
mybatis 第一天 mybatis的基础知识
课程安排:
mybatis和springmvc通过订单商品 案例驱动
第一天:基础知识(重点,内容量多)
对原生态jdbc程序(单独使用jdbc开发)问题总结
mybatis框架原理 (掌握)
mybatis入门程序
用户的增、删、改、查
mybatis开发dao两种方法:
原始dao开发方法(程序需要编写dao接口和dao实现类)(掌握)
mybaits的mapper接口(相当于dao接口)代理开发方法(掌握)
mybatis配置文件SqlMapConfig.xml
mybatis核心:
mybatis输入映射(掌握)
mybatis输出映射(掌握)
mybatis的动态sql(掌握)
第二天:高级知识
订单商品数据模型分析
高级结果集映射(一对一、一对多、多对多)
mybatis延迟加载
mybatis查询缓存(一级缓存、二级缓存)
mybaits和spring进行整合(掌握)
mybatis逆向工程
1
对原生态jdbc程序中问题总结
1.1
环境
java环境:jdk1.7.0_72
eclipse:indigo
mysql:5.1
1.2
创建mysql数据
导入下边的脚本:
sql_table.sql:记录表结构
sql_data.sql:记录测试数据,在实际企业开发中,最后提供一个初始化数据脚本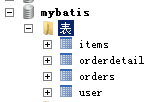
1.3
jdbc程序
使用jdbc查询mysql数据库中用户表的记录。
创建java工程,加入jar包:
数据库驱动包(mysql5.1)
上边的是mysql驱动。
下边的是oracle的驱动。
程序代码:
1.4
问题总结
1、数据库连接,使用时就创建,不使用立即释放,对数据库进行频繁连接开启和关闭,造成数据库资源浪费,影响
数据库性能。
设想:使用数据库连接池管理数据库连接。
2、将sql语句硬编码到java代码中,如果sql 语句修改,需要重新编译java代码,不利于系统维护。
设想:将sql语句配置在xml配置文件中,即使sql变化,不需要对java代码进行重新编译。
3、向preparedStatement中设置参数,对占位符号位置和设置参数值,硬编码在java代码中,不利于系统维护。
设想:将sql语句及占位符号和参数全部配置在xml中。
4、从resutSet中遍历结果集数据时,存在硬编码,将获取表的字段进行硬编码,,不利于系统维护。
设想:将查询的结果集,自动映射成java对象。
2
mybatis框架
2.1
mybatis是什么?
mybatis是一个持久层的框架,是apache下的顶级项目。
mybatis托管到goolecode下,再后来托管到github下(https://github.com/mybatis/mybatis-3/releases)。
mybatis让程序将主要精力放在sql上,通过mybatis提供的映射方式,自由灵活生成(半自动化,大部分需要程序员编写sql)满足需要sql语句。
mybatis可以将向 preparedStatement中的输入参数自动进行输入映射,将查询结果集灵活映射成java对象。(输出映射)
2.2
mybatis框架
3
3.1
需求
根据用户id(主键)查询用户信息
根据用户名称模糊查询用户信息
添加用户
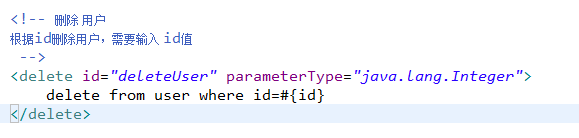
删除
用户
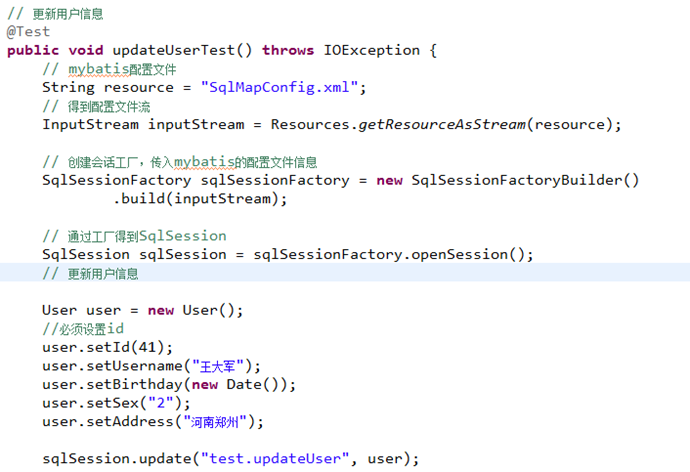
更新用户
3.1
环境
java环境:jdk1.7.0_72
eclipse:indigo
mysql:5.1
mybatis运行环境(jar包):
从https://github.com/mybatis/mybatis-3/releases下载,3.2.7版本
lib下:依赖包
mybatis-3.2.7.jar:核心 包
mybatis-3.2.7.pdf,操作指南
加入mysql的驱动包
3.2
3.3
3.4
SqlMapConfig.xml
配置mybatis的运行环境,数据源、事务等。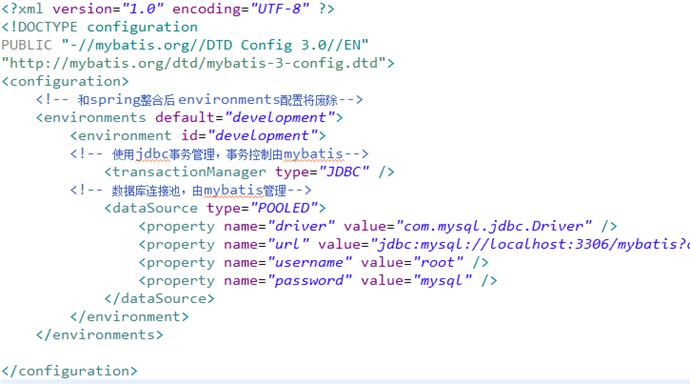
3.5
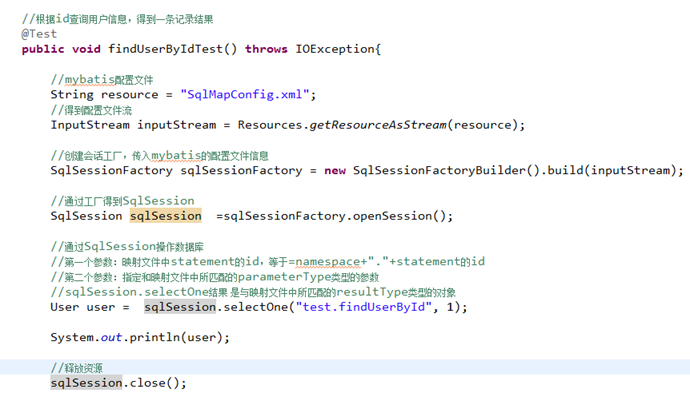
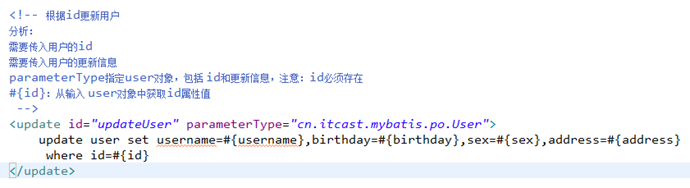
根据用户id(主键)查询用户信息
3.5.1
3.5.2
映射文件
映射文件命名:
User.xml(原始ibatis命名),mapper代理开发映射文件名称叫XXXMapper.xml,比如:UserMapper.xml、ItemsMapper.xml
在映射文件中配置sql语句。

