启动服务(三大组件)
1. elasticsearch
进入es用户,执行bin/elasticsearch -d -d为在后台启动
2. kibana
如上进入es用户,执行nohup /usr/share/kibana/bin/kibana -c /etc/kibana/kibana.yml &
3. logstash
nohup /usr/share/logstash/bin/logstash -path.settings /etc/logstash/ &
测试端口是否正常:netstat -anp | grep 端口号
一、Elasticsearch
Elasticsearch简称ES,是一个开源的高扩展的分布式全文搜索引擎
日期(数值)范围查询
1. 范围查询的符号
| 符号 | 含义 |
|---|---|
| gte | 大于或等于 |
| gt | 大于 |
| lte | 小于或等于 |
| lt | 小于 |
2. 数值范围查询
需求:查询商品中40<=price<=80的文档:
Get book_shop/_search{"query":{"range":{"price":{"gte":40,"lte":80}}}}
3. 时间范围查询
3.1 简单查询示例
需求:查询网站中最近一天发布的博客:
Get website/_search{"query":{"range":{"post_date":{"gte":"now-1d/d",//当前时间的上一天,四舍五入到最近的一天"lt":"now/d" //当前时间,四舍五入到最近的一天}}}}
3.2 关于时间的数字表达式
ES中时间可以表示为now,也就是系统当前时间,也可以是以||结尾的日期字符串表示
在日期之后,可以选择一个或多个数学表达式:
+1h——加1小时;-1d——减1天;/d——四舍五入到最近的一天
下面是ES支持数学表达式的时间单位
| 表达式 | 含义 | 表达式 | 含义 |
|---|---|---|---|
y |
年 | M |
月 |
w |
星期 | d |
天 |
h |
小时 | H |
小时 |
m |
分钟 | s |
秒 |
说明:假设系统当前时间now=2021-5-24 12:00:00:
now+1h:now的毫秒值+1小时,结果是:2021-5-24 13:00:00now-1h:now的毫秒值-1小时,结果是:2021-5-24 11:00:00now-1h/d:now的毫秒值-1小时,然后四舍五入到最近的一天的起始,结果是:2021-5-24 00:00:002021.5.24||+1M/d:2021-5-24的毫秒值+1月,在四舍五入到最近的一天的起始,结果是2021-6-24 00:00:00
3.3 关于时间的四舍五入
对日期中的日、月、小时等 进行四舍五入时, 取决于范围的结尾是包含(include)还是排除(exclude).
向上舍入: 移动到舍入范围的最后一毫秒;
向下舍入: 一定到舍入范围的第一毫秒.
举例说明:
① "gt": "2018-12-18||/M" —— 大于日期, 需要向上舍入, 结果是2018-12-31T23:59:59.999, 也就是不包含整个12月.
②"gte": "2018-12-18||/M" —— 大于或等于日期, 需要向下舍入, 结果是 2018-12-01, 也就是包含整个12月.
③ "lt": "2018-12-18||/M" —— 小于日期, 需要向上舍入, 结果是2018-12-01, 也就是不包含整个12月.
④"lte": "2018-12-18||/M" —— 小于或等于日期, 需要向下舍入, 结果是2018-12-31T23:59:59.999, 也就是包含整个12月.
3.4 日期格式化范围查询
格式化日期查询时, 将默认使用日期field中指定的格式进行解析, 当然也可以通过format参数来覆盖默认配置.
示例:
GET website/_search{"query": {"range": {"post_date": {"gte": "2/1/2018","lte": "2019","format": "dd/MM/yyyy||yyyy"}}}}
注意: 如果日期中缺失了部分年、月、日, 缺失的部分将被填充为unix系统的初始值, 也就是1970年1月1日。比如, 将dd指定为format, 像"gte": 10将转换为1970-01-10T00:00:00.000Z。
二、Logstash
第1部分:设置和启动logstash
1.1 logstash文件结构
| 类型 | 描述 | 默认位置 | 设置 |
|---|---|---|---|
| home | Logstash安装的主目录 | /usr/share/logstash | |
| bin | 二进制脚本包括启动logstash和安装插件的logstash-plugin | /usr/share/logstash/bin | |
| settings | 配置文件,包括logstash.yml,jvm.options,startup.options | /etc/logstash | path.settings |
| conf | 日志存储管道配置文件 | /etc/logstash/conf.d/*.conf | See /etc/logstash/pipelines.yml |
| logs | 日志文件 | /var/log/logstash | path.logs |
| plugins | 本地,非Ruby-Gem插件文件。每个插件都包含在一个子目录中。建议仅用于开发。 | /usr/share/logstash/plugins | path.plugins |
| data | 由logstash及其插件用于任何持久性需求的数据文件。 | /var/lib/logstash | path.data |
1.2 logstash配置文件
Logstash有两种类型的配置文件:管道配置文件(定义Logstash处理管道)和设置文件(指定控制Logstash启动和执行的选项)。
- pipeline配置文件
在定义Logstash处理管道的各个阶段时,您将创建管道配置文件。在deb和rpm中,将管道配置文件放在/etc/logstash/conf.d目录。Logstash尝试只加载/etc/ Logstash /conf扩展名为.conf的文件。忽略所有其他文件。
