- 3.1 HDFS(分布式文件系统)
- ! -put:从本地上传文件
- ! -cat:查看文件内容
- ! -appendToFile:把ABC的内容追加到README里面
- ! -ls:查询根目录
- ! hdfs的 url 这一串内容在使用时默认是可以省略的,因为hdfs在执行的时候会根据HDOOP_HOME自动识别配置文件中的fs.defaultFS属性,可以简写以下
- ! 把根目录的所有文件夹都查出来
- ! -mkdir [-p]:创建文件夹
- ! 递归创建文件夹
- ! -rm [-r]:删除文件
- ! 删除文件夹
- ! -rmdir:删除空目录
- ! -chmod:修改文件权限
- ! -chown:修改文件所有者
- ! -cp:拷贝到其他路径
- ! -mv:移动到其他路径
- ! -du:统计文件夹大小
- ! -setrep:设置副本数量
- ! 实操:查出文件数量和文件大小,假设hdfs有三个文件
- ! 统计目录下的文件
- ! 计算文件大小
笔记内容选自慕课网《大数据开发工程师》体系课
3.1 HDFS(分布式文件系统)
3.1.1 HDFS的设计思想
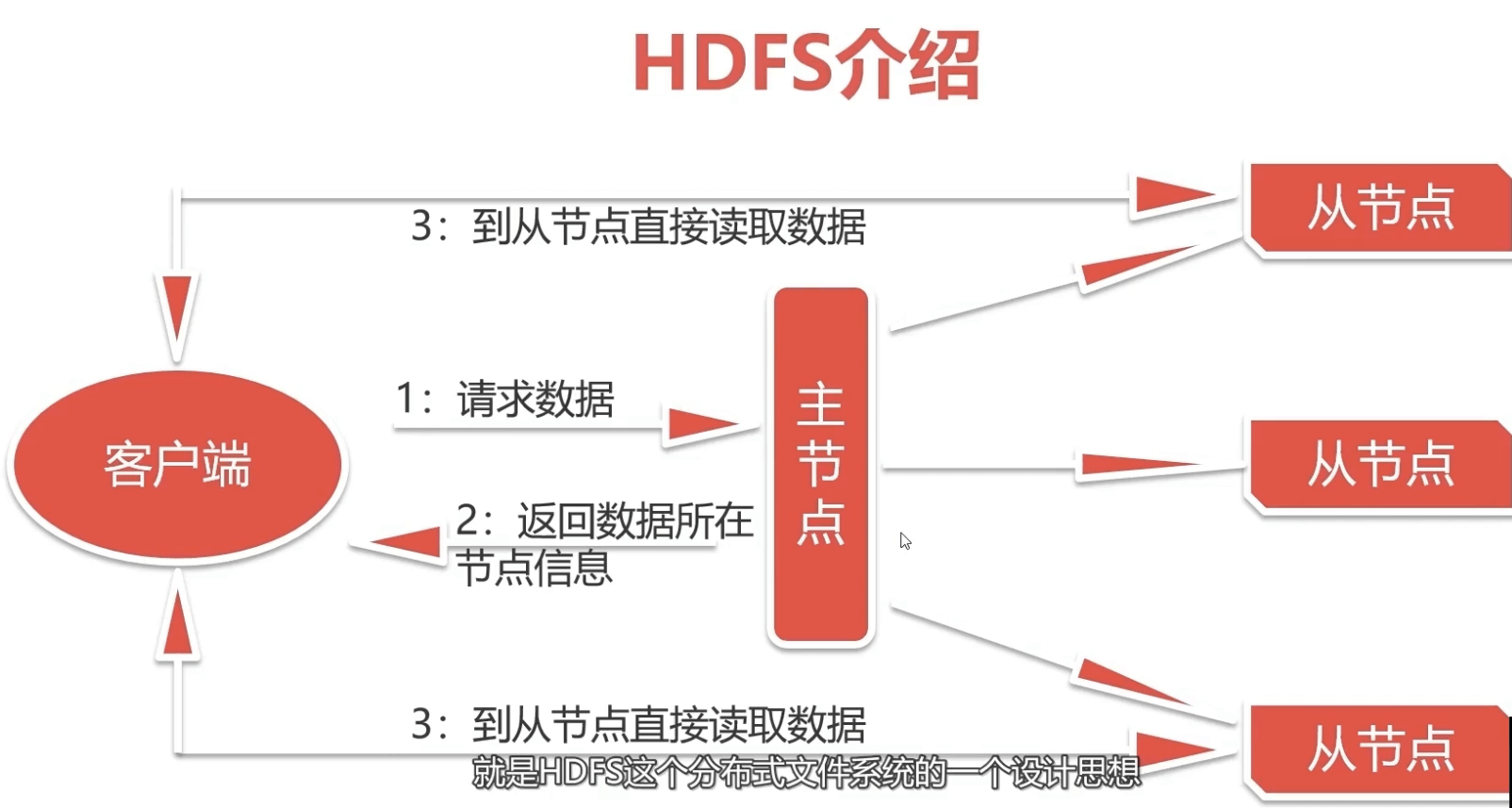
3.1.2 HDFS(Hadoop Distributed File System)
- HDFS是一种允许文件通过网络在多台主机上分享的文件系统可以让多台机器上的多个用户分享文件和存储空间
- 分布式文件管理系统有很多,
- HDFS只是其中一种实现,且适合存储大文件,不适合存储小文件
- 常见的分布式文件系统
- GFS(谷歌)
- TFS(淘宝)
- S3(亚马逊)
- HDFS的使用场景
- 适合一次写入,多次读出的场景
- 且不支持文件内容的修改,支持文件内容的追加
- 优点
- 数据自动保存多个副本。它通过增加副本的形式,提高容错性
- 某一个副本丢失以后,它可以自动恢复
- 缺点
- 不适合低延时数据访问,比如毫秒级的存储数据,是做不到的
- 无法高效的对大量小文件进行存储
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息
- 原本128MB文件存10个,相当于存了1280MB资源
- 结果1MB小文件存10个,相当于只存了10MB资源
- NameNode的内存总是有限的,存储小文件会浪费空间
- 解决方法:合并思想,把小文件都合并即可
- 小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息
- 同一个文件只能一个客户端上传写入,不能并发多线程同时写入
3.1.3 Shell操作HDFS
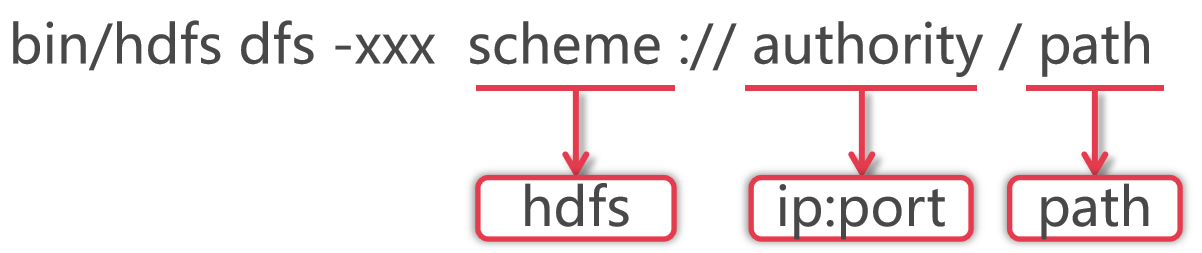
- 操作格式
! -cat:查看文件内容
hdfs dfs -cat /README.txt
! -appendToFile:把ABC的内容追加到README里面
hdfs dfs -appendToFile ABC.txt /README.txt
- **下载**```bash#! -get:下载文件到本地,最后面有一个点,它代表了下载到当前目录hdfs dfs -get /README.txt .#! -getmerge:下载并合并hdfs dfs -getmerge /user/atguigu/test/* ./zaiyiqi.txt#! 发现下载下来的文件重名了,可以下载时改名hdfs dfs -get /README.txt README.txt.bak
- 常见操作
```bash
! -ls:查询根目录
hdfs dfs -ls hdfs://bigdata01:9000/! hdfs的 url 这一串内容在使用时默认是可以省略的,因为hdfs在执行的时候会根据HDOOP_HOME自动识别配置文件中的fs.defaultFS属性,可以简写以下
hdfs dfs -ls /! 把根目录的所有文件夹都查出来
hdfs dfs -ls -R /
! -mkdir [-p]:创建文件夹
hdfs dfs -mkdir /test
! 递归创建文件夹
hdfs dfs -mkdir -p /abc/xyz
! -rm [-r]:删除文件
hdfs dfs -rm /README.txt
! 删除文件夹
hdfs dfs -rm -r /abc
! -rmdir:删除空目录
hdfs dfs -rmdir /test
! -chmod:修改文件权限
hdfs dfs -chmod 666 /README.txt
! -chown:修改文件所有者
hdfs dfs -chown atguigu:atguigu /README.txt
! -cp:拷贝到其他路径
hdfs dfs -cp /README.txt /test
! -mv:移动到其他路径
hdfs dfs -mv /README.txt /test
! -du:统计文件夹大小
hdfs dfs -du -h /test
! -setrep:设置副本数量
hdfs dfs -setrep 10 /test/README.txt
! 实操:查出文件数量和文件大小,假设hdfs有三个文件
hdfs dfs -put LICENSE.txt / hdfs dfs -put NOTICE.txt / hdfs dfs -put README.txt /
! 统计目录下的文件
hdfs dfs -ls / |grep /| wc -l
! 计算文件大小
hdfs dfs -ls / |grep /| awk ‘{print $8,$5}’