3.5.3
在SqlMapConfig.xml加载映射文件
在sqlMapConfig.xml中加载User.xml: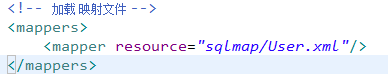
3.5.4
3.6
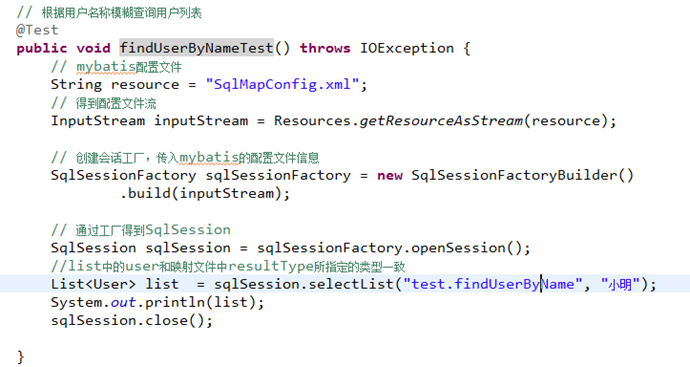
根据用户名称模糊查询用户信息
3.6.1
映射文件
使用User.xml,添加根据用户名称模糊查询用户信息的sql语句。 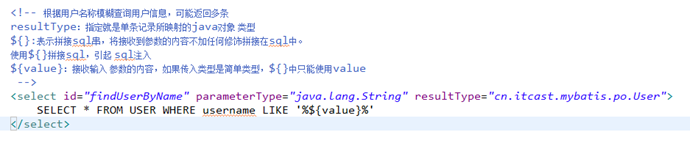
3.6.2
3.7
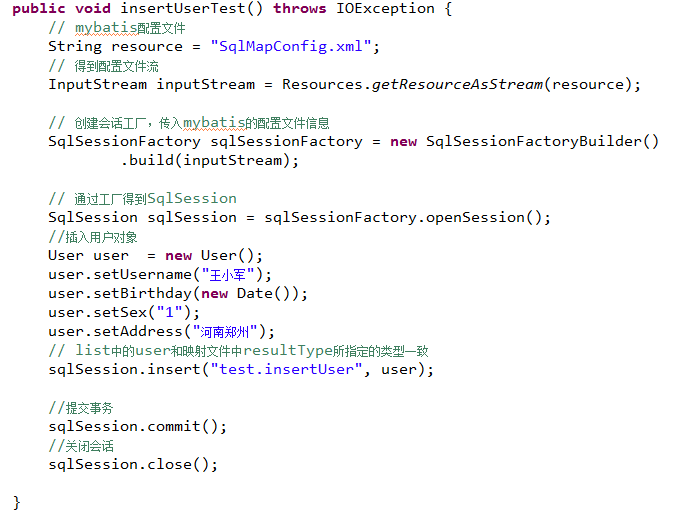
添加用户
3.7.1
映射文件
在 User.xml中配置添加用户的Statement

3.7.2
3.7.3
自增主键返回
mysql自增主键,执行insert提交之前自动生成一个自增主键。
通过mysql函数获取到刚插入记录的自增主键:
LAST_INSERT_ID()
是insert之后调用此函数。
修改insertUser定义:
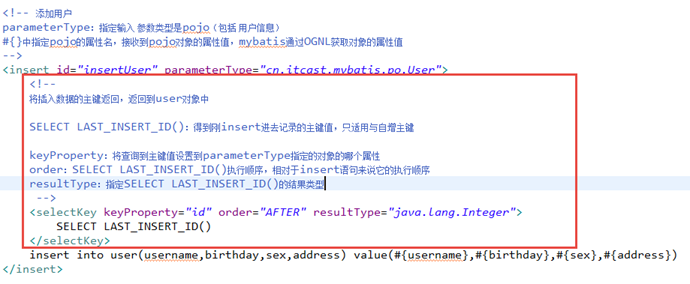
3.7.4
非自增主键返回(使用uuid())
使用mysql的uuid()函数生成主键,需要修改表中id字段类型为string,长度设置成35位。
执行思路:
先通过uuid()查询到主键,将主键输入
到sql语句中。
执行uuid()语句顺序相对于insert语句之前执行。
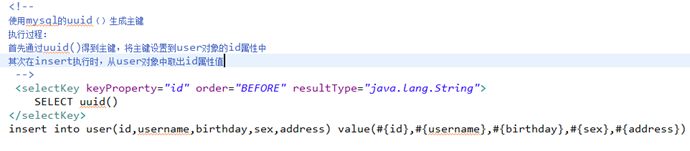
通过oracle的序列生成主键:
SELECT 序列名.nextval()
insert into user(id,username,birthday,sex,address)
value(#{id},#{username},#{birthday},#{sex},#{address})
3.8
3.8.1
3.8.2
3.9
3.9.1
3.9.2
3.10
总结
3.10.1parameterType
在映射文件中通过parameterType指定输入 参数的类型。
3.10.2resultType
3.10.3#{}和${}
#{}表示一个占位符号,#{}接收输入参数,类型可以是简单类型,pojo、hashmap。
如果接收简单类型,#{}中可以写成value或其它名称。
#{}接收pojo对象值,通过OGNL读取对象中的属性值,通过属性.属性.属性…的方式获取对象属性值。
${}表示一个拼接符号,会引用sql注入,所以不建议使用${}。
${}接收输入参数,类型可以是简单类型,pojo、hashmap。
如果接收简单类型,${}中只能写成value。
${}接收pojo对象值,通过OGNL读取对象中的属性值,通过属性.属性.属性…的方式获取对象属性值。
3.10.4selectOne和selectList
selectOne表示查询出一条记录进行映射。如果使用selectOne可以实现使用selectList也可以实现(list中只有一个对象)。
selectList表示查询出一个列表(多条记录)进行映射。如果使用selectList查询多条记录,不能使用selectOne。
如果使用selectOne报错:
org.apache.ibatis.exceptions.TooManyResultsException:
Expected one result (or null) to be returned by selectOne(), but found: 4
3.11
mybatis和hibernate本质区别和应用场景
hibernate:是一个标准ORM框架(对象关系映射)。入门门槛较高的,不需要程序写sql,sql语句自动生成了。
对sql语句进行优化、修改比较困难的。
应用场景:
适用与需求变化不多的中小型项目,比如:后台管理系统,erp、orm、oa。。
mybatis:专注是sql本身,需要程序员自己编写sql语句,sql修改、优化比较方便。mybatis是一个不完全 的ORM框架,虽然程序员自己写sql,mybatis 也可以实现映射(输入映射、输出映射)。
应用场景:
适用与需求变化较多的项目,比如:互联网项目。
企业进行技术选型,以低成本
高回报作为技术选型的原则,根据项目组的技术力量进行选择。
4
mybatis开发dao的方法
4.1
SqlSession使用范围
4.1.1
SqlSessionFactoryBuilder
通过SqlSessionFactoryBuilder创建会话工厂SqlSessionFactory
将SqlSessionFactoryBuilder当成一个工具类使用即可,不需要使用单例管理SqlSessionFactoryBuilder。
在需要创建SqlSessionFactory时候,只需要new一次SqlSessionFactoryBuilder即可。
4.1.2
SqlSessionFactory
通过SqlSessionFactory创建SqlSession,使用单例模式管理sqlSessionFactory(工厂一旦创建,使用一个实例)。
将来mybatis和spring整合后,使用单例模式管理sqlSessionFactory。
4.1.3
SqlSession
SqlSession是一个面向用户(程序员)的接口。
SqlSession中提供了很多操作数据库的方法:如:selectOne(返回单个对象)、selectList(返回单个或多个对象)、。
SqlSession是线程不安全的,在SqlSesion实现类中除了有接口中的方法(操作数据库的方法)还有数据域属性。
SqlSession最佳应用场合在方法体内,定义成局部变量使用。
4.2
4.2.1
思路
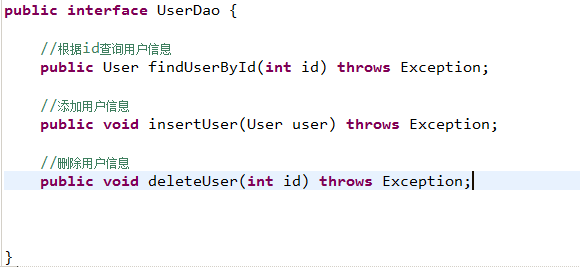
程序员需要写dao接口和dao实现类。
需要向dao实现类中注入SqlSessionFactory,在方法体内通过SqlSessionFactory创建SqlSession
4.2.2
4.2.3
dao接口实现类
public class UserDaoImpl implements UserDao {
// 需要向dao实现类中注入SqlSessionFactory
// 这里通过构造方法注入
private SqlSessionFactory sqlSessionFactory;
public UserDaoImpl(SqlSessionFactory sqlSessionFactory) {
this.sqlSessionFactory = sqlSessionFactory;
}
@Override
public User findUserById(int id) throws Exception {
SqlSession sqlSession = sqlSessionFactory.openSession();
User user = sqlSession.selectOne(“test.findUserById”, id);
// 释放资源
sqlSession.close();
return user;
}
@Override
public void insertUser(User user) throws Exception {
SqlSession sqlSession = sqlSessionFactory.openSession();
//执行插入操作
sqlSession.insert(“test.insertUser”, user);
// 提交事务
sqlSession.commit();
// 释放资源
sqlSession.close();
}
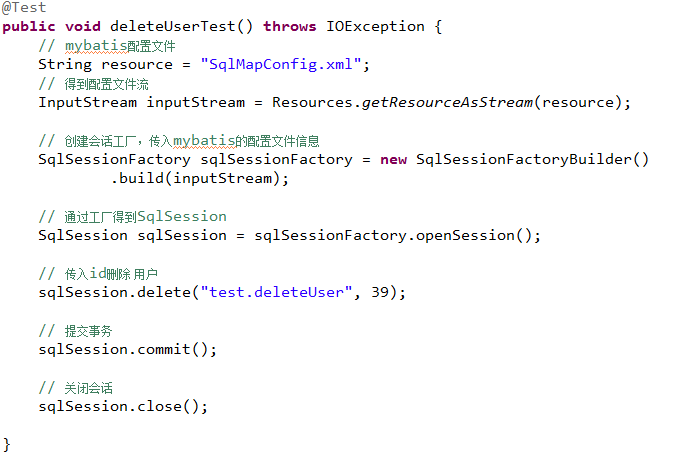
@Override
public void deleteUser(int id) throws Exception {
SqlSession sqlSession = sqlSessionFactory.openSession();
//执行插入操作
sqlSession.delete(“test.deleteUser”, id);
// 提交事务
sqlSession.commit();
// 释放资源
sqlSession.close();
}
}
4.2.4
4.2.5
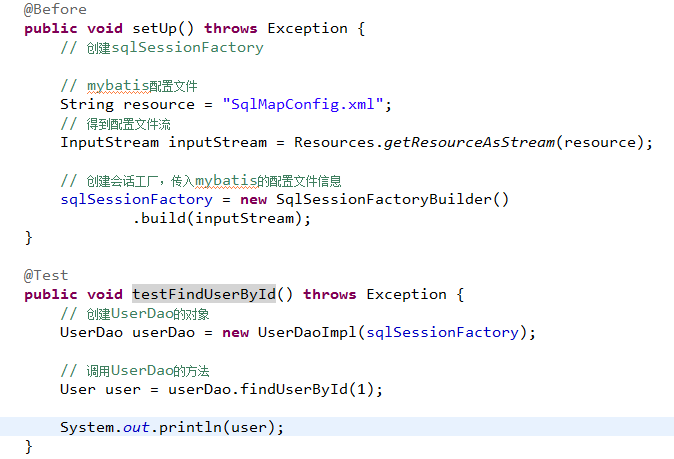
总结原始 dao开发问题
1、dao接口实现类方法中存在大量模板方法,设想能否将这些代码提取出来,大大减轻程序员的工作量。
2、调用sqlsession方法时将statement的id硬编码了
3、调用sqlsession方法时传入的变量,由于sqlsession方法使用泛型,即使变量类型传入错误,在编译阶段也不报错,不利于程序员开发。
4.3
mapper代理方法(程序员只需要mapper接口(相当 于dao接口))
4.3.1
思路(mapper代理开发规范)
程序员还需要编写mapper.xml映射文件
程序员编写mapper接口需要遵循一些开发规范,mybatis可以自动生成mapper接口实现类代理对象。
开发规范:
1、在mapper.xml中namespace等于mapper接口地址
2、mapper.java接口中的方法名和mapper.xml中statement的id一致
3、mapper.java接口中的方法输入参数类型和mapper.xml中statement的parameterType指定的类型一致。
4、mapper.java接口中的方法返回值类型和mapper.xml中statement的resultType指定的类型一致。

