- 整体架构
- 一、模块角度
- user 模块
- 发送短信验证码
- ⭐一键注册登陆
- ⭐用户账户信息完善【缓存双删】
- 拦截器验证用户合法性
- 退出登陆与注销会话
- ⭐粉丝关注
- 粉丝画像
- admin 模块
- user 模块
- file 模块
- article 模块
- 文章评论
- 二、表的介绍
- 三、中间件的业务
- 四、涉及的八股
- 五、面试题
- END
整体架构
一、模块角度
user 模块
发送短信验证码
(无需配置阿里云业务,发送验证码后直接在 redis 中查看即可)
短信发送接口:Redis 中存储 验证码 和 用户 IP.
分布式Session:验证码发出会会进行保存,单体项目用 session 保存也行;但是分布式项目中,还是用 Redis 保存.
在 getSMSCode 方法中补充形参。moblile为手机号,request获取 IP 便于判断是否发送 60 秒,用于防刷.
1 获取短信验证码:设置 IP 存在 60 s,验证码存在 30 min.
public GraceJSONResult getSMSCode(String mobile, HttpServletRequest request) {// 获得用户ipString userIp = IPUtil.getRequestIp(request);// 根据用户的ip进行限制,限制用户在60秒内只能获得一次验证码redis.setnx60s(MOBILE_SMSCODE + ":" + userIp, userIp);// 生成随机验证码并且发送短信String random = (int)((Math.random() * 9 + 1) * 100000) + "";// smsUtils.sendSMS(MyInfo.getMobile(), random);// 把验证码存入redis,用于后续进行验证redis.set(MOBILE_SMSCODE + ":" + mobile, random, 30 * 60);return GraceJSONResult.ok();}
(1)获取 IP,用于指定用户(之后浏览量防刷也用到了)
因为有了 request ,就可以根据用户 IP 限制60s内用户只能发送一次短信!
IP 需要从 request 中获取,老师事先加入了一个 IPutil 在 common 工程中,用于获取用户 ip,直接使用即可。
(2)保存发送验证码的用户信息
需要用到 Redis ,限制用户 60s 内只能获取一次验证码。
把 redisoperator 注入进来,调用 setnx60x 方法:key不存在就会设置,超过60s就会消失。
redis 里面存的信息有两部分:**MOBILE_SMSCODE + ip**。其中key不会写死,会写在公共的地方!因此把 key 提取,写在 api 工程中。这样,**通过 "常量 + IP" 的方式,就组合成了 key ,只要这个 key 在,就不能再次发送**!至于验证码,随便写一个:ip 即可<br />==> ?????是不是还没有设置,不足60s时不能再次发送的警告???
(3)生成随机验证码,并发送短信
(4)验证码存入redis,用于后续验证
短信存在 redis 中(???啥时候存的???)==> 这应该就是个业务逻辑.
set 时,加上时间设置,验证码有效时间为 30min.
2 验证码防刷:若 IP 存在,拦截并限制 60s 用户短信发送
防刷:就是规定时间内,再次发送,会对请求进行拦截!
如下图,60s 这个方法,补充判断,只要 key 存在,调用这个接口时,就进行拦截!
如果存在,让前端做一个抛出,返回一个错误的 json。前端接收到后提示发送频率太高了,所以这里需要构建 json。使用:“自定义异常——统一异常处理”.
@Autowiredprivate RedisOperator redis;public static final String MOBILE_SMSCODE = "mobile:smscode:";/*** 拦截请求,在访问controller调用之前* @param request* @param response* @param handler* @return* @throws Exception*/@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {//得到IPString userIP = IPUtil.getRequestIp(request);//判断IP是否存在Redisboolean keyIsExist = redis.keyIsExist(MOBILE_SMSCODE + userIP);if (keyIsExist) {return false;}/*** false: 请求被拦截,被驳回,验证出现问题* true: 请求在经过验证校验以后,是OK的,是可以放行的*/return true;}/*** 请求访问controller之后,渲染视图之前* @param request* @param response* @param handler* @param modelAndView* @throws Exception*/@Overridepublic void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {}/*** 请求访问controller之后,渲染视图之后* @param request* @param response* @param handler* @param ex* @throws Exception*/@Overridepublic void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {}
3 自定义异常,统一异常处理,返回错误信息:60s内不可重复发送验证码
完善要返回给前端的 报错 JSON 信息 !
只要拦截到自己写的自定义异常,捕获以后,就会以 JSON 字符串的形式,抛给前端。不管是浏览器端,还是手机端,都可以拿到这个异常信息,然后再提示用户。
⭐一键注册登陆
UUID:统一XX码,去了解下
(1)验证BO:判断 BindingResult 中是否保存了错误的验证信息,如果有,则需要返回
(2)校验验证码是否匹配;
(3) 查询数据库,判断该用户注册
<1> 调用 Service 层的方法
包含了两个数据库方面的操作,根据 mobile 查找数据库:
①如果用户存在,可以 直接登陆;
②没有,则在数据库中 创建用户;
关于创建用户的 ID:分布式环境中,业务量继续增多过程中,考虑“分库分表”。此时,自增主键的效率就非常差了,此时我们选择:“全局ID”。需要第三方组件,如下图:idworker 这个包,里面有个 Sid ,就用这个.(放在common工程中)
<2> Controller层:
如果用户不为空,并且状态为冻结,则直接抛出异常,禁止登录.
如果用户没有注册过,则为 null,需要注册信息入库.
(4)保存用户分布式会话的相关操作
用户注册和登陆以后,会产生相应的会话。
用户会话早期都是直接用 request 中的 session ;现如今使用分布式会话,会话信息存入redis,任何节点都能获取;将 cookie 和后端的 token 结合起来。
==> 保存 token 到 redis + 保存用户 id 和 token 到cookie中.
(5)用户登录或注册成功以后,需要删除redis中的短信验证码,验证码只能使用一次,用过后则作废
(6)返回用户状态
@Overridepublic GraceJSONResult doLogin(@Valid RegistLoginBO registLoginBO,BindingResult result,HttpServletRequest request,HttpServletResponse response) {// 0.判断BindingResult中是否保存了错误的验证信息,如果有,则需要返回if (result.hasErrors()) {Map<String, String> map = getErrors(result);return GraceJSONResult.errorMap(map);}String mobile = registLoginBO.getMobile();String smsCode = registLoginBO.getSmsCode();// 1. 校验验证码是否匹配String redisSMSCode = redis.get(MOBILE_SMSCODE + ":" + mobile);if (StringUtils.isBlank(redisSMSCode) || !redisSMSCode.equalsIgnoreCase(smsCode)) {return GraceJSONResult.errorCustom(ResponseStatusEnum.SMS_CODE_ERROR);}// 2. 查询数据库,判断该用户注册AppUser user = userService.queryMobileIsExist(mobile);if (user != null && user.getActiveStatus() == UserStatus.FROZEN.type) {// 如果用户不为空,并且状态为冻结,则直接抛出异常,禁止登录return GraceJSONResult.errorCustom(ResponseStatusEnum.USER_FROZEN);} else if (user == null) {// 如果用户没有注册过,则为null,需要注册信息入库user = userService.createUser(mobile);}// 3. 保存用户分布式会话的相关操作int userActiveStatus = user.getActiveStatus();if (userActiveStatus != UserStatus.FROZEN.type) {// 保存token到redisString uToken = UUID.randomUUID().toString();redis.set(REDIS_USER_TOKEN + ":" + user.getId(), uToken);redis.set(REDIS_USER_INFO + ":" + user.getId(), JsonUtils.objectToJson(user));// 保存用户id和token到cookie中setCookie(request, response, "utoken", uToken, COOKIE_MONTH);setCookie(request, response, "uid", user.getId(), COOKIE_MONTH);}// 4. 用户登录或注册成功以后,需要删除redis中的短信验证码,验证码只能使用一次,用过后则作废redis.del(MOBILE_SMSCODE + ":" + mobile);// 5. 返回用户状态return GraceJSONResult.ok(userActiveStatus);}
⭐用户账户信息完善【缓存双删】
1 查询用户“详细”信息:getAccountInfo
用户登陆注册完成后,需要用户信息进行更新。
当时就跳转到了这里:需要操作的就在这!更新前,当前页面中有一部分信息没有展示,所以先把用户信息展示出来,在页面中显示,然后就可以修改或提交.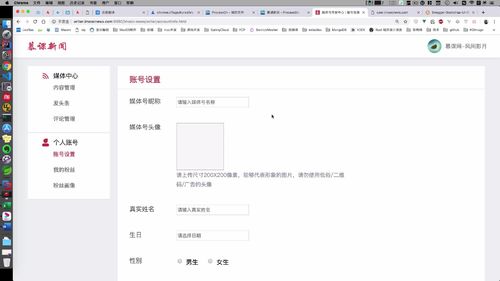
@Overridepublic GraceJSONResult getAccountInfo(String userId) {// 0. 判断参数不能为空if (StringUtils.isBlank(userId)) {return GraceJSONResult.errorCustom(ResponseStatusEnum.UN_LOGIN);}// 1. 根据userId查询用户的信息AppUser user = getUser(userId);// 2. 返回用户信息(VO类)UserAccountInfoVO accountInfoVO = new UserAccountInfoVO();BeanUtils.copyProperties(user, accountInfoVO);return GraceJSONResult.ok(accountInfoVO);}
(0)判断参数不能为空
(1)根据 userId 查询用户的信息:创建 VO 类,Service 层创建 getUser 方法
① user是持久层的数据,并不是所有信息都需要。一般是用什么,加载什么。一般会构建一个视图层对象:VO类,让视图层渲染与加载.
∴ user对象一般是不会直接抛出的(假如 user 有密码,不也直接抛出了嘛)因此,我们需要先搞一个Vo类!复制一个AppUser类,直接在这个基础上改!
(2)返回用户信息(VO类):通过 BeanUtils 工具类拷贝 AppUser 信息到 Vo 类中。
通过一个 BeanUtils 工具类进行属性拷贝!属性名匹配就能拷贝!!!
( BeanUtils 属于 package org.springframework.beans; 这个类不是我们自己导入的,靠依赖导入)
1.X 优化 getUser:在 Redis 中缓存用户信息
之前虽然已经通过 sessionStorage 对“基本信息”进行了优化(这个操作是什么时候做的????前端做的吗???),但是用户如果已经知道地址,还是可以发起高频率的请求.<br /> **因为“基本信息”基本不更改的特性 ==> 我们可以把基本信息存入到 Redis 中去**!这样用户查询时,直接去缓存Redis中查询即可,不用再进入数据库了**由于用户信息不怎么会变动,对于千万级别的网站,这类信息数据不会去查询数据库,完全可以把用户信息存入redis**。<br />**哪怕修改信息,也不会立马体现,这也是弱一致性**。在这里有过期时间,比如1天以后,用户信息会更新到页面显示,或者缩短到1小时,都可以; **基本信息在新闻媒体类网站是属于数据一致性优先级比较低的,用户眼里看的主要以文章为主,至于文章是谁发的,一般来说不会过多关注**.
private AppUser getUser(String userId) {String userJson = redis.get(REDIS_USER_INFO + ":" + userId);//1 尝试从redis获取AppUser user = null;//2 查询判断redis中是否包含用户信息,如果包含,则查询后直接返回,就不去查询数据库了if (StringUtils.isNotBlank(userJson)) {user = JsonUtils.jsonToPojo(userJson, AppUser.class);} else {// 3 说明 redis 无,去 mysql 中搞user = userService.getUser(userId);// 由于用户信息不怎么会变动,对于一些千万级别的网站来说,这类信息不会直接去查询数据库// 那么完全可以依靠redis,直接把查询后的数据存入到redis中redis.set(REDIS_USER_INFO + ":" + userId, JsonUtils.objectToJson(user));}return user;}
2 更新用户信息:updateUserInfo(未优化)
更新用户信息代码:缓存双写 时,会优化 service 层的 updateUserInfo)
updateUserInfo 方法:校验 BO + 执行更新操作
public GraceJSONResult updateUserInfo(@Valid UpdateUserInfoBO updateUserInfoBO,BindingResult result) {// 0. 校验BOif (result.hasErrors()) {Map<String, String> map = getErrors(result);return GraceJSONResult.errorMap(map);}// 1. 执行更新操作userService.updateUserInfo(updateUserInfoBO); //后面要更新补充redis的逻辑return GraceJSONResult.ok();}
(1)提交信息前,信息校验:同登陆时的BO验证
我们现在需要填写个人信息,并且提交。登陆前需要对 手机号 和 验证码判空,这里提交信息前的信息校验也是同理!就是看看提交的信息是否合理!!
信息还是表单类的信息。我们首先要做的就是【通过 BO 进行信息的验证】.
编写BO(包含判断信息合法性的注解):涉及到了BO,我们专门去写一份。Model 项目的 BO 包中.
(2)调用 Service 传递BO信息:提交信息,激活用户,信息入库
2.X 优化 updateUserInfo:Redis 中缓存用户信息 + 双写缓存不一致 + 缓存双删
优化1:保证双写一致,先删除 redis 中的数据,后更新数据库.
优化2:再次查询用户的最新信息,放入redis中
优化3:缓存双删策略,sleep一会,再删掉
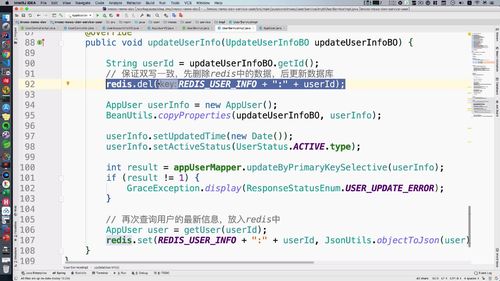
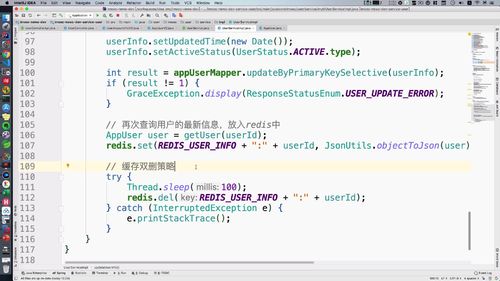
@Overridepublic void updateUserInfo(UpdateUserInfoBO updateUserInfoBO) {String userId = updateUserInfoBO.getId();// 【本节继续优化1】保证双写一致,先删除redis中的数据,后更新数据库.redis.del(REDIS_USER_INFO + ":" + userId);AppUser userInfo = new AppUser();BeanUtils.copyProperties(updateUserInfoBO, userInfo);userInfo.setUpdatedTime(new Date());userInfo.setActiveStatus(UserStatus.ACTIVE.type);int result = appUserMapper.updateByPrimaryKeySelective(userInfo);if (result != 1) {GraceException.display(ResponseStatusEnum.USER_UPDATE_ERROR);}// 【上一部分刚优化】再次查询用户的最新信息,放入redis中AppUser user = getUser(userId);redis.set(REDIS_USER_INFO + ":" + userId, JsonUtils.objectToJson(user));// 【本节继续优化2】缓存双删策略try {Thread.sleep(100);redis.del(REDIS_USER_INFO + ":" + userId);} catch (InterruptedException e) {e.printStackTrace();}}
(1)双写不一致:更新 mysql 时删除 redis,使得 redis 必须去 mysql 读取数据再存入
如何避免“双写不一致”的呢?
