基本架构
数据结构
Redis 数据结构的底层实现方式
动态字符串SDS——字符数组实现
1 为什么用sds,不用一般的字符串?

2 底层结构与特点
sds使用 字符数 组存储字符串。
其中 len 和 alloc 刚申请时是一样的,但是动态扩容以后,就不一样了,一个是“存的数量”,一个是“上限”。
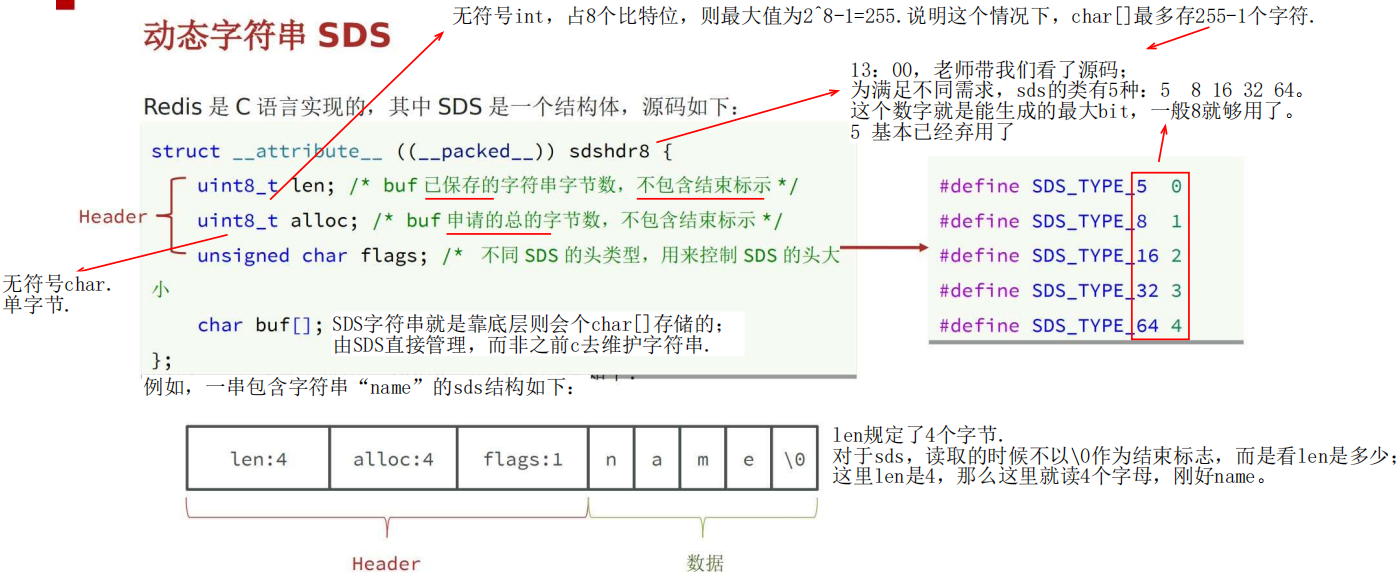
3 sds的动态扩容
扩容涉及内存预分配,这个操作十分消耗性能,涉及用户态内核态切换,所以扩容规则中,新空间长度要大一些,就可以一次多申请内存,减少申请次数。
IntSet——数组模拟set
1 底层结构与特点
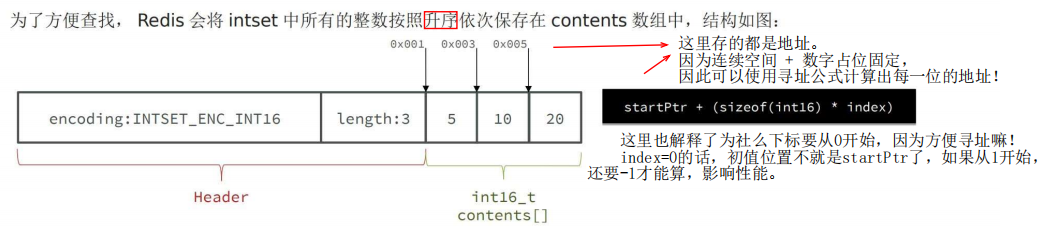
(1)整数数组实现,长度可变,有序(升序存储),数据不可重复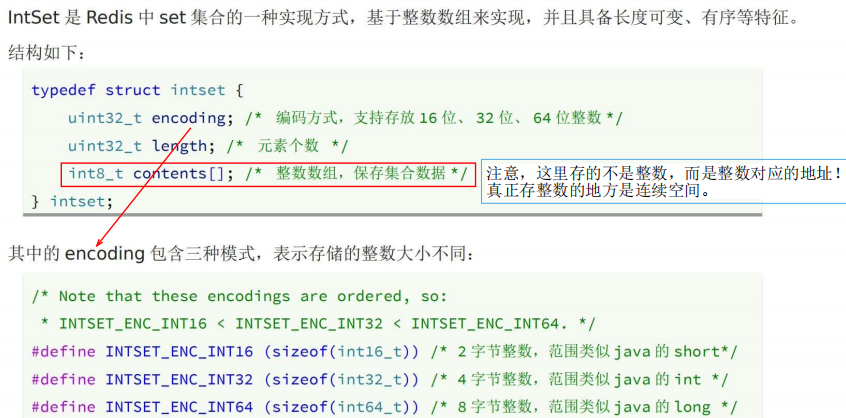
(2)为了查找方便,根据 寻址公式,升序记录每一个数的地址。
因为是连续空间,数字占位固定,所以可以根据下标和计算每一个数的地址。
2 IntSet升级
超出encoding范围,就需要扩容。
扩容要倒序扩容,因为是直接在原来的数组上搞,若是正序的话,会导致某些数字被覆盖.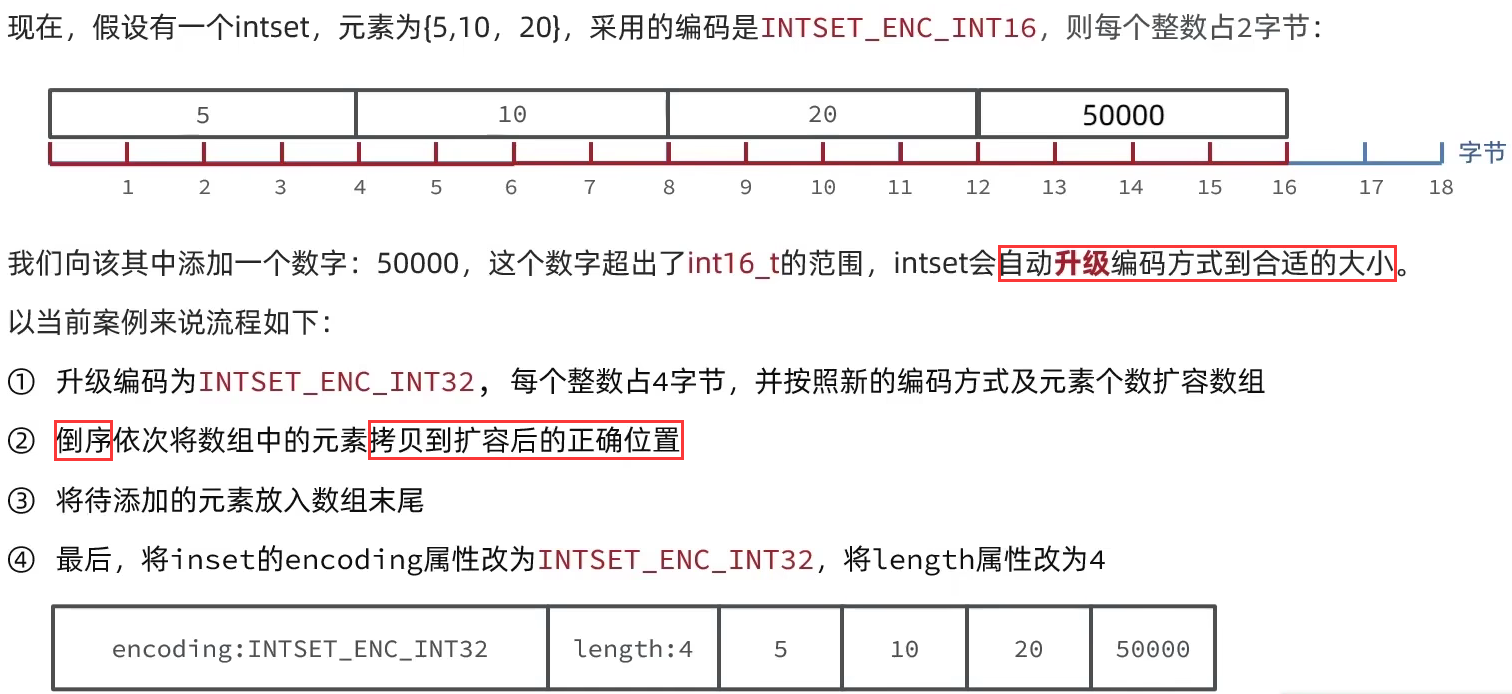
3 总结