总结:
以上开发规范主要是对下边的代码进行统一生成:
User user =
sqlSession.selectOne(“test.findUserById”, id);
sqlSession.insert(“test.insertUser”,
user);
。。。。
4.3.2

4.3.3

4.3.4
在SqlMapConfig.xml中加载mapper.xml

4.3.5
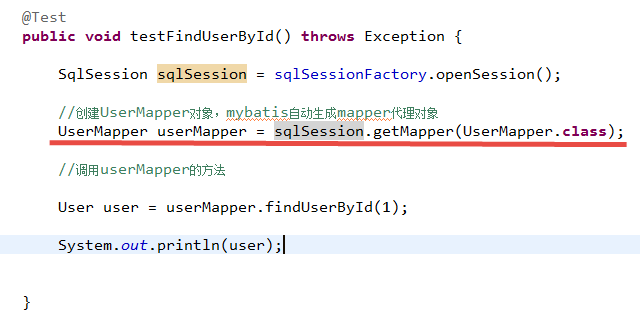
4.3.6
4.3.6.1
代理对象内部调用selectOne或selectList
如果mapper方法返回单个pojo对象(非集合对象),代理对象内部通过selectOne查询数据库。
如果mapper方法返回集合对象,代理对象内部通过selectList查询数据库。
4.3.6.2
mapper接口方法参数只能有一个是否影响系统 开发
mapper接口方法参数只能有一个,系统是否不利于扩展维护。
系统 框架中,dao层的代码是被业务层公用的。
即使mapper接口只有一个参数,可以使用包装类型的pojo满足不同的业务方法的需求。
注意:持久层方法的参数可以包装类型、map。。。,service方法中建议不要使用包装类型(不利于业务层的可扩展)。
5
SqlMapConfig.xml
mybatis的全局配置文件SqlMapConfig.xml,配置内容如下:
properties(属性)
settings(全局配置参数)
typeAliases(类型别名)
typeHandlers(类型处理器)
objectFactory(对象工厂)
plugins(插件)
environments(环境集合属性对象)
environment(环境子属性对象)
transactionManager(事务管理)
dataSource(数据源)
mappers(映射器)
5.1
properties属性
需求:
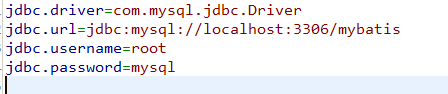
将数据库连接参数单独配置在db.properties中,只需要在SqlMapConfig.xml中加载db.properties的属性值。
在SqlMapConfig.xml中就不需要对数据库连接参数硬编码。
将数据库连接参数只配置在db.properties中,原因:方便对参数进行统一管理,其它xml可以引用该db.properties。
在sqlMapConfig.xml加载属性文件: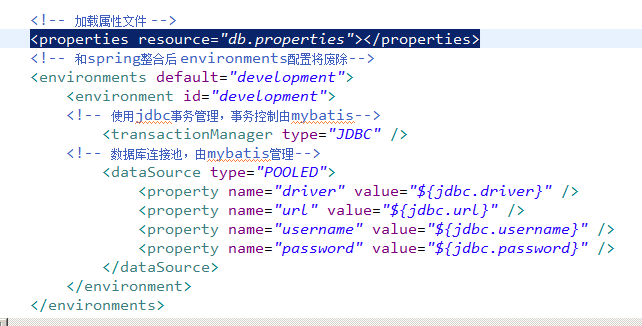
properties特性:
注意: MyBatis 将按照下面的顺序来加载属性:
u 在 properties 元素体内定义的属性首先被读取。
u 然后会读取properties
元素中resource或 url 加载的属性,它会覆盖已读取的同名属性。
u 最后读取parameterType传递的属性,它会覆盖已读取的同名属性。
建议:
不要在properties元素体内添加任何属性值,只将属性值定义在properties文件中。
在properties文件中定义属性名要有一定的特殊性,如:XXXXX.XXXXX.XXXX
5.2
settings全局参数配置
mybatis框架在运行时可以调整一些运行参数。
比如:开启二级缓存、开启延迟加载。。
全局参数将会影响mybatis的运行行为。
详细参见“学习资料/mybatis-settings.xlsx”文件


5.3
typeAliases(别名)重点
5.3.1
需求
在mapper.xml中,定义很多的statement,statement需要parameterType指定输入参数的类型、需要resultType指定输出结果的映射类型。
如果在指定类型时输入类型全路径,不方便进行开发,可以针对parameterType或resultType指定的类型定义一些别名,在mapper.xml中通过别名定义,方便开发。
5.3.2
mybatis默认支持别名
| 别名 | 映射的类型 |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | BigDecimal |
5.3.3
自定义别名
5.3.3.1
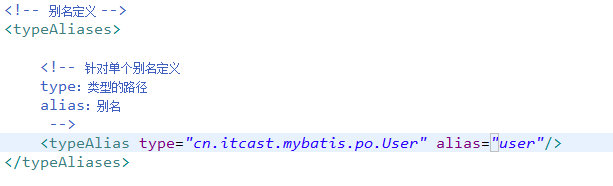

5.3.3.2
批量定义别名(常用)

