1 Introduction
随着 Deep Learning 的爆火,图数据挖掘和 CV、NLP 等领域一样,存在着 “爆发式” 发展的趋势。更加准确地说,笔者认为图数据挖掘正处在爆发的前夜。本文主要从基于图结构的表示学习和基于图特征的表示学习两个角度简要介绍图表示学习的现状和自己的认识。
在非图的表示学习中,研究者们主要考虑的是每一个研究对象的特征 (姓名、年龄、身高等) 信息。然而,研究对象是存在于客观世界的主体,存在一定的图结构信息(QQ、微信好友,师生关系等都构成了图网络)。如何对图结构进行表示学习以表示图的结构信息是一个很重要的 topic。
图表示学习的主要目标是:将结点映射为向量表示的时候尽可能多地保留图的拓扑信息。图表示学习主要分为基于图结构的表示学习和基于图特征的表示学习。如图 1,基于图结构的表示学习对结点的向量表示只来源于图的拓扑结构 ( 
的邻接矩阵表达的图结构),只是对图结构的单一表示,缺乏对图结点特征消息的表示。如图 2,基于图特征的表示学习对结点的向量表示既包含了图的拓扑信息 (
的邻接矩阵表达的图结构)也包含了已有的特征向量 ( 
个维度为 
包含结点特征的向量,如姓名、年龄、身高等信息)。
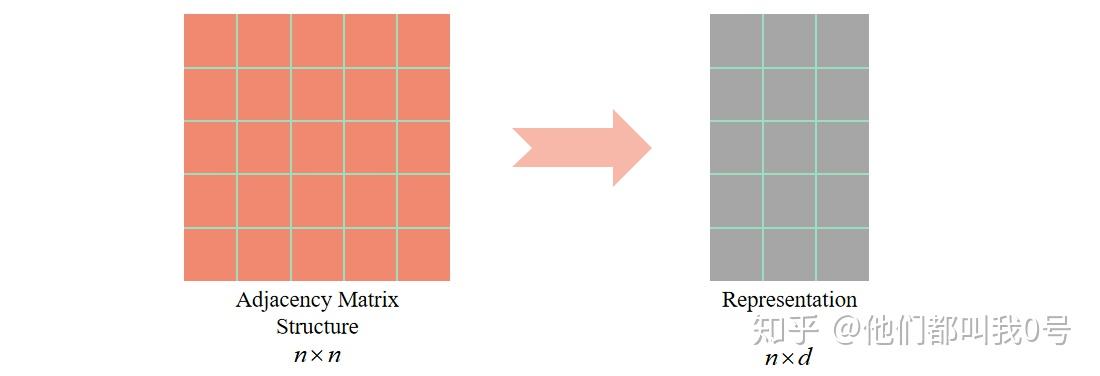
图 1:基于图结构的表示学习
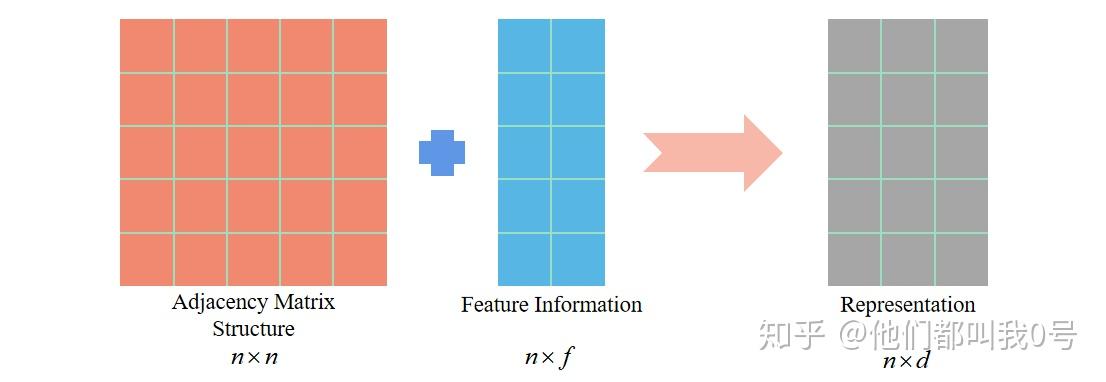
图 2:基于图特征的表示学习
通过上述的介绍,我们可以知道图表示学习的 task 就是用
个向量表示图上的
个结点,这样我们就可以将一个难以表达的拓扑结构转化为可以丢进炼丹炉的 vector 啦。
2 基于图结构的表示学习
在我们的图表示学习中,我们希望 Embedding 出来的向量在图上 “接近” 时在向量空间也“接近”。对于第 2 个“接近”,就是欧式空间两个向量的距离。对于第一个“接近”,可以有很多的解释:
- 1-hop:两个相邻的结点就可以定义为临近;
