- 基础篇
- 开篇词 | 这样学Redis,才能技高一筹
- 01 | 基本架构:一个键值数据库包含什么?
- 02 | 数据结构:快速的 Redis 有哪些慢操作?
- (没太懂)03 | 高性能IO模型:为什么单线程Redis能那么快?
- 04 | AOF日志:宕机了,Redis如何避免数据丢失?
- 05 | 内存快照:宕机后,Redis如何实现快速恢复?
- 06 | 数据同步:主从库如何实现数据一致?
- 07 | 哨兵机制:主库挂了,如何不间断服务?
- 08 | 哨兵集群:哨兵挂了,主从库还能切换吗?
- 09 | 切片集群:数据增多了,是该加内存还是加实例?
- 实践篇:数据结构
- 实践篇:性能和内存
- 实践篇:缓存
- 实践篇:锁
- 实践篇:集群
- 结尾
基础篇
开篇词 | 这样学Redis,才能技高一筹
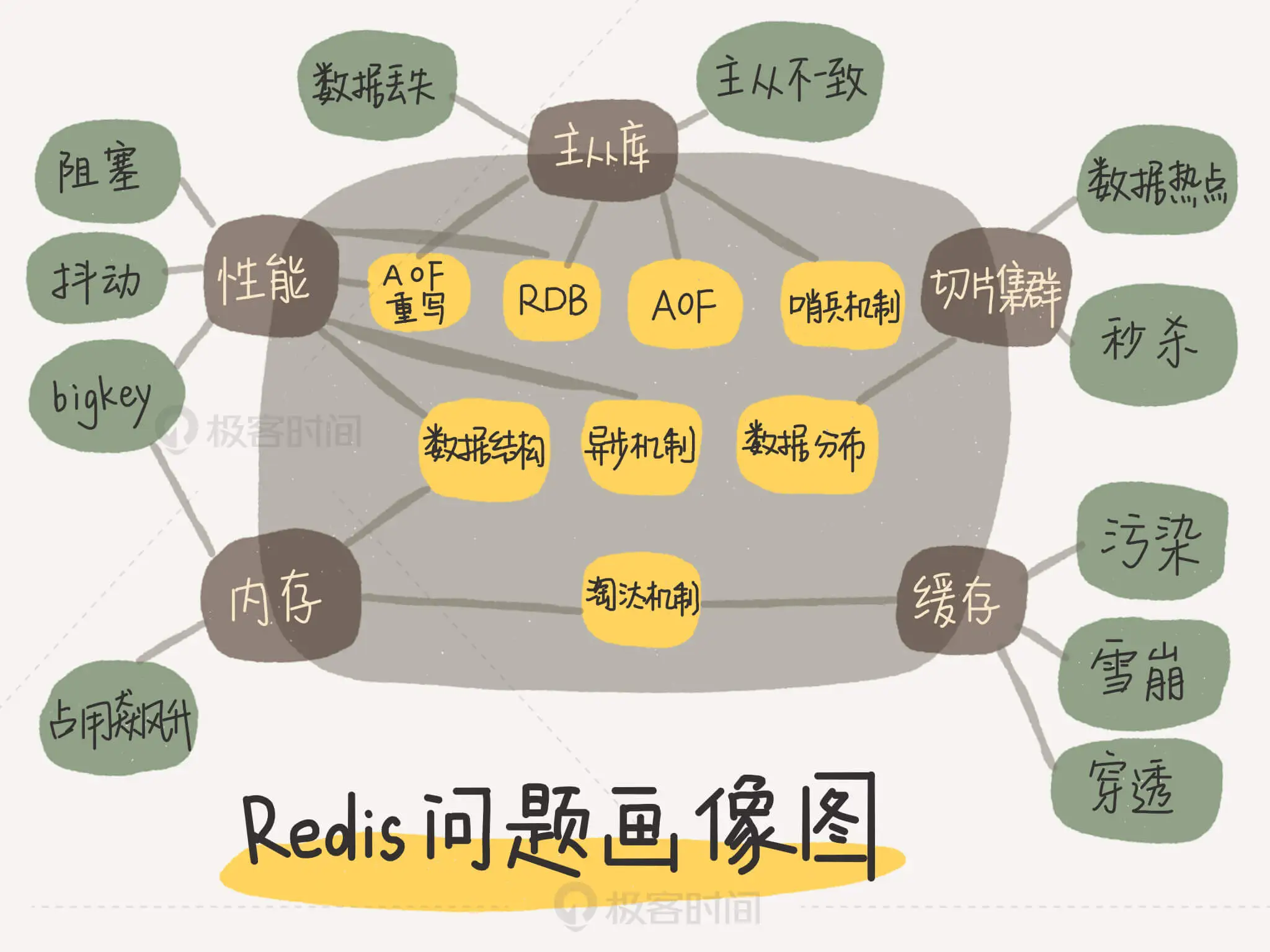
所谓的 Redis 知识全景图都包括什么呢?简单来说,就是“两大维度,三大主线”。
01 | 基本架构:一个键值数据库包含什么?
引
构造简单的kv数据库
小结
(1)本节结构
1-2:应用层面涉及
3-6:SimpleKV 的完整内部构造
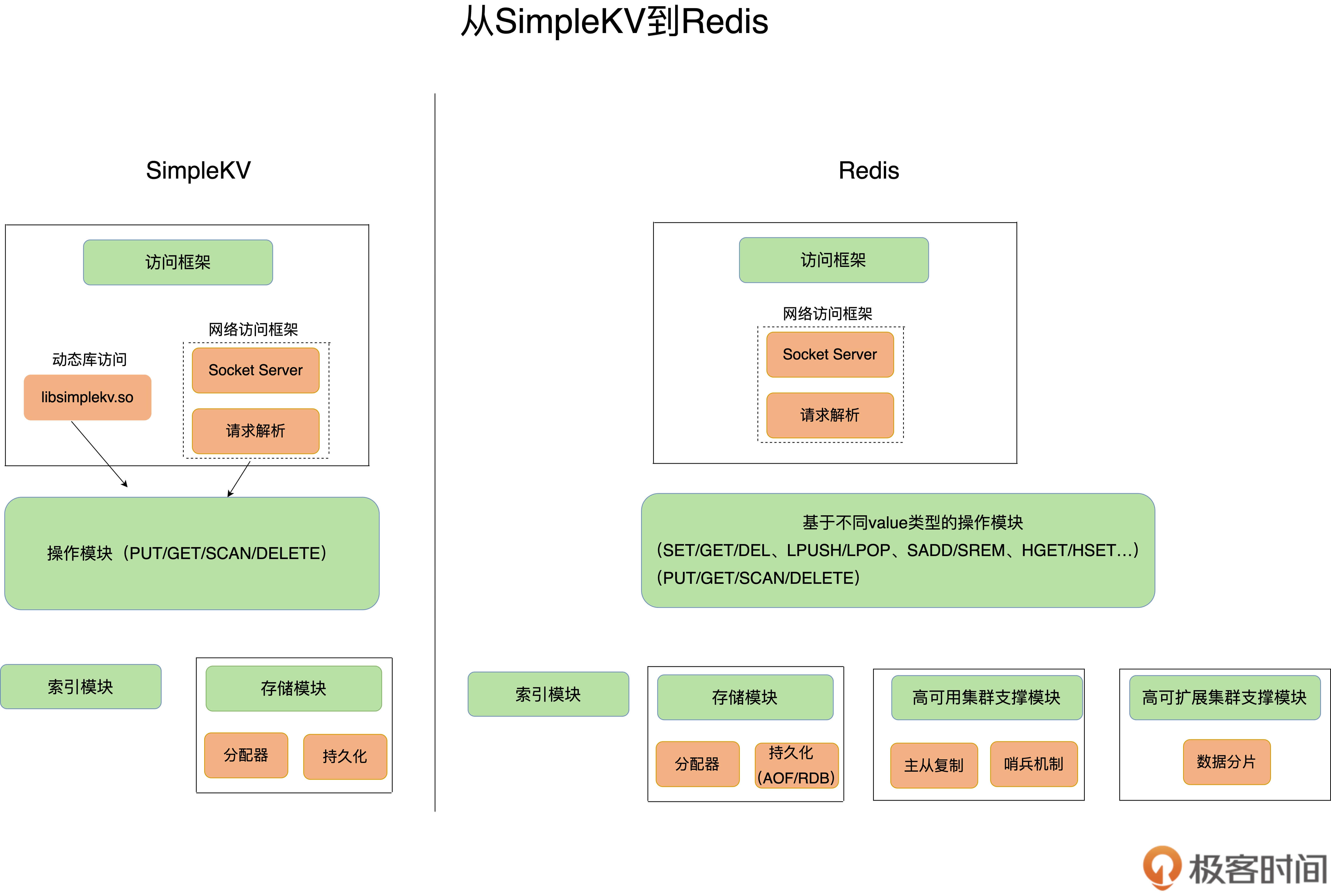
(2)从 SimpleKV 到 Redis
Redis 就是丰富版的 SimpleKV.
