document 对象
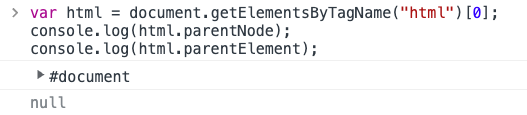
html就是一个文档,也就是document。html的「父节点」是document,html的「父元素」是null
var html = document.getElementsByTagName("html")[0];console.log(html.parentNode); //console.log(html.parentElement);
获取元素
getElementById(“IdName”)
:::info
通过元素的id来获取元素,返回元素对象
:::
:::danger
IE8及以下浏览器不区分大小写
:::
document.getElementById("testid");
getElementsByTagName(“tagName”)
:::info 通过元素的「标签名」来获取元素,返回元素集合伪数组 :::
document.getElementsByTagName("p");
getElementsByClassName(“className”)
:::info
通过元素的「类名」来获取元素,返回元素集合伪数组
:::
:::danger
IE8及以下浏览器没有该方法
:::
document.getElementsByClassName(".header");
getElementsByName(“testName”)
:::info
通过元素的name属性来获取元素,返回元素集合伪数组
:::
document.getElementsByName("name");
querySelector(“str”)
:::info
以CSS选择器的方式来获取元素,返回元素对象
📌 HTML5 新引入的 WEB API
:::
document.querySelector("p"); // 用标签名document.querySelector("#id"); // 用IDdocument.querySelector(".class"); // 用类名document.querySelector(".box > .item");
querySelectorAll(“str”)
:::info
以CSS选择器的方式来获取元素,返回元素集合伪数组
📌 HTML5 新引入的 WEB API
:::
document.querySelectorAll("div");
**querySelector**和**querySelectorAll**虽然好用,但是他们也有缺点:
- 性能不太好
- 不是实时更新的
下面看个案例:
<ul><li></li><li></li><li></li><li></li></ul>
先用getElementsByTagName()来试试:
var lis = document.getElementsByTagName("li");console.log(lis) // HTMLCollection(4) [li, li, li, li]lis[1].remove()console.log(lis) // HTMLCollection(3) [li, li, li]
然后再来看看querySelectorAll():
var lis = document.querySelectorAll("li");console.log(lis); // NodeList(4) [li, li, li, li]lis[1].remove();console.log(lis); // NodeList(4) [li, li, li, li]
可以明显的看到querySelectorAll()子元素删除后打印依然是4个元素!!!
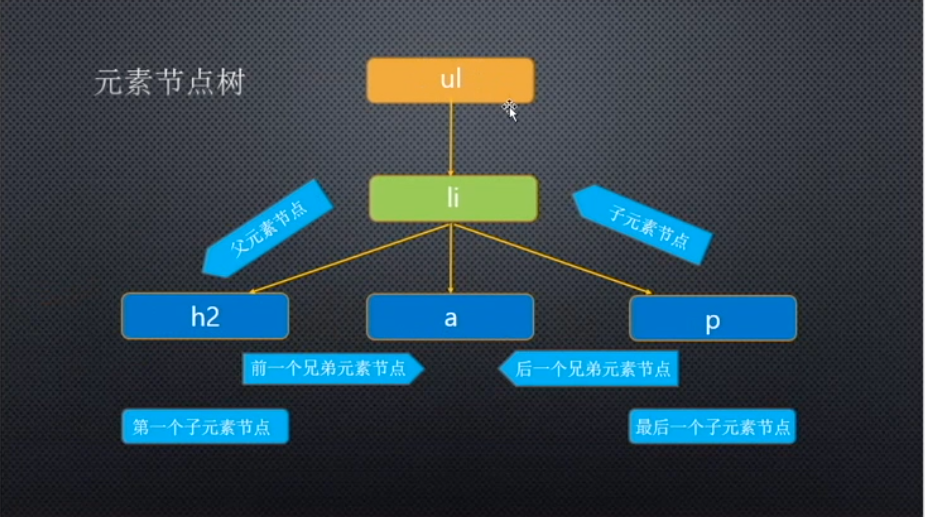
获取节点树
🌴 要理解「节点包含元素,元素只是节点的一部分!!!」
节点的类型总共包括:
DOM元素节点,代表码1- 属性节点,代表码
2 - 文本节点,代表码
3 - 注释节点,代表码
8 document节点,代表码9documentFragment节点,代表码11
下面来看看如何操作节点树:
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8" /><meta http-equiv="X-UA-Compatible" content="IE=edge" /><meta name="viewport" content="width=device-width, initial-scale=1.0" /><title>Document</title></head><body><ul><li><h2>我是标题标签</h2><p>我是段落标签</p><a href="">我是超链接</a><!-- 我是注释 --></li></ul></body></html><script>var p = document.getElementsByTagName("p")[0];</script>
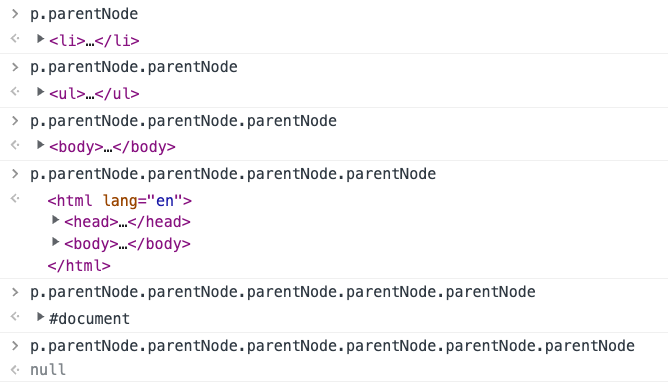
parentNode
:::info
查找元素的父节点html的父节点是document,document的父节点是null
:::
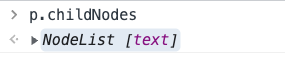
childNodes
:::info
查找元素的子节点
📌 该属性会返回子节点的所有类型元素,包括元素节点、文本节点、注释节点等
:::
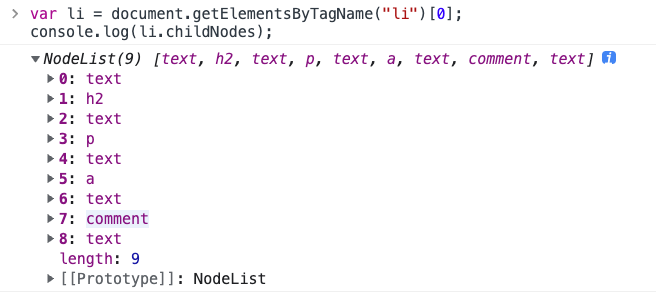
返回的多种元素节点,其中空格也属于文本节点!!!
firstChild
:::info
查找元素的第一个子节点
📌 返回的类型和childNodes一样,包括文本节点、属性节点等
:::
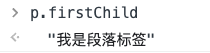
lastChild
:::info
查找元素的最后一个子节点
📌 返回的类型和childNodes一样,包括文本节点、属性节点等
:::
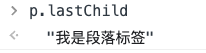
因为p元素下只有我是段落标签这段文字,所以firstChild和lastChild返回内容一样。
previousSibling
:::info
查找元素的前一个节点
📌 返回的类型和childNodes一样,包括文本节点、属性节点等
:::
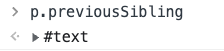
因为p元素的前面是空格,空格也属性节点,所以返回文本节点
nextSibling
:::info
查找元素的后一个节点
📌 返回的类型和childNodes一样,包括文本节点、文本节点等
:::
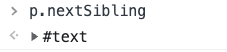
因为p元素的后面是空格,空格也属性节点,所以返回文本节点,如果p元素后面紧挨着a元素,那就就会返回a元素。
获取元素节点树
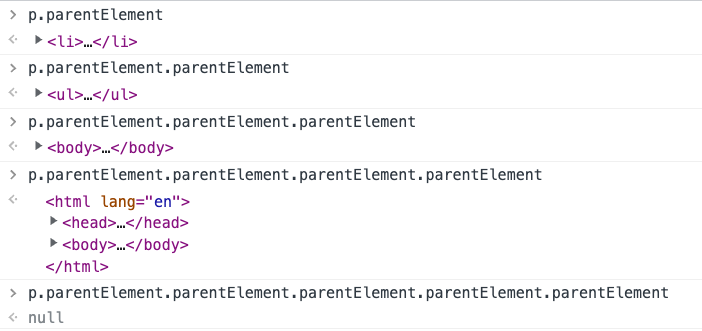
parentElement
:::info
查找元素的父元素html元素的父元素是null
:::
:::danger
IE8及以下版本浏览器不支持
:::
children
:::info
查找元素的子元素
📌 该属性只会返回子DOM元素不会返回其他类型的元素
:::

元素还有个childElementCount属性,返回子元素的数量(该数量里不包括文本和注释等)!!!
firstElementChild
:::info
查找元素的第一个子元素
:::
:::danger
IE8及以下版本浏览器不支持
:::

lastElementChild
:::info
查找元素的最后一个子元素
:::
:::danger
IE9及以下版本浏览器不支持
:::

previousElementSibling
:::info
查找元素的前一个元素
:::
:::danger
IE9及以下版本浏览器不支持
:::

nextElementSibling
:::info
查找元素的后一个元素
:::
:::danger
IE9及以下版本浏览器不支持
:::

是否有子节点
hasChildNodes()
:::info
该方法用于判断父节点下有没有子节点,包括文本、注释、元素节点等,返回true或者false
:::
<body><ul id="list"></ul></body>
console.log(document.body.hasChildNodes()); // true, ul 元素在 body 下

若有收获,就点个赞吧
0 人点赞