<1> 发起修改请求时,【先删除 redis 中过的数据】
<2> 删除后才更改数据库
<3> …后续就是再写入redis
redis中数据删除后,在重新写入前,如果用户此时访问了,【就和我们之前写的逻辑一样:redis中没有时,去数据库中查询】
(2)缓存双删:优化双写不一致
此时,分析一下,还有什么遗漏的问题。假如,用户的请求在 “ redis删除之后,mysql更新之前 ”,那么此时 redis 去 mysql 中拿到的数据,还是旧数据。如何避免?
==> 引入【缓存双删】:mysql “更新时”删一次,”等一会”再删除一次
我们在 mysql 更新后,【所在线程休眠半分钟左右,然后再次删除redis中的数据】,然后再更新。
注:这样的做法仍然是不能完全解决“脏数据的问题”,只是【很大程度上压缩脏数据的存在时时间】!!!因为对于用户来说,做到这样其实也已经足够了,这个业务并不是说,用户晚几秒看到用户信息就不能接受之类的。
3 查询用户“基本”信息:getUserInfo(只显示关键信息,后面用)
目前也已经更新了用户的信息到数据库,并已经做了激活。按理说,用户激活后,左侧菜单可以点击:但是因为用于【基本信息接口】我们都还没有写,所以还点不了;<br />我们之前处理的只是“账户信息”:在 (§ 2.2 注册登录 五)中,我们已经完成了用户详细信息的查询.<br />(这块逻辑其实可以再听听)
@Overridepublic GraceJSONResult getUserInfo(String userId) {// 0. 判断参数不能为空if (StringUtils.isBlank(userId)) {return GraceJSONResult.errorCustom(ResponseStatusEnum.UN_LOGIN);}// 1. 根据userId查询用户的信息AppUser user = getUser(userId);// 2. 返回用户信息AppUserVO userVO = new AppUserVO();BeanUtils.copyProperties(user, userVO);// 3. 查询redis中用户的关注数和粉丝数,放入userVO到前端渲染userVO.setMyFansCounts(getCountsFromRedis(REDIS_WRITER_FANS_COUNTS + ":" + userId));userVO.setMyFollowCounts(getCountsFromRedis(REDIS_MY_FOLLOW_COUNTS + ":" + userId));return GraceJSONResult.ok(userVO);}
(1)追加 “基本信息VO类”,只显示部分关键信息
(2)回到Controller,给前端抛出“基本信息VO类”即可
4 注:getAccountInfo & getUserInfo
==**>查询 用户信息 / 基本信息 代码逻辑基本一致,返回给前端内容不同,两者也实现了解耦**。
拦截器验证用户合法性
用户会话拦截器
有些接口是需要用户登录以后才能操作,比如用户发布文章。如果随随便便一个用户调用接口,会有问题。
所以我们需要构建拦截器来验证一下用户是否合法,只有合法用户才能放行。
用户状态拦截器
同理,有的接口必须在用户状态激活的情况才能去操作,不然只能看看,这也是很多网站的惯用手段。增加限制,促进用户主动去填写资料。
退出登陆与注销会话
用户退出系统后,那么不必要的资源可以释放,主要就是 redis中的数据 + cookie中数据 ,清除即可。
@Overridepublic GraceJSONResult logout(HttpServletRequest request,HttpServletResponse response,String userId) {// 1. 清除用户已登录的会话信息redis.del(REDIS_USER_TOKEN + ":" + userId);// 2. 清除用户userId与token的cookiesetCookie(request, response, "utoken", "", COOKIE_DELETE);setCookie(request, response, "uid", "", COOKIE_DELETE);return GraceJSONResult.ok();}
⭐粉丝关注
业务介绍:关注、取关、redis 单线程计数
(上节课的作业做的时候需要注意一个问题:文章的“阅读数”,这块后面都会讲的,暂时不用管。)
做法一:使用数据库,使用 count 函数查询数量,但是如果访问的多的话,数据的压力会很大,我们不选择这种方式。
做法二:我们使用redis,把它当作数据库来使用。因为它是单线程的,安全,累加或者累减都是可以的。使用 INCR / DECR 命令来。
redis 可以当做数据库来使用,累计数可以不需要同步到数据库,不需要对数据库做count查询,类似的累计统计数每次直接查redis使得更加高效,减少数据库压力,提高抗并发能力。
如果说要把统计数同步到数据库,那么也可以使用定时任务来同步到数据库,但是没有必要,因为会增加系统的额外资源开销。
查询用户关注状态( mysql 中的数据 )
本节开发【关注我】这块相关的业务.
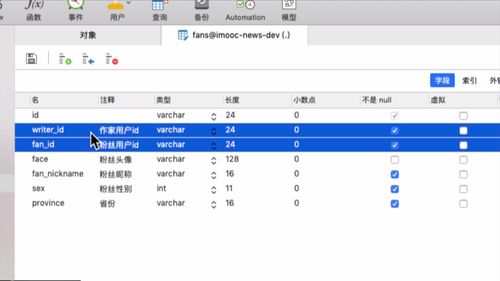
1 粉丝表的设计思路:冗余设计 + 保存粉丝的关键性信息
粉丝的头像,昵称这些,后面进行粉丝画像等数据处理时会涉及到。其实都算是“冗余设计”,也叫“宽表设计”。你不设置这些东西,也可以通过粉丝 id 来查到这些信息,但是呢,这就涉及 多表查询 了,会影响到性能。
==> 因此,我们这里的表的涉及都是为了能够 避免多变查询。这一部分后买你还会使用 ES 来进行优化,都会存入ES中。比如你想问这里的粉丝信息更新了怎么办?我们使用 “被动查询” 解决这一问题。因为对于被关注者,大部分时候不会去关心粉丝的这些信息,他最关心的是“粉丝量”,“男女比”这种,所以采用被动更新。
==> 因此,我们这里要做的就是保存粉丝的关键性信息而已,其他的后面再说。
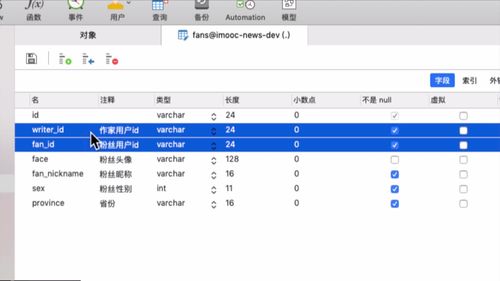
2 Controller 层:用户关注状态,表示当前用户 与 被浏览作家的关系
当前用户 与 被浏览作家的关系.==> 若没关注,显示“关注我”;否则,显示“已关注”
所以,涉及 “关注” “取消关注” 这两个接口.
到 api 工程中去,找到user,在user服务中去写。如下:这个接口就来显示 writerId 和 fanId 的关系,这俩也就作为方法参数传进去。
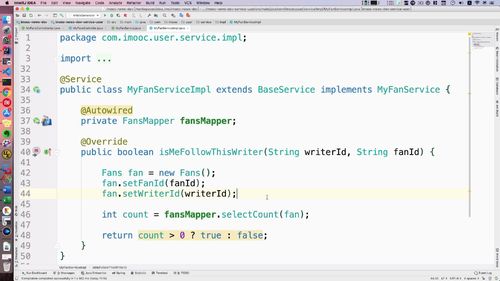
3 Service:查询当前用户是否关注作家
定义接口:返回 boolean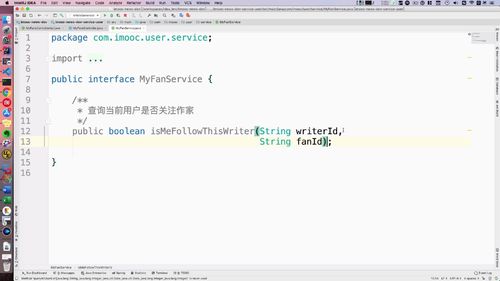
实现方法.
Mapper已经有了,直接注入.
fanMapper里把查询方法已经写好了,这个方法需要传入1个对象,我们搞个fan对象,作者id和浏览者id都放进去,它俩都在一个对象里,这样就存在联系了。
可以看到,这里的操作还是针对数据库的,后面这些东西我们都会放到es中去,就可以不再用这个count函数了。
关注 & 粉丝累加
**我们退出登录时,作者界面的关注选项就没有了,这个是前端做的。
**
演示完了重新登陆。然后我们来做下一个接口:【关注】【取关】!
上节课做的其实是“是否关注的状态”。注意一下,自己也可以关注自己,不过老师这块没有处理.
Service 层实现:通过 fanId 查到粉丝基本数据,创建 Fan 对象保证关系,关注数/粉丝数 存入redis
@Autowiredprivate UserService userService;@Transactional@Overridepublic void follow(String writerId, String fanId) {// 获得粉丝用户信息AppUser fanInfo = userService.getUser(fanId); //根据粉丝Id拿到粉丝基本信息String fanPkId = sid.nextShort(); //定义表的id// 保存作家粉丝关联关系,字段冗余便于统计分析,并且只认成为第一次成为粉丝的数据Fans fan = new Fans();fan.setId(fanPkId);fan.setFanId(fanId);fan.setWriterId(writerId);// 以下4个为冗余信息fan.setFace(fanInfo.getFace());fan.setFanNickname(fanInfo.getNickname());fan.setProvince(fanInfo.getProvince());fan.setSex(fanInfo.getSex());fansMapper.insert(fan);// redis 作家粉丝数累加redis.increment(REDIS_WRITER_FANS_COUNTS + ":" + writerId, 1);// redis 我的关注数累加redis.increment(REDIS_MY_FOLLOW_COUNTS + ":" + fanId, 1);}
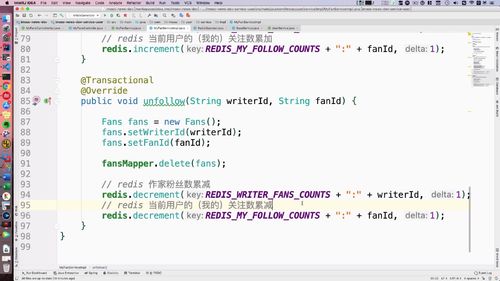
取关 & 粉丝累减
Service 层实现:del 两者关系的 Fan 对象,然后redis数据递减即可.
这里说了一段没听懂:什么 多对多 的?所以 关注 里的 fanPKId 这里可以不写了??什么 fanId 和 writerId 联合Id ???
==> 查询的时候,只要匹配 fanId 和 writerId 就行了的意思?fanPKId只是作为主键,查询的时候不用在意这个?
这里是累减方法.
粉丝数与关键页面显示
1 前端调用这个getUserInfo来查询的.
2 修改 AppUserVO:补充 关注数量 和 粉丝数量 的属性
3 BaseController 补充公用“获取数量的”的方法:用key查到count。
4 补充 getUserInfo,获取 关注数,粉丝数
粉丝画像
admin 模块
管理员 账号密码登陆(BCrypt 加密)
(1)手动创建第 1 个 admin 账户
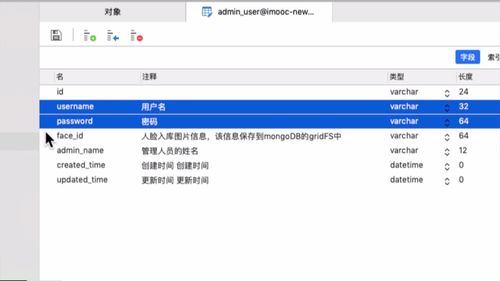
1 查看 admin 表结构
开发业务前,看看数据库列表,我们这里 admin 和 app 用户是两张表
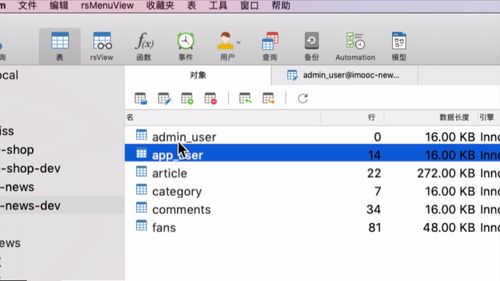
字段如下:
faceId 对应 mogoDB 中的人脸文件,搞到 mongoDB 里去.
2 创建初始 admin 账号 + 加密密码:BCrypt 加密
因为 admin 没有 “注册” 这一概念,都是 “预分配”:手动创建admin账号。然后通过 admin 再创建一些其他的账号.
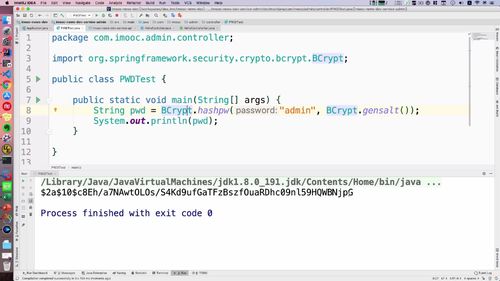
密码需要涉及加密,去 java 里面写一下。controller 城里面创建 PWDTest 类,api工程中加入spring的一个依赖(看笔记或者视频),然后就可以调用 BCrypt 这个类了。
我们并不是直接加密密码,而是先搞一个【salt】(hashpw中第二个形参),然后和密码(hashpw中第一个形参)一起放到 hashpw 方法中。当然老师这里用的是 “明文:admin作为密码”,实际上的话,这里最好把密码先用 【md5 加密】,然后再作为形参传入,再加盐。
这里,编写完代码并打印,如下:
String pwd = BCrypt.hashpw("admin", BCrypt.gensalt());
我们把这段拷贝到数据库中去:
ID1001,用户名admin,密码刚才生成,然后其他的如图:

(2)持久层查询管理员:mapper 和 service
看看admin登陆页,人脸识别先不管,我们需要先写相应的 service 和 controller。<br />
创建mapper
创建service:【根据用户名查询】(业务上,用户名唯一)
写对应方法:用来查询:【根据用户名查询】(业务上,用户名唯一).
查询后,把 adminUser 对象返回给 controller 层,然后在 controller 层就可以密码校验.
(3)用户密码登陆:controller层
紧接上节,编写controller
登陆界面的 用户名 和 密码 是在表单里面的,可以作为 BO 传入.
当然只是这样 是不行的,用户登陆以后,cookie 和 token 这种我们也都是要设置的!