根据下图
1 可以存哪些数据?
对于k-v数据库,基本的数据模型是:key-value
实际中,value的类型可以是复杂类型,不同k-v数据库支持的key类型差异小,value差异大。数据库选型时的一个重要考虑因素:支持的value类型。
了解不同类型value类型背后的原理,对于选择value类型或者优化时很有帮助
2 可以对数据做什么操作?
作为k-v数据库,操作无外乎:增删改查
业务补充
value类型多样化时,需要操作接口
数据模块 操作接口 构造完了.
开始思考【键值对保存在内存还是外村】==>看应用场景,redis就适用于数据可以快速访问但允许丢失的场景
内存优势,外存优势
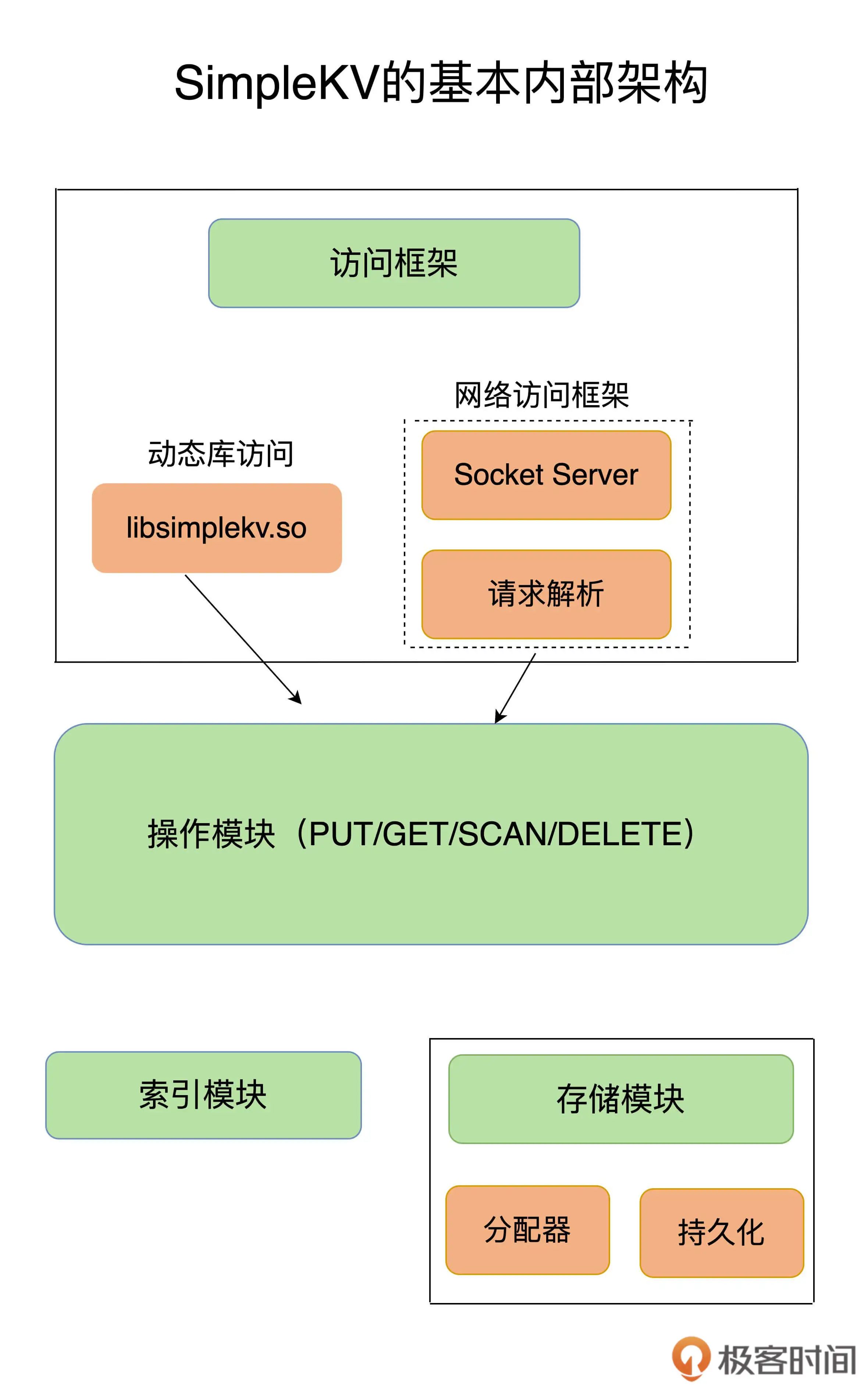
开始了解simpleKV基本组件:访问框架 + 索引模块 + 操作模块 + 存储模块
3 采用什么访问模式?
常用两种访问模式:
…
…
网络这个,不同ky数据库与客户端交互协议并不相同
redis就是通过利用的第二种访问模式。扩大受用面的同时,带来了新问题:
一个例子:…这一过程,用“一个线程?多个线程?多个进程?”,这就是I/O模型设计问题,redis采用的是单线程,至于怎么实现“高性能”的,后面再说
4 如何定位键值对的位置?
通过访问请求,得知了“需要进行什么kv操作”
此时,需要 “利用索引模块检索k-v是否存在,存在时,定位位置”
redis中找到value后,不一定就找到了结果。因为value可能本身类型很复杂,这样就需要我们进一步根据其实现结构查找结果。索引只是帮我们由key到value
redis中某些value底层采用的高效索引结构,为redis实现高性能访问提供了基础
5 不同操作的具体逻辑是什么?
根据索引找到k-v后,就需要执行了,这就用到了“操作模块”:即真正实现crud
其中,对于put和delete这俩,还涉及内存分配和释放,这又涉及“存储模块”
6 如何实现重启后快速提供服务?
管理功能
simplekv中的..redis中的内存分配器选择多…(后面讲)
持久化功能:为了重启后快速重新提供服务
simple kv 的…(文件形式..)redis也提供持久化功能
评论
02 | 数据结构:快速的 Redis 有哪些慢操作?
引
redis“快”的表现:接收到一个kv操作后,可以用“微妙级别”的速度找到数据并完成操作.
