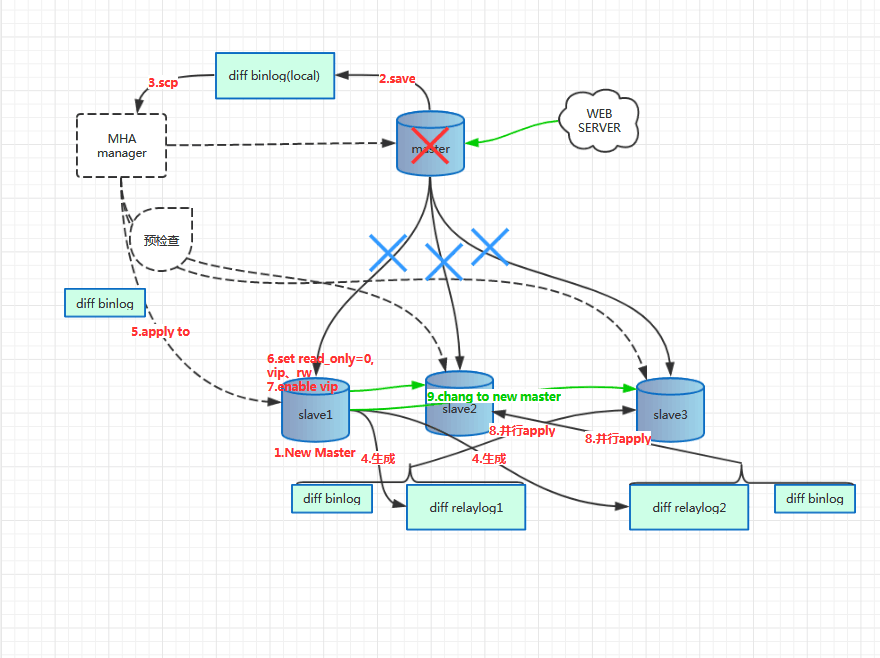
failover过程
完整日志如下(GTID模式)
Mon Jun 10 11:25:51 2019 - [warning] Got error on MySQL select ping: 1053 (Server shutdown in progress)Mon Jun 10 11:25:51 2019 - [info] Executing SSH check script: exit 0Mon Jun 10 11:25:51 2019 - [warning] HealthCheck: SSH to db1 is NOT reachable.Mon Jun 10 11:25:52 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '10.100.64.119' (111))Mon Jun 10 11:25:52 2019 - [warning] Connection failed 2 time(s)..Mon Jun 10 11:25:53 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '10.100.64.119' (111))Mon Jun 10 11:25:53 2019 - [warning] Connection failed 3 time(s)..Mon Jun 10 11:25:54 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '10.100.64.119' (111))Mon Jun 10 11:25:54 2019 - [warning] Connection failed 4 time(s)..Mon Jun 10 11:25:54 2019 - [warning] Master is not reachable from health checker!Mon Jun 10 11:25:54 2019 - [warning] Master db1(10.100.64.119:3306) is not reachable!Mon Jun 10 11:25:54 2019 - [warning] SSH is NOT reachable.Mon Jun 10 11:25:54 2019 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha/masterha_default.conf and /etc/masterha/app1.conf again, and trying to connect to all servers to check server status..Mon Jun 10 11:25:54 2019 - [info] Reading default configuration from /etc/masterha/masterha_default.conf..Mon Jun 10 11:25:54 2019 - [info] Reading application default configuration from /etc/masterha/app1.conf..Mon Jun 10 11:25:54 2019 - [info] Reading server configuration from /etc/masterha/app1.conf..Mon Jun 10 11:25:55 2019 - [info] GTID failover mode = 1Mon Jun 10 11:25:55 2019 - [info] Dead Servers:Mon Jun 10 11:25:55 2019 - [info] db1(10.100.64.119:3306)Mon Jun 10 11:25:55 2019 - [info] Alive Servers:Mon Jun 10 11:25:55 2019 - [info] db2(10.100.64.120:3306)Mon Jun 10 11:25:55 2019 - [info] db3(10.100.64.121:3306)Mon Jun 10 11:25:55 2019 - [info] Alive Slaves:Mon Jun 10 11:25:55 2019 - [info] db2(10.100.64.120:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:55 2019 - [info] GTID ONMon Jun 10 11:25:55 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:55 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:55 2019 - [info] db3(10.100.64.121:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:55 2019 - [info] GTID ONMon Jun 10 11:25:55 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:55 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:55 2019 - [info] Checking slave configurations..Mon Jun 10 11:25:55 2019 - [info] read_only=1 is not set on slave db2(10.100.64.120:3306).Mon Jun 10 11:25:55 2019 - [info] read_only=1 is not set on slave db3(10.100.64.121:3306).Mon Jun 10 11:25:55 2019 - [info] Checking replication filtering settings..Mon Jun 10 11:25:55 2019 - [info] Replication filtering check ok.Mon Jun 10 11:25:55 2019 - [info] Master is down!Mon Jun 10 11:25:55 2019 - [info] Terminating monitoring script.Mon Jun 10 11:25:55 2019 - [info] Got exit code 20 (Master dead).Mon Jun 10 11:25:55 2019 - [info] MHA::MasterFailover version 0.58.Mon Jun 10 11:25:55 2019 - [info] Starting master failover.Mon Jun 10 11:25:55 2019 - [info]Mon Jun 10 11:25:55 2019 - [info] * Phase 1: Configuration Check Phase..Mon Jun 10 11:25:55 2019 - [info]Mon Jun 10 11:25:56 2019 - [info] GTID failover mode = 1Mon Jun 10 11:25:56 2019 - [info] Dead Servers:Mon Jun 10 11:25:56 2019 - [info] db1(10.100.64.119:3306)Mon Jun 10 11:25:56 2019 - [info] Checking master