See Configuring Logstash for more info. - Settings文件
设置文件已经在Logstash安装中定义。Logstash包括以下设置文件:logstash.yml:包含日志库配置标志。您可以在此文件中设置标志,而不是在命令行中传递标志。在命令行中设置的任何标志都会覆盖logstash.yml中的相应设置。See logstash.yml for more info.pipelines.yml:包含在单个Logstash实例中运行多个管道的框架和说明。See Multiple Pipelines for more info.jvm.options:包含JVM配置标志。使用此文件设置总堆空间的初始值和最大值。您还可以使用这个文件来设置Logstash的locale。在单独的行上指定每个标志。此文件中的所有其他设置都被视为高级设置。log4j2.properties:包含log4p2库的默认设置。See Log4j2 configuration for more info.startup.options(Linux):包含/usr/share/logstash/bin中的system-install脚本用于为您的系统构建适当的启动脚本的选项。安装Logstash包时,system-install脚本将在安装过程结束时执行,并使用startup中指定的设置。默认情况下,logstash服务安装在用户logstash下。logstash.options文件使您更容易安装Logstash服务的多个实例。您可以复制该文件并更改特定设置的值。注意启动时未读取startup.options文件。如果您想要更改Logstash启动脚本(例如,更改Logstash用户或从不同的配置路径读取),您必须重新运行system-install脚本(作为根用户)以传递新的设置。
1.3 logstash.yml
可以在logstash设置文件logstash.yml中设置来控制logstash执行。例如,您可以指定管道设置、配置文件的位置、日志记录选项和其他设置。logstash.yml中的大部分设置也可以作为命令行标志运行Logstash。您在命令行中设置的任何标志都会覆盖日志库中的相应yml文件。具体配置参数
1.4 安全配置
1.5 用命令行运行logstash
使用以下command运行logstash:bin/logstash [options],其中 options是command-lineflags可以具体控制logstash的执行。
以下命令运行logstash并且加载mypipeline.conf中的配置:bin/logstash -f mypipeline.conf
在测试Logstash时,指定命令行选项非常有用。但是,在生产环境中,我们建议您使用logstash.yml控制日志库的执行。使用settings文件可以使您更容易地指定多个选项,并且它为您提供了一个可版本化的单个文件,您可以使用该文件在每次运行时一致地启动Logstash。
- Command-Line Flags
**--node.name NAME**:指定此Logstash实例的名称。如果没有给出值,它将默认为当前主机名。**-f, --path.config CONFIG_PATH**:从特定的文件或目录加载Logstash配置。如果给定一个目录,该目录中的所有文件将按字典序连接起来,然后作为单个配置文件解析。不支持多次指定此标志。如果多次指定此标志,Logstash将使用最后一次出现。**-e, --config.string CONFIG_STRING**:使用给定的字符串作为配置数据。语法与配置文件相同。如果没有指定输入,则使用以下命令作为默认输入:input { stdin { type => stdin } },如果没有指定输出,则使用下面的输出作为默认输出:output { stdout { codec => rubydebug } },如果您希望使用这两种默认值,请使用空字符串作为-e标志。默认值是nil。**--modules**:启动命名模块。与-M选项一起工作,为指定模块的默认变量赋值。如果--modules在命令行中使用,则logstash.yml任何模块将被忽略,任何设置也会被忽略。此标志与-f和-e标志互斥。只能指定-f、-e或--modules中的一个。可以用逗号分隔多个模块,或者多次调用`—modules``标志来指定多个模块。
更多详见
第2部分:配置logstash
要配置Logstash,您需要创建一个配置文件来指定您想要使用的插件以及每个插件的设置。您可以在配置中引用事件字段,并在事件满足特定条件时使用条件来处理事件。运行logstash时,使用-f指定配置文件。
让我们逐步创建一个简单的配置文件,并使用它来运行Logstash。创建一个名为“Logstash-simple.conf”的文件,并将其保存在与Logstash相同的目录下。
input { stdin { } }output {elasticsearch { hosts => ["localhost:9200"] }stdout { codec => rubydebug }}
然后,运行logstash并使用-f标志指定配置文件。
bin/logstash -f logstash-simple.conf
2.1 config文件的结构
Logstash配置文件为您想要添加到事件处理管道中的每种类型的插件都有一个单独的部分。例如:
# This is a comment. You should use comments to describe# parts of your configuration.input {...}filter {...}output {...}
每个部分包含一个或多个插件的配置选项。如果指定多个过滤器,它们将按照它们在配置文件中出现的顺序应用。
插件配置
一个插件的配置由插件名和该插件的设置块组成。例如,这个输入部分配置两个文件输入:
在本例中,为每个文件输入配置了两个设置:路径和类型。
根据插件类型的不同,您可以配置的设置也不同。关于每个插件的信息,看Input Plugins, Output Plugins,Filter Plugins, 和 Codec Plugins.input {file {path => "/var/log/messages"type => "syslog"}file {path => "/var/log/apache/access.log"type => "apache"}}