快的原因:内存型数据库 + 数据结构
本节课聊聊“前两个问题”:了解到 [redis快的原理] 和[redis中潜在的满操作]
小结
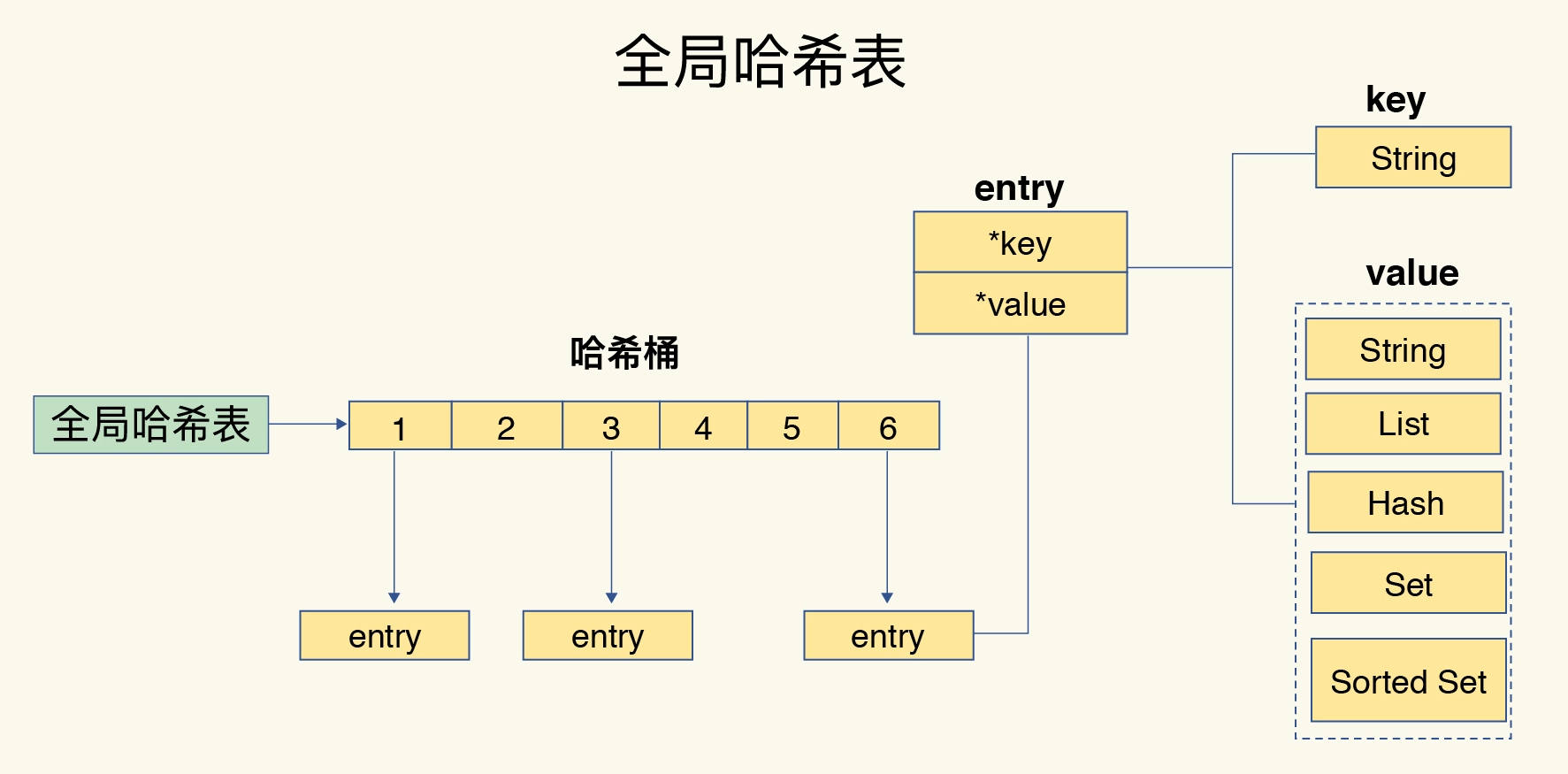
用来保存每个k-v的全局哈希表结构
支持集合类型实现的5大底层结构:双向链表/压缩列表/整数数组/哈希表/调表
哈希表的应用
list类型
1 键和值用什么结构组织?
全局哈希表
这里key和其对应的value是一个整体,一个entry
哈希表(其实就是一个数组),存指针,这样的话什么类型都可以保存
redis 写入大量数据后,哈希操作可能变慢==>一个潜在风险:哈希表的冲突问题 + rehash可能的操作阻塞
为什么哈希表操作变慢了?
(1)数据多了,造成hash冲突==>使用拉链发,一个位置上用链表
(2)数据再增加,一个位置上链表增加==>使用rehash,对哈希表扩容
(3)一次扩容,复制数据太多,导致阻塞==>多批次复制,即渐进式rehash
2 value为集合类型时
对于str,根据hash找到value后crud即可;
对于集合,找到了v,还得在集合中进一步操作,所以来看看集合类型的操作效率如何.
集合数据操作效率
取决于两点:
(1)这个集合是什么实现的? 哈希还是链表?…
(2)用这个集合干什么? 读写一个还是读写所有?…
有哪些底层数据结构?
..
这里就把这5个结构说了一下
中间有俩没咋说,有三个介绍较为仔细
不同操作的复杂度
评论
(没太懂)03 | 高性能IO模型:为什么单线程Redis能那么快?
0 Redis真的只有单线程吗?
Redis的单线程具体指什么?
∴Redis严格来讲不是单线程
小结
外什么用单线程:核心原因是 避免多线程开发的并发控制问题
高性能:与多路复用的IO模型密切相关,这避免了…操作潜在网络IO操作阻塞点
拓展:redis6.0的多线程?后续介绍
1 Redis为什么用单线程?
多线程的开销
多线程提升吞吐率的效果不如人们预期:存在共享资源,就涉及额外机制,导致额外开销——并发访问控制
并发访问机制一直是多线程开发的难点,如果要采用也需要精密的涉及,适用保护机制会将i的“系统代码易调试性” 和 “可维护性”,所以redis采用单线程来避免这些问题.
黑马解释:
精彩评论:
因为Redis是基于内存的操作,CPU不是Redis的瓶颈(意思是不用从磁盘读取数据),Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
2 单线程Redis为什么那么快?
一般单线程能力应该比多线程差很多,为什么redis的就快呢?
综合涉及的结果:内存中执行操作 + 高效数据结构 + 多路复用机制
① 一方面,Redis 的大部分操作在内存上完成,② 再加上它采用了高效的数据结构,例如哈希表和跳表,这是它实现高性能的一个重要原因。③ 另一方面,就是 Redis 采用了多路复用机制,使其在网络 IO 操作中能并发处理大量的客户端请求,实现高吞吐率。
3 多路复用机制
基本 IO 模型与阻塞点
(socket网络模型是什么?)
介绍了simpleKV中处理get请求的过程
其中 accept 和 recv 过程中可能存在阻塞:前者阻塞可能不太容易建立连接,后者可能就是得不到数据
非阻塞模式
学习sokcet网络模型的非阻塞模式:体现在“三个关键的函数调用
socket模型?套接字类型?
…(1)针对 “监听套接字” ==>设置非阻塞模式
—(2)针对 “已连接套接字” ==>设置非阻塞模式
基于多路复用的高性能I/O模型
…
Redis不会阻塞在某一个特定的监听或已经连接的套接字(上一部分设置的两个非阻塞模式)
即:不会阻塞在某一特定的客户端请求处理了上
==>因此,可以同时和多个客户端连接并处理请求,从而提升并发性
不同操作系统,多路复用机制也OK
评论
(拓展)Redis_黑马:Linux中的 IO 多路复用(其他系统的可能有不同)
用户空间和内存空间(见黑马Redis讲义的笔记)
阻塞IO/非阻塞IO(见黑马Redis讲义的笔记)
IO多路复用(见黑马Redis讲义的笔记)
select:最早
select 方法的结构
(1)select方法中
方法中 nfds:要监听的fd_set的max+1;如右图,最大的fd是5,那么这个属性就是5+1=6
fd_set:fd结构体,主要涵盖“读 写 异常”三类事件,具体如图
返回:超时事件
(2)fd_set
如图,这是一个数组.
元素是__fd_mask,这个图中也有,是一个long,在c语言中,占4字节,即32位.
长度=1024/32=32,即存储32个32bit的元素
==>一个bit代表一个fd,因此可以存储1024个fd
select方法的执行流程
如图 1.1 - 2.4 已经标好了.
1.1 创建数组,所有fd初始化为0
1.2 中,要监听的fd是1 2 5,所以会把图中的 1 2 5这几个位置改成1(图中只有一个1,是因为这是2.3回来给覆盖了)
1.3 中 5+1 就是 nfds,因为 fd 最大是 5. 这里就演示一个读事件,其他俩事件就是Null了
从 1.3 -2.1 ,需要进行“拷贝”!,因为这个fd数组内核空间中没有!但是2.1 又需要,所以得搞过来.
2.2 在 2.1 遍历后,发现只有 5 就绪了,1 2 还是休眠,那就设置为0
2.3 等一会,要是监听对象没有在这期间被唤醒,就不等了
从 2.3 -2.4,用内核空间的 fd_set 刷新——“拷贝”用户空间的 fd_set。因为不知道哪个 fd 就绪了,所以必须重新扫描一遍!
select方法的问题
根据上述流程,select有如下问题:
(1)每次select涉及两次拷贝(1.3 -2.1 2.3 -2.4)
(2)select 不知道 哪个fd刷新了,得从头扫描.
(3)fd_set 的长度固定,只能是1024
==> select是最早出现的,后来出现了poll,对select进行了一定的改进(性能提升也就那样了)!
poll:没啥改进
基本没人用,没啥性能提升
select的三大问题,就解决了一个 (3),即数组长度问题.
epoll:对于 select 的巨大改进
epoll提供了三大函数:【eventpoll结构体创建函数】 + 【FD添加/监听函数】 + 【FD等待函数】
epoll_create:eventpoll结构体创建函数
(1)方法的作用
这个方法就是为了 “创建【eventpoll 结构体】”.