reachability via MySQL(double check)...Mon Jun 10 11:25:56 2019 - [info] ok.Mon Jun 10 11:25:56 2019 - [info] Alive Servers:Mon Jun 10 11:25:56 2019 - [info] db2(10.100.64.120:3306)Mon Jun 10 11:25:56 2019 - [info] db3(10.100.64.121:3306)Mon Jun 10 11:25:56 2019 - [info] Alive Slaves:Mon Jun 10 11:25:56 2019 - [info] db2(10.100.64.120:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:56 2019 - [info] GTID ONMon Jun 10 11:25:56 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:56 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:56 2019 - [info] db3(10.100.64.121:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:56 2019 - [info] GTID ONMon Jun 10 11:25:56 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:56 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:56 2019 - [info] Starting GTID based failover.Mon Jun 10 11:25:56 2019 - [info]Mon Jun 10 11:25:56 2019 - [info] ** Phase 1: Configuration Check Phase completed.Mon Jun 10 11:25:56 2019 - [info]Mon Jun 10 11:25:56 2019 - [info] * Phase 2: Dead Master Shutdown Phase..Mon Jun 10 11:25:56 2019 - [info]Mon Jun 10 11:25:56 2019 - [info] Forcing shutdown so that applications never connect to the current master..Mon Jun 10 11:25:56 2019 - [info] Executing master IP deactivation script:Mon Jun 10 11:25:56 2019 - [info] /etc/masterha/master_ip_failover --orig_master_host=db1 --orig_master_ip=10.100.64.119 --orig_master_port=3306 --command=stop --orig_master_ssh_port=52000drop vip from original masterssh: connect to host db1 port 52000: Connection refusedMon Jun 10 11:25:59 2019 - [info] done.Mon Jun 10 11:25:59 2019 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master.Mon Jun 10 11:25:59 2019 - [info] * Phase 2: Dead Master Shutdown Phase completed.Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] * Phase 3: Master Recovery Phase..Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] * Phase 3.1: Getting Latest Slaves Phase..Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] The latest binary log file/position on all slaves is mysql-bin.000037:194Mon Jun 10 11:25:59 2019 - [info] Latest slaves (Slaves that received relay log files to the latest):Mon Jun 10 11:25:59 2019 - [info] db2(10.100.64.120:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:59 2019 - [info] GTID ONMon Jun 10 11:25:59 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:59 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:59 2019 - [info] db3(10.100.64.121:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:59 2019 - [info] GTID ONMon Jun 10 11:25:59 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:59 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:59 2019 - [info] The oldest binary log file/position on all slaves is mysql-bin.000037:194Mon Jun 10 11:25:59 2019 - [info] Oldest slaves:Mon Jun 10 11:25:59 2019 - [info] db2(10.100.64.120:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:59 2019 - [info] GTID ONMon Jun 10 11:25:59 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:59 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:59 2019 - [info] db3(10.100.64.121:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:59 2019 - [info] GTID ONMon Jun 10 11:25:59 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:59 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] * Phase 3.3: Determining New Master Phase..Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] Searching new master from slaves..Mon Jun 10 11:25:59 2019 - [info] Candidate masters from the configuration file:Mon Jun 10 11:25:59 2019 - [info] db2(10.100.64.120:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:59 2019 - [info] GTID ONMon Jun 10 11:25:59 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:59 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:59 2019 - [info] db3(10.100.64.121:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:59 2019 - [info] GTID ONMon Jun 10 11:25:59 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:59 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:59 2019 - [info] Non-candidate masters:Mon Jun 10 11:25:59 2019 - [info] Searching from candidate_master slaves which have received the latest relay log events..Mon Jun 10 11:25:59 2019 - [info] New master is db2(10.100.64.120:3306)Mon Jun 10 11:25:59 2019 - [info] Starting master failover..Mon Jun 10 11:25:59 2019 - [info]From:db1(10.100.64.119:3306) (current master)+--db2(10.100.64.120:3306)+--db3(10.100.64.121:3306)To:db2(10.100.64.120:3306) (new master)+--db3(10.100.64.121:3306)Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] * Phase 3.3: New Master Recovery Phase..Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] Waiting all logs to be applied..Mon Jun 10 11:25:59 2019 - [info] done.Mon Jun 10 11:25:59 2019 - [info] Getting new master's binlog name and position..Mon Jun 10 11:25:59 2019 - [info] mysql-bin.000032:194Mon Jun 10 11:25:59 2019 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='db2 or 10.100.64.120', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='xxx';Mon Jun 10 11:25:59 2019 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: mysql-bin.000032, 194, 479dbc89-e31e-11e8-83eb-005056a8803c:1-696587Mon Jun 10 11:25:59 2019 - [info] Executing master IP activate script:Mon Jun 10 11:25:59 2019 - [info] /etc/masterha/master_ip_failover --command=start --ssh_user=root --orig_master_host=db1 --orig_master_ip=10.100.64.119 --orig_master_port=3306 --new_master_host=db2 --new_master_ip=10.100.64.120 --new_master_port=3306 --new_master_user='xucl' --orig_master_ssh_port=52000 --new_master_ssh_port=52000 --new_master_password=xxxSet read_only=0 on the new master.add vip to new masterWarning: Permanently added '[db2]:52000' (ECDSA) to the list of known hosts.Mon Jun 10 11:25:59 2019 - [info] OK.Mon Jun 10 11:25:59 2019 - [info] ** Finished master recovery successfully.Mon Jun 10 11:25:59 2019 - [info] * Phase 3: Master Recovery Phase completed.Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] * Phase 4: Slaves Recovery Phase..Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] * Phase 4.1: Starting Slaves in parallel..Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] -- Slave recovery on host db3(10.100.64.121:3306) started, pid: 2886. Check tmp log /var/log/masterha/app1/db3_3306_20190610112555.log if it takes time..Mon Jun 10 11:26:00 2019 - [info]Mon Jun 10 11:26:00 2019 - [info] Log messages from db3 ...Mon Jun 10 11:26:00 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] Resetting slave db3(10.100.64.121:3306) and starting replication from the new master db2(10.100.64.120:3306)..Mon Jun 10 11:25:59 2019 - [info] Executed CHANGE MASTER.Mon Jun 10 11:25:59 2019 - [info] Slave started.Mon Jun 10 11:25:59 2019 - [info] gtid_wait(479dbc89-e31e-11e8-83eb-005056a8803c:1-696587) completed on db3(10.100.64.121:3306). Executed 