登陆信息BO验证
@Overridepublic GraceJSONResult adminLogin(AdminLoginBO adminLoginBO,HttpServletRequest request,HttpServletResponse response) {// 0. TODO 验证BO中的用户名和密码不为空// 1. 查询admin用户的信息AdminUser admin =adminUserService.queryAdminByUsername(adminLoginBO.getUsername());// 2. 判断admin不为空,如果为空则登录失败if (admin == null) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_NOT_EXIT_ERROR);}// 3. 判断密码是否匹配// 判断存在时,从数据库中获得密码,与输入的BO中的密码匹配一下.boolean isPwdMatch =BCrypt.checkpw(adminLoginBO.getPassword(), admin.getPassword());if (isPwdMatch) {//如果数据库中有,则登录成功,并且设置admin的会话以及cookie信息即可。doLoginSettings(admin, request, response);return GraceJSONResult.ok();} else {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_NOT_EXIT_ERROR);}}
登陆成功时,设置 redis token cookie 信息
/*** 用于admin用户登录过后的基本信息设置* @param admin* @param request* @param response*/private void doLoginSettings(AdminUser admin,HttpServletRequest request,HttpServletResponse response) {// 保存token放入到redis中String token = UUID.randomUUID().toString();redis.set(REDIS_ADMIN_TOKEN + ":" + admin.getId(), token);// 保存 admin 登录基本 token 信息到 cookie 中setCookie(request, response, "atoken", token, COOKIE_MONTH);setCookie(request, response, "aid", admin.getId(), COOKIE_MONTH);setCookie(request, response, "aname", admin.getAdminName(), COOKIE_MONTH);}
管理员 账号创建(唯一性校验,人脸不存入数据库)
创建 BO
直接拷贝。里面的img64就是老师说的啥啥64那玩意。img64和faceId暂时用不上
admin用户名“唯一性”验证
该代码原来不是单独就有的,这里为了以后方便调用,单独抽出来了.
@Overridepublic GraceJSONResult adminIsExist(String username) {checkAdminExist(username);return GraceJSONResult.ok();}//得到用户名,判断是否存在,为方便调用,解耦出来private void checkAdminExist(String username) {AdminUser admin = adminUserService.queryAdminByUsername(username);if (admin != null) {GraceException.display(ResponseStatusEnum.ADMIN_USERNAME_EXIST_ERROR);}}
看到下面的确认添加了吗?本节就完成这个功能!
说白了就是把这里的数据发到后端,也可以将其作为一个BO的数据将其传过去。人脸数据现在还涉及不到,是以一个 img64(没听懂)的字符串传入的,这个后面再说。
步骤:controller 层
- TODO 验证BO中的用户名和密码不为空
1. base64不为空,则代表人脸入库,否则需要用户输入密码和确认密码
2. 密码不为空,则必须判断两次输入一致
3. 校验用户名唯一 (上部分的逻辑,直接到用单独写的那个方法)
4. 调用 service 存入admin信息
@Overridepublic GraceJSONResult addNewAdmin(NewAdminBO newAdminBO,HttpServletRequest request,HttpServletResponse response) {// 0. TODO 验证BO中的用户名和密码不为空// 1. base64不为空,则代表人脸入库,否则需要用户输入密码和确认密码if (StringUtils.isBlank(newAdminBO.getImg64())) {if (StringUtils.isBlank(newAdminBO.getPassword()) ||StringUtils.isBlank(newAdminBO.getConfirmPassword())) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_PASSWORD_NULL_ERROR);}}// 2. 密码不为空,则必须判断两次输入一致if (StringUtils.isNotBlank(newAdminBO.getPassword())) {if (!newAdminBO.getPassword().equalsIgnoreCase(newAdminBO.getConfirmPassword())) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_PASSWORD_ERROR);}}// 3. 校验用户名唯一 (上部分的逻辑,直接到用单独写的那个方法)checkAdminExist(newAdminBO.getUsername());// 4. 调用 service 存入admin信息adminUserService.createAdminUser(newAdminBO); //代码在下边return GraceJSONResult.ok();}
步骤:service 层
①(sid主键生成啥的??==>嘶,是不是之前讲过分布式系统中的全局唯一ID那讲的???)
② 密码这里需要判空,不空时才加入
(?不是那啥,前面,难道没有判空吗?你这写了密码判空,那我前面还需要密码判空吗?)
如果密码不为空,则需要加密密码,存入数据库
③ 设置faceID,前端提交信息的时候其实还有人脸信息的,不为空时需要设置这个,后面详细说.
如果人脸上传以后,则有faceId,需要和admin信息关联存储入库
④ 设置时间
@Transactional //别忘了加“事务注解”@Overridepublic void createAdminUser(NewAdminBO newAdminBO) {//①(sid主键生成啥的??==>嘶,是不是之前讲过分布式系统中的全局唯一ID那讲的???)String adminId = sid.nextShort();AdminUser adminUser = new AdminUser();adminUser.setId(adminId);adminUser.setUsername(newAdminBO.getUsername());adminUser.setAdminName(newAdminBO.getAdminName());//② 密码这里需要判空,不空时才加入//(?不是那啥,前面,难道没有判空吗?你这写了密码判空,那我前面还需要密码判空吗?)// 如果密码不为空,则需要加密密码,存入数据库if (StringUtils.isNotBlank(newAdminBO.getPassword())) {String pwd = BCrypt.hashpw(newAdminBO.getPassword(), BCrypt.gensalt());adminUser.setPassword(pwd);}//③ 设置faceID,前端提交信息的时候其实还有人脸信息的,不为空时需要设置这个,后面详细说.// 如果人脸上传以后,则有faceId,需要和admin信息关联存储入库if (StringUtils.isNotBlank(newAdminBO.getFaceId())) {adminUser.setFaceId(newAdminBO.getFaceId());}//④ 设置时间adminUser.setCreatedTime(new Date());adminUser.setUpdatedTime(new Date());//返回int result = adminUserMapper.insert(adminUser);if (result != 1) {GraceException.display(ResponseStatusEnum.ADMIN_CREATE_ERROR);}}
讨论:为什么这里不能直接存入 人脸信息?
用户人脸信息为什么不存入数据库,要存入mogoDB?
这个 base64 字符串太长了,存到数据库不适合,会放到 gridFS 去(这啥?).
也不能存入OSS,不然会公网暴露URL(???).
==>需要“私有读”,gridFS这方面好一些
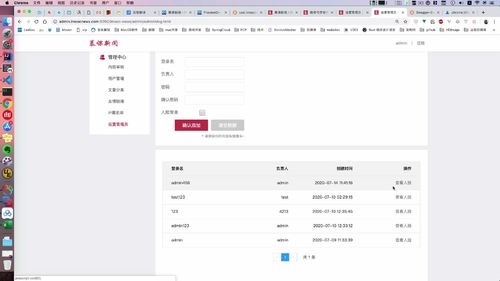
管理员 账户列表(使用分页插件,计算分页所需数据)
本节做【查询admin列表】。页面下方有个列表:我们发现还需要分页
controller 传入:页码 + 每页的数量
@Override// 涉及到分页,传入“第几页” “每一页要显示的数量”.public GraceJSONResult getAdminList(Integer page, Integer pageSize) {// 首先判断一下这俩形参,因为这俩是“非必填选项”,所以空的时候,来一波默认赋值.if (page == null) {page = COMMON_START_PAGE;//常数,因此我们把这俩抽离出来放到 baseControlller中}if (pageSize == null) {pageSize = COMMON_PAGE_SIZE;}PagedGridResult result = adminUserService.queryAdminList(page, pageSize);return GraceJSONResult.ok(result);}
工具方法 setterPagedGrid 封装分页数据,使用插件,返回 PagedGridResult
前端这里分页组件,需要后端提供数据,计算这回才在这显示这些数字链接供我们点击。如当前第几页,查询了多少条记录。这些功能都要封装,然后返回给前端,让前端进行相应的渲染:列表和分页组件效果.
Service 层封装分页数据,这里写一个统一的方法,因为后面不仅仅是这里使用分页的方法。
其中这个rows,就是我们查询出来的数据,与在 controller 中调用 service 返回的查询结果 list 是匹配的。
// 形参这个List就是对应我们从service层查询返回的结果,为了通用性这里使用泛型.public PagedGridResult setterPagedGrid(List<?> list,Integer page) {//PageInfo里面的属性很多,我们用不了那么多. (老师提供的工具类)PageInfo<?> pageList = new PageInfo<>(list); //PageInfo类//PagedGridResult,于下部分.//这里 getPage getTotal 都是插件内部的一些方法,会帮我们计算页码.PagedGridResult gridResult = new PagedGridResult();gridResult.setRows(list);gridResult.setPage(page);gridResult.setRecords(pageList.getTotal()); // getTotalgridResult.setTotal(pageList.getPages()); // getPagereturn gridResult;}
/*** @Title: PagedGridResult.java* @Package com.imooc.utils* @Description: 用来返回分页Grid的数据格式* Copyright: Copyright (c) 2019*/public class PagedGridResult {private int page; // 当前页数private long total; // 总页数private long records; // 总记录数private List<?> rows; // 每行显示的内容...get/set...}
AdminUserServiceImpl 调用 工具方法,进行分页查询
相比于之前,我们这没啥查询条件,所以 criteria 这个条件介质我们就不要了。
针对 example 可以增加一个额外属性:ordeby 这个可以根据某一个属性进行排序。这里就用创建时间了.
这个返回了一个List,这是查询分页.
@Overridepublic PagedGridResult queryAdminList(Integer page, Integer pageSize) {Example adminExample = new Example(AdminUser.class);adminExample.orderBy("createdTime").desc(); //用创建时间排序PageHelper.startPage(page, pageSize); //使用分页工具:PageHelperList<AdminUser> adminUserList =adminUserMapper.selectByExample(adminExample); //返回查询分页.return setterPagedGrid(adminUserList, page); //上部分封装好的方法.}
//接口如下@ApiOperation(value = "查询admin列表", notes = "查询admin列表", httpMethod = "POST")@PostMapping("/getAdminList")public GraceJSONResult getAdminList(//这里使用了swagger2的注解对两个形参进行解释。这里required表示是否必要,true就表示必要@ApiParam(name = "page", value = "查询下一页的第几页", required = false)@RequestParam Integer page,@ApiParam(name = "pageSize", value = "分页查询每一页显示的条数", required = false)@RequestParam Integer pageSize);
管理员 账号登出
会话 和 cookie 删掉即可.
(1)redis中删除会话token
(2)coolie中删除admin登陆信息
⭐人脸登录【远程调用,人脸入库属于 file 模块】
流程图
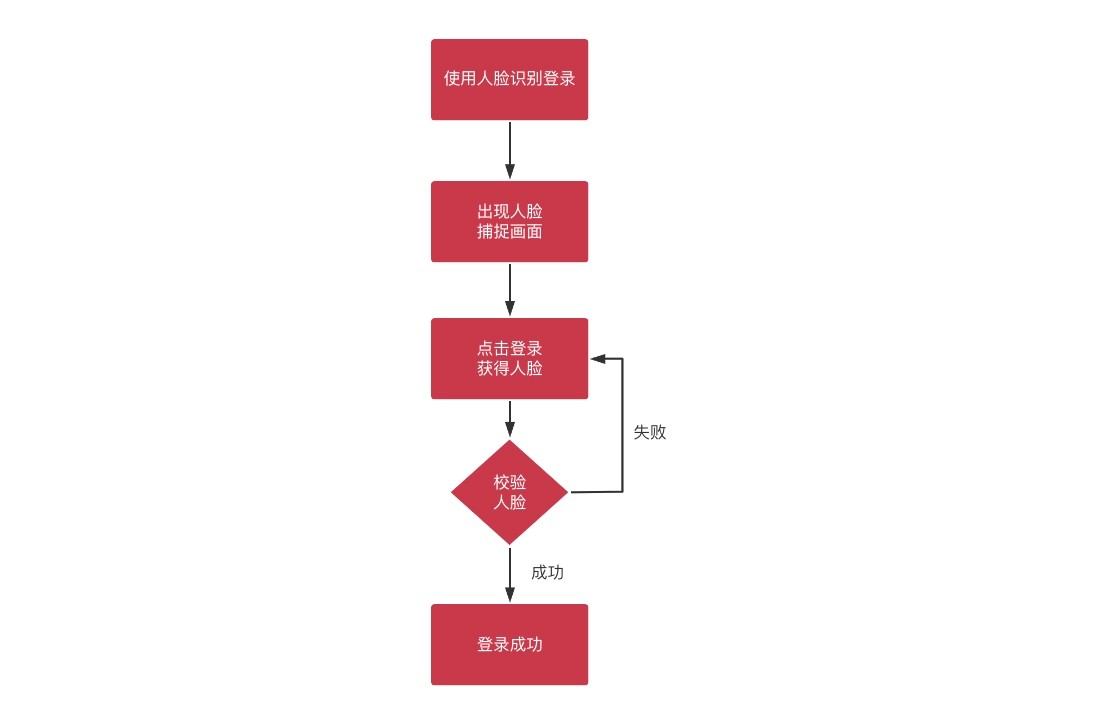
阿里人脸识别
人脸识别一般都可以借助第三方来实现,比如阿里只能AI/百度AI/腾讯云AI等来进行实现。
如下是阿里AI的相关资料,可以打开进行参考,内容介绍也是分详细。并且他也提供了很详细的api代码进行直接的对接。
- 人脸识别 Face Recognition: https://www.aliyun.com/product/bigdata/product/face
- 介绍:https://help.aliyun.com/document_detail/146428.html
- api:https://help.aliyun.com/knowledge_detail/53535.html
- api示例:https://help.aliyun.com/document_detail/67818.html
- 演示端:https://data.aliyun.com/ai?spm=a2c0j.14094218.813079.11.16022fd5Ii0wRk#/face-detect
完整代码
编码还是跟着页面走.
图片1:点击人脸识别登陆,拿到 faceId,然后就可以调用文件服务,把对应数据从 mongodb 中拿出来,并且转换成base64
图片2:下图左(没搞懂),人脸提交过去进行对比
注意,这里不是在 admin 工程中直接搜索人脸信息,我们是微服务,文件相关的业务都放到 file 工程中去,admin 这里远程调用 file 的方法即可。服务之间要保证边界的存在.
