好文。
http://www.jasongj.com/java/concurrenthashmap/
HashMap
https://www.yuque.com/docs/share/ded15ad2-6d64-4bbe-9a31-b83bb0a40675?# 《HashMap源码分析》
HashTable
Hashtable同样是基于哈希表实现的,同样每个元素是一个key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
Hashtable也是JDK1.0引入的类,是线程安全的,能用于多线程环境中。
Hashtable同样实现了Serializable接口,它支持序列化,实现了Cloneable接口,能被克隆。
package java.util;import java.io.*;public class Hashtable<K,V>extends Dictionary<K,V>implements Map<K,V>, Cloneable, java.io.Serializable {// 保存key-value的数组。// Hashtable同样采用单链表解决冲突,每一个Entry本质上是一个单向链表private transient Entry[] table;// Hashtable中键值对的数量private transient int count;// 阈值,用于判断是否需要调整Hashtable的容量(threshold = 容量*加载因子)private int threshold;// 加载因子private float loadFactor;// Hashtable被改变的次数,用于fail-fast机制的实现private transient int modCount = 0;// 序列版本号private static final long serialVersionUID = 1421746759512286392L;// 指定“容量大小”和“加载因子”的构造函数public Hashtable(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal Load: "+loadFactor);if (initialCapacity==0)initialCapacity = 1;this.loadFactor = loadFactor;table = new Entry[initialCapacity];threshold = (int)(initialCapacity * loadFactor);}// 指定“容量大小”的构造函数public Hashtable(int initialCapacity) {this(initialCapacity, 0.75f);}// 默认构造函数。public Hashtable() {// 默认构造函数,指定的容量大小是11;加载因子是0.75this(11, 0.75f);}// 包含“子Map”的构造函数public Hashtable(Map<? extends K, ? extends V> t) {this(Math.max(2*t.size(), 11), 0.75f);// 将“子Map”的全部元素都添加到Hashtable中putAll(t);}public synchronized int size() {return count;}public synchronized boolean isEmpty() {return count == 0;}// 返回“所有key”的枚举对象public synchronized Enumeration<K> keys() {return this.<K>getEnumeration(KEYS);}// 返回“所有value”的枚举对象public synchronized Enumeration<V> elements() {return this.<V>getEnumeration(VALUES);}// 判断Hashtable是否包含“值(value)”public synchronized boolean contains(Object value) {//注意,Hashtable中的value不能是null,// 若是null的话,抛出异常!if (value == null) {throw new NullPointerException();}// 从后向前遍历table数组中的元素(Entry)// 对于每个Entry(单向链表),逐个遍历,判断节点的值是否等于valueEntry tab[] = table;for (int i = tab.length ; i-- > 0 ;) {for (Entry<K,V> e = tab[i] ; e != null ; e = e.next) {if (e.value.equals(value)) {return true;}}}return false;}public boolean containsValue(Object value) {return contains(value);}// 判断Hashtable是否包含keypublic synchronized boolean containsKey(Object key) {Entry tab[] = table;//计算hash值,直接用key的hashCode代替int hash = key.hashCode();// 计算在数组中的索引值int index = (hash & 0x7FFFFFFF) % tab.length;// 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {if ((e.hash == hash) && e.key.equals(key)) {return true;}}return false;}// 返回key对应的value,没有的话返回nullpublic synchronized V get(Object key) {Entry tab[] = table;int hash = key.hashCode();// 计算索引值,int index = (hash & 0x7FFFFFFF) % tab.length;// 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {if ((e.hash == hash) && e.key.equals(key)) {return e.value;}}return null;}// 调整Hashtable的长度,将长度变成原来的2倍+1protected void rehash() {int oldCapacity = table.length;Entry[] oldMap = table;//创建新容量大小的Entry数组int newCapacity = oldCapacity * 2 + 1;Entry[] newMap = new Entry[newCapacity];modCount++;threshold = (int)(newCapacity * loadFactor);table = newMap;//将“旧的Hashtable”中的元素复制到“新的Hashtable”中for (int i = oldCapacity ; i-- > 0 ;) {for (Entry<K,V> old = oldMap[i] ; old != null ; ) {Entry<K,V> e = old;old = old.next;//重新计算indexint index = (e.hash & 0x7FFFFFFF) % newCapacity;e.next = newMap[index];newMap[index] = e;}}}// 将“key-value”添加到Hashtable中public synchronized V put(K key, V value) {// Hashtable中不能插入value为null的元素!!!if (value == null) {throw new NullPointerException();}// 若“Hashtable中已存在键为key的键值对”,// 则用“新的value”替换“旧的value”Entry tab[] = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {if ((e.hash == hash) && e.key.equals(key)) {V old = e.value;e.value = value;return old;}}// 若“Hashtable中不存在键为key的键值对”,// 将“修改统计数”+1modCount++;// 若“Hashtable实际容量” > “阈值”(阈值=总的容量 * 加载因子)// 则调整Hashtable的大小if (count >= threshold) {rehash();tab = table;index = (hash & 0x7FFFFFFF) % tab.length;}//将新的key-value对插入到tab[index]处(即链表的头结点)Entry<K,V> e = tab[index];tab[index] = new Entry<K,V>(hash, key, value, e);count++;return null;}// 删除Hashtable中键为key的元素public synchronized V remove(Object key) {Entry tab[] = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;//从table[index]链表中找出要删除的节点,并删除该节点。