更正一下题目中的几个小误区:
原题:如何解决图神经网络(GNN)训练中过度平滑的问题?即在图神经网络的训练过程中,随着网络层数的增加和迭代次数的增加,每个节点的隐层表征会趋向于收敛到同一个值(即空间上的同一个位置)。
不是所有图神经网络都有 over-smooth 的问题,例如,基于 RandomWalk + RNN、基于 Attention 的模型大多不会有这个问题,是可以放心叠深度的~只有部分图卷积神经网络会有该问题。
不是每个节点的表征都趋向于收敛到同一个值,更准确的说,是同一连通分量内的节点的表征会趋向于收敛到同一个值。这对表征图中不通簇的特征、表征图的特征都有好处。但是,有很多任务的图是连通图,只有一个连通分量,或较少的连通分量,这就导致了节点的表征会趋向于收敛到一个值或几个值的问题。
注:在图论中,无向图的连通分量是一个子图,其中任何两个顶点通过路径相互连接。
可视化试验
在讲解理论之前,我们首先进行一个可视化试验,以直观地获得对 over-smooth 的认识。
我们知道,GCN 的单层图卷积公式为:

其中, 
为激活函数, 
为节点特征, 
为训练参数, 
, 
为邻接矩阵, 
, 
为 graph 中的节点集合。训练参数
由任务相关的损失函数反向传播进行优化,可以理解为任务相关的模式提取能力,我们将其统一在图卷积后进行,多层卷积公式可以近似为:

其中, 
为所有卷积层实现的变换操作。这里,我们对 
取不同的值,通过观察 
模拟
层卷积的聚合效果。
模拟程序如下。
首先,定义三个连通子图:随机图、完全图和彼得森图:
import networkx as nximport matplotlib.pyplot as plt%matplotlib inlinesubgraph_1 = nx.sedgewick_maze_graph()subgraph_2 = nx.complete_graph(5)subgraph_3 = nx.petersen_graph()graph = nx.disjoint_union(subgraph_1, subgraph_2)graph = nx.disjoint_union(graph, subgraph_3)nx.draw_circular(graph)plt.show()
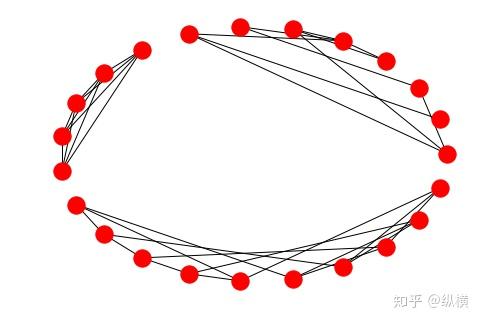
图 1: Graph 的三个连通子图 —— 随机图、完全图和彼得森图
接着,计算矩阵 
:
import scipyimport numpy as npimport scipy.sparse as sparsenodelist = graph.nodes()graph.add_edges_from(graph.selfloop_edges())A_hat = nx.to_scipy_sparse_matrix(graph, nodelist=nodelist, weight='weight', format='csr')n, m = A_hat.shapediags = A_hat.sum(axis=1).flatten()with scipy.errstate(divide='ignore'):diags_sqrt = 1.0 / np.sqrt(diags)diags_sqrt[scipy.isinf(diags_sqrt)] = 0D_hat = scipy.sparse.spdiags(diags_sqrt, [0], m, n, format='csr')aggregate_matrix = D_hat.dot(A_hat).dot(D_hat)
最后,在得到汇聚矩阵
的
次幂后,我们使用 heatmap 可视化卷积结果
。其中,我们令
为一个随机矩阵,模拟节点的不同特征:
import seaborn as sns;X = np.random.randn(23, 10)sns.heatmap(aggregate_matrix.todense())# 1 timefor _ in range(1):aggregate_matrix = aggregate_matrix.dot(aggregate_matrix)sns.heatmap(aggregate_matrix.todense().dot(X))# 3 timesfor _ in range(2):aggregate_matrix = aggregate_matrix.dot(aggregate_matrix)sns.heatmap(aggregate_matrix.todense().dot(X))# 6 timesfor _ in range(3):aggregate_matrix = aggregate_matrix.dot(aggregate_matrix)sns.heatmap(aggregate_matrix.todense().dot(X))
如下图所示,我们可视化了 23 个节点(行),的 9 维度特征(列),每个维度的特征值大小用亮度表示,越亮则表示越大:
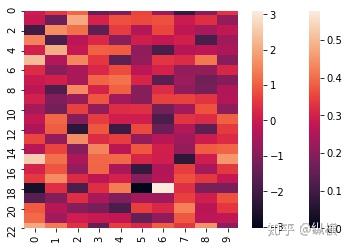
图 2: 特征矩阵的可视化
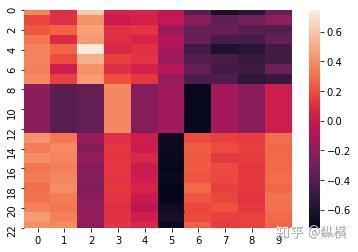
图 3: 经过 3 次卷积特征矩阵的可视化
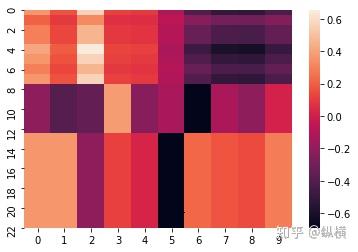
图 6: 经过 6 次卷积特征矩阵的可视化
可以发现,无论特征矩阵的初始状态如何(随机产生),多次卷积后,同一联通分量内所有节点的特征都趋于一致了。特别的,全连接连通分量内的节点特征,恰巧与连通分量内所有节点特征的平均成正比。
为什么 GCN 中会存在 over-smooth 的问题
有的工作 [1]想到利用特征分解给出 over-smooth 定理(同一连通分量内的节点的表征会趋向于收敛到同一特征向量)的证明:
对于没有激活函数的卷积操作 
,我们首先利用特征分解得到:

根据频率将特征矩阵展开(求和符号),得到:

假设 Graph 中有 
个连通分量,则对应的频率为:

当 
时, 
,
从而,从 1 到
之间的 
… 
,从 
到 
的 
… 
。
即, 
由于与 
相乘,可以知道,在计算结果中,该连通分量内的节点特征将均相同,且由 
决定。
定理得证。
该工作还进一步论证了带有 ReLU 和 bias 下的收敛情况。
十分推荐阅读以下 over-smooth 的收敛性论证论文:
- Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning [1]
- Tackling Over-Smoothing for General Graph Convolutional Networks [2]
- A Note on Over-Smoothing for Graph Neural Networks [3]
- Revisiting Oversmoothing in Deep GCNs [4]
值得一提的是,在知道 over-smooth 的存在后,如何度量 over-smooth 的程度呢?最近提出的 MADGap [5]十分有趣,如果你的 motivation 是解决 over-smooth 的话,可以尝试使用其进行度量和说明。
如何解决 over-smooth 的问题
在了解为什么 GCN 中会存在 over-smooth 问题后,剩下的工作就是对症下药了:
图卷积会使同一连通分量内的节点的表征趋向于收敛到同一个值。
- 针对 “图卷积”: 在当前任务上,是否能够使用 RNN + RandomWalk(数据为图结构,边已然存在)或是否能够使用 Attention(数据为流形结构,边不存在,但含有隐式的相关关系)?
- 针对 “同一连通分量内的节点”: 在当前任务上,是否可以对图进行 cut 等预处理?如果可以,将图分为越多的连通分量,over-smooth 就会越不明显。极端情况下,节点都不相互连通,则完全不存在 over-smooth 现象(但也无法获取周围节点的信息)。
如果上述方法均不适用,仍有以下 deeper 和 wider 的措施可以保证 GCN 在过参数化时对模型的训练和拟合不产生负面影响。个人感觉,这类方法的实质是不同深度的 GCN 模型的 ensamble:
巨人肩膀上的模型深度 —— residual 等
Kipf 在提出 GCN 时,就发现了添加更多的卷积层似乎无法提高图模型的效果,并通过试验将其归因于 over-smooth:多层 GCN 可能导致节点趋同化,没有区别性。但是,早期的研究认为这是由 GCN 过分强调了相邻节点的关联而忽视了节点自身的特点导致的。 所以 Kipf 给出的解决方案是添加残差连接[6],将节点自身特点从上一层直接传输到下一层:

在这个思路下,陆续有工作借鉴 DenseNet,将 residual 连接替换为 dense 连接,提出了自己的 module [7][8]:

其中,
表示拼接节点的特征向量。
最近,也有些工作认为直接将使用残差连接矫枉过正,残差模块完全忽略了相邻节点的权重,因而选择在
的基础上,对节点自身进行加强[9]:

在此基础上,作者进一步考虑了相邻节点的数量,提出了新的正则化方法:

另辟蹊径的模型宽度 —— multi-hops 等
随着图卷积渗透到各个领域,一些研究开始放弃深度上的拓展,选择效仿 Inception 的思路拓宽网络的宽度,通过不同尺度感受野的组合对提高模型对节点的表征能力。N-GCN[10]通过在不同尺度下进行卷积,再融合所有尺度的卷积结果得到节点的特征表示:

其中, 
,
表示拼接节点的特征向量。原文中尝试了 
和 
等不同的归一化方法对当前节点
阶临域的进行信息汇聚,取得了还不错的效果。
也有一些工作认为 GCN 的各层的卷积结果是一个有序的序列:对于一个
层的 GCN,第 
层捕获了
-hop 邻居节点的信息,其中 
,相邻层
和 
之间有依赖关系。因而,这类方法选择使用 RNN 对各层之间的长期依赖建模[11]:

即为:

与 over-smooth 相关的其他问题
随着图卷积的广泛应用,越来越的同学开始使用图卷积解决各个领域的问题,这使得 Graph 早已不再是最初规则的 Graph,它可能是自行构建的完全图、可能是高维点少的场景图等等。但凡遇到问题,我们第一个想到的就是 over-smooth。然而,这真的是 over-smooth 的问题吗,由于私信的同学太多,这里我简单介绍一下相关的问题,帮助提升性能。不感兴趣的同学可以直接跳过。
under-reaching 网络不能太浅(具体表现:加深网络性能提升)
由于每层 GCN(或 GraphSAGE 等)只能聚合一阶邻居节点(节点的直接相邻节点)的特征。较少的 GCN 层数会导致网络根本无法从远距离节点获得信息,从而,在卷积过程中卷积核的感受野过小,无法识别较为宏观的图结构信息。例如,较大的社区、或者区域性的 3d-point。这种现象通常在点云相关任务中出现,化简卷积操作,直接加深网络(添加图卷积层)即可。
over-squashing 网络不能太挤(具体表现:加深网络性能不变)
此前,一部分学者认为,加深网络而性能没有提升属于 over-smooth 现象。然而,另一些工作认为,over-smooth 应在网络过深时导致性能下降(因为节点特征收敛到同一个值,节点间无法区分,应该有害于任务的完成),因此事情另有蹊跷。
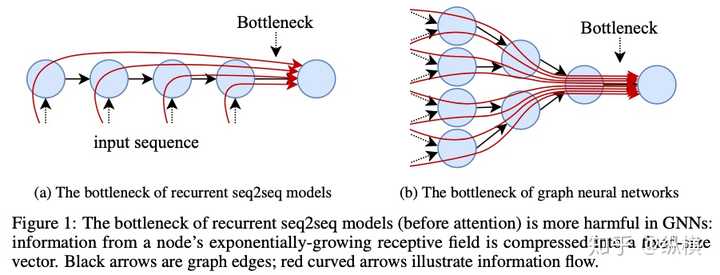
图 1: over-squashing 与 bottleneck
随着研究的不断深入,近年来 over-squashing 的观念又(因为此前在 RNN 上流行过)流行起来。他们认为,将众多的节点信息压缩在固定维度的当前节点特征中,会导致信息的损失。而距离较远的节点到当前节点的链路最长,最容易丢失信息,这些丢失的长程依赖,阻止了网络更全面地利用图上信息[12]。这种现象在边较为稀疏的 Graph 上比较常见(例如社交网络),可以考虑添加 attention 等机制。
over-fitting 网络不能太宽(具体表现:加宽网络性能下降)
一些同学在解决 over-squashing 问题时的直观思路是,扩大节点特征向量的维度。这样做在一定范围内是可以的。但是,随着节点特征向量维度的增长,网络中全连接层也势必会增大。而较宽的网络虽然能够在训练集上拟合更多特征,却容易在验证集上产生性能的下滑(即过拟合现象)。这时,我们可能需要结合预训练、归一化、正则化等策略解决问题[13]。
随着图卷积的日益成熟,深层的图卷积已经在各个领域开花结果啦~ 相信在不久的将来,pruning 和 NAS 还会碰撞出新的火花,童鞋们加油呀!另外,有的同学私信想看我的论文中是怎样处理 over-smooth 的~可是由于写作技巧太差我的论文还没发粗去(最开始导师都看不懂我写的是啥,感谢一路走来没有放弃我的导师和师兄,现在已经勉强能看了),等以后有机会再分享叭~
参考
[1](#ref_1_0)bDeeper Insights into Graph Convolutional Networks for Semi-Supervised Learning https://arxiv.org/abs/1801.07606
^Tackling Over-Smoothing for General Graph Convolutional Networks https://arxiv.org/abs/2008.09864
^A Note on Over-Smoothing for Graph Neural Networks https://arxiv.org/abs/2006.13318
^Revisiting Over-smoothing in Deep GCNs https://arxiv.org/abs/2003.13663
^Measuring and Relieving the Over-smoothing Problem for Graph Neural Networks from the Topological View https://arxiv.org/abs/1909.03211
^Semi-supervised classification with graph convolutional networks https://arxiv.org/abs/1609.02907
^Representation learning on graphs with jumping knowledge networks https://arxiv.org/abs/1806.03536
^Can GCNs Go as Deep as CNNs https://arxiv.org/abs/1904.03751
^Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks https://arxiv.org/abs/1905.07953
^N-GCN: Multi-scale graph convolution for semi-supervised node classification https://arxiv.org/abs/1802.08888
^Residual or Gate? Towards Deeper Graph Neural Networks for Inductive Graph Representation Learning https://arxiv.org/abs/1904.08035
^On the Bottleneck of Graph Neural Networks and its Practical Implications https://arxiv.org/abs/2006.05205
^Effective Training Strategies for Deep Graph Neural Networks https://arxiv.org/abs/2006.07107
https://www.zhihu.com/
- a ↩︎

若有收获,就点个赞吧
0 人点赞
