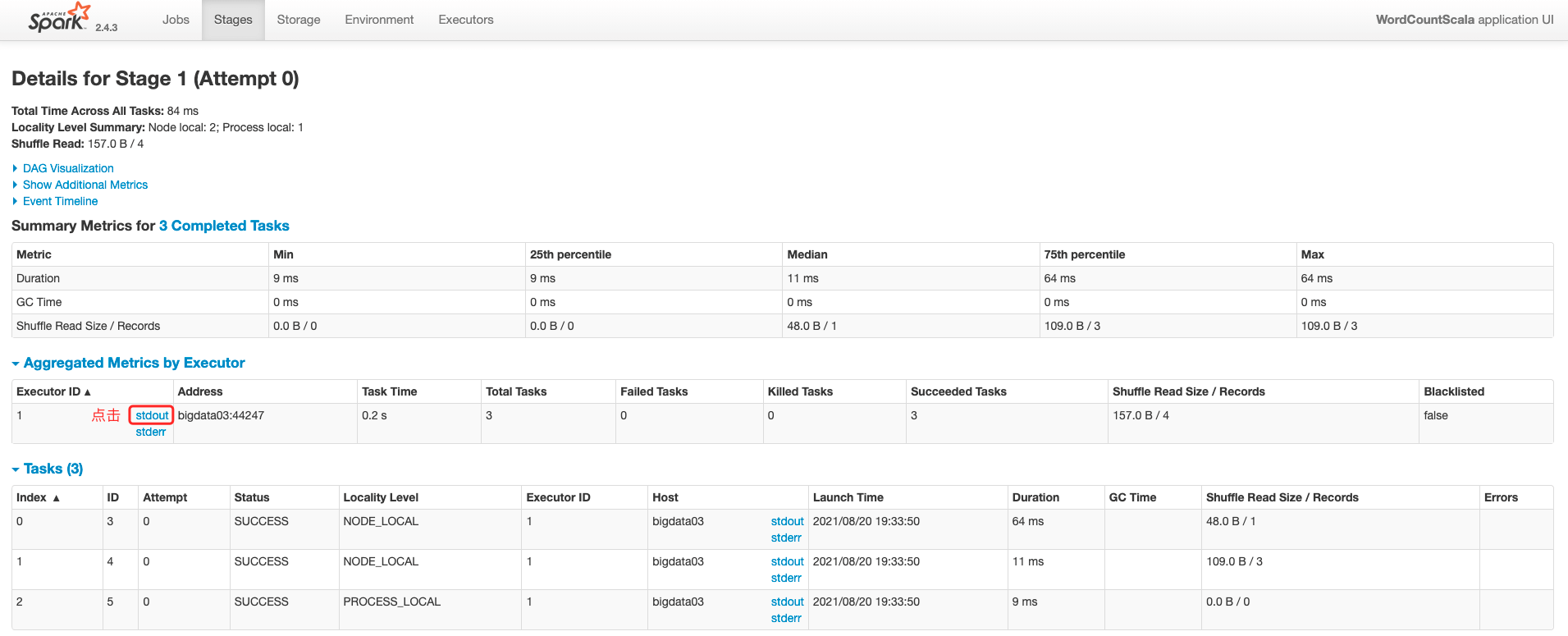
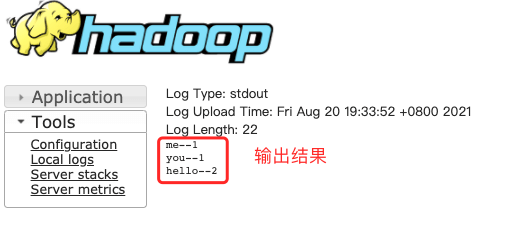
**_「注意:On Yarn模式是查看不到输出结果的,需要到Yarn查看日志」_**
<a name="ydRSf"></a>
#### 3、Spark开启historyServer服务
```basic
# 切换目录到conf
[root@bigdata04 /]# cd /data/soft/spark-2.4.3-bin-hadoop2.7/conf
# 改配置名
mv spark-defaults.conf.template spark-defaults.conf
# 添加第一个配置信息
vi spark-defaults.conf
...
spark.eventLog.enabled=true
spark.eventLog.compress=true
spark.eventLog.dir=hdfs://bigdata01:9000/tmp/logs/root/logs
spark.history.fs.logDirectory=hdfs://bigdata01:9000/tmp/logs/root/logs
spark.yarn.historyServer.address=http://bigdata04:18080
# 添加第二个配置信息
vi spark-env.sh
...