值类型
插件可以要求设置的值为特定类型,如布尔型、列表型或散列型。
2.2 获取配置中的事件数据和字段
logstash代理是一个处理管道,包含3个阶段: inputs → filters → outputs。输入生成事件,过滤器修改它们,输出将它们发送到其他地方。
所有事件都有属性。例如,apache访问日志将包含状态代码(200,404)、请求路径(“/“,”index.html”)、HTTP谓词(GET, POST)、客户端IP地址等内容。Logstash将这些属性称为“字段fields”。
具体设置详见:https://www.elastic.co/guide/en/logstash/current/event-dependent-configuration.html
2.3 在配置中使用环境变量
2.3.1 overview
- 可以使用
${var}在配置中设置环境变量. - 在Logstash启动时,每个引用将被替换为环境变量的值。
- 替换是区分大小写的。
- 引用未定义的变量会引发日志库配置错误。
- 可以使用表单
${var:default value}提供一个默认值 . 如果环境变量未定义,Logstash将使用默认值。 - 您可以在任何插件选项类型中添加环境变量引用:字符串、数字、布尔、数组或hash。
- 环境变量是不可变的。如果更新环境变量,则必须重新启动Logstash以获取更新后的值。
2.3.2 举例
设置TCP端口
下面是一个使用环境变量设置TCP端口的示例:
现在设置TCP_PORT的值:
在启动时,Logstash使用以下配置:
如果没有设置TCP_PORT环境变量,Logstash将返回一个配置错误。
你可以通过指定一个默认值来解决这个问题:
现在,如果变量未定义,Logstash将使用默认值,而不是返回配置错误:
如果定义了环境变量,Logstash将使用为该变量指定的值,而不是默认值。input {tcp {port => "${TCP_PORT}"}}
export TCP_PORT=12345
input {tcp {port => 12345}}
input {tcp {port => "${TCP_PORT:54321}"}}
input {tcp {port => 54321}}
设置标签的值
下面是一个使用环境变量来设置标签值的例子:
设置ENV_TAG的值:
启动时,logstash使用以下配置:filter {mutate {add_tag => [ "tag1", "${ENV_TAG}" ]}}
export ENV_TAG="tag2"
filter {mutate {add_tag => [ "tag1", "tag2" ]}}
设置文件路径
下面是一个使用环境变量设置日志文件路径的示例:
设置home值:
初始时,使用以下配置:filter {mutate {add_field => {"my_path" => "${HOME}/file.log"}}}
export HOME="/path"
filter {mutate {add_field => {"my_path" => "/path/file.log"}}}
2.4 Logstash配置示例
https://www.elastic.co/guide/en/logstash/current/config-examples.html
第3部分:高级logstash配置
您可以在基本配置之外使用Logstash来处理更高级的需求,例如多个管道、Logstash管道之间的通信和多个平行事件。
3.1 多管道
如果您需要在同一个进程中运行多个管道,Logstash提供了一种方法,通过名为pipeline.yml的配置文件来实现这一点。这个文件必须放在path.settings文件夹,并遵循以下结构:
- pipeline.id: my-pipeline_1path.config: "/etc/path/to/p1.config"pipeline.workers: 3- pipeline.id: my-other-pipelinepath.config: "/etc/different/path/p2.cfg"queue.type: persisted
该文件以YAML格式格式化,并包含一个字典列表,其中每个字典描述一个管道,每个键/值对指定该管道的设置。该示例显示了由其id和配置路径描述的两个不同管道。对于第一个管道,pipeline.workers被设置为3,而在另一个中,持久化队列特性被启用。未在管道中显式设置的值为logstash.yml中指定的默认值。
- 使用场景
如果当前配置的事件流不共享相同的输入/过滤器和输出,并且使用标记和条件将其彼此分离,那么使用多个管道尤其有用。
在单个实例中拥有多个管道还允许这些事件流具有不同的性能和持久性参数(例如,对管道工作者和持久队列的不同设置)。这种分离意味着一个管道中的阻塞输出不会在另一个管道中施加反压力。
也就是说,考虑管道之间的资源竞争是很重要的,因为默认值是针对单个管道调优的。因此,例如,考虑减少每个管道使用的管道worker的数量,因为每个管道默认情况下每个CPU核心将使用1个worker。第4部分:输出插件
4.1 Elasticsearch
- 写到不同的索引中
如果你将事件发送到同一个Elasticsearch集群,但你的目标是不同的索引,你可以:
- 使用不同的Elasticsearch输出,每个输出具有不同的索引参数值
- 使用一个Elasticsearch输出,并对索引参数使用动态变量替换
每个Elasticsearch输出都是一个连接到集群的新客户端:
- 它必须初始化客户端并连接到Elasticsearch(如果有更多客户端,重启时间会更长)
- 它有一个关联的连接池
为了最小化打开到Elasticsearch的连接数,最大化批量大小并减少“小”批量请求的数量(这很容易填满队列),通常使用单个Elasticsearch输出会更有效。举例:
output {elasticsearch {index => "%{[some_field][sub_field]}-%{+YYYY.MM.dd}"}}
如果事件中没有包含目标索引前缀的字段怎么办?