5.4
typeHandlers(类型处理器)
mybatis中通过typeHandlers完成jdbc类型和java类型的转换。
通常情况下,mybatis提供的类型处理器满足日常需要,不需要自定义.
mybatis支持类型处理器:
| 类型处理器 | Java类型 | JDBC类型 |
|---|---|---|
| BooleanTypeHandler | Boolean,boolean | 任何兼容的布尔值 |
| ByteTypeHandler | Byte,byte | 任何兼容的数字或字节类型 |
| ShortTypeHandler | Short,short | 任何兼容的数字或短整型 |
| IntegerTypeHandler | Integer,int | 任何兼容的数字和整型 |
| LongTypeHandler | Long,long | 任何兼容的数字或长整型 |
| FloatTypeHandler | Float,float | 任何兼容的数字或单精度浮点型 |
| DoubleTypeHandler | Double,double | 任何兼容的数字或双精度浮点型 |
| BigDecimalTypeHandler | BigDecimal | 任何兼容的数字或十进制小数类型 |
| StringTypeHandler | String | CHAR和VARCHAR类型 |
| ClobTypeHandler | String | CLOB和LONGVARCHAR类型 |
| NStringTypeHandler | String | NVARCHAR和NCHAR类型 |
| NClobTypeHandler | String | NCLOB类型 |
| ByteArrayTypeHandler | byte[] | 任何兼容的字节流类型 |
| BlobTypeHandler | byte[] | BLOB和LONGVARBINARY类型 |
| DateTypeHandler | Date(java.util) | TIMESTAMP类型 |
| DateOnlyTypeHandler | Date(java.util) | DATE类型 |
| TimeOnlyTypeHandler | Date(java.util) | TIME类型 |
| SqlTimestampTypeHandler | Timestamp(java.sql) | TIMESTAMP类型 |
| SqlDateTypeHandler | Date(java.sql) | DATE类型 |
| SqlTimeTypeHandler | Time(java.sql) | TIME类型 |
| ObjectTypeHandler | 任意 | 其他或未指定类型 |
| EnumTypeHandler | Enumeration类型 | VARCHAR-任何兼容的字符串类型,作为代码存储(而不是索引)。 |
5.5
mappers(映射配置)
5.5.1
通过resource加载单个映射文件

5.5.2
按照上边的规范,将mapper.java和mapper.xml放在一个目录
,且同名。

**
5.5.3

6
输入映射
通过parameterType指定输入参数的类型,类型可以是简单类型、hashmap、pojo的包装类型
。
6.1
6.1.1
需求 完成用户信息的综合查询,需要传入查询条件很复杂(可能包括用户信息、其它信息,比如商品、订单的)
6.1.2
定义包装类型pojo
针对上边需求,建议使用自定义的包装类型的pojo。
在包装类型的pojo中将复杂的查询条件包装进去。
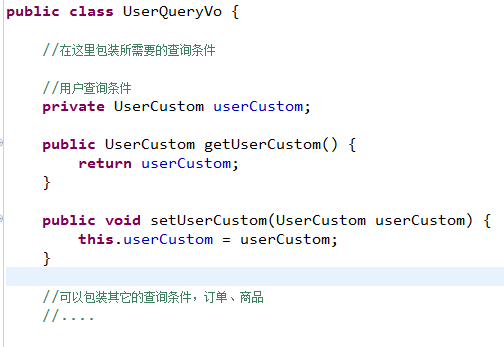
6.1.3
mapper.xml
在UserMapper.xml中定义用户信息综合查询(查询条件复杂,通过高级查询进行复杂关联查询)。
6.1.4

6.1.5
测试代码
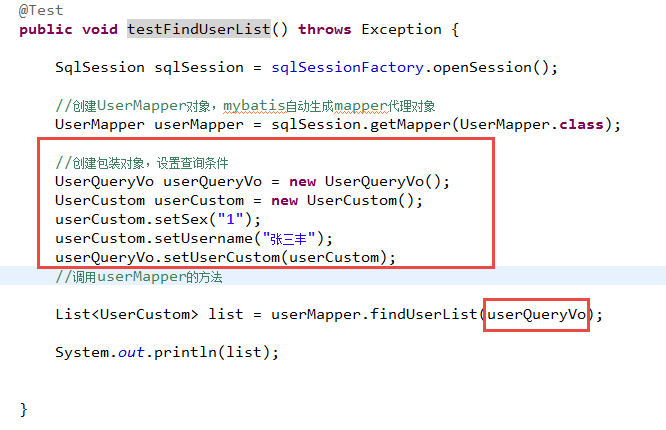
7
输出映射
7.1
resultType
使用resultType进行输出映射,只有查询出来的列名和pojo中的属性名一致,该列才可以映射成功。
如果查询出来的列名和pojo中的属性名全部不一致,没有创建pojo对象。
只要查询出来的列名和pojo中的属性有一个一致,就会创建pojo对象。
7.1.1
7.1.1.1
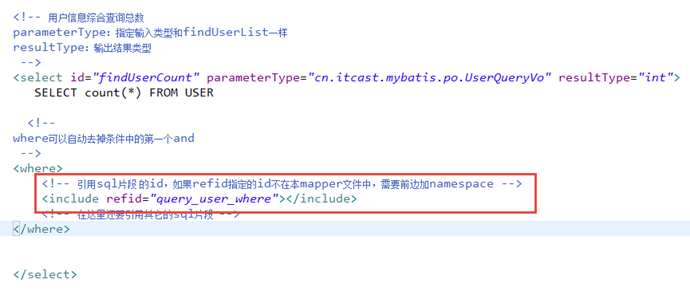
需求
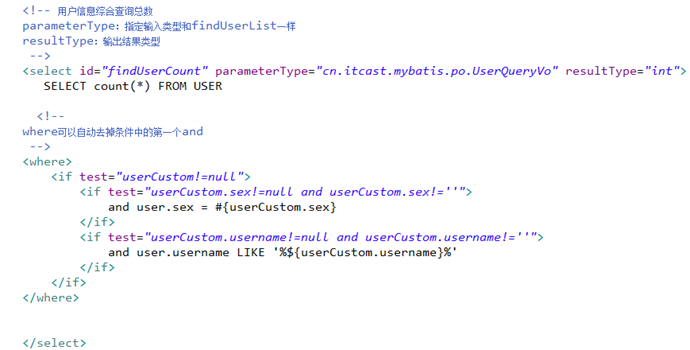
用户信息的综合查询列表总数,通过查询总数和上边用户综合查询列表才可以实现分页。
7.1.1.2

7.1.1.3

7.1.1.4
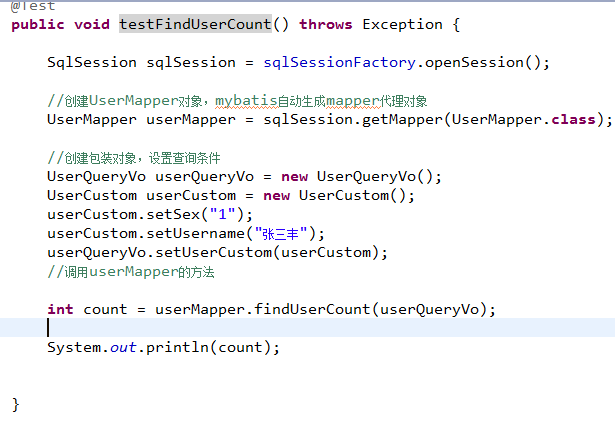
7.1.1.5
小结
查询出来的结果集只有一行且一列,可以使用简单类型进行输出映射。
7.1.2
输出pojo对象和pojo列表
不管是输出的pojo单个对象还是一个列表(list中包括pojo),在mapper.xml中resultType指定的类型是一样的。
在mapper.java指定的方法返回值类型不一样:
1、输出单个pojo对象,方法返回值是单个对象类型
2、输出pojo对象list,方法返回值是List
生成的动态代理对象中是根据mapper方法的返回值类型确定是调用selectOne(返回单个对象调用)还是selectList (返回集合对象调用
).
7.2
resultMap
mybatis中使用resultMap完成高级输出结果映射。
7.2.1
resultMap使用方法
如果查询出来的列名和pojo的属性名不一致,通过定义一个resultMap对列名和pojo属性名之间作一个映射关系。
1、定义resultMap
2、使用resultMap作为statement的输出映射类型
7.2.2
将下边的sql使用User完成映射
SELECT id id,username username FROM USER
WHERE id=#{value}
User类中属性名和上边查询列名不一致。
7.2.2.1
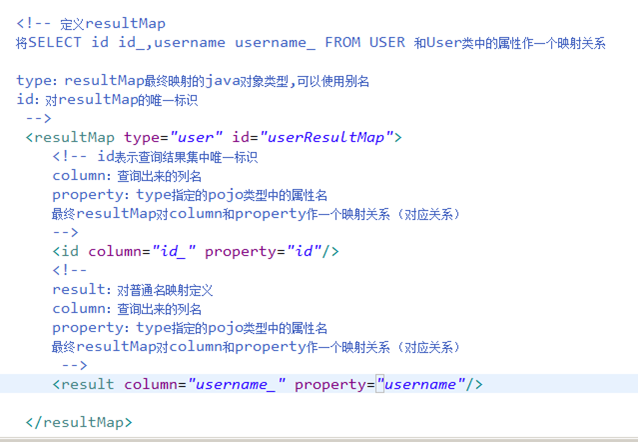
7.2.2.2