//因为是单链表,因此要保留带删节点的前一个节点,才能有效地删除节点for (Entry<K,V> e = tab[index], prev = null ; e != null ; prev = e, e = e.next) {if ((e.hash == hash) && e.key.equals(key)) {modCount++;if (prev != null) {prev.next = e.next;} else {tab[index] = e.next;}count--;V oldValue = e.value;e.value = null;return oldValue;}}return null;}// 将“Map(t)”的中全部元素逐一添加到Hashtable中public synchronized void putAll(Map<? extends K, ? extends V> t) {for (Map.Entry<? extends K, ? extends V> e : t.entrySet())put(e.getKey(), e.getValue());}// 清空Hashtable// 将Hashtable的table数组的值全部设为nullpublic synchronized void clear() {Entry tab[] = table;modCount++;for (int index = tab.length; --index >= 0; )tab[index] = null;count = 0;}// 克隆一个Hashtable,并以Object的形式返回。public synchronized Object clone() {try {Hashtable<K,V> t = (Hashtable<K,V>) super.clone();t.table = new Entry[table.length];for (int i = table.length ; i-- > 0 ; ) {t.table[i] = (table[i] != null)? (Entry<K,V>) table[i].clone() : null;}t.keySet = null;t.entrySet = null;t.values = null;t.modCount = 0;return t;} catch (CloneNotSupportedException e) {throw new InternalError();}}public synchronized String toString() {int max = size() - 1;if (max == -1)return "{}";StringBuilder sb = new StringBuilder();Iterator<Map.Entry<K,V>> it = entrySet().iterator();sb.append('{');for (int i = 0; ; i++) {Map.Entry<K,V> e = it.next();K key = e.getKey();V value = e.getValue();sb.append(key == this ? "(this Map)" : key.toString());sb.append('=');sb.append(value == this ? "(this Map)" : value.toString());if (i == max)return sb.append('}').toString();sb.append(", ");}}// 获取Hashtable的枚举类对象// 若Hashtable的实际大小为0,则返回“空枚举类”对象;// 否则,返回正常的Enumerator的对象。private <T> Enumeration<T> getEnumeration(int type) {if (count == 0) {return (Enumeration<T>)emptyEnumerator;} else {return new Enumerator<T>(type, false);}}// 获取Hashtable的迭代器// 若Hashtable的实际大小为0,则返回“空迭代器”对象;// 否则,返回正常的Enumerator的对象。(Enumerator实现了迭代器和枚举两个接口)private <T> Iterator<T> getIterator(int type) {if (count == 0) {return (Iterator<T>) emptyIterator;} else {return new Enumerator<T>(type, true);}}// Hashtable的“key的集合”。它是一个Set,没有重复元素private transient volatile Set<K> keySet = null;// Hashtable的“key-value的集合”。它是一个Set,没有重复元素private transient volatile Set<Map.Entry<K,V>> entrySet = null;// Hashtable的“key-value的集合”。它是一个Collection,可以有重复元素private transient volatile Collection<V> values = null;// 返回一个被synchronizedSet封装后的KeySet对象// synchronizedSet封装的目的是对KeySet的所有方法都添加synchronized,实现多线程同步public Set<K> keySet() {if (keySet == null)keySet = Collections.synchronizedSet(new KeySet(), this);return keySet;}// Hashtable的Key的Set集合。// KeySet继承于AbstractSet,所以,KeySet中的元素没有重复的。private class KeySet extends AbstractSet<K> {public Iterator<K> iterator() {return getIterator(KEYS);}public int size() {return count;}public boolean contains(Object o) {return containsKey(o);}public boolean remove(Object o) {return Hashtable.this.remove(o) != null;}public void clear() {Hashtable.this.clear();}}// 返回一个被synchronizedSet封装后的EntrySet对象// synchronizedSet封装的目的是对EntrySet的所有方法都添加synchronized,实现多线程同步public Set<Map.Entry<K,V>> entrySet() {if (entrySet==null)entrySet = Collections.synchronizedSet(new EntrySet(), this);return entrySet;}// Hashtable的Entry的Set集合。// EntrySet继承于AbstractSet,所以,EntrySet中的元素没有重复的。private class EntrySet extends AbstractSet<Map.Entry<K,V>> {public Iterator<Map.Entry<K,V>> iterator() {return getIterator(ENTRIES);}public boolean add(Map.Entry<K,V> o) {return super.add(o);}// 查找EntrySet中是否包含Object(0)// 首先,在table中找到o对应的Entry链表// 然后,查找Entry链表中是否存在Objectpublic boolean contains(Object o) {if (!(o instanceof Map.Entry))return false;Map.Entry entry = (Map.Entry)o;Object key = entry.getKey();Entry[] tab = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;for (Entry e = tab[index]; e != null; e = e.next)if (e.hash==hash && e.equals(entry))return true;return false;}// 删除元素Object(0)// 首先,在table中找到o对应的Entry链表// 然后,删除链表中的元素Objectpublic boolean remove(Object o) {if (!(o instanceof Map.Entry))return false;Map.Entry<K,V> entry = (Map.Entry<K,V>) o;K key = entry.getKey();Entry[] tab = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;for (Entry<K,V> e = tab[index], prev = null; e != null;prev = e, e = e.next) {if (e.hash==hash && e.equals(entry)) {modCount++;if (prev != null)prev.next = e.next;elsetab[index] = e.next;count--;e.value = null;return true;}}return false;}public int size() {return count;}public void clear() {Hashtable.this.clear();}}// 返回一个被synchronizedCollection封装后的ValueCollection对象// synchronizedCollection封装的目的是对ValueCollection的所有方法都添加synchronized,实现多线程同步public Collection<V> values() {if (values==null)values = Collections.synchronizedCollection(new ValueCollection(),this);return values;}// Hashtable的value的Collection集合。// ValueCollection继承于AbstractCollection,所以,ValueCollection中的元素可以重复的。