@Override//形参 BO 就包含了 img64 这个属性;public GraceJSONResult adminFaceLogin(AdminLoginBO adminLoginBO,HttpServletRequest request,HttpServletResponse response) {// 0. 判断用户名和人脸信息不能为空if (StringUtils.isBlank(adminLoginBO.getUsername())) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_USERNAME_NULL_ERROR);}String tempFace64 = adminLoginBO.getImg64(); //【拿到前端收集的 faceId】if (StringUtils.isBlank(tempFace64)) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_FACE_NULL_ERROR);}// 1. 从数据库中查询出faceIdAdminUser admin = adminUserService.queryAdminByUsername(adminLoginBO.getUsername());String adminFaceId = admin.getFaceId();if (StringUtils.isBlank(adminFaceId)) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_FACE_LOGIN_ERROR);}// 2. 请求文件服务,获得人脸数据的base64数据//远程调用的 url 拼接String fileServerUrlExecute= "http://files.imoocnews.com:8004/fs/readFace64InGridFS?faceId=" + adminFaceId;//这个就是 远程调用 方法ResponseEntity<GraceJSONResult> responseEntity= restTemplate.getForEntity(fileServerUrlExecute, GraceJSONResult.class);//拿到返回的对象,就可以调用 getBody 返回了.GraceJSONResult bodyResult = responseEntity.getBody();//最后需要将 getData 得到的 object 类型强转成 String 类型.String base64DB = (String)bodyResult.getData(); //【拿到后端存储的 faceId】// 3. 调用阿里ai进行人脸对比识别,判断可信度,从而实现人脸登录boolean result = faceVerifyUtils.faceVerify(FaceVerifyType.BASE64.type,tempFace64, //1 中拿到了 前端收集的 faceIdbase64DB, //2 中拿到了 后端存储的 faceId60);if (!result) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_FACE_LOGIN_ERROR);}// 4. admin登录后的数据设置,redis与cookiedoLoginSettings(admin, request, response);return GraceJSONResult.ok();}
第 0 步:用户名 / 人脸信息 不能为空(密码没关系)
第 1 步:admin服务中,获得 faceId
根据用户名,从 mysql 查到admin对象.
通过admin对象拿到 faceId。
// 1. 从数据库中查询出faceId//根据用户名,从 mysql 查到admin对象AdminUser admin = adminUserService.queryAdminByUsername(adminLoginBO.getUsername());//通过admin对象拿到 faceIdString adminFaceId = admin.getFaceId();//判断 faceId 是否存在if (StringUtils.isBlank(adminFaceId)) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_FACE_LOGIN_ERROR);}
第 X 步:file 模块中,调用“查看人脸”方法,请求文件服务,获得人脸数据的 base64 数据
@Overridepublic GraceJSONResult readFace64InGridFS(String faceId,HttpServletRequest request,HttpServletResponse response)throws Exception {// 0. 获得 gridfs 中人脸文件//readGridFSByFaceIdFile myface = readGridFSByFaceId(faceId);// 1. 转换人脸为 base64String base64Face = FileUtils.fileToBase64(myface);return GraceJSONResult.ok(base64Face);}
第 2 步:admin 模块 远程调用 file 模块的 人脸查询 方法,通过 restTemplate 的方法
第 3 步:调用阿里ai API进行人脸对比,判断可信度,实现人脸登陆
第 4 步:admin登陆后的数据设置,redis和cookie
(好像,没专门设置 cookie 和 redis 啥的吧….)
// 4. admin登录后的数据设置,redis与cookiedoLoginSettings(admin, request, response);
管理文章分类
文章分类/领域(admin管理,发文章时要选,网页上端一直显示)
【user 端】与 admin 的解耦, [发布文章时的分类选择] + [首页高频显示],内容基本不变 ==> 放入redis.
了解业务:文章分类功能
我们看看当前页面,最底下:【文章领域/分类】。我们现在需要 “显示出相应的文章分类,提供给用户进行选择”
这个功能不止再发文章最底下能看,在首页也能看到文章分类。
这个地方的显示特点:用户高频访问,但是内容基本不变 ==> 放入redis.
回顾 admin 管理员模块中的 文章分类功能
§ 5.5 文章分类管理 中,写过两个方法,属于 admin 管理员模块的。
getCatList() 方法:查询分类列表,这个主要就是给 admin 对接。这里我们需要 “额外写一个接口,提供给用户端”==>用户 和 管理员这里解耦
@Api(value = "文章分类维护", tags = {"文章分类维护controller"})@RequestMapping("categoryMng")public interface CategoryMngControllerApi {@PostMapping("saveOrUpdateCategory")@ApiOperation(value = "新增或修改分类", notes = "新增或修改分类", httpMethod = "POST")public GraceJSONResult saveOrUpdateCategory(@RequestBody @Valid SaveCategoryBO newCategoryBO,BindingResult result);@PostMapping("getCatList")@ApiOperation(value = "查询分类列表", notes = "查询分类列表", httpMethod = "POST")public GraceJSONResult getCatList();}
1(用户端发文章时)文章分类查询功能(与admin的方法实现解耦)
如下,补充API接口第三个方法。注意请求是GET类型。
@Api(value = "文章分类维护", tags = {"文章分类维护controller"})@RequestMapping("categoryMng")public interface CategoryMngControllerApi {@PostMapping("saveOrUpdateCategory")@ApiOperation(value = "新增或修改分类", notes = "新增或修改分类", httpMethod = "POST")public GraceJSONResult saveOrUpdateCategory(@RequestBody @Valid SaveCategoryBO newCategoryBO,BindingResult result);@PostMapping("getCatList")@ApiOperation(value = "查询分类列表", notes = "查询分类列表", httpMethod = "POST")public GraceJSONResult getCatList();// 新增@GetMapping("getCats")@ApiOperation(value = "用户端查询分类列表", notes = "用户端查询分类列表", httpMethod = "GET")public GraceJSONResult getCats();}
然后去 CategoryMngController 中实现这个接口:
如图中,getCatList(admin中用)和getCats(面向用户)代码几乎一样,为什么分开写(解耦)?区别在哪里?
代码角度看是一样的,但是只当前业务场景下一样;同时,其路由是不一样的,说明服务于不同的业务。
如下图:主要是这两个方法属于“两个不同的模块”,为了方便模块化,或者将来的扩展性,这里最好拆分出来!
(这块讲的其实挺详细的,有需要可以再过来听听)
2 (辨析)[ admin的获得分类列表 ] 和 [ 用户获得分类列表 ] 为啥是两个接口?
- 从代码角度来看,两个接口内容完全一样,但是为啥不合并呢?因为主要会从业务角度来看,两个接口是在不同的系统里了,虽然我们在同一个微服务,但是如果说系统再一次的拆分,把当前微服务拆了2个,那么这个接口就不好归类了,并且 admin 和用户端业务不同,考虑到未来的扩展性也会拆分,耦合度越大,那么当代码量越来越多的时候就越难维护。如果以后增加 is_delete 字段,那么两个业务功能的查询肯定都是不一样的,一个是全部,一个是只查未删除的。
- 如果是这个接口都是在同一个业务中调用的,比如都是在用户端调用,那么公用一个接口则是没有问题的。
- 此外,admin端查询直接查数据库更有效,而用户端并发更高直接查缓存更好。
- 还有一点就是由于前后端分离的部署,接口的改定必定影响前端,所以如果初期定义好解耦的接口,那么后续修改的时候只需要修改后端,而前端则不需要做改动,这样影响的面积更少。
3 (优化)更新文章分类后,用户首页访问时 文章分类 的显示:不要从redis读出来改了,直接删了,下次读取时再去mysql中加载
【admin 端】 维护数据缓存:补充 admin 管理员对于文章分类的 “增加 和 删除” 功能
上节课做的就是 文章分类的展示,使用了redis,但只是查询。后面必然会涉及 “增加 和 删除”.
看看之前的作业:新增和修改都已经写好了。但是“redis”那块还没有这个功能!应该和这边对接一下。
不建议如下做法:不要从redis读出来改了,直接删了,下次读取时再去mysql中加载.
1. 查询 redis 中的 categoryList
2. 转化 categoryList 为 list 类型
3. 在 categoryList 中 add 一个当前的 category
4. 再次转换 categoryList 为 json,并存入 redis 中
推荐做法:【直接把redis中的文章分类删掉(仅1行代码)】即可,那么当其他地方有需要的时候,会根据我们我上节课的逻辑:redis中没数据时,直接从数据库读取数据,并存入redis中,从而达到更新redis的效果。
@Transactional@Overridepublic void createCategory(Category category) {// 分类不会很多,所以id不需要自增;// 这个表的数据也不会多到几万甚至分表,数据都会集中在一起int result = categoryMapper.insert(category);if (result != 1) {GraceException.display(ResponseStatusEnum.SYSTEM_OPERATION_ERROR);}// 直接使用redis删除缓存即可// 用户端在查询的时候会直接查库,再把最新的数据放入到缓存中redis.del(REDIS_ALL_CATEGORY);}
管理 友情链接(MongoDB 处理)
目前管理员模块已经完成,现在呢,我们看左侧列表:我们从下往上去做.
黑名单先不做.
友情链接用 mongodb 做 ————- 再次介绍使用场景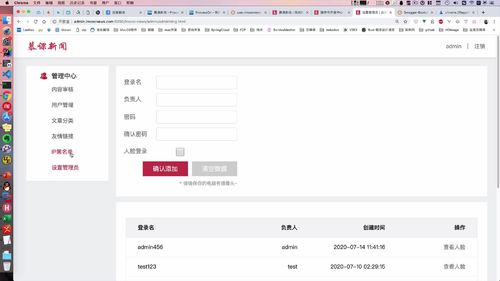
MongoDB 使用场景

① GridFS 用来存储一些隐私小文件:人脸 ,身份证这种以也可以.
② 历史数据快照:例如,你在商城买了一个东西100元,没给钱,明天涨价到150,你的订单里的数据不会涨价到150,该商品数据不会随着商户的更改而更改,这就是快照数据,此时订单里的这个就是一个快照。而快照数据对于每个用户来说有很多,所以往往把他们剥离出来放到MongoDB中去,我们就不存在MYSQL中了。
③ 用户浏览记录:用户在电商系统会浏览很多商品,那么如果存到数据库,那么该张表的数据就是指数级增长了,mysql 压力相当大,所以可以剥离放入到mongodb中。
④ 客服聊天记录:虽然我们对外称聊天记录不存保存,但是我们还是会存储一下,而聊天记录都是非关键数据,哪怕没有也无所谓,所以完全可以放到mongodb中去。
==> 后面三个,本身也是“非必要数据”,为数据库分担了大数据量的存储压力
Q:能不能把这些数据都存 redis 中呢?
A:不行,Redis是持久化的,存储到内存的,都存到 redis 成本顶不住,内存太贵了。如果你们公司老板土豪,可以无限购买内存的话,无所谓。但是需要考虑内存成本的时候,这就需要使用 mongodb 了。所以说,Redis主要用来分摊读压力,提供缓存机制。而 MongoDB为数据库分摊大数据量的存储压力,此外这些都是非核心业务数据,哪怕全部丢失了,也无所谓,不会造成整个系统崩溃。
==> 存在Redis中行吗?Redis是持久化的,存储到内存的,都存到 redis 成本顶不住,内存太贵了.
友情链接保存与更新:Controller 层 —— 保存 BO 到 MO(Service 层下部分处理)
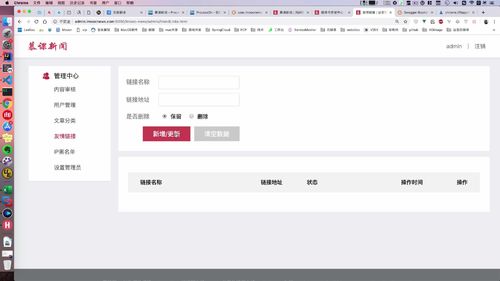
友情页面如上图
(1)新增和修改:[ 无id,新增;有id,修改. ]
同时也是表单页面,需要把这些放到 BO 里面去
(2)是否删除(说是“逻辑删除”,没懂啥意思)
(3)下面那个查询列表先不管.
创建 friendBO
方法中用到的 friendBO 老师写好的,直接导入即可.
① id 作为我们判断“更新/增加”等的依据.
② BO中属性的 自定义校验注解:关于url的校验
linkurl 上面 checkurl 注解是用来校验其url格式是否正确的。也属于工具类。
(老师自己写的还是导入的?看包名好像是导入的)
(好像 有个 urlUtil 需要自己导入一下.)
(这里点了很多层看这个注解底层啥的,最后还是通过正则表达式判断的)
==> 没有这个注解的话,只能去 controller 层进行校验了(因为BO是前端搞过来的,直接接触的就是BO层)!
有了这个注解以后,就可以精简代码!
public class SaveFriendLinkBO {private String id;@NotBlank(message = "友情链接名不能为空")private String linkName;@NotBlank(message = "友情链接地址不能为空")@CheckUrl //@CheckUrl 用来校验其url格式是否正确的。也属于工具类private String linkUrl;@NotNull(message = "请选择保留或删除")private Integer isDelete;...set/get......}
(4)作业,参考(3),写一个@Name来校验用户名
要求:not blank 无空格 + not empty 非空 + length 6-12
去理解一下自定义注解的使用方式(操,其实还是不太懂,得专门去复习注解的知识)
补充MO交互对象(为了保存BO信息)
数据库中没有 友情链接 的内容,友情链接应该保存到 mongodb 中去。和持久层做交互,需要有对应的持久层对象。命名上,与 mongodb 交互的对象我们一般都命名为 *MO。
现在:和 DB 交互的映射对象叫 BO ,和 mogodb 交互的叫 MO .
① 去 model 工程中的pojo中创建一个新的包:mo。
② id 前加 @id 代表其是 Mongodb中 的主键**。注解选择 springframework 包下的,而非 javax下的.
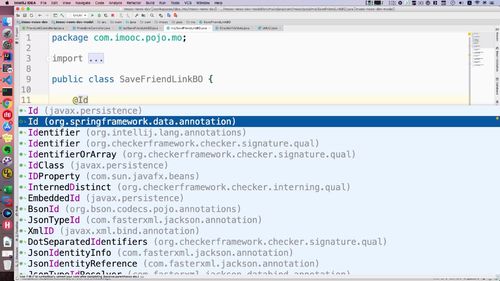
③ 对于 linkname,需要 @field 注解,配置后使用
实际上mongodb中对应字段是link_name,所以需要 @field 注解帮我们进行处理。这个注解注入mogodb相关配置以后才能使用,去搞一搞。打开model里面的配置文件,如下:属于一个spirngboot和Mongodb的整合包:
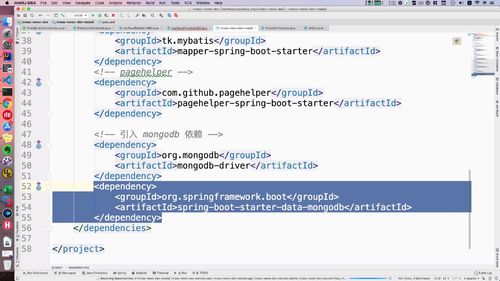
这个时候就可以添加 field 注解了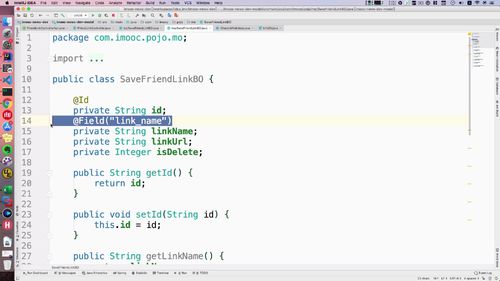
不想加这个也米有关系:表中属性名“驼峰式命名”即可.
④ 增加创建时间和更新时间
⑤ 类名别忘了改成MO的
controller: BO属性拷贝到MO中
保存BO信息2:BO属性拷贝到MO中
( 注意,这里回去把接口形参和方法形参都改成 saveFriendLinkBO )
至此,controller 中基本的设置都没啥问题了.