您可以使用mutate过滤器和条件语句添加[@metadata]字段来设置每个事件的目标索引。[@metadata]字段不会被发送到Elasticsearch。
filter {if [log_type] in [ "test", "staging" ] {mutate { add_field => { "[@metadata][target_index]" => "test-%{+YYYY.MM}" } }} else if [log_type] == "production" {mutate { add_field => { "[@metadata][target_index]" => "prod-%{+YYYY.MM.dd}" } }} else {mutate { add_field => { "[@metadata][target_index]" => "unknown-%{+YYYY}" } }}}output {elasticsearch {index => "%{[@metadata][target_index]}"}}
第5部分:输入插件
5.1 Beats输入插件
5.1.1 描述
这个输入插件使Logstash能够从Elastic Beats框架接收事件。
下面的示例展示了如何配置Logstash在端口5044上侦听传入的Beats连接,并将其索引到Elasticsearch中。
input {beats {port => 5044}}output {elasticsearch {hosts => ["http://localhost:9200"]index => "%{[@metadata][beat]}-%{[@metadata][version]}"}}
在这里显示的Logstash配置中索引到Elasticsearch的事件与Beats直接索引到Elasticsearch的事件类似。
5.1.2 configuration options
这个插件支持以下配置选项以及后面描述的常用选项。
| 设置 | 输入类型 | Required |
|---|---|---|
| add_hostname | boolean | No |
| cipher_suites | array | No |
| client_inactivity_timeout | number | No |
| ecs_compatibility | string | No |
| host | string | No |
| include_codec_tag | boolean | No |
| port | number | Yes |
| ssl | boolean | No |
| ssl_certificate | a valid filesystem path | No |
| ssl_certificate_authorities | array | No |
| ssl_handshake_timeout | number | No |
| ssl_key | a valid filesystem path | No |
| ssl_key_passphrase | password | No |
| ssl_verify_mode | string, one of [“none”, “peer”, “force_peer”] | No |
| ssl_peer_metadata | boolean | No |
| tls_max_version | number | No |
| tls_min_version | number | No |
- port
- 这是需要的设置
- 参数类型是number
- 没有默认值
5.1.3 common options
所有输入插件都支持以下配置选项:
| Setting | Input type | Required |
|---|---|---|
| add_field | hash | No |
| codec | codec | No |
| enable_metric | boolean | No |
| id | string | No |
| tags | array | No |
| type | string | No |
细节:
add_field- 值类型是哈希
- 默认值是{}
向事件添加一个字段
codec- 值类型为codec
- 默认值为plain
用于输入数据的编解码器。输入编解码器是一种方便的方法,可以在数据进入输入之前对其进行解码,而不需要在您的Logstash管道中使用单独的过滤器。
enable_metric- 值类型为布尔值
- 默认值为true
默认情况下,为这个特定的插件实例禁用或启用指标日志记录,我们会记录我们所能记录的所有指标,但是你可以禁用特定插件的指标收集。
id- 值类型为字符串
- 此设置没有默认值。
添加一个唯一的ID到插件配置。如果没有指定ID, Logstash将生成一个。强烈建议在您的配置中设置这个ID。当您有两个或更多相同类型的插件时,这特别有用,例如,如果您有2个beats输入。在这种情况下,添加一个命名ID将有助于在使用监视api时监视Logstash。
input {beats {id => "my_plugin_id"}}
