codetop100:40次
codetop200:16次
codetop300:8次
一、数据结构
数组
双指针
27. 移除元素 典型题目:快慢指针的运用.
75. 颜色分类 要按lc要求做,只能背过了,非常规思路 —— 三指针。
面试时若是无要求,就是个大水题!设三个变量,分别统计0 1 2 的个数即可!
88. 合并两个有序数组 【codetop 100】关键是要倒着来!避免前面的被覆盖.
283. 移动零 数组双指针.
977. 有序数组的平方 双指针 + 二路归并.
169. 多数元素 【lc 100】【codetop 100】理想做法难想,直接背过。
利用 多数元素数量一定比其他元素数量总和多 的性质。
剑指 Offer 39. 数组中出现次数超过一半的数字 【codetop 200】 完全同 lc 169. 多数元素.
209. 长度最小的子数组 经典双指针题目,枚举区间双端题目,要熟悉。
二分
33. 搜索旋转排序数组 【lc 100】【codetop 100】两次二分,二分板子题.
34. 在排序数组中查找元素的第一个和最后一个位置 典型题目:二分模板题
69. x 的平方根 【codetop 100】 二分板子题.
一处细节if(mid * mid > x)
【易错/细节】这么写导致运算时间过长,甚至越界.;把一个 mid 除过去
if(mid > x / mid){
153. 寻找旋转排序数组中的最小值 与 lc33.搜索旋转排序数组很类似,这个题是简化版,1次二分.
704. 二分查找 【codetop 100】二分板子题,熟背。
while 中的 if 中,必须是 l = mid 或者 r = mid, = mid +- 1 这种不可以!!
模拟
剑指 Offer 29. 顺时针打印矩阵 典型题目:蛇形矩阵 问题。当模板背下来,不然到时候有些细节不好调整。
54. 螺旋矩阵 【codetop 100】 蛇形矩阵板子题.
一些易错点三大易错点:
【易错】add res 写在前面好啊,别写在后面
【易错】判断数字得自己开,不能设置-1来判断,因为数组中元素可能是-1的!
【重大失误】if,别写成while
class Solution {public List<Integer> spiralOrder(int[][] matrix) {List<Integer> res = new ArrayList<>();int m = matrix.length;int n = matrix[0].length;int[] dx = new int[]{0,1,0,-1};int[] dy = new int[]{1,0,-1,0};int x = 0;int y = 0;int t = 0;boolean[][] flag = new boolean[m][n];for(int i = 0; i < m * n; i ++){res.add(matrix[x][y]); //【易错】写在前面好啊,别写在后面// matrix[x][y] = -1;flag[x][y] = true; //【易错】判断数字得自己开,不能设置-1来判断,因为数组中元素可能是-1的!int a = x + dx[t];int b = y + dy[t];if(a >= m || a < 0 || b < 0 || b >= n || flag[a][b]){//【重大失误】if,别写成while// System.out.println(x + " " + y + " " + a + " " + b + " " + ( matrix[a][b] == -1 ));t = (t + 1) % 4;a = x + dx[t];b = y + dy[t];}x = a;y = b;}return res;}}
59. 螺旋矩阵 II 蛇形矩阵。
<br />[498. 对角线遍历](https://leetcode.cn/problems/diagonal-traverse/) 模拟题目演示过程即可。题目的关键特点,起终点的求法,最好背过!
其他
215. 数组中的第K个最大元素 【lc 100】【codetop 100】 快排模板.
347. 前 K 个高频元素 哈希表 + 计数排序。中间数组的含义一定要搞清楚!
136. 只出现一次的数字 典型题目:考察 “异或” 性质。
169. 多数元素 典型题目:“最优做法”比较难想,但是简单,直接背过即可.
240. 搜索二维矩阵 II 技巧题:每次判断右上角的元素,分三类情况讨论。找到结果 or 删掉一行/列。
链表
删除节点
203. 移除链表元素 链表最基础的题目,学习 双指针 与 虚拟头 结点配合删除节点.
82. 删除排序链表中的重复元素 II 【codetop 100】while 中的小细节把握不住啊.
判断 pre 和 wait 之间有几个元素来判断是否重复的,若只有1各,说明没重复.