Dict——数组与哈希表
1 底层结构与特点
Dict 底层三大结构:哈希表 + 哈希节点 + 字典
哈希表 里面存的是 哈希节点, 哈希节点里面是 k-v。
2 哈希表的 hash 计算过程
图中这几个结构很重要.
通过 key 算 hash,hash 再跟掩码 sizemask “与运算” 计算存储位置(相当于java中hash的取模)。
size 务必取 2^n,这样 sizemask 与 hash 与运算能把 结果控制在 size 以内。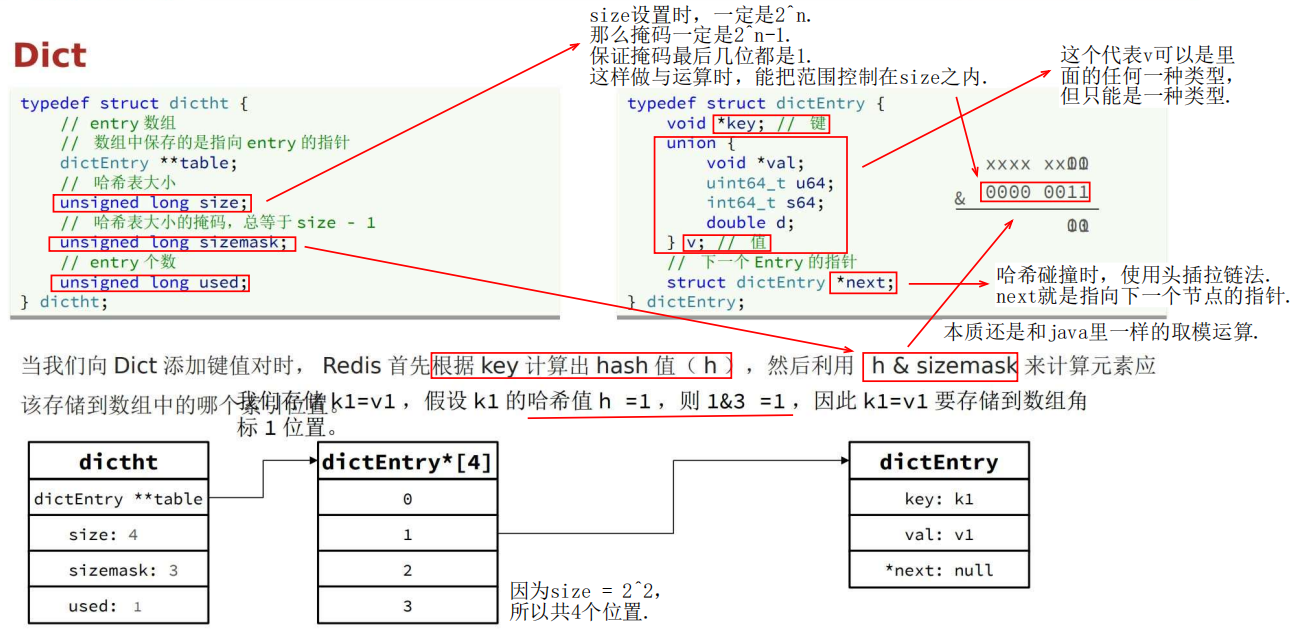
使用头插拉链发解决 哈希冲突问题。

3 字典 dict 的结构
dict 代码结构如下: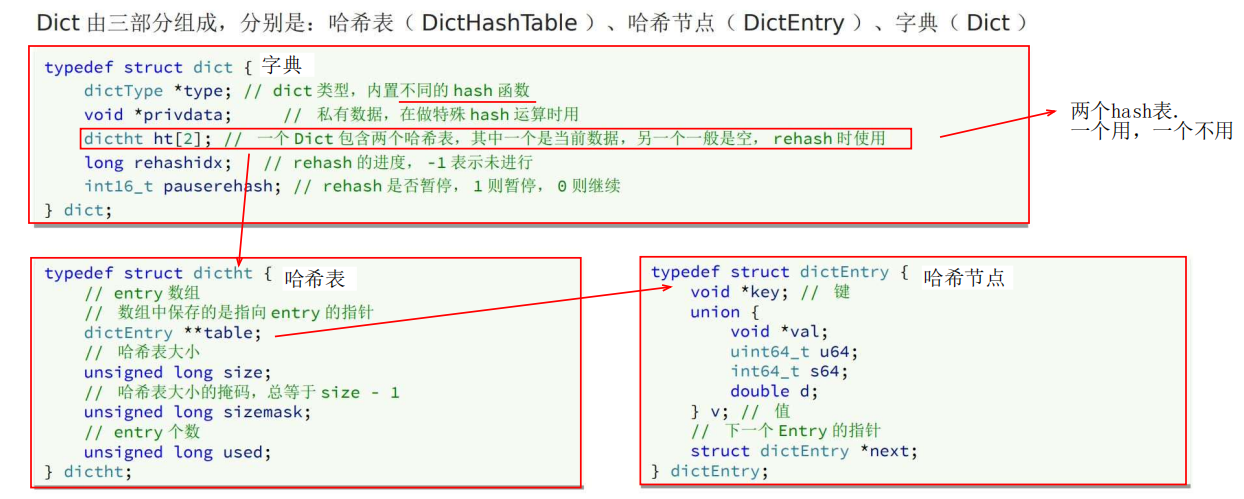
图示,两个 hash 表,一个用,一个不用。
不用的那个后面 rehash 要用。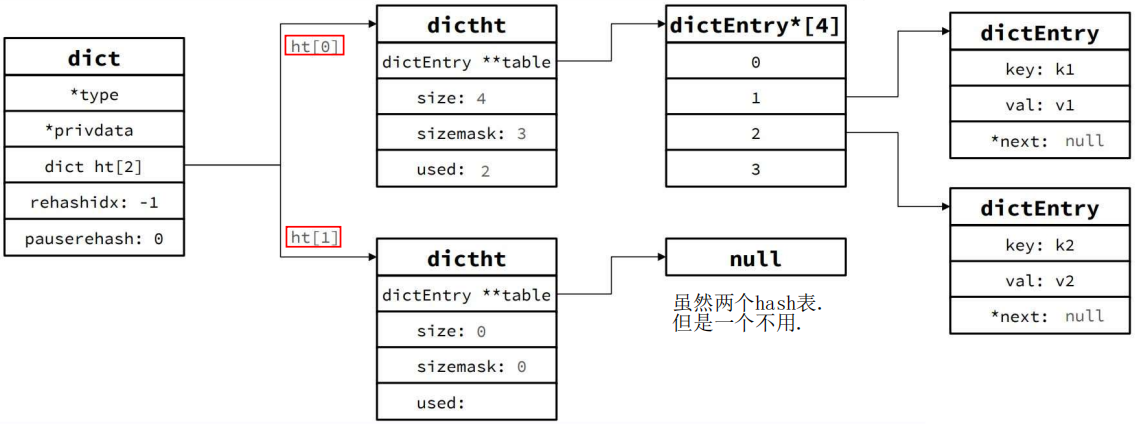
4 dict 扩容/收缩 & rehash
(1)扩容
哈希冲突太多时,需要扩容;扩容导致 size 变化,这样计算的 hash 值就变了,所以需要 rehash。
通过 负载因子 具体判断何时需要 扩容。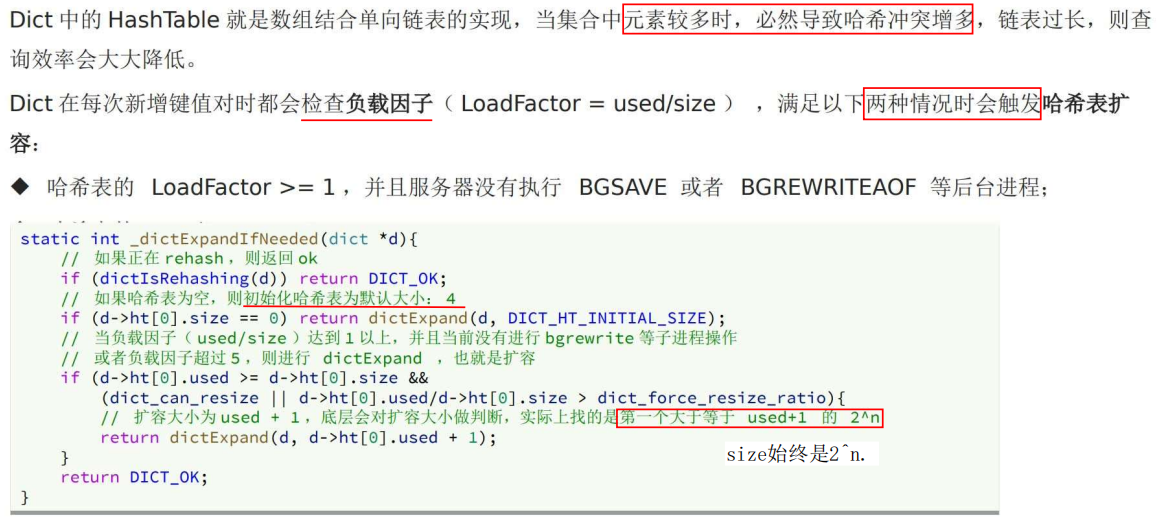
(2)收缩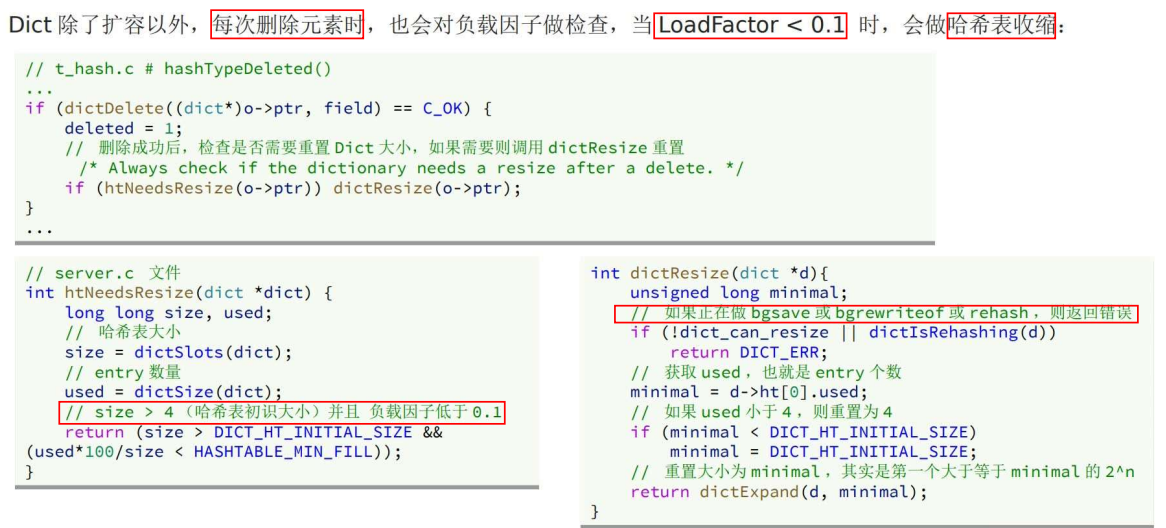
(3)rehash 的过程
5 渐进式 rehash
渐进式rehash:一次只算 旧hash表 中,一个 idx 对应的链表。