<a name="A8MQU"></a>### 3.1.4 Java操作HDFS- **在代码操作之前,需要关闭Hadoop的权限管理,不然无法通过本地客户端上传文件,或者把代码丢到集群环境里的root运行**```c# 停止bigdata01的集群cd /data/soft/hadoop-3.2.0sbin/stop-all.sh# 修改hdfs-site.xml配置文件vi etc/hadoop/hdfs-site.xml...<configuration><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.namenode.secondary.http-address</name><value>bigdata01:50090</value></property><property><name>dfs.permissions.enabled</name><value>false</value></property></configuration># 同步到另外两个节点scp -rq etc/hadoop/hdfs-site.xml bigdata02:/data/soft/hadoop-3.2.0/etc/hadoop/scp -rq etc/hadoop/hdfs-site.xml bigdata03:/data/soft/hadoop-3.2.0/etc/hadoop/# 启动Hadoop集群sbin/start-all.sh
- 创建maven项目
```xml
org.apache.hadoop hadoop-client 3.2.0
- **在Resource文件夹下创建 log4j.properties**
```css
log4j.rootLogger=info,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
- Java代码 ```java package com.chaunceyi.hdfs;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils;
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException;
/**
- java代码操作hdfs
- 文件操作:上传文件,下载文件,删除文件 *
@author angel */ public class HdfsOp { public static void main(String[] args) throws IOException {
// 创建一个配置对象 Configuration conf = new Configuration(); // 指定HDFS的地址 conf.set("fs.defaultFS", "hdfs://bigdata01:9000"); // 获取操作HDFS的对象 FileSystem fileSystem = FileSystem.get(conf); // 上传文件 put(fileSystem); // 下载文件 get(fileSystem); // 删除文件 delete(fileSystem);}
private static void delete(FileSystem fileSystem) throws IOException {
// 如果需要递归删除文件夹,则添加个true的参数 boolean flag = fileSystem.delete(new Path("/东宫.txt"), true); if (flag) { System.out.println("删除成功!"); } else { System.out.println("删除失败!"); }}
private static void get(FileSystem fileSystem) throws IOException {
// 获取HDFS文件系统的输入流 FSDataInputStream fis = fileSystem.open(new Path("/README.txt")); // 获取本地文件的输出流 FileOutputStream fos = new FileOutputStream("/Users/angel/Documents/Code/BigData/db_hadoop/src/main/resources/save/README.txt"); // 下载文件 IOUtils.copyBytes(fis, fos, 1024, true);}
private static void put(FileSystem fileSystem) throws IOException {
// 上传文件 // 获取本地文件的输入流 FileInputStream fis = new FileInputStream("/Users/angel/Documents/Code/BigData/db_hadoop/src/main/resources/save/README.txt"); // 获取HDFS文件系统的输出流 FSDataOutputStream fos = fileSystem.create(new Path("/README.txt")); // 上传文件:通过工具类把输入流拷贝到输出流里面,实现本地文件上传到HDFS IOUtils.copyBytes(fis, fos, 1024, true);} } ```
3.1.5 HDFS体系架构
- HDFS支持主从结构
- 主节点称为NameNode,支持多个,相当于「老板」
- 从节点称为DataNode,支持多个,相当于「员工」
- HDFS中还包含一个SecondaryNameNode进程,相当于「秘书」
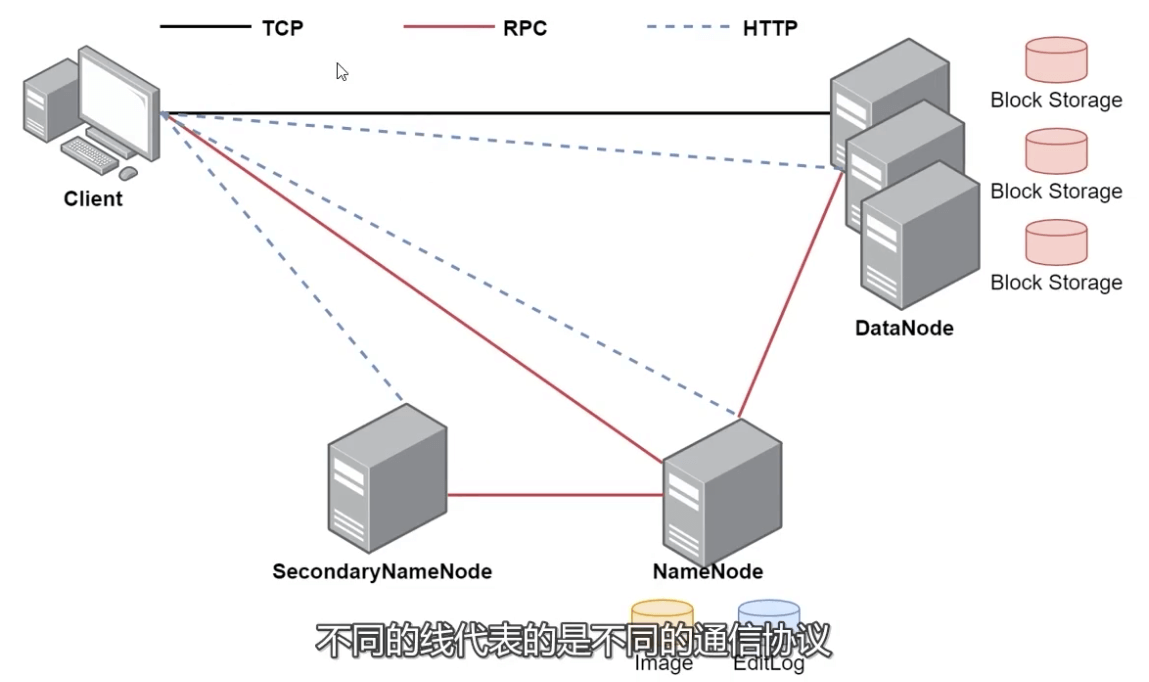
1、NameNode
- NameNode是整个文件系统的管理节点
- 它主要维护着整个文件系统的
- 文件目录树
- 如:hdfs dfs -ls / 可以看到的目录结构信息
- 文件/目录的信息
- 文件/目录的所有者是谁、属于哪个组、修改时间、文件大小等基本信息
- 数据块列表
- 对于大文件会切割成多个Block,并且存放到各个从节点
- 接收用户操作请求
- 使用Shell或者Java代码操作HDFS时,都需要与NameNode通信,才能开始去操作
- 为什么呢?