只不过,“ 保存到mongodb的操作 ”还没有写.
下节课讲解“mongodb”持久层操作!
代码
@Overridepublic GraceJSONResult saveOrUpdateFriendLink(@Valid SaveFriendLinkBO saveFriendLinkBO,BindingResult result) {//1 校验 result,判断 BindingResult 是否保存错误的验证信息if (result.hasErrors()) {Map<String, String> map = getErrors(result);return GraceJSONResult.errorMap(map);}// saveFriendLinkBO -> ***MO//2 BO属性拷贝到MO中FriendLinkMO saveFriendLinkMO = new FriendLinkMO();BeanUtils.copyProperties(saveFriendLinkBO, saveFriendLinkMO); //BO拷贝至MOsaveFriendLinkMO.setCreateTime(new Date()); //创建时间saveFriendLinkMO.setUpdateTime(new Date());//3 存入 MongoDB(具体下部分处理)friendLinkService.saveOrUpdateFriendLink(saveFriendLinkMO);return GraceJSONResult.ok();}
友情链接保存与更新:Service 层 —— MO 到 MongoDB(MO 信息来自前端传来的 BO)
上节课,把 前端表单 填入并提交 到 后端 的 BO 信息,存入了MO.
本节课补充进一步的存储操作:完成与持久层的交互,把 MO 信息存入mongodb
友情链接列表查询
之前做的是更新和插入,这里做列表.
友情链接也不会放很多,不需要进行分页
友情链接删除(感觉不是很重要???)
(删除mongodb中的数据也非常简单,因为内置api已经继承了,直接调用接口)
开始讲列表中后面那个删除,这个删除才是真正的删除,上面那个只是“逻辑删除”(??逻辑删除??)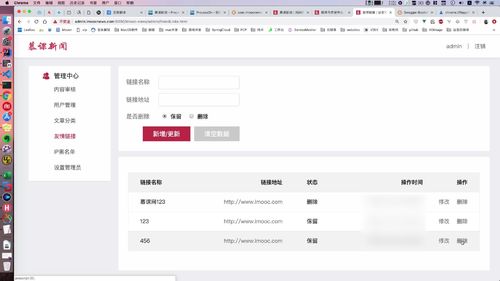
这个地方有两个删除:一个是上面的逻辑删除,一个是下面列表中的删除.
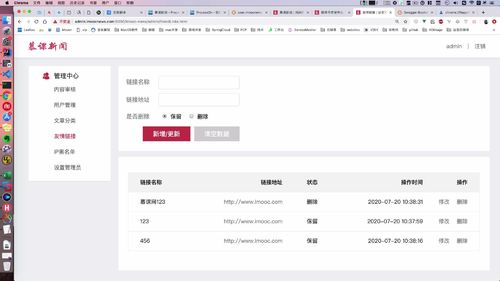
首页展示1: 展示友情链接(根据 MongoDB 字段查询 友情链接)
Mapper 层交互方法:根据 MO 的某一个字段进行查询,我们选择isDelete
friendlink 相关的我们写在了 admin 模块.
现在要 “根据其中的一个字段进行查询”:根据 MO 的某一个字段进行查询,我们选择isDelete
(每块没太懂)这里这个方式和 JPA(这啥啊?)的方式一样,mogodb数据层交互有一些自定义封装规则.
file 模块
用户:保存用户头像(阿里云 OSS)
管理员账信息:人脸入库,存入 MongoDB
流程图
Chrome开启视频调试模式
步骤:实现人脸存入MongoDB 【GridFS】
人脸入库,我们会把用户的人脸信息保存到 gridfs 中,当然如果使用oss或者fastdfs也可以,只不过gridfs可以控制在内部访问,其他的相对不是很方便,而且做好内部资源和外部资源的解耦也是一种不错的选型。(???不是很懂,什么内部资源外部资源的???)
接下来,我们就需要去实现我们写的 api 中的文件上传至 GridFS 的方法了。前端拿到 文件ID 以后,会在下次提交时把这个 id 提交到后端,这样的话,【mongodb 就和 Mysql 建立了关联】.
思考:mysql 和 mongodb 怎么建立联系的 ???
==> 注意,mongodb 只存了 用户文件 的 fileId 和 头像 img64,所以注定了若想查询这里的数据,都必须是根据用户 id,去 mysql 中拿到 fileId,然后用 fileId 去 MongoDB 中查询头像.
步骤:
① 通过 BO 获得 base64 的字符串
② 通过 decodeBuffer 把这个字符串转成 byte 数组,中间使用 trim 去除两边的空格
③ byte[] 就可以转成输入流
④ 上传成功以后,我们通过 fileId 拿到其再 gridfs 中的 id,这个就可以返回给前端了。
上传到gridfs中,需要注入 gridFSBucket 这个类,获得文件在 gridfs 中的主键 fileId
@Overridepublic GraceJSONResult uploadToGridFS(NewAdminBO newAdminBO)throws Exception {// ① 通过 bo 获得 base64 的字符串String file64 = newAdminBO.getImg64();// ② 通过decodeBuffer把这个字符串转成byte数组,中间使用trim去除两边的空格byte[] bytes = new BASE64Decoder().decodeBuffer(file64.trim());// ③ byte[] 就可以转成输入流ByteArrayInputStream inputStream = new ByteArrayInputStream(bytes);// ④ 上传成功以后,我们通过 fileId 拿到其再 gridfs 中的 id,这个就可以返回给前端了。// 上传到gridfs中,需要注入 gridFSBucket 这个类.ObjectId fileId =gridFSBucket.uploadFromStream(newAdminBO.getUsername() + ".png", inputStream);// 获得文件在 gridfs 中的主键 fileIdString fileIdStr = fileId.toString();return GraceJSONResult.ok(fileIdStr);}
管理员列表:查看人脸【被远程调用:人脸登陆】
分析:需要建立起 mysql 的 id 和 mongodb 的 faceId 的联系
我们点击人脸,有一个参数的传递,点击的时候拿到了数据库的【 admin表 的 faceId】 ,传给后端。后端接收到这个id,我们【去 mongodb 获得这个文件】,然后传给前端输出即可.(和咱之前分析的逻辑一致)
从 mongoDB 获得文件,保存一个temp文件,然后下载到本地:readGridFSByFaceId
(1)(2)
mongodb中,ID 才是主键,实际上调用时候得用 _id;
拿到 文件 以及 文件名 就可以输出了,我们其实可以把当前这个文件在服务器上进行保存,然后写到临时目录(???什么现在本地,linux的话就临时目录啥的???),然后可以通过 response 展现给前端。所以,file 这里我们就把目录写死了;可以判断一下这个目录有没有,如果没有的话就创建这个目录.
==> 我们一般做法都会在机子上留存temp文件,方便排查问题。定时删除就行的哈。
return 的是个 file,这个 file 在 new 的时候制定了 “文件路径” + “fileName”,这样的话,直接能跟着这个找到我们存储的文件了?是这个意思吗??
//【核心】查询的时候就和 数据库传过来的 faceId 进行匹配.private File readGridFSByFaceId(String faceId) throws Exception {//(1)这里调用 mongodb 包里面的 filters 类进行过滤查询,这个就是和mongodb里机制一样.GridFSFindIterable gridFSFiles= gridFSBucket.find(Filters.eq("_id", new ObjectId(faceId)));//(2)通过first文件保证得到第一个,返回一个文件类;GridFSFile gridFS = gridFSFiles.first();//(3) 再判空一下,不空时,拿到文件.if (gridFS == null) {GraceException.display(ResponseStatusEnum.FILE_NOT_EXIST_ERROR);}// 我们先或得一下filename,为了方便测试,我们这里先写一个sout;String fileName = gridFS.getFilename();System.out.println(fileName);// (4)获取文件流,保存文件到本地或者服务器的临时目录File fileTemp = new File("/workspace/temp_face");if (!fileTemp.exists()) {fileTemp.mkdirs();}File myFile = new File("/workspace/temp_face/" + fileName);// (5)创建文件输出流OutputStream os = new FileOutputStream(myFile);// (6)下载到服务器或者本地gridFSBucket.downloadToStream(new ObjectId(faceId), os);// (7)return myFile;}
从 gridfs 中读取文件,然后输出给浏览器:readInGridFS
刚才写的方法返回了一个file,接受一下.
然年后把图片输出到浏览器即可,这里需要用到一个工具类:FileUtils。包含了两个方法:下载文件 和 输出成base64。我们用的就是这个下载文件这个方法,这个方法就是把图片搞到了response中。因为需要用到response,我们去api中补充一下形参.
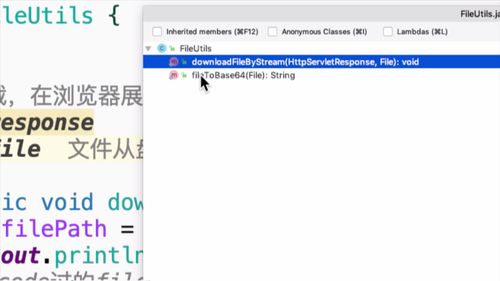
@Overridepublic void readInGridFS(String faceId,HttpServletRequest request,HttpServletResponse response) throws Exception {// 0. 判断参数if (StringUtils.isBlank(faceId) || faceId.equalsIgnoreCase("null")) {GraceException.display(ResponseStatusEnum.FILE_NOT_EXIST_ERROR);}// 1. 从gridfs中读取File adminFace = readGridFSByFaceId(faceId); //该方法见下面// 2. 把人脸图片输出到浏览器FileUtils.downloadFileByStream(response, adminFace);}
疑问:这里说的OSS控制不了是啥意思???之前就对比了GridFS,OSS啥的,区别在哪呢??
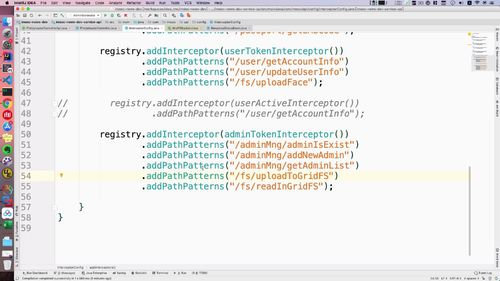
拦截器中补充 本节以及上一节 的路径
此时,我们可以控制 admin 登陆时才能访问到数据.
OSS这种在代码层就控制不了(why???)
article 模块
用户:发头条(存入mysql)
summernote 与 多文件上传需求
【发头条】发表一篇文章,把相应文章给你内容保存到数据库.
一、summernote(开源富文本编辑器)介绍
二、多文件上传功能 介绍
可以上传1张,可以上传多张。
==> 多图上传需要在前端构建成 “ list/数组 ”,然后发送到后端,随后进行相应的处理。
要是发送成功(状态码200),就能得到一个 imageList,然后调用summernote的接口拼接组装这些图片,这些图片会循环插入富文本编辑器中。
(1)实现 富文本编辑器中 多文件上传,存入 OSS
多图上传需要在前端构建成 “ list/数组 ”,然后发送到后端,随后进行相应的处理。
要是发送成功(状态码200),就能得到一个 imageList,然后调用summernote的接口拼接组装这些图片,这些图片会循环插入富文本编辑器中。
主要还是在之前的基础上进行修改,“套了一层循环”。直接在上传头像(用户头像,存入OSS那个;管理员人脸识别存在) 的方法了,我们直接扩展这个方法。声明 list,存储多个图片的保存地址并返回给前端。
@Override//0. 这里形参补充数组,形参名和前端一样是files.public GraceJSONResult uploadSomeFiles(String userId,MultipartFile[] files)throws Exception {// 【补充1】声明 list,存储多个图片的保存地址并返回给前端。List<String> imageUrlList = new ArrayList<>();//写一个循环,之前复制的“头像上传”的代码放到这个循环中去。//(之前的代码只针对1个文件,现在要处理的是一组文件,所以要每个都取出来这么处理一遍)if (files != null && files.length > 0) {for (MultipartFile file : files) {String path = "";if (file != null) {// 获得文件上传的名称String fileName = file.getOriginalFilename();// 判断文件名不能为空if (StringUtils.isNotBlank(fileName)) {String fileNameArr[] = fileName.split("\\.");// 获得后缀String suffix = fileNameArr[fileNameArr.length - 1];// 判断后缀符合我们的预定义规范if (!suffix.equalsIgnoreCase("png") &&!suffix.equalsIgnoreCase("jpg") &&!suffix.equalsIgnoreCase("jpeg")) {continue;}// 执行上传// path = uploaderService.uploadFdfs(file, suffix);path = uploaderService.uploadOSS(file, userId, suffix);//} else {continue;}} else {continue;}String finalPath = "";//【补充4】搞到单个文件的 Path 后,直接放入补充补充 1 的 listif (StringUtils.isNotBlank(path)) {// finalPath = fileResource.getHost() + path;finalPath = fileResource.getOssHost() + path;// FIXME: 放入到imagelist之前,需要对图片做一次审核imageUrlList.add(finalPath);} else {continue;}}}//【补充2】return ok 拿出来,把补充1中的 list 从这里返回给前端return GraceJSONResult.ok(imageUrlList);}
1 确定该业务所在的服务:不放在 article 服务中,而是放在 files 服务中.
2 编写“多文件上传”接口方法:在 “上传头像” 基础上改
3 编写“多文件接口”实现方法
随后进入之前上传头像所在的实现类,把这个多文件上传的接口方法实现一下。方法内容直接复制上传单个头像的,然后进行微调即可。
4 补充拦截器
(2)发布文章,存入 mysql
业务介绍:先完成文章分类部分.
进行本部分前,需要先 文章分类的维护(先完成文章分类部分)。本节课 针对当前页面进行数据的保存。
从页面上也能看出了,这里的内容是封装成表单后提交的,那么后端可以使用 BO 去接受数据,并验证,然后就可以入库了。
建 BO,接收前端表单
categoryId (文章领域)这个必须填!如果填入的值和后端不一致,需要专门处理。这一块我们放到 controller 中去验证。
articleType 是封面类型,可以是文件,可以是图片。
publishUserId不能为空,这是登陆状态。
/*** 用户发文的BO*/public class NewArticleBO {@NotBlank(message = "文章标题不能为空")@Length(max = 30, message = "文章标题长度不能超过30")private String title;@NotBlank(message = "文章内容不能为空")@Length(max = 9999, message = "文章内容长度不能超过10000")private String content;@NotNull(message = "请选择文章领域")private Integer categoryId;@NotNull(message = "请选择正确的文章封面类型")@Min(value = 1, message = "请选择正确的文章封面类型")@Max(value = 2, message = "请选择正确的文章封面类型")private Integer articleType;private String articleCover;@NotNull(message = "文章发布类型不正确")@Min(value = 0, message = "文章发布类型不正确")@Max(value = 1, message = "文章发布类型不正确")private Integer isAppoint;@JsonFormat(timezone = "GMT+8", pattern = "yyyy-MM-dd HH:mm:ss") // 前端日期字符串传到后端后,转换为Date类型private Date publishTime;@NotBlank(message = "用户未登录")private String publishUserId;...}
Controller:判断BO,验证 categoryId(直接在 redis 中查询),然后入库
(1)BO校验
“死部分”:这个和之前内容一样(没看清从哪个方法copy过来的);
“活部分”:articleType,封面类型.