(2)eventpoll 结构体
如图,eventpoll 结构体包含了两个超级重要的属性:
==> 在内核空间中,【存储 所有FD 的 红黑树】和【存储 就绪FD 的 链表】
(3)方法的返回值
返回值是 刚才创建的 eventpoll 结构体 的 句柄 epfd,这个也很重要!这是其他方法定位
epoll_ctl:FD添加/监听函数
(1)作用
这一步,负责【把 FD 从 用户空间 拷贝进 内核空间】
(2)形参
epfd 就是之前那个,用来锁定 epollevent 结构体.
op 指定“CRUD”类型
fd 就是要拷贝的FD
(3)注意,在这一步,“ FD 和 异常事件 会被挂上 callback方法 ”.
一旦 “这个FD就绪了” ,直接【把 FD 从 epfd 的 红黑树 拷贝到其 链表 中】.
epoll_wait:FD等待函数
(1)作用
返回【epfd 的 链表(已就绪FD集合) 中的 FD数量】.
(2)形参
其中这个 “ events ”(注意有s,和函数2中的不同)很重要!
在用户内存中.
【epfd 的 链表(已就绪FD集合) 中的 FD】会被 “拷贝” 到 “ events ”!
epoll 如何解决 select 中的3个问题?
(1)解决 1024 上限问题:红黑树.
其 epollevent 中采用了红黑树,大幅增加了存储FD的上限!
(2)解决 “两次全拷贝”:红黑树 + 链表.
select 中的两次拷贝都是 fd_set 全体复制,有很多无用的 fd。
epoll 的话,第一次只复制要监听的(用户内存,添加到 内核内存的 红黑树),第二次只拷贝就绪的(链表 到 用户内存)。
同时,第二次是明确了“就绪FD”的,而非 select 不知道哪个 FD 就绪了。
(3)解决 “不确定就绪的FD”:call_back方法.
函数2中嵌入的 “ callback方法 ”,把 FD 从 epfd 的 红黑树(所有FD) 拷贝到其 链表(就绪FD) 中,提前完成了 “ 就绪FD ” 的筛选!
epoll 的 两种触发模式:ET和LT
04 | AOF日志:宕机了,Redis如何避免数据丢失?
引
缓存场景,引出:宕机怎么办?
从后端数据库恢复数据的缺点,引出:Redis持久化
==>本节 AOF,下节课 RDB快照
小结
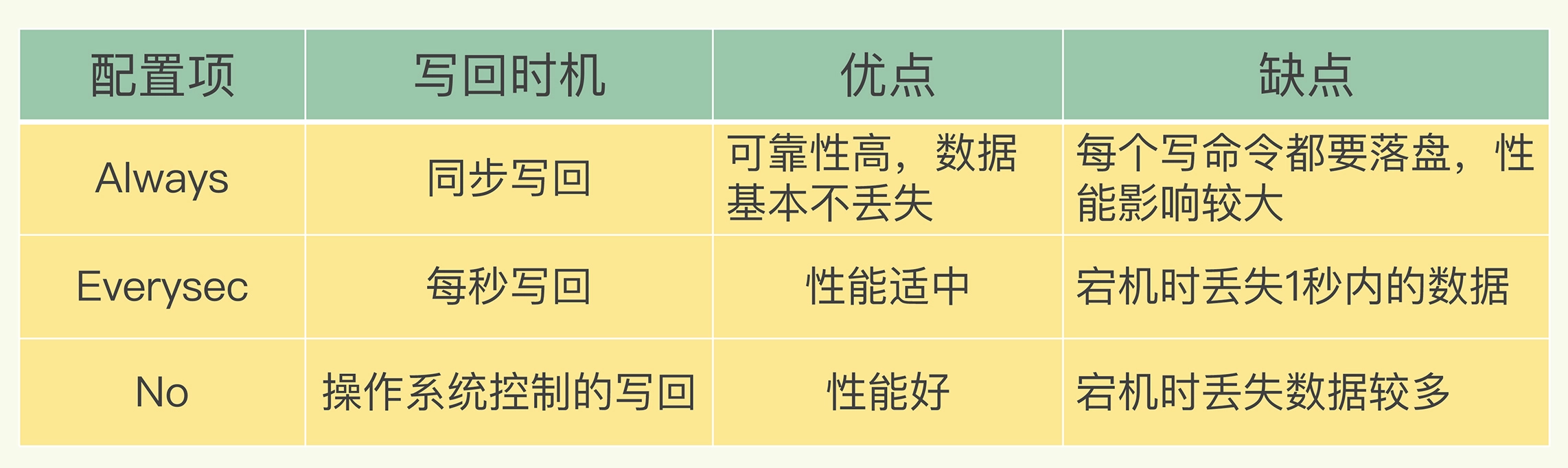
(1)AOP提供三种写回策略,避免数据丢失
(2)AOF重写:避免日志文件过大
(3)写回策略体现出的 “取舍原则”
(4)落盘时机 + 重写机制的 作用时机:“记日志”的过程.
1 AOF 日志是如何实现的? 写后日志
AOF:写后日志——先执行命令,再记录日志,日志记录的是
写后”的意思是 Redis 是先执行命令,把数据写入内存,然后才记录日志
两点好处:可以不记录错误命令。因为写后日志:执行了才记录,要是错的都不会执行,更别说记录了
执行完才写,所以不阻塞当前写操作
两点隐患:
宕机的时候,数据容易丢失,命令没来得及记录;AOF避免当前命令的阻塞,但是可能造成后面线程的阻塞.
==> 都与AOF写回磁盘相关,所以改变这个写回时机或许有改善!
下一节,3个写回策略缓解这个问题
2 三种写回策略:缓解AOF的两点隐患(阻塞 数据丢失)
AOF机制提供了三个选择:但是并无法完美解决之前提到的两个问题,得做出取舍
根据系统对高性能和高可靠性的要求,来选择使用哪种写回策略了。总结一下就是:想要获得高性能,就选择 No 策略;如果想要得到高可靠性保证,就选择 Always 策略;如果允许数据有一点丢失,又希望性能别受太大影响的话,那么就选择 Everysec 策略。
按照系统的性能需求选定了写回策略,并不是“高枕无忧”了。毕竟,AOF 是以文件的形式在记录接收到的所有写命令。随着接收的写命令越来越多,AOF 文件会越来越大。这也就意味着,我们一定要小心 AOF 文件过大带来的性能问题。这里的“性能问题”,主要在于以下三个方面:一是,文件系统本身对文件大小有限制,无法保存过大的文件;二是,如果文件太大,之后再往里面追加命令记录的话,效率也会变低;三是,如果发生宕机,AOF 中记录的命令要一个个被重新执行,用于故障恢复,如果日志文件太大,整个恢复过程就会非常缓慢,这就会影响到 Redis 的正常使用。
即:
(1)存不了这么大的;
(2)存这么大的,影响后续的追加
(3)宕机后重启,还是这么大,那么恢复过程会很慢
==>需要AOF重写机制
3 日志文件太大了怎么办?:AOF重写机制
(1)执行过程?
重写时,搞一个新的aof文件,读取所有键值对,每一个键值对用一个set命令写入。比如说,当读取了键值对“testkey”: “testvalue”之后,重写机制会记录 set testkey testvalue 这条命令。这样,当需要恢复时,可以重新执行该命令,实现“testkey”: “testvalue”的写入
(2)为什么这个机制可以把日志文件变小?
为什么重写机制可以把日志文件变小呢? 实际上,重写机制具有“多变一”功能。所谓的“多变一”,也就是说,旧日志文件中的多条命令,在重写后的新日志中变成了一条命令。多条命令重写后变成一条 / 多变一:记录结果就行,比如你push了一个数又给pop了,相当于啥都没干,那么重写机制这啥都可以不记录,即省略中间过程,只记录结果.
尽管这样,重写过程也很耗时==>重写会阻塞主线程码?见下一小节
4 AOF 重写会阻塞吗?:不会,重写交给了后台子线程
和 AOF 日志由主线程写回不同,重写过程是由后台子进程 bgrewriteaof 来完成的,这也是为了避免阻塞主线程,导致数据库性能下降。我把重写的过程总结为“一个拷贝,两处日志”。这部分“两个日志(正在适用的aof日志 + aof重写日志)”没太懂,为啥第一个日志宕机了,aof日志操作齐全?这里说redis把操作带到缓冲区,可是宕机了缓冲区还能存在吗???