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://bigdata01:9000/tmp/logs/root/logs"
「注意:在哪个节点上启动 spark 的 historyserver 进程, spark.yarn.historyServer.address 的值里 面就指定哪个节点的主机名信息」
4、启动historyServer服务
# 启动服务
[root@bigdata04 /]# /data/soft/spark-2.4.3-bin-hadoop2.7/sbin/start-history-server.sh
# 验证服务
[root@bigdata04 /]# jps
7654 Jps
7613 HistoryServer
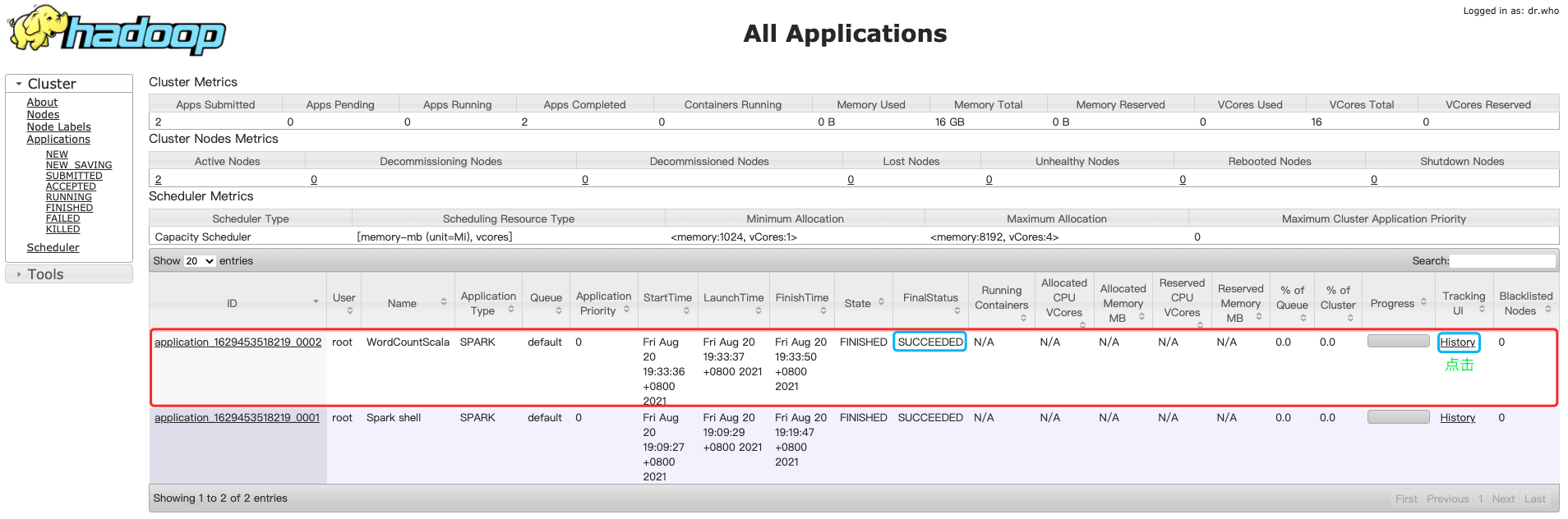
5、启动spark脚本
# 进入目录
[root@bigdata04 /]# cd /data/soft/sparkjars
# 启动脚本
[root@bigdata04 /]# sh -x wordCountJob.sh

9.4 Spark RDD编程实战
9.4.1 创建RDD的三种方式
- RDD是 Spark编程的核心,在进行 Spark编程时,首要任务是创建一个初始的RDD
- Spark提供三种创建RDD方式
- 集合
- 主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构 造一些测试数据,来测试后面的spark应用程序的流程
- 本地文件
- 主要用于临时性地处理一些存储了大量数据的文件
- HDFS文件「工作常用」
- 是最常用的生产环境的处理方式,主要可以针对HDFS上存储的数据,进 行离线批处理操作
- 集合
9.4.2 集合创建RDD
- 通过 SparkContextparallelize的()方法将集合转化为RDD
- 可以通过 parallelize() 方法的第二个参数来设置RDD的partition数量
- Spark会为每一个partition运行一个task来进行处理
1、Scala实现
import org.apache.spark.{SparkConf, SparkContext}
/**
* @description: 在本地用数组创建RDD
* @projectName: db_scala
* @since: com.jade.scala
* @author: jade
* @createTime: 2021/8/24 6:59 下午
*/
object CreateRddByArrayScala {
def main(args: Array[String]): Unit = {
//创建SparkContext
val conf = new SparkConf()
conf.setAppName("CreateRddByArrayScala").setMaster("local")
val sc = new SparkContext(conf)
//创建集合
val arr = Array(1,2,3,4,5)
//基于集合创建RDD
val rdd = sc.parallelize(arr)
//对集合中的数据求和
val sum = rdd.reduce(_ + _)
//注意:这行println代码是在driver进程中执行的
println(sum)
}
}
2、Java实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import java.util.Arrays;
import java.util.List;
/**
* 需求:使用集合创建RDD
* Created by jade
*/
public class CreateRddByArrayJava {
public static void main(String[] args) {
//创建JavaSparkContext
SparkConf conf = new SparkConf();
conf.setAppName("CreateRddByArrayJava")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
//创建集合
List<Integer> arr = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> rdd = sc.parallelize(arr);
Integer sum = rdd.reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
System.out.println(sum);
sc.stop();
}
}
9.4.3 HDFS文件创建RDD
- 通过SparkContext的textFile()方法,可以针对本地文件或HDFS文件创建RDD
- textFile() 方法支持针对目录、压缩文件以及通配符创建RDD
- Spark默认会为HDFS文件的每一个Block创建一个partition
- 也可以通过textFile()的第二个参数手动设置分区数量
- 只能比Block数量多,不能比Block数量少
1、Scala实现
import org.apache.spark.{SparkConf, SparkContext}
/**
* @description: 用文件创建RDD
* @projectName: db_scala
* @since: com.jade.scala
* @author: jade
* @createTime: 2021/8/24 7:05 下午
*/
object CreateRddByFileScala {
def main(args: Array[String]): Unit = {
//创建SparkContext
val conf = new SparkConf()
conf.setAppName("CreateRddByFileScala")
.setMaster("local")
val sc = new SparkContext(conf)
// 本地文件
var path = "/Users/angel/Desktop/data/hello.txt"
// HDFS文件
path = "hdfs://bigdata01:9000/test/hello.txt"
//读取文件数据,可以在textFile中指定生成的RDD的分区数量
val rdd = sc.textFile(path,2)
//获取每一行数据的长度,计算文件内数据的总长度
val length = rdd.map(_.length).reduce(_ + _)
println(length)
sc.stop()
}
}
2、Java实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
/**
* 需求:通过文件创建RDD
* Created by jade
*/
public class CreateRddByFileJava {
public static void main(String[] args) {
//创建JavaSparkContext
SparkConf conf = new SparkConf();
conf.setAppName("CreateRddByArrayJava")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
String path = "/Users/angel/Desktop/data/hello.txt";
path = "hdfs://bigdata01:9000/test/hello.txt";
JavaRDD<String> rdd = sc.textFile(path, 2);
//获取每一行数据的长度
JavaRDD<Integer> lengthRDD = rdd.map(new Function<String, Integer>() {
@Override
public Integer call(String line) throws Exception {
return line.length();
}
});
//计算文件内数据的总长度
Integer length = lengthRDD.reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
