一、B树(B-Tree)
1、概念:
B树和平衡二叉树稍有不同的是B树属于多叉树又名平衡多路查找树(查找路径不只两个),数据库索引技术里大量使用者B树和B+树的数据结构。我们描述一颗B树时需要指定它的阶数,阶数表示了一个结点最多有多少个孩子结点,一般用字母m表示阶数。当m取2时,就是我们常见的二叉搜索树,m为3时是2-3树。
2、规则:
(1)排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则;
(2)子节点数:非叶节点的子节点数>1,且<=M ,且M>=2,空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M路,当M=2则是2叉树,M=3则是3叉);
(3)关键字数:枝节点的关键字数量大于等于ceil(m/2)-1个且小于等于M-1个(注:ceil()是个朝正无穷方向取整的函数 如ceil(1.1)结果为2);
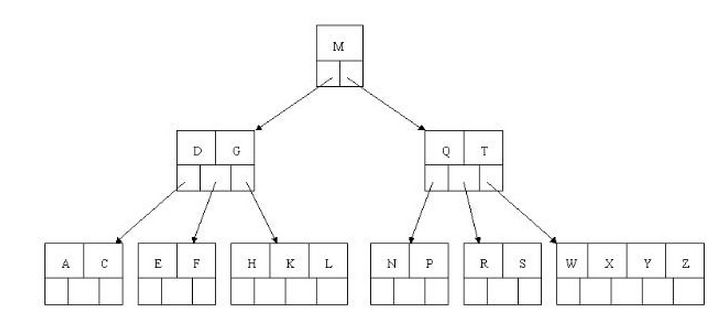
(4)所有叶子节点均在同一层、叶子节点除了包含了关键字和关键字记录的指针外也有指向其子节点的指针只不过其指针地址都为null对应下图最后一层节点的空格子;
3、B树的查询流程:
B-树的查找其实是对二叉搜索树查找的扩展, 与二叉搜索树不同的地方是,B-树中每个节点有不止一棵子树。在B-树中查找某个结点时,需要先判断要查找的结点在哪棵子树上,然后在结点中逐个查找目标结点。B树的查找过程相对简单,与二叉搜索树类似。
如上图我要从上图中找到E字母,查找流程如下
(1)获取根节点的关键字进行比较,当前根节点关键字为M,E
4、B树的插入节点流程:
B树的插入操作是指在树种插入一条新记录,即(key, value)的键值对。如果B树中已存在需要插入的键值对,则用需要插入的value替换旧的value。若B树不存在这个key,则一定是在叶子结点中进行插入操作。
定义一个5阶树(平衡5路查找树;),现在我们要把3、8、31、11、23、29、50、28 这些数字构建出一个5阶树出来;
遵循规则:
(1)节点拆分规则:当前是要组成一个5路查找树,那么此时m=5,关键字数必须<=5-1(这里关键字数>4就要进行节点拆分);
(2)排序规则:满足节点本身比左边节点大,比右边节点小的排序规则;
先插入 3、8、31、11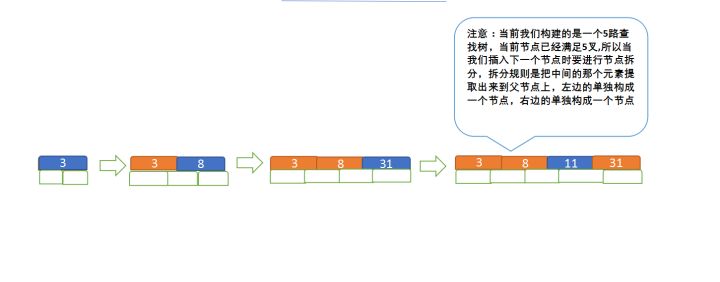
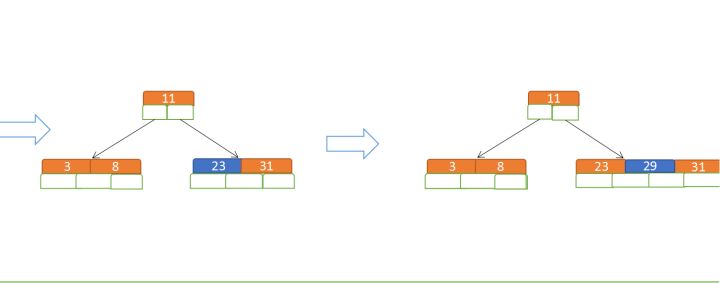
再插入23、29
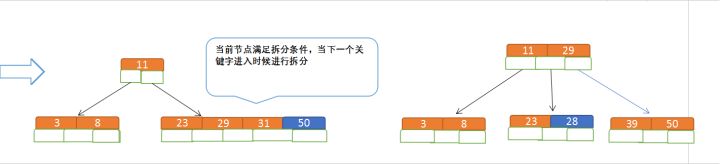
再插入50、28
5、B树节点的删除:
规则:
(1)节点合并规则:当前是要组成一个5路查找树,那么此时m=5,关键字数必须大于等于ceil(5/2)(这里关键字数<2就要进行节点合并);
(2)满足节点本身比左边节点大,比右边节点小的排序规则;
(3)关键字数小于二时先从子节点取,子节点没有符合条件时就向向父节点取,取中间值往父节点放;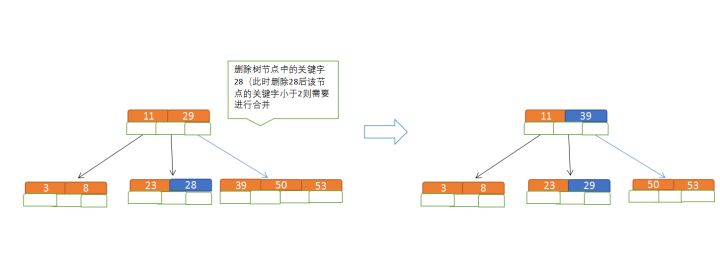
7、特点:B树相对于平衡二叉树的不同是,每个节点包含的关键字增多了,特别是在B树应用到数据库中的时候,数据库充分利用了磁盘块的原理(磁盘数据存储是采用块的形式存储的,每个块的大小为4K,每次IO进行数据读取时,同一个磁盘块的数据可以一次性读取出来)把节点大小限制和充分使用在磁盘快大小范围;把树的节点关键字增多后树的层级比原来的二叉树少了,减少数据查找的次数和复杂度;
二、B+树(B+Tree)
1、概念:
B+树是B树的一个升级版,相对于B树来说B+树更充分的利用了节点的空间,让查询速度更加稳定,其速度完全接近于二分法查找。为什么说B+树查找的效率要比B树更高、更稳定;我们先看看两者的区别
2、规则:
(1)B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加;
(2)B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样;
(3)B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
(4)非叶子节点的子节点数=关键字数(来源百度百科)(根据各种资料 这里有两种算法的实现方式,另一种为非叶节点的关键字数=子节点数-1(来源维基百科),虽然他们数据排列结构不一样,但其原理还是一样的Mysql 的B+树是用第一种方式实现);

若有收获,就点个赞吧
0 人点赞
