我来当个课代表吧,如有遗漏欢迎补充(=・ω・=)
JVM从整体架构上分类讲解:Class文件,类加载子系统,运行时数据区,执行引擎,本地接口,本地方法栈
Class文件结构
参考文章:
https://blog.csdn.net/luanlouis/article/details/39960815
https://louluan.blog.csdn.net/article/details/40301985
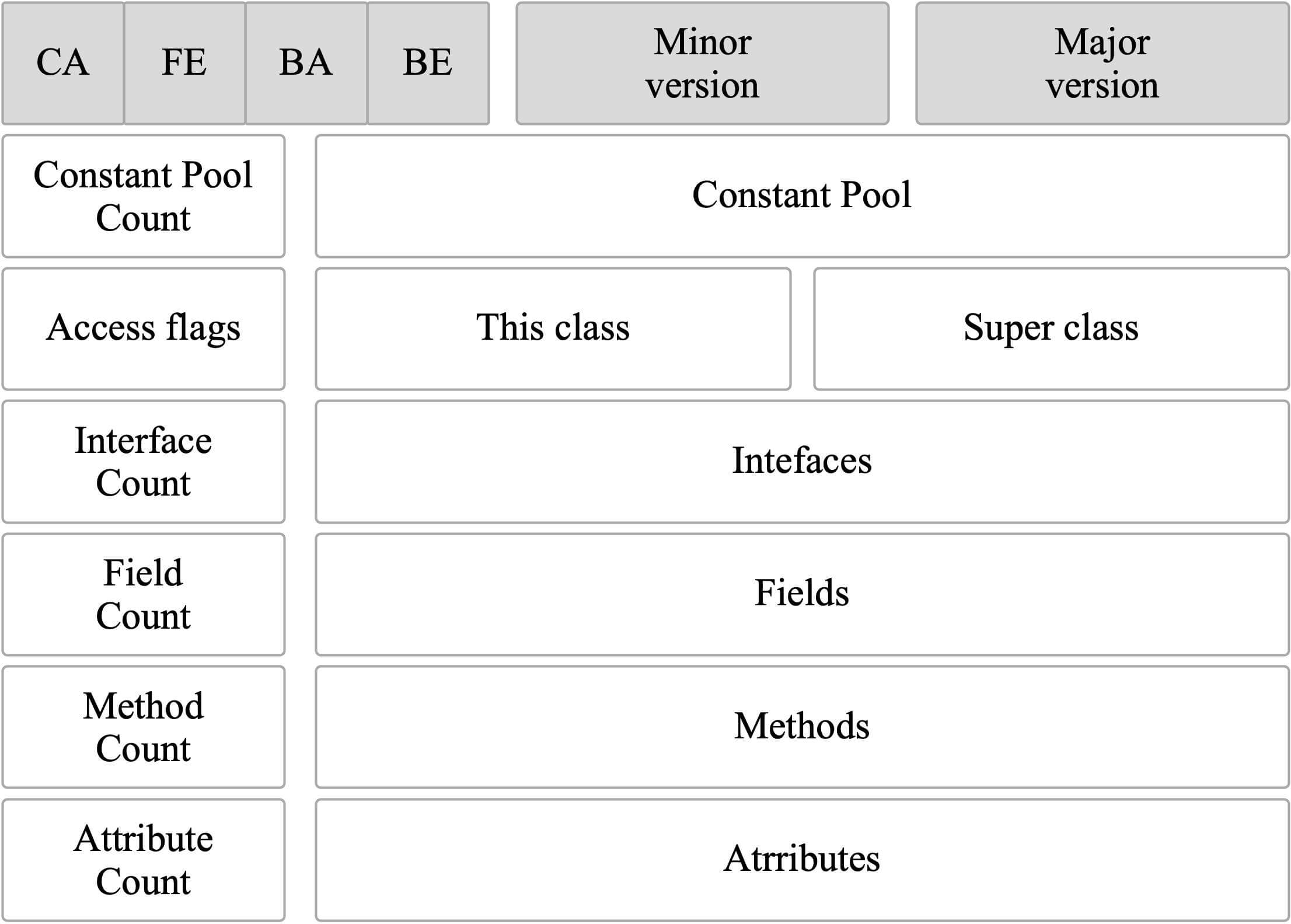
(这块基本和周志明第六章6.3类文件结构这块差不多啊,最后一个属性表没有讲)
8个字节为单位基础的二进制流就是class文件经过javac编译后的
(1)魔数
他里面的结构开始就是一个“魔术” :魔术干嘛的?<br />==> 标记它是一个class文件,宽泛说就是 “标注文件类型”。
(2)“次版本号” 和 “主版本号”
然后 “次版本号” 和 “主版本号” 标志JDK版本,为了处理JDK兼容性的问题。<br />比如高版本的JDK在低版本的JDK上运行不了,这就是版本号起的作用。
(3)“常量池计数器”
接下来是“常量池计数器”,记录后面常量池中常量的个数。常量池这里补充一下,因为会引申出硬核的面试知识点。它里面也有 “字面量” “符号引用” ,符号引用 包括 packege名字,类和接口全限定类名,字段名称,方法名称,字段描述符,方法描述符,方法句柄,方法类型,动态调用点,动态常量等。
——————————————————————————————————————————————————————————————————————————————————————-
如何读取解读class文件中的常量池编码?