6 总结

ZipList——数组实现双端链表
1 底层结构与特点
能够 快速得到 首位节点的位置,进而可以便捷的操作双端。
(用来计算 tail 位置的参数,就是 起始位置 和entry 的长度,entry的事情后面说)
中间的 entry 存储数据。
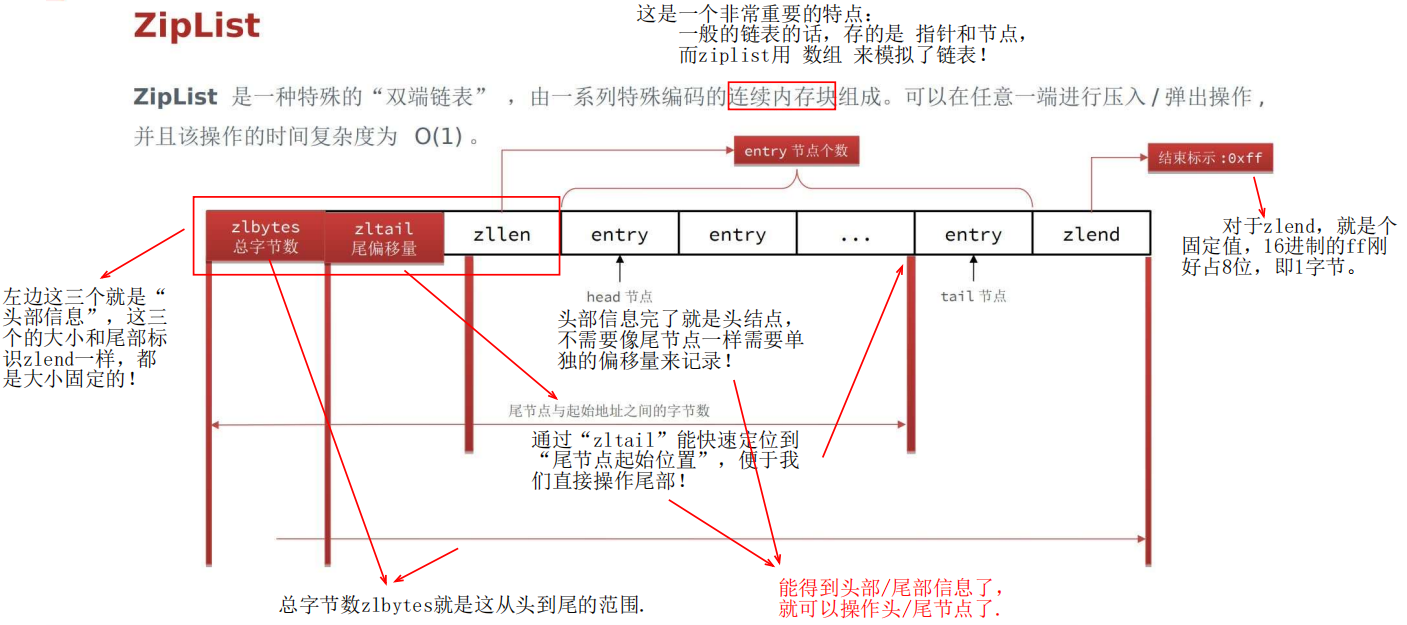
2 zip的关键——不定长entry
不定长的 entry 便是 zl 的关键所在!
根据前面的说明,zl 已经违背链表的逻辑了.。现在,你一个不定长,又好像违背了数组的逻辑了.
其实这都是为了“节省内存”,为不同的数据采用不用的长度,这个是可以动态调整的。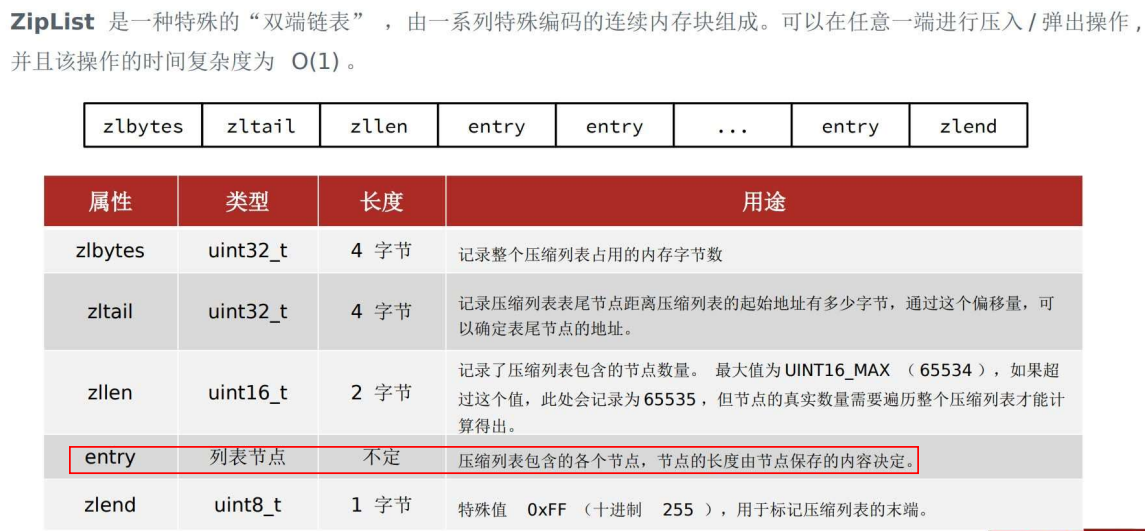
zipEntry结构如下,三部分组成。
previous_entry_length是很关键的参数,encoding居然还记录了长度,反正这些参数能帮助确定 “上一个entry的长度” 和 “当前entry的长度”,这样 tail 节点的位置就能累加起来了。
3 连锁更新问题
说白了就是:
前面的entry长度,1字节的 p_e_l 存不下,导致 p_e_l 扩容到 5字节, 导致自身len增长,其后面的 p_e_l 也被迫扩容到5字节, 然后导致了一连串的扩容.
==> 就是因为连续 N个entry长度都是 250-253 之间,在扩容的边缘疯狂试探,一旦 Len 加了 4byte ,就导致扩容。
4 总结
zl 中间讲的这些各种各样的 encoding 编码,目的都是为了节省内存,所以zl在redis的使用场景还是不少。
(crud怎么体现??)
但是,毕竟还是链表的形式,只能从前向后或者从后向前遍历, 如果数据太多,性能依然不理想,所以使用时,有必要对数据数量进 行限制。
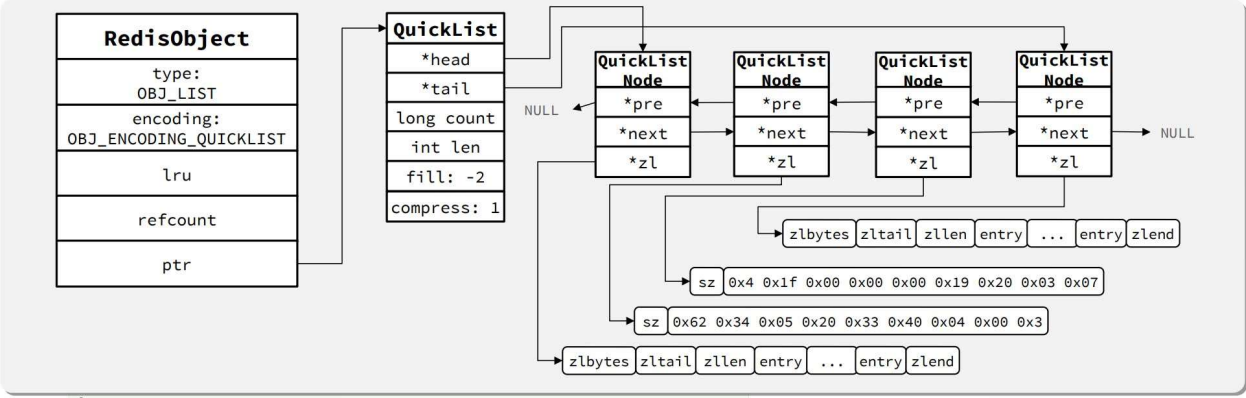
QuickList——ZipList 数组
1 ZipList的缺点 与 优化思路
ziplist是数组,不好一次申请太多数据;达到ziplist上限后,怎么实现扩容 等。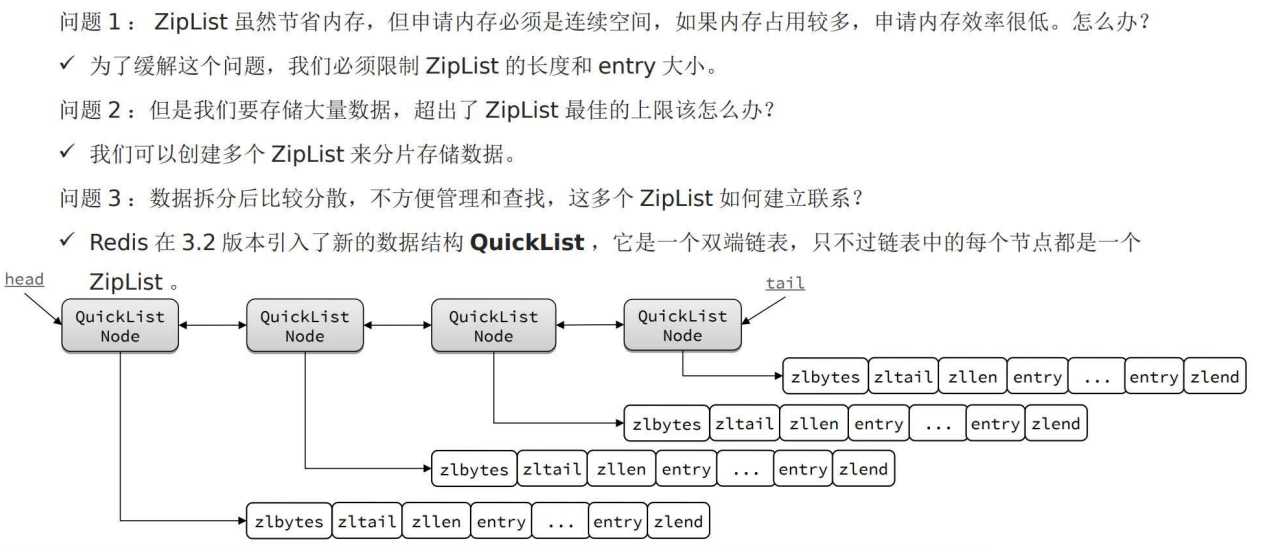
2 ZipList节点 内存大小 & 压缩
俩都有参数控制。
内存: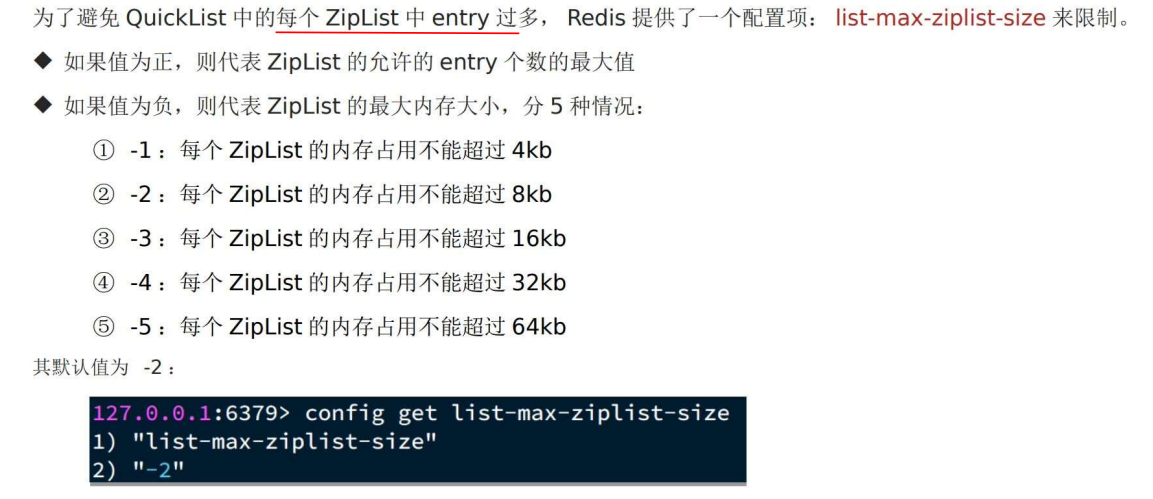
压缩: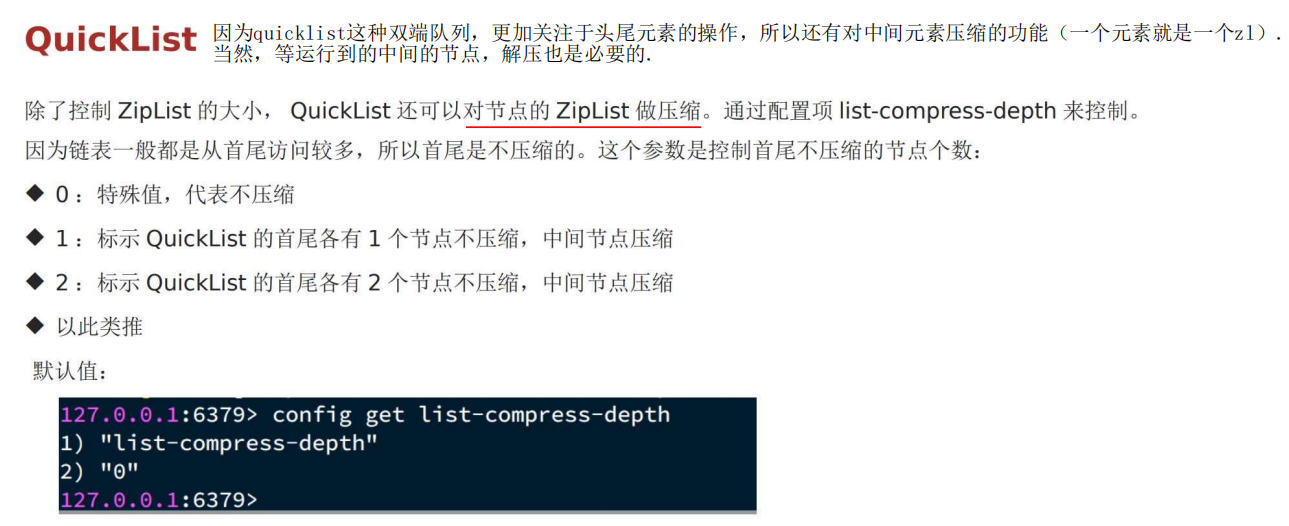
3 结构示意图
注意,中间的ziplist因为参数配置的原因,进一步压缩了。
到后面要用的话,还得解压缩。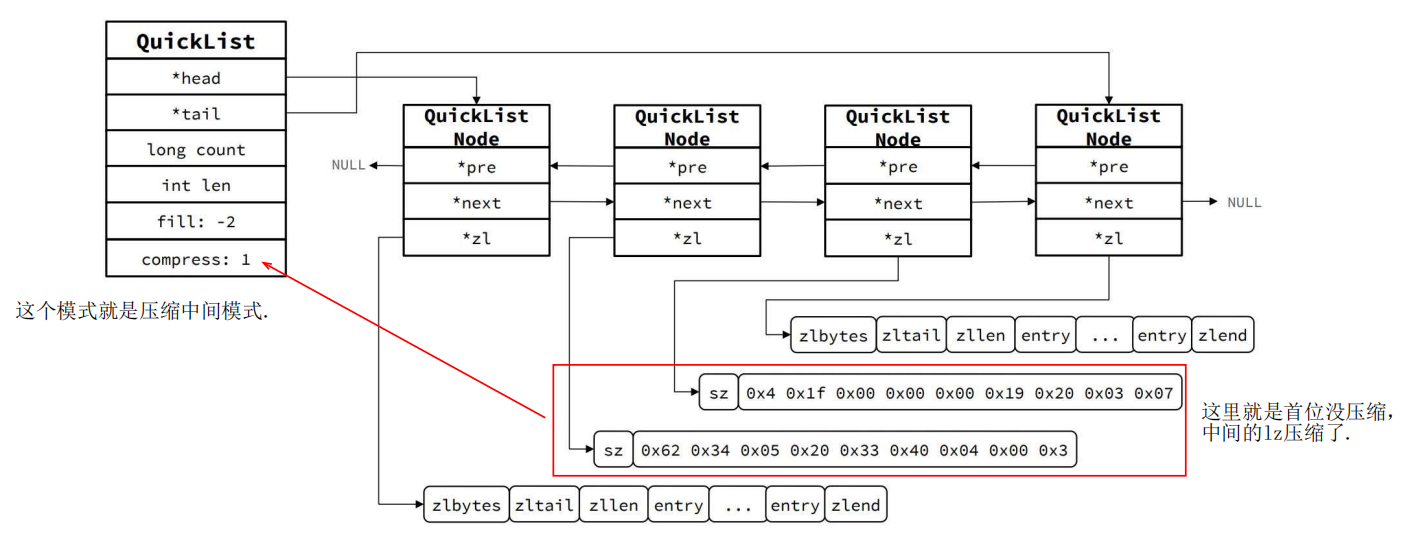
4 总结