- 因为文件信息都在NameNode上面存储着的,它的这些文件信息最终是会存储到文件上的
- NameNode都包含了哪些文件呢?
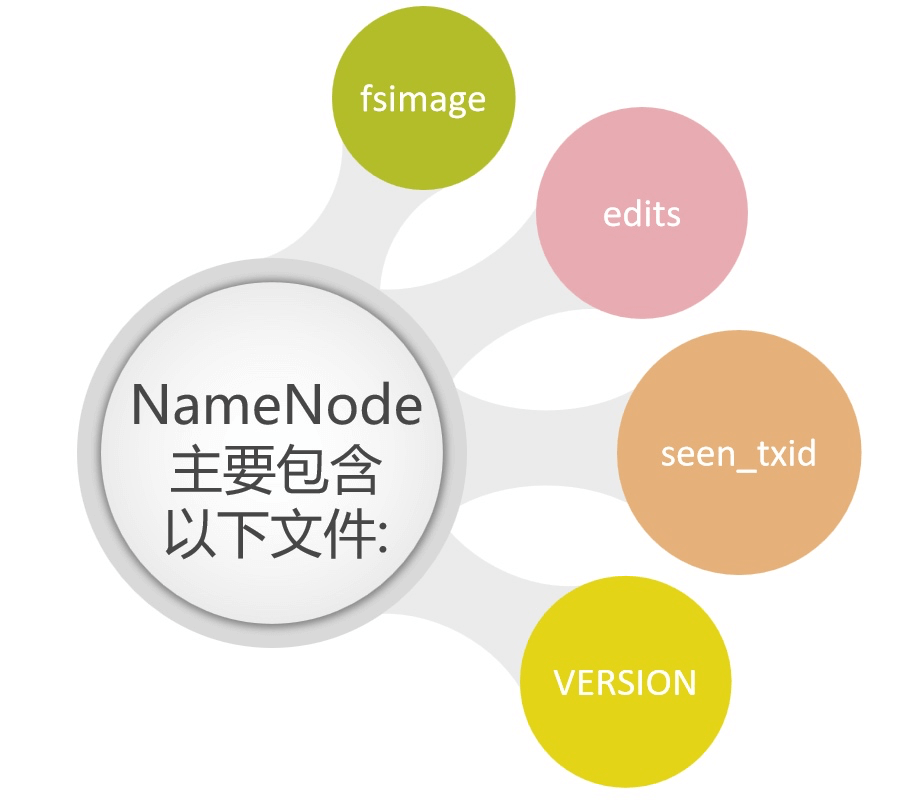
这些文件的路径在哪呢?
- 这些文件所在的路径是由hdfs-default.xml的dfs.namenode.name.dir属性控制的
<property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> ... </property>
- 这些文件所在的路径是由hdfs-default.xml的dfs.namenode.name.dir属性控制的
hdfs-default.xml 在哪呢?
- 它在hadoop-3.2.0\share\hadoop\hdfs\hadoop-hdfs-3.2.0.jar中,这个文件中包含了HDFS相关的所有默认参数
- 在搭建集群时需要配置hdfs-site.xml文件,hdfs-site.xml 文件属于 hdfsdefault.xml的一个扩展,它可以覆盖掉hdfs-default.xml中同名的参数
${hadoop.tmp.dir} 这个属性指的是什么?
- 这个属性的值默认在core-default.xml文件中
- 在搭建集群时需要配置core-site.xml文件,当时设置的hadoop.tmp.dir属性的值是/data/hadoop_repo,它可以覆盖掉core-default.xml中同名的参数
NameNode启动的🔐锁机制
- 当你主节点开启时,会启动NameNode进程
- 这个时候会判断这个目录下是否有in_use.lock文件,相当于一把锁,如果没有的话,才可以启动成功,启动成功之后就会加一把锁, 停止的时候会把这个锁去掉。
「注 意:edits文件和fsimage文件,其中fsimage有两个文件名相同,但是后缀为.md5的一种加密算法,用于校验文件完整性」[root@bigdata01 hadoop-3.2.0]# cd /data/hadoop_repo/dfs/name [root@bigdata01 name]# ll total 8 drwxr-xr-x. 2 root root 4096 Aug 5 14:28 current -rw-r--r--. 1 root root 15 Aug 5 10:27 in_use.lock [root@bigdata01 name]# cd current [root@bigdata01 current]# ll total 3124 -rw-r--r--. 1 root root 42 Aug 4 20:40 edits_0000000000000000001-0000000000000000002 -rw-r--r--. 1 root root 1048576 Aug 4 20:40 edits_0000000000000000003-0000000000000000003 -rw-r--r--. 1 root root 42 Aug 5 09:32 edits_0000000000000000004-0000000000000000005 -rw-r--r--. 1 root root 1048576 Aug 5 09:38 edits_0000000000000000006-0000000000000000012 -rw-r--r--. 1 root root 42 Aug 5 10:28 edits_0000000000000000013-0000000000000000014 -rw-r--r--. 1 root root 3408 Aug 5 11:28 edits_0000000000000000015-0000000000000000054 -rw-r--r--. 1 root root 42 Aug 5 12:28 edits_0000000000000000055-0000000000000000056 -rw-r--r--. 1 root root 42 Aug 5 13:28 edits_0000000000000000057-0000000000000000058 -rw-r--r--. 1 root root 42 Aug 5 14:28 edits_0000000000000000059-0000000000000000060 -rw-r--r--. 1 root root 1048576 Aug 5 14:28 edits_inprogress_0000000000000000061 -rw-r--r--. 1 root root 518 Aug 5 13:28 fsimage_0000000000000000058 -rw-r--r--. 1 root root 62 Aug 5 13:28 fsimage_0000000000000000058.md5 -rw-r--r--. 1 root root 518 Aug 5 14:28 fsimage_0000000000000000060 -rw-r--r--. 1 root root 62 Aug 5 14:28 fsimage_0000000000000000060.md5 -rw-r--r--. 1 root root 3 Aug 5 14:28 seen_txid -rw-r--r--. 1 root root 219 Aug 5 09:31 VERSION
fsimage(filesystem image)文件系统镜像,就是给文件照了一个像,把文件的当前信息记录下来
查看fsimage都写了什么?