(这个朋友的意思我觉得能接受:该丢的数据还是丢,不过那是aof写回策略担心的事!这里保证的不丢失,应该是 重写日志 不会丢失 正在使用的aof 中的数据)
评论
05 | 内存快照:宕机后,Redis如何实现快速恢复?
引:两个问题
(1)
上节课AOF的优劣:记录的是操作命令
==>记录的少,故障恢复时慢(需要逐一重新执行)
(2)
如何解决 [宕机时的快速恢复]?==> RDB,内存快照
(3)AOF和RDB的小对比
AOF记录操作,RDB记录数据.
==>两者都不是最优解
(4)为什么RDB不是最优解?两个关键问题
① 什么数据需要快照?不能所有数据都快照吧
② 快照时,数据能操作吗?不能操作,就意味着,很可能阻塞线程!
小结
(1)
Redis用于避免数据丢失的“内存快照方法”
优势:快速恢复数据库—>只需要把RDB文件直接读入内存,避免AOF按行按顺序逐一‘重新执行’带来的低效性能问题.
(2)
局限性:内存的“大合影”,耗时耗力
尽管有 (bgsave + 写时复制机制),仍不能完美解决
==> RDB + AOF才是更好的选择
(3)AOF和RDB的选择问题
1 给哪些内存数据做快照?(引中的问题1)
(1)给哪些内容快照?
Redis是“全量快照”,即 给【所有数据】快照==>保证数据 “可靠性”
(2)引发的问题
给所有数据都快照,太耗费资源
(3)Redis是单线程,这个问题会引起 [线程阻塞]吗?怎么解决?
两个命令:save会,bgsave会创建子线程
2 快照时数据能修改吗?(引中的问题2)
若因为快照,导致写操作阻塞,不可接受。
(1)能用 bgsave 避免吗?
(2)如何避免这一问题?==> 写时复制技术
快照时,如果有写操作,那么就为这个写操作复制一个副本,让它在副本上更改.
(然后呢?改完了直接覆盖原来的?快照与数据不实时,可以接受吗?????)
(3)
3 可以每秒做一次快照吗?
(1)无法即使快照的后果
t1快照,t2修改,t3宕机,==> t3 只能按 t1 的恢复,导致 t2 的数据丢失
(2)如何解决?大幅缩小快照间隔,“连拍”,可以吗?
不可以!频繁“全量快照”的两大负担:
①磁盘压力
② bgsave执行不阻塞主线程,但是频繁用创建bgsave会阻塞主线程
(3)那怎么办?==>增量快照(本来是全量快照)
① 什么是增量快照?
② 增量快照的前提?
③ “记住”功能引发新问题:额外的空间开销
(4)以上问题揭露出RDB的核心难题:快照频率很难把控
(5)有什么更好的方案吗?==>混合使用RDB和AOF
① 怎么操作?
快照设置一定过的频率
AOF在快照间记录命令(相当于替换了刚才了“增量快照”)
06 | 数据同步:主从库如何实现数据一致?
引
(1)AOF 和 RDB 仍然不能完全解决【服务不可用】
(2)Redis高可靠性的另一层含义
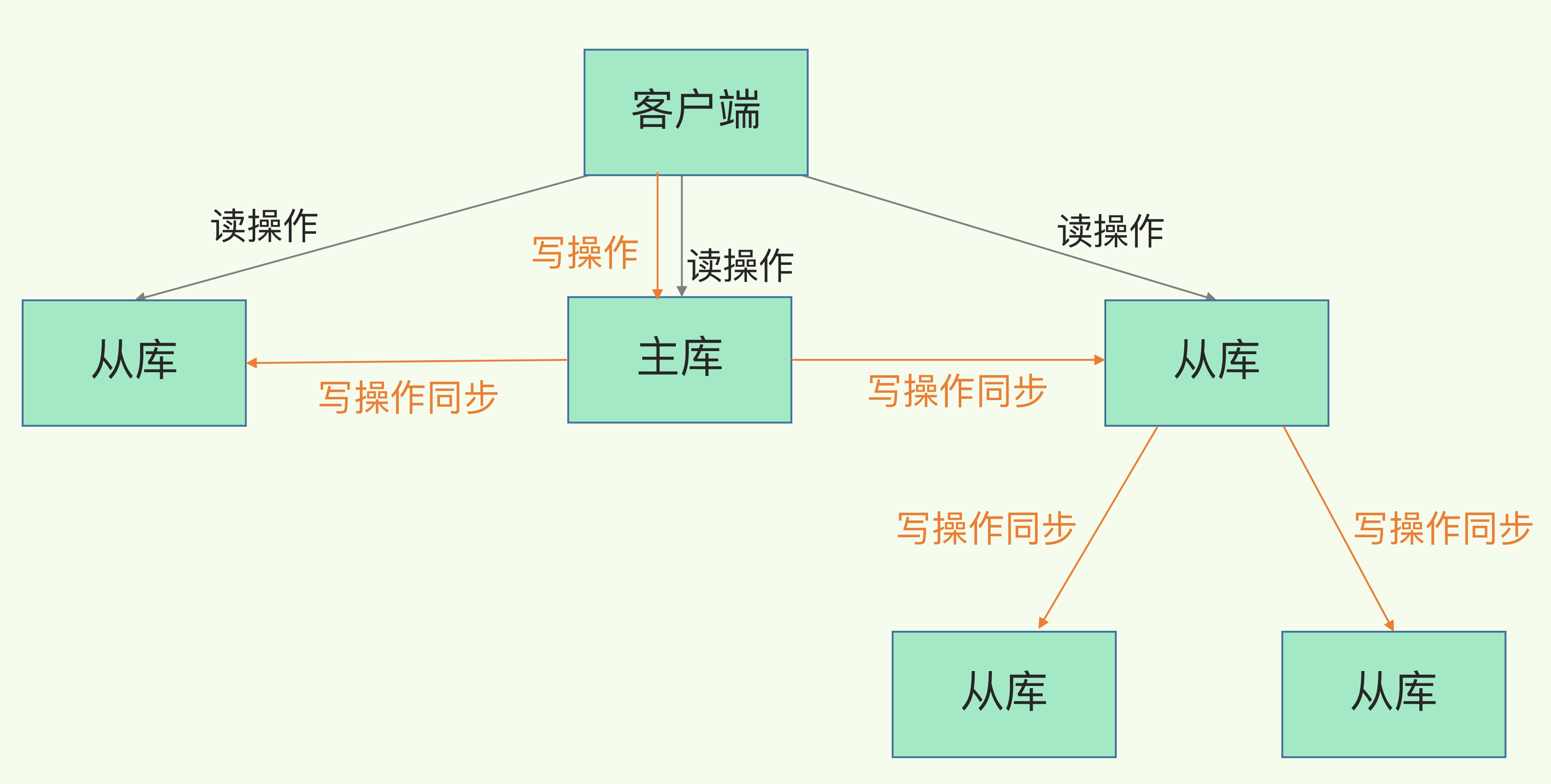
(3)Redis可靠性第二层含义的实现方式:主从库模式,其中主从库读写分离
(4)为什么要读写分离?==>保证数据一致性的同时每减少一些加锁上的麻烦
(5)主从库同步如何完成?
小结
学习了【Redis主从库同步的基本原理】
主要分为三种模式:【全量复制】【基于长连接的命令传播】【增量复制】
(1)全量复制
耗时
对于从库,第一次同步,无法避免
建议1:一个redis实例数据库不要太大!减少RDB文件生成、传输、重新加载的开销
建议2:采用“主-从-从”级联模式,同时多个从库同时和主库全量复制时给主库带来的同步压力
(2)基于长连接的命令传播
时机:主从库正常运行后的馋鬼同步阶段
方式:命令传播实现同步
(3)增量复制
时机:(2)的这种,网络断连时,就需要用到(3)
建议:repl-backlog-size这个参数调大一点,减少从库在网络断连时,引发全量复制的几率
1 主从库间如何进行第一次同步?Redis实例建立主从库模式后的规定动作(一个Redis实例指的就是一个库吧?)
(1)主从库的设置
(2)主从库数据【第一次同步 的 三个阶段】

(2-1)阶段1:建立连接,协商同步 ==>为全量复制准备
① 从库给主库发psync命令:我要同步
psync:包含 【主库 runID】【复制进度offset】
② 主库启动复制
(2-2)阶段2:主库 同步数据 给从库 ==>从库接受数据,在本地完成数据加载
① 主库执行bgsave,生成RDB,发给从库
② 从库收到RDB,清空当前数据库,保存RDB.