tags- 值类型为array
- 此设置没有默认值。
向事件中添加任意数量的任意标记。这有助于以后的处理。
type- 值类型为string
- 此设置没有默认值。
三、Filebeat
第1部分:简介
https://www.elastic.co/guide/en/beats/filebeat/7.13/filebeat-overview.html
Filebeat是转发和集中日志数据的轻量级托运人。作为服务器上的代理安装,Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或Logstash进行索引。
Filebeat是这样工作的:当您启动Filebeat时,它将启动一个或多个输入,这些输入位于您为日志数据指定的位置。对于Filebeat定位的每个日志,Filebeat启动一个采集器。每个采集器读取单个日志以获取新内容,并将新日志数据发送到libbeat, libbeat将聚合事件并将聚合的数据发送到为Filebeat配置的输出。
第2部分:Filebeat快速开始-安装和配置
本指南描述如何快速开始日志收集。你将学习如何:
- 在您想要监视的每个系统上安装Filebeat
- 指定日志文件的位置
- 将日志数据解析为字段并发送给Elasticsearch
- 可视化Kibana的日志数据
2.1 下载Filebeat
//linuxcurl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.13.1-linux-x86_64.tar.gztar xzvf filebeat-7.13.1-linux-x86_64.tar.gz
2.2 连接到Elastic Stack
设置Filebeat可以找到Elasticsearch安装的主机和端口,并设置授权设置Filebeat的用户名和密码。例如:
output.elasticsearch:hosts: ["myEShost:9200"]username: "filebeat_internal"password: "YOUR_PASSWORD"
如果您计划使用我们预先构建的Kibana仪表板,请配置Kibana端点。如果Kibana与Elasticsearch在同一台主机上运行,则跳过此步骤。
setup.kibana:host: "mykibanahost:5601"username: "my_kibana_user"password: "{pwd}"
2.3 收集日志数据
有几种方法可以使用Filebeat收集日志数据:
- 数据收集模块——简化常见日志格式的收集、解析和可视化
- ECS记录器——将应用程序日志结构和格式化为ECS兼容的JSON
- 手动Filebeat配置
2.3.1 激活和配置数据收集模块
确定需要的模块,模块清单
./filebeat modules list
从安装目录中启用一个或多个模块。例如,下面的命令启用了system, nginx和mysql模块configs:
./filebeat modules enable system nginx mysql
在modules.d下配置。更改模块Settings以匹配您的环境。
例如,根据操作系统设置日志位置。如果你的日志不在默认位置,设置path变量:
```
- module: nginx access: var.paths: [“/var/log/nginx/access.log*”] ```
2.3.2 激活和配置ECS
虽然Filebeat可用于摄取原始的、纯文本的应用程序日志,但我们建议在摄取时对日志进行结构化。这允许您提取字段,如日志级别和异常堆栈跟踪。
Elastic通过提供各种流行编程语言的应用程序日志格式化器简化了这个过程。这些插件将日志格式化为与ecs兼容的JSON,这样就无需手动解析日志了。
2.3.3 人工配置Filebeat
如果您无法找到适合您的文件类型的模块,或者无法更改应用程序的日志输出,请参见手动配置输入。
2.4 启动assets
Filebeat附带了用于解析、索引和可视化数据的预定义资源。要加载这些资源:
- 确定filebeat.yml中的用户被授权启动Filebeat
- 在安装目录下,运行命令:
-e是可选的,将输出发送到标准错误,而不是配置的日志输出。./filebeat setup -e
这一步将加载推荐的索引模板,用于写入Elasticsearch,并部署示例仪表板,用于在Kibana中可视化数据。
此步骤不加载用于解析日志行的摄取管道。默认情况下,摄取管道会在您第一次运行模块并连接到Elasticsearch时自动设置。
2.5 启动Filebeat
要启动Filebeat,运行:
sudo chown root filebeat.ymlsudo chown root modules.d/system.ymlsudo ./filebeat -e
2.6 查看Kibana中的数据
Filebeat附带了预先构建的Kibana仪表板和用于可视化日志数据的ui。您在前面运行setup命令时加载了指示板。
第3部分:Filebeat工作原理
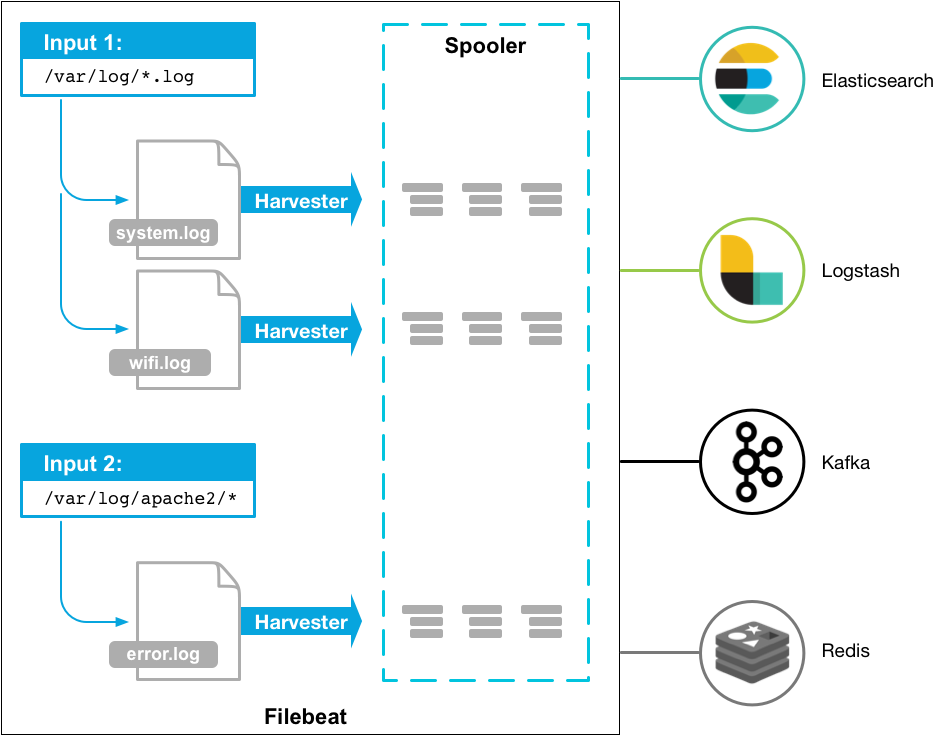
3.1 什么是harvester(收集器)?