- -i:输入文件,-o:输出文件
- hdfs oiv -p XML -i fsimage_0000000000000000060 -o fsimage60.xml
把 /data/hadoop_repo/dfs/name/current/fsimage60.xml 文件拖拽到桌面打开分析
<?xml version="1.0"?> <fsimage> <version> <layoutVersion>-65</layoutVersion> <onDiskVersion>1</onDiskVersion> <oivRevision>e97acb3bd8f3befd27418996fa5d4b50bf2e17bf</oivRevision> </version> <NameSection> <namespaceId>1174768969</namespaceId> <genstampV1>1000</genstampV1> <genstampV2>1005</genstampV2> <genstampV1Limit>0</genstampV1Limit> <lastAllocatedBlockId>1073741829</lastAllocatedBlockId> <txid>60</txid> </NameSection> <ErasureCodingSection> <erasureCodingPolicy> <policyId>5</policyId> <policyName>RS-10-4-1024k</policyName> <cellSize>1048576</cellSize> <policyState>DISABLED</policyState> <ecSchema> <codecName>rs</codecName> <dataUnits>10</dataUnits> <parityUnits>4</parityUnits> </ecSchema> </erasureCodingPolicy> <erasureCodingPolicy> <policyId>2</policyId> <policyName>RS-3-2-1024k</policyName> <cellSize>1048576</cellSize> <policyState>DISABLED</policyState> <ecSchema> <codecName>rs</codecName> <dataUnits>3</dataUnits> <parityUnits>2</parityUnits> </ecSchema> </erasureCodingPolicy> <erasureCodingPolicy> <policyId>1</policyId> <policyName>RS-6-3-1024k</policyName> <cellSize>1048576</cellSize> <policyState>ENABLED</policyState> <ecSchema> <codecName>rs</codecName> <dataUnits>6</dataUnits> <parityUnits>3</parityUnits> </ecSchema> </erasureCodingPolicy> <erasureCodingPolicy> <policyId>3</policyId> <policyName>RS-LEGACY-6-3-1024k</policyName> <cellSize>1048576</cellSize> <policyState>DISABLED</policyState> <ecSchema> <codecName>rs-legacy</codecName> <dataUnits>6</dataUnits> <parityUnits>3</parityUnits> </ecSchema> </erasureCodingPolicy> <erasureCodingPolicy> <policyId>4</policyId> <policyName>XOR-2-1-1024k</policyName> <cellSize>1048576</cellSize> <policyState>DISABLED</policyState> <ecSchema> <codecName>xor</codecName> <dataUnits>2</dataUnits> <parityUnits>1</parityUnits> </ecSchema> </erasureCodingPolicy> </ErasureCodingSection> <INodeSection> <lastInodeId>16401</lastInodeId> <numInodes>2</numInodes> <inode> <id>16385</id> <type>DIRECTORY</type> <name></name> <mtime>1628131900166</mtime> <permission>root:supergroup:0755</permission> <nsquota>9223372036854775807</nsquota> <dsquota>-1</dsquota> </inode> <inode> <id>16401</id> <type>FILE</type> <name>README.txt</name> <replication>3</replication> <mtime>1628131900289</mtime> <atime>1628131900166</atime> <preferredBlockSize>134217728</preferredBlockSize> <permission>angel:supergroup:0644</permission> <blocks> <block> <id>1073741829</id> <genstamp>1005</genstamp> <numBytes>1361</numBytes> </block> </blocks> <storagePolicyId>0</storagePolicyId> </inode> </INodeSection> <INodeReferenceSection></INodeReferenceSection> <SnapshotSection> <snapshotCounter>0</snapshotCounter> <numSnapshots>0</numSnapshots> </SnapshotSection> <INodeDirectorySection> <directory> <parent>16385</parent> <child>16401</child> </directory> </INodeDirectorySection> <FileUnderConstructionSection></FileUnderConstructionSection> <SecretManagerSection> <currentId>0</currentId> <tokenSequenceNumber>0</tokenSequenceNumber> <numDelegationKeys>0</numDelegationKeys> <numTokens>0</numTokens> </SecretManagerSection> <CacheManagerSection> <nextDirectiveId>1</nextDirectiveId> <numDirectives>0</numDirectives> <numPools>0</numPools> </CacheManagerSection> </fsimage>inode标签:表示是hdfs中的每一个目录或者文件信息
- id:唯一编号
- type:文件类型
- replication:文件的副本数量
- mtime:修改时间
- atime:访问时间
- preferredBlockSize:推荐每一个数据块的大小
- permission:权限信息
- blocks:包含多少数据块【文件被切成数据块】
- block :内部的 id 表示是块 id
- genstamp:是一个唯一编号
- numBytes:表示当前数据块的实际大小
- storagePolicyId:表示是数据的存储策略
<inode> <id>16401</id> <type>FILE</type> <name>README.txt</name> <replication>3</replication> <mtime>1628131900289</mtime> <atime>1628131900166</atime> <preferredBlockSize>134217728</preferredBlockSize> <permission>angel:supergroup:0644</permission> <blocks> <block> <id>1073741829</id> <genstamp>1005</genstamp> <numBytes>1361</numBytes> </block> </blocks> <storagePolicyId>0</storagePolicyId> </inode>
「注 意:这个文件中其实就维护了整个文件系统的文件目录树, 文件/目录的元信息和每个文件对应的数据块列表,所以说fsimage中存放了hdfs最核心的数据」
edits:它是事务文件
- 当上传大文件的时候,一个大文件会分为多个block,那么edits文件中就会记录这些block的上传状态
- 只有当全部block都上传成功了以后,这个时候edits中才会记录这个文件上传成功了,那么执行 hdfs dfs -ls 的时候就能查到这个文件了
查看edits都写了什么?