==> 见慕课网JVM课程,及笔记:对应章节:2-6 阅读Class字节码:常量池
总的来说,这块分为两部分:
常量池计数器(记录有多少个常量) + 常量池
常量池中,每一个常量编码结构为:
常量类型(根据编码去查表) + 地址长度 + 地址(指向真正的全限定类名等)
——————————————————————————————————————————————————————————————————————————————————————-
常量池有啥面试题?<br />(1)java字段名和方法名写名称时有长度限制吗?<br />常量池中有个constant_utf8_info类型,这个会存储字面量类型的数值,长度最大是65535,即64kb.
(2)常量计数器从0开始还是1开始?
1开始。0得留给没有父类(object类)、没有类名的(匿名内部类),即留给“无法指向的东西”。
比如匿名内部类没有名称,也需要吧类名存储在常量池constant_utf8_info,那就只能存在第0号位置;又比如object类,它没有父类,所以它的父类索引也需要指向常量池中第0位。
(4)访问标志
标注类方法的访问属性,比如public private final这种。
(5)类索引,父类索引,接口索引:全限定类名的寻址
对于类索引,存全限定类名。比如student类的package后面的包名,先指向 constant_class_info 存的时候指向 constant_utf8_info ,先是类,再才是对象。这样连着找就能找到student类的全限定类名。对于extend继承的父类,这种父类索引,先指向 constant_class_info 存的时候指向 constant_utf8_info。(这块没懂)接口再java中都是可以实现的,所以它是一个集合,接口索引集合前得有一个接口索引计数器(???)来记录有多少个接口。其全限定类名的寻址和之前两个一样的,只不过它这里不指向 constant_class_info ,而是 constant_interface_info
(6)字段表集合
( 类中常量(final static String)在字节码中的存储方式 )接口索引集合后面是“字段表”,里面有很多字段,所以前面理所当然需要字段表计数器。<br />字段表这里多提一嘴 constant 属性,final 和 static 同时修饰 string 类型数据(必须是这个组合),就会存在这个 constant 属性里,这样避免类还没有加载时就能用了(?????),这是效率上的提升.
(7)方法表集合
( 方法中代码在字节码中的存储方式(方法表Code属性,JVM字节码指令) )字段表以后就是方法表,方法表里有很多方法,其中就用方法表计数器。<br />方法表里就自带有方法表计数器。<br />方法表里也有自带的属性块:CODE,这里存的就是这些方法,这里存的是什么呢?你这些方法的代码编译成jvm 的执行指令以后,再存入CODE中。
(8)属性表集合
CODE(就是(7)中提到的)中有一些重要的属性,待会还要用到(很重要):操作数栈的最大深度,局部变量表最大空间,方法代码的长度等。java文件编译以后这些值就已经确定了。
类加载子系统
内容多,开始就用 “JVM类加载整体流程” 串一遍.
JVM类加载流程:不仅仅是“加载-练级—链接-初始化”!
如果你在博客上看,那么这个流程就是:加载 链接(验证 准备 解析) 初始化。这个过程没问题,但是要说起细节,那么就有问题了,太绝对了!<br /> 真正的类加载流程是分为7-8步,一会解释为什么不是一个绝对步数。1加载 + 2验证 + 3加载 + 4加载 + 5验证 + 6验证 + 7准备 +(8初始化)<br />==> 第八步初始化不定,好像还少了解析.
第一步 加载 是 “静态加载”。
java文件编译为class文件后,此时第一次加载,获得class文件字节流;
第二步 验证1 “连接 . 验证 . 文件格式验证”。
验证有四步,第一步就是文件格式验证,验证魔术和主次版本号;
第三步 继续加载,已经发现是class文件,且符合JVM版本要求。
此时需要把这个class字节码文件加载到 “方法区”,把文件从 静态存储文件 转换为 运行时数据结构。
运行时数据结构 就会涉及 class文件中的常量池 和 运行时数据区的运行时常量池有什么联系?(之后再说)
第四步 加载
基于第三步到达方法区的运行时数据区,会【在java堆内存生成当前类的class类对象】,作为方法区这个类的各种访问入口。
第五步 验证2.元数据验证
第六步 验证3.字节码验证
第七步 准备。
验证的第四步符号引用验证还有没处理,怎么就到准备了?<br /> 准备完了,该干嘛了?不知道了,我们先说一下 解析什么时候发生.<br /> 目前来看,解析是一个游离性的状态:从第一步加载class字节流的时候,解析可能已经开始了!<br /> 解析代表什么?代表了验证里的第四步——符号引用验证,把符号引用转化为直接引用。 解析可能就随着整个类加载流程一致在做。<br /> 但是有一点可以肯定,解析这一步必然在初始化之前完成,但你说它穿插在哪一步,不知道。
第八步 初始化
现在再来解释,一开始说博客的说法的不对是什么意思,如下:
加载和验证是穿插的,且解析具体在哪一步是确定不了的!
