
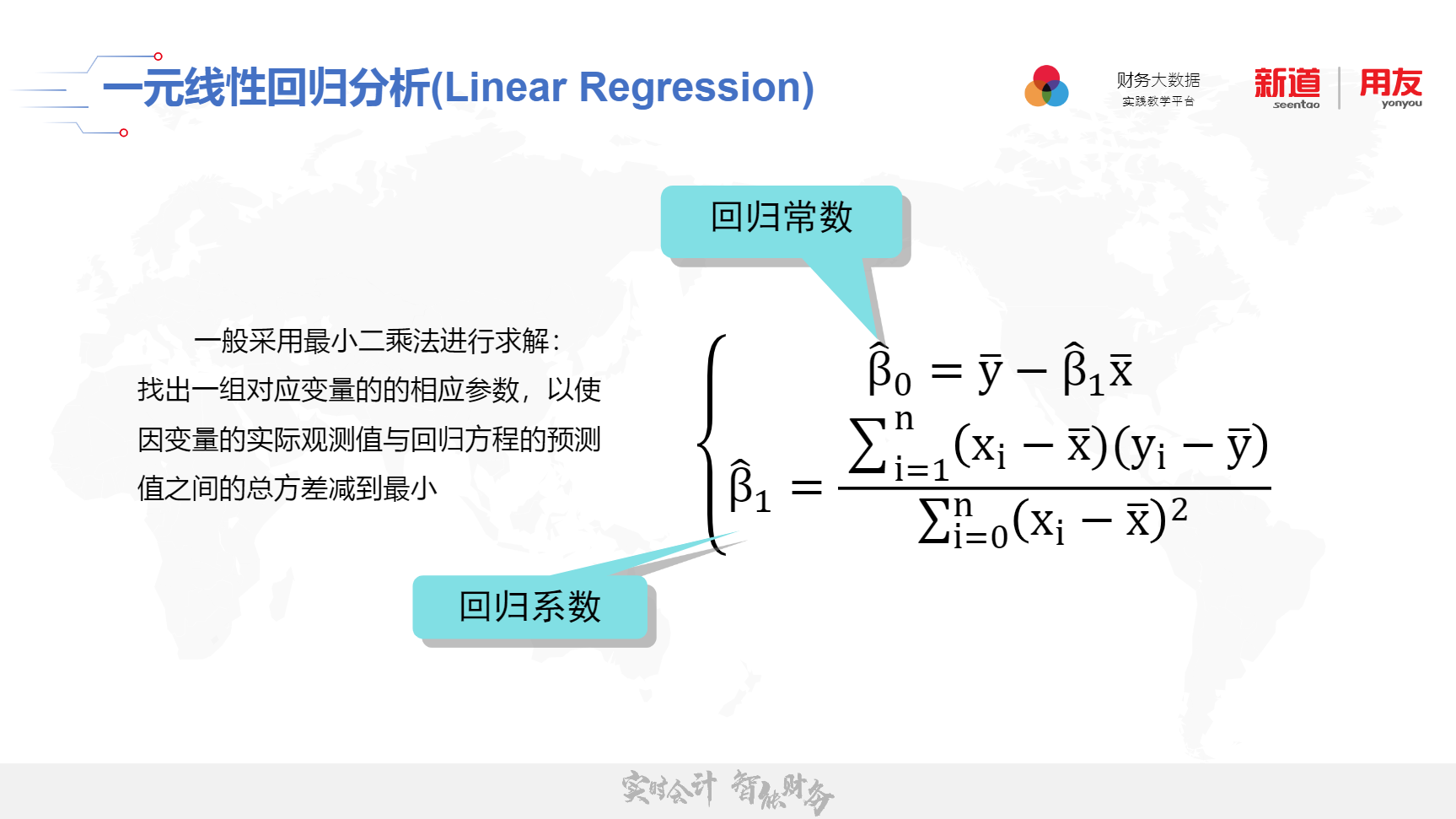
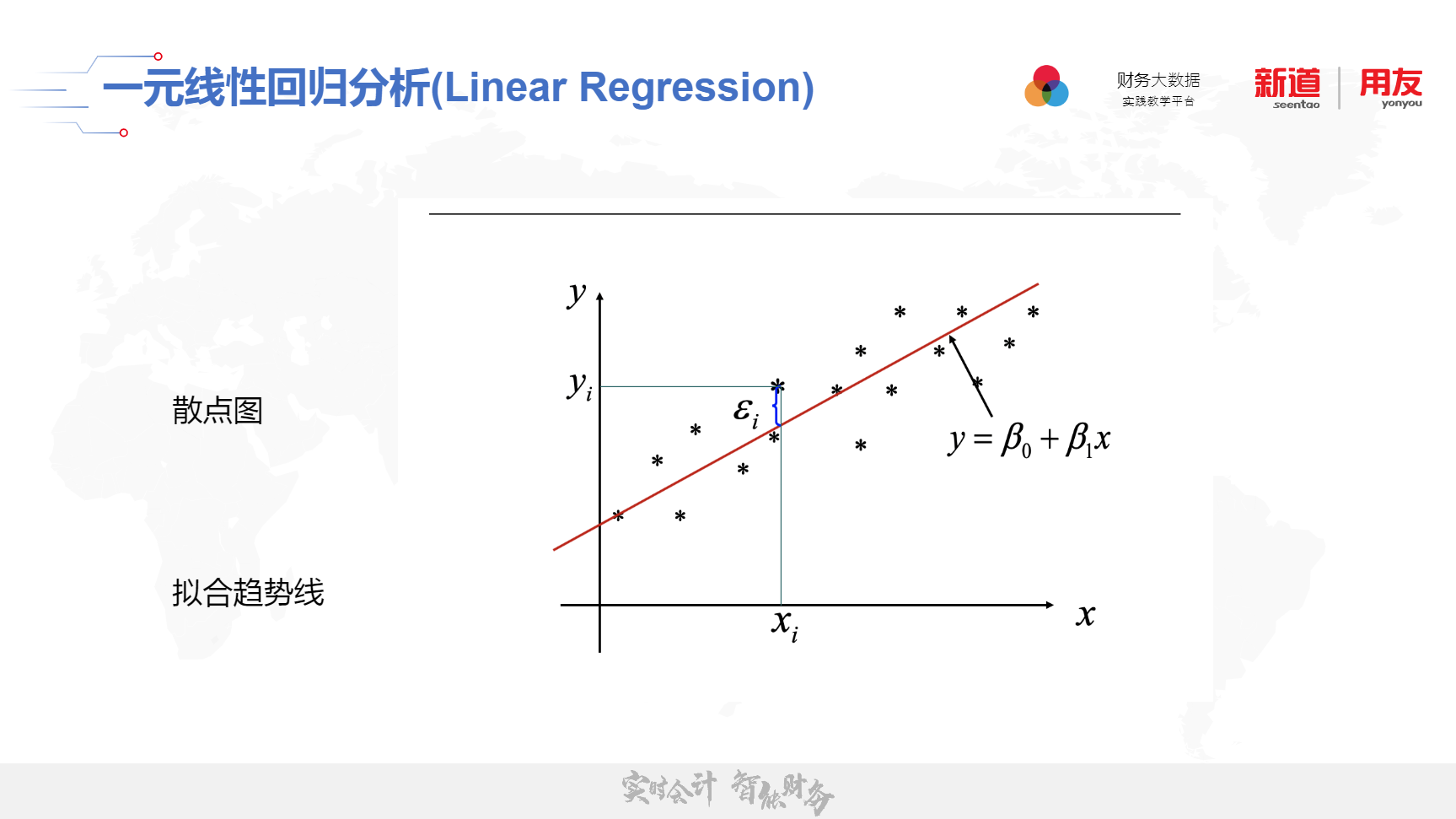
一元线性回归分析
一元线性回归是描述两个变量之间相关关系的最简单的回归模型。自变量与因变量间的线性关系的数学结构通常用式(1)的形式:y = po + $1x+E其中两个变量y与x之间的关系用两部分描述。一部分是由于x的变化引起y线性变化的部分,即β+ 31x,另一部分是由其他一切随机因素引起的,记为E。β和β是未知参数,β为回归常数,β1为回归系数。E表示其他随机因素的影响。一般假定E是不可观测的随机误差,它是一个随机变量
—训练集、验证集、测试集
训练集(Training Set) :用来训练与拟合模型;数据量大概占总样本的50%~70%