- hdfs oev -i edits_0000000000000000006-0000000000000000012 -o edits.xml
把 /data/hadoop_repo/dfs/name/current/edits.xml 文件拖拽到桌面打开分析
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <EDITS> <EDITS_VERSION>-65</EDITS_VERSION> <RECORD> <OPCODE>OP_START_LOG_SEGMENT</OPCODE> <DATA> <TXID>6</TXID> </DATA> </RECORD> <RECORD> <OPCODE>OP_ADD</OPCODE> <DATA> <TXID>7</TXID> <LENGTH>0</LENGTH> <INODEID>16386</INODEID> <PATH>/README.txt._COPYING_</PATH> <REPLICATION>2</REPLICATION> <MTIME>1628127510075</MTIME> <ATIME>1628127510075</ATIME> <BLOCKSIZE>134217728</BLOCKSIZE> <CLIENT_NAME>DFSClient_NONMAPREDUCE_-290076553_1</CLIENT_NAME> <CLIENT_MACHINE>192.168.53.100</CLIENT_MACHINE> <OVERWRITE>true</OVERWRITE> <PERMISSION_STATUS> <USERNAME>root</USERNAME> <GROUPNAME>supergroup</GROUPNAME> <MODE>420</MODE> </PERMISSION_STATUS> <ERASURE_CODING_POLICY_ID>0</ERASURE_CODING_POLICY_ID> <RPC_CLIENTID>9406985b-cdc2-43e0-a858-0d13448a2f3d</RPC_CLIENTID> <RPC_CALLID>3</RPC_CALLID> </DATA> </RECORD> <RECORD> <OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE> <DATA> <TXID>8</TXID> <BLOCK_ID>1073741825</BLOCK_ID> </DATA> </RECORD> <RECORD> <OPCODE>OP_SET_GENSTAMP_V2</OPCODE> <DATA> <TXID>9</TXID> <GENSTAMPV2>1001</GENSTAMPV2> </DATA> </RECORD> <RECORD> <OPCODE>OP_ADD_BLOCK</OPCODE> <DATA> <TXID>10</TXID> <PATH>/README.txt._COPYING_</PATH> <BLOCK> <BLOCK_ID>1073741825</BLOCK_ID> <NUM_BYTES>0</NUM_BYTES> <GENSTAMP>1001</GENSTAMP> </BLOCK> <RPC_CLIENTID/> <RPC_CALLID>-2</RPC_CALLID> </DATA> </RECORD> <RECORD> <OPCODE>OP_CLOSE</OPCODE> <DATA> <TXID>11</TXID> <LENGTH>0</LENGTH> <INODEID>0</INODEID> <PATH>/README.txt._COPYING_</PATH> <REPLICATION>2</REPLICATION> <MTIME>1628127510900</MTIME> <ATIME>1628127510075</ATIME> <BLOCKSIZE>134217728</BLOCKSIZE> <CLIENT_NAME/> <CLIENT_MACHINE/> <OVERWRITE>false</OVERWRITE> <BLOCK> <BLOCK_ID>1073741825</BLOCK_ID> <NUM_BYTES>1361</NUM_BYTES> <GENSTAMP>1001</GENSTAMP> </BLOCK> <PERMISSION_STATUS> <USERNAME>root</USERNAME> <GROUPNAME>supergroup</GROUPNAME> <MODE>420</MODE> </PERMISSION_STATUS> </DATA> </RECORD> <RECORD> <OPCODE>OP_RENAME_OLD</OPCODE> <DATA> <TXID>12</TXID> <LENGTH>0</LENGTH> <SRC>/README.txt._COPYING_</SRC> <DST>/README.txt</DST> <TIMESTAMP>1628127510910</TIMESTAMP> <RPC_CLIENTID>9406985b-cdc2-43e0-a858-0d13448a2f3d</RPC_CLIENTID> <RPC_CALLID>9</RPC_CALLID> </DATA> </RECORD> </EDITS>RECORD标签:代表不同的操作
- OP_ADD:执行上传操作
- OP_ALLOCATE_BLOCK_ID:申请block块id
- OP_SET_GENSTAMP_V2:设置GENSTAMP编码
- OP_ADD_BLOCK:添加block块
- OP_CLOSE:关闭上传操作
- 一个put操作会在edits文件中产生很多的record操作,且每个操作都有txid事务ID连续记录着
在对hdfs的增删改操作都会在edits文件留下信息,那么fsimage 文件中的内容是从哪来?
- edits文件会定期合并内容到fsimage文件中
edits文件和fsimage文件中的内容是不一样的,这怎么合并出来的?
「注 意:这个其实是框架去做的,在合并的时候会对edits中的内容进行转换,生成新的内容,**其实 edits中保存的内容太细节太多了,单单一个上传操作就分为了好几步,其实上传成功之后,只需要保存文件具体存储的block信息就行了,所以在合并的时候其实是对edits中的内容进行了精简」**
seen_txid
- 它代表的是NameNode里面的edits_*文件的尾数
HDFS format格式化后会是0
[root@bigdata01 current]# cat seen_txid 65NameNode重启的时候,会按照seen_txid的数字,顺序从头跑edits_0000001~到seen_txid的数字。如果根据对应的seen_txid无法加载到对应的文件,NameNode进程将不会完成启动,从而保障数据一致性。
VERSION
- 这里面显示的集群的一些信息、当重新对hdfs格式化之后,这里面的信息会变化
[root@bigdata01 current]# cat VERSION #Thu Aug 05 09:31:27 CST 2021 namespaceID=1174768969 clusterID=CID-c4d833e0-b21a-4c88-bb9e-e2c4e0c85682 cTime=1628080762891 storageType=NAME_NODE blockpoolID=BP-1107237941-192.168.53.100-1628080762891 layoutVersion=-65
- 这里面显示的集群的一些信息、当重新对hdfs格式化之后,这里面的信息会变化
使用HDFS的时候只格式化一次,不要格式化多次,为什么?