如果是图片类型,articleCover必须有.(如下图)
逻辑如下(34行开始);纯文字的话,直接设置为空即可。
(2)分类:判断 分类id 是否存在,直接在 redis 中查询
这里 list 装的是“文章类别吧”,所以才需要循环判断,匹配到就停下 .
(3)调用 service,入库
用户:预览文章(不经过后端,保存到 sessionStorage)
预览没有经过后端,有两种方式可以去做:
①保存到数据库(扩展性更好,视频中说的比较详细,有需要可以再听)
② 保存到sessionStorage。
⭐发文章补充:定时发布文章
构建定时任务
本节专门处理一下 定时发布 的问题。
@Configuration // 1. 标记配置类注入容器@EnableScheduling // 2. 开启定时任务public class TaskPublishArticle {@Autowiredprivate ArticleService articleService;//3. 添加定时任务@Scheduled(cron = "0/10 * * * * ?") // 4. 定时任务表达式private void publishArticle() {// 4 修改文章定时状态改为即时状态articleService.updateAppointToPublish();}}
(1)在 springboot 中做定时的配置
(2)开启定时功能,并把 任务类 需要放入springboot容器中用.
所以 configuration 注解是一定需要的.
通过 enableScheduling 注解开启定时任务。类中添加一个方法,@scheduled用于执行定时任务,这里需要配置一个表达式。测试这个方法,里卖弄sout一下即可。
(3)定时任务表达式
表达式可以使用生成器直接生成
(4)定时发布文章:当前时间 > 发布时间 时发送,同时修改文章定时状态改为即时状态
目前数据库中只有 1 条数据,我们之前设置了定时时间:当前时间 > 发布时间 时,就可以发送了。主要得去把这个状态从 1 改成 0 .
自己编写 sql,不适用生成的 mapper 文件
编写sql语句:(这块有些小细节,后面实操的时候再听听)(小于号得用转移符号<写)
然后就可以去service层调用了.
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" ><mapper namespace="com.imooc.article.mapper.ArticleMapperCustom" ><update id="updateAppointToPublish">UPDATEarticleSETis_appoint = 0WHEREpublish_time <= NOW() //当前时间 > 发布时间andis_appoint = 1 //状态</update></mapper>
目前定时任务存在的问题
定时任务在不停的运行,并且扫描我们的数据库,一直在做全表扫描,数量多了的话,对性能很不好。
因此,后期会使用MQ进行优化!
(老师最后把定时任务的注解注释了,暂时用不到,就别让它运行了)
MQ 优化定时任务
管理员中心:文章列表显示,文章审核
文章列表显示
发文章补充:实现阿里AI自动审核文章,在createArticle方法最后,【应该发起调用,请求检测文章】
目前,在当前用户中心实现了【内容管理 的 列表查询.】【发头条的功能也做好了】.
==> 文章入库后,审核就要介入了!分为“机审”和“人工审核”
1 我们要干什么?——自动审核代码
在createArticle方法最后,【应该发起调用,请求检测文章】
2 注入阿里的AI审核方法,并调用
3 补充修改状态的service方法,完善审核代码
发文章补充:人工审核
审核通过/失败 是一个接口。
审核是在前端进行的,管理员审核后点击 通过/不通过,后端接收到前端的指令,然后 文章状态 进行相应的更新即可.
接受两个参数:文章id,代表通过与否的数值(该形参与前端对应).
⭐首页展示2:文章列表
首页文章列表 1:显示文章列表
普通查询之外,还要携带一些相应的参数:
首先是文章分类的 id,如果有,去对应类别查找;如果没有,那就查询所有.
此外,右上角的这里,输入关键字进行搜索,支持“滚动分页.”.
代码写在article文章服务.
新建 Controller 层 api:新建 门户端 controller 实现解耦,对首页文章列表进行查询
我们重新创建一个api,这样就能解耦了.
@Api(value = "门户站点文章业务controller", tags = {"门户站点文章业务controller"})@RequestMapping("portal/article")public interface ArticlePortalControllerApi {@GetMapping("list")@ApiOperation(value = "首页查询文章列表", notes = "首页查询文章列表", httpMethod = "GET")public GraceJSONResult list(@RequestParam String keyword,@RequestParam Integer category,@RequestParam Integer page,@RequestParam Integer pageSize);}
新建 Service 层:专门针对门户端创建新的service,添加 隐性查询条件
这里的service也需要重新创建,这里的 service 同时涉及“用户中心”“admin中心”的业务.
所以我们专门针对门户端创建新的service.
(1)实现1:添加 隐性查询条件
需要根据发布时间进行排序。增加几个“文章自带隐性查询对象”(去 Article.java 的实体类中找)
(2)实现2:添加 keyword 和 category 查询条件
keyword 关键词吗,有的话模糊查询.
category 分类,没的话查询所有.
(3)实现3:分页查询,并返回
@Servicepublic class ArticlePortalServiceImpl extends BaseService implements ArticlePortalService {@Autowiredprivate ArticleMapper articleMapper;@Overridepublic PagedGridResult queryIndexArticleList(String keyword, Integer category, Integer page, Integer pageSize) {Example articleExample = new Example(Article.class);articleExample.orderBy("publishTime").desc();/*** 自带隐性查询条件:* isPoint为即时发布,表示文章已经直接发布,或者定时任务到点发布* isDelete为未删除,表示文章不能展示已经被删除的* status为审核通过,表示文章经过机审/人审通过*/Example.Criteria criteria = articleExample.createCriteria();criteria.andEqualTo("isAppoint", YesOrNo.NO.type);criteria.andEqualTo("isDelete", YesOrNo.NO.type);criteria.andEqualTo("articleStatus", ArticleReviewStatus.SUCCESS.type);// category 为空则查询全部,不指定分类// keyword 为空则查询全部if (StringUtils.isNotBlank(keyword)) {criteria.andLike("title", "%" + keyword + "%");}if (category != null) {criteria.andEqualTo("categoryId", category);}/*** page: 第几页* pageSize: 每页显示条数*/PageHelper.startPage(page, pageSize);List<Article> list = articleMapper.selectByExample(articleExample);return setterPagedGrid(list, page);}}
⭐首页文章列表 2:文章列表显示发布者需求
业务分析:文章列表中,用户昵称/头像显示不合理,但是“多表联查”不合理,所以还是得“远程调用”
数据库中,发布者数据里有 publish_user_id。如果要显示 头像 和 昵称 的话,一般就是去做 “多表关联”的查询。
上节课只是做了单表数据的查询。其实访问量特别大的话,对于表查询,就尽量减少多表查询,一般限制在3张表以下。
一种做法:我们通过文章查到 发布者id,用这个 id 去查 user表,查到后,我们在 controller 或者 service 曾进行 list合并,把相应的用户信息匹配到 文章列表 中去,让其作为一个对象放入文章列表中,然后再到前端进行对应的渲染。
另一个角度来讲,我们现在有两个系统——user 服务 和 article 服务。我们后期会把这些做成微服务(???)。对于微服务,不同的系统存在边界,各自职责不同,只能查询自己对应的表。从这一角度说,也不应该进行 多表查询!
==> 我们应该发起一个新的远程调用,【在文章服务中请求用户服务】,把从用户服务得到的信息拼接到下图的 PagedGridResult 中去,这样再由前端进行渲染。
因此,最后我们确定方案:【单表查询 + 拼接】
1 从 文章列表 得到 id 列表:使用 set 集合去重
list 可以从这个 gridResult 里面拿出来。重新查询这个 List,得到所有用户 id。
这个时候就有一个问题:首页文章中每一个文章的 id 都要查吗?No,可能有一个人发布的,因此我们这里要做去重!==> 使用 set 集合!从而去重.完成以上步骤的代码如下:我们把这个 idSet 发到 user 服务中去进行查询
...// START/*** FIXME:* 并发查询的时候要减少多表关联查询,尤其首页的文章列表。* 其次,微服务有边界,不同系统各自需要查询各自的表数据* 在这里采用单表查询文章以及用户,然后再业务层(controller或service)拼接,* 而且,文章服务和用户服务是分开的,所以持久层的查询也是在不同的系统进行调用的。* 对于用户来说是无感知的,这也是比较好的一种方式。* 此外,后续结合elasticsearch扩展也是通过业务层拼接方式来做。*/List<Article> list = (List<Article>)gridResult.getRows();// 1. 构建用户id列表Set<String> idSet = new HashSet<>();for (Article a : list) {// System.out.println(a.getPublishUserId());idSet.add(a.getPublishUserId());}// 2. 发起restTemplate请求查询用户列表// 3. 重组文章列表// END...
2 远程调用:回到文章服务,发起 restTemplate 请求查询用户列表
3 List 拼接:构建新的 List,并拼接(文章 + 用户)
进阶上节,已经完成了 远程调用,现在需要拼接两个list了(文章 和 用户)
一个 publishList(用户的),一个 articleList.
为了拼接,我们需要 “构建1个新的对象,能存入这两个List的信息”.
首页展示3:查询热闻
⭐文章详情
文章详情展示
一、本节目标:查询文章详情内容,并在详情页进行展示.
该部分在 ArticlePortalController(文章服务模块)编写.
Controller :传入文章 id ,远程调用后,拼接 redis 查到的数据和文章数据
这个从 redis 查用户的方法,是通过远程调用先拿到了整个用户列表吧,所以是 list。 然后再用文章里的作者 id 去这个表里面查询(至于为什么用set,之前刚封装过后面复习了再看看吧—->保证唯一性)
Service:专门去搞了一个VO类,ArticleDetailVO,就比 article 类多了一个 “用户名” 这样的属性.
专门去搞了一个VO类:ArticleDetailVO。这里就比 article 类多了一个 “用户名” 这样的属性.
Service 实现,这里也需要设置“隐形条件”。
阅读文章 & 阅读量累加:不用 Service了,直接操作redis.
文章首页列表的“阅读量”,阅读时进行数据的累加。(总感觉这个功能,因该放在上一章节)
看看数据库:已经设计 了这个东西。但是呢,和之前一样,这个数据在首页展示,并发很大,所以不放在数据库,放在redis中。所以表这里这个设计就没啥用了。
后面还会有“评论数”,这个也一样会放进redis中。
⭐文章阅读数防刷:通过 request 的 ip + 文章 id 来进行拦截
找到它的api,加上一个request:通过这个得到用户ip,后面就可以根据这个ip进行拦截。
得到ip。根据ip拼接出对应的redis所需的key,以后识别到这个key,那么月的时候就不能累加了(会面改错的时候还得加上文章id,这样才能作对对于每篇文章都防刷)。
redis 的 key 再加上文章 id,这样的话一个 Ip 看不同文章,阅读量是分开计算的。
⭐文章列表:加入 mget 功能,批量 get 优化单次 get
问题在哪里? for 中的 get 是单次调用
使用 redis的 mget 批量查询 优化,替换单个查询.
(1)1中的方式有什么问题?
redis的 get 调用写在了 for 循环中,每次都是“单次调用”,每一次都要“建立连接并且断掉连接”当请求很多时,不断地连接与断开对性能影响很大!
(!!感觉这一块的底层分析很重要啊,面试可能深挖,去了解一下redis请求的连接原理是不是这样的!!)
使用什么优化?——mget,批量读取
使用 get 就是“一来一回”,建立了还要关闭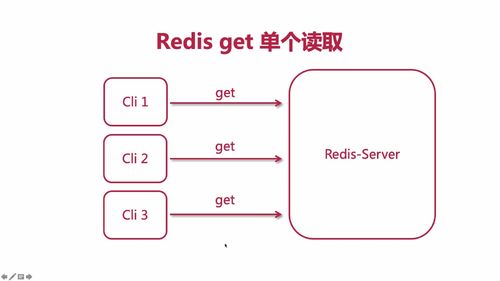
但是呢,这些个get都差不多,所以我们想办法一次都给读取,不用频繁建立连接与断开连接。
==>当key多时,且比较重复,可以用Redis mget 批量读取:我们把请求放在 mget。
加入mget功能,优化代码:redisOperator 里封装了mget方法
之前:一个一个从redis中获取阅读量;
现在:已经从redis中得到了所有,返回了list,从这个list获取阅读量;
文章评论
用户评论入库保存
1 创建评论 Bo 类
2 远程调用,得到评论用户的昵称.
3 评论入库
注入Sid,用这个得到评论主键。
评论数:统计,显示,查询
1 评论数累计与显示(redis中累加,累减)
2 文章评论数 sql 关联查询:评论功能单独设置接口,如果与阅读量一起查的话,耦合度太高
显示评论列表:需要“多表关联”了,因为涉及到不同的用户 id,
fatherId:什么意思?
A评论了B,那么显示B再A中就是红框显示(如下图),B的id就是father_id,之前都理解错了!就是作为一种引用关系,B能在A中显示,表明A是回复B的。
下图中,本业务:A可以评论A,这个允许的。但是如果你的业务不允许,就要去判断了。
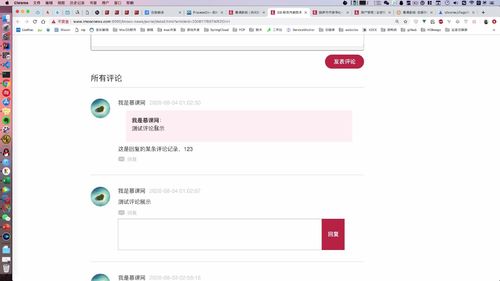
因为 comment 表的 id 是主键,所以这个自关联查询的操作效率也不会太低的。首先从数据库 comment 表中读取id=#{id},然后再从这个数据记录中取出它的 father_id,再从另一张从去寻找有没 有id=这个father_id,另一张表也是走的主键索引遍历,所以速度是很快的。
管理评论列表以及删除评论
作家中心有个 评论管理 :这里可以删除评论.
包含两个业务:【查询评论列表】+【删除评论】
Service实现:查询方法中传入 writerId 就可以查到作者文章里的所有评论.
增加评论者头像展示功能
二、表的介绍
admin_user
app_user
article
category
comments
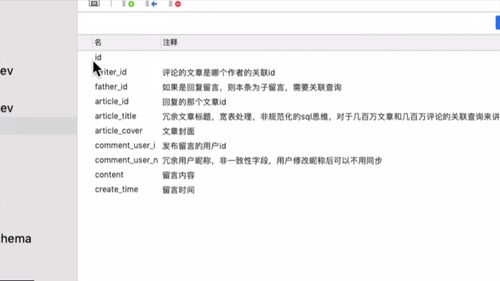
comments就是评论:
点击进入后:表结构如下.