7.2.2.3

7.2.2.4
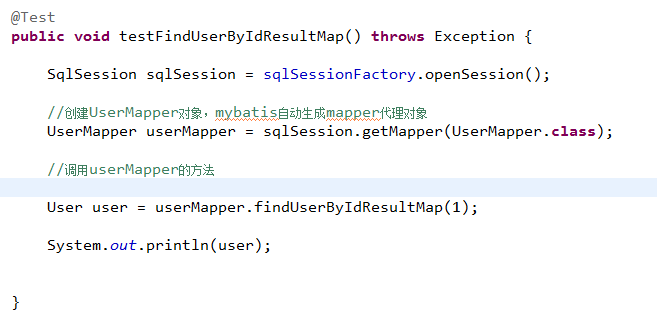
7.3
小结
使用resultType进行输出映射,只有查询出来的列名和pojo中的属性名一致,该列才可以映射成功。
如果查询出来的列名和pojo的属性名不一致,通过定义一个resultMap对列名和pojo属性名之间作一个映射关系。
8
动态sql
8.1
什么是动态sql
mybatis核心 对sql语句进行灵活操作,通过表达式进行判断,对sql进行灵活拼接、组装。
8.2
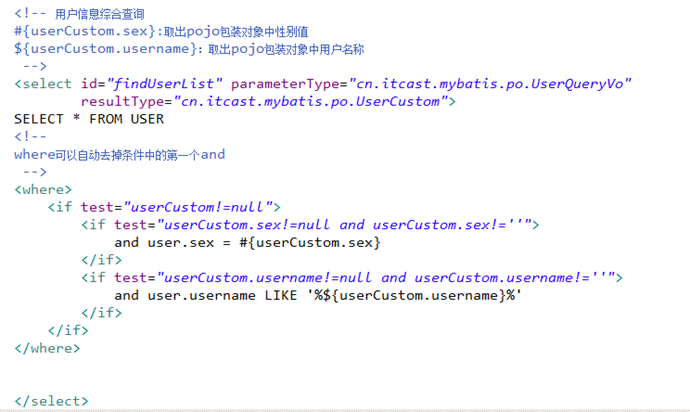
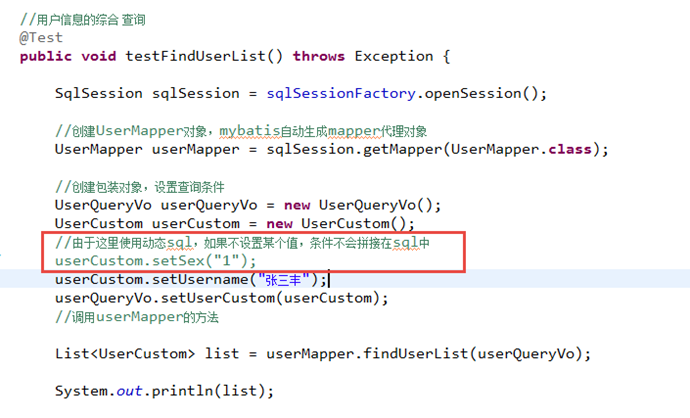
需求
用户信息综合查询列表和用户信息查询列表总数这两个statement的定义使用动态sql。
对查询条件进行判断,如果输入参数不为空才进行查询条件拼接。
8.3
8.4
8.5
sql片段
8.5.1
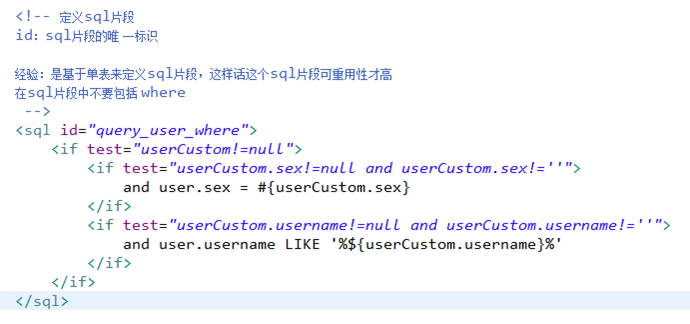
需求
将上边实现的动态sql判断代码块抽取出来,组成一个sql片段。其它的statement中就可以引用sql片段。
方便程序员进行开发。
8.5.2
8.5.3
引用sql片段
在mapper.xml中定义的statement中引用sql片段: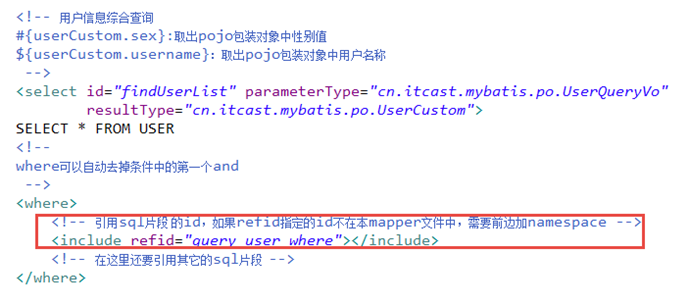
8.1
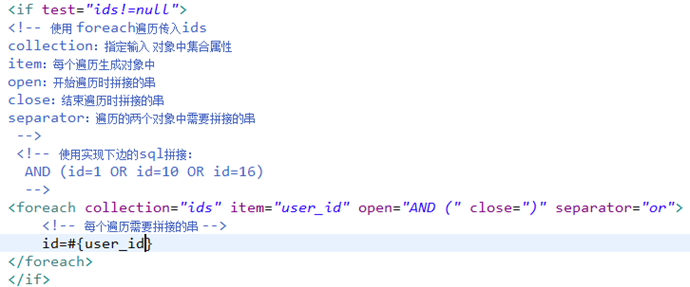
foreach
向sql传递数组或List,mybatis使用foreach解析
8.1.1
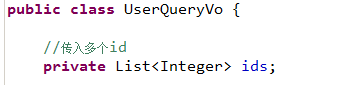
需求
在用户查询列表和查询总数的statement中增加多个id输入查询。
sql语句如下:
两种方法:
SELECT FROM USER WHERE id=1 OR id=10 OR
id=16
SELECT FROM USER WHERE id IN(1,10,16)
8.1.2
8.1.3
修改mapper.xml
WHERE id=1 OR id=10 OR id=16
在查询条件中,查询条件定义成一个sql片段,需要修改sql片段。
8.1.4
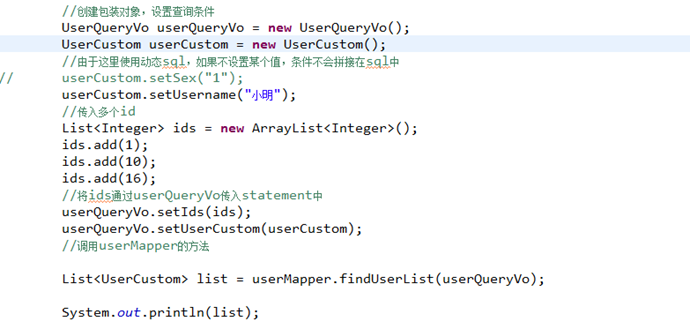
8.1.5
另外一个sql的实现:

mybatis第二天 高级映射 查询缓存 和spring整合
课程复习:
mybatis是什么?
mybatis是一人持久层框架,mybatis是一个不完全的ORM框架。sql语句需要程序员自己去编写,但是mybatis也有映射(输入参数映射、输出结果映射)。
mybatis入门门槛不高,学习成本低,让程序员把精力放在sql语句上,对sql语句优化非常方便,适用与需求变化较多项目,比如互联网项目。
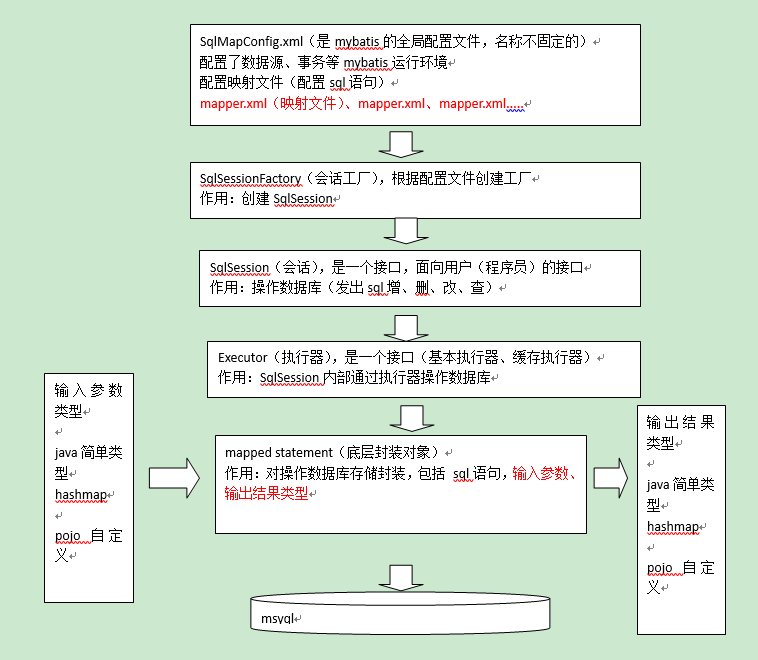
mybatis框架执行过程:
1、配置mybatis的配置文件,SqlMapConfig.xml(名称不固定)
2、通过配置文件,加载mybatis运行环境,创建SqlSessionFactory会话工厂
SqlSessionFactory在实际使用时按单例方式。
3、通过SqlSessionFactory创建SqlSession
SqlSession是一个面向用户接口(提供操作数据库方法),实现对象是线程不安全的,建议sqlSession应用场合在方法体内。
4、调用sqlSession的方法去操作数据。
如果需要提交事务,需要执行SqlSession的commit()方法。
5、释放资源,关闭SqlSession
mybatis开发dao的方法:
1、原始dao 的方法
需要程序员编写dao接口和实现类
需要在dao实现类中注入一个SqlSessionFactory工厂。
2、mapper代理开发方法(建议使用)
只需要程序员编写mapper接口(就是dao接口)
程序员在编写mapper.xml(映射文件)和mapper.java需要遵循一个开发规范:
1、mapper.xml中namespace就是mapper.java的类全路径。
2、mapper.xml中statement的id和mapper.java中方法名一致。
3、mapper.xml中statement的parameterType指定输入参数的类型和mapper.java的方法输入 参数类型一致。
4、mapper.xml中statement的resultType指定输出结果的类型和mapper.java的方法返回值类型一致。
SqlMapConfig.xml配置文件:可以配置properties属性、别名、mapper加载。。。
输入映射:
parameterType:指定输入参数类型可以简单类型、pojo、hashmap。。
对于综合查询,建议parameterType使用包装的pojo,有利于系统 扩展。
输出映射:
resultType:
查询到的列名和resultType指定的pojo的属性名一致,才能映射成功。
reusltMap:
可以通过resultMap
完成一些高级映射。
如果查询到的列名和映射的pojo的属性名不一致时,通过resultMap设置列名和属性名之间的对应关系(映射关系)。可以完成映射。
高级映射:
将关联查询的列映射到一个pojo属性中。(一对一)
将关联查询的列映射到一个List
动态sql:(重点)
if判断(掌握)
where
foreach
sql片段(掌握)
课程安排:
对订单商品数据模型进行分析。
高级映射:(了解)
实现一对一查询、一对多、多对多查询。
延迟加载
查询缓存
一级缓存
二级缓存(了解mybatis二级缓存使用场景)
mybatis和spirng整合(掌握)
逆向工程(会用)
订单商品数据模型
1.1
数据模型分析思路
1、每张表记录的数据内容
分模块对每张表记录的内容进行熟悉,相当 于你学习系统 需求(功能)的过程。
2、每张表重要的字段设置
非空字段、外键字段
3、数据库级别表与表之间的关系
外键关系
4、表与表之间的业务关系
在分析表与表之间的业务关系时一定要建立 在某个业务意义基础上去分析。
1.2
数据模型分析
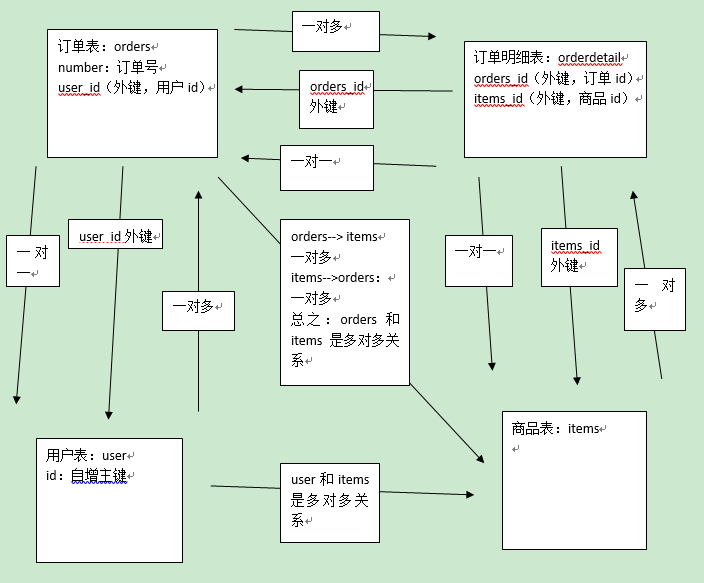
用户表user:
记录了购买商品的用户信息
订单表:orders
记录了用户所创建的订单(购买商品的订单)
订单明细表:orderdetail:
记录了订单的详细信息即购买商品的信息
商品表:items
记录了商品信息
表与表之间的业务关系:
在分析表与表之间的业务关系时需要建立 在某个业务意义基础上去分析。
先分析数据级别之间有关系的表之间的业务关系:
usre和orders:
user——>orders:一个用户可以创建多个订单,一对多
orders—->user:一个订单只由一个用户创建,一对一
orders和orderdetail:
orders—-》orderdetail:一个订单可以包括 多个订单明细,因为一个订单可以购买多个商品,每个商品的购买信息在orderdetail记录,一对多关系
orderdetail—> orders:一个订单明细只能包括在一个订单中,一对一
orderdetail和itesm:
orderdetail—-》itesms:一个订单明细只对应一个商品信息,一对一
items—> orderdetail:一个商品可以包括在多个订单明细 ,一对多
再分析数据库级别没有关系的表之间是否有业务关系:
orders和items:
orders和items之间可以通过orderdetail表建立 关系。
2
一对一查询
2.1
2.2
resultType
2.2.1
sql语句
确定查询的主表:订单表
确定查询的关联表:用户表
关联查询使用内链接?还是外链接?
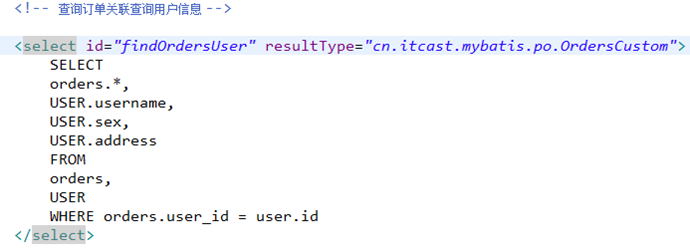
由于orders表中有一个外键(user_id),通过外键关联查询用户表只能查询出一条记录,可以使用内链接。
SELECT
orders.*,
USER.username,
USER.sex,
USER.address
FROM
orders,
USER
WHERE orders.user_id = user.id
2.2.2
创建pojo
将上边sql查询的结果映射到pojo中,pojo中必须包括所有查询列名。
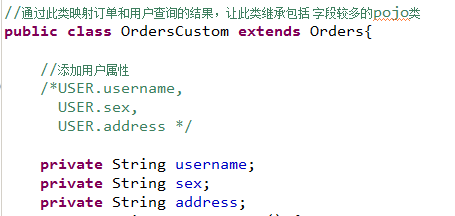
原始的Orders.java不能映射全部字段,需要新创建的pojo。
创建 一个pojo继承包括查询字段较多的po类。
2.2.3
2.2.4

2.3
resultMap
2.3.1
2.3.2
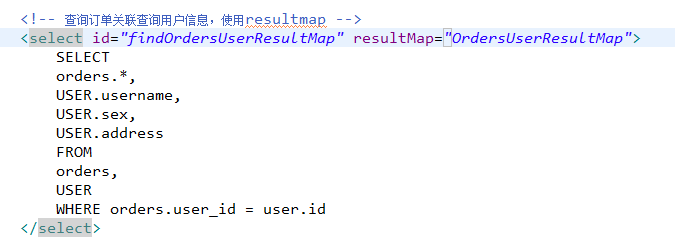
使用resultMap映射的思路
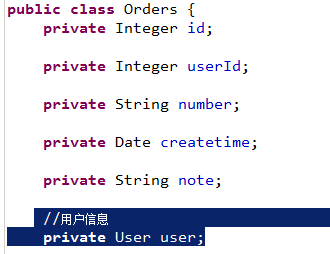
使用resultMap将查询结果中的订单信息映射到Orders对象中,在orders类中添加User属性,将关联查询出来的用户信息映射到orders对象中的user属性中。
2.3.3
2.3.4
mapper.xml
2.3.4.1
2.3.4.2
2.3.5