加载阶段
双亲委派模型
好了现在就可以开始分阶段引出面试知识点了,比如一些技术细节.比如加载里面肯定会问 “双亲委派模型”,至少要答出来启动类加载器,扩展类加载器,系统类/应用类加载器。当然还可以继承方法实现classloader,做自定义类加载器.
(1)这些加载器的功能?
启动类加载器加载什么?javahome下的lib目录.
扩展类加载器加载什么?javahome下的lib目录下的ext目录.
应用类加载器加载什么?项目代码.
自定义类加载器加载什么?自定义的想让它加载的类.
(2)什么是双亲委派?
双亲委派分为 “向上委托” + “向下委派”.<br /> studen t类上来先到系统类加载器,它不管,向上委托到扩展类加载器,并再次委托给“启动类”加载器。<br />启动类加载器发现你不是home/lib目录下的,它直接不加载,向下委派给“扩展类”加载器。<br />然后又委派给“应用类”加载器,终于发现是我自己写的,然后我自己加载。
.
(3)双亲委派好处是什么?
顺序加载: 所有类得先加载父类把,比如object类,应用层和扩展类都不加载,传到启动类加载器,它说它自己加载,因为这是 javahome / lib 下的。安全/唯一性:比如说自己写了自定义类加载器,我自己写了一个java.lang.string,开始搞事情,你原生就有了,你还写。 那么此时你写的这个string还能加载吗?还能的。 ==>因为JVM确定一个类是依靠 “类加载器 + 全限定类名” 确定的,原生的string由启动类加载器加载,你自己写的由应用类或者自定义类加载器加载,搞出来是不一样的。针对安全性的这个例子这里,又要引申出 javase 里的一个关键词:instanceof。这玩意判别一个类是否属于另一个类。此时,你用原生的string去instanceof你自己写的string,此时返回true还是false?答案是false,这个instanceof 依靠的就是 “类名 + 类加载器” 判断从属关系的!这就保证了类的唯一性
数组加载
继续说加载这一块的问题。这一块还有一个大问题:数组加载.
(1)JVM加载数组和加载类有什么区别?
好,这个问题非常 NB。<br />① 首先说一下啊,数组不是类加载器加载的,是 jvm 直接在内存中动态构造出内存区域了。
② 但是问题又来了。数组有类型,这个类型嘛还是得由类加载器加载的。
③ 那么问题又来了,数组如何标记这个唯一类型的?这里要分两种情况来说。.<br /> 引用类型:首先用student这个来举例,它由应用类加载器加载,那么数组就会被标记在 “应用/系统类加载器的类名空间(???啥玩意这是)”。<br /> 基本数据类型:其次,如果数组用的是基本数据类型,如int类型,那么它直接把数字标记在 “启动类加载器” 的类名空间上。
链接阶段:各步骤作用
链接分为三步:验证 准备 解析.
验证又分4步: 文件格式验证 + 元数据验证 + 字节码验证 + 符号引用验证.
准备:初始化0值。public static int a = 123; 准备阶段a=0而不是123,在初始化阶段才是123.
解析 和 符号引用:符号引用转换为直接引用.
初始化阶段:什么时候jvm立即执行初始化?
java代码真正开始执行了.<br /> 调用类的构造器 clinit 方法,这个方法我们看不到,从java文件编译成class文件时,自动生成的,所以我们看不到.什么时候 jvm 立即对类初始化?<br />(1)到 new、getstatic、putstatic 或 invokestatic 四条字节码指令<br /> 不是我们手敲的new,这是 jvm 自己能识别的。为什么new 数组时候不初始化?因为这个时候是 new array,不包含在刚才那4个指令,所以不会触发初始化.<br />(2)反射<br />(3)父类没有初始化,先初始化父类<br />(4)main函数<br />(5)invokeMethodHandler 这些用来解析的<br />(6)jdk1.8以后加入的一些默认方法——defalut修饰的接口方法
类加载子系统内容,到此为止!!!
内存区域
运行时数据区
基础:运行时数据区包括什么?
两方面回答:
线程共享:方法区,堆<br /> 线程私有:程序计数器,两个栈(虚拟机栈,本地方法栈)
后面啊,就分别介绍这几个部分.
私有:程序计数器
首先得知道这是一块非常小的内存空间,基本上没有出现过OOM异常.
作用:控制代码执行的位置.