- 因为HDFS多次格式化的话,NameNode里的VERSION集群信息会变,但是DataNode里的VERSION集群信息没变,两者有绑定关系,则启动起来发现对应不上则会报错
- 如果想重新格式化,需要所有集群服务移除 rm -rf /data/hadoop_repo/
2、SecondaryNameNode
- 这个进程就是负责定期的把edits中的内容合并到fsimage中
- 这个合并操作称为checkpoint,在合并的时候会对edits中的内容进行转换,生成新的内容保存到fsimage文件中
- 它只做一件事,这是一个单独的进程,在实际工作中部署的时候,也需要部署到一个单独的节点
「注 意:在NameNode的HA架构中没有SecondaryNameNode进程,文件合并操作会由Standby NameNode负责实现」
- HA架构:NameNode主从架构
- 会有主节点的NameNode和备用的NameNode
- 合并文件的操作由StandbyNameNode(备用的NameNode)去操作
- 因而在HA架构,就不需要SecondaryNameNode进程了
- 在Hadoop1.x时,SecondaryNameNode是必须的
- 在Hadoop2.x时,SecondaryNameNode不是必须的
3、DataNode
- 提供真实文件数据的存储服务
- HDFS会按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block,HDFS默认Block大小是128MB
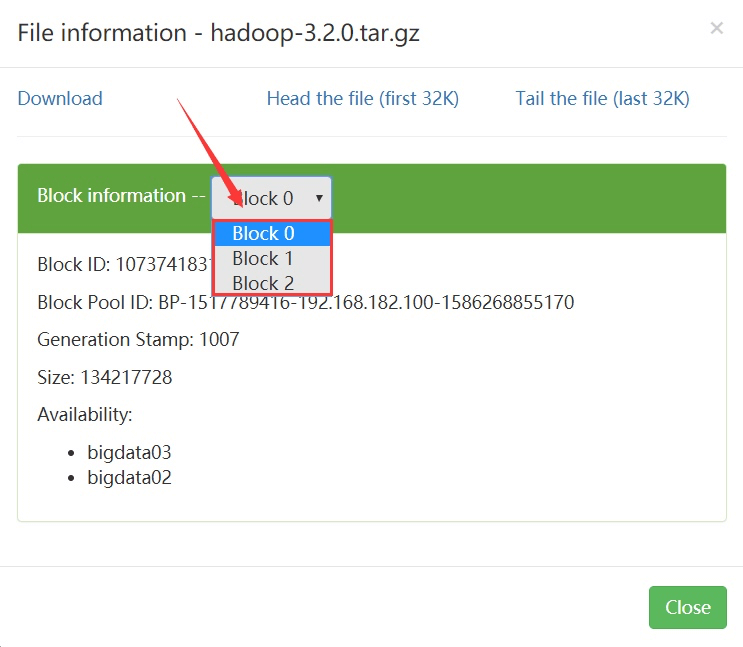
- http://bigdata01:9870/ -> Utllities -> Browse the fle system
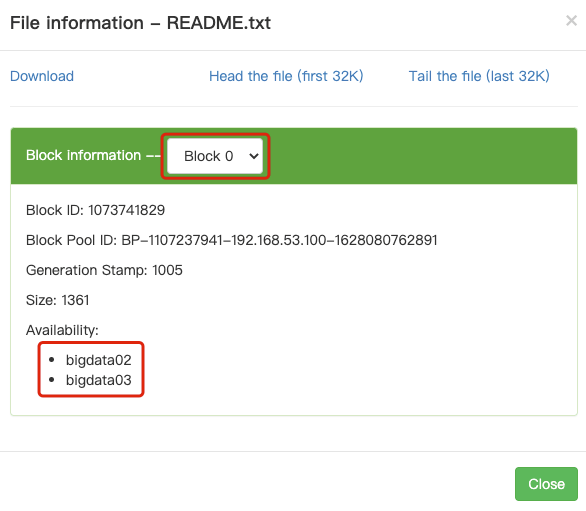
- 这里显示文件的Block在bigdata02和bigdata03上面都有
DataNode的数据路径是怎么设置的?
- DataNode中数据所在的路径是由hdfs-default.xml的dfs.datanode.data.dir属性控制的
<property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data</value> ... </property>
- DataNode中数据所在的路径是由hdfs-default.xml的dfs.datanode.data.dir属性控制的
具体的Block的路径在哪呢? ```c [root@bigdata02 ~]# cd /data/hadoop_repo/dfs/data/ [root@bigdata02 data]# ll -R current current: total 4 drwx———. 4 root root 54 Aug 5 10:27 BP-1107237941-192.168.53.100-1628080762891 -rw-r—r—. 1 root root 229 Aug 5 10:27 VERSION
current/BP-1107237941-192.168.53.100-1628080762891: total 4 drwxr-xr-x. 4 root root 64 Aug 5 10:18 current -rw-r—r—. 1 root root 166 Aug 4 20:39 scanner.cursor drwxr-xr-x. 2 root root 6 Aug 5 10:27 tmp
current/BP-1107237941-192.168.53.100-1628080762891/current: total 8 -rw-r—r—. 1 root root 19 Aug 5 10:18 dfsUsed drwxr-xr-x. 3 root root 21 Aug 5 09:38 finalized drwxr-xr-x. 2 root root 6 Aug 5 10:51 rbw -rw-r—r—. 1 root root 146 Aug 5 10:27 VERSION
current/BP-1107237941-192.168.53.100-1628080762891/current/finalized: total 0 drwxr-xr-x. 3 root root 21 Aug 5 09:38 subdir0
current/BP-1107237941-192.168.53.100-1628080762891/current/finalized/subdir0: total 0 drwxr-xr-x. 2 root root 60 Aug 5 10:51 subdir0
current/BP-1107237941-192.168.53.100-1628080762891/current/finalized/subdir0/subdir0:
total 8
-rw-r—r—. 1 root root 1361 Aug 5 10:51 blk_1073741829
-rw-r—r—. 1 root root 19 Aug 5 10:51 blk_1073741829_1005.meta
_**「注 意: 这里面的.meta文件也是做校验用的」**_
- **根据hdfs webui看到的blockid信息到这对应的找到文件,可以直接打开看**
```css
[root@bigdata02 subdir0]# cat blk_1073741829
For the latest information about Hadoop, please visit our website at:
...
「注 意:这个block中的内容可能只是文件的一部分,如果你的文件较大的话,就会分为多个block 存储,默认 hadoop3中一个block的大小为128M 。
根据字节进行截取,截取到 128M 就是一个block。如果文件大小没有默认的block块大,那最终就只有一个block。
HDFS中,如果一个文件小于一个数据块的大小,那么并不会占用整个数据块的存储空间」
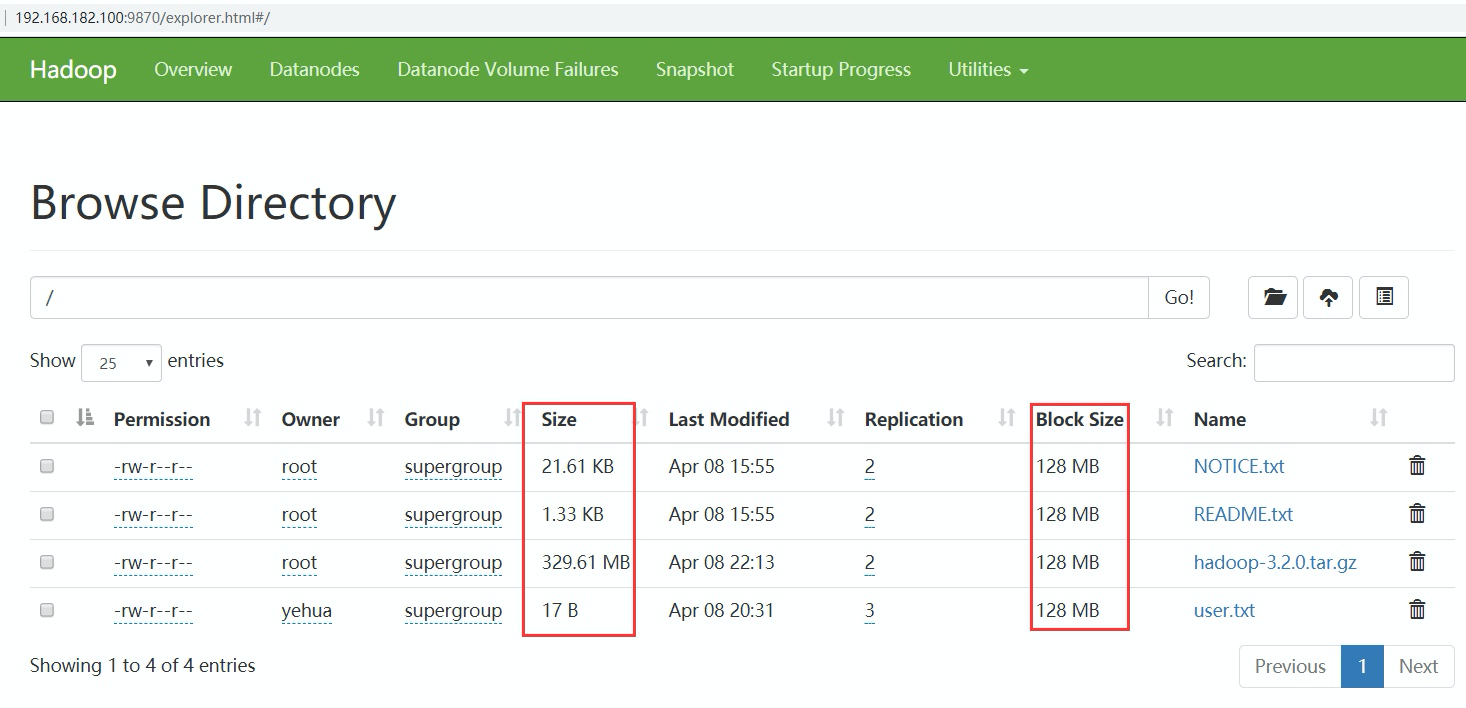
- size是表示我们上传文件的实际大小,blocksize是指文件的最大块大小
「注 意:这个block块是hdfs产生的,如果我们直接把文件上传到这个block文件所在的目录,这个时候hdfs是不识别的,没有用的」
- 假设我们上传了两个10M的文件 又上传了一个200M的文件
- 问1:会产生多少个block块?