System.out.println(length);
sc.stop();
}
}
9.4.4 Transformation和Action
- Spark支持两种RDD操作,也称为算子
- Transformation
- Action
- Transformation会针对已有的RDD创建一个新的RDD
- 比如:map算子、flatMap算子、filter算子
- Action主要对RDD进行最后的操作
- 比如:遍历、reduce算子、保存到文件等
- 并且还可以把结果返回给Driver程序
- 有一个特性
- lazy
- transformation 是不会触发 spark 任务的执行, 它们只是记录了对 RDD 所做的操作, 不会执行
- 只有当transformation之后,接着执行了一个action操作,那么所有的transformation才会执行
- park通过lazy这种特性,来进行底层的spark任务执行的优化,避免产生过多中间结果。
- lazy
- Action的特性
- 执行Action操作才会触发一个Spark Job的运行,从而触发这个Action之前所有的Transformation的执行
1、常用Transformation
| 算子 | 介绍 |
|---|---|
| map | 将RDD中的每个元素进行处理,一进一出 |
| filter | 对RDD中每个元素进行判断,返回true则保留 |
| flatMap | 与map类似,但是每个元素都可以返回一个或多个新元素 |
| groupByKey | 根据key进行分组,每个key对应一个Iterable |
| reduceByKey | 对每个相同key对应的value进行reduce操作 |
| sortByKey | 对每个相同key对应的value进行排序操作(全局排序) |
| join | 对两个包含 |
| distinct | 对RDD中的元素进行全局去重 |
2、Transformation之Scala
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:Transformation实战
* map:对集合中每个元素乘以2
* filter:过滤出集合中的偶数
* flatMap:将行拆分为单词
* groupByKey:对每个大区的主播进行分组
* reduceByKey:统计每个大区的主播数量
* sortByKey:对主播的音浪收入排序
* join:打印每个主播的大区信息和音浪收入
* distinct:统计当天开播的大区信息
*/
object TransformationOpScala {
def main(args: Array[String]): Unit = {
val sc = getSparkContext
//map:对集合中每个元素乘以2
//mapOp(sc)
//filter:过滤出集合中的偶数
//filterOp(sc)
//flatMap:将行拆分为单词
//flatMapOp(sc)
//groupByKey:对每个大区的主播进行分组
//groupByKeyOp(sc)
//groupByKeyOp2(sc)
//reduceByKey:统计每个大区的主播数量
//reduceByKeyOp(sc)
//sortByKey:对主播的音浪收入排序
//sortByKeyOp(sc)
//join:打印每个主播的大区信息和音浪收入
//joinOp(sc)
//distinct:统计当天开播的大区信息
//distinctOp(sc)
sc.stop()
}
def distinctOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array((150001,"US"),(150002,"CN"),(150003,"CN"),(150004,"IN")))
//由于是统计开播的大区信息,需要根据大区信息去重,所以只保留大区信息
dataRDD.map(_._2).distinct().foreach(println(_))
}
def joinOp(sc: SparkContext): Unit = {
val dataRDD1 = sc.parallelize(Array((150001,"US"),(150002,"CN"),(150003,"CN"),(150004,"IN")))
val dataRDD2 = sc.parallelize(Array((150001,400),(150002,200),(150003,300),(150004,100)))
val joinRDD = dataRDD1.join(dataRDD2)
//joinRDD.foreach(println(_))
joinRDD.foreach(tup=>{
//用户id
val uid = tup._1
val area_gold = tup._2
//大区
val area = area_gold._1
//音浪收入
val gold = area_gold._2
println(uid+"\t"+area+"\t"+gold)
})
}
def sortByKeyOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array((150001,400),(150002,200),(150003,300),(150004,100)))
//由于需要对音浪收入进行排序,所以需要把音浪收入作为key,在这里要进行位置和互换
/*dataRDD.map(tup=>(tup._2,tup._1))
.sortByKey(false)//默认是正序,第一个参数为true,想要倒序需要把这个参数设置为false
.foreach(println(_))*/
//sortBy的使用:可以动态指定排序字段,比较灵活
dataRDD.sortBy(_._2,false).foreach(println(_))
dataRDD.sortByKey()
}
def reduceByKeyOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array((150001,"US"),(150002,"CN"),(150003,"CN"),(150004,"IN")))
//由于这个需求只需要使用到大区信息,所以在mao操作的时候只保留大区信息即可
dataRDD.map(tup=>(tup._2,1)).reduceByKey(_ + _).foreach(println(_))
}
def groupByKeyOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array((150001,"US"),(150002,"CN"),(150003,"CN"),(150004,"IN")))
//需要使用map对tuple中的数据进行位置互换,因为我们需要把大区作为key进行分组操作
//此时的key就是tuple中的第一列,其实在这里就可以把这个tuple认为是一个key-value
//注意:在使用类似于groupByKey这种基于key的算子的时候,需要提前把RDD中的数据组装成tuple2这种形式
//此时map算子之后生成的新的数据格式是这样的:("US",150001)
//如果tuple中的数据列数超过了2列怎么办?看groupByKeyOp2
dataRDD.map(tup=>(tup._2,tup._1)).groupByKey().foreach(tup=>{
//获取大区信息
val area = tup._1
print(area+":")
//获取同一个大区对应的所有用户id
val it = tup._2
for(uid <- it){
print(uid+" ")
}
println()
})
}
/**
* TODO: 考虑使用grouBy去实现
* @param sc
*/
def groupByKeyOp2(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array((150001, "US","male"), (150002, "CN","female"), (150003, "CN","male"), (150004, "IN","female")))
//如果tuple中的数据列数超过了2列怎么办?