0 events.Mon Jun 10 11:26:00 2019 - [info] End of log messages from db3.Mon Jun 10 11:26:00 2019 - [info] -- Slave on host db3(10.100.64.121:3306) started.Mon Jun 10 11:26:00 2019 - [info] All new slave servers recovered successfully.Mon Jun 10 11:26:00 2019 - [info]Mon Jun 10 11:26:00 2019 - [info] * Phase 5: New master cleanup phase..Mon Jun 10 11:26:00 2019 - [info]Mon Jun 10 11:26:00 2019 - [info] Resetting slave info on the new master..Mon Jun 10 11:26:00 2019 - [info] db2: Resetting slave info succeeded.Mon Jun 10 11:26:00 2019 - [info] Master failover to db2(10.100.64.120:3306) completed successfully.Mon Jun 10 11:26:00 2019 - [info]----- Failover Report -----app1: MySQL Master failover db1(10.100.64.119:3306) to db2(10.100.64.120:3306) succeededMaster db1(10.100.64.119:3306) is down!Check MHA Manager logs at manager:/var/log/masterha/app1/app1.log for details.Started automated(non-interactive) failover.Invalidated master IP address on db1(10.100.64.119:3306)Selected db2(10.100.64.120:3306) as a new master.db2(10.100.64.120:3306): OK: Applying all logs succeeded.db2(10.100.64.120:3306): OK: Activated master IP address.db3(10.100.64.121:3306): OK: Slave started, replicating from db2(10.100.64.120:3306)db2(10.100.64.120:3306): Resetting slave info succeeded.Master failover to db2(10.100.64.120:3306) completed successfully.
从日志上我们可以做一下分解、切割
Phase 1: Configuration Check Phase..
Mon Jun 10 11:25:56 2019 - [info] GTID failover mode = 1Mon Jun 10 11:25:56 2019 - [info] Dead Servers:Mon Jun 10 11:25:56 2019 - [info] db1(10.100.64.119:3306)Mon Jun 10 11:25:56 2019 - [info] Checking master reachability via MySQL(double check)...Mon Jun 10 11:25:56 2019 - [info] ok.Mon Jun 10 11:25:56 2019 - [info] Alive Servers:Mon Jun 10 11:25:56 2019 - [info] db2(10.100.64.120:3306)Mon Jun 10 11:25:56 2019 - [info] db3(10.100.64.121:3306)Mon Jun 10 11:25:56 2019 - [info] Alive Slaves:Mon Jun 10 11:25:56 2019 - [info] db2(10.100.64.120:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:56 2019 - [info] GTID ONMon Jun 10 11:25:56 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:56 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:56 2019 - [info] db3(10.100.64.121:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:56 2019 - [info] GTID ONMon Jun 10 11:25:56 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:56 2019 - [info] Primary candidate for the new Master (candidate_master is set)
该阶段主要做的是:
- 检查failover模式(这里是基于GTID的failover)
- 检查dead master(double check)
- 检查alive servers,并检查每个节点信息(GTID_MODE、从哪里复制、是否是candidate_master、read_only、replication filter)
Phase 2: Dead Master Shutdown Phase..
Mon Jun 10 11:25:56 2019 - [info] * Phase 2: Dead Master Shutdown Phase..Mon Jun 10 11:25:56 2019 - [info]Mon Jun 10 11:25:56 2019 - [info] Forcing shutdown so that applications never connect to the current master..Mon Jun 10 11:25:56 2019 - [info] Executing master IP deactivation script:Mon Jun 10 11:25:56 2019 - [info] /etc/masterha/master_ip_failover --orig_master_host=db1 --orig_master_ip=10.100.64.119 --orig_master_port=3306 --command=stop --orig_master_ssh_port=52000drop vip from original masterssh: connect to host db1 port 52000: Connection refusedMon Jun 10 11:25:59 2019 - [info] done.Mon Jun 10 11:25:59 2019 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master.Mon Jun 10 11:25:59 2019 - [info] * Phase 2: Dead Master Shutdown Phase completed.