采集器负责读取单个文件的内容。采集器逐行读取每个文件,并将内容发送到输出。每个文件启动一个采集器。采集器负责打开和关闭文件,这意味着在采集器运行时,文件描述符保持打开状态。如果文件在获取过程中被删除或重命名,Filebeat将继续读取该文件。这有一个副作用,磁盘上的空间被保留到采集器关闭。默认情况下,Filebeat保持文件打开,直到达到close_inactive。
3.2 什么是输入?
一个输入负责管理采集器并找到所有要读取的源。
如果输入类型是log,输入将查找驱动器上与定义的glob路径匹配的所有文件,并为每个文件启动一个采集器。每个输入都在自己的Go例程中运行。
下面的示例配置Filebeat从所有匹配指定glob模式的日志文件中获取行:
filebeat.inputs:- type: logpaths:- /var/log/*.log- /var/path2/*.log
3.3 Filebeat怎么保持文件的状态?
Filebeat保存每个文件的状态,并经常将状态刷新到注册表文件中的磁盘。该状态用于记住采集器读取的最后一个偏移量,并确保发送所有日志行。如果输出(如Elasticsearch或Logstash)不可达,Filebeat将跟踪发送的最后一行,并在输出再次可用时继续读取文件。当Filebeat运行时,每个输入的状态信息也保存在内存中。当Filebeat重新启动时,将使用注册表文件中的数据来重新构建状态,Filebeat将在每个收获器的最后已知位置继续运行。
对于每个输入,Filebeat保存它找到的每个文件的状态。由于可以重命名或移动文件,因此文件名和路径不足以标识文件。对于每个文件,Filebeat存储唯一的标识符,以检测以前是否获取了某个文件。
3.4 Filebeat怎么保证至少一次传递
Filebeat保证事件将至少一次传递到配置的输出,并且不会丢失数据。Filebeat能够实现此行为,因为它将每个事件的传递状态存储在注册表文件中。
在定义的输出被阻塞并且没有确认所有事件的情况下,Filebeat将继续尝试发送事件,直到输出确认它已经接收到事件。
如果Filebeat在发送事件的过程中关闭,它在关闭之前不会等待输出确认所有事件。当重新启动Filebeat时,将再次发送任何发送到输出但在Filebeat关闭前未被确认的事件。这确保每个事件至少发送一次,但最终可能会有重复的事件被发送到输出。您可以通过设置shutdown_timeout选项将Filebeat配置为在关闭之前等待特定的时间。
第4部分:配置
4.1 配置输入
要手动配置Filebeat(而不是使用模块),您需要在Filebeat中指定输入列表。filebeat.yml的输入部分。输入指定Filebeat如何定位和处理输入数据。
该列表是一个YAML数组,因此每个输入都以破折号(-)开头。您可以指定多个输入,并且可以多次指定相同的输入类型。例如:
filebeat.inputs:- type: logpaths:- /var/log/system.log- /var/log/wifi.log- type: logpaths:- "/var/log/apache2/*"fields:apache: truefields_under_root: true
对于最基本的配置,定义具有单个路径的单个输入。例如:
filebeat.inputs:- type: logenabled: truepaths:- /var/log/*.log
这个示例中的输入收集路径/var/log/*.log中的所有文件,这意味着Filebeat将收集目录/var/log/中以.log结尾的所有文件。Go Glob支持的所有模式也在这里得到支持。
要从预定义的子目录级别获取所有文件,请使用/var/log/*/*.log模式。这将从/var/log的子文件夹中获取所有.log文件。它不会从/var/log文件夹本身获取日志文件。目前不可能递归地获取一个目录的所有子目录中的所有文件。
4.1.1 log类型输入
使用日志输入从日志文件中读取行。
要配置此输入,请指定一个基于全局的路径列表,必须抓取这些路径来定位和获取日志行。
示例配置:
filebeat.inputs:- type: logpaths:- /var/log/messages- /var/log/*.log
您可以将其他配置设置(如fields、include_lines、exclude_lines、multiline等)应用到从这些文件中获取的行。您指定的选项将应用于此输入收集的所有文件
要对不同的文件应用不同的配置设置,你需要定义多个输入节:
filebeat.inputs:- type: logpaths:- /var/log/system.log- /var/log/wifi.log- type: logpaths:- "/var/log/apache2/*"fields:apache: true //uses the fields configuration option to add a field called apache to the output.fields_under_root: true
具体参数配置:https://www.elastic.co/guide/en/beats/filebeat/7.13/filebeat-input-log.html
4.2 配置输出
4.2.1 Elasticsearch
Elasticsearch输出使用Elasticsearch HTTP API直接向Elasticsearch发送事件。
output.elasticsearch:hosts: ["https://myEShost:9200"]
当通过elasticsearch输出将数据发送到安全集群时,Filebeat可以使用以下任何一种身份验证方法:
Basic authentication credentials (username and password).