- k-hop:两个k阶临近的结点也可以定义为临近;
- 具有结构性:结构性相对于异质性而言。异质性关注的是结点的邻接关系;结构性将两个结构上相似的结点定义为 “临近”。比方说,某两个点是各自小组的中心,这样的两个节点就具有结构性。
因此,针对上述的一些观点,就有了下列的模型:
2.1 DeepWalk
DeepWalk的方法采用了Random walk的思想进行结点采样。具体参见图 3,我们首先根据用户的行为构建出一个图网络;随后通过 Random walk 随机采样的方式构建出结点序列 (例如:一开始在 A 结点,A->B,B 又跳到了它的邻居结点 E,最后到 F,得到 “A->B->E->F” 序列);对于序列的问题就是 NLP 中的语言模型,因为我们的句子就是单词构成的序列。接下来我们的问题就变成 Word2vec(词用向量表示) 的问题,我们可以采用Skip-gram的模型来得到最终的结点向量。可以说这种想法确实是十分精妙,将图结构转化为序列问题确实是非常创新的出发点。
在这里,结点走向其邻居结点的概率是均等的。当然,在有向图和无向图中,游走的方式也不一样。无向图中的游走方式为相连即可走;而有向图中则是只沿着 “出边” 的方向走。
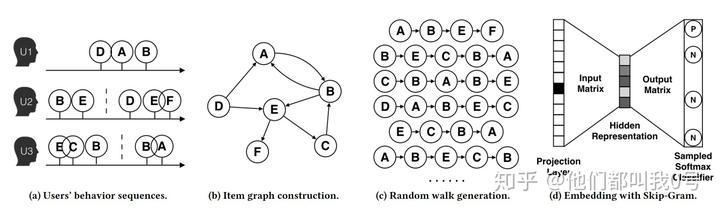
图 3:DeepWalk(图源:阿里的 paper)
2.2 Node2vec
之前所述的 Random Walk 方法中,一个结点向邻居结点游走的概率是相等的。这种等概率的游走操作似乎是比较 naive 的,对此,Node2vec的提出就是对结点间游走概率的定义。在图 4 中,我们看到当从结点 t 跳跃到结点 v 之后,算法下一步从结点 v 向邻居结点跳跃的概率是不同的。
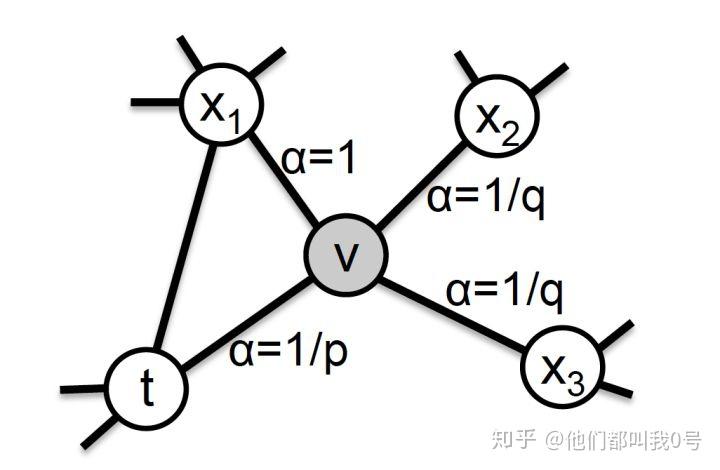
图 4:Node2vec 结点的跳转概率示意
具体的跳转概率 (这里的“概率” 不是严格的概率,实际上要对下面这个公式进行归一化处理)定义为:

该公式中 
后项表示权重, 
定义如下:

在上面的公式中,从结点 v回跳到上一个结点 
的 
为 
;从结点 
跳到
、
的公共邻居结点的
为 1;从结点 v 跳到其他邻居的
为 
。
根据上述的方法,我们就可以获得节点间的跳转概率了。我们发现,当 
比较小的时候,结点间的跳转类似于BFS,结点间的 “接近” 就可以理解为结点在邻接关系上“接近”;当 
比较小的时候,结点间的跳转类似于DFS,节点间的 “接近” 就可以视作是结构上相似。具体可借助图 5 理解。
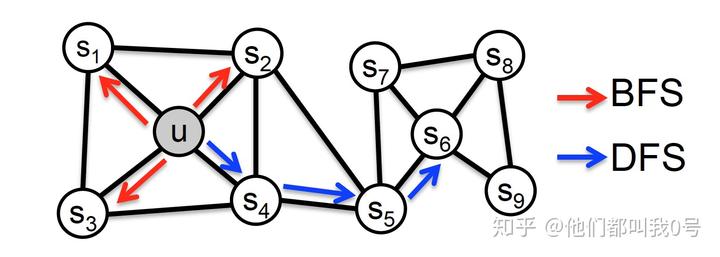
图 5:p、q 取值不同时结点的游走趋势
2.3 Metapath2vec,LINE and so on
针对异构图而言,其结点的属性不同,采样的方式也与传统的图网络不同,需要按照定义的Meta-Path规则进行采样。采样的样例可类似于 “电影 - 导演 - 主演” 这样的方法进行采样。对于唐建等人提出的LINE中,他们认为 1-hop 和 2-hop 临近的结点为 “接近” 的结点。关于 Embedding 的技术还有很多,这里就不作详述啦。
3 基于图特征的表示学习
在基于图特征的表示学习中,由于加入了结点的特征矩阵 
(姓名、年龄、身高等这样的特征),需要同基于图结构的表示学习区别开来。这一类的模型通常被叫做 “图神经网络”。在这里,笔者需要安利(非利益相关) 一本非常值得读的书《深入浅出图神经网络》!
3.1 GCN