/etc/masterha/master_ip_failover --orig_master_host=db1 --orig_master_ip=10.100.64.119 --orig_master_port=3306 --command=stop --orig_master_ssh_port=52000
调用master_ip_failover脚本,调用stop命令,我们再看下调用stop命令是进行了什么操作
if ( $command eq "stop" || $command eq "stopssh" ) {# $orig_master_host, $orig_master_ip, $orig_master_port are passed.# If you manage master ip address at global catalog database,# invalidate orig_master_ip here.&drop_vip();my $exit_code = 1;eval {# updating global catalog, etc$exit_code = 0;};if ($@) {warn "Got Error: $@\n";exit $exit_code;}exit $exit_code;}
实际上,就是去原先的master执行了删除vip的动作,从我们的日志上看到的是,因为原先的server服务器无法ssh上去,因此也无法执行drop动作
Phase 3: Master Recovery Phase..
Mon Jun 10 11:25:59 2019 - [info] * Phase 3: Master Recovery Phase..Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] * Phase 3.1: Getting Latest Slaves Phase..Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] The latest binary log file/position on all slaves is mysql-bin.000037:194Mon Jun 10 11:25:59 2019 - [info] Latest slaves (Slaves that received relay log files to the latest):Mon Jun 10 11:25:59 2019 - [info] db2(10.100.64.120:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:59 2019 - [info] GTID ONMon Jun 10 11:25:59 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:59 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:59 2019 - [info] db3(10.100.64.121:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:59 2019 - [info] GTID ONMon Jun 10 11:25:59 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:59 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:59 2019 - [info] The oldest binary log file/position on all slaves is mysql-bin.000037:194Mon Jun 10 11:25:59 2019 - [info] Oldest slaves:Mon Jun 10 11:25:59 2019 - [info] db2(10.100.64.120:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:59 2019 - [info] GTID ONMon Jun 10 11:25:59 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:59 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:59 2019 - [info] db3(10.100.64.121:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:59 2019 - [info] GTID ONMon Jun 10 11:25:59 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:59 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] * Phase 3.3: Determining New Master Phase..Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] Searching new master from slaves..Mon Jun 10 11:25:59 2019 - [info] Candidate masters from the configuration file:Mon Jun 10 11:25:59 2019 - [info] db2(10.100.64.120:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:59 2019 - [info] GTID ONMon Jun 10 11:25:59 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:59 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:59 2019 - [info] db3(10.100.64.121:3306) Version=5.7.23-log (oldest major version between slaves) log-bin:enabledMon Jun 10 11:25:59 2019 - [info] GTID ONMon Jun 10 11:25:59 2019 - [info] Replicating from 10.100.64.119(10.100.64.119:3306)Mon Jun 10 11:25:59 2019 - [info] Primary candidate for the new Master (candidate_master is set)Mon Jun 10 11:25:59 2019 - [info] Non-candidate masters:Mon Jun 10 11:25:59 2019 - [info] Searching from candidate_master slaves which have received the latest relay log events..Mon Jun 10 11:25:59 2019 - [info] New master is db2(10.100.64.120:3306)Mon Jun 10 11:25:59 2019 - [info] Starting master failover..Mon Jun 10 11:25:59 2019 - [info]From:db1(10.100.64.119:3306) (current master)+--db2(10.100.64.120:3306)+--db3(10.100.64.121:3306)To:db2(10.100.64.120:3306) (new master)+--db3(10.100.64.121:3306)Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] * Phase 3.3: New Master Recovery Phase..Mon Jun 10 11:25:59 2019 - [info]Mon Jun 10 11:25:59 2019 - [info] Waiting all logs to be applied..Mon Jun 10 11:25:59 2019 - [info] done.Mon Jun 10 11:25:59 2019 - [info] Getting new master's binlog name and position..Mon Jun 10 11:25:59 2019 - [info] mysql-bin.000032:194Mon Jun 10 11:25:59 2019 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='db2 or 10.100.64.120', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='xxx';Mon Jun 10 11:25:59 2019 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: mysql-bin.000032, 194, 479dbc89-e31e-11e8-83eb-005056a8803c:1-696587Mon Jun 10 11:25:59 2019 - [info] Executing master IP activate script:Mon Jun 10 11:25:59 2019 - [info] /etc/masterha/master_ip_failover --command=start --ssh_user=root --orig_master_host=db1 --orig_master_ip=10.100.64.119 --orig_master_port=3306 --new_master_host=db2 --new_master_ip=10.100.64.120 --new_master_port=3306 --new_master_user='xucl' --orig_master_ssh_port=52000 --new_master_ssh_port=52000 --new_master_password=xxxSet read_only=0 on the new master.add vip to new masterWarning: Permanently added '[db2]:52000' (ECDSA) to the list of known hosts.Mon Jun 10 11:25:59 2019 - [info] OK.Mon Jun 10 11:25:59 2019 - [info] ** Finished master recovery successfully.Mon Jun 10 11:25:59 2019 - [info] * Phase 3: Master Recovery Phase completed.