- 4个
- 问2:在hdfs中会显示几个文件?
- 3个
- 问1:会产生多少个block块?
- Replication:多副本机制
- HDFS默认副本数量为3
- 目前现有集群有两个从节点, 所以最多可以有 2 个备份
- 这个是在 hdfs-site.xml 中进行配置的,dfs.replication 属性
- 副本只有一个作用就是保证数据安全
4、NameNode的总结
「注 意:Block块存放在哪些DataNode上,只有DataNode自己知道,
当集群启动的时候,DataNode会扫描自己节点上面的所有Block块信息,然后把节点和这个节点上的所有block块信息告诉给NameNode」
这个关系是每次重启集群都会动态加载的【这个其实就是集群为什么数据越多,启动越慢的原因】
NameNode维护了两份关系:
- 第一份关系:File与Block list的关系,对应的关系信息存储在fsimage和edits文件中(当NameNode启动的时候会把文件中的元数据信息加载到内存中)
- 第二份关系:DataNode与Block的关系(当DataNode启动时会把当前节点上的BIock信息和节点信息上报给NameNode)
- 就可以根据文件找到对应的block块,再根据block块找到对应的DataNode节点,这样就真正找到了数据
NameNode为什么把文件中的元数据信息加载到内存中?
- 为了后期查询速度更快,效率高
每一个文件的元数据信息会占用150字节的内存空间,这个是恒定的,和文件大小没有关系
- 所以说,HDFS不适合存储小文件
- 原因是,不管是大文件还是小文件,一个文件的元数据信息在NameNode中都会占用150字节,NameNode节点的内存是有限的, 所以它的存储能力也是有限的, 如果我们存储了一堆都是几KB的小文件,最后发现 NameNode 的内存占满了,确实存储了很多文件,但是文件的总体大小却很小,这样就失去了HDFS存在的价值
3.1.6 HDFS的回收站
「注意:HDFS的回收站默认是没有开启的,需要修改core- site.xml中的fs.trash.interval 属性」
1、停止集群
cd /data/soft/hadoop-3.2.0
sbin/stop-all.sh
2、vi core-site.xml
<!--以分钟为单位,1440分钟为1天-->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
3、文件拷贝给其他两台节点
scp -rq /data/soft/hadoop-3.2.0/etc/hadoop/core-site.xml bigdata02:/data/soft/hadoop-3.2.0/etc/hadoop/
scp -rq /data/soft/hadoop-3.2.0/etc/hadoop/core-site.xml bigdata03:/data/soft/hadoop-3.2.0/etc/hadoop/
4、启动集群测试
# 启动
sbin/start-all.sh
# 删除进回收站
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm /README.txt
2021-08-08 07:43:28,722 INFO fs.TrashPolicyDefault: Moved: 'hdfs://bigdata01:9000/README.txt' to trash at: hdfs://bigdata01:9000/user/root/.Trash/Current/README.txt
「注意:如果文件太大,回收站存不进去,可以使用 hdfs dfs -rm -skipTrash /Test.txt 会直接删除,而不会进入回收站」
5、回收站总结
- HDFS为每个用户创建一个回收站目录:/user/用户名/.Trash/
- 回收站中的数据都会有一个默认保存周期,过期未恢复则会被HDFS自动彻底删除
3.1.7 HDFS的安全模式
- 集群刚启动时HDFS会进入安全模式,此时无法执行写操作
- 建议去喝杯Java
- 着急使用?查看状态
- 查看安全模式:hdfs dfsadmin -safemode get
- 手动停止安全模式「不建议」
- 离开安全模式:hdfs dfsadmin -safemode leave
3.1.8 实战:定时上传数据至HDFS
「需求分析: 在实际工作中会有定时上传数据到HDFS的需求,我们有一个web项目每天都会产生日志文件,日 志文件的格式为access_2020_01_01.log这种格式的,每天产生一个,我们需要每天凌晨将昨天生 成的日志文件上传至HDFS上,按天分目录存储,HDFS上的目录格式为20200101」
- 针对这个需求,我们需要开发一个shell脚本,方便定时调度执行
- 我们需要获取到昨天日志文件的名称
- 在HDFS上面使用昨天的日期创建目录
- 将昨天的日志文件上传到刚创建的HDFS目录中
- 要考虑到脚本重跑,补数据的情况
- 配置crontab任务
1、创建Shell脚本
[root@bigdata01 ~]# mkdir -p /data/shell
[root@bigdata01 ~]# cd /data/shell
[root@bigdata01 shell]# vi uploadLogData.sh
#!/bin/bash
# 获取昨天日期字符串
yesterday=$1
if [ "$yesterday" = "" ]
then
yesterday=`date +%Y_%m_%d --date="1 days ago"`
fi