SkipList——链表
1 底层结构与特点
跳表节点中:当前节点真正的值 element + 前一个节点的指针 + 用来排序的 score + 索引结构 level [ ] .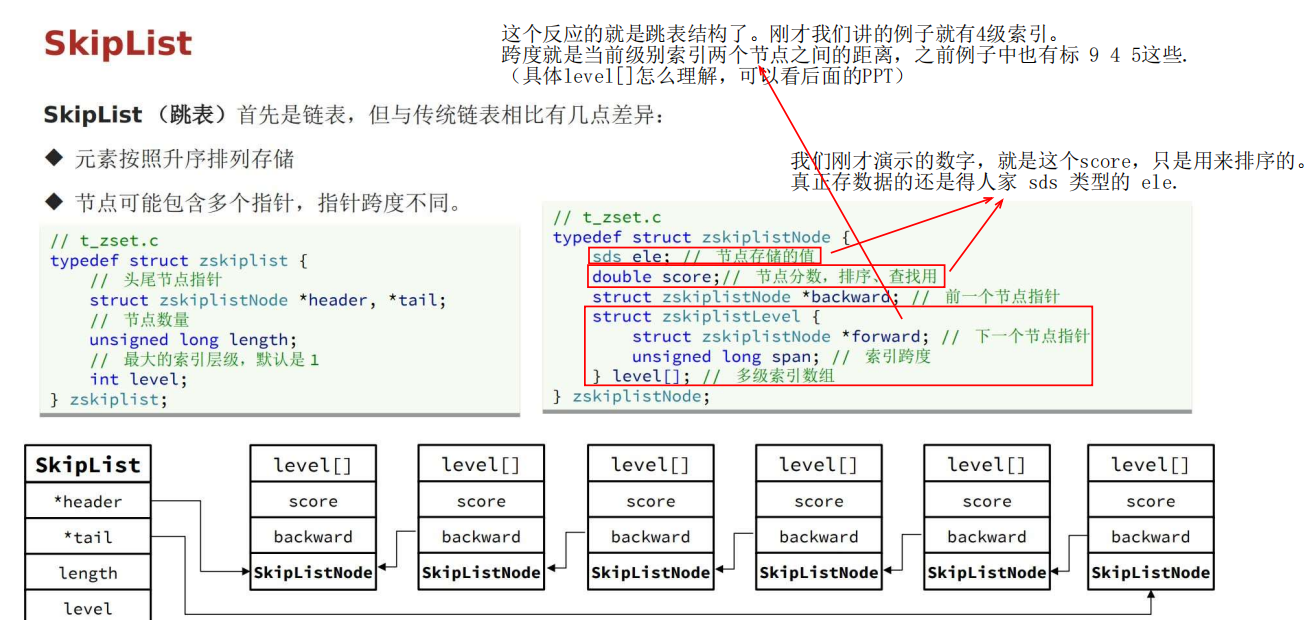
2 结构示意图
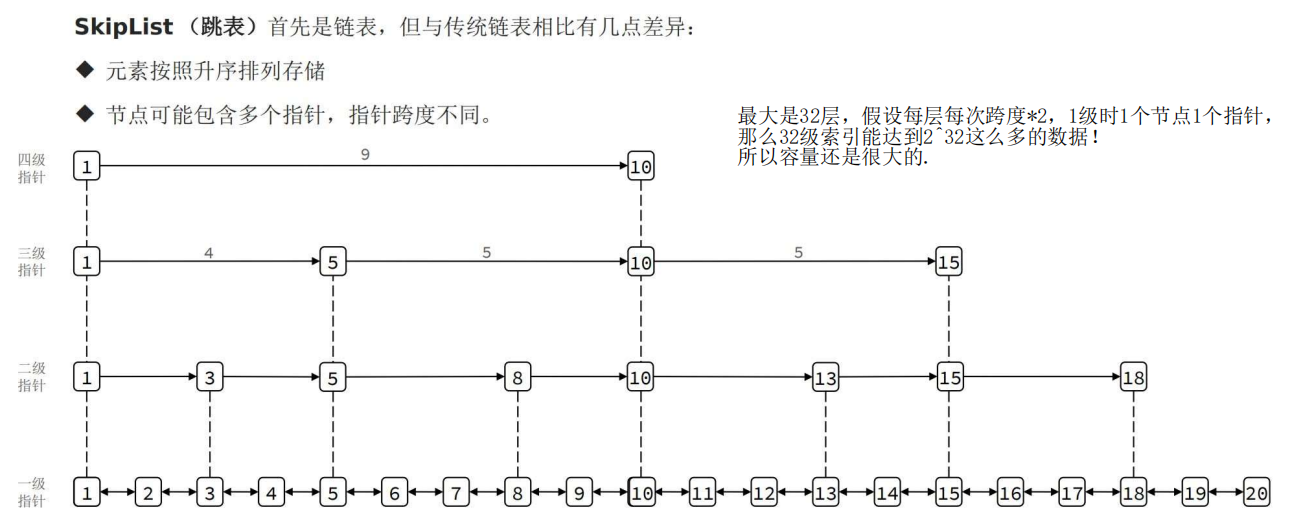
如图,一个节点如果被多个指针指向,那么它的 level[] 元素就会变多。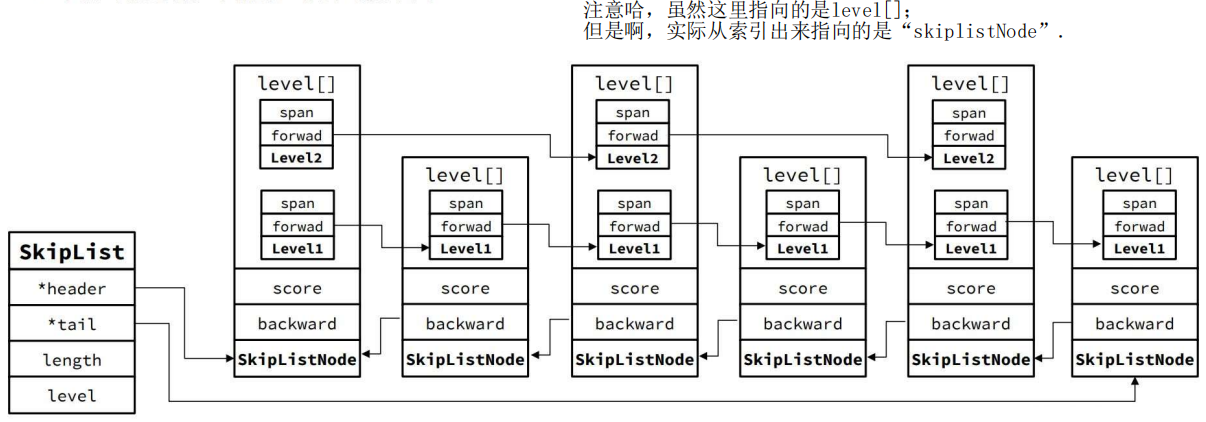
3 总结