共享:方法区
(1)作用
作用:存储类型信息!常量,静态变量,包括即时编译之后代码缓存数据。
之前提到的,加载阶段第三/四阶段,提供方法区入口
回顾:
第三步 继续加载,已经发现是class文件,且符合JVM版本要求。此时需要把这个class字节码文件加载到 “方法区”,把文件从 静态存储文件 转换为 运行时数据结构。运行时数据结构 就会涉及 class文件中的常量池 和 运行时数据区的运行时常量池有什么联系?(之后再说)
第四步加载,基于第三步到达方法区的运行时数据区,会【在java堆内存生成当前类的class类对象】,作为方法区这个类的各种访问入口。
(2)代码缓存数据为啥在方法区?
刚才说 class 文件结构部分,方法区里面有个code属性,这里面保存了 jvm 的执行指令码。这些编译后的代码在方法区。
(3)方法区 元空间 永久代
提到方法区,JDK1.8之前,还把“方法区”叫“永久代”,1.8以后把他废弃了,叫元空间。而“元空间就是方法区”!<br /> 那元空间有什么好处?元空间可以使用服务器所有内存资源,不会有最高限制!它的最高限制就是所在服务器的最高限制!
(4)运行时常量池与Class文件中的常量池有何区别?
之前提到,加载中,有一个静态class二进制文件,会转化为 运行时数据区 中的东西。那么这里就有问题了:运行时常量池与Class文件中的常量池有何区别?这个问题非常经典,Class文件中的常量池 转化为 运行时常量池 这是一个动态的转化,运行时常量池子在项目运行中才会使用的,那么运行中如何使用?千万别忘了string中有个string.intern方法,这个方法能在项目运行中直接把想要放入的数据放入到常量池中,这个方法非常变态,因为这个常量池是javac生成,放入方法区,形成的运行时的结构,你却能直接放入,这就代表了动态性。
共享:堆
(1)
堆:存放对象.
对象有 对象头,实例数据,对齐填充。
对象头有 hashcode…..(都是一些细节的概念)
….(这里说了一堆…)
(2)前两年热点面试题:64位 JVM 在 new Object() 操作时,对象实例占多少个字节?(没懂)
markword 8 字节,因为 java 默认使用了 calssPointer 压缩,classpointer 4 字节,对象实例0字节, padding 4 字节 因此是 16 字节 .<br /> 如果没开启 classpointer 默认压缩,markword 8 字节,classpointer 8 字节,对象实例0字节,padding 0 字节 也是 16 字节.
私有:虚拟机栈与本地方法栈
为了从堆引到这两个栈,先引出“线程”,那如何从对象引入到线程?从下面这个题开始说:
(1)对象 如何被 线程 访问定位?
你一个线程想用 object.hashcode 方法,线程怎么定位到object对象?这个很底层。一般就两个方式:使用句柄(中间有个句柄池,帮我们指向)<br />使用直接指针(当前对象直接指向内存对象).∴ 直接指针一次寻址,如果地址发生变化就很烦,这个指针在线程里,还得改,不好。这时候句柄作用就体现了,只需要改句柄池到对象的链接,线程到句柄池的不用改。这样就引入到线程了,这就能讲栈了.
(2)栈帧(结构, 作用)
JVM栈和本地方法栈只讲一个,俩仅仅是执行的地方不同。.只讲JVM栈JVM中有一个非常重要的结构:栈帧。 细细道来!
(1)栈帧里面有:
方法局部变量表(class文件方法表的code属性里,有确认最大局部变量表大小的属性——slot,槽)操作数栈、动态链接、方法返回地址 等(其他不用管了).
(2)栈帧干啥的?
调用一次方法,就会有一个栈帧。<br /> 开始调用入栈,调用完会出栈。JVM栈中都是栈帧.
(3)方法局部变量表存的啥?
对应着JVM栈中的一个栈帧: 把方法的局部变量,一些参数存储在这里.这些啥时候存储的?java文件javac编译成class文件时,直接存放在 方法表 附带的属性表 中的 CODE 中。
(4)操作数栈是啥?
方法的栈的最大调用深度!<br /> overstackflow就是这的异常,超过栈的最大容量了.
(5)动态链接
方法调用时连接到其他方法其他类。
(6)返回地址
方法谁调用的,调用方法结束,把调用方法结果返回去。这又分两种情况:正常退出 异常退出.
.
上节课这个 “堆内存结构” 没有展开细说,这块知识和 “垃圾回收” 联系非常紧密,所以 “堆内存和垃圾回收结合起来讲”。 从JVM整体架构来讲,堆内存结构属于运行时数据区,垃圾收集器属于执行引擎。jvm运行中,执行引擎和运行时数据区每时每刻都在进行交互。所以这俩集合一起说,更加系统,更加容易让大家接受。这部分内容分为两个视频去讲,知识点太多
堆
本节从一个简单的问题引入.