# 拼接日志文件路径信息
logPath=/data/log/access_${yesterday}.log
# 将日期字符串中的_去掉,并且拼接成hdfs的路径
hdfsPath=/log/${yesterday//_/}
# 在hdfs上创建目录
hdfs dfs -mkdir -p ${hdfsPath}
# 将数据上传到hdfs的指定目录中
hdfs dfs -put ${logPath} ${hdfsPath}
2、准备测试数据
[root@bigdata01 shell]# mkdir -p /data/log
[root@bigdata01 shell]# cd /data/log
[root@bigdata01 log]# vi access_2021_08_07.log
# 随机数据
abc
123
qwer
df二连
3、执行脚本
[root@bigdata01 log]# cd /data/shell/
[root@bigdata01 shell]# sh -x uploadLogData.sh
+ yesterday=
+ '[' '' = '' ']'
++ date +%Y_%m_%d '--date=1 days ago'
+ yesterday=2021_08_07
+ logPath=/data/log/access_2021_08_07.log
+ hdfsPath=/log/20210807
+ hdfs dfs -mkdir -p /log/20210807
+ hdfs dfs -put /data/log/access_2021_08_07.log /log/20210807
# 查看下hdfs的日志文件是否存在
[root@bigdata01 shell]# hdfs dfs -ls /log/20210807
Found 1 items
-rw-r--r-- 2 root supergroup 22 2021-08-08 10:23 /log/20210807/access_2021_08_07.log
# 查看日志文件
[root@bigdata01 shell]# hdfs dfs -cat /log/20210807/access_2021_08_07.log
abc
123
qwer
df二连
4、补数据
# 拷贝一份数据
[root@bigdata01 shell]# cd /data/log/
[root@bigdata01 log]# ls
access_2021_08_07.log
[root@bigdata01 log]# cp access_2021_08_07.log access_2020_01_01.log
# 执行带参Shell脚本
[root@bigdata01 log]# cd /data/shell/
[root@bigdata01 shell]# sh -x uploadLogData.sh 2020_01_01
+ yesterday=2020_01_01
+ '[' 2020_01_01 = '' ']'
+ logPath=/data/log/access_2020_01_01.log
+ hdfsPath=/log/20200101
+ hdfs dfs -mkdir -p /log/20200101
+ hdfs dfs -put /data/log/access_2020_01_01.log /log/20200101
# 查看日志文件是否存在
[root@bigdata01 shell]# hdfs dfs -ls /log/20200101
Found 1 items
-rw-r--r-- 2 root supergroup 22 2021-08-08 10:31 /log/20200101/access_2020_01_01.log
5、配置crontab定时任务,每天凌晨1点执行
# 添加任务
[root@bigdata01 shell]# vi /etc/crontab
# 设置定时
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn
0 1 * * * root sh /data/shell/uploadLogData.sh
3.1.9 HDFS的高可用和高扩展
1、HDFS的高可用HA(Highly Available)架构图
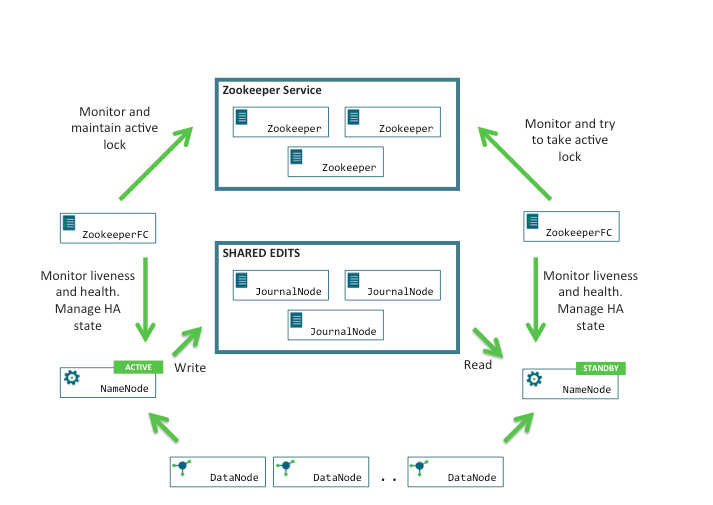
- HDFS的HA,表示一个集群中存在多个NameNode,只有一个NameNode是Activel状态,其它的是 Standby 状态,用于解决NameNode的单点故障
- ActiveNameNode(ANN)负责所有客户端的操作,StandbyNameNode(SNN)用来同步ANN的状态信息,以提供快速故障恢复能力
- ANN会把数据持久化到JournalNode(JN),SNN会读取JN里的数据,负责把edits中的内容合并到fsimage中
- 如果ANN故障了,ZK会检测到故障,由ZK故障切换器,选举SNN来做ANN,当故障的ANN重启后则成为SNN
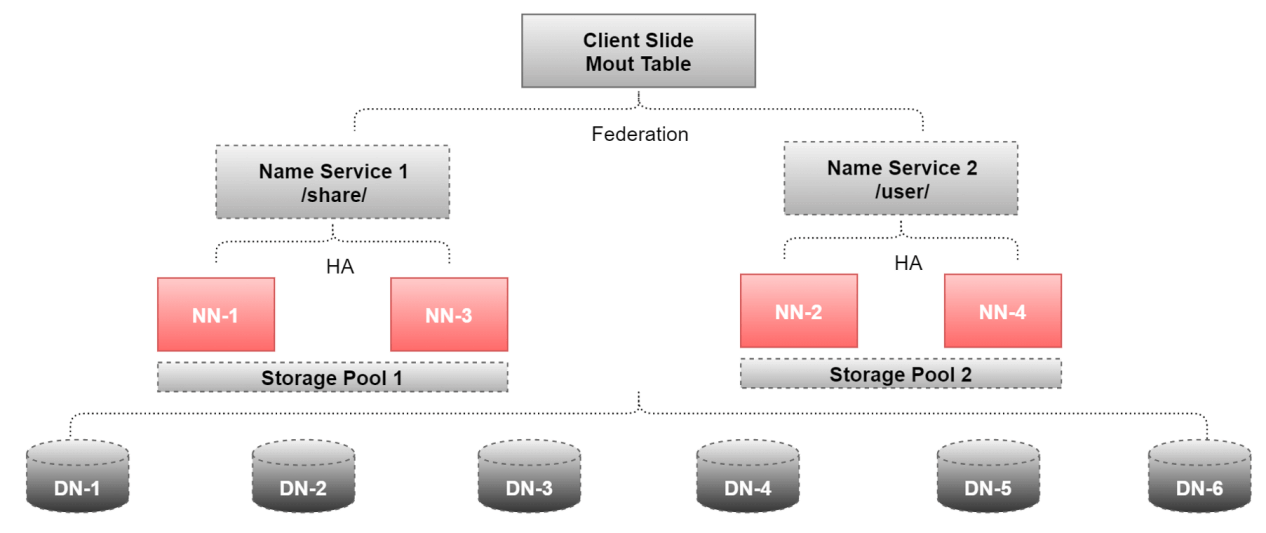
2、HDFS的高扩展(Federation)
- 集群每个NameNode分管一部分目录,则不会因为NameNode内存的限制来制约文件存储的数量
- 多个NameNode分管不同的数据,并且它们同时对外提供服务,这时候就可以为用户提供更高的读写吞吐率
- 用户可以根据业务的需要,将不同的业务数据交由不同的NameNode管理,则不同业务的NameNode影响最小
3、Federation+HA的应用

若有收获,就点个赞吧
0 人点赞