/*Y总写法:比我那种简洁多了!*/class Solution {public ListNode deleteDuplicates(ListNode head) {//声明ListNode dummy = new ListNode(-1);dummy.next = head;ListNode wait = dummy;//遍历//注意1:Y总在外侧,用wait控制循环,我用的是gowhile(wait.next != null){ListNode go = wait.next;//注意2:(感觉是最重要的)Y总比较时,用go和wait.next比,我用的go和go.next,Y总写法更好//==>使用go.next的话就会产生诸多限制:// 如看他是否为null,比完了还得看g是在连续段的最后一位,还是在连续段外.//==>wait.next是“相对固定”的,所以省去了很多判断while(go != null && go.val == wait.next.val) go = go.next;//注意3:Y总是判断go和wait之间有几个元素来判断是否重复的,若只有1各,说明没重复.if(go == wait.next.next){wait = wait.next;}else{wait.next = go;}}//返回return dummy.next;}}
83. 删除排序链表中的重复元素 双指针.
翻转链表
24. 两两交换链表中的节点 多指针。还是翻转节点类似的题目,不难,纸上画画就清楚了.
25. K 个一组翻转链表 【lc 100】【codetop 100】难点在于细节处理,要点背一背:
while中,更新 start 节点就行,p q不用管,下一轮重新声明!
同样在 while 的 for 中,更新 p/q 节点就行,t 不用管,下一轮重新声明!
206. 反转链表 【lc 100】【codetop 100】
典型题目:原汁原味的翻转链表,最经典,三指针,熟记.
92. 反转链表 II 【codetop 100】感觉和 lc.25 K个一组翻转链表 有点像.
234. 回文链表 涉及:翻转链表.
合并与拆分链表
21. 合并两个有序链表 【lc 100】【codetop 100】
典型题目:链表合并。二路归并算法,建立dummy和tail节点,其他节点插入。
23. 合并K个升序链表 【lc 100】【codetop 100】代码背过
lc 21 的升级版本,常考。每轮找最小值时,使用堆(优先队列),把复杂度降到 O(1)!
class Solution {public ListNode mergeKLists(ListNode[] lists) {//1. 重写compareQueue<ListNode> q = new PriorityQueue<>(new Comparator<ListNode>(){@Overridepublic int compare(ListNode o1, ListNode o2){return o1.val - o2.val;}});//2. 首节点放入优先队列建堆,lists 中存的都是链表首节点.for(ListNode node:lists){if(node!=null) q.offer(node);}//3. 合并ListNode dummy = new ListNode(-1);ListNode tail = dummy; //就是cur节点,合并链表常用技巧while(!q.isEmpty()){ //队列不空就一直搞.ListNode minNode = q.poll(); //拉出最小的tail.next = minNode; //合并到链表中去tail = minNode; //tail移动到最后if(minNode.next!=null){ //min所在链表若是还有值,就放入堆中q.offer(minNode.next);}}//4. 返回结果return dummy.next;}}
138. 复制带随机指针的链表 链表中很难得题了感觉.,思路也挺独特的,代码也难写。
143. 重排链表 【codetop 100】参考了 [ lc.21合并有序链表 ]中构建新链表的方法
右半先翻转链表 + 左右两边进行归并 + 左半 & 最后 tail 节点单独处理.