2.4
resultType和resultMap实现一对一查询小结
实现一对一查询:
resultType:使用resultType实现较为简单,如果pojo中没有包括查询出来的列名,需要增加列名对应的属性,即可完成映射。
如果没有查询结果的特殊要求建议使用resultType。
resultMap:需要单独定义resultMap,实现有点麻烦,如果对查询结果有特殊的要求,使用resultMap可以完成将关联查询映射pojo的属性中。
resultMap可以实现延迟加载,resultType无法实现延迟加载。
3
一对多查询
3.1
3.2
sql语句
确定主查询表:订单表
确定关联查询表:订单明细表
在一对一查询基础上添加订单明细表关联即可。
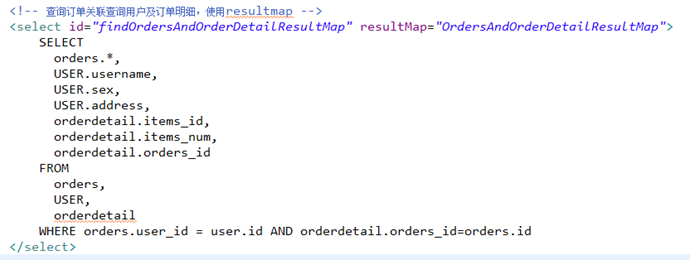
SELECT
orders.*,
USER.username,
USER.sex,
USER.address,
orderdetail.id
orderdetail_id,
orderdetail.items_id,
orderdetail.items_num,
orderdetail.orders_id
FROM
orders,
USER,
orderdetail
WHERE orders.user_id = user.id AND
orderdetail.orders_id=orders.id
3.3
分析
使用resultType将上边的
查询结果映射到pojo中,订单信息的就是重复。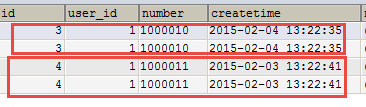
要求:
对orders映射不能出现重复记录。
在orders.java类中添加List
最终会将订单信息映射到orders中,订单所对应的订单明细映射到orders中的orderDetails属性中。

映射成的orders记录数为两条(orders信息不重复)
每个orders中的orderDetails属性存储了该
订单所对应的订单明细。
3.4
3.5
3.6
3.7

3.8
小结
mybatis使用resultMap的collection对关联查询的多条记录映射到一个list集合属性中。
使用resultType实现:
将订单明细映射到orders中的orderdetails中,需要自己处理,使用双重循环遍历,去掉重复记录,将订单明细放在orderdetails中。
4
多对多查询
4.1
4.2
sql语句
查询主表是:用户表
关联表:由于用户和商品没有直接关联,通过订单和订单明细进行关联,所以关联表:
orders、orderdetail、items
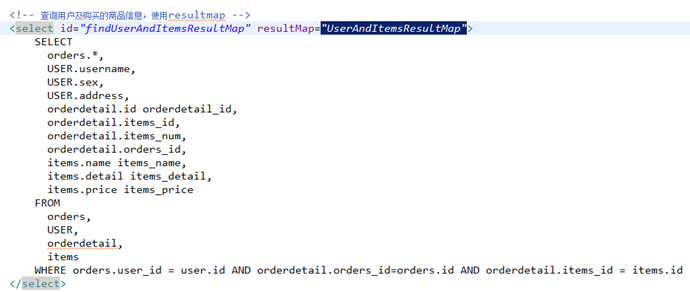
SELECT
orders.*,
USER.username,
USER.sex,
USER.address,
orderdetail.id orderdetail_id,
orderdetail.items_id,
orderdetail.items_num,
orderdetail.orders_id,
items.name items_name,
items.detail items_detail,
items.price items_price
FROM
orders,
USER,
orderdetail,
items
WHERE orders.user_id = user.id AND
orderdetail.orders_id=orders.id AND orderdetail.items_id = items.id
4.3
映射思路
将用户信息映射到user中。
在user类中添加订单列表属性List
在Orders中添加订单明细列表属性List
在OrderDetail中添加Items属性,将订单明细所对应的商品映射到Items
4.4
4.5
4.6

4.7
多对多查询总结
将查询用户购买的商品信息明细清单,(用户名、用户地址、购买商品名称、购买商品时间、购买商品数量)
针对上边的需求就使用resultType将查询到的记录映射到一个扩展的pojo中,很简单实现明细清单的功能。
一对多是多对多的特例,如下需求:
查询用户购买的商品信息,用户和商品的关系是多对多关系。
需求1:
查询字段:用户账号、用户名称、用户性别、商品名称、商品价格(最常见)
企业开发中常见明细列表,用户购买商品明细列表,
使用resultType将上边查询列映射到pojo输出。
需求2:
查询字段:用户账号、用户名称、购买商品数量、商品明细(鼠标移上显示明细)
使用resultMap将用户购买的商品明细列表映射到user对象中。
总结:
使用resultMap是针对那些对查询结果映射有特殊要求的功能,,比如特殊要求映射成list中包括
多个list。
5
resultMap总结
resultType:
作用:
将查询结果按照sql列名pojo属性名一致性映射到pojo中。
场合:
常见一些明细记录的展示,比如用户购买商品明细,将关联查询信息全部展示在页面时,此时可直接使用resultType将每一条记录映射到pojo中,在前端页面遍历list(list中是pojo)即可。
resultMap:
使用association和collection完成一对一和一对多高级映射(对结果有特殊的映射要求)。
association:
作用:
将关联查询信息映射到一个pojo对象中。
场合:
为了方便查询关联信息可以使用association将关联订单信息映射为用户对象的pojo属性中,比如:查询订单及关联用户信息。
使用resultType无法将查询结果映射到pojo对象的pojo属性中,根据对结果集查询遍历的需要选择使用resultType还是resultMap。
collection:
作用:
将关联查询信息映射到一个list集合中。
场合:
为了方便查询遍历关联信息可以使用collection将关联信息映射到list集合中,比如:查询用户权限范围模块及模块下的菜单,可使用collection将模块映射到模块list中,将菜单列表映射到模块对象的菜单list属性中,这样的作的目的也是方便对查询结果集进行遍历查询。
如果使用resultType无法将查询结果映射到list集合中。
6
6.1
什么是延迟加载
resultMap可以实现高级映射(使用association、collection实现一对一及一对多映射),association、collection具备延迟加载功能。
需求:
如果查询订单并且关联查询用户信息。如果先查询订单信息即可满足要求,当我们需要查询用户信息时再查询用户信息。把对用户信息的按需去查询就是延迟加载。
延迟加载:先从单表查询、需要时再从关联表去关联查询,大大提高
数据库性能,因为查询单表要比关联查询多张表速度要快。
6.2 使用association实现延迟加载
6.2.1
6.2.2
mapper.xml
需要定义两个mapper的方法对应的statement。
1、只查询订单信息
SELECT FROM orders
在查询订单的statement中使用association去延迟加载(执行)下边的satatement(关联查询用户信息*)
2、关联查询用户信息
通过上边查询到的订单信息中user_id去关联查询用户信息
使用UserMapper.xml中的findUserById
上边先去执行findOrdersUserLazyLoading,当需要去查询用户的时候再去执行findUserById,通过resultMap的定义将延迟加载执行配置起来。
6.2.3
延迟加载resultMap
使用association中的select指定延迟加载去执行的statement的id。
6.2.4

6.2.5
6.2.5.1
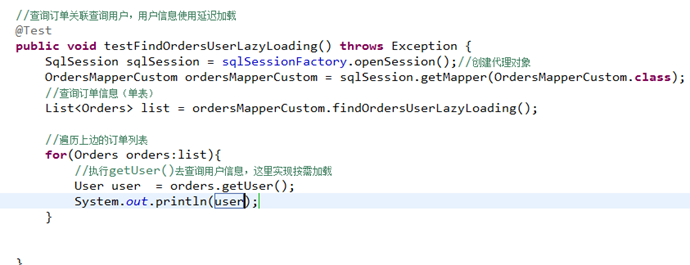
测试思路:
1、执行上边mapper方法(findOrdersUserLazyLoading),内部去调用cn.itcast.mybatis.mapper.OrdersMapperCustom中的findOrdersUserLazyLoading只查询orders信息(单表)。
2、在程序中去遍历上一步骤查询出的List
3、延迟加载,去调用UserMapper.xml中findUserbyId这个方法获取用户信息。
6.2.5.2
延迟加载配置
mybatis默认没有开启延迟加载,需要在SqlMapConfig.xml中setting配置。
在mybatis核心配置文件中配置:
lazyLoadingEnabled、aggressiveLazyLoading
| 设置项 | 描述 | 允许值 | 默认值 |
|---|---|---|---|
| lazyLoadingEnabled | 全局性设置懒加载。如果设为‘false’,则所有相关联的都会被初始化加载。 | true | false | false |
| aggressiveLazyLoading | 当设置为‘true’的时候,懒加载的对象可能被任何懒属性全部加载。否则,每个属性都按需加载。 | true | false | true |