整个第三阶段步骤是最多的,主要有如下:
- 3.1: Getting Latest Slaves Phase
- 该阶段主要通过复制信息确定哪个slave节点有最新的binlog
- 3.2: Saving Dead Master’s Binlog Phase
- 保存dead master上的binlog,如果是由于down机导致无法ssh,那么会提示
Transactions that were not sent to the latest slave (Read_Master_Log_Pos to the tail of the dead master's binlog) were lost - 3.3: Determining New Master Phase
- 该阶段即确认哪个slave节点会被选为新的master节点
- 3.4:New Master Diff Log Generation Phase
- 该阶段即调用save_binary_logs来补齐binlog
- 3.5: Master Log Apply Phase
- 等待新master应用完全部的binlog,确定应用完日志的最新位点,生成change master to语句
- 完成以后调用failover命令
/etc/masterha/master_ip_failover --command=start --ssh_user=root --orig_master_host=db1 --orig_master_ip=10.100.64.119 --orig_master_port=3306 --new_master_host=db2 --new_master_ip=10.100.64.120 --new_master_port=3306 --new_master_user='xucl' --orig_master_ssh_port=52000 --new_master_ssh_port=52000 --new_master_password=xxx
这里调用start命令,源码如下:
elsif ( $command eq "start" ) {# all arguments are passed.# If you manage master ip address at global catalog database,# activate new_master_ip here.# You can also grant write access (create user, set read_only=0, etc) here.my $exit_code = 10;eval {my $new_master_handler = new MHA::DBHelper();# args: hostname, port, user, password, raise_error_or_not$new_master_handler->connect( $new_master_ip, $new_master_port,$new_master_user, $new_master_password, 1 );## Set read_only=0 on the new master$new_master_handler->disable_log_bin_local();print "Set read_only=0 on the new master.\n";$new_master_handler->disable_read_only();## Creating an app user on the new master#print "Creating app user on the new master..\n";#FIXME_xxx_create_user( $new_master_handler->{dbh} );$new_master_handler->enable_log_bin_local();$new_master_handler->disconnect();## Update master ip on the catalog database, etc&add_vip();$exit_code = 0;};if ($@) {warn $@;# If you want to continue failover, exit 10.exit $exit_code;}exit $exit_code;}
这里实际上执行的是设置read_only,然后绑定VIP的操作
Phase 4: Slaves Recovery Phase
- Phase 4.1: Starting Parallel Slave Diff Log Generation Phase
- 其他从库全部应用完relay log以后,从新的master上补齐差异binlog
- Phase 4.2: Starting Parallel Slave Log Apply Phase
- 其他节点应用差异的binlog
Phase 5: New master cleanup phase
该阶段即清理new master上的slave信息
最后完成fail over后,给出简单的报告:
app1: MySQL Master failover db1(10.100.64.119:3306) to db2(10.100.64.120:3306) succeededMaster db1(10.100.64.119:3306) is down!Check MHA Manager logs at manager:/var/log/masterha/app1/app1.log for details.Started automated(non-interactive) failover.Invalidated master IP address on db1(10.100.64.119:3306)Selected db2(10.100.64.120:3306) as a new master.db2(10.100.64.120:3306): OK: Applying all logs succeeded.db2(10.100.64.120:3306): OK: Activated master IP address.db3(10.100.64.121:3306): OK: Slave started, replicating from db2(10.100.64.120:3306)db2(10.100.64.120:3306): Resetting slave info succeeded.Master failover to db2(10.100.64.120:3306) completed successfully.
简单给出了从哪个节点选举了新的master节点,其他节点成功复制,failover完成


若有收获,就点个赞吧
0 人点赞