//Y总讲解的思路上,参考了 [lc.21合并有序链表]中构建新链表的方法class Solution {public void reorderList(ListNode head) {//1. 先把后一段重排一下//1.1 计算链表长度ListNode cur = head;int len = 0;while(cur != null){cur = cur.next;len++;}//1.2 计算分段的长度:如果是奇数长度,左边一侧的节点多一个int lenL = (len + 1) / 2; //左侧长度:+1是为了保证奇数时,左侧多一个int lenR = len - lenL; //右侧长度//1.3 移动指针到目标位置:,ListNode pre = head;cur = head.next;for(int i = 1; i < lenL; i++){ //这里1开始,<lenL都是为了辅助到目标位置.pre = pre.next; //pre到左侧的最后一位cur = cur.next; //cur到右侧的第一位.}//1.4 翻转右侧这一段:最后pre到达右侧第一位(原来的最后一位),cur为null了while(cur != null){ListNode tmp = cur.next;cur.next = pre;pre = cur;cur = tmp;}//2. 打印在新链表上(注:通过lc21那种类似构建一个新链表的方式,Y总那种是直接在原链表上更改)//2.1 找到两侧头结点ListNode L = head; //左侧的head就是headListNode R = pre; //右侧的head就是pre//2.2 初始化新链表的"虚拟头"和"尾"ListNode dummy = new ListNode(-1);ListNode tail = dummy;dummy.next = head;//2.3 按题目要求构建新链表:每一次左边插入一个,右边插入一个// ==>注:这里按右侧链表长度定次数,左侧的可能比右侧多一个,单独处理(原链表长度为奇数时)for(int i = 0; i < lenR; i++){//2.3.1 左侧链表元素插入// System.out.println(L.val);//tail.next = L;tail = tail.next;L = L.next;//2.3.2 右侧链表元素插入// System.out.println(R.val);//tail.next = R;tail = tail.next;R = R.next;}//2.4 如果链表长度为奇数,那么左侧必然还有一个节点没接入if(L != null){tail.next = L;tail = tail.next;L = L.next;// System.out.println(R.val);}//2.5 【重要/易错】消除闭环,不然最后两位无线循环了tail.next = null;//3. 结果head = dummy.next;//测试用// int text = 5;// while(text > 0){// System.out.println(head.val);// head = head.next;// }}}
逆序遍历链表
剑指 Offer 22. 链表中倒数第k个节点 【codetop 100】
典型题目:高频考点,双指针定位 倒数第k个节点,数量掌握.
19. 删除链表的倒数第 N 个结点 【lc 100】【codetop 100】同上题,高频考点,熟练掌握.
链表交点
160. 相交链表 【lc 100】【codetop 100】高频考题,记住思路,熟练掌握:a+c+b = a+b+c.
剑指 Offer 52. 两个链表的第一个公共节点 【codetop 200】完全同 lc.160 相交链表.
环形链表
141. 环形链表 高频考题。双指针,一个每次走2步,1个每次走1步,若有环,此两点必相遇.
142. 环形链表 II 典型题目,高频考题,记住结论,要会证明。lc 141 的写法就是本题第一部分.
其他
14. 最长公共前缀 纵向枚举不同字符串的同一位置.
字符串
哈希表
242. 有效的字母异位词 基础题目:数组哈希。当然用 hashmap 也可以。
括号问题
20. 有效的括号 【lc 100】【codetop 100】
典型题目:括号问题入门题,高频考点,必会!注意 isEmpty ,别写错地方了.
22. 括号生成 【lc 100】【codetop 100】
非常重要的一道题:回溯 + 自己做的 + 根据 Y 总的纯递归;
讨论 “ 括号序列问题 ” + “ 回溯与递归却别 ” + “ 回溯中的 for 循环讨论问题 ”.
32. 最长有效括号 括号字串问题,非典型题,需要背板。
字符串运算
2. 两数相加 【lc 100】【codetop 100】
典型题目:属于“模拟题”,学会利用 % / 等计算符号.
注意:别忘了最后单独判断 进位是否为0!
43. 字符串相乘 Y总取巧优化,忘了可看视频。也属于模拟题了,模拟小学“列数式”的过程.
415. 字符串相加 【codetop 100】基本同 lc.2.
其他
5. 最长回文子串 【lc 100】【codetop 100】
方法很多,但是枚举法最容易理解,至于奇偶性,不需要判断,俩都便利一遍即可。
8. 字符串转换整数 (atoi) 【codetop 100】
溢出判断 ==> ans × 10 容易溢出,所以这里用MAX/10处理!