③ 同步过程中的新数据,用 replication buffer记录
(2-3)阶段3:主库 发送新写命令 给从库
① 将(2-2)的③中的replication buffer也发给从库,真正实现“主从同步”
2 主从机链模式分担全量复制时的主库压力:“主-从-从”模式
(1)第一次同步的恼火问题:在 1 中,主库需要【生成RDB和传输RDB】,这非常耗时间!
(2)如何KO ?==>“主-从-从”模式
(3)解决主从库的第一次同步的全量复制后,进入一个新状态【基于长连接的命令传播】
(4)【基于长连接的命令传播】状态引发的新问题:网络断连或者阻塞了怎么办?
3 主从之间网络断了怎么办?(如何保证“基于长连接的命令传播”的稳定 )==> 增量复制 与 repl_backlog_buffer
(1)怎么办?==> 增量复制
(2)增量复制时,怎么保证主从库同步?==>缓冲区 repl_backlog_buffer
在 1 的 第2/3阶段中,提到过replication buffer。断连时其实在写入 replication buffer 时(这个不仅在第一次复制时写,同步过程中的新写操作都会记录在这),还写入了 repl_backlog_buffer
==> master_repl_offset 记录主库的写的进度,slave_repl_offset 记录从库的同步位置
主库的进度一般就比从库快,回复连接后,从库追进度就行了
(3)因为是环形缓冲区,从库的指针跑太慢,被主库的绕了一圈追上了,覆盖了咋办?
==>调整 repl_backlog_buffer 这个参数.
(4)进一步的问题
07 | 哨兵机制:主库挂了,如何不间断服务?
引
(1)从库切换为主库的需求
之前的主从复制,可以保证,从库G了,还能继续运行.但是主库G了,出大问题!==>不能主从复制 + 没有库执行写操作
==>【需要一个新主库】
(2)从库切换为主库的三个问题==>哨兵机制均可KO
小结
(1)
主从集群的数据同步:数据可靠的基础保证
自动的主从切换:主库故障时,服务不断的关键支撑
(2)哨兵机制的三大功能:
(3)多个哨兵,降低误判
(4)多个哨兵,引发的新问题(下节课讲 哨兵集群 的问题)
1 哨兵机制的基本流程
(1)什么是哨兵?
一个运行在特殊模式下的 Redis 进程.
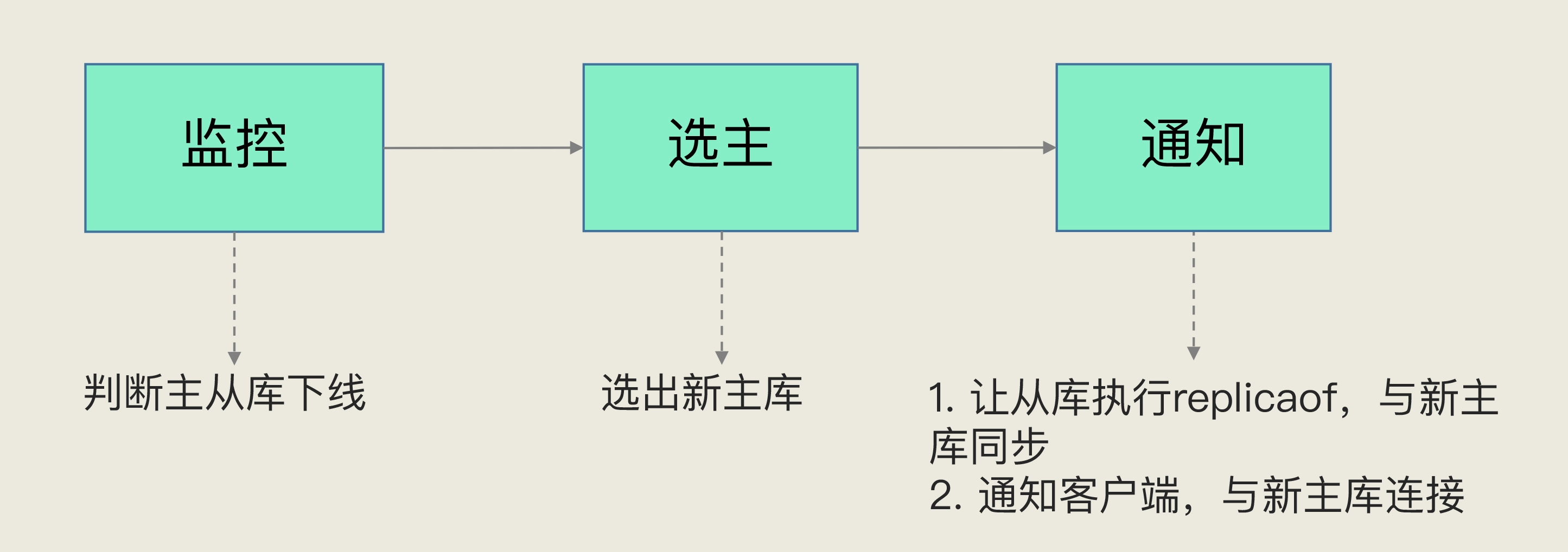
(2)哨兵的三个任务:【监控】【选择主库】【通知】
2 哨兵机制的功能
功能1:监控
周期性给所有主从库发送PING命令,检测他们是否正常运行.
若从库不响应,哨兵标记它为“下线状态”.
….主……………,哨兵判断主库下线,然后 “开始自动切换主库“ 的流程.
功能2:选主
主库G了,就按一定规则,选一个从库作为新的主库.
功能3:通知
哨兵把 新主库 的连接信息发送给其他从库,让他们执行 replicaof 命令,”建立新的主从关系“.
进行数据复制 .
哨兵把新竹库连接信息告知客户端,让他们把请求操作发到新主库 .
功能1/2中的难点
功能1:怎判断主库下线?
功能2:如何决定那个从库称为主库?
3 功能 1 中,如何判断主库下线?==> 主观下线和客观下线
主观下线:1个哨兵认为这个主库G了
客观下线:多个哨兵都认为这个主库G了
(1)如何判断一个库的状态?
PING命令
回应超时,则标记这个库”主管下线“
(2)只有一个哨兵判断,有什么问题?==> 可能会误判
从库误判了没关系,主库要是误判了下线,问题就很大,会导致额外开销,所以”务必减小误判几率“
(3)怎么解决(2)中的问题?==>【哨兵集群】
例如:1个人做不了决定,可以一群人来做
反映在哨兵机制:1个哨兵害怕误判,可以很多个哨兵一起判断,少数服从多数,减少误判几率
4 功能 2 中,如何选定新主库?
(0)基本流程:【筛选】 + 【打分】
”一定“ 的筛选条件,筛掉不符合条件的从库
”一定“ 的规则,给剩下的从库逐个打分,选分高的为新主库
==> 注意两个 ”一定“.
==>三轮打分,不是求和!而是上一轮得分一样时,才进行下一轮!!!
(1)筛选
当前在线状态:得在线吧
之前的网络连接状态:保证连接一直是通常的,不能我刚选你你就断了
(2)第 1 轮打分:【优先级】最高的从库 得分高
优先级是在一开始管理者配置好的.
若优先级一样,进行第二轮!
(3)第 2 轮打分:【和旧主库同步程度】最接近的从库 得分高
如何判断同步程度?上节课讲过 ” 主从库同步时的命令传播过程 “,有个 master/slave_repl_offset 分别记录主从库的同步进度.
==> slave_repl_offset 最接近 master/_repl_offset 的,得分高!
若进度一样,进行第三轮!
(4)第 3 轮打分:【ID号】最小的主库 得分高
ID必不同,这一轮不会再出现打分一样的情况了.
08 | 哨兵集群:哨兵挂了,主从库还能切换吗?
引
上节课,哨兵机制功能2,提到:为了减少哨兵的误判率,我们使用 “哨兵集群机制”.
(1)一个哨兵运行时候G了,主从库还能正常切换吗?
形成哨兵集群的话,有可替代的哨兵
(2)部署哨兵集群式,不许要配置其他哨兵的连接信息。既然各个哨兵不知道彼此的地址,怎么组成集群?
==> pub / sub机制
小结
(1)
通常,我们在解决一个系统问题前,会引入一个新的机制,或者设计一层新的功能.