RedisObject
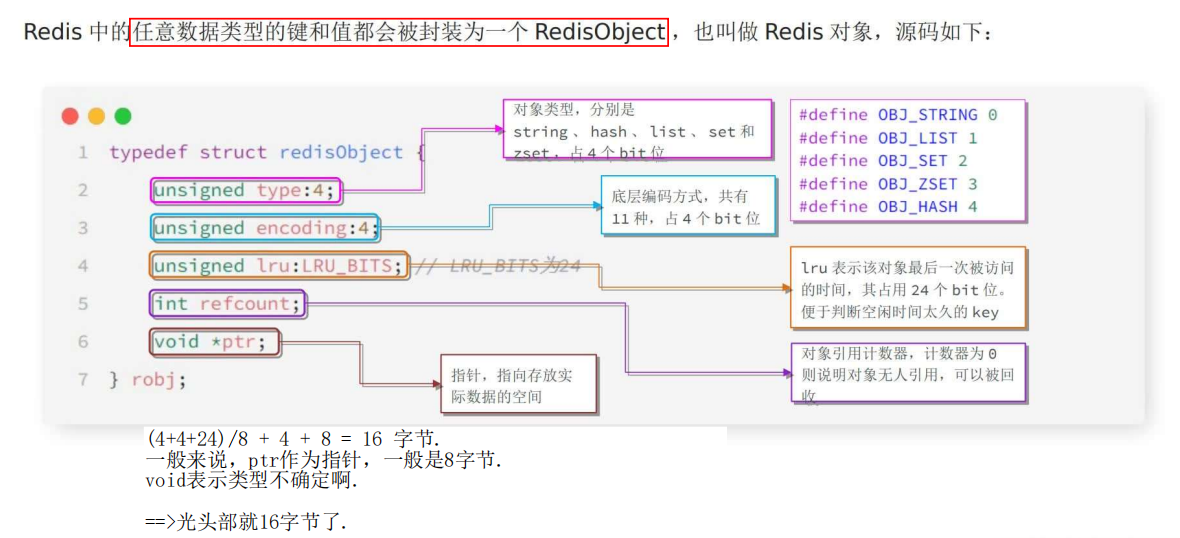
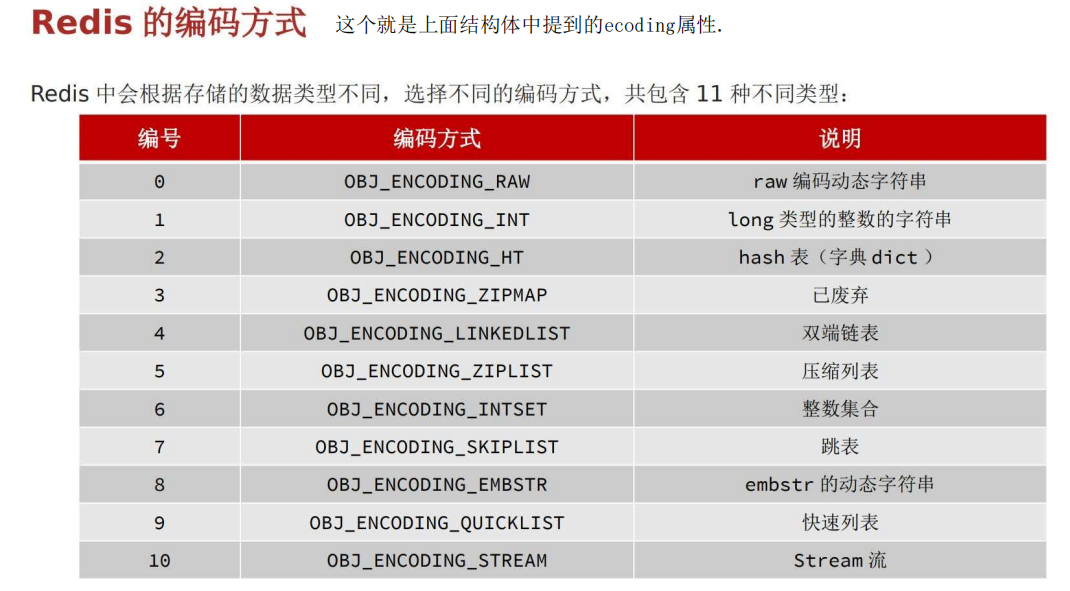

五种数据结构
String
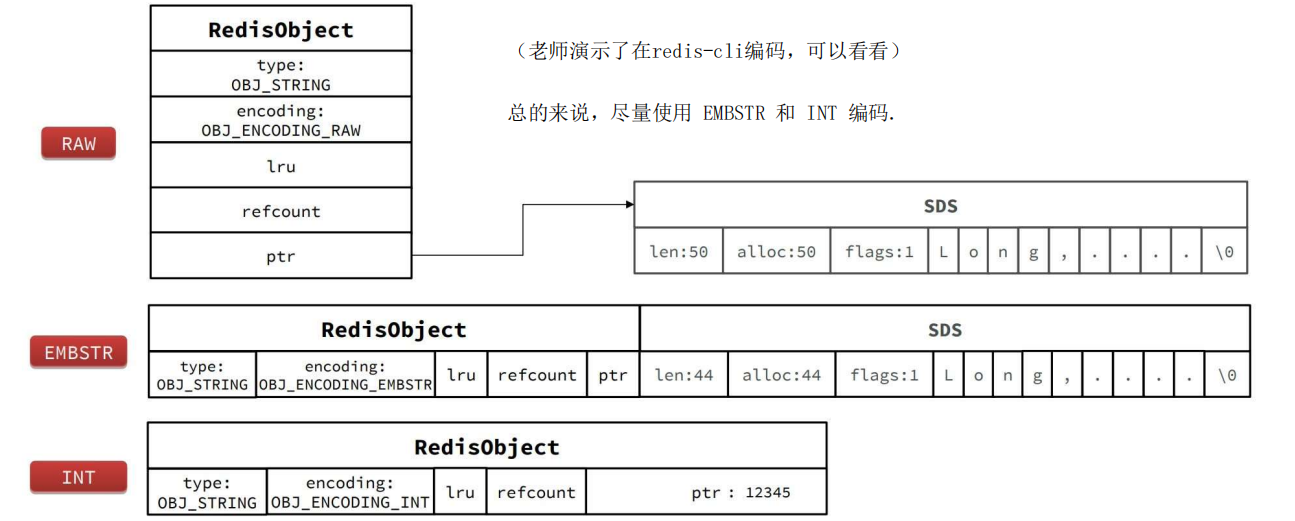
SDS动态字符串——RAW编码
RAW编码方式。
此时,头信息和 sds 是两块空间,同时需要使用str进行索引。

SDS动态字符串——EMBSTR编码
EMBSTR形式的话,就是sds和redisObject用一 块内存来存,而不是raw编码的两块内存.
为什么设定44字节? 因为 redisObject 和 sds 的固定信息加起来是 20byte,加 44byte 刚好是 64byte,是一个 2^n,刚好是 redis 底层内存分配的一个整块的值,不至于产生内存碎片.