output.elasticsearch:hosts: ["https://myEShost:9200"]username: "filebeat_writer"password: "YOUR_PASSWORD"
API key authentication:
output.elasticsearch:hosts: ["https://myEShost:9200"]api_key: "KnR6yE41RrSowb0kQ0HWoA"
PKI certificate authentication:
output.elasticsearch:hosts: ["https://myEShost:9200"]ssl.certificate: "/etc/pki/client/cert.pem"ssl.key: "/etc/pki/client/cert.key"
具体配置:https://www.elastic.co/guide/en/beats/filebeat/7.13/elasticsearch-output.html#hosts-option
4.2.2 Logstash
通过使用运行于TCP之上的lumberjack协议,Logstash输出直接将事件发送到Logstash。Logstash允许对生成的事件进行额外的处理和路由。
如果您想使用Logstash对Filebeat收集的数据执行额外的处理,您需要配置Filebeat以使用Logstash。
要做到这一点,你可以编辑Filebeat配置文件,通过注释它来禁用Elasticsearch输出,并通过取消注释Logstash部分来启用Logstash输出:
output.logstash:hosts: ["127.0.0.1:5044"]
hosts选项指定Logstash服务器和端口(5044),Logstash在其中被配置为侦听传入的Beats连接。
- 处理metadata fields
hosts选项指定Logstash服务器和端口(5044),Logstash在其中被配置为侦听传入的Beats连接。
您可以从Logstash配置文件中访问此元数据,以基于元数据的内容动态地设置值。
例如,下面的Logstash配置文件告诉Logstash使用由Filebeat报告的索引将事件索引到Elasticsearch:
```yaml input { beats { port => 5044 } }{..."@metadata": {"beat": "filebeat","version": "7.13.1"}}
output { elasticsearch { hosts => [“http://localhost:9200“] index => “%{[@metadata][beat]}-%{[@metadata][version]}” } }
<a name="YY05T"></a>## 第5部分:Filebeat和Logstash<a name="Bdp8M"></a>### 5.1 应用场景Filebeat是目前最好的日志文件传送者之一——它是轻量级的,支持SSL和TLS加密,支持背压,具有良好的内置恢复机制,而且非常可靠。但是,在大多数情况下,它不能使用日志增强过滤器将日志转换为易于分析的结构化日志消息。这就是Logstash所扮演的角色。<br />Logstash的作用就像一个聚合器——从不同的来源提取数据,然后将其推送到管道中,通常会将其推送到Elasticsearch中,但在更大的生产环境中也会将其推送到缓冲组件中。