验证集(Validation Set):用于调整模型的参数和用于对模型的能力进行评估
测试集(Testing Set):用来检验最终选择最优的模型的性能如何
训练集+验证集+测试集=数据集

线性回归应用中的注意事项
(1)算法对于噪声和异常值比较敏感;因此,实践应用中,回归之前努力消除噪声和异常值,确保模型的稳定和准确度。
(2)算法只适合处理线性关系;如果自变量和因变量之间有比较强烈的非线性关系,直接利用多元线性回归不合适的。应该对自变量进行一定的转换
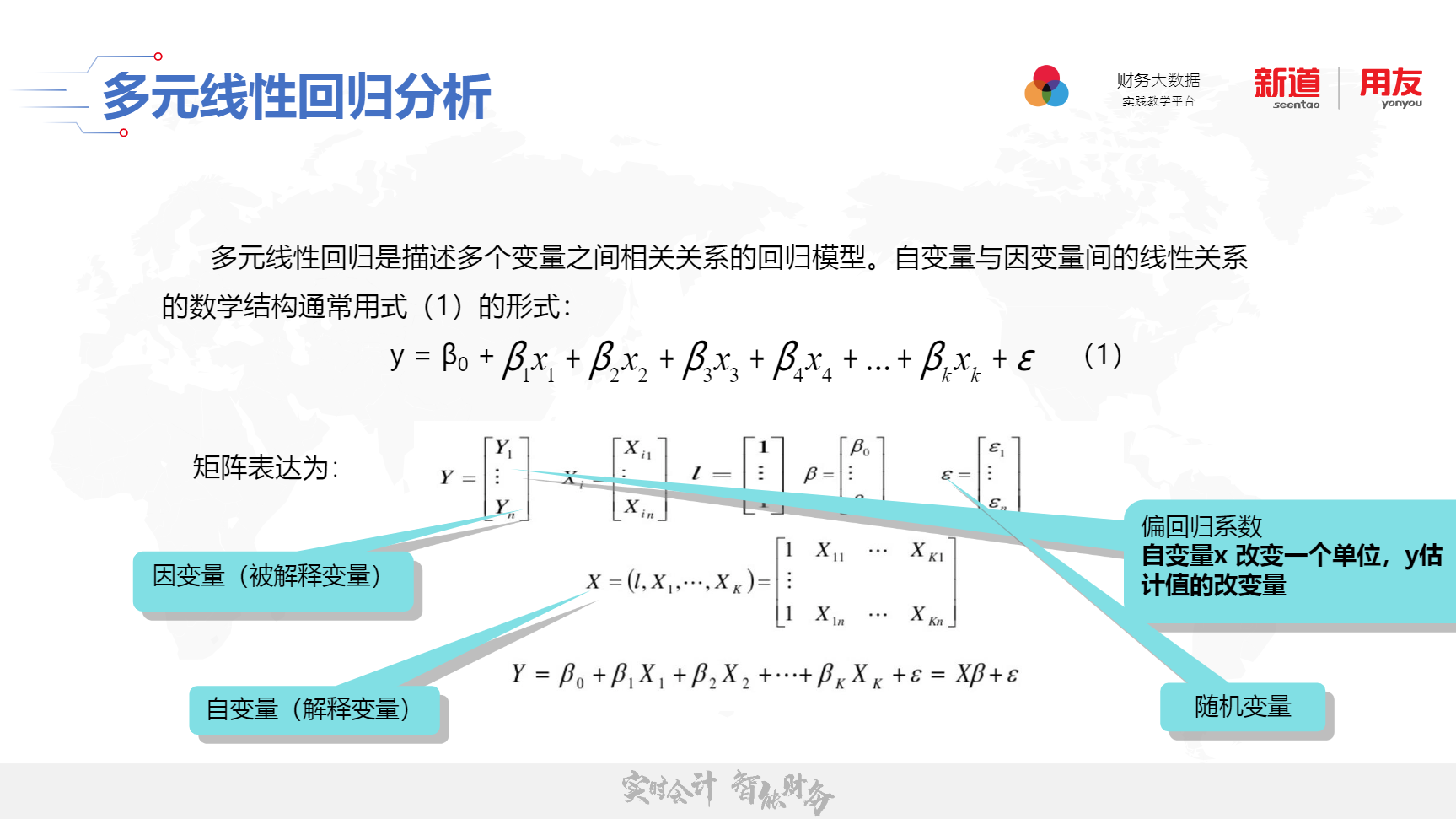
(3)多元线性回归还应满足一些前提假设;自变量是确定的变量,而不是随机变量,并且自变量之间没有线性相关性的;随机误差项具有均值为0和等方差性;随机误差呈正态分布等。
实验操作
数据挖掘操作流程