INT编码
Int 类型的话,ptr 就不存指针了,因为ptr有8字节,64位,因此可以存很大的数! 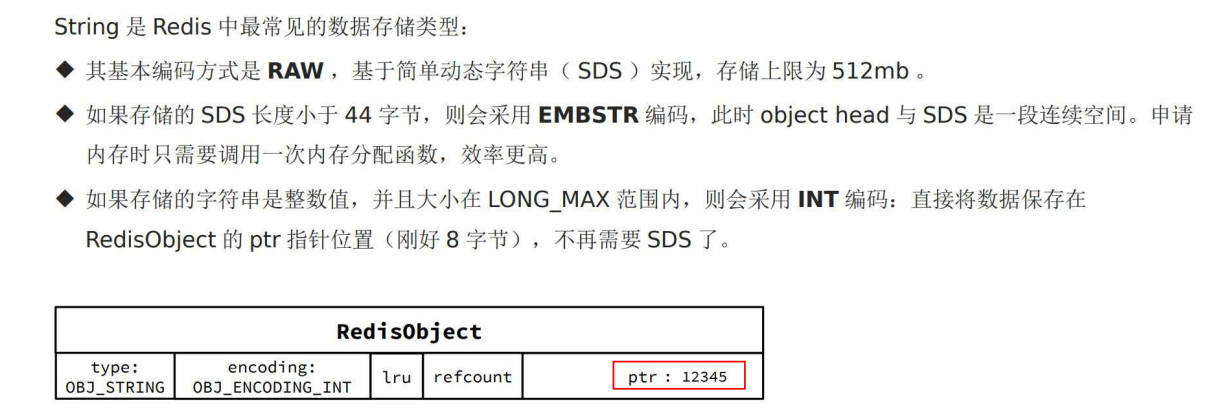
List
QuickList 实现 List
LinkedList 实现 List(已被淘汰)

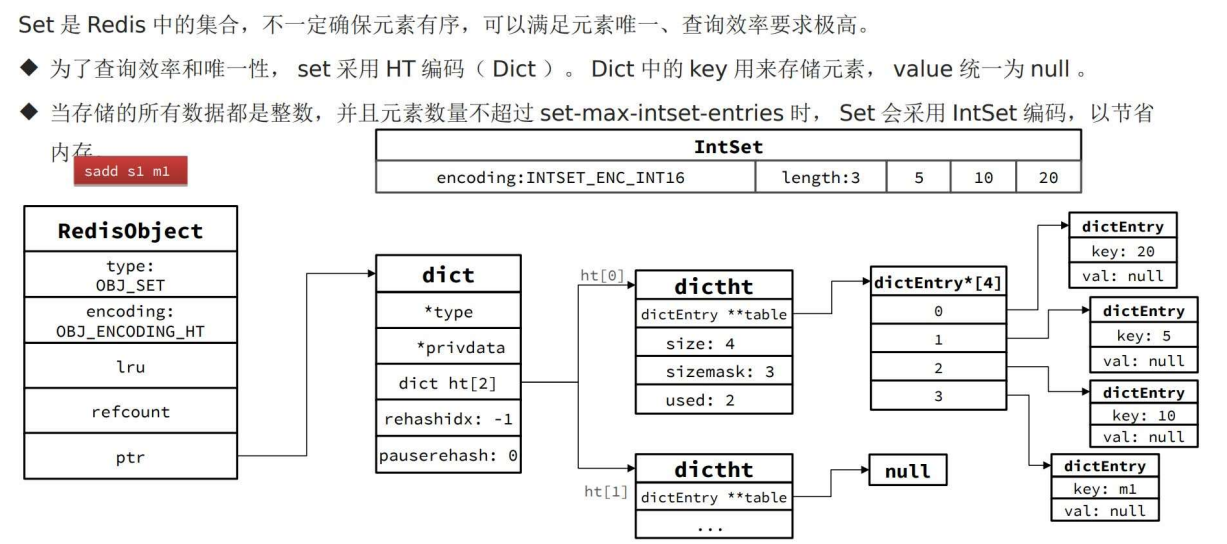
Set
Dict/Hashtable 实现 Set

IntSet 实现 Set
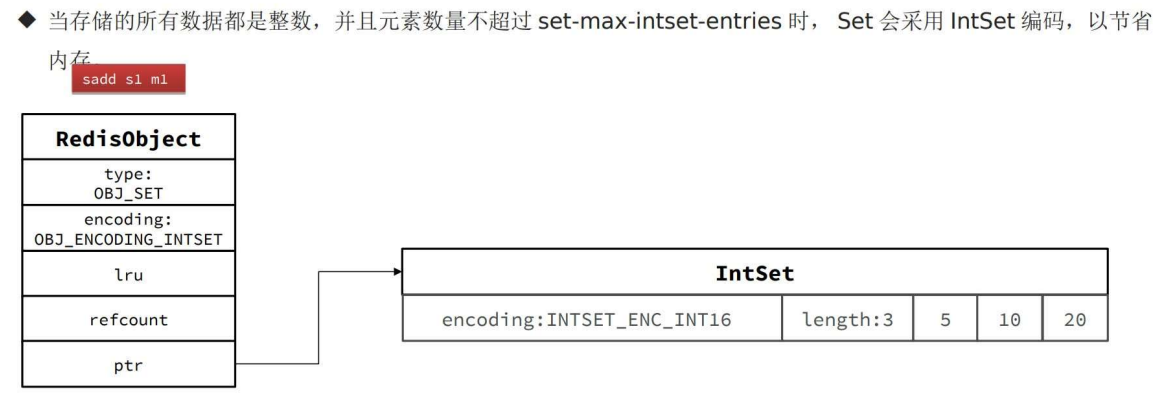

IntSet 插入 String 时,IntSet 转成 Dict 编码
一旦插入string,intset就用不了了,转成dict。
换到 dict 以后,key 存值即可,val 置成 null 即可。
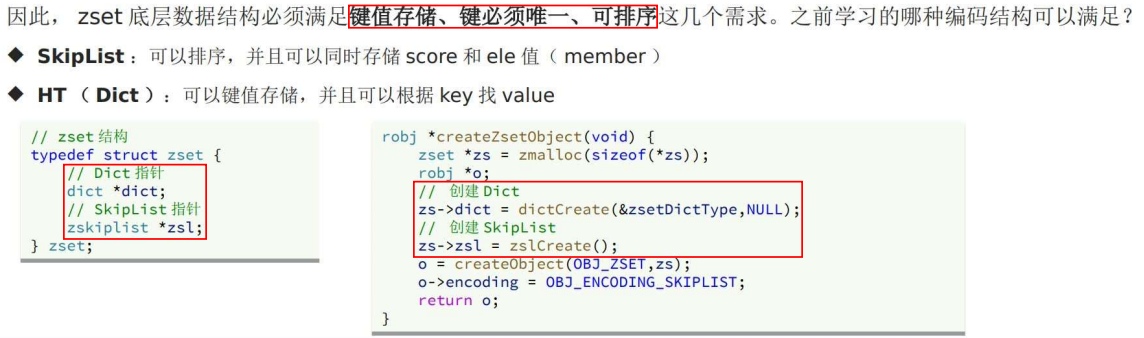
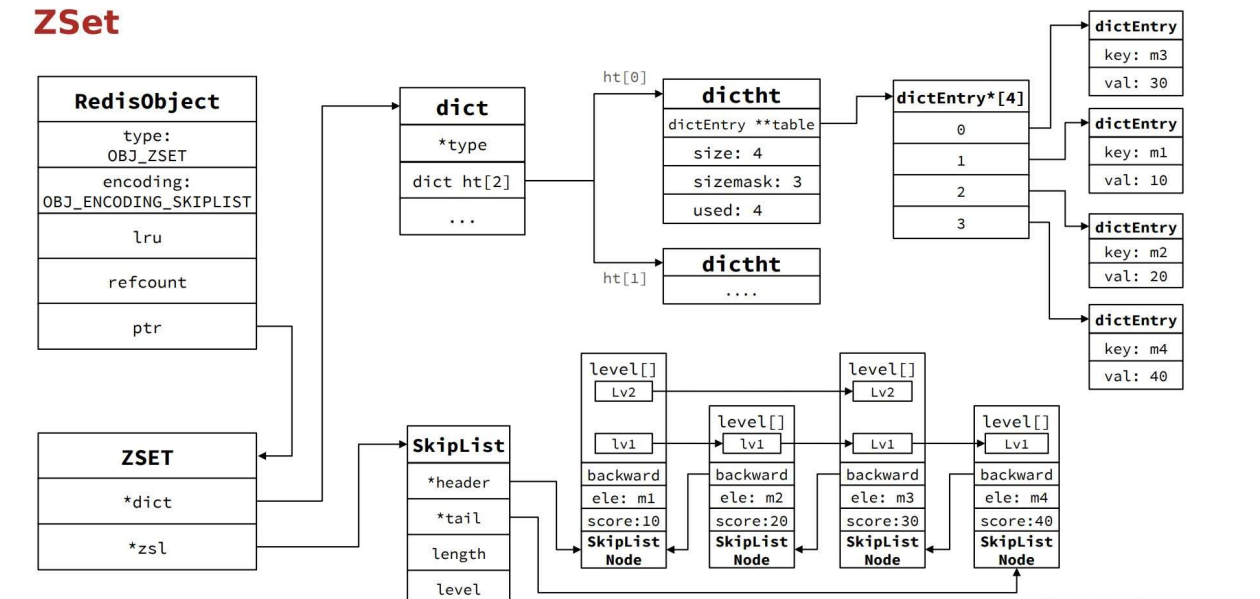
Zset
特点:有序,k-v,查询效率高
不同于Set,Zset 更类似于 map 结构,需要 k-v,而 set 只要有 key 即可。