//把需要作为key的那一列作为tuple2的第一列,剩下的可以再使用一个tuple2包装一下
//此时map算子之后生成的新的数据格式是这样的:("US",(150001,"male"))
//注意:如果你的数据结构比较负责,你可以在执行每一个算子之后都调用foreach打印一下,确认数据的格式
dataRDD.map(tup=>(tup._2,(tup._1,tup._3))).groupByKey().foreach(tup=>{
//获取大区信息
val area = tup._1
print(area+":")
//获取同一个大区对应的所有用户id和性别信息
val it = tup._2
for((uid,sex) <- it){
print("<"+uid+","+sex+"> ")
}
println()
})
}
def flatMapOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array("good good study","day day up"))
dataRDD.flatMap(_.split(" ")).foreach(println(_))
}
def filterOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
//满足条件的保留下来
dataRDD.filter(_ % 2 == 0).foreach(println(_))
}
def mapOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
dataRDD.map(_ * 2).foreach(println(_))
}
def getSparkContext = {
val conf = new SparkConf()
conf.setAppName("WordCountScala")
.setMaster("local")
new SparkContext(conf)
}
}
3、Transformation之Java
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.*;
import scala.Tuple2;
import scala.Tuple3;
import java.util.Arrays;
import java.util.Iterator;
/**
* 需求:Transformation实战
* map:对集合中每个元素乘以2
* filter:过滤出集合中的偶数
* flatMap:将行拆分为单词
* groupByKey:对每个大区的主播进行分组
* reduceByKey:统计每个大区的主播数量
* sortByKey:对主播的音浪收入排序
* join:打印每个主播的大区信息和音浪收入
* distinct:统计当天开播的大区信息
*/
public class TransformationOpJava {
public static void main(String[] args) {
JavaSparkContext sc = getSparkContext();
//map:对集合中每个元素乘以2
//mapOp(sc);
//filter:过滤出集合中的偶数
//filterOp(sc);
//flatMap:将行拆分为单词
//flatMapOp(sc);
//groupByKey:对每个大区的主播进行分组
//groupByKeyOp(sc);
//groupByKeyOp2(sc);
//reduceByKey:统计每个大区的主播数量
//reduceByKeyOp(sc);
//sortByKey:对主播的音浪收入排序
//sortByKeyOp(sc);
//join:打印每个主播的大区信息和音浪收入
//joinOp(sc);
//distinct:统计当天开播的大区信息
//distinctOp(sc);
sc.stop();
}
private static void distinctOp(JavaSparkContext sc) {
Tuple2<Integer, String> t1 = new Tuple2<>(150001, "US");
Tuple2<Integer, String> t2 = new Tuple2<>(150002, "CN");
Tuple2<Integer, String> t3 = new Tuple2<>(150003, "CN");
Tuple2<Integer, String> t4 = new Tuple2<>(150004, "IN");
JavaRDD<Tuple2<Integer, String>> dataRDD = sc.parallelize(Arrays.asList(t1, t2, t3, t4));
dataRDD.map(new Function<Tuple2<Integer, String>, String>() {
@Override
public String call(Tuple2<Integer, String> tup) throws Exception {
return tup._2;
}
}).distinct().foreach(new VoidFunction<String>() {
@Override
public void call(String area) throws Exception {
System.out.println(area);
}
});
}
private static void joinOp(JavaSparkContext sc) {
Tuple2<Integer, String> t1 = new Tuple2<>(150001, "US");
Tuple2<Integer, String> t2 = new Tuple2<>(150002, "CN");
Tuple2<Integer, String> t3 = new Tuple2<>(150003, "CN");
Tuple2<Integer, String> t4 = new Tuple2<>(150004, "IN");
Tuple2<Integer, Integer> t5 = new Tuple2<Integer, Integer>(150001, 400);
Tuple2<Integer, Integer> t6 = new Tuple2<Integer, Integer>(150002, 200);
Tuple2<Integer, Integer> t7 = new Tuple2<Integer, Integer>(150003, 300);
Tuple2<Integer, Integer> t8 = new Tuple2<Integer, Integer>(150004, 100);
JavaRDD<Tuple2<Integer, String>> dataRDD1 = sc.parallelize(Arrays.asList(t1, t2, t3, t4));
JavaRDD<Tuple2<Integer, Integer>> dataRDD2 = sc.parallelize(Arrays.asList(t5, t6, t7, t8));
JavaPairRDD<Integer, String> dataRDD1Pair = dataRDD1.mapToPair(new PairFunction<Tuple2<Integer, String>, Integer, String>() {
@Override
public Tuple2<Integer, String> call(Tuple2<Integer, String> tup)
throws Exception {
return new Tuple2<Integer, String>(tup._1, tup._2);
}
});
JavaPairRDD<Integer, Integer> dataRDD2Pair = dataRDD2.mapToPair(new PairFunction<Tuple2<Integer, Integer>, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(Tuple2<Integer, Integer> tup)
throws Exception {
return new Tuple2<Integer, Integer>(tup._1, tup._2);
}
});
dataRDD1Pair.join(dataRDD2Pair).foreach(new VoidFunction<Tuple2<Integer, Tuple2<String, Integer>>>() {
@Override
public void call(Tuple2<Integer, Tuple2<String, Integer>> tup)
throws Exception {
System.out.println(tup);
}
});
}
private static void sortByKeyOp(JavaSparkContext sc) {
Tuple2<Integer, Integer> t1 = new Tuple2<Integer, Integer>(150001, 400);
Tuple2<Integer, Integer> t2 = new Tuple2<Integer, Integer>(150002, 200);