6.2.5.3
6.2.6
延迟加载思考
不使用mybatis提供的association及collection中的延迟加载功能,如何实现延迟加载??
实现方法如下:
定义两个mapper方法:
1、查询订单列表
2、根据用户id查询用户信息
实现思路:
先去查询第一个mapper方法,获取订单信息列表
在程序中(service),按需去调用第二个mapper方法去查询用户信息。
总之:
使用延迟加载方法,先去查询简单的**sql(**最好单表,也可以关联查询),再去按需要加载关联查询的其它信息。
7
查询缓存
7.1
什么是查询缓存
mybatis提供查询缓存,用于减轻数据压力,提高数据库性能。
mybaits提供一级缓存,和二级缓存。
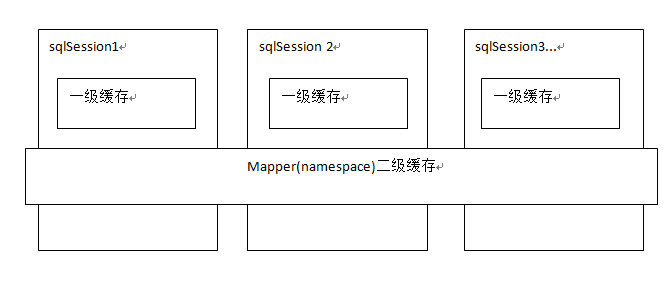
一级缓存是SqlSession级别的缓存。在操作数据库时需要构造 sqlSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。
二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
为什么要用缓存?
如果缓存中有数据就不用从数据库中获取,大大提高系统性能。
7.2
7.2.1
一级缓存工作原理
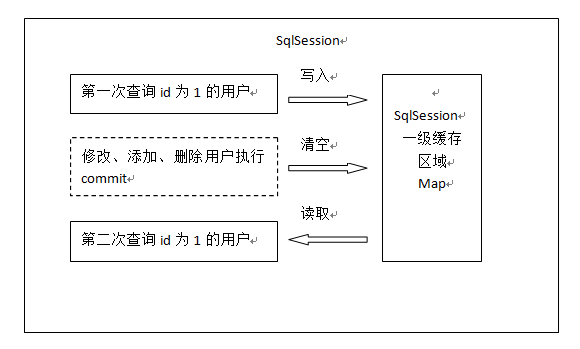
第一次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,如果没有,从数据库查询用户信息。
得到用户信息,将用户信息存储到一级缓存中。
如果sqlSession去执行commit操作(执行插入、更新、删除),清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
第二次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,缓存中有,直接从缓存中获取用户信息。
7.2.2
一级缓存测试
mybatis默认支持一级缓存,不需要在配置文件去配置。
按照上边一级缓存原理步骤去测试。
@Test
public void testCache1() throws Exception{
SqlSession sqlSession = sqlSessionFactory.openSession();//创建代理对象
UserMapper userMapper =
sqlSession.getMapper(UserMapper.class);
//下边查询使用一个SqlSession
//第一次发起请求,查询id为1的用户
User user1 = userMapper.findUserById(1);
System.out.println(user1);
// 如果sqlSession去执行commit操作(执行插入、更新、删除),清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
//更新user1的信息
user1.setUsername(“测试用户22”);
userMapper.updateUser(user1);
//执行commit操作去清空缓存
sqlSession.commit();
//第二次发起请求,查询id为1的用户
User user2 = userMapper.findUserById(1);
System.out.println(user2);
sqlSession.close();
}
7.2.3
一级缓存应用
正式开发,是将mybatis和spring进行整合开发,事务控制在service中。
一个service方法中包括
很多mapper方法调用。
service{
//开始执行时,开启事务,创建SqlSession对象
//第一次调用mapper的方法findUserById(1)
//第二次调用mapper的方法findUserById(1),从一级缓存中取数据
//方法结束,sqlSession关闭
}
如果是执行两次service调用查询相同
的用户信息,不走一级缓存,因为session方法结束,sqlSession就关闭,一级缓存就清空。
7.3
7.3.1
原理
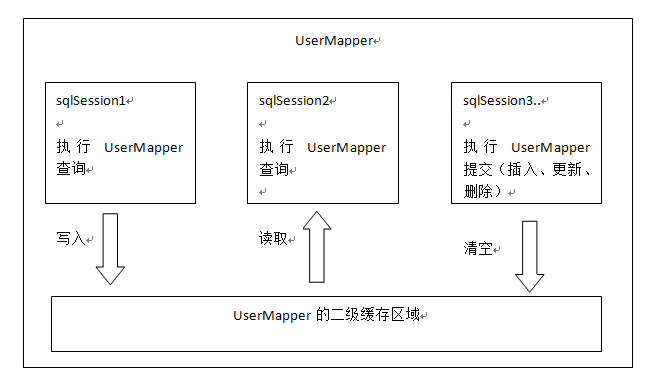
首先开启mybatis的二级缓存。
sqlSession1去查询用户id为1的用户信息,查询到用户信息会将查询数据存储到二级缓存中。
如果SqlSession3去执行相同 mapper下sql,执行commit提交,清空该 mapper下的二级缓存区域的数据。
sqlSession2去查询用户id为1的用户信息,去缓存中找是否存在数据,如果存在直接从缓存中取出数据。
二级缓存与一级缓存区别,二级缓存的范围更大,多个sqlSession可以共享一个UserMapper的二级缓存区域。
UserMapper有一个二级缓存区域(按namespace分) ,其它mapper也有自己的二级缓存区域(按namespace分)。
每一个namespace的mapper都有一个二缓存区域,两个mapper的namespace如果相同,这两个mapper执行sql查询到数据将存在相同
的二级缓存区域中。
7.3.2
开启二级缓存
mybaits的二级缓存是mapper范围级别,除了在SqlMapConfig.xml设置二级缓存的总开关,还要在具体的mapper.xml中开启二级缓存。
在核心配置文件SqlMapConfig.xml中加入
<setting name=“cacheEnabled”
_value=“true”_/>
| 描述 | 允许值 | 默认值 | |
|---|---|---|---|
| cacheEnabled | 对在此配置文件下的所有cache 进行全局性开/关设置。 | true false | true |

在UserMapper.xml中开启二缓存,UserMapper.xml下的sql执行完成会存储到它的缓存区域(HashMap)。

7.3.3
调用pojo类实现序列化接口
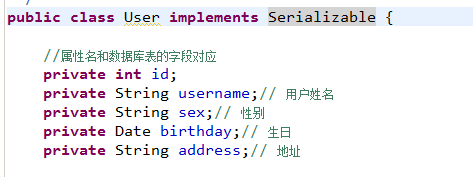
为了将缓存数据取出执行反序列化操作,因为二级缓存数据存储介质多种多样,不一样在内存。
7.3.4
测试方法
// 二级缓存测试
@Test
public void testCache2() throws Exception {
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
SqlSession sqlSession3 = sqlSessionFactory.openSession();
// 创建代理对象
UserMapper userMapper1 =
sqlSession1.getMapper(UserMapper.class);
// 第一次发起请求,查询id为1的用户
User user1 = userMapper1.findUserById(1);
System.out.println(user1);
//这里执行关闭操作,将sqlsession中的数据写到二级缓存区域
sqlSession1.close();
//使用sqlSession3执行commit()操作
UserMapper userMapper3 = sqlSession3.getMapper(UserMapper.class);
User user
= userMapper3.findUserById(1);
user.setUsername(“张明明”);
userMapper3.updateUser(user);
//执行提交,清空UserMapper下边的二级缓存
sqlSession3.commit();
sqlSession3.close();
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
// 第二次发起请求,查询id为1的用户
User user2 = userMapper2.findUserById(1);
System.out.println(user2);
sqlSession2.close();
}
7.3.5
useCache配置
在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存。

若有收获,就点个赞吧
0 人点赞