数据多:SkipList + Dict/HT
回顾一下,跳表节点中,有 ele 和 score 元素,score 来存值, ele存当前节点数据.
数据少:ZipList
ziplist 不具备我们一开始要求的键值对、排序等直接功能,为此,这几个功能我们要专门去想办法实现那。
如图。

Hash
特点:比 Zset 少了排序功能而已
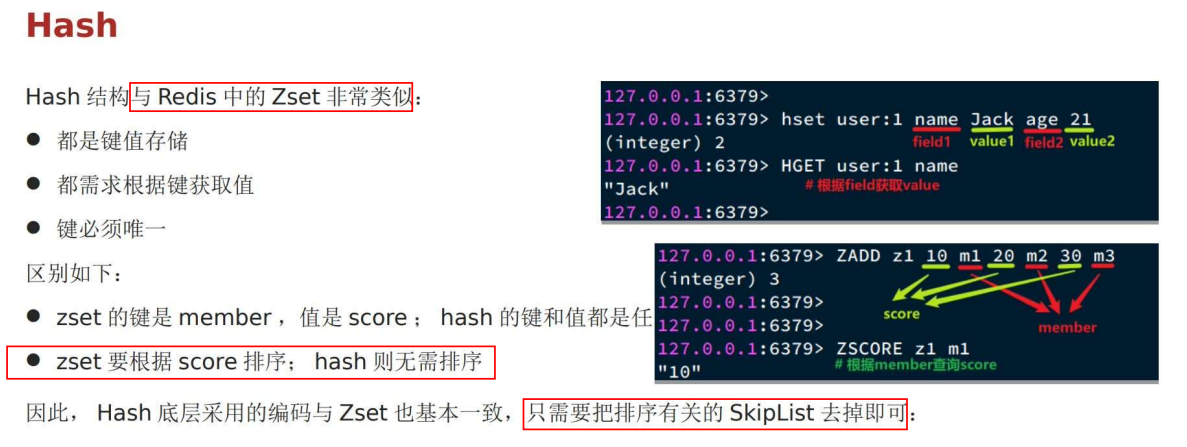
数据少:ZipList(默认)