JVM堆内存结构简介
JVM堆内存结构,分为新生代/老年代,新生代又分为(eden区,s0区,s1区,占比8:1:1)。<br />问题来了,所有垃圾回收器(这不是堆内存吗?怎么就垃圾回收器了)都是这样的内存分区结构吗?8:1:1这种比例基于什么思想呢?(1)先说第一个,Java中垃圾回收器是很多的,并不是所有垃圾回收器都按这种情况进行内存分区。比如基于 标记-清除 算法的垃圾回收器不是这样的,这块后面具体再说,只是举个例子。(2)811这个比例,基于 “标记复制”这样一个算法思想。再次印证对内存结构不都是这样划分的.
JVM对象在 年轻代 的移动过程
再次引申:为什么要有这个所谓的S区(幸存者区/survive区)?还一下弄俩?这时要结合 “jvm对象内存空间移动过程” 来讲,这样刚才的问题就不攻自破咯。来一个场景,假如这个时候,项目刚刚运行起来,也就是说 jvm刚把项目加载进来。此时 minorgc / fullgc 都还没发生过。
① 第一次minorgc
此时项目开始运行了,我们 new 的对象放到 eden 区。
放了一段时间以后,进行了第一次Minorgc(年轻代的垃圾回收):第一次垃圾回收只针对eden区. eden区存活的对象会移动到s0区,并且年龄 +1. 同时清空eden区。
此时,eden区是空的,s0为存活时间为1岁的对象,s1也是空的。
② 第二次垃圾回收
程序继续执行,new的对象放到eden区,直到发生第二次垃圾回收。
第二次垃圾回收,同时回收 eden区 和 s0区,跟第一次不一样咯。并将eden区和s0区存活的对象完全移动到s1区,eden过去的变成1岁,s0过去的变成2岁。同时清空 eden 区和 s0 区。
此时,JVM会做一个非常重要的转换:s1和s0角色互换。这是角色互换,“不是复制”!<br /> 最后,eden和s1区没有对象,s0有对象.
③ 第三次垃圾回收,及之后的
继续运行,迎来第三次垃圾回收。逻辑同第二次,相应的年龄+1
==>至此可以解答一开始的问题
(1)为什么有幸存区?
就是为了接受 eden 区存活对象,清空eden区,为下一次新对象的创建做准备。
(2)为什么有两个?
eden 区需要一块地方存存活的;存eden区存活对象的s0,也要垃圾回收,因此也需要一块地方,所以搞出了另一个s区,说白了就是eden和s0需要缓冲区域。也能避免eden区和s0区的 “空间碎片化”。因为把 eden和s0的存活对象“复制”到了s1,这俩区再一起清空,这样内存空间就完整了。这一步就是基于 “标志-复制算法” 思想.
JVM对象在 老年代 的移动过程
刚才都是再讲对象在 “年轻代” 的移动情况,现在讲讲老年代,分为四种情况。
(1)年满15周岁(jvm阈值)
(2)特别大的对象
超过了 max_tenuring_thread_hold 这个参数的阈值,此时直接把对象创建在老年代。
(3)幸存者空间中,相同年龄所有对象大小的总和,大于幸存者空间的一半,年龄大于等于该年龄对象,可以直接进入老年代
举个例子。如果s区只能存5个对象,里面存了5个,年龄为 1 2 2 2 3岁。2岁的超过了空间的一半,这 [ 3个2岁的 + 1个3岁的(>=2岁的)] 也要移动到老年代.
(4)eden区的存货对象大小超过了survivor区的大小,直接放入老年代.
这里s区指1个s区的大小。因为永远有1个s区空的,所以年轻代空间利用率就90%.
针对老年代:空间分配担保策略
那么问题来了,一旦老年代满了,就会引发 fullGC 啊,说明每次 MinorGC 都是在对老年代进行挑战,老年代慌啊,它满了不久fullGC了?JVM为了安抚老年代,提出了 “空间分配担保策略”。来看看一个场景:minorgc发生前(注意这个前提),年轻代有1G对象。此时老年代怕了,jvm就会在minorGC发生前,检查一下 “老年代最大可用连续空间”。比如说,jvm发现老年带最大可用连续空间为2g,虚拟机机会告诉老年代:你空间很足,不慌。这时候老年代就放心了。但是,更多的情况是,老年代可用连续空间不足500M。这时候JVM不能直接告诉老年代啊,老年代慌啊。这个时候JVM检查完后,会进行第二次检查:检查自己的参数 handle promotion failure,看这个参数设置的值,“是否允许担保失败”,是一个 boolean 形式的值。
(1)如果允许,进行第三次检查:老年代最大连续可用空间,是否大于,历次晋升到老年代对象的平均大小。 比如这个平均值是300M,小于500M。此时,JVM会尝试进行minorGC,当然,这次minorGC是有风险的,但是允许担保失败。
假如你700M呢,那没辙了,fullGC 吧,不尝试MinorGC了,直接fullGC腾出空间.