上节课:为了【实现主从切换】, 引入 【哨兵机制】.
本节课:为了【减少哨兵误判几率】+【但哨兵故障后无法主从切换】,引入 【哨兵集群】.
(2)本节课介绍的 哨兵集群关键机制 如下:
(3)哨兵需要leader,不是随便选一个哨兵就去执行 主从切换的
(4)老师分享一个经验:
1 基于 pub/sub(发布/订阅) 机制 的 哨兵集群组成
(1)哨兵,如何获得 “其他哨兵” 的 ip 和 port 等信息?
利用 “pub/sub” 功能.
主库中维护 “频道”,同一类别的信息在一个频道中.
因此,各个哨兵会把自己的信息发布到“哨兵频道”,这样,哨兵之间可以通过该频道互通有无
(2)哨兵,如何获取 “从库” 的信息?
哨兵向主库发送 INFO 请求,主库给哨兵返回 从库列表.
这样哨兵和从库之间就可以建立联系了.
(3)哨兵,如何获取 “客户端” 的信息?
(如果发生 主从切换 了,需要通知 客户端; 客户端 有必要了解哨兵集群在 监控/选主/切换 过程中发生的各种事件)
==> 依然使用 pub/sub 机制,从而完成 哨兵 和 客户端 之间的同步.
2 基于 pub/sub 机制 的 客户端事件通知
哨兵的本质:一个运行在特定模式下的 “ Redis实例 ” ==> 同主库,都是Redis实例.
==> 那么,哨兵也有 “ 频道的pub/sub功能 ”.
【客户端 订阅 哨兵的相关频道,即可获得对应的信息】
3 由哪个哨兵执行主从切换?==> “投票仲裁”
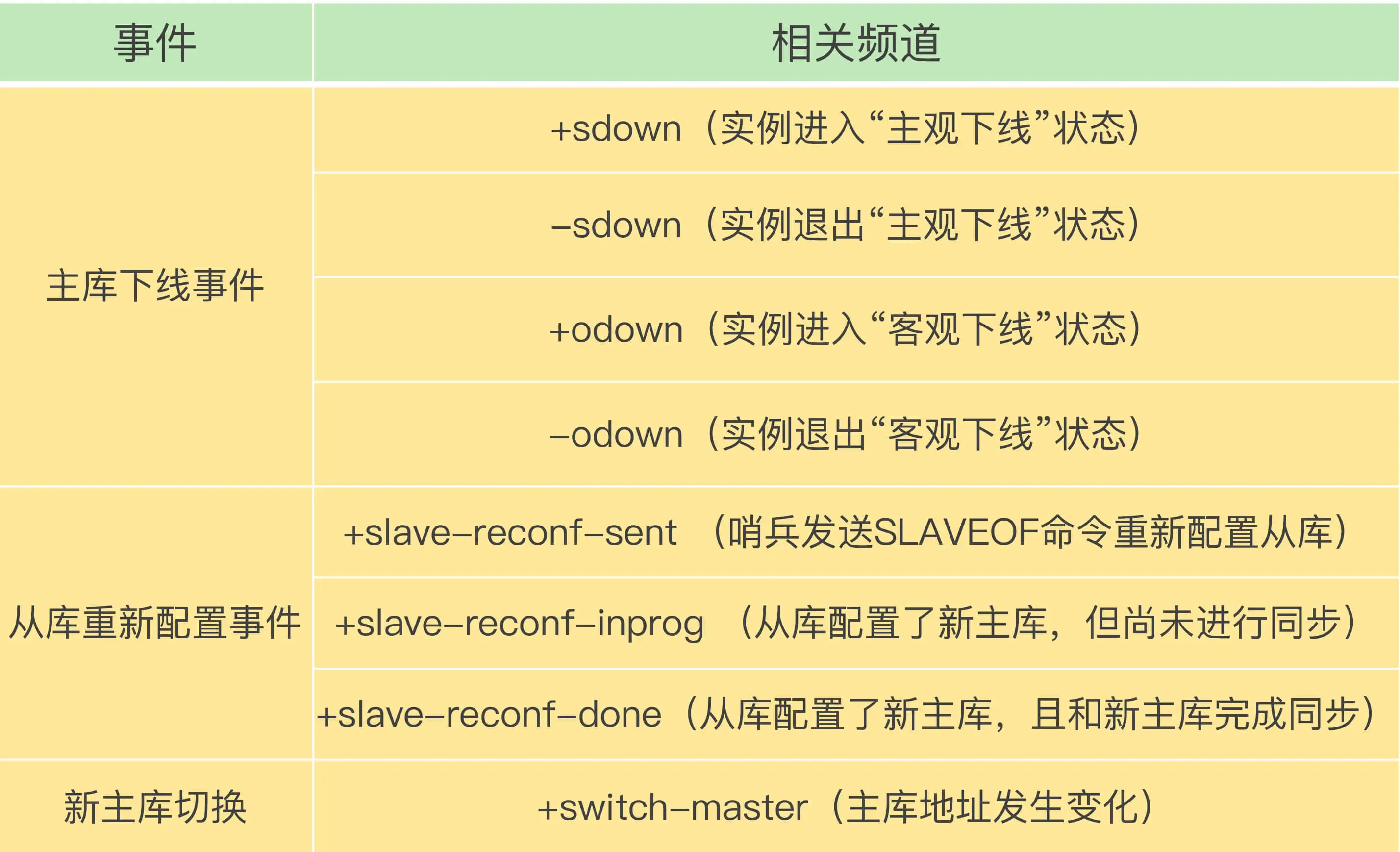
(1)如何确定 “客观下线” ?
① 任何一个哨兵,只要自身判断主库 “主观下线”,就会向 其他哨兵发送 is-master-down-by-adder命令.
② 各哨兵根据自己与主库的连接情况,投出 Y 或者 N 票.
③ 一个哨兵,获得 “足够的Y票”,便可标记主库 “客观下线”.
(因为网络原因,各个哨兵得票时机并不相同)(投票目标数根据 quorum 配置)
(2)如何选定 “哨兵leader”,从而主持 主从切换?
①
【标记“客观下线的哨兵”】发起 “ Leader选举 ” 的投票.
② 任何一个想成为 leader 的哨兵的 要满足的 “两个条件”:
赞成票【半数以上 且 >=quorum设置值】
(3)Leader选举的几点注意事项
① 发起者不一定能成为 Leader
② 根据 “网络传输是否正常” 评判是否能够拿到 赞成票
③ 一轮投票,因为网络原因,【不保证一定能选出leader】
如果没有选出,等过一段时间,会 “重新选举”
④ 【务必配置至少3个哨兵】
09 | 切片集群:数据增多了,是该加内存还是加实例?
引
…
一个案例,所需内存大,用了更大的内存,但是速度慢==>数据大,占内存多,RDB会超级慢!
所以需要想其他办法.