class Solution {public int myAtoi(String s) {int sign = 1, ans = 0, index = 0;char[] array = s.toCharArray();//1. 去除前导空格while (index < array.length && array[index] == ' ') {index ++;}//2. 判断正负号,只有第一个+/-有效; 只有是+/-时,这里index才++,否则无符号不++,当正数处理if (index < array.length && (array[index] == '-' || array[index] == '+')) {sign = array[index++] == '-' ? -1 : 1;}//3. 判断数字串:第一个不是数字的地方停止//3.1 数字截取,溢出判断//【注意】负号最后处理即可!前面计算全按“正数”计算while (index < array.length && array[index] <= '9' && array[index] >= '0') {int digit = array[index++] - '0';//【重要】溢出判断 ==> ans × 10 容易溢出,所以这里用MAX/10处理!!if (ans > (Integer.MAX_VALUE - digit) / 10) {//根据正负号,判断溢出时返回MAX还是MINreturn sign == 1 ? Integer.MAX_VALUE : Integer.MIN_VALUE;}ans = ans * 10 + digit;}//3.2 正负号处理return ans * sign;}}
394. 字符串解码 递归(貌似用堆也行,没试过),细节多,易出错
哈希表
数组 Hash
242. 有效的字母异位词 基础题目:数组哈希。当然用 hashmap 也可以。
Hash Set
349. 两个数组的交集 基础题目:HashSet 应用。
Hash Map
383. 赎金信 简单的 map 应用问题.
栈与队列
224. 基本计算器 典型题目:表达式求值模板题。与 lc 227 侧重略有不同。
样例增强后,Y总代码过不了了。根据三叶大大建议补充3点细节才能过。
227. 基本计算器 II 典型题目:表达式求值模板题。比较难想,记住思路与分类,背过即可。
补充Y总在笔试面试辅导课里讲过:day8 acwing454.表达式求值,有例子。
Y总在 acwing151.表达式计算4 中详细讲解,有例子。这个版本太复杂了,先不用考虑。
[注意] lc 224 仅 + - ( ),无 /;lc 227 考虑了 + - /,无 ( )。因此,两题应该结合!
155. 最小栈 【lc 100】【codetop 100】
最小栈本质是前缀最小值,最小值
二叉树
662. 二叉树最大宽度 感觉是蛮特殊的一道 BFS宽度求解
剑指 Offer 54. 二叉搜索树的第k大节点 【codetop 200】
分析与代码二叉搜索树的性质:中序遍历是递归序列;
因为求第K大,所以 按“右中左”的顺序遍历,从而得到递减数列。
class Solution {//三、递归调用public int kthLargest(TreeNode root, int k) {K = k;dfs(root);return res;}//一、声明变量int res = -1;int K = 0; //值调用的问题,所以要定义全局变量//二、dfs 方法void dfs(TreeNode root){if(root == null) return;//因为求第K大,所以 按“右中左”的顺序遍历,从而得到递减数列dfs(root.right);K--;if(K == 0){res = root.val;return;}dfs(root.left);}}
94. 二叉树的中序遍历 【lc 100】【codetop 100】递归 迭代,都得会!
102. 二叉树的层序遍历 【lc 100】【codetop 100】经典题目,必会!
103. 二叉树的锯齿形层序遍历 【codetop 100】
比 lc.102 的层序遍历多用了一个 API 而已:Collections.reverse(…)。
199. 二叉树的右视图 【lc 100】 目前只开发了迭代法,递归法还没做过呢.
112. 路径总和 【codetop 100】 回溯二叉树!
剑指 Offer 34. 二叉树中和为某一值的路径 【codetop 200】完全同 lc 112. 路径总和
226. 翻转二叉树 【lc 100】【codetop 100】
剑指 Offer 27. 二叉树的镜像 【codetop 200】 简单的递归,完全同 lc 226. 翻转二叉树
剑指 Offer 36. 二叉搜索树与双向链表 【codetop 200】较难,背板,中序遍历。 题解链接:pre 和 head 指针含义要搞清楚.https://leetcode.cn/problems/er-cha-sou-suo-shu-yu-shuang-xiang-lian-biao-lcof/solution/tu-wen-bing-mao-zui-tong-su-yi-dong-de-t-0adg/
297. 二叉树的序列化与反序列化 【lc 100】【codetop 200】 这题有啥意思?就是个考的频率高的困难题,背思路呗做法有很多,这里用的是 “前序遍历”.
public class Codec {// 一、序列化(前序遍历):Encodes a tree to a single string.public String serialize(TreeNode root) {if(root == null) return null;return root.val + "," + serialize(root.left) + "," + serialize(root.right);}// 二、反序列化:Decodes your encoded data to tree.//2.1 反序列调用public TreeNode deserialize(String data) {if(data == null) return null; //【易错】输入样例 [] 时,