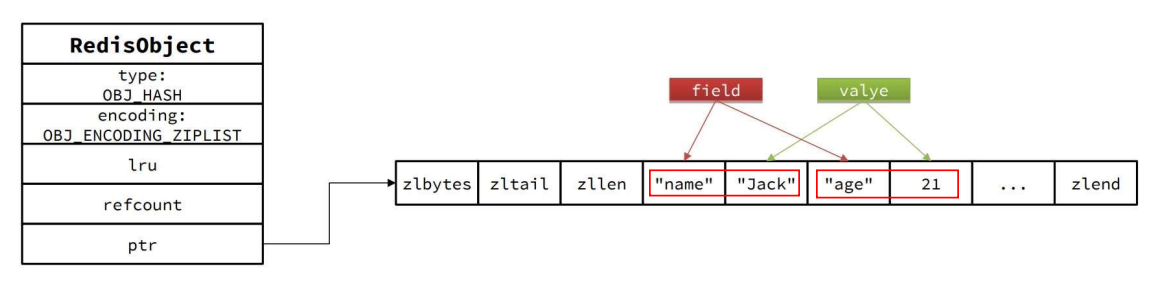
数据多:Dict
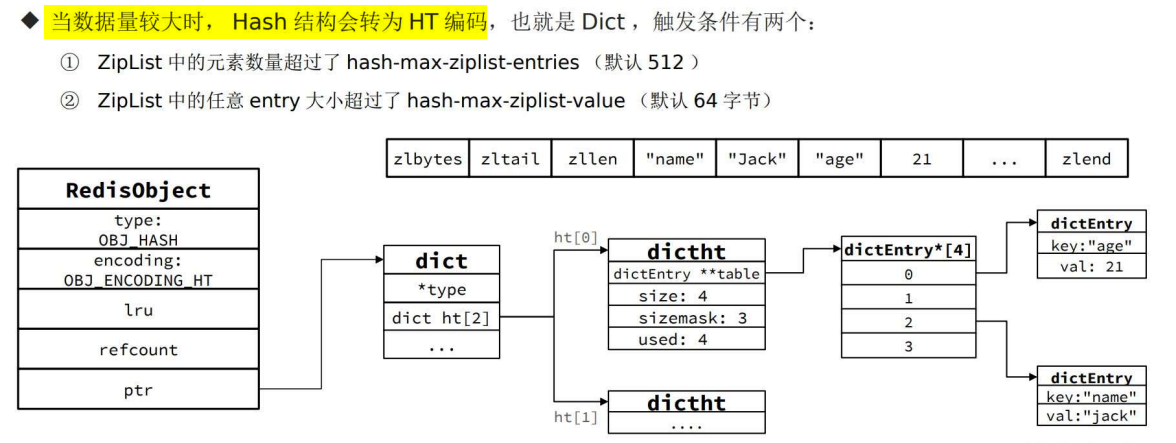
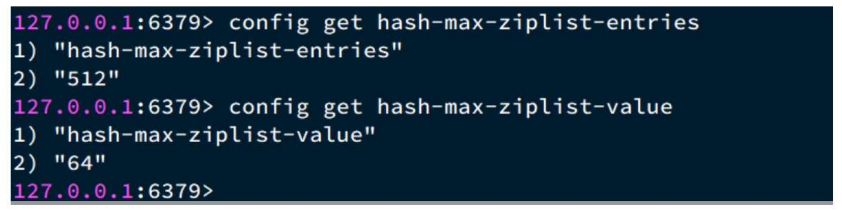
持久化
AOF
RDB
混合 AOF + RDB
高可用:主从 + 哨兵 + 集群
分布式锁
30 | 如何使用Redis实现分布式锁?
Redis 属于分布式系统,当有多个客户端需要争抢锁时,我们必须要保证,这把锁不能是某个客户端本地的锁。否则的话,其它客户端是无法访问这把锁的,当然也就不能获取这把锁了。
所以,在分布式系统中,当有多个客户端需要获取锁时,我们需要分布式锁。此时,锁是保存在一个共享存储系统中的,可以被多个客户端共享访问和获取。Redis 本身可以被多个客户端共享访问,正好就是一个共享存储系统,可以用来保存分布式锁。而且 Redis 的读写性能高,可以应对高并发的锁操作场景。
所以,这节课,我就来和你聊聊如何基于 Redis 实现分布式锁。
小结
在基于单个 Redis 实例实现分布式锁时,对于加锁操作,我们需要满足三个条件。
1 加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个操作,但需要以原子操作的方式完成,所以,我们使用 SET 命令带上 NX 选项来实现加锁;
2 锁变量需要设置过期时间,以免客户端拿到锁后发生异常,导致锁一直无法释放,所以,我们在 SET 命令执行时加上 EX/PX 选项,设置其过期时间;
3 锁变量的值需要能区分来自不同客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,我们使用 SET 命令设置锁变量值时,每个客户端设置的值是一个唯一值,用于标识客户端。
和加锁类似,释放锁也包含了读取锁变量值、判断锁变量值和删除锁变量三个操作,不过,我们无法使用单个命令来实现,所以,我们可以采用 Lua 脚本执行释放锁操作,通过 Redis 原子性地执行 Lua 脚本,来保证释放锁操作的原子性。
基于单个 Redis 实例实现分布式锁时,会面临实例异常或崩溃的情况,这会导致实例无法提供锁操作,正因为此,Redis 也提供了 Redlock 算法,用来实现基于多个实例的分布式锁。这样一来,锁变量由多个实例维护,即使有实例发生了故障,锁变量仍然是存在的,客户端还是可以完成锁操作。Redlock 算法是实现高可靠分布式锁的一种有效解决方案,你可以在实际应用中把它用起来。
单机上的锁和分布式锁的联系与区别
单机锁的实现
对于在单机上运行的多线程程序来说,锁本身可以用一个变量表示。
变量值为 0 时,表示没有线程获取锁;
变量值为 1 时,表示已经有线程获取到锁了。
一个线程调用加锁操作,其实就是检查锁变量值是否为 0。
如果是 0,就把锁的变量值设置为 1,表示获取到锁;
如果不是 0,就返回错误信息,表示加锁失败,已经有别的线程获取到锁了。
而一个线程调用释放锁操作,其实就是将锁变量的值置为 0,以便其它线程可以来获取锁。
分布式锁的实现猜想
分布式锁同样可以用一个变量来实现。客户端加锁和释放锁的操作逻辑,也和单机上的加锁和释放锁操作逻辑一致:加锁时同样需要判断锁变量的值,根据锁变量值来判断能否加锁成功;释放锁时需要把锁变量值设置为 0,表明客户端不再持有锁。
单机锁和分布式锁的区别
和线程在单机上操作锁不同的是,在分布式场景下,锁变量需要由一个共享存储系统来维护,只有这样,多个客户端才可以通过访问共享存储系统来访问锁变量。相应的,加锁和释放锁的操作就变成了读取、判断和设置共享存储系统中的锁变量值。
分布式锁的两个要求
要求一:分布式锁的加锁和释放锁的过程,涉及多个操作。所以,在实现分布式锁时,我们需要保证这些锁操作的原子性;
要求二:共享存储系统保存了锁变量,如果共享存储系统发生故障或宕机,那么客户端也就无法进行锁操作了。在实现分布式锁时,我们需要考虑保证共享存储系统的可靠性,进而保证锁的可靠性。
基于单个 Redis 节点实现分布式锁
Redis 可以使用键值对来保存锁变量,再接收和处理不同客户端发送的加锁和释放锁的操作请求
赋予锁变量一个变量名,把这个变量名作为键值对的键,而锁变量的值,则是键值对的值,这样一来,Redis 就能保存锁变量了,客户端也就可以通过 Redis 的命令操作来实现锁操作
实现方式
总结来说,我们就可以用 SETNX 和 DEL 命令组合来实现加锁和释放锁操作。下面的伪代码示例显示了锁操作的过程,你可以看下。
// 加锁SETNX lock_key 1// 业务逻辑DO THINGS// 释放锁DEL lock_key
使用 SETNX 和 DEL 命令组合实现分布锁,存在两个潜在的风险。
风险1:设置过期时间,解决无法释放锁的问题
第一个风险是,假如某个客户端在执行了 SETNX 命令、加锁之后,紧接着却在操作共享数据时发生了异常,结果一直没有执行最后的 DEL 命令释放锁。因此,锁就一直被这个客户端持有,其它客户端无法拿到锁,也无法访问共享数据和执行后续操作,这会给业务应用带来影响。
针对这个问题,一个有效的解决方法是,给锁变量设置一个过期时间
这样一来,即使持有锁的客户端发生了异常,无法主动地释放锁,Redis 也会根据锁变量的过期时间,在锁变量过期后,把它删除。其它客户端在锁变量过期后,就可以重新请求加锁,这就不会出现无法加锁的问题了。
风险2:设置唯一值,解决误释放锁的问题
我们再来看第二个风险。如果客户端 A 执行了 SETNX 命令加锁后,假设客户端 B 执行了 DEL 命令释放锁,此时,客户端 A 的锁就被误释放了。如果客户端 C 正好也在申请加锁,就可以成功获得锁,进而开始操作共享数据。这样一来,客户端 A 和 C 同时在对共享数据进行操作,数据就会被修改错误,这也是业务层不能接受的。为了应对这个问题,我们需要能区分来自不同客户端的锁操作,具体咋做呢?其实,我们可以在锁变量的值上想想办法。
在使用 SETNX 命令进行加锁的方法中,我们通过把锁变量值设置为 1 或 0,表示是否加锁成功。1 和 0 只有两种状态,无法表示究竟是哪个客户端进行的锁操作。所以,我们在加锁操作时,可以让每个客户端给锁变量设置一个唯一值,这里的唯一值就可以用来标识当前操作的客户端。在释放锁操作时,客户端需要判断,当前锁变量的值是否和自己的唯一标识相等,只有在相等的情况下,才能释放锁。这样一来,就不会出现误释放锁的问题了。
实现:SET 命令和 Lua 脚本
在查看具体的代码前,我要先带你学习下 Redis 的 SET 命令。
我们刚刚在说 SETNX 命令的时候提到,对于不存在的键值对,它会先创建再设置值(也就是“不存在即设置”),为了能达到和 SETNX 命令一样的效果,Redis 给 SET 命令提供了类似的选项 NX,用来实现“不存在即设置”。
如果使用了 NX 选项,SET 命令只有在键值对不存在时,才会进行设置,否则不做赋值操作。此外,SET 命令在执行时还可以带上 EX 或 PX 选项,用来设置键值对的过期时间。举个例子,执行下面的命令时,只有 key 不存在时,SET 才会创建 key,并对 key 进行赋值。另外,key 的存活时间由 seconds 或者 milliseconds 选项值来决定。
其中,unique_value 是客户端的唯一标识,可以用一个随机生成的字符串来表示,PX 10000 则表示 lock_key 会在 10s 后过期,以免客户端在这期间发生异常而无法释放锁。
SET key value [EX seconds | PX milliseconds] [NX]// 加锁, unique_value作为客户端唯一性的标识SET lock_key unique_value NX PX 10000
在释放锁操作中,我们使用了 Lua 脚本,这是因为,释放锁操作的逻辑也包含了读取锁变量、判断值、删除锁变量的多个操作,而 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,从而保证了锁释放操作的原子性。
好了,到这里,你了解了如何使用 SET 命令和 Lua 脚本在 Redis 单节点上实现分布式锁。
基于多个 Redis 节点实现高可靠的分布式锁
当我们要实现高可靠的分布式锁时,就不能只依赖单个的命令操作了,我们需要按照一定的步骤和规则进行加解锁操作,否则,就可能会出现锁无法工作的情况。“一定的步骤和规则”是指啥呢?其实就是分布式锁的算法。
为了避免 Redis 实例故障而导致的锁无法工作的问题,Redis 的开发者 Antirez 提出了分布式锁算法 Redlock。
Redlock 算法的基本思路
让客户端和多个独立的 Redis 实例依次请求加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁了,否则加锁失败。
这样一来,即使有单个 Redis 实例发生故障,因为锁变量在其它实例上也有保存,所以,客户端仍然可以正常地进行锁操作,锁变量并不会丢失。
Redlock 算法的执行步骤
第一步:客户端获取当前时间。
第二步:客户端按顺序依次向 N 个 Redis 实例执行加锁操作。
当然,如果某个 Redis 实例发生故障了,为了保证在这种情况下,Redlock 算法能够继续运行,我们需要给加锁操作设置一个超时时间。如果客户端在和一个 Redis 实例请求加锁时,一直到超时都没有成功,那么此时,客户端会和下一个 Redis 实例继续请求加锁。加锁操作的超时时间需要远远地小于锁的有效时间,一般也就是设置为几十毫秒。
第三步:一旦客户端完成了和所有 Redis 实例的加锁操作,客户端就要计算整个加锁过程的总耗时。
客户端只有在满足下面的这两个条件时,才能认为是加锁成功。
条件一:客户端从超过半数(大于等于 N/2+1)的 Redis 实例上成功获取到了锁;
条件二:客户端获取锁的总耗时没有超过锁的有效时间。
在满足了这两个条件后,我们需要重新计算这把锁的有效时间,计算的结果是锁的最初有效时间减去客户端为获取锁的总耗时。
如果锁的有效时间已经来不及完成共享数据的操作了,我们可以释放锁,以免出现还没完成数据操作,锁就过期了的情况。当然,如果客户端在和所有实例执行完加锁操作后,没能同时满足这两个条件,那么,客户端向所有 Redis 节点发起释放锁的操作。
在 Redlock 算法中,释放锁的操作和在单实例上释放锁的操作一样,只要执行释放锁的 Lua 脚本就可以了。这样一来,只要 N 个 Redis 实例中的半数以上实例能正常工作,就能保证分布式锁的正常工作了。所以,在实际的业务应用中,如果你想要提升分布式锁的可靠性,就可以通过 Redlock 算法来实现。
面试答法
得分点
标准回答
在分布式的环境下,会发生多个server并发修改同一个资源的情况,这种情况下,由于多个server是多个不同的 JRE 环境,而 Java 自带的锁局限于当前 JRE,所以Java自带的锁机制在这个场景下是无效的,那么就需要我们自己来实现一个分布式锁。
采用Redis实现分布式锁,我们可以在 Redis 中存一份代表锁的数据,数据格式通常使用字符串即可。
1 加锁
首先加锁的逻辑可以通过 setnx key value来实现,但如果客户端忘记解锁,那么这种情况就很有可能造成死锁,但如果直接给锁增加过期时间即新增 expire key seconds又会发生其他问题,即这两个命令并不是原子性的,那么如果第二步失败,依然无法避免死锁问题。
考虑到如上问题,我们最终可以通过 set...nx...命令,将加锁、过期命令编排到一起,把他们变成原子操作,这样就可以避免死锁。写法为 **set key value nx ex seconds** 。
2 解锁
解锁就是将代表锁的那份数据删除,但不能用简单的 del key,因为会出现一些问题。
比如此时有进程A,如果进程A在任务没有执行完毕时,锁被到期释放了。这种情况下进程 A 在任务完成后依然会尝试释放锁,因为它的代码逻辑规定它在任务结束后释放锁,但是它的锁早已经被释放过了,那这种情况它释放的就可能是其他线程的锁。
为解决这种情况,我们可以在加锁时为 key 赋一个随机值,来充当进程的标识,进程要记住这个标识。当进程解锁的时候进行判断,是自己持有的锁才能释放,否则不能释放。
另外判断,释放这两步需要保持原子性,否则如果第二步失败,就会造成死锁。而获取和删除命令不是原子的,这就需要采用Lua脚本,通过Lua脚本将两个命令编排在一起,而整个Lua脚本的执行是原子的。
3 优化后的 加/解锁 方式
综上所述,优化后的实现分布式锁命令如下:
# 加锁 set key random-value nx ex seconds
# 解锁 if redis.call(“get”,KEYS[1]) == ARGV[1] then return redis.call(“del”,KEYS[1]) else return 0 end
加分回答
上述的分布式锁实现方式是建立在单节点之上的,它可能存在一些问题,比如有一种情况,进程A在主节点加锁成功,但主节点宕机了,那么从节点就会晋升为主节点。那如果此时另一个进程B在新的主节点上加锁成功而原主节点重启了,成为了从节点,系统中就会出现两把锁,这违背了锁的唯一性原则。 总之,就是在单个主节点的架构上实现分布式锁,是无法保证高可用的。
若要保证分布式锁的高可用,则可以采用多个节点的实现方案。这种方案有很多,而 Redis 的官方给出的建议是采用 RedLock 算法的实现方案。
该算法基于多个Redis节点,它的基本逻辑如下:
(1)这些节点相互独立,不存在主从复制或者集群协调机制;
(2)加锁:以相同的 KEY 向 N 个实例加锁,只要超过一半节点成功,则认定加锁成功;
(3)解锁:向所有的实例发送DEL命令,行解锁;
我们可以自己实现该算法,也可以直接使用 Redisson 框架。
END

若有收获,就点个赞吧
0 人点赞