…
我们注意到了 Redis 的切片集群:虽然组建切片集群比较麻烦,但是它可以保存大量数据,而且对 Redis 主线程的阻塞影响较小。切片集群,也叫分片集群,就是指启动多个 Redis 实例组成一个集群,然后按照一定的规则,把收把收到的数据划分成多份,每一份用一个实例来保存。在实际应用 Redis 时,随着用户或业务规模的扩展,保存大量数据的情况通常是无法避免的。而切片集群,就是一个非常好的解决方案。这节课,我们就来学习一下。
小结
这节课,我们学习了 ① 切片集群在保存大量数据方面的优势,② 以及基于哈希槽的数据分布机制和 ③ 客户端定位键值对的方法。
(1)
在应对数据量扩容时,虽然 增加内存这种 纵向扩展 的方法 简单直接,但是会造成数据库的内存过大,导致性能变慢。Redis 切片集群提供了 横向扩展 的模式,也就是使用多个实例,并给每个实例配置一定数量的 哈希槽,数据可以通过 键的哈希值 映射到哈希槽,再通过哈希槽分散保存到不同的实例上。这样做的好处是扩展性好,不管有多少数据,切片集群都能应对。
(2)
集群的实例增减,或者是为了实现负载均衡而进行的 数据重新分布 ,会导致哈希槽和实例的映射关系发生变化,客户端发送请求时,会收到命令执行报错信息。了解了 MOVED 和 ASK 命令,你就不会为这类报错而头疼了。
(3)
1 如何保存更多数据:横向集群扩展 + 纵向内存扩展
(1)什么是 纵向/横向 扩展
在刚刚的案例里,为了保存大量数据,我们使用了大内存云主机和切片集群两种方法。实际上,这两种方法分别对应着 Redis 应对数据量增多的两种方案:纵向扩展(scale up)和横向扩展(scale out)。纵向扩展:升级单个 Redis 实例的资源配置,包括增加内存容量、增加磁盘容量、使用更高配置的 CPU。就像下图中,原来的实例内存是 8GB,硬盘是 50GB,纵向扩展后,内存增加到 24GB,磁盘增加到 150GB。横向扩展:横向增加当前 Redis 实例的个数,就像下图中,原来使用 1 个 8GB 内存、50GB 磁盘的实例,现在使用三个相同配置的实例。
(2)纵向内存扩展 的 优缺点
纵向扩展的好处是,实施起来简单、直接。不过,这个方案也面临两个潜在的问题。① 第一个问题是,当使用 RDB 对数据进行持久化时,如果数据量增加,需要的内存也会增加,主线程 fork 子进程时就可能会阻塞(比如刚刚的例子中的情况)。不过,如果你不要求持久化保存 Redis 数据,那么,纵向扩展会是一个不错的选择。② 不过,这时,你还要面对第二个问题:纵向扩展会受到硬件和成本的限制。这很容易理解,毕竟,把内存从 32GB 扩展到 64GB 还算容易,但是,要想扩充到 1TB,就会面临硬件容量和成本上的限制了。
(3)横向集群扩展 的 优缺点
与纵向扩展相比,横向扩展是一个 扩展性更好 的方案。这是因为,要想保存更多的数据,采用这种方案的话,只用增加 Redis 的实例个数就行了,不用担心单个实例的硬件和成本限制。在面向百万、千万级别的用户规模时,横向扩展的 Redis 切片集群会是一个非常好的选择。不过,在只使用单个实例的时候,数据存在哪儿,客户端访问哪儿,都是非常明确的,但是,切片集群不可避免地涉及到 多个实例的分布式管理问题 。要想把切片集群用起来,我们就需要解决两大问题:
① 数据切片后,在多个实例之间如何分布?
② 客户端怎么确定想要访问的数据在哪个实例上?
2 问题1:数据切片和实例的对应分布关系
(1)切片集群 和 Redis Cluster 的联系与区别
实际上,**切片集群是一种保存大量数据的通用机制**,这个机制可以**有不同的实现方案**。在 Redis 3.0 之前,官方并没有针对切片集群提供具体的方案。从 3.0 开始,官方提供了**一个名为 Redis Cluster 的方案,用于实现切片集群**。Redis Cluster 方案中就规定了 **数据和实例的对应规则**。具体来说,**Redis Cluster 方案采用哈希槽(Hash Slot,接下来我会直接称之为 Slot),来处理数据和实例之间的映射关系**。在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中。
(2)具体映射过程
具体的映射过程分为两大步:
① 首先根据键值对的 key,按照 CRC16 算法计算一个 16 bit 的值;② 然后,再用这个 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。关于 CRC16 算法,不是这节课的重点,你简单看下链接中的资料就可以了。
(3)哈希槽又是如何被映射到具体的 Redis 实例上的呢
① 自动均分
cluster create 命令创建集群,自动把这些槽平均分布在集群实例我们在部署 Redis Cluster 方案时,可以使用 cluster create 命令创建集群,此时,Redis 会自动把这些槽平均分布在集群实例上。例如,如果集群中有 N 个实例,那么,每个实例上的槽个数为 16384/N 个。
② 手动按比例分
使用 cluster meet 命令手动建立实例间的连接,形成集群,再使用 cluster addslots 命令,指定每个实例上的哈希槽个数举个例子,假设集群中**不同 Redis 实例的内存大小配置不一**,如果把哈希槽均分在各个实例上,在保存相同数量的键值对时,和内存大的实例相比,内存小的实例就会有更大的容量压力。遇到这种情况时,你可以根据不同实例的资源配置情况,使用 cluster addslots 命令手动分配哈希槽。一个小提醒,在手动分配哈希槽时,需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作。
**通过哈希槽,切片集群就实现了数据到哈希槽、哈希槽再到实例的分配**。但是,即使实例有了哈希槽的映射信息,客户端又是怎么知道要访问的数据在哪个实例上呢?
3 问题2:客户端如何定位数据
(1)如何定位?集群实例间的信息扩散
在定位键值对数据时,它所处的哈希槽是可以通过计算得到的,这个计算可以在客户端发送请求时来执行。但是,要进一步定位到实例,还需要知道哈希槽分布在哪个实例上。一般来说,客户端和集群实例建立连接后,实例就会把哈希槽的分配信息发给客户端。但是,在集群刚刚创建的时候,每个实例只知道自己被分配了哪些哈希槽,是不知道其他实例拥有的哈希槽信息的。那么,客户端为什么可以在访问任何一个实例时,都能获得所有的哈希槽信息呢?这是因为,**Redis 实例会把自己的哈希槽信息发给和它相连接的其它实例,来完成哈希槽分配信息的扩散。当实例之间相互连接后,每个实例就有所有哈希槽的映射关系了**。(有点哨兵的 订阅/发布 内味了)客户端收到哈希槽信息后,会把哈希槽信息缓存在本地。当客户端请求键值对时,会先计算键所对应的哈希槽,然后就可以给相应的实例发送请求了。
(2)实例和哈希槽的对应关系改变的后果
(感觉就是rehash嘛)① 在集群中,实例有新增或删除,Redis 需要重新分配哈希槽;② 为了负载均衡,Redis 需要把哈希槽在所有实例上重新分布一遍。(负载均衡?不懂)此时,实例之间还可以通过相互传递消息,获得最新的哈希槽分配信息,但是,客户端是无法主动感知这些变化的。这就会导致,它缓存的分配信息和最新的分配信息就不一致了,那该怎么办呢?
==>重定向机制
(3)Redis Cluster 方案 的 重定向机制
Redis Cluster 方案提供了一种重定向机制,所谓的“重定向”,就是指,**客户端给一个实例发送数据读写操作时,这个实例上并没有相应的数据,客户端要再给一个新实例发送操作命令**。那客户端又是怎么知道重定向时的新实例的访问地址呢?**当客户端把一个键值对的操作请求发给一个实例时,如果这个实例上并没有这个键值对映射的哈希槽,那么,这个实例就会给客户端返回下面的 MOVED 命令响应结果,这个结果中就包含了新实例的访问地址**。
GET hello:key(error)MOVED 13320 172.16.19.5:6379
其中,MOVED 命令表示,客户端请求的键值对所在的哈希槽 13320,实际是在 172.16.19.5 这个实例上。**通过返回的 MOVED 命令,就相当于把哈希槽所在的新实例的信息告诉给客户端了**。这样一来,客户端就可以直接和 172.16.19.5 连接,并发送操作请求了。
(4)MOVED 重定向命令的使用方法
① 像实例2 请求;② 实例 2 给客户端返回一条 MOVED 命令,把 Slot 2 的最新位置(也就是在实例 3 上),返回给客户端③ 客户端就会再次向实例 3 发送请求,同时还会更新本地缓存,把 Slot 2 与实例的对应关系更新过来
(5)迁移未完成时发送请求:ASK报错信息
Slot a 中的数据只有一部分迁移到了实例 b,还有部分数据没有迁移。**在这种迁移部分完成的情况下,客户端就会收到一条 ASK 报错信息**。此时,客户端需要先给 Slot b 所在的 这个实例**发送一个 ASKING 命令**。这个命令的意思是,**让这个实例允许执行客户端接下来发送的命令**。然后,客户端**再向这个实例发送 GET 命令,以读取数据**。ASK 命令表示两层含义:第一,表明 Slot 数据还在迁移中;第二,ASK 命令把客户端所请求数据的最新实例地址返回给客户端,此时,客户端需要给实例 3 发送 ASKING 命令,然后再发送操作命令。和 MOVED 命令不同,**ASK 命令并不会更新客户端缓存的哈希槽分配信息**。所以,在上图中,如果客户端再次请求 Slot 2 中的数据,它还是会给实例 2 发送请求。这也就是说,**ASK 命令的作用只是让客户端能给新实例发送一次请求,而不像 MOVED 命令那样,会更改本地缓存,让后续所有命令都发往新实例**。
实践篇:数据结构
实践篇:性能和内存
实践篇:缓存
实践篇:锁
实践篇:集群
结尾

若有收获,就点个赞吧
0 人点赞
