最近了解了一下 GNN,写本文概述以加深理解,主要参考一下两篇综述文章:
清华大学孙茂松组的 Graph Neural Networks: A Review of Methods and Applications
IEEE Fellow, Philip S. Yu 的 A Comprehensive Survey on Graph Neural Networks
符号定义
GNN(Graph Neural Networks) 简介
之前深度学习主要关注例如文字的序列结构、例如图片的平面结构,现在处理这些数据的做法也比较成熟,关注序列任务的 NLP 领域多用 RNN、Transformer、CNN 对数据进行 Encoder,而关注平面结构的 CV 领域更多使用 CNN 及其各种变体对数据进行 Encoder。在现实世界中更多的数据表示并不是序列或者平面这种简单的排列,而是表现为更为复杂的图结构,如社交网络、商品 - 店铺 - 人之间的关系、分子结构等等.
图是由节点及连接节点的边构成的,现在热门的基于深度学习的 GNN 就是用来处理图类型数据的网络,而该网络的目标就是学习每个节点 v 的表示 
,而每个节点的表示由该节点的特征、与该节点连接的边的特征、该节点的邻居表示和它邻居节点的特征计算得到:

对于关注节点的任务,可以直接拿 
的表示去完成特定任务,而对于关注整个图的任务这可以通过将所有的节点的表示做 Pooling 或其他方法获得一个全局的表示信息然后去做相应的任务。
GNN 分类 — 按更新方式分类
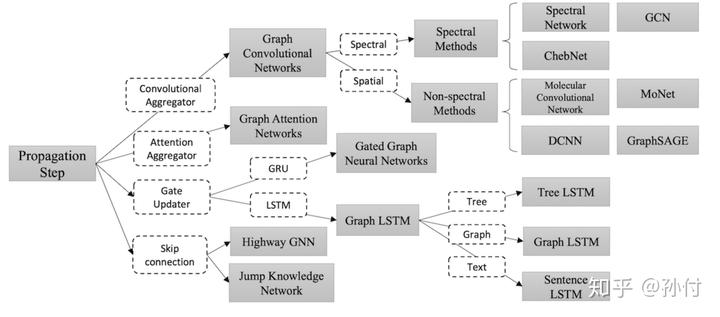
如图所示,GNN 主要分为图卷积网络 (GCN)、基于注意力更新的图网络 (GAT)、基于门控的更新的图网络、具有跳边的图网络.
各种 GCN
图卷积网络是目前最主要(重要)的图网络,GCN 按照更新方式又可以分为基于谱的和基于空间的。
基于谱的 GCN
我们常用的 GCN 模型长这样:
我们常用的 GCN 模型长这样:

对于这个式子直觉告诉我这和 NLP 里面的 Self-Attention 的聚合过程也太像了吧,把 
换成我们 Attention 时计算出来的权重矩阵,简直一模一样。这里的 A 是一个邻接矩阵,若两个节点之间存在一种关系(有边)则对应邻接矩阵 A 上的一个非零值(权重),如果没有关系则对应 0,而 
在这个式子里面起到的作用就是归一化,单位阵 
起到的作用是添加一个自己到自己的边,这个 A 对应于 Attention 里的权重矩阵也很符合直觉。
这个公式很容易理解,它就是一个图卷积神经网络, 
充当卷积核,虽然看起来和我们见过的卷积操作好像相差比较大,不过这个公式并不是和我们直觉的想法一样得来的,而是经历了一个漫长的过程。
在继续介绍之前先讲一个图信号处理领域的一个结论:
定义归一化的拉普拉斯矩阵 
, 拉普拉斯矩阵是实对称矩阵,可以对其进行谱分解得到 
, 其中 
是酉矩阵(即矩阵的列向量两两正交,且 
)。 图信号 
是图中第 i 个节点 
的表示向量, 信号 h 的图傅里叶变换定义为 
, 逆傅里叶变换为 
表示图傅里叶变换对信号 h 的输出。因为我理论基础不足,只能根据直觉解释这个过程,在信号处理中,傅里叶变换就是将在时域的信号变换到频域,而所用到的所有的余弦 / 正弦函数都是正交向量(无穷维向量),每一个正弦 / 余弦函数就是一个频域的基,所以傅里叶变换终究还是一个变基的过程,就是将信号从一个空间通过改变基的表示映射到另一个空间。上文中提到的 
矩阵作为一个酉矩阵(列向量两两正交)显然满足作为一组基 (且是标准正交基) 的条件,我们可以通过 
矩阵将 
映射到另一个空间,该空间就是图的频域空间,至于为什么选择矩阵 
作为变换矩阵而不是随便选一个酉矩阵作为变换矩阵,应该是因为这个 
矩阵是和图的结构密切相关的(由该图的归一化拉普拉斯矩阵谱分解得到的)。
对于该结论的严格推倒过程可以参考 The Emerging Field of Signal Processing on Graphs 这篇论文。
下面开始继续介绍 GCN,定义对每个节点 v 的卷积操作, 
,在傅里叶变换的两个域里: 时域的卷积等价于在频域的乘积,所以为了计算方便可以先将信号做傅里叶变换到频域之后再做逆变换即可得到卷积结果,其中 g 是与拉普拉斯矩阵的特征值相关的。所以图上的卷积定义为:

这里如果将 
参数化为 
,上式将简化为 
,基于谱的卷积都是如此定义,区别在于 
的不同选择。
最简单的方法是直接另 
,此处 
是与拉普拉斯矩阵特征值相关的.
可惜这种简单的计算方法每次都要对 
矩阵进行谱分解,参数数量和图的大小一致(大小为 n),且每次都是全局卷积学习参数的复杂度会非常高,不仅如此,每次卷积涉及到的大规模矩阵乘法耗时也是 
,还有一个问题是现在的做法没有很好的应用节点之间的空间特性(距离远近)。
为了解决上面的问题有人提出一种巧妙地方法即下面要讲的 ChebNet
首先解决参数数量和局部卷积简化参数学习难度的问题。
我们希望用更少的(与图大小无关)的参数来表示卷积核,对 
的参数表示进行压缩,另

其中 
(拉普拉斯矩阵的特征值)
这样由:

得

现在的图卷积已经不用进行谱分解了,这里只需要计算 
,其中 
是由邻接矩阵导出来的(加上自回归的边后,每个位置是否为 0 是相同的),我们学习图论的时候知道通过计算邻接矩阵的 k 次方得到的矩阵非 0 位置表示两个节点存在长度为 k 的路径,这样的卷积具有很好的空间局部性,我们可以通过控制 k 来决定每个节点的表示仅由与其距离不超过 k 的节点及其关系决定,不像之前的图卷积计算当前节点会用到全局所有节点的信息,更能运用好 spatial localization,且现在需要学习的参数数量变为了与图无关的 K 个。
现在来解决每次卷积计算复杂度为 
的问题
这里用到 Chebyshev polynomial,该多项式是递归定义的:

为了能够简化卷积的计算复杂度,我们发现卷积核的计算需要计算 
, 将卷积核定义为如下可以递归计算的方式可以减少计算量。

然后通过和上面类似的推倒得到递归的卷积计算方式:

现在的卷积操作已经能满足上面提出的所有要求了。
在此基础上的变种
很多时候 K 不需要取的很大就能获得很好的效果,当 K=2 时,即只取前两项可以得到:

进一步简化,取 
则:
这就是本节刚开头提到的形式。
这种形式在堆叠多层时会造成数值上的不稳定及梯度爆炸 / 消失问题,所以可以用到重归一化技巧:
非基于谱的方法
基于谱的方法需要学习的参数都是与 Laplacian 矩阵的特征向量和特征值相关的,即取决于图的结构,这样有什么问题呢,如果你在一个大图或者很多同构的小图上进行训练是可以的,这也有很多应用场景。但是如果我们要处理很多不同结构的图,那就不能用同一套参数来学习,不惧泛化性,比如我们对很多树结构的句子进行分类(句子表示为依存句法树或其他),每个句子的表示可能都不同,那就没办法用上面的方法做。
下面介绍几种不依赖于图谱的方法的 GNN。
不基于谱最简单的方法就是直接把每个节点的邻居节点直接求和:

这里根据邻居个数的不同用不同的参数 W。
DCNN
DCNN 的做法也很简单:

其中 
, P 是度归一化后的临接矩阵。不要误会,这里的参数和图的结构没有关系,这里的参数 W 对应于与该节点不同距离的信息。
GraphSAGE 提出了一个更加通用的框架:

这里的 AGGREGATE 可以取不同的方法,GraphSAGE 论文中提到可以用 mean,max-pooling, sum,LSTM。 其实这是一个通用框架,本文提到的很多方法都可以套进来。
Attention
图的信息传递当然也可以用 attention(NLP 中的每个单词、CV 中的每个像素当做一个节点,它们的 attention 都可以当做是在图上的操作),通过当前节点的不同邻居与当前节点表示上的关系计算信息流的权重, a 为 attention 参数:

为了获得更充分(不同侧重)的信息,Attention is all you need 提出的 multi-head attention,可以表示为下面两种形式

其中 
表示拼接
Skip connection
相比于传统的网络,GNN 的深度一般更浅,原因是 GNN 的感受野随着深度的增加指数增大在信息传递过程中会引入大量噪声。所以在 GNN 中也有人尝试加入 skip connection 来缓解这个问题。下面是一个用 Highway 的方法的例子:

当前的输出还有一部分来自于上层的输出。
Gate
Highway 的方法比较简单,还有更复杂的方法来控制信息的传播,比如可以用 GRU,LSTM 的门控方式来传递图的信息,这个没啥好解释的,看公式应该写的很明白了,这里只介绍一下基于 GRU 的 GGNN:

其中 
是临接矩阵中与 v 有关的值构成的矩阵。
GNN 训练方法
原始的 GCN 方法每个节点的表示依赖于图中所有的其他节点,计算复杂度过大,且由于依赖于拉普拉斯矩阵训练的网络不惧泛化性。
GraphSAGE 对于每个节点的计算不涉及整张图,所以效率更加高,不过为了缓解深度加深感受野指数爆炸的现象,GraphSAGE 每次信息计算通过采样只使用部分邻居。
FastGCN 对 GraphSAGE 的随机采样加以改进,针对每个节点连接其他节点个数的不同给定不同的重要性。

还有一些限制感受野的其他方法,咱也不懂.
通用框架
Message Passing
该框架包含 3 个操作,信息传递操作(M),更新操作(U),读取操作(R):

其中 
表示边的信息。
上文提到的 GGNN 套用这个框架表示为:

NLNN
何凯明提出的 Non-local Neural Networks 用来捕捉图像上的 non-local 信息:
其中 f 用于计算 i、j 之间的关系, 
表示对输入做一个映射, 
表示对结果进行归一化。其中 
可以有不同的计算方式,比如什么 Gaussian,Embedded Gaussian, Dot product, Concatenation 等。
感觉这个有点牵强。。
Graph Networks
这个就是去年火爆一时的由一群大佬联名的 Relational inductive biases, deep learning, and graph networks。
由于这个更复杂更 general,先来介绍一下其中的符号表示, 这里 V 的表示与文章开头定义有所不同:

表示节点总数,
表示边的数量
图:G = (u, V, E) , 其中 
表示图中的每个节点的表示,u 表示全局信息, 
, 这其中,
表示边的信息, 
表示接收节点, 
表示发送节点
分别针对边、节点、全局节点定义了三种更新函数 
和三种聚合函数 
:

其中 
每个操作都很符合直觉,比如边的表示的更新依赖于原始边的表示、全局节点的表示及边连接的两个节点的表示。下面给出在该框架下的计算算法:

最终返回全局节点、普通节点、边的表示,在该框架下的图任务可以是基于图的也可以是基于节点的还可以是基于边的。
大部分的模型都只是实现了该框架的一部分,包括上面提到的两种通用框架也只是该框架的子集,比如上面的 Message passing 框架就没有 u 节点,也没有对边的更新,NLNN 框架没有的东西就更多了。
https://zhuanlan.zhihu.com/p/68015756

若有收获,就点个赞吧
0 人点赞