Tuple2<Integer, Integer> t3 = new Tuple2<Integer, Integer>(150003, 300);
Tuple2<Integer, Integer> t4 = new Tuple2<Integer, Integer>(150004, 100);
JavaRDD<Tuple2<Integer, Integer>> dataRDD = sc.parallelize(Arrays.asList(t1, t2, t3, t4));
/*dataRDD.mapToPair(new PairFunction<Tuple2<Integer, Integer>, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(Tuple2<Integer, Integer> tup)
throws Exception {
return new Tuple2<Integer, Integer>(tup._2,tup._1);
}
}).sortByKey(false).foreach(new VoidFunction<Tuple2<Integer, Integer>>() {
@Override
public void call(Tuple2<Integer, Integer> tup) throws Exception {
System.out.println(tup);
}
});*/
//使用sortBy
dataRDD.sortBy(new Function<Tuple2<Integer, Integer>, Integer>() {
@Override
public Integer call(Tuple2<Integer, Integer> tup) throws Exception {
return tup._2;
}
},false,1).foreach(new VoidFunction<Tuple2<Integer, Integer>>() {
@Override
public void call(Tuple2<Integer, Integer> tup)
throws Exception {
System.out.println(tup);
}
});
}
private static void reduceByKeyOp(JavaSparkContext sc) {
Tuple2<Integer, String> t1 = new Tuple2<>(150001, "US");
Tuple2<Integer, String> t2 = new Tuple2<>(150002, "CN");
Tuple2<Integer, String> t3 = new Tuple2<>(150003, "CN");
Tuple2<Integer, String> t4 = new Tuple2<>(150004, "IN");
JavaRDD<Tuple2<Integer, String>> dataRDD = sc.parallelize(Arrays.asList(t1, t2, t3, t4));
dataRDD.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> tup)
throws Exception {
return new Tuple2<String, Integer>(tup._2,1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
}).foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tup) throws Exception {
System.out.println(tup);
}
});
}
private static void groupByKeyOp(JavaSparkContext sc) {
Tuple2<Integer, String> t1 = new Tuple2<>(150001, "US");
Tuple2<Integer, String> t2 = new Tuple2<>(150002, "CN");
Tuple2<Integer, String> t3 = new Tuple2<>(150003, "CN");
Tuple2<Integer, String> t4 = new Tuple2<>(150004, "IN");
JavaRDD<Tuple2<Integer, String>> dataRDD = sc.parallelize(Arrays.asList(t1, t2, t3, t4));
dataRDD.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> tup)
throws Exception {
return new Tuple2<String, Integer>(tup._2,tup._1);
}
}).groupByKey().foreach(new VoidFunction<Tuple2<String, Iterable<Integer>>>() {
@Override
public void call(Tuple2<String, Iterable<Integer>> tup)
throws Exception {
//获取大区信息
String area = tup._1;
System.out.print(area+":");
//获取同一个大区对应的所用用户id
Iterable<Integer> it = tup._2;
for(Integer uid : it){
System.out.print(uid+" ");
}
System.out.println();
}
});
}
private static void groupByKeyOp2(JavaSparkContext sc) {
Tuple3<Integer, String,String> t1 = new Tuple3<Integer, String,String>(150001, "US","male");
Tuple3<Integer, String,String> t2 = new Tuple3<Integer, String,String>(150002, "CN","female");
Tuple3<Integer, String,String> t3 = new Tuple3<Integer, String,String>(150003, "CN","male");
Tuple3<Integer, String,String> t4 = new Tuple3<Integer, String,String>(150004, "IN","female");
JavaRDD<Tuple3<Integer, String, String>> dataRDD = sc.parallelize(Arrays.asList(t1, t2, t3, t4));
dataRDD.mapToPair(new PairFunction<Tuple3<Integer, String, String>, String, Tuple2<Integer,String>>() {
@Override
public Tuple2<String, Tuple2<Integer, String>> call(Tuple3<Integer, String, String> tup)
throws Exception {
//("US",(150001,"male"))
return new Tuple2<String, Tuple2<Integer, String>>(tup._2(),new Tuple2<Integer, String>(tup._1(),tup._3()));
}
}).groupByKey().foreach(new VoidFunction<Tuple2<String, Iterable<Tuple2<Integer, String>>>>() {
@Override
public void call(Tuple2<String, Iterable<Tuple2<Integer, String>>> tup)
throws Exception {
//获取大区信息
String area = tup._1;
System.out.print(area+":");
//获取同一个大区对应的所用用户id和性别信息
Iterable<Tuple2<Integer, String>> it = tup._2;
for(Tuple2<Integer,String> tu : it){
System.out.print("<"+tu._1+","+tu._2+"> ");
}
System.out.println();
}
});
}
private static void flatMapOp(JavaSparkContext sc) {
JavaRDD<String> dataRDD = sc.parallelize(Arrays.asList("good good study","day day up"));
dataRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
String[] words = line.split(" ");