值得一提的是,在磁盘上存储消息队列时,最新版本的Logstash还包括对持久队列的支持。<br />Filebeat和Beats家族的其他成员充当部署在边缘主机上的轻量级代理,将数据抽取到Logstash中进行聚合、过滤和充实。<br />两个日志托运方之间的关系可以在下面的图中更好地理解:<br />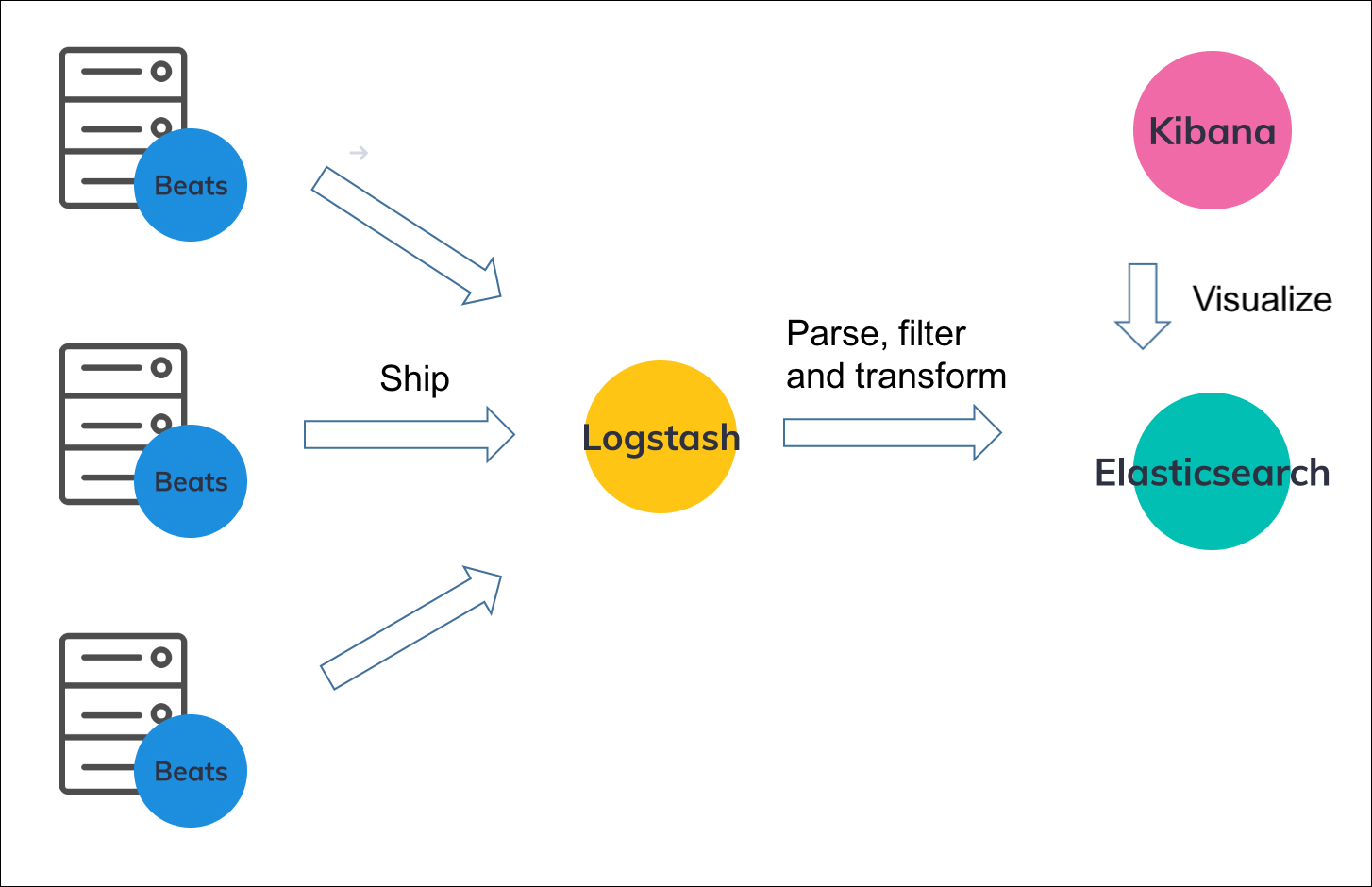<br />如果您使用ELK作为日志记录解决方案,那么发送这些日志的一种方法是使用Filebeat将数据直接发送到Elasticsearch。<br />由于Filebeat以JSON格式发送数据,Elasticsearch应该能够解析时间戳和消息字段,而不会有太多麻烦。不仅如此,Filebeat还支持一个Apache模块,该模块可以实施一些处理和解析。<br />然而,到目前为止,高级日志增强——通过将日志消息解析为单独的字段,过滤掉不需要的数据位并丰富其他数据来为日志消息添加上下文——没有Logstash是无法处理的。<br />此外,由于许多原因,特别是在中型和大型环境中,您不希望在主机上安装每个Filebeat代理将数据直接发送到Elasticsearch。<br />如果Elasticsearch暂时不可用,对磁盘的回压并不总是一个好的解决方案,因为文件可能会被旋转和删除。理想情况下,您希望控制索引连接的数量,如果数量太多,可能会导致高批量队列、糟糕的响应和超时。此外,需要暂停索引的Elasticsearch维护工作(例如在升级期间)变得更加复杂。<br />因此,在大多数情况下,您将同时使用Filebeat和Logstash。<a name="MTnV6"></a>### 5.2 为Logstash配置FilebeatFilebeat将被配置为跟踪主机上的特定文件路径,并使用Logstash作为目标端点。确保Logstash输出目标被定义为端口5044。```yamlfilebeat.inputs:- input_type: logpaths:- /var/log/httpd/access.logdocument_type: apache-accessfields_under_root: trueoutput.logstash:hosts: ["127.0.0.1:5044"]
5.2.1 配置Logstash发送Filebeat输入到Elasticsearch
在你的Logstash配置文件中,你将使用Beats输入插件、过滤器插件来解析和增强日志,并且Elasticsearch是Logstash在localhost:9200的输出目标:
input {beats {port => 5044}}filter {grok {match => { "message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:time}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-)" }}date {match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]}}output {elasticsearch { hosts => ["localhost:9200"] }}

若有收获,就点个赞吧
0 人点赞