评论主键.
father_id 感觉是 评论回复者的 id?comment_user_id是留言/评论者的id。writer_id是文章作者的id,别搞混了。
文章标题和封面是冗余数据,计算没有也可以用 article id 查询。
用户昵称也是冗余数据,是宽表处理。用户修改昵称你用同步。后面会讲 ES 会涉及“被动更新”。之前也提到过。
fans
1 粉丝表的设计思路:冗余设计 + 保存粉丝的关键性信息
打开数据库,看看fans表: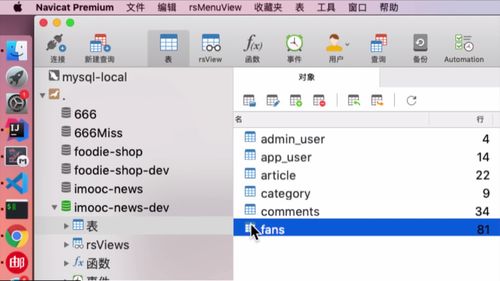
表中,包含了如下数据:
作家 id 和 粉丝 id 都属于用户信息。
至于粉丝的头像,昵称这些,后面进行粉丝画像等数据处理时会涉及到。其实都算是“冗余设计”,也叫“宽表设计”。你不设置这些东西,也可以通过粉丝 id 来查到这些信息,但是呢,这就涉及 多表查询 了,会影响到性能。
==> 因此,我们这里的表的涉及都是为了能够 避免多变查询。这一部分后买你还会使用 ES 来进行优化,都会存入ES中。
比如你想问这里的粉丝信息更新了怎么办?我们使用 “被动查询” 解决这一问题。因为对于被关注者,大部分时候不会去关心粉丝的这些信息,他最关心的是“粉丝量”,“男女比”这种,所以采用被动更新。
==> 因此,我们这里要做的就是保存粉丝的关键性信息而已,其他的后面再说。
三、中间件的业务
Redis
短信验证码,防刷
一件注册登录时,分布式 session
在 Redis 中缓存用户信息 + 用户信息更新时,缓存双删.
admin 登陆时也存
首页文章分类id
粉丝数递增递减
阅读量防刷
MongoDB
MongoDB 介绍
简介
人脸入库需要用到这个。MongoDB 可以存储 JSON。
MongoDB 是非关系型数据库,也就是nosql,存储json数据格式会非常灵活,要比数据库mysql/MariaDB更好,同时也能为 mysql/MariaDB 分摊一部分的流量压力。
对于经常读写的数据他会存入内存,如此一来对于热数据的并发性能是相当高的,从而提升整体的系统效率。另外呢,对于非事务的数据完全可以保存到MongoDB中,这些数据往往也是非核心数据。
一般来说,我们可以把一些非重要数据但是读写却很大的数据存储在MongoDB,比如我们自己的物流运输的车辆运行轨迹,GPS坐标,以及大气监测的一些动态指标等数据。又或者说咱们实战中的友情链接,友情链接在首页,这数据本身不重要,但是在首页里会经常被读到,并发读很大,所以放mongoDB中没毛病。
此外,mongodb 提供的 gridfs 提供小文件存储,可以自己把控接口读取的权限,这一点也是有优势的,比如存储一些身份证信息啊,人脸信息啊都是可以的。

术语
以下是MongoDB和数据库以及ElasticSearch(es没接触过的,待后续整合es后可以回过头来对比看看)的术语对比: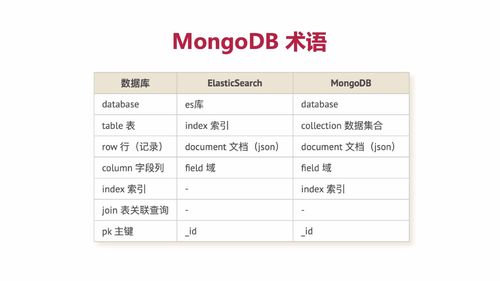
数据结构演示
一个 {} 就是一个大对象 / 一个document / 一个JSON对象.
MongoDB 是 Nosql 数据库,一个 {} 三个结构,另一个可以是四个结构.

- MongoDB可以创建多个数据库(同mysql)
- 一个数据库可以创建多个collection(同mysql创建多表)
- 一个集合可以包含很多文档数据(同mysql一张表包含很多行记录)
我们可以通过如下代码片段来更好的理解MongoDB的数据对比,假设这张表中总记录有3条
UserList: [{userId: "1001",username: "lee",age: 18,sex: "boy"},{userId: "1002",username: "jay",age: 20,sex: "boy"},{userId: "1003",username: "jolin",age: 19,sex: "girl"}]
如上述代码中:
- UserList是一个collection,在mysql中可以当做是一张表
- UserList中的每个{}都是一个json对象,他们称之为document文档,在mysql中称之为行记录
- userId、username、age、sex 这些都是field 域,在MySQL中称之为column列字段
GridFS
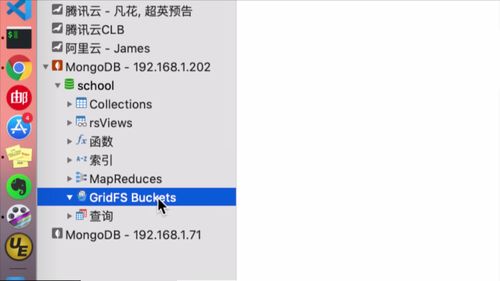
一、介绍
一般软件中,bucket相关的都是和“文件存储”挂钩.
为了实现人脸识别,我们需要用到gridFs Buckets这个模块.
这个也算是一个“对象”,我们需要将其放到spring容器中去,随后才能使用它进行文件的上传,传到 mongodb 中去.
二、整合 SpringBoot
1 定义接口
file 工程中的文件上传 controller 的 api 中:这样的话,前端那里手机号图像,点击确定后,就会触发这里的方法.
==>【其实不仅仅可以上传人脸文件,其他文件都可以通过这个方法上传】!!!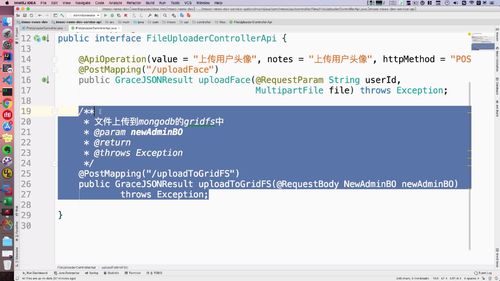
2 引入依赖
…
3 mogodb配置信息
打开当前项目的 yml 文件:
spring的下面加: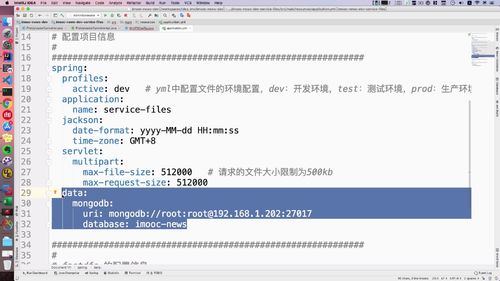
这里数据库这个imooc-news数据库中没有,得先去创建一下.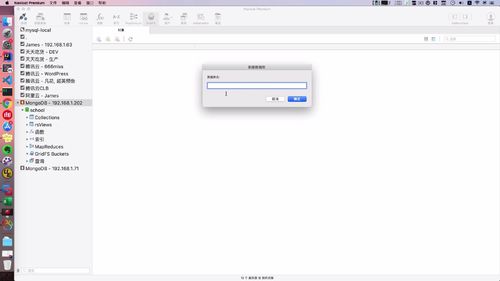
4 编写 GridFS 配置类
file包下搞一个配置类.
str 这个 mongodb 就是获取配置文件中 mongodb 信息的。gridFS Bucket 这个方法就是我们之前引入以后才可以调用的;其他一些没见过的形参基本也都是输入mongodb的依赖的.
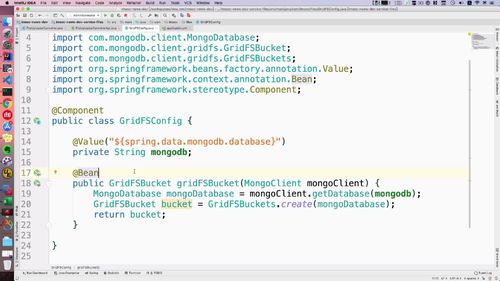
————————
至此,mogodb 和 gridfs 就算是整合到项目中去了.
存储人脸信息,查询人脸信息
友情链接
RabbitMQ
优化定时任务
ES
四、涉及的八股
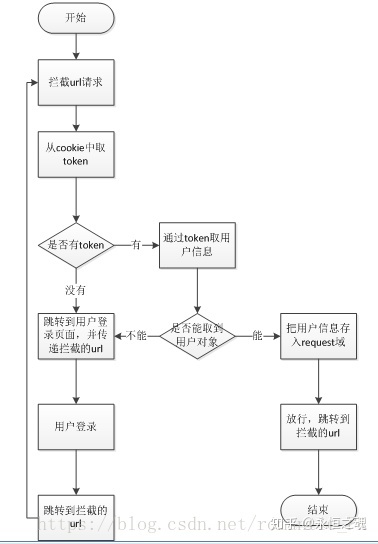
拦截器
【重要】疑问:admin登陆不用redis吗?寸的session、token这些怎么用的?前端处理还是后端处理?
seesion token 不是不维护登陆状态用的?一个网站不用进入一个模块就查数据库,而是直接看token就行?
那查看redis的代码在哪呢?(包括第三章)==>在拦截器中呢,拦截器那里判断redis里若是有数据,对比完了直接放行
那redis没有token代表什么?没登陆?还是得去mysql中获取???
缓存一致性问题 & 缓存双写!
【理论】浏览器缓存介质
1 概述
(1)为什么要对“基本信息”优化?
基本信息在 “很多页面” 都会用到,一个重复的数据,可能会在很多页面重复调用。所以这个 getUserInfo 的接口方法压力其实挺大的.
有没有一种方式降低压力?
==> 因为“基本信息”改动频率很低,所以我们把它【存在服务器上】
(2)一种存储情形
如下,session stroage 存的就是基本信息:<br />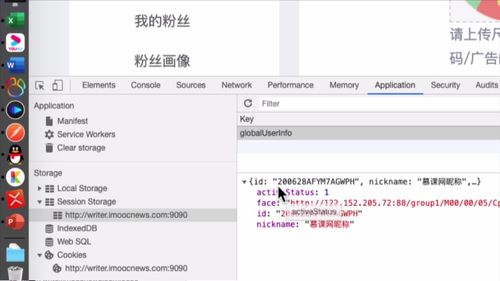<br /> 这一步,代码中也有体现:<br /> (注意看灰框中的注释,存到了“session stroage ”)<br />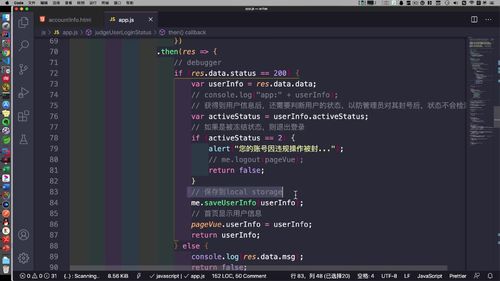
2 浏览器存储介质的几种方式
(1)cookie
浏览器存储介质其实本质上也可以称之为缓存,比如cookie,就是早期我们使用最多的,目前用户的 id 以及 token 也是保存在cookie 理的。<br /> 通过保存数据后,那么可以获得并且和后端服务器交互。<br /> Cookie是保存在浏览器的,如果不设置过期时间,那么cookie会保存到内存,如果浏览器关了,那么cookie就没了,这也起到了会话的作用。如果我们设置了过期时间,那么cookie会保存在硬盘,关闭浏览器cookie还会存在,直到过期,一般7天重新登录或者1个月免登录都是这样的。<br /> cookie 中只能存一些字符串类的内容,对象或list以json字符串去保存,但是需要注意,cookie有大小限制,4k左右,所以一般不会设置很大的数据放到cookie中。
(2)webStorage
在HTML5以后,那么浏览器可以使用 webStorage ,其实也是类似一种数据存储的表现形式,是对cookie的一种改良。
- sessionStorage:数据可以保存到session对象中。session是指用户在浏览某个网站时,从进入网站到浏览器关闭的这一段段时间,称之为会话。session中可以保存任何数据。
localStorage:数据可以保存在客户端本地磁盘中,就算浏览器关了,数据还是会存在的,重启电脑,下次打开网站,数据还是能获取。这相当于数据持久化的一种表现。
sessionStorag 和 localStorage 的区别就是,sessionStorage是临时保存,localStorage是永久保存持久化。
他们的数据存储在 5m 左右,比 cookie 大很多(能存4K左右)。
安全方面也比 cookie 好,因为不会被携带到请求中,通过 webStroage,大多网站数据进行缓存后,可以更快加载,也能为并发减轻一定压力。
优化 getUser & updateUserInfo :在 Redis 中缓存用户信息 + 更新 mysql 时同步更新redis
之前虽然已经通过 sessionStorage 对“基本信息”进行了优化(这个操作是什么时候做的????前端做的吗???),但是用户如果已经知道地址,还是可以发起高频率的请求.<br /> **因为“基本信息”基本不更改的特性 ==> 我们可以把基本信息存入到 Redis 中去**!这样用户查询时,直接去缓存Redis中查询即可,不用再进入数据库了
代码
**由于用户信息不怎么会变动,对于千万级别的网站,这类信息数据不会去查询数据库,完全可以把用户信息存入redis**。<br />**哪怕修改信息,也不会立马体现,这也是弱一致性**。在这里有过期时间,比如1天以后,用户信息会更新到页面显示,或者缩短到1小时,都可以; **基本信息在新闻媒体类网站是属于数据一致性优先级比较低的,用户眼里看的主要以文章为主,至于文章是谁发的,一般来说不会过多关注**.
private AppUser getUser(String userId) {String userJson = redis.get(REDIS_USER_INFO + ":" + userId);//1 尝试从redis获取AppUser user = null;//2 查询判断redis中是否包含用户信息,如果包含,则查询后直接返回,就不去查询数据库了if (StringUtils.isNotBlank(userJson)) {user = JsonUtils.jsonToPojo(userJson, AppUser.class);} else {// 3 说明 redis无,去 mysql 中搞user = userService.getUser(userId);// 由于用户信息不怎么会变动,对于一些千万级别的网站来说,这类信息不会直接去查询数据库// 那么完全可以依靠redis,直接把查询后的数据存入到redis中redis.set(REDIS_USER_INFO + ":" + userId, JsonUtils.objectToJson(user));}return user;}
...//缓存双写那里还要更新!!这就不展示了!
1 扩展 UserController 的 getUser 方法:增加初次查询放入缓存的功能
(1)定位 getUser
打开 UserController 里获取“基本信息”的方法,里面有一个getUser;找到这个方法,进行扩展!