private class ValueCollection extends AbstractCollection<V> {public Iterator<V> iterator() {return getIterator(VALUES);}public int size() {return count;}public boolean contains(Object o) {return containsValue(o);}public void clear() {Hashtable.this.clear();}}// 重新equals()函数// 若两个Hashtable的所有key-value键值对都相等,则判断它们两个相等public synchronized boolean equals(Object o) {if (o == this)return true;if (!(o instanceof Map))return false;Map<K,V> t = (Map<K,V>) o;if (t.size() != size())return false;try {// 通过迭代器依次取出当前Hashtable的key-value键值对// 并判断该键值对,存在于Hashtable中。// 若不存在,则立即返回false;否则,遍历完“当前Hashtable”并返回true。Iterator<Map.Entry<K,V>> i = entrySet().iterator();while (i.hasNext()) {Map.Entry<K,V> e = i.next();K key = e.getKey();V value = e.getValue();if (value == null) {if (!(t.get(key)==null && t.containsKey(key)))return false;} else {if (!value.equals(t.get(key)))return false;}}} catch (ClassCastException unused) {return false;} catch (NullPointerException unused) {return false;}return true;}// 计算Entry的hashCode// 若 Hashtable的实际大小为0 或者 加载因子<0,则返回0。// 否则,返回“Hashtable中的每个Entry的key和value的异或值 的总和”。public synchronized int hashCode() {int h = 0;if (count == 0 || loadFactor < 0)return h; // Returns zeroloadFactor = -loadFactor; // Mark hashCode computation in progressEntry[] tab = table;for (int i = 0; i < tab.length; i++)for (Entry e = tab[i]; e != null; e = e.next)h += e.key.hashCode() ^ e.value.hashCode();loadFactor = -loadFactor; // Mark hashCode computation completereturn h;}
针对Hashtable,我们同样给出几点比较重要的总结,但要结合与HashMap的比较来总结
- 二者的存储结构和解决冲突的方法都是相同的
- HashTable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
- Hashtable中key和value都不允许为null,而HashMap中key和value都允许为null(key只能有一个为null,而value则可以有多个为null)。但是如果在Hashtable中有类似put(null,null)的操作,编译同样可以通过,因为key和value都是Object类型,但运行时会抛出NullPointerException异常,这是JDK的规范规定的。
- Hashtable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。
- Hashtable计算hash值,直接用key的hashCode(),而HashMap重新计算了key的hash值,Hashtable在求hash值对应的位置索引时,用取模运算,而HashMap在求位置索引时,则用与运算,且这里一般先用hash&0x7FFFFFFF后,再对length取模,&0x7FFFFFFF的目的是为了将负的hash值转化为正值,因为hash值有可能为负数,而&0x7FFFFFFF后,只有符号外改变,而后面的位都不变。
HashTable是线程安全的。
LinkedHashMap
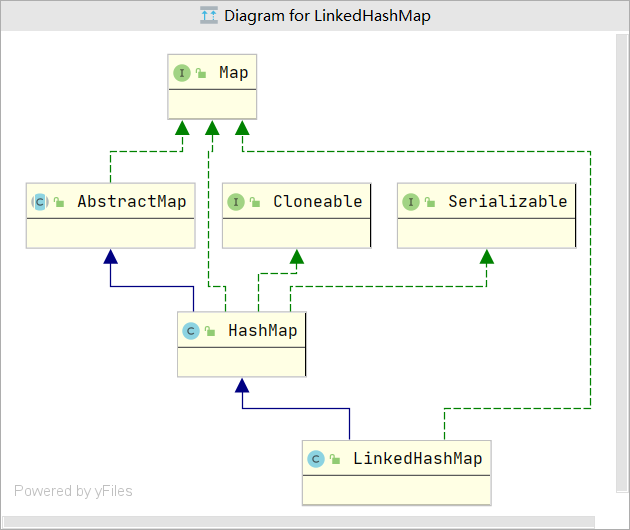
类继承关系图表LinkedHashMap 直接继承自HashMap , HashMap 一切重要的概念 LinkedHashMap 都是拥有的,这就包括了,hash 算法定位 hash 桶位置,哈希表由数组和单链表构成,并且当单链表长度超过 8 的时候转化为红黑树,扩容体系,这一切都跟 HashMap 一样。那么除了这么多关键的相同点以外,LinkedHashMap 比 HashMap 更加强大,这体现在:
**LinkedHashMap 内部维护了一个双向链表,解决了 不能随时保持遍历顺序和插入顺序一致的问题**``**HashMap****LinkedHashMap 元素的访问顺序也提供了相关支持,也就是我们常说的 LRU(最近最少使用)原则。**LinkedHashMap 双向链表的构建过程
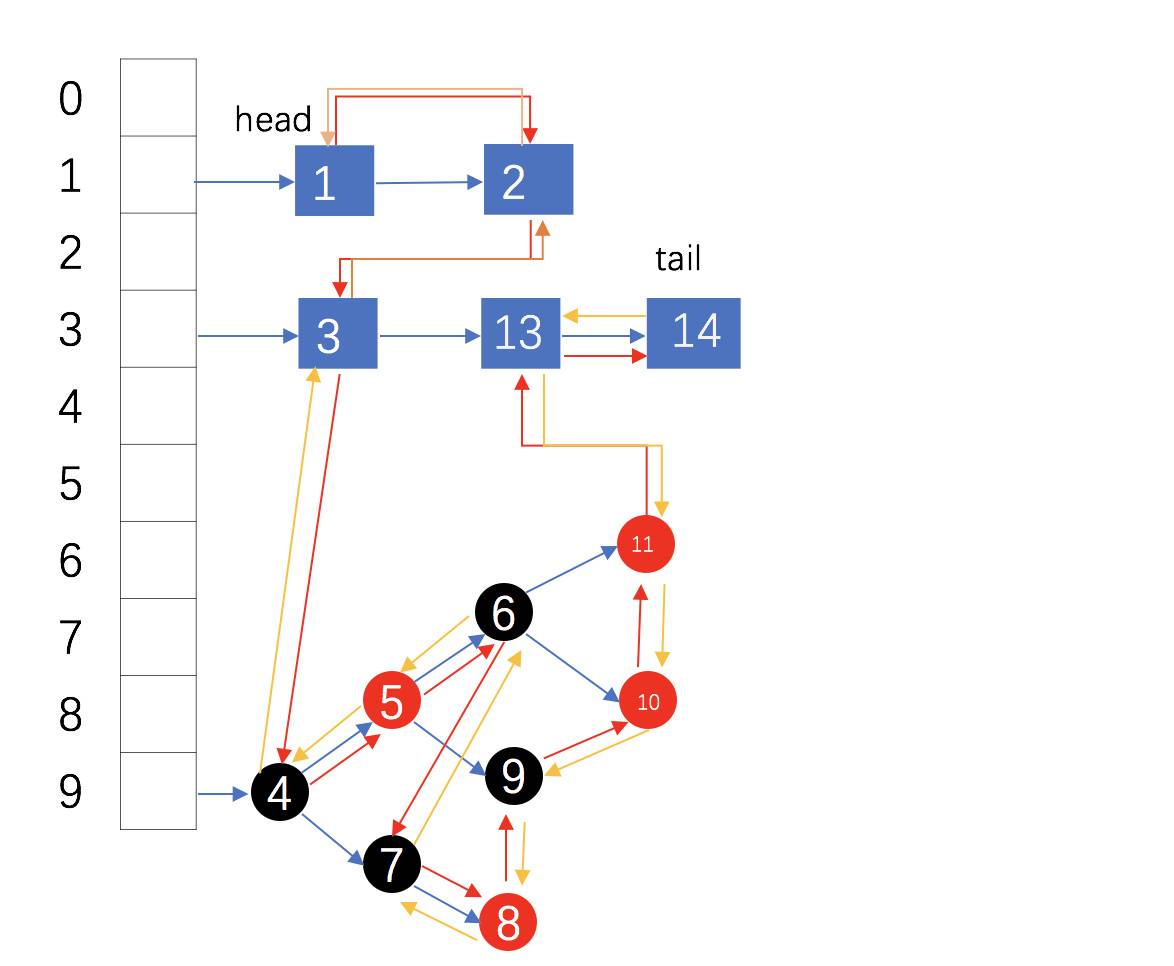
HashMap的存储结构为,数组 + 单链表 + 红黑树,从上边的图片我们也可以看出LinkedHashMap底层的存储结构并没有发生变化。
唯一变化的是使用双向链表(图中红黄箭头部分)记录了元素的添加顺序,我们知道HashMap中的 Node 节点只有 next 指针,对于双向链表而言只有 next 指针是不够的,所以LinkedHashMap对于 Node 节点进行了拓展:static class Entry<K,V> extends HashMap.Node<K,V> {Entry<K,V> before, after;Entry(int hash, K key, V value, Node<K,V> next) {super(hash, key, value, next);}}
LinkedHashMap基本存储单元Entry<K,V>继承自HashMap.Node<K,V>,并在此基础上添加了 before 和 after 这两个指针变量。这 before 变量在每次添加元素的时候将会链接上一次添加的元素,而上一次添加的元素的 after 变量将指向该次添加的元素,来形成双向链接。值得注意的是LinkedHashMap并没有覆写任何关于 HashMap put 方法。所以调用LinkedHashMap的 put 方法实际上调用了父类 HashMap 的方法。HashMap中newNode方法无法完成上述所讲的双向链表节点的间的关系,所以LinkedHashMap复写了该方法: ```java // HashMap newNode 中实现 Node
// LinkedHashMap newNode 的实现
Node
```java/*** 该引用始终指向双向链表的头部*/transient LinkedHashMap.Entry<K,V> head;/*** 该引用始终指向双向链表的尾部*/transient LinkedHashMap.Entry<K,V> tail;// newNode 中新节点,放到双向链表的尾部private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {// 添加元素之前双向链表尾部节点LinkedHashMap.Entry<K,V> last = tail;// tail 指向新添加的节点tail = p;//如果之前 tail 指向 null 那么集合为空新添加的节点 head = tail = pif (last == null)head = p;else {// 否则将新节点的 before 引用指向之前当前链表尾部p.before = last;// 当前链表尾部节点的 after 指向新节点last.after = p;}}
LinkedHashMap 通过调用父类的 HashMap 的 remove 方法将 Hash 表的中节点的删除操作完成即:
- 获取对应 key 的哈希值 hash(key),定位对应的哈希桶的位置
- 遍历对应的哈希桶中的单链表或者红黑树找到对应 key 相同的节点,在最后删除,并返回原来的节点。
对于 afterNodeRemoval(node) HashMap 中是空实现,而该方法,正是 LinkedHashMap 删除对应节点在双向链表中的关系的操作:
// 从双向链表中删除对应的节点 e 为已经删除的节点void afterNodeRemoval(Node<K,V> e) {LinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;// 将 p 节点的前后指针引用置为 null 便于内存释放p.before = p.after = null;// p.before 为 null,表明 p 是头节点if (b == null)head = a;else//否则将 p 的前驱节点连接到 p 的后驱节点b.after = a;// a 为 null,表明 p 是尾节点if (a == null)tail = b;else //否则将 a 的前驱节点连接到 ba.before = b;}
LinkedHashMap 维护节点访问顺序
HashMap的遍历结果是跟添加顺序并无关系LinkedHashMap的遍历结果就是添加顺序
这就是双向链表的作用。双向链表能做的不仅仅是这些,在介绍双向链表维护访问顺序前我们看来看一个重要的参数:
final boolean accessOrder;// 是否维护双向链表中的元素访问顺序
该方法随 LinkedHashMap 构造参数初始化,accessOrder 默认值为 false.