选择数据源:查看数据源;
配置模型,选择算法模型;
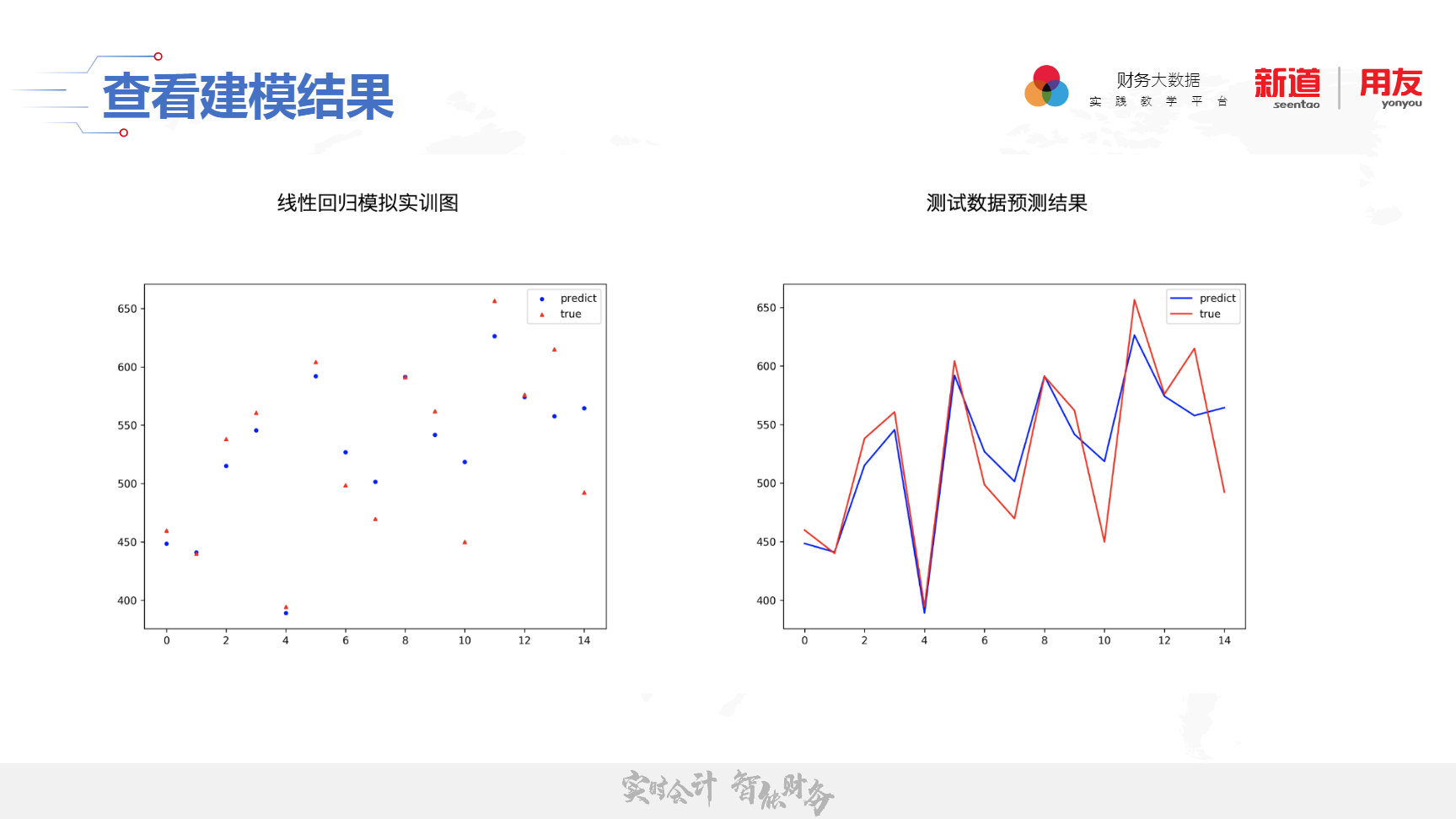
开始建模,查看训练结果;
选择预测数据源;
开始预测,查看预测结果;
选择数据源
点击“选择数据源”,弹出右1
侧“选择数据源框”;
点击“上传数据源,弹出上传
数据源框;
点击或者通过拖拽文件到区域
内完成上传,A单个文件不能
超过4M;
上传数据后,点击保存
查看数据源
①点击查看数据源;
2观察数据源,含有字段和数据;
③观察数据源是否还有缺失值、
异常字符、异常值;
配置模型1
1点击配置模型,弹出模型库;
选择回归分析模型中的线性回
归,弹出线性回归参数设置
框
3点击选择自变量和因变量中的
相应字段;
配置模型2
点击自变量,弹出选择字段框;
自变量为解释变量,选择相应解释变
量字段,通过点击选
③将选择的字段放入右侧已选字段框
中,勾选选择字段,点击确定;
④因变量为被解释变量,选择被解释变
量字段,点击确定;
⑤图中为所选定的自变量和因变量字
段;
自变量有:下游钢材产量、下游
奖对会计有Y财务
配置模型3
测试集比例:
是指回归模型机器学习中所用的测试集的比例,缺省值为25%,这也
意味着训练集比例是75%。
截距项:
是指回归模型是否有截距项,缺省为True;如果设为False,则在回归模型中不包括截距项。
标准化:
是指变量的正则化(标准化),采用变量减去均值后,除以标准差。
缺省值为False。当截距项选项设为False时,此选项无效。
覆盖:
是指自变量是否复制,缺省为True,如果设为False,则自变量会被覆盖




若有收获,就点个赞吧
0 人点赞