return Arrays.asList(words).iterator();
}
}).foreach(new VoidFunction<String>() {
@Override
public void call(String word) throws Exception {
System.out.println(word);
}
});
}
private static void filterOp(JavaSparkContext sc) {
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
dataRDD.filter(new Function<Integer, Boolean>() {
@Override
public Boolean call(Integer i1) throws Exception {
return i1 % 2 == 0;
}
}).foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer i1) throws Exception {
System.out.println(i1);
}
});
}
private static void mapOp(JavaSparkContext sc) {
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
dataRDD.map(new Function<Integer, Integer>() {
@Override
public Integer call(Integer i1) throws Exception {
return i1 * 2;
}
}).foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer i1) throws Exception {
System.out.println(i1);
}
});
}
private static JavaSparkContext getSparkContext() {
//创建JavaSparkContext
SparkConf conf = new SparkConf();
conf.setAppName("TransformationOpJava")
.setMaster("local");
return new JavaSparkContext(conf);
}
}
4、常用Action
| 算子 | 介绍 |
|---|---|
| reduce | 聚合计算 |
| collect | 获取元素集合 |
| take(n | 获取前n个元素 |
| count | 获取元素总数 |
| saveAsTextFile | 保存文件 |
| countByKey | 统计相同的key出现多少次 |
| foreach | 迭代遍历元素 |
5、Action之Scala
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:Action实战
* reduce:聚合计算
* collect:获取元素集合
* take(n):获取前n个元素
* count:获取元素总数
* saveAsTextFile:保存文件
* countByKey:统计相同的key出现多少次
* foreach:迭代遍历元素
*/
object ActionOpScala {
def main(args: Array[String]): Unit = {
val sc = getSparkContext
//reduce:聚合计算
//reduceOp(sc)
//collect:获取元素集合
//collectOp(sc)
//take(n):获取前n个元素
//takeOp(sc)
//count:获取元素总数
//countOp(sc)
//saveAsTextFile:保存文件
//saveAsTextFileOp(sc)
//countByKey:统计相同的key出现多少次
//countByKeyOp(sc)
//foreach:迭代遍历元素
//foreachOp(sc)
sc.stop()
}
def foreachOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
//注意:foreach不仅限于执行println操作,这个只是在测试的时候使用的
//实际工作中如果需要把计算的结果保存到第三方的存储介质中,就需要使用foreach
//在里面实现具体向外部输出数据的代码
dataRDD.foreach(println(_))
}
def countByKeyOp(sc: SparkContext): Unit = {
val daraRDD = sc.parallelize(Array(("A",1001),("B",1002),("A",1003),("C",1004)))
//返回的是一个map类型的数据
val res = daraRDD.countByKey()
for((k,v) <- res){
println(k+","+v)
}
}
def saveAsTextFileOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
//指定HDFS的路径信息即可,需要指定一个不存在的目录
dataRDD.saveAsTextFile("hdfs://bigdata01:9000/out001")
}
def countOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
val res = dataRDD.count()
println(res)
}
def takeOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
//从RDD中获取前2个元素
val res = dataRDD.take(2)
for(item <- res){
println(item)
}
}
def collectOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
//collect返回的是一个Array数组
//注意:如果RDD中数据量过大,不建议使用collect,因为最终的数据会返回给Driver进程所在的节点
//如果想要获取几条数据,查看一下数据格式,可以使用take(n)
val res = dataRDD.collect()
for(item <- res){
println(item)
}
}
def reduceOp(sc: SparkContext): Unit = {
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
val num = dataRDD.reduce(_ + _)
println(num)
}
def getSparkContext = {
val conf = new SparkConf()
conf.setAppName("ActionOpScala")
.setMaster("local")
new SparkContext(conf)
}
}
5、Action之Java
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
/**
* 需求:Action实战
* reduce:聚合计算
* collect:获取元素集合
* take(n):获取前n个元素
* count:获取元素总数
* saveAsTextFile:保存文件
* countByKey:统计相同的key出现多少次
* foreach:迭代遍历元素
*/
public class ActionOpJava {
public static void main(String[] args) {
JavaSparkContext sc = getSparkContext();
//reduce:聚合计算
//reduceOp(sc);
//collect:获取元素集合
//collectOp(sc);
//take(n):获取前n个元素
//takeOp(sc);
//count:获取元素总数
//countOp(sc);
//saveAsTextFile:保存文件
//saveAsTextFileOp(sc);
//countByKey:统计相同的key出现多少次
//countByKeyOp(sc);
//foreach:迭代遍历元素
//foreachOp(sc);
sc.stop();
}
private static void foreachOp(JavaSparkContext sc) {
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
dataRDD.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer i) throws Exception {
System.out.println(i);
}
});
}
private static void countByKeyOp(JavaSparkContext sc) {
Tuple2<String, Integer> t1 = new Tuple2<>("A", 1001);
