 多数据源(读写分离)
多数据源(读写分离)
ykkj-spring-boot-starter-mybatis技术组件,除了提供 MyBatis 数据库操作,还提供了如下 2 种功能:
- 数据连接池:基于 Alibaba Druid实现,额外提供监控的能力。
- 多数据源(读写分离):基于 Dynamic Datasource实现,支持 Druid 连接池,可集成 Seata实现分布式事务。
1. 数据连接池
```xmlcom.alibaba druid-spring-boot-starter
<a name="lxbDT"></a>### 1.1 Druid 监控配置在 application-local.yaml配置文件中,通过 spring.datasource.druid 配置项,仅仅设置了 Druid **监控**相关的配置项目,具体数据库的设置需要使用 Dynamic Datasource 的配置项。如下图所示:<br />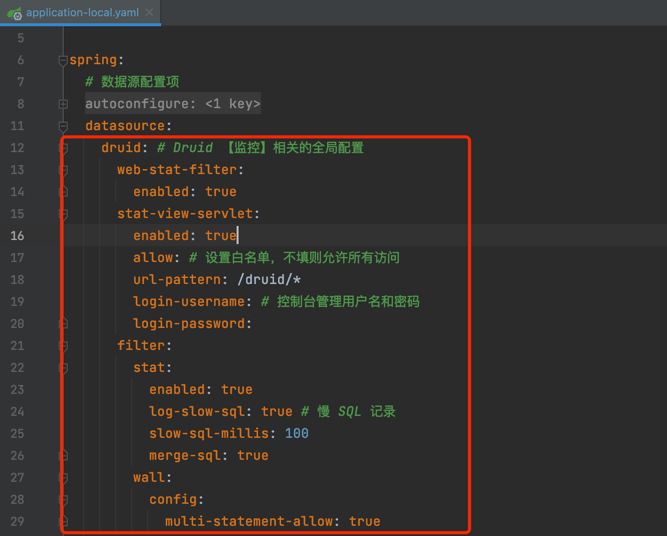<a name="qtQg1"></a>### 1.2 Druid 监控界面① 访问后端的 /druid/index.html 路径,例如说本地的 http://127.0.0.1:48080/druid/index.html 地址,可以查看到 Druid 监控界面。如下图所示:<br />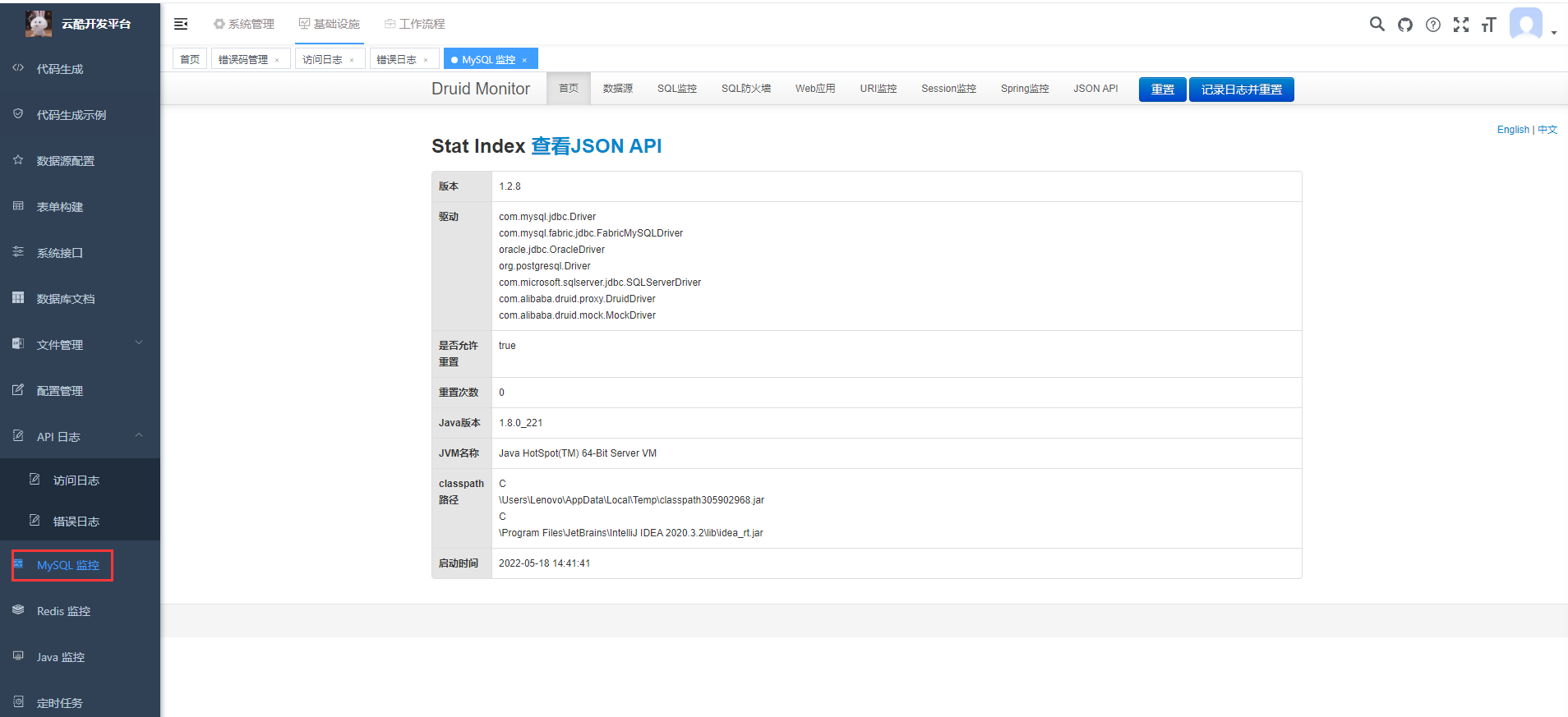<br />② 访问前端的 [基础设施 -> MySQL 监控] 菜单,也可以查看到 Druid 监控界面。如下图所示:<a name="p8JtN"></a>## 2. 多数据源```xml<dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId></dependency>
2.1 多数据源配置
在 application-local.yaml配置文件中,通过 spring.datasource.dynamic 配置项,配置了 Master-Slave 主从两个数据源。如下图所示:
2.2 数据源切换
2.2.1 @Master 注解
在方法上添加 @Master注解,使用名字为 master 的数据源,即使用【主】库,一般适合【写】场景。示例如下图:
由于项目的 spring.datasource.dynamic.primary 为 master,默认使用【主】库,所以无需手动添加 @Master 注解。
2.2.2 @Slave 注解
在方法上添加 @Slave注解,使用名字为 slave 的数据源,即使用【从】库,一般适合【读】场景。示例如下图:
2.2.3 @DS 注解
在方法上添加 @DS注解,使用指定名字的数据源,适合多数据源的情况。示例如下图:
2.3 分布式事务
在使用 Spring @Transactional 声明的事务中,无法进行数据源的切换,此时有 3 种解决方案:
① 拆分成多个 Spring 事务,每个事务对应一个数据源。如果是【写】场景,可能会存在多数据源的事务不一致的问题。
② 引入 Seata 框架,提供完整的分布式事务的解决方案。
③ 使用 Dynamic Datasource 提供的 @DSTransactional注解,支持多数据源的切换,不提供绝对可靠的多数据源的事务一致性(强于 ① 弱于 ②)。
3. 分库分表
建议采用 ShardingSphere 的子项目 Sharding-JDBC 完成分库分表的功能。

若有收获,就点个赞吧
0 人点赞