可以看出当我们使用 access 为 true 后,我们访问元素的顺序将会在下次遍历的时候体现,最后访问的元素将最后获得。其实这一切在 HashMap 源码中 putVal/get/repalce 最后都有一个 void afterNodeAccess(Node<K,V> e) 方法,该方法在 HashMap 中是空实现,但是在 LinkedHasMap 中该后置方法,将作为维护节点访问顺序的重要方法,我们来看下其实现:
//将被访问节点移动到链表最后void afterNodeAccess(Node<K,V> e) { // move node to lastLinkedHashMap.Entry<K,V> last;if (accessOrder && (last = tail) != e) {LinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;//访问节点的后驱置为 nullp.after = null;//如访问节点的前驱为 null 则说明 p = headif (b == null)head = a;elseb.after = a;//如果 p 不为尾节点 那么将 a 的前驱设置为 bif (a != null)a.before = b;elselast = b;if (last == null)head = p;else {p.before = last;last.after = p;}tail = p;// 将 p 接在双向链表的最后++modCount;}}
Java 中最简单的 LRU 构建方式
LRU(Least Recently Used) 算法实现的关键就像它名字一样,当达到预定阈值的时候,这个阈值可能是内存不足,或者容量达到最大,找到最近最少使用的存储元素进行移除,保证新添加的元素能够保存到集合中。
HashMap 的 putVal 方法添加完元素后还有个后置操作void afterNodeInsertion(boolean evict){} 就是这个方法。 LinkedHashMap 重写了此方法:
// HashMap 中 putVal 方法实现 evict 传递的 true,表示表处于创建模式。public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) { .... }//evict 由上述说明大部分情况下都传 true 表示表处于创建模式void afterNodeInsertion(boolean evict) { // possibly remove eldestLinkedHashMap.Entry<K,V> first;//由于 evict = true 那么当链表不为空的时候 且 removeEldestEntry(first) 返回 true 的时候进入if 内部if (evict && (first = head) != null && removeEldestEntry(first)) {K key = first.key;removeNode(hash(key), key, null, false, true);//移除双向链表中处于 head 的节点}}//LinkedHashMap 默认返回 false 则不删除节点。 返回 true 双向链表中处于 head 的节点protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {return false;}
由上述源码可以看出,如果 removeEldestEntry(Map.Entry<K,V> eldest) 方法返回值为 true 的时候,当我们添加一个新的元素之后,afterNodeInsertion这个后置操作,将会删除双向链表最初的节点,也就是 head 节点。
TreeMap
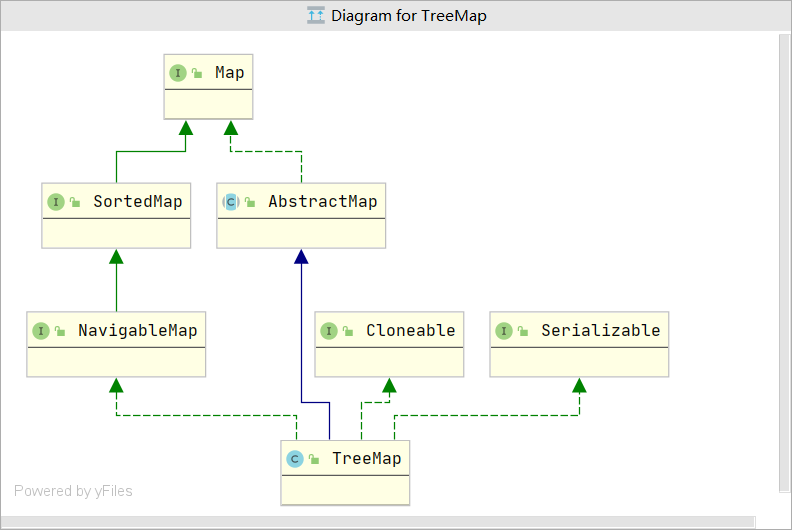
TreeMap继承于AbstractMap,实现了Map, Cloneable, NavigableMap, Serializable接口。
(1)TreeMap 继承于AbstractMap,而AbstractMap实现了Map接口,并实现了Map接口中定义的方法,减少了其子类继承的复杂度;
(2)TreeMap 实现了Map接口,成为Map框架中的一员,可以包含着key—value形式的元素;
(3)TreeMap 实现了NavigableMap接口,意味着拥有了更强的元素搜索能力;
(4)TreeMap 实现了Cloneable接口,实现了clone()方法,可以被克隆;
(5)TreeMap 实现了Java.io.Serializable接口,支持序列化操作,可通过Hessian协议进行传输。
对于SortedMap来说,该类是TreeMap体系中的父接口,也是区别于HashMap体系最关键的一个接口。
主要原因就是SortedMap接口中定义的第一个方法—-Comparator<? super K> comparator();
public interface SortedMap<K,V> extends Map<K,V> {//返回元素比较器。如果是自然顺序,则返回null;Comparator<? super K> comparator();//返回从fromKey到toKey的集合:含头不含尾java.util.SortedMap<K,V> subMap(K fromKey, K toKey);//返回从头到toKey的集合:不包含toKeyjava.util.SortedMap<K,V> headMap(K toKey);//返回从fromKey到结尾的集合:包含fromKeyjava.util.SortedMap<K,V> tailMap(K fromKey);//返回集合中的第一个元素:K firstKey();//返回集合中的最后一个元素:K lastKey();//返回集合中所有key的集合:Set<K> keySet();//返回集合中所有value的集合:Collection<V> values();//返回集合中的元素映射:Set<Map.Entry<K, V>> entrySet();}
NavigableMap接口又是对SortedMap进一步的扩展:主要增加了对集合内元素的搜索获取操作,例如:返回集合中某一区间内的元素、返回小于大于某一值的元素等类似操作。
public interface NavigableMap<K,V> extends SortedMap<K,V> {//返回小于key的第一个元素:Map.Entry<K,V> lowerEntry(K key);//返回小于key的第一个键:K lowerKey(K key);//返回小于等于key的第一个元素:Map.Entry<K,V> floorEntry(K key);//返回小于等于key的第一个键:K floorKey(K key);//返回大于或者等于key的第一个元素:Map.Entry<K,V> ceilingEntry(K key);//返回大于或者等于key的第一个键:K ceilingKey(K key);//返回大于key的第一个元素:Map.Entry<K,V> higherEntry(K key);//返回大于key的第一个键:K higherKey(K key);//返回集合中第一个元素:Map.Entry<K,V> firstEntry();//返回集合中最后一个元素:Map.Entry<K,V> lastEntry();//返回集合中第一个元素,并从集合中删除:Map.Entry<K,V> pollFirstEntry();//返回集合中最后一个元素,并从集合中删除:Map.Entry<K,V> pollLastEntry();//返回倒序的Map集合:java.util.NavigableMap<K,V> descendingMap();NavigableSet<K> navigableKeySet();//返回Map集合中倒序的Key组成的Set集合:NavigableSet<K> descendingKeySet();java.util.NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive,K toKey, boolean toInclusive);java.util.NavigableMap<K,V> headMap(K toKey, boolean inclusive);java.util.NavigableMap<K,V> tailMap(K fromKey, boolean inclusive);SortedMap<K,V> subMap(K fromKey, K toKey);SortedMap<K,V> headMap(K toKey);SortedMap<K,V> tailMap(K fromKey);}
TreeMap具有如下特点:
- 不允许出现重复的key
- 可以插入null键,null值
- 可以对元素进行排序
-
TreeMap基本操作
public class TreeMapTest {public static void main(String[] agrs){//创建TreeMap对象:TreeMap<String,Integer> treeMap = new TreeMap<String,Integer>();System.out.println("初始化后,TreeMap元素个数为:" + treeMap.size());//新增元素:treeMap.put("hello",1);treeMap.put("world",2);treeMap.put("my",3);treeMap.put("name",4);treeMap.put("is",5);treeMap.put("jiaboyan",6);treeMap.put("i",6);treeMap.put("am",6);treeMap.put("a",6);treeMap.put("developer",6);System.out.println("添加元素后,TreeMap元素个数为:" + treeMap.size());//遍历元素:Set<Map.Entry<String,Integer>> entrySet = treeMap.entrySet();for(Map.Entry<String,Integer> entry : entrySet){String key = entry.getKey();Integer value = entry.getValue();System.out.println("TreeMap元素的key:"+key+",value:"+value);}//获取所有的key:Set<String> keySet = treeMap.keySet();for(String strKey:keySet){System.out.println("TreeMap集合中的key:"+strKey);}//获取所有的value:Collection<Integer> valueList = treeMap.values();for(Integer intValue:valueList){System.out.println("TreeMap集合中的value:" + intValue);}//获取元素:Integer getValue = treeMap.get("jiaboyan");//获取集合内元素key为"jiaboyan"的值String firstKey = treeMap.firstKey();//获取集合内第一个元素String lastKey =treeMap.lastKey();//获取集合内最后一个元素String lowerKey =treeMap.lowerKey("jiaboyan");//获取集合内的key小于"jiaboyan"的keyString ceilingKey =treeMap.ceilingKey("jiaboyan");//获取集合内的key大于等于"jiaboyan"的keySortedMap<String,Integer> sortedMap =treeMap.subMap("a","my");//获取集合的key从"a"到"my"的元素//删除元素:Integer removeValue = treeMap.remove("jiaboyan");//删除集合中key为"jiaboyan"的元素treeMap.clear(); //清空集合元素://判断方法:boolean isEmpty = treeMap.isEmpty();//判断集合是否为空boolean isContain = treeMap.containsKey("jiaboyan");//判断集合的key中是否包含"jiaboyan"}}