(2)如果不允许担保失败呢?直接fullGC,没有第三次检查了
==>现在,更专业的说一下:什么是空间分配担保?(面试就说这个)
mgc前,JVM必须检查【老年代最大可用连续空间 是否大于 新生代所有对象总空间】
(1)如果大于,这次mgc安全
(2)如果不成立,检查 handle promotion failure,看看是否允许担保失败.
如果允许,继续检查 “老年代最大连续可用空间,是否大于,历次晋升到老年代对象的平均大小”。如果大于,尝试一次有风险的 minorGC,如果小于,进行 fullGC.<br /> 如果不允许,直接进行 fullGC.
GC过程是什么?JVM如何判断对象是否存活?——可达性分析
前面一直讲GC,那么就引申出这里的问题:你怎么知道这些对象是否需要GC?——可达性分析
可达性分析算法是什么
可达性分析算法:根据一系列 gcroots 根节点,从这些点开始进行 “引用链的搜索”,如果对象搜索不到,证明对象不可达。此时会在 “三色标记算法” 帮助下标记为 “白色不可达”,最终引发垃圾回收.
根据可达性分析又引申出5个问题:
gcroot是什么?<br /> 引用链是什么?<br /> 对象不可达意味着什么?<br /> 三色标记算法是什么?<br /> 有没有跨代引用的问题?
一一解释。
gcroot是什么?
可达性分析的起点,包括如下类型:
1 虚拟机栈中 “引用的对象”,也就是栈帧中的本地变量;2 本地方法栈也要有 “引用对象”.3 4 方法区中 “静态属性引用的对象”,“常量引用对象”.
目前是两个栈,两个方法区.
5 JVM内部也有引用.6 锁,其获取释放都需要对象.…
引用链是什么?
首先提到引用类型:强软弱虚
强:最常见的,x = new Object这种
软:有用,但不是必需的。系统即将要发生内存溢出时,会把这些对象列进回收范围,进行第二次垃圾回收。这次回收还没有足够的内存时,才会抛出异常.
弱:只能生存到下一次垃圾回收
虚:没办法通过虚引用找到对象实例。什么场景下用?后续非JVM视频中分享源码
对象不可达意味着什么?
意味这个对象要被回收。
那会被立刻回收吗?不对,“ 还得看finalize方法是否被无缘无故复写且调用过 ”。如下:
(弹幕说这段不准确)首先把它放到 f-q 队列,该队列起一条低优先级线程读取这些对象,并逐个调用对象的finalize方法。 如果对象的finalize方法之前被覆盖过,被调用过,那么JVM这个时候就会将该对象置为没有必要执行垃圾回收,此时该对象就逃过了垃圾回收。
三色标记算法是什么?
白黑灰:白色不可达,黑色已访问,灰色未扫描(灰色下节课讲)
有没有跨代引用的问题?
比如mGC发生时,该对象被老年代对象引用咋办?
JVM引入了“记忆集”,记录 “从 非收集区域 指向 收集区域 的指针集合的抽象数据结构”.
minorGC里面有 记忆集,在年轻代。记录从 老年代 到 年轻代 指针的集合。
如果记忆集中有当前对象,说明老年代有跨代引用,这个对象就不能被回收。
记忆集具体的结构可以去看书。
垃圾回收机制
垃圾回收1:垃圾回收算法
就三种.
标记清除算法
不需要分区,就一块内存空间,不分什么eden,s0,s1啥的。缺点:如果被回收的话,直接把这个对象拿掉。容易出现大量“空间碎片”,导致没有太多“连续可用空间”。有的大一点的对象如果找不到连续可用空间,会直接进入老年代。优点:很快,找到直接删除.
标记复制算法
分区:eden,s0,s1.缺点:空间浪费,s1永远是空缺的<br /> 优点:可以针对放新对象的位置,有 “很大的连续内存空间”
标记整理算法(基于标记复制)
因为标记复制算法存在空间浪费,考虑处理一下,即为标记复制算法的升级版。(???这里是不是写错了,感觉是针对 标记清除 啊?)第一步:标记清除(就第一个算法),此时内存空间很散碎<br /> 第二步:整理内存空间(不是复制,在当前空间整理),把存活对象放到一块去
垃圾回收2:垃圾回收器(除G1)
垃圾回收器种类较多。
常见的有 三个新生代 + 三个老年代 + G1(新/老年代均可用)。
G1下一期连同JVM调优一起说,本期说其他的垃圾回收器。
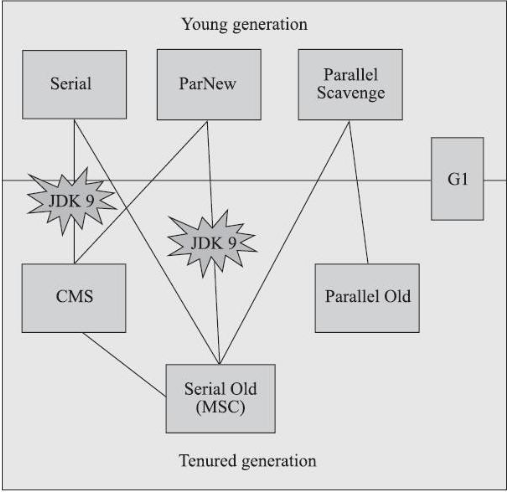
新生代垃圾回收器
serial / ParNew / Parallel Scavenge 这三个是年轻代的垃圾回收器.