(2)设置 redis 所需的 key 值
这里 redisController 用到一个key,这个玩意我们去BaseController中去设置一下,如下:<br /> redis_user_info
(3)导入第三方工具类
把 user 信息放到 value 的位置,需要 **JSON 转换类 ,把对象转成 str**.<br /> 这个类从老师源码中拿即可,放入 common 中的 utils 包中即可<br />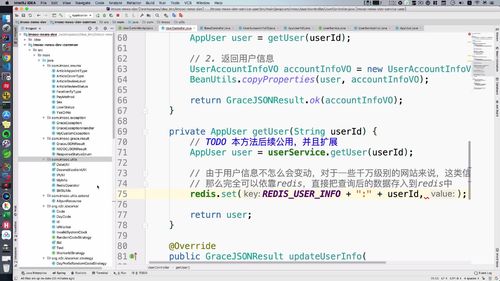
2 更改 userServiceImpl 中的 updateUserInfo 方法:补充修改信息时,同步更新缓存的逻辑(未完待续)
( 注意是 service 层 而不是 controller 层,虽然两层方法同名)
(之前只更新在了数据库,现在为了配合查询的方法,现在还要更新到Redis中)
(1)为什么
之前用户修改了信息以后,**只是存在了数据库中**!<br /> **如果不同步覆盖 redis 中的数据,那么 1 中的方法从 redis 中读取的可能就是脏数据了!**
(2)怎么做
这个方法,我们最后“补充一个查询”.<br /> “把最新的信息放入redis中”.<br /> 补充后代码如下: userId 得从 BO 中获取,这句代码也别忘了.<br />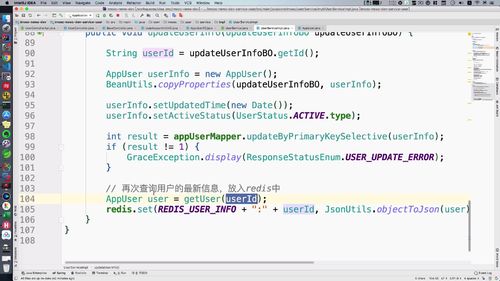
【理论/重要】双写数据不一致的情况
1 啥是:缓存双写
由于分布性系统,不能保证每个节点都可用,所有可能引起 redis 在极限情况下数据没有写入成功。那么此时缓存中的数据和数据库数据不一致。
这样的情况,同步存入 redis 的过程就可能产生问题:数据没放进redis中!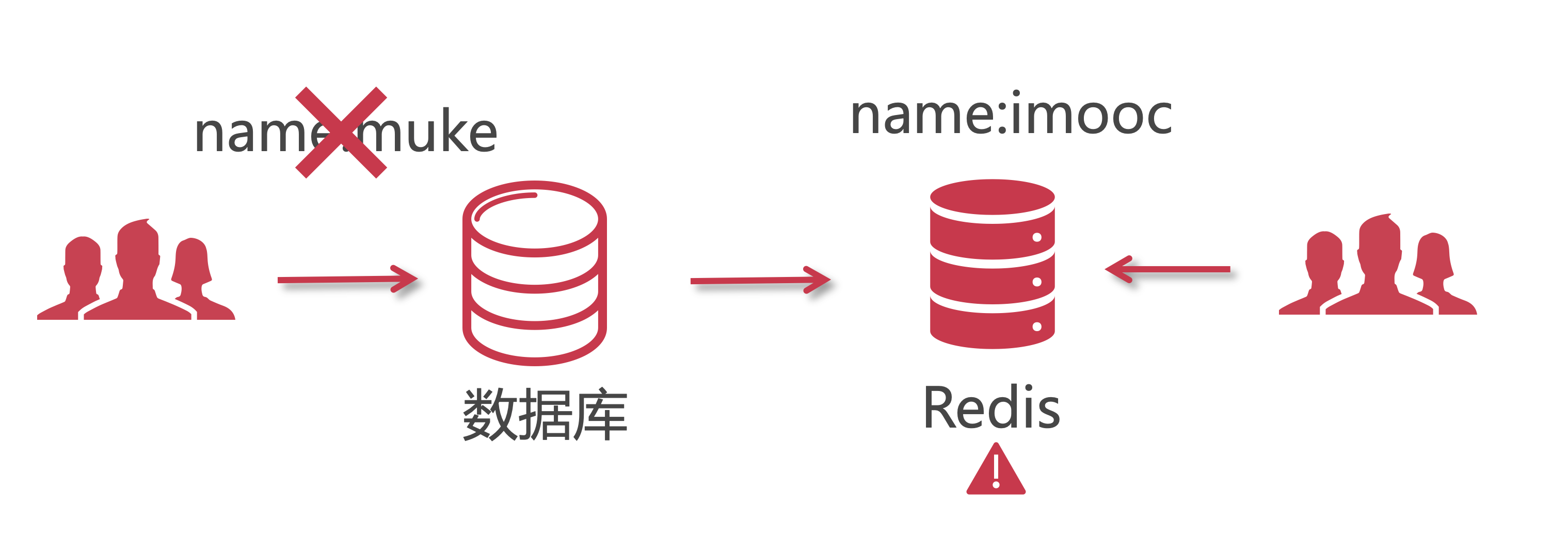
具体见老师笔记:拓展阅读https://www.imooc.com/wiki/imoocnewsarchitect/BothWriteEqual.html
如下图,“数据库中修改成功了,但是redis修改失败了”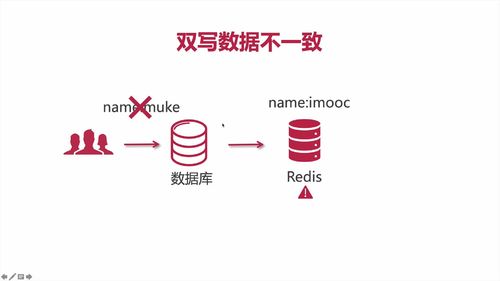
优化 updateUserInfo:双写缓存不一致 + 缓存双删
本节开始解决上节课提到的“双写不一致的情况”。
代码
@Overridepublic void updateUserInfo(UpdateUserInfoBO updateUserInfoBO) {String userId = updateUserInfoBO.getId();// 【本节继续优化1】保证双写一致,先删除redis中的数据,后更新数据库.redis.del(REDIS_USER_INFO + ":" + userId);AppUser userInfo = new AppUser();BeanUtils.copyProperties(updateUserInfoBO, userInfo);userInfo.setUpdatedTime(new Date());userInfo.setActiveStatus(UserStatus.ACTIVE.type);int result = appUserMapper.updateByPrimaryKeySelective(userInfo);if (result != 1) {GraceException.display(ResponseStatusEnum.USER_UPDATE_ERROR);}// 【上一部分刚优化】再次查询用户的最新信息,放入redis中AppUser user = getUser(userId);redis.set(REDIS_USER_INFO + ":" + userId, JsonUtils.objectToJson(user));// 【本节继续优化2】缓存双删策略try {Thread.sleep(100);redis.del(REDIS_USER_INFO + ":" + userId);} catch (InterruptedException e) {e.printStackTrace();}}
1 双写不一致:更新 mysql 时删除 redis,使得 redis 必须去 mysql 读取数据再存入
(1) 思路分析
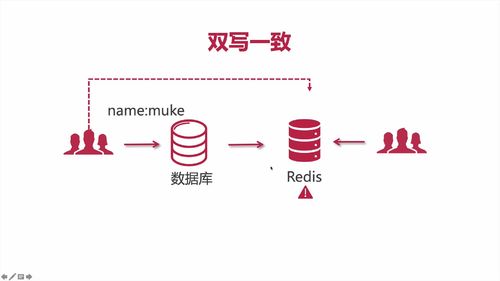
如何避免“双写不一致”的呢?
<1> 发起修改请求时,【先删除 redis 中过的数据】
<2> 删除后才更改数据库
<3> …后续就是再写入redis
redis中数据删除后,在重新写入前,如果用户此时访问了,【就和我们之前写的逻辑一样:redis中没有时,去数据库中查询】
(2) 代码实现:补充删除代码
2 缓存双删:优化双写不一致
(1) 问题反思
此时,分析一下,还有什么遗漏的问题。假如,用户的请求在 “ redis删除之后,mysql更新之前 ”,那么此时 redis 去 mysql 中拿到的数据,还是旧数据。如何避免?
==> 引入【缓存双删】:mysql “更新时”删一次,”等一会”再删除一次
我们在 mysql 更新后,【所在线程休眠半分钟左右,然后再次删除redis中的数据】,然后再更新。
注:这样的做法仍然是不能完全解决“脏数据的问题”,只是【很大程度上压缩脏数据的存在时时间】!!!因为对于用户来说,做到这样其实也已经足够了,这个业务并不是说,用户晚几秒看到用户信息就不能接受之类的。
(2) 代码实现
【理论】业务角度分析:为何可以容许脏数据存在?
一些情况下,业务不能受到并发影响,如果出现了 1~2秒 的脏数据,我们在首页展示的用户信息可能是错的,但是这个对整个系统的完整性是没有什么影响的,所以“保证系统可用性即可!!!”
——> 不能把太多的请求放在数据库.
从业务角度分析:并发请求绝大多数在首页和新闻详情页,用户的查询是很多的。如果出现了1-2秒的脏数据缓存,那么首页展示的用户昵称或者用户头像可能是老数据,但是对于整个系统来讲无所谓,没有太大的影响,而且用户的注意力是在新闻上,而不是新闻发布者,所以有几秒的不一致是无所谓的,因为热点数据的并发读是很大的,一旦删除,那么这个时候由于缓存击穿,数据库可能会瞬间被炸了,直接宕机。所以务必以系统可用性为优先考虑。
(????什么是缓存击穿????????)
(卧槽,感觉挺重要的,但是没听懂啊,啥叫“并发读”)
==> 因为对于这个项目,重点在于“看文章”,发布者如果信息有1-2秒错误的话,没有什么关系。
因为热点数据的 “并发读” 是非常大的,一旦删除之后,用户有大量的并发请求进来,可能造成“缓存击穿”,数据库可能瞬间爆炸。所以保证系统更可用性更加重要,几秒的脏数据没什么关系。
【理论】CAP理论
https://www.imooc.com/wiki/imoocnewsarchitect/CAP.html
1 CAP 简介
分布式系统由多个组成部分共同构成,**用户的请求通过不同节点的多次运算后才能把结果响应给用户,也意味着请求经过了多个系统**。<br /> **分布式系统,都有CAP的情况。**<br />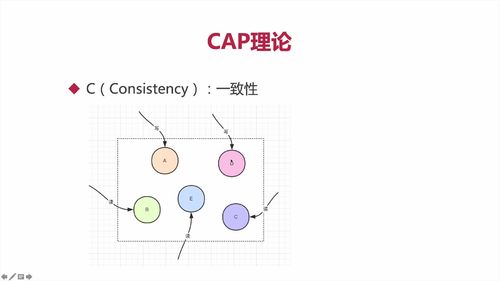<br />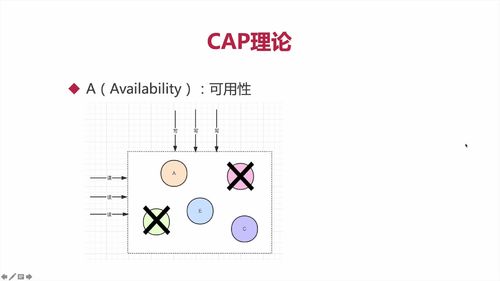<br /> 云服务器在不同地方,这就是“网络分区”。<br /> 分区之间有通信。部分系统故障不影响整体。即考虑“分区容错”<br /><br />理论上应该都满足,但实际上,因为人开发了系统,难免有错,**所以一般【只能满足CAP中任意两个】**<br />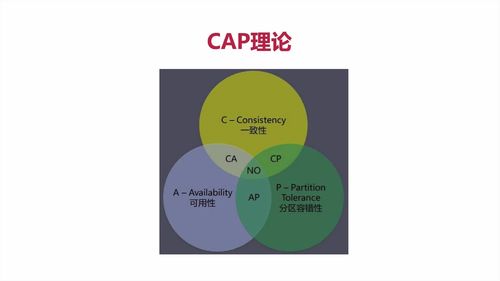
2 为何无法同时满足CAP?
(看视频讲解即可)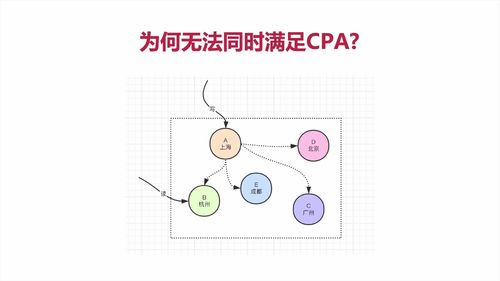
==> 开发中,都是保证好P(分区容错性)以后,采取抉择保证C(一致性)还是A(可用性)
3 各搭配分析
1 介绍
CP:效率低
redis mongoDB这种都是CP,强一致性,效率低
AP:多用(可用性 + 分区容错性)
CA:一般都是关系型数据库才用,一些单体的数据库
日常中,一般都关注“弱一致性”,强一致性难满足,用户对一般的业务也不太关注一致性。
但是数据服务一定要满足强一致性。
2 项目首页体现“弱一致性”
首页高访问,所以“优先保证可用性”,一致性可以延后处理。
(???这个为啥刷新了还不出来,不是已经重写了那个方法码?为啥非得重开一个会话才读取后端数据???==>最后老师讲了,如下,首页基本信息这里有一句“数据存入seesion storage”,估计更改信息的页面没有这句话,估计实时获取)
4 弱一致性(具体见老师笔记)
整合 restTemplate 服务通信,在 admin 中调用 file 中的方法
整合 RestTemplate 服务通信,在 admin 中调用 file 中的方法
分析:服务间发起调用
现在目标是:调用编写的的 “文件获取并且转换类型” 方法.
这里 admin 和 file 工程之间是没有关系的,是并列的,都是继承于api工程的,所以 admin 不能直接调用 file 的API.
服务间发起调用其实有多种方式,比如 RPC 通信;这里选择 HTTP 通信( 这一步分后期可以通过spring cloud微服务的方式进行进一步的优化 )。使用 HTTP 的话,就得用到 restTemplate 这个类了。需要进行相应的配置。
不同服务之间的通信可以采用restTemplate来进行通信调用,当然使用httpClient来构建也是可以的。
Api 工程中 config 包下构建 CloudConfig 类(没搞懂这狗玩意咋用的)
OKHttp3 这个玩意好像是 sb 框架中提供的
@Configurationpublic class CloudConfig {/*** 基于OkHttp3配置RestTemplate* @return*/@Beanpublic RestTemplate restTemplate() {return new RestTemplate(new OkHttp3ClientHttpRequestFactory());}}
(有疑问,参数传递不太懂)编写调用方法所需的 url
定时任务
五、面试题
END

若有收获,就点个赞吧
0 人点赞