TreeMap排序
使用元素自然排序
在使用自然顺序排序时候,需要区分两种情况:一种是Jdk定义的对象,一种是我们应用自己定义的对象;
public class SortedTest implements Comparable<SortedTest> {private int age;public SortedTest(int age){this.age = age;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}//自定义对象,实现compareTo(T o)方法:public int compareTo(SortedTest sortedTest) {int num = this.age - sortedTest.getAge();//为0时候,两者相同:if(num==0){return 0;//大于0时,传入的参数小:}else if(num>0){return 1;//小于0时,传入的参数大:}else{return -1;}}}public class TreeMapTest {public static void main(String[] agrs){//自然顺序比较naturalSort();}//自然排序顺序:public static void naturalSort(){//第一种情况:Integer对象TreeMap<Integer,String> treeMapFirst = new TreeMap<Integer, String>();treeMapFirst.put(1,"jiaboyan");treeMapFirst.put(6,"jiaboyan");treeMapFirst.put(3,"jiaboyan");treeMapFirst.put(10,"jiaboyan");treeMapFirst.put(7,"jiaboyan");treeMapFirst.put(13,"jiaboyan");System.out.println(treeMapFirst.toString());//第二种情况:SortedTest对象TreeMap<SortedTest,String> treeMapSecond = new TreeMap<SortedTest, String>();treeMapSecond.put(new SortedTest(10),"jiaboyan");treeMapSecond.put(new SortedTest(1),"jiaboyan");treeMapSecond.put(new SortedTest(13),"jiaboyan");treeMapSecond.put(new SortedTest(4),"jiaboyan");treeMapSecond.put(new SortedTest(0),"jiaboyan");treeMapSecond.put(new SortedTest(9),"jiaboyan");System.out.println(treeMapSecond.toString());}}
在自然顺序比较中,需要让被比较的元素实现Comparable接口,否则在向集合里添加元素时报:”java.lang.ClassCastException: com.jiaboyan.collection.map.SortedTest cannot be cast to java.lang.Comparable”异常;这是因为在调用put()方法时,会将传入的元素转化成Comparable类型对象,所以当你传入的元素没有实现Comparable接口时,就无法转换,报错。
- 使用自定义比较器排序
使用自定义比较器排序,需要在创建TreeMap对象时,将自定义比较器对象传入到TreeMap构造方法中;
自定义比较器对象,需要实现Comparator接口,并实现比较方法compare(T o1,T o2);
值得一提的是,使用自定义比较器排序的话,被比较的对象无需再实现Comparable接口了。
public class SortedTest {private int age;public SortedTest(int age){this.age = age;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}}public class SortedTestComparator implements Comparator<SortedTest> {//自定义比较器:实现compare(T o1,T o2)方法:public int compare(SortedTest sortedTest1, SortedTest sortedTest2) {int num = sortedTest1.getAge() - sortedTest2.getAge();if(num==0){//为0时候,两者相同:return 0;}else if(num>0){//大于0时,后面的参数小:return 1;}else{//小于0时,前面的参数小:return -1;}}}public class TreeMapTest {public static void main(String[] agrs){//自定义顺序比较customSort();}//自定义排序顺序:public static void customSort(){TreeMap<SortedTest,String> treeMap = new TreeMap<SortedTest, String>(new SortedTestComparator());treeMap.put(new SortedTest(10),"hello");treeMap.put(new SortedTest(21),"my");treeMap.put(new SortedTest(15),"name");treeMap.put(new SortedTest(2),"is");treeMap.put(new SortedTest(1),"jiaboyan");treeMap.put(new SortedTest(7),"world");System.out.println(treeMap.toString());}}
background introduction (tree)
- 二叉查找树
二叉查找树规定:
如果二叉查找树的左子树不为空,那么它的左子树上的任意节点的值都小于根节点的值;如果二叉查找树的右子树不为空,那么它的右子树上的任意节点的值都大于根节点的值;
- 平衡二叉树(AVL树)
它要求左右子树的高度差的绝对值不能大于1,也就是说左右子树的高度差只能为-1、0、1。
- 红黑树

NIL节点是就是一个假想的或是无实在意义的节点,所有应该指向NULL的指针,都看成指向了NIL节点。包括叶节点的子节点指针或是根节点的父指针(均是指向null的)。
红黑树,即红颜色和黑颜色并存的自平衡二叉查找树,插入的元素节点会被赋为红色或者黑色,待所有元素插入完成后就形成了一颗完整的红黑树。
一颗红黑树必须满足以下几点要求:
- 树中每个节点必须是有颜色的,要么红色,要么黑色;
- 树中的根节点必须是黑色的;
- 树中的叶节点必须是黑色的,也就是树尾的NIL节点或者为null的节点;
- 树中任意一个节点如果是红色的,那么它的两个子节点一定是黑色的;
- 任意节点到叶节点(树最下面一个节点)的每一条路径所包含的黑色节点数目一定相同;
首先,我们先来看下在红黑树中,每一个节点的数据结构。
public class TreeNode {//节点的值:private int data;//节点的颜色:private String color;//指向左孩子的指针:private TreeNode leftTreeNode;//指向右孩子的指针:private TreeNode rightTreeNode;//指向父节点的指针private TreeNode parentNode;public TreeNode(int data, String color, TreeNode leftTreeNode,TreeNode rightTreeNode, TreeNode parentNode) {this.data = data;this.color = color;this.leftTreeNode = leftTreeNode;this.rightTreeNode = rightTreeNode;this.parentNode = parentNode;}public int getData() {return data;}public void setData(int data) {this.data = data;}public String getColor() {return color;}public void setColor(String color) {this.color = color;}public TreeNode getLeftTreeNode() {return leftTreeNode;}public void setLeftTreeNode(TreeNode leftTreeNode) {this.leftTreeNode = leftTreeNode;}public TreeNode getRightTreeNode() {return rightTreeNode;}public void setRightTreeNode(TreeNode rightTreeNode) {this.rightTreeNode = rightTreeNode;}public TreeNode getParentNode() {return parentNode;}public void setParentNode(TreeNode parentNode) {this.parentNode = parentNode;}}
与HashMap不同,TreeMap底层不是数组结构,成员变量中并没有数组,而是用根节点root来替代,所有的操作都是通过根节点来进行的。
public class TreeMap<K,V>extends AbstractMap<K,V>implements NavigableMap<K,V>, Cloneable, java.io.Serializable {//自定义的比较器:private final Comparator<? super K> comparator;//红黑树的根节点:private transient java.util.TreeMap.Entry<K,V> root = null;//集合元素数量:private transient int size = 0;//对TreeMap操作的数量:private transient int modCount = 0;//无参构造方法:comparator属性置为null//代表使用key的自然顺序来维持TreeMap的顺序,这里要求key必须实现Comparable接口public TreeMap() {comparator = null;}//带有比较器的构造方法:初始化comparator属性;public TreeMap(Comparator<? super K> comparator) {this.comparator = comparator;}//带有map的构造方法://同样比较器comparator为空,使用key的自然顺序排序public TreeMap(Map<? extends K, ? extends V> m) {comparator = null;putAll(m);}//带有SortedMap的构造方法://根据SortedMap的比较器来来维持TreeMap的顺序public TreeMap(SortedMap<K, ? extends V> m) {comparator = m.comparator();try {buildFromSorted(m.size(), m.entrySet().iterator(), null, null);} catch (java.io.IOException cannotHappen) {} catch (ClassNotFoundException cannotHappen) {}}}