(1)S.. :单线程
是 单线程 垃圾回收器。如果服务器单核,使用这个收集器最快最理想.
单线程垃圾收集时,其他线程在干嘛?会不会有CPU时间切片轮询?
不会。只要开始垃圾收集,其他线程必须停止。
至于为什么,后面讲 stw 和 安全点 时再说.
(2)ParNew:多线程
这个是serial收集器的多线程版本,这里也体现出了垃圾收集器的衍生过程。
除了多线程这个特点,完全与serial收集器一样,就多了一个多线程功能。
(3)p.. s..w 多线程:吞吐量
有了单/多线程,就想着怎么搞一个 “又能多线程提升速度,又能关注吞吐量” 的功能。
标记复制算法,进行了分区。
新生代收集器 + 多线程 + psw收集器特点“吞吐量控制”
什么是吞吐量?吞吐量 = 用户代码运行时间 / ( 运行用户代码时间 + 运行垃圾回收器的时间 ).
代码运行10s,垃圾回收器10s,吞吐量 = 10 / (10 + 10)=50%。
这个收集器提供了一些参数,才能控制吞吐量。
如果想概念吞吐量,只能改变(垃圾回收器运行时间)
==> 多次运行,10s拆成两次5s来运行,但是这样会非常危险,比如你设置100%吞吐,那么会连续执行minorGC,所以设置参数的时候一定要设置成jvm垃圾回收器可接受的,不要贪
老年代垃圾回收器
新生代三个是有演变时间的.
老年代比较好记忆.
其中 serialOld 与新生代 serial 对应,po 与新生代 ps 对应.
新生代的parNew没得老年代与之对应的,老年代的另外一个叫CMS
(1)
SO也是一个单线程垃圾回收器,只不过在老年代,用的是“标记整理算法”,这一点和新生代小有不同
单核服务器下运行非常畅快
(2)Po 多线程并发
和新生代的PS协作
PO也是多线程,也是基于“标记整理“,JDK1.6才提供.
非常尴尬,只能和新生代PS合作。CMS出了以后基本不用这个了,这个就不说了
记住三个特点即可:”多线程并发“ + ”控制吞吐量“ + ”标记整理算法“
(??之前哪个psw好像是 标记复制??)
(3)CMS【小重点】
全称:concurrent mark swap,多线程标记清除
目标:最短回收停顿时间
CMS一处,得到广泛应用.
CMS中这个M——mark 和 S——swap很关键,直接说明了,”标记“和”清除“是CMS执行过程中,很重要的一个过程。
① CMS里怎么操作?
三个mark一清除:初始标记 + 并发标记 + 重新标记 + 并发清除。
注意,1/3步需要stw:”初始标记“ 和 ”重新标记“时,JVM需要停顿所有线程。这些线程停顿时被挂起了,线程处于”内核态“,至于挂到哪里了,之后再说。
==>总结:一三步cas + 3 mark一清除 + 一三步要stw
②
初始标记:标记 gcroots 能直接关联到的对象。
并发标记:我该做我的并发收集,你该做你的用户线程,不需要停顿你.
重新标记:并发标记阶段产生了新的垃圾(我扫地,你还往地上嗑瓜子)
并发清除
③ 优缺点
CMS是继G1以来,老年代最靠谱的垃圾收集器。JDK9之前,老年代都得靠CMS。
3个缺点:
<1> 对资源处理非常敏感。CMS第二步是并发标记,会占用服务器的线程数,占用了就会影响项目里面所运行使用的线程数,即”占用资源“,导致项目可用资源不足。
对于单核服务器,CMS默认启动 (1+3)/4=1个线程
对于4核服务器,CMS默认启动 (4+3)/4=1.75个线程
对于x核服务器,CMS默认启动 (x+3)/4个线程
<2> 处理不了 浮动垃圾
并发的 failed 导致 fullGC 的产生.