Tuple2<String, Integer> t2 = new Tuple2<>("B", 1002);
Tuple2<String, Integer> t3 = new Tuple2<>("A", 1003);
Tuple2<String, Integer> t4 = new Tuple2<>("C", 1004);
JavaRDD<Tuple2<String, Integer>> dataRDD = sc.parallelize(Arrays.asList(t1, t2, t3, t4));
//想要使用countByKey,需要先使用mapToPair对RDD进行转换
Map<String, Long> res = dataRDD.mapToPair(new PairFunction<Tuple2<String, Integer>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<String, Integer> tup)
throws Exception {
return new Tuple2<String, Integer>(tup._1, tup._2);
}
}).countByKey();
for(Map.Entry<String,Long> entry : res.entrySet()){
System.out.println(entry.getKey()+","+entry.getValue());
}
}
private static void saveAsTextFileOp(JavaSparkContext sc) {
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
dataRDD.saveAsTextFile("hdfs://bigdata01:9000/out002");
}
private static void countOp(JavaSparkContext sc) {
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
long res = dataRDD.count();
System.out.println(res);
}
private static void takeOp(JavaSparkContext sc) {
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
List<Integer> res = dataRDD.take(2);
for(Integer item : res){
System.out.println(item);
}
}
private static void collectOp(JavaSparkContext sc) {
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
List<Integer> res = dataRDD.collect();
for(Integer item : res){
System.out.println(item);
}
}
private static void reduceOp(JavaSparkContext sc) {
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
Integer num = dataRDD.reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
System.out.println(num);
}
private static JavaSparkContext getSparkContext() {
//创建JavaSparkContext
SparkConf conf = new SparkConf();
conf.setAppName("ActionOpJava")
.setMaster("local");
return new JavaSparkContext(conf);
}
}
9.4.5 RDD持久化
1、RDD持久化原理
Spark中有一个非常重要的功能就是可以对RDD进行持久化
- 当对RDD执行持久化操作时,每个节点都会 将自己操作的RDD的partition数据持久化到内存中,并且在之后对该RDD的反复使用中,直接使用内存中缓存的partition数据
- 针对一个 RDD 反复执行多个操作的场景, 就只需要对 RDD 计算一次即可, 后面直接使用该 RDD,而不需要反复计算多次该RDD,特别是对于迭代式算法和快速交互式应用来说,RDD持久化,是非常重要的
- 在该RDD第一次被计算出来时,就会直接缓存在每个节点中
- 而且Spark的持久化机制还是自动容错的,如果持久化的RDD的任何partition数据丢失了,那么Spark会自动通过其源RDD,使用transformation算子重新计算该partition的数据。
- 要持久化一个RDD,只需要调用它的 cache() 或者 persist() 方法即可
- cache()和persist()的区别在于:
- cache() 是 persist() 的一种简化方式, cache() 的底层就是调用的 persist() 的无参版本
- 也就是调用 persist(MEMORY_ONLY),将数据持久化到内存中
- 如果需要从内存中清除缓存,那么可以使用 unpersist() 方法
2、RDD持久化策略
| 策略 | 介绍 | | —- | —- | | MEMORY_ONLY | 以非序列化的方式持久化在JVM内存中 | | MEMORY_AND_DISK | 同上,但是当某些partition无法存储在内存中时,会持久化到磁盘中 | | MEMORY_ONLY_SER | 同MEMORY_ONLY,但是会序列化 | | MEMORY_AND_DISK_SER | 同MEMORY_AND_DSK,但是会序列化 | | DISK_ONLY | 以非序列化的方式完全存储到磁盘上 | | MEMORY_ONLY_2、MEMORY_AND_DISK_2等 | 尾部加了2的持久化级别,表示会将持久化数据复制 |
MEMORY_ONLY
- 以非序列化的Java对象的方式持久化在JVM内存中。如果内存无法完全存储RDD所有
- MEMORY_AND_DISK
- 当某些 partition 无法存储在内存中时, 会持久化到磁盘中。 下次需要使用这些 partition时,需要从磁盘上读取,不需要重新计算
- MEMORY_ONLY_SER
- 同MEMORY_ONLY,但是会使用Java的序列化方式,将Java对象序列化后进行持 久化。可以减少内存开销,但是在使用的时候需要进行反序列化,因此会增加CPU开销
- MEMORY_AND_DISK_SER
- 同MEMORY_AND_DSK。但是会使用序列化方式持久化Java对象
- DISK_ONLY
- 使用非序列化Java对象的方式持久化,完全存储到磁盘上
- MEMORY_ONLY_2、MEMORY_AND_DISK_2
- 如果是尾部加了2的持久化级别,表示会将持久化数据 复制一份,保存到其它节点,从而在数据丢失时,不需要重新计算,只需要使用备份数据即可
3、如何选择RDD持久化策略
- Spark提供了多种持久化级别,主要是为了在CPU和内存消耗之间进行取舍
以下建议:
Scala实现 ```scala import org.apache.spark.{SparkConf, SparkContext}
/**
需求:RDD持久化 */ object PersistRddScala {
def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.setAppName(“PersistRddScala”) .setMaster(“local”) val sc = new SparkContext(conf)
//注意cache的用法和位置 //cache默认是基于内存的持久化 // cache()=persist()=persist(StorageLevel.MEMORY_ONLY) val dataRDD = sc.textFile(“/Users/angel/Desktop/data/hello.txt”).cache() var start_time = System.currentTimeMillis() var count = dataRDD.count() println(count) var end_time = System.currentTimeMillis() println(“第一次耗时:”+(end_time-start_time))
start_time = System.currentTimeMillis() count = dataRDD.count() println(count) end_time = System.currentTimeMillis() println(“第二次耗时:”+(end_time-start_time))
sc.stop() } } ```
- Java实现 ```java import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext;
/**
需求:RDD持久化 */ public class PersistRddJava {