TreeMap元素添加
//插入key-value:public V put(K key, V value) {//根节点赋值给t:java.util.TreeMap.Entry<K,V> t = root;//如果根节点为null,则创建第一个节点,根节点if (t == null) {//对传入的元素进行比较,若TreeMap没定义了Comparator,则验证传入的元素是否实现了Comparable接口;compare(key, key);//根节点赋值:root = new java.util.TreeMap.Entry<>(key, value, null);//长度为1:size = 1;//修改次数+1modCount++;//直接返回:此时根节点默认为黑色return null;}//如果根节点不为null:int cmp;java.util.TreeMap.Entry<K,V> parent;Comparator<? super K> cpr = comparator;//判断TreeMap中自定义比较器comparator是否为null:if (cpr != null) {// do while循环,查找新插入节点的父节点:do {// 记录上次循环的节点t,首先将根节点赋值给parent:parent = t;//利用自定义比较器的比较方法:传入的key跟当前遍历节点比较:cmp = cpr.compare(key, t.key);//判断结果小于0,处于父节点的左边if (cmp < 0)t = t.left;else if (cmp > 0)//判断结果大于0,处于父节点的右边t = t.right;else//判断结果等于0,为当前节点,覆盖原有节点处的value:return t.setValue(value);// 只有当t为null,也就是找到了新节点的parent了} while (t != null);} else {//没有自定义比较器:if (key == null)//TreeMap不允许插入key为null,抛异常:throw new NullPointerException();//将key转换为Comparable对象:若key没有实现Comparable接口,此处会报错Comparable<? super K> k = (Comparable<? super K>) key;//同上:寻找新增节点的父节点:do {parent = t;cmp = k.compareTo(t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;elsereturn t.setValue(value);} while (t != null);}//构造新增节点对象:java.util.TreeMap.Entry<K,V> e = new java.util.TreeMap.Entry<>(key, value, parent);//根据之前的比较结果,判断新增节点是在父节点的左边还是右边if (cmp < 0)// 如果新节点key的值小于父节点key的值,则插在父节点的左侧parent.left = e;else// 如果新节点key的值大于父节点key的值,则插在父节点的右侧parent.right = e;//核心方法:插入新的节点后,为了保持红黑树平衡,对红黑树进行调整fixAfterInsertion(e);size++;modCount++;return null;}//对插入的元素比较:若TreeMap没有自定义比较器,则调用调用默认自然顺序比较,要求元素必须实现Comparable接口;//若自定义比较器,则用自定义比较器对元素进行比较;final int compare(Object k1, Object k2) {return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2): comparator.compare((K)k1, (K)k2);}//核心方法:维护TreeMap平衡的处理逻辑;(回顾上面的图文描述)private void fixAfterInsertion(java.util.TreeMap.Entry<K,V> x) {//首先将新插入节点的颜色设置为红色x.color = RED;//TreeMap是否平衡的重要判断,当不在满足循环条件时,代表树已经平衡;//x不为null,不是根节点,父节点是红色(三者均满足才进行维护):while (x != null && x != root && x.parent.color == RED) {//节点x的父节点 是 x祖父节点的左孩子:if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {//获取x节点的叔叔节点y:java.util.TreeMap.Entry<K,V> y = rightOf(parentOf(parentOf(x)));//叔叔节点y是红色:if (colorOf(y) == RED) {//将x的父节点设置黑色:setColor(parentOf(x), BLACK);//将x的叔叔节点y设置成黑色:setColor(y, BLACK);//将x的祖父节点设置成红色:setColor(parentOf(parentOf(x)), RED);//将x节点的祖父节点设置成x(进入了下一次判断):x = parentOf(parentOf(x));} else {//叔叔节点y不为红色://x为其父节点的右孩子:if (x == rightOf(parentOf(x))) {x = parentOf(x);rotateLeft(x);}setColor(parentOf(x), BLACK);setColor(parentOf(parentOf(x)), RED);//右旋:rotateRight(parentOf(parentOf(x)));} } else {//节点x的父节点 是x祖父节点的右孩子://获取x节点的叔叔节点y:java.util.TreeMap.Entry<K,V> y = leftOf(parentOf(parentOf(x)));//判断叔叔节点y是否为红色:if (colorOf(y) == RED) {setColor(parentOf(x), BLACK);12setColor(y, BLACK);5setColor(parentOf(parentOf(x)), RED);10x = parentOf(parentOf(x));} else {if (x == leftOf(parentOf(x))) {x = parentOf(x);rotateRight(x);}setColor(parentOf(x), BLACK);setColor(parentOf(parentOf(x)), RED);//左旋:rotateLeft(parentOf(parentOf(x)));}}}root.color = BLACK;}//获取节点的颜色:private static <K,V> boolean colorOf(java.util.TreeMap.Entry<K,V> p) {//节点为null,则默认为黑色;return (p == null ? BLACK : p.color);}//获取p节点的父节点:private static <K,V> java.util.TreeMap.Entry<K,V> parentOf(java.util.TreeMap.Entry<K,V> p) {return (p == null ? null: p.parent);}//对节点进行着色,TreeMap使用了boolean类型来代表颜色(true为红色,false为黑色)private static <K,V> void setColor(java.util.TreeMap.Entry<K,V> p, boolean c){if (p != null)p.color = c;}//获取左子节点:private static <K,V> java.util.TreeMap.Entry<K,V> leftOf(java.util.TreeMap.Entry<K,V> p) {return (p == null) ? null: p.left;}//获取右子节点:private static <K,V> java.util.TreeMap.Entry<K,V> rightOf(java.util.TreeMap.Entry<K,V> p) {return (p == null) ? null: p.right;}//左旋:private void rotateLeft(java.util.TreeMap.Entry<K,V> p) {if (p != null) {java.util.TreeMap.Entry<K,V> r = p.right;p.right = r.left;if (r.left != null)r.left.parent = p;r.parent = p.parent;if (p.parent == null)root = r;else if (p.parent.left == p)p.parent.left = r;elsep.parent.right = r;r.left = p;p.parent = r;}}//右旋:private void rotateRight(java.util.TreeMap.Entry<K,V> p) {if (p != null) {java.util.TreeMap.Entry<K,V> l = p.left;p.left = l.right;if (l.right != null) l.right.parent = p;l.parent = p.parent;if (p.parent == null)root = l;else if (p.parent.right == p)p.parent.right = l;else p.parent.left = l;l.right = p;p.parent = l;}}
WeakHashMap

WeakHashMap也是一个散列表,它存储的内容是键值对(key-value)映射,而且键和值都可以为null。与其他散列表不同的是,WeakHashMap的键是弱键。即在WeakHashMap中当某个键不再正常使用时,会被从WeakHashMap中自动移除。更精确的说,对于给定的一个键,其映射的存在并不影响垃圾回收器对该键的回收,这就使得该键是可终止的。被终止,然后被回收。当一个键被终止时,它对应的键值对也就从映射中移除了。
构造方法