Graph Convolutional Networks(图卷积网络) 是非常基本第一个 GNN 模型。在讨论 GCN 之前,我们先来看一下 CNN(卷积神经网络) 是怎么做卷积运算的。如图 6 所示,CNN 的两个主要特点是局部感知与权值共享。换句话说,就是聚合某个像素点周围的像素特征。
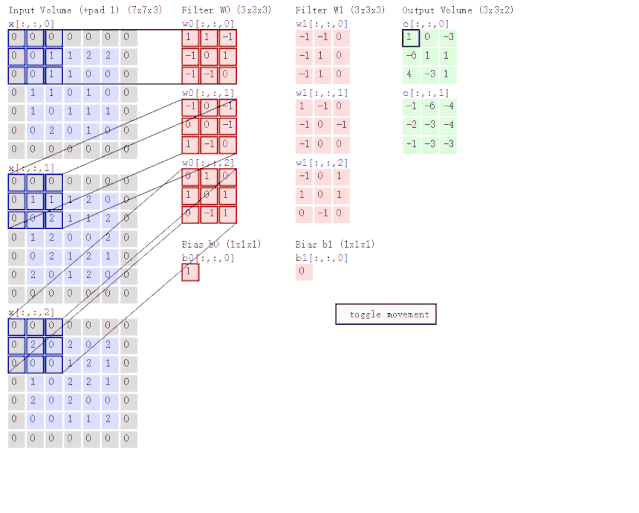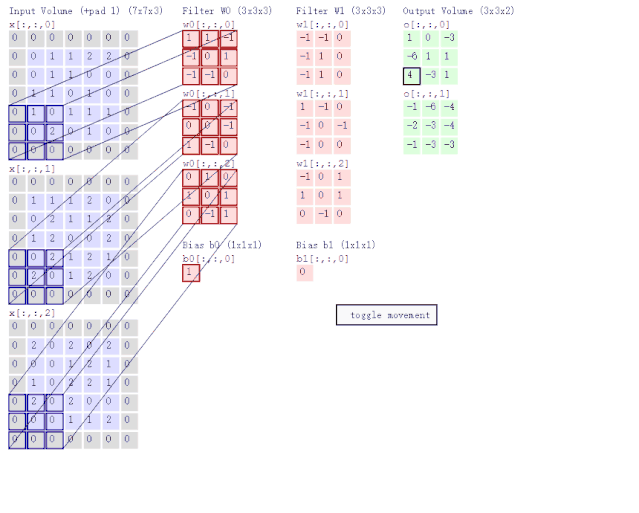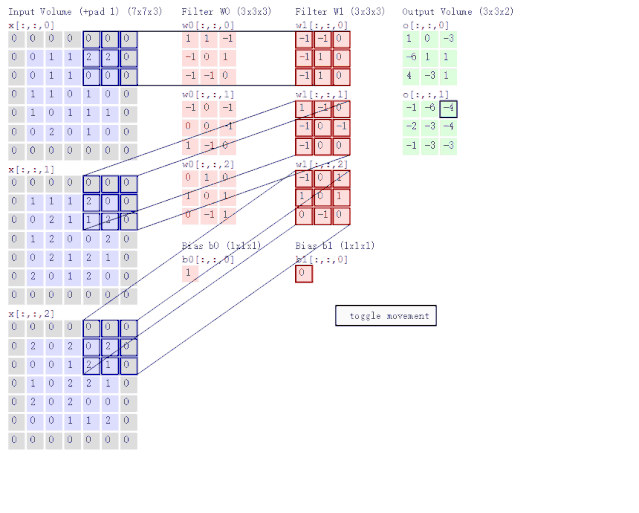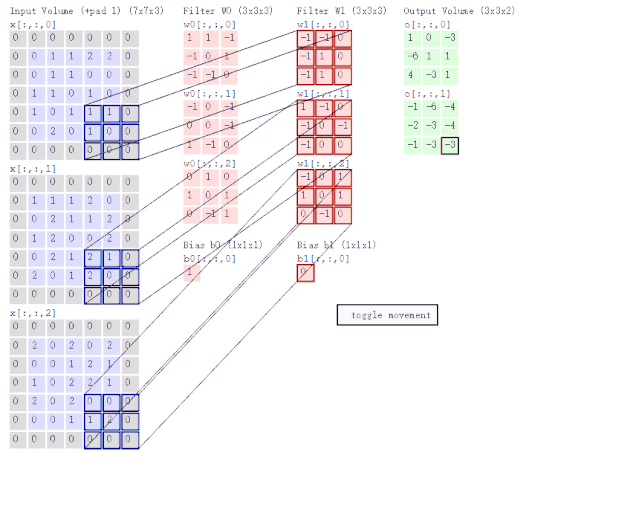
图 6:卷积神经网络示意
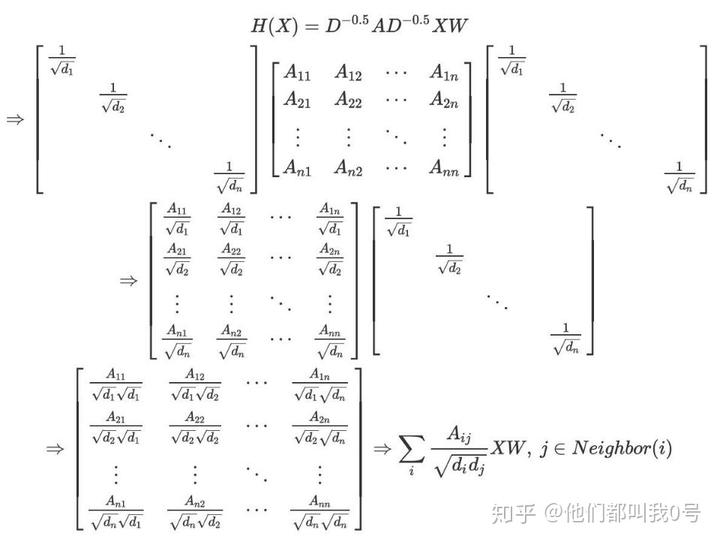
类似地,在 GCN 中,新的特征也是对上一层邻居结点特征的聚合,公式如下: 
其中 
是邻接矩阵, 
是顶点的度矩阵 (对角阵), 
是单位阵, 
是神经网络层与层之间传播的系数矩阵。此外 
表示的是该层的结点特征矩阵,第一层的特征矩阵 
是原始的结点特征矩阵
。也许有人会有疑问,DNN 的输入应该是一个向量,为什么这里用的是矩阵的表示呢?其实,这里的矩阵可以视作是由多个向量组成的,可以类比于 CNN 中的 “多通道” 概念。我们来看一下下面的公式推演:
根据上面的推导,我们不难从最后一个公式中看看出结点 
在下一层的表示是由其所有的邻居结点 
所构成集合 
来决的。
因此,我们换一个视角,从每一个结点的角度来看 GCN 的公式。我们可以发现公式 (3.1-1) 可以表示为:

其中 
是第
层网络中结点
的向量表示,
是第层网络上一结点
的向量表示 
表示的是结点
的邻居结点构成的集合。公式 (3.1-1)、公式(3.1-2) 和上面的一堆推导可以说是殊途同归。其核心的意思都表示的是“邻居结点的聚合”。
从直观层面,GCN 的含义就是 “聚合” 的含义。然而,从图信号角度对 GCN 进行分析,又会是一番新的境界。某在另一篇文章:图卷积网络 (GCN) 的谱分析中对如何从频域的视角理解 GCN 以及 GCN 的过平滑问题做了较为深入的探讨,欢迎批评指正。
3.2 GraphSAGE
GCN 提出之后,同年的 NIPS 上GraphSAGE也横空出世,其主要的特点是固定的采样倍率和不同的聚合方式。
采样倍率
在 GCN 中,我们采用的聚合方式是将一个结点的所有邻居进行聚合。若每一层结点的平局邻居结点个数为

,那么经过
层的聚合后,结点的聚合代价为
。若
,那么每个结点就要有 1111 个结点参与计算,要是乘上所有的结点个数,计算的代价简直 credible。对于邻居节点的聚合,GraphSAGE 在一个 epoch 中,作者并未将某个结点所有的邻居结点进行聚合,而是设置一个定值

,在第
层选择邻居的时候只从中选最多只选择
个邻居结点进行聚合,计算的复杂度大致在
这个水平。这一改进对 GNN 的落地有着重要意义。聚合方式
结点聚合应该满足:
(1): 对聚合结点的数量自适应:向量的维度不应随邻居结点和总结点个数改变。
(2): 聚合操作对聚合结点具有排列不变性:e.g. 
。
(3): 显然,在优化过程中,模型的计算要是可导的。
根据上述的几点原则,作者提出了几种聚合方式:
- 平均 / 求和聚合算子 (mean/sum):

其中
和 
都是需要 learning 的参数。
- 池化算子 (pooling):

对其中的MAX的含义是各元素上运用 max 算子计算。
max denotes the element-wise max operator.
- LSTM 聚合:
与平均聚合相比,LSTM 聚合具有更大的表达能力。但是,重要的是 LSTM 并不具有排列不变性,因为它们是以顺序方式处理其输入。因此,需要将 LSTM 应用于节点邻居的随机排列,这可以使 LSTM 适应无序集合。
3.3 GAT
自从有了 Attention 机制之后,似乎万物皆可 Attention 了。在图学习中,Graph Attention Network就是引入了注意力机制的 GNN。说到底,GAT 还是对邻居结点信息的聚合:

其中 
是结点 
与其相邻结点 
之间的权重系数,
的计算公式为:

其中 || 是 concat 操作,权重参数向量 
。这个公式乍一看比较复杂,其实是由两个部分组成。如图 7(左),首先算出相关度的权重系数 
,然后在对 
进行 softmax 归一化处理,以确保权重之和为 1。其实这里的 Attention 不就是一个加权嘛。
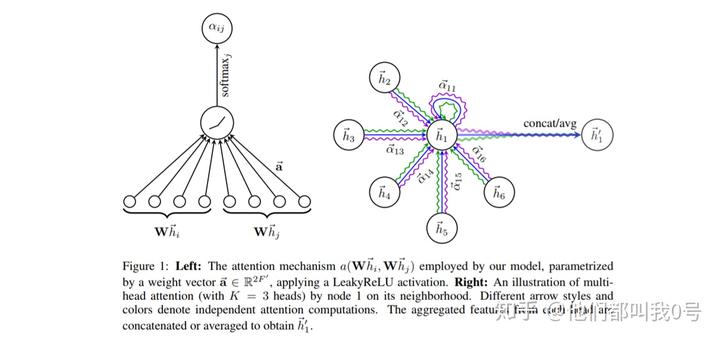
图 7:图注意力机制示意
此外,作者在提出 GAT 时也提出了多头注意力机制的方法。如图 7(右) 所示,不同的颜色代表了不同的注意力计算过程,并将结果进行拼接或平均。具体公式如下:

由于笔者的 level 问题,对其他网络的了解还不够深入,日后有空再更!
4 一些有参考意义的博客
- Word2Vec (Part 1): NLP With Deep Learning with Tensorflow (Skip-gram)
- Word2Vec 介绍:直观理解 skip-gram 模型 (知乎)
- node2vec 原理介绍及实践
- [论文笔记]node2vec
- 深度学习中不得不学的 Graph Embedding 方法
- 图卷积网络 GCN Graph Convolutional Network(谱域 GCN)的理解和详细推导 - 持续更新
- GCN 作者 blog
- 深度学习中的注意力机制
- 图深度表示(GNN)的基础和前沿进展视频
- 唐杰 - 图神经网络及认知推理 - 图神经网络学习班视频
- 图网络学习算法——从 GraphSAGE,GAT 到 H-GCN
联系我:xdu Dot lhchen At gmail Dot com
https://zhuanlan.zhihu.com/p/112295277

若有收获,就点个赞吧
0 人点赞