public static void main(String[] args) {
//创建JavaSparkContext SparkConf conf = new SparkConf(); conf.setAppName("PersistRddJava") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> dataRDD = sc.textFile("/Users/angel/Desktop/data/hello.txt").cache(); long start_time = System.currentTimeMillis(); long count = dataRDD.count(); System.out.println(count); long end_time = System.currentTimeMillis(); System.out.println("第一次耗时:"+(end_time-start_time));
start_time = System.currentTimeMillis();
count = dataRDD.count();
System.out.println(count);
end_time = System.currentTimeMillis();
System.out.println("第二次耗时:"+(end_time-start_time));
sc.stop();
}
}
<a name="dBDgY"></a>
###
<a name="MTkd7"></a>
### 9.4.6 共享变量
<a name="mGM4h"></a>
#### 1、共享变量的工作原理
- 默认情况下,一个算子函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个task中,此时每个task只能操作自己的那份变量数据
- Spark提供了两种共享变量,一种是**Broadcast Variable(广播变量)**,另一种是**Accumulator(累加变量)**
<a name="cwIL5"></a>
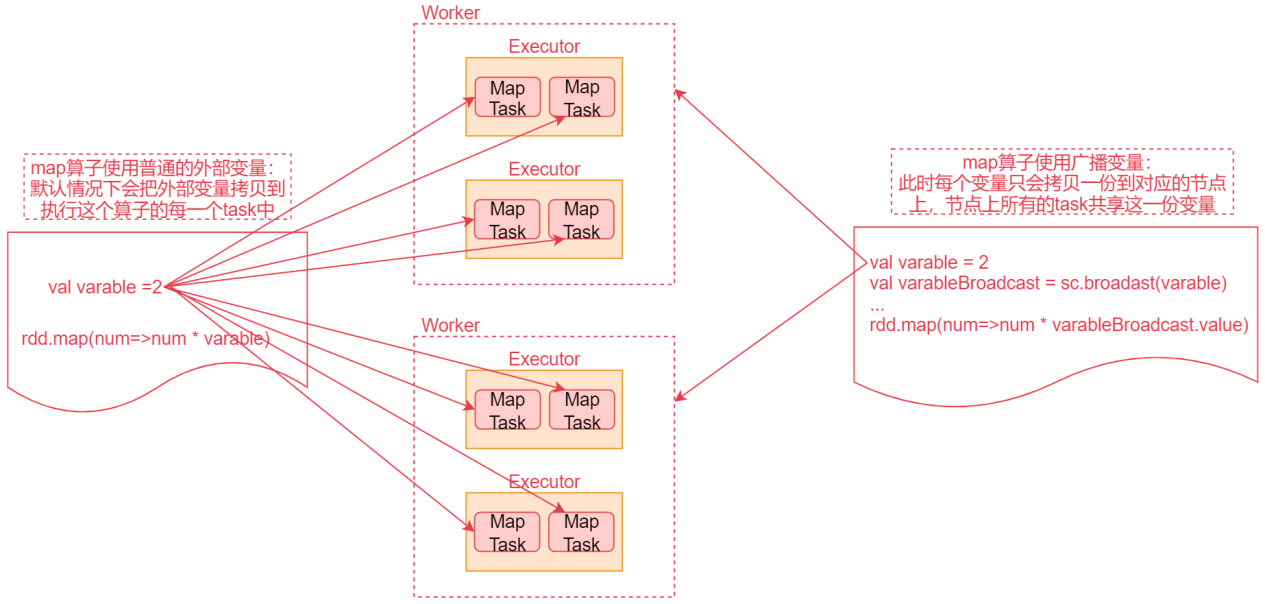
#### 2、Broadcast Variable
- Broadcast Variable会将使用到的变量,仅仅为每个节点拷贝一份,更大的用处是优化性能,减少网络传输以及内存消耗
- 通过调用SparkContext的 **broadcast() **方法,针对某个变量创建广播变量【**广播变量是只读的**】,然后在算子函数内,**使用到广播变量时,每个节点只会拷贝一份副本。可以使用广播变量的 value() 方法 获取值**
- 如图所示
<a name="iIXUo"></a>
####
- Scala实现
```scala
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:使用广播变量
*/
object BoradcastOpScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("BoradcastOpScala")
.setMaster("local")
val sc = new SparkContext(conf)
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
val varable = 2
//dataRDD.map(_ * varable)
//1:定义广播变量
val varableBroadcast = sc.broadcast(varable)
//2:使用广播变量,调用其value方法
dataRDD.map(_ * varableBroadcast.value).foreach(println(_))
sc.stop()
}
}
- Java实现 ```java import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import org.apache.spark.api.java.function.VoidFunction; import org.apache.spark.broadcast.Broadcast;
import java.util.Arrays;
/**
需求:使用广播变量 */ public class BroadcastOpJava {
public static void main(String[] args) {
//创建JavaSparkContext SparkConf conf = new SparkConf(); conf.setAppName("BroadcastOpJava") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5)); int varable = 2; //1:定义广播变量 Broadcast<Integer> varableBroadcast = sc.broadcast(varable); //2:使用广播变量 dataRDD.map(new Function<Integer, Integer>() { @Override public Integer call(Integer i1) throws Exception { return i1 * varableBroadcast.value(); } }).foreach(new VoidFunction<Integer>() { @Override public void call(Integer i) throws Exception { System.out.println(i); } }); sc.stop();} } ```
3、Accumulator
- Accumulator:用于多个节点对一个变量进行共享性的操作
「注意:Accumulator只提供了累加的功能,在task中只能对 Accumulator进行累加操作,不能读取它的值。只有Driver 进程中才可以读取Accumulator的值」
- Scala实现 ```scala import org.apache.spark.{SparkConf, SparkContext}
/**
需求:使用累加变量 / object AccumulatorOpScala { def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.setAppName(“AccumulatorOpScala”) .setMaster(“local”) val sc = new SparkContext(conf) val dataRDD = sc.parallelize(Array(1,2,3,4,5)) //这种写法是错误的,因为foreach代码是在worker节点上执行的 //var total = 0 和 println(total) 是在Driver进程中执行的 //所以无法实现累加操作 //并且foreach算子可能会在多个task中执行,这样foreach内部实现的累加也不是最终全局累加的结果 /var total = 0 dataRDD.foreach(num=>total += num) println(total)*/
//所以此时想要实现累加操作就需要使用累加变量了 //1:定义累加变量 val sumAccumulator = sc.longAccumulator
//2:使用累加变量 dataRDD.foreach(num=>sumAccumulator.add(num))
//注意:只能在Driver进程中获取累加变量的结果 println(sumAccumulator.value)
sc.stop() } } ```
- Java实现 ```java import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.VoidFunction; import org.apache.spark.util.LongAccumulator;
import java.util.Arrays;
/**
需求:使用累加变量 */ public class AccumulatorOpJava {
public static void main(String[] args) {
//创建JavaSparkContext SparkConf conf = new SparkConf(); conf.setAppName("AccumulatorOpJava") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5)); //1:定义累加变量 LongAccumulator sumAccumulator = sc.sc().longAccumulator(); //2:使用累加变量 dataRDD.foreach(new VoidFunction<Integer>() { @Override public void call(Integer i) throws Exception { sumAccumulator.add(i); } }); //获取累加变量的值 System.out.println(sumAccumulator.value()); sc.stop();} } ```

若有收获,就点个赞吧
0 人点赞