CMS并发标记 并发清除阶段,用户线程还在继续运行,就会有新的对象产生,就会有对象失去可达性。那这部分垃圾,以及并发清除中产生的垃圾,收集不了了,我标记不上了。
如果这个时候,服务器被疯狂访问,大致大量对象的堆积,最后导致FullGC也是非常有可能的。
<3> CMS基于”标记清除算法“,这种算法就会导致”空间碎片化“时间
==>由此可见,CMS的快建立于 ”并发“ + ”标记清除“ 这两种提升速度的方式之上。
STW【大重点】
先引出一个概念”根节点枚举“
根节点枚举
所有垃圾回收器在 “根节点枚举” 这一步都得暂停所有线程。当开始进行所谓的垃圾收集的 ”标记阶段“ ,要保证开始垃圾收集时,所有对象 ”一定要在一致性快照里进行“。如果不知道当前状态,后期的标记无法进行。 这里的 ”一致性快照“ ,就是”根节点枚举期间“,所有线程突然停止不动,即STW。
安全点
垃圾回收,根节点枚举的时候,这些线程应该在哪啊?==> 安全点<br /> 垃圾收集时,所有正在执行项目的用户线程达到一个”特定的位置“,”不会产生新的对象,也不会影响项目的执行,让项目安全的运行下去“.<br /> 哪些是安全点?一些循环,异常跳转,方法返回,方法调用等,不会创建新对象。(这段特别长,复习时候重新听吧….)方法调用刚开始点调用时,进行了类的寻址(之前讲的线程找对象的两种方式:直接指针 和 reference句柄池,找到对象了再去找class文件中常量池的constant class info下的,再到utf-8_info,再拿到全限定类名,然后去方法区找class文件入口 [加载第4步,我们搞了入口] ),即找到了方法区的入口(第三步加载时是class静态加载到运行时数据区的动态class结构)。找到动态class文件,怎么找方法?又涉及到class文件数据结构的方法表,里面有属性表里有CODE,有局部变量表,然后找到方法入口,又找到一些…….
垃圾回收3:G1
其实非常ES,之前都是基于 ”分代理论“ 的垃圾收集器。G1也是基于”分代理论“的垃圾回收器,只不过它在这个理论上做了自己的拓展,”把自己的内存区域分成了很多个大小相等的内存区域块“,是一个基于 ”region/模块“ 的内存布局。G1在JDK9开始被启用,一上来就把搞吞吐量的垃圾收集器(新生代的PSW和老年代的…干掉了)KO了,成为了服务端模式的默认垃圾收集器。CMS 还可以在 JDK9 时使用,但是 JDK9 会警告你 CMS 将来会废弃。G1把内存分成很多快,就可以按照自己的”意愿“进行局部的收集。假设内存分成了10块,我想收集哪一块,就收集哪一块(后面的话讲怎么弄)。
G1中堆内存布局原理
G1不再坚持固定大小,固定分代,而是分为很多个region,每一个 region都可以根据需要去扮演 新生代/老年代/eden…,说明也是基于分代理论,不过是一种拓展。之前的什么大对象,超过xxx阈值,会直接放入老年代。G1的话,大对象的话,会从region中分出一部分区域作为一个”特殊的区域——humagers“,专门存储大对象。只要大小超过一个region容量的一半,就可以判断是一个大对象。<br />一个region的大小我们可以专门去设置,范围在0-32M之间。所以一个对象最大为16M时,会被判断是一个大对象。<br /> 一个 region 32M,一个对象 64M 时,会分配连续的 region 存储大对象。
G1的目标是”预测停顿时间“
堆内存设置了很多模块,G1会”判断每个模块的停顿价值的大小“。如果设置(max GC pause millions)每次收集最多停顿200ms,根据你设置的时间 ”找能够收集的region“,比如说10个region需要300ms,那么就会按比例降低,我只收6个region。当然这里,有一个和之前吞吐量一样的问题,如果你把这个停顿时间设置的太短,就会经常发生垃圾收集,因此一定要根据项目需要进行region的设立。
如何解决跨代对象引用问题
之前提到了”记忆集“。G1也是用这个,不过它的记忆集要复杂,有很多个region,对于卡表的设计是”双向卡表设计“,更加复杂了。
G1垃圾回收步骤
初始标记:和CMS一样的。需要STW,这一步”根结点枚举“,”达到安全点“,一定要STW
并发标记:无需STW
最终标记:CMS里这一步是重新标记,处理并发标记中新产生的垃圾。
这一步用户线程一定要停顿。需要STW。
筛选回收:CMS叫”并发清除“,进行一个mGC/fullGC。
G1不是这样的,它会根据”用户设定的max_gc_pause_million“进行计算,保证时间可预测模型。
总结
<1> 分代:建立在”分代理论基础之上“,进行了更大胆的扩展。
分成了多等分相同大小的 region,每一个region可以扮演各种角色:新生代,老年代,eden区
<2> 跨代引用:也使用”记忆集“,但是设计更加复杂
<3> 大对象:超过region的一半为大对象,太大时分配到”连续的region中“
…(更细节的东西,up建议看书)
JVM调优经验(11:50)
End

若有收获,就点个赞吧
0 人点赞