/** 使用指定的容量、加载因子初始化WeakHashMap*/public WeakHashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal Initial Capacity: "+initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal Load factor: "+loadFactor);int capacity = 1;while (capacity < initialCapacity)capacity <<= 1;table = new Entry[capacity];this.loadFactor = loadFactor;threshold = (int)(capacity * loadFactor);}/** 使用指定初始容量、默认加载因子创建WeakHashMap*/public WeakHashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}/**使用默认初始容量 16、默认加载因子0.75创建WeakHashMap*/public WeakHashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR;threshold = (int)(DEFAULT_INITIAL_CAPACITY);table = new Entry[DEFAULT_INITIAL_CAPACITY];}/** 创建包含指定传入Map的所有键值对创建WeakHashMap、使用默认加载因子、使用处理后的容量*/public WeakHashMap(Map<? extends K, ? extends V> m) {this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1, 16),DEFAULT_LOAD_FACTOR);putAll(m);}
成员属性
public class WeakHashMap<K,V> extends AbstractMap<K,V> implements Map<K,V> {/** 初始化HashMap时默认的容量、必须是2的幂*/private static final int DEFAULT_INITIAL_CAPACITY = 16;/** HashMap容量最大值、必须是2幂、并且要小于2的30次方、如果容量超过这个值、将会被这个值代替*/private static final int MAXIMUM_CAPACITY = 1 << 30;/** 默认加载因子*/private static final float DEFAULT_LOAD_FACTOR = 0.75f;/** 存储数据的Entry数组,长度是2的幂。Entry的本质是一个单向链表*/private Entry[] table;/** 当前HashMap中键值对的总数*/private int size;/** 阈值*/private int threshold;/** 加载因子*/private final float loadFactor;/** 当WeakHashMap中某个“弱引用的key”由于没有再被引用而被GC收回时、被回收的“弱引用key”会被添加到"ReferenceQueue(queue)"中。* 在这里结合WeakReference使用、用于记录WeakHashMap中的弱引用键*/private final ReferenceQueue<K> queue = new ReferenceQueue<K>();private volatile int modCount;
内部方法
/** 当key为null时使用的值* 因为WeakHashMap中允许“null的key”,若直接插入“null的key”,将其当作弱引用时,会被删除。*/private static final Object NULL_KEY = new Object();/** 当key为null时使用的值特殊处理、将其使用静态不可变常量“new Object()”代替* 在put中会被调用、防止将null作为的key被当作“弱引用键”被GC回收。*/private static Object maskNull(Object key) {return (key == null ? NULL_KEY : key);}/*** 还原对“null的key”的特殊处理* 在get(key)中被调用、返回key为null的value。*/private static <K> K unmaskNull(Object key) {return (K) (key == NULL_KEY ? null : key);}
方法
private Entry[] getTable() {expungeStaleEntries();return table;}public int size() {if (size == 0)return 0;expungeStaleEntries();return size;}/** 判断当前HashMap是否为空*/public boolean isEmpty() {return size() == 0;}//遍历queue中有的元素,如果table中有就把引用置为nullprivate void expungeStaleEntries() {Entry<K,V> e;while ( (e = (Entry<K,V>) queue.poll()) != null) {int h = e.hash;int i = indexFor(h, table.length);Entry<K,V> prev = table[i];Entry<K,V> p = prev;while (p != null) {Entry<K,V> next = p.next;if (p == e) {if (prev == e)table[i] = next;elseprev.next = next;e.next = null; // Help GCe.value = null; // " "size--;break;}prev = p;p = next;}}}
/** 获取指定key对应的value*/public V get(Object key) {Object k = maskNull(key);int h = HashMap.hash(k.hashCode());Entry[] tab = getTable();int index = indexFor(h, tab.length);Entry<K,V> e = tab[index];while (e != null) {if (e.hash == h && eq(k, e.get()))return e.value;e = e.next;}return null;}/** 是否包含传入的 key*/public boolean containsKey(Object key) {return getEntry(key) != null;}/** 获取指定key所代表的映射Entry*/Entry<K,V> getEntry(Object key) {Object k = maskNull(key);int h = HashMap.hash(k.hashCode());Entry[] tab = getTable();int index = indexFor(h, tab.length);Entry<K,V> e = tab[index];while (e != null && !(e.hash == h && eq(k, e.get())))e = e.next;return e;}/** 将指定键值对放入HashMap中、如果HashMap中存在key、则替换key映射的value*/public V put(K key, V value) {K k = (K) maskNull(key);int h = HashMap.hash(k.hashCode());Entry[] tab = getTable();int i = indexFor(h, tab.length);for (Entry<K,V> e = tab[i]; e != null; e = e.next) {if (h == e.hash && eq(k, e.get())) {V oldValue = e.value;if (value != oldValue)e.value = value;return oldValue;}}modCount++;Entry<K,V> e = tab[i];tab[i] = new Entry<K,V>(k, value, queue, h, e);if (++size >= threshold)resize(tab.length * 2);return null;}/** rehash当前WeakHashMap、此方法会在WeakHashMap容量达到阀值的时候自动调用*/void resize(int newCapacity) {Entry[] oldTable = getTable();int oldCapacity = oldTable.length;if (oldCapacity == MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return;}Entry[] newTable = new Entry[newCapacity];transfer(oldTable, newTable);table = newTable;/** If ignoring null elements and processing ref queue caused massive* shrinkage, then restore old table. This should be rare, but avoids* unbounded expansion of garbage-filled tables.*/if (size >= threshold / 2) {threshold = (int)(newCapacity * loadFactor);} else {expungeStaleEntries();transfer(newTable, oldTable);table = oldTable;}}/** 将原来table中所有元素转移到新的table中*/private void transfer(Entry[] src, Entry[] dest) {for (int j = 0; j < src.length; ++j) {Entry<K,V> e = src[j];src[j] = null;while (e != null) {Entry<K,V> next = e.next;Object key = e.get();if (key == null) {e.next = null; // Help GCe.value = null; // " "size--;} else {int i = indexFor(e.hash, dest.length);e.next = dest[i];dest[i] = e;}e = next;}}}/** 将m中所有键值对存储到HashMap中*/public void putAll(Map<? extends K, ? extends V> m) {int numKeysToBeAdded = m.size();if (numKeysToBeAdded == 0)return;/** 计算容量是否满足添加元素条件* 若不够则将原来容量扩容2倍*/if (numKeysToBeAdded > threshold) {int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1);if (targetCapacity > MAXIMUM_CAPACITY)targetCapacity = MAXIMUM_CAPACITY;int newCapacity = table.length;while (newCapacity < targetCapacity)newCapacity <<= 1;if (newCapacity > table.length)resize(newCapacity);}//使用迭代器迭代m中每个元素、然后添加到HashMap中for (Map.Entry<? extends K, ? extends V> e : m.entrySet())put(e.getKey(), e.getValue());}
Entry
/*** Entry是单向链表。* 他继承WeakReference、使得可以使用Entry的key作为弱引用、并且向ReferenceQueue(queue)中注册该引用、以便后期检测WeakHashMap中key的引用类型、进而调整WeakHashMap* 它实现了Map.Entry 接口,即实现getKey(), getValue(), setValue(V value), equals(Object o), hashCode()这些函数*/private static class Entry<K,V> extends WeakReference<K> implements Map.Entry<K,V> {private V value;private final int hash;private Entry<K,V> next;/** 创建一个实体Entry、并将Entry的key以弱引用的形式向给定的ReferenceQueue注册*/Entry(K key, V value, ReferenceQueue<K> queue, int hash, Entry<K,V> next) {//创建引用给定对象的新的弱引用,并向给定队列注册该引用。super(key, queue);this.value = value;this.hash = hash;this.next = next;}}
ConcurrentHashMap
Java 7基于分段锁的ConcurrentHashMap
Java 7中的ConcurrentHashMap的底层数据结构仍然是数组和链表。与HashMap不同的是,ConcurrentHashMap最外层不是一个大的数组,而是一个Segment的数组。每个Segment包含一个与HashMap数据结构差不多的链表数组。整体数据结构如下图所示。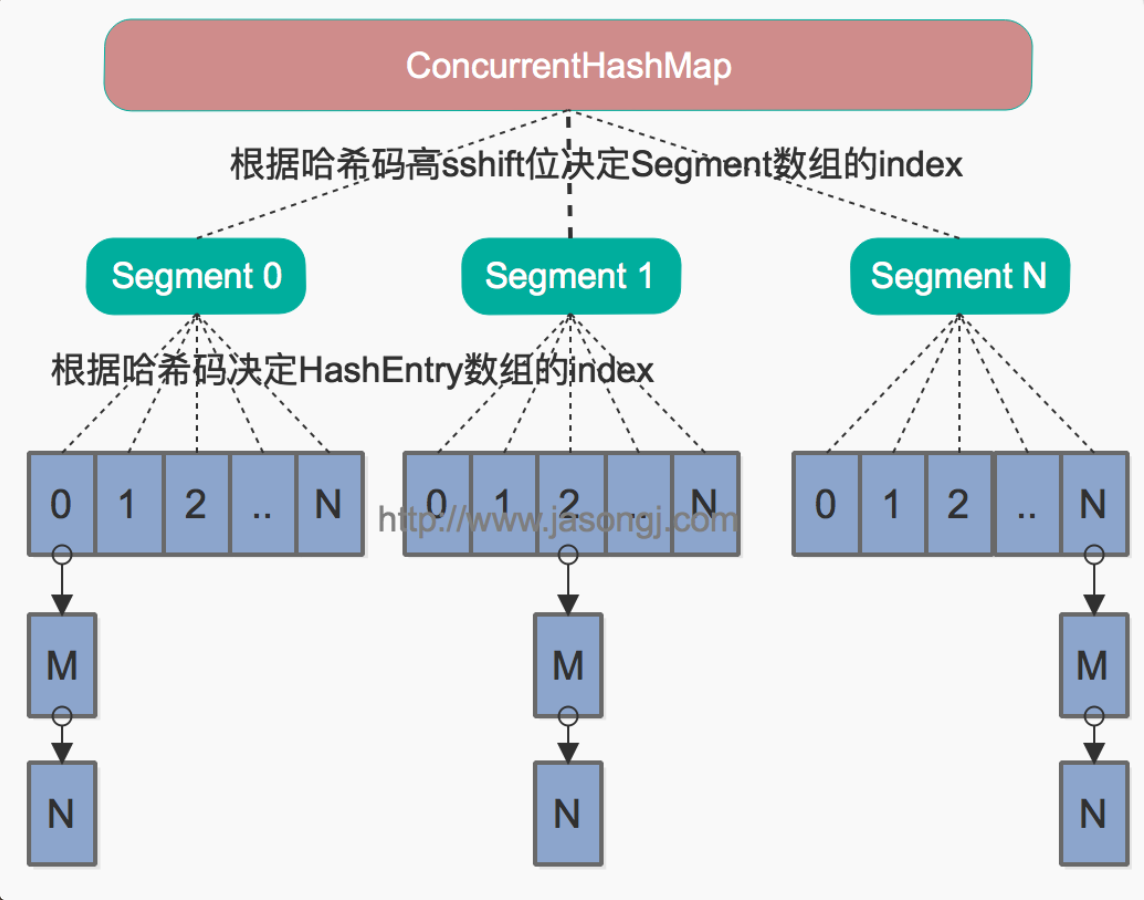
final Segment<K,V>[] segments;Segment继承了ReentrantLock,所以它就是一种可重入锁(ReentrantLock)。在ConcurrentHashMap,一个Segment就是一个子哈希表,Segment里维护了一个HashEntry数组,并发环境下,对于不同Segment的数据进行操作是不用考虑锁竞争的。(就按默认的ConcurrentLevel为16来讲,理论上就允许16个线程并发执行)。
Segment类似于HashMap,一个Segment维护着一个HashEntry数组。transient volatile HashEntry<K,V>[] table;
static final class HashEntry<K,V> {final int hash;final K key;volatile V value;volatile HashEntry<K,V> next;//其他省略}
构造方法
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)throw new IllegalArgumentException();//MAX_SEGMENTS 为1<<16=65536,也就是最大并发数为65536if (concurrencyLevel > MAX_SEGMENTS)concurrencyLevel = MAX_SEGMENTS;//2的sshif次方等于ssize,例:ssize=16,sshift=4;ssize=32,sshif=5int sshift = 0;//ssize 为segments数组长度,根据concurrentLevel计算得出int ssize = 1;while (ssize < concurrencyLevel) {++sshift;ssize <<= 1;}//segmentShift和segmentMask这两个变量在定位segment时会用到,后面会详细讲this.segmentShift = 32 - sshift;this.segmentMask = ssize - 1;if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;//计算cap的大小,即Segment中HashEntry的数组长度,cap也一定为2的n次方.int c = initialCapacity / ssize;if (c * ssize < initialCapacity)++c;int cap = MIN_SEGMENT_TABLE_CAPACITY;while (cap < c)cap <<= 1;//创建segments数组并初始化第一个Segment,其余的Segment延迟初始化Segment<K,V> s0 =new Segment<K,V>(loadFactor, (int)(cap * loadFactor),(HashEntry<K,V>[])new HashEntry[cap]);Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];UNSAFE.putOrderedObject(ss, SBASE, s0);this.segments = ss;}
从上面的代码可以看出来,Segment数组的大小ssize是由concurrentLevel来决定的,但是却不一定等于concurrentLevel,ssize一定是大于或等于concurrentLevel的最小的2的次幂。比如:默认情况下concurrentLevel是16,则ssize为16;若concurrentLevel为14,ssize为16;若concurrentLevel为17,则ssize为32。为什么Segment的数组大小一定是2的次幂?其实主要是便于通过按位与的散列算法来定位Segment的index。
put方法
1.定位segment并确保定位的Segment已初始化 2.调用Segment的put方法。
public V put(K key, V value) {Segment<K,V> s;//concurrentHashMap不允许key/value为空if (value == null)throw new NullPointerException();//hash函数对key的hashCode重新散列,避免差劲的不合理的hashcode,保证散列均匀int hash = hash(key);//返回的hash值无符号右移segmentShift位与段掩码进行位运算,定位segmentint j = (hash >>> segmentShift) & segmentMask;if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegments = ensureSegment(j);return s.put(key, hash, value, false);}//来看下concurrentHashMap代理到Segment上的put方法,//Segment中的put方法是要加锁的。只不过是锁粒度细了而已。final V put(K key, int hash, V value, boolean onlyIfAbsent) {HashEntry<K,V> node = tryLock() ? null :scanAndLockForPut(key, hash, value);//tryLock不成功时会遍历定位到的HashEnry位置的链表(遍历主要是为了使CPU缓存链表),//若找不到,则创建HashEntry。tryLock一定次数后(MAX_SCAN_RETRIES变量决定),则lock。//若遍历过程中,由于其他线程的操作导致链表头结点变化,则需要重新遍历。V oldValue;try {HashEntry<K,V>[] tab = table;int index = (tab.length - 1) & hash;//定位HashEntry,可以看到,//这个hash值在定位Segment时和在Segment中定位HashEntry都会用到,//只不过定位Segment时只用到高几位。HashEntry<K,V> first = entryAt(tab, index);for (HashEntry<K,V> e = first;;) {//分两种情况,1.entry不等于null,则遍历entry中的链表if (e != null) {K k;if ((k = e.key) == key ||(e.hash == hash && key.equals(k))) {oldValue = e.value;if (!onlyIfAbsent) {e.value = value;++modCount;}break;}e = e.next;}//2.entry等于null,需要new,再判断node是否创建成功else {//1.node new成功就把原有数组的链表接到node后面if (node != null)node.setNext(first);else//2.node new 失败就再new hashentrynode = new HashEntry<K,V>(hash, key, value, first);int c = count + 1;//若c超出阈值threshold,需要扩容并rehash。扩容后的容量是当前容量的2倍。//这样可以最大程度避免之前散列好的entry重新散列,//具体在另一篇文章中有详细分析,不赘述。//扩容并rehash的这个过程是比较消耗资源的。if (c > threshold && tab.length < MAXIMUM_CAPACITY)rehash(node);else//不扩容就直接替换tab的链表头setEntryAt(tab, index, node);++modCount;count = c;oldValue = null;break;}}} finally {unlock();}return oldValue;}
关于segmentShift和segmentMask
segmentShift和segmentMask这两个全局变量的主要作用是用来定位Segment,int j =(hash >>> segmentShift) & segmentMask。
segmentMask:段掩码,假如segments数组长度为16,则段掩码为16-1=15;segments长度为32,段掩码为32-1=31。这样得到的所有bit位都为1,可以更好地保证散列的均匀性。
segmentShift:2的sshift次方等于ssize,segmentShift=32-sshift。若segments长度为16,segmentShift=32-4=28;若segments长度为32,segmentShift=32-5=27。而计算得出的hash值最大为32位,无符号右移segmentShift,则意味着只保留高几位(其余位是没用的),然后与段掩码segmentMask位运算来定位Segment。
get方法
get方法无需加锁,由于其中涉及到的共享变量都使用volatile修饰,volatile可以保证内存可见性,所以不会读取到过期数据。
public V get(Object key) {Segment<K,V> s;HashEntry<K,V>[] tab;int h = hash(key);long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;//先定位Segment,再定位HashEntryif ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&(tab = s.table) != null) {for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);e != null; e = e.next) {K k;if ((k = e.key) == key || (e.hash == h && key.equals(k)))return e.value;}}return null;}

若有收获,就点个赞吧
0 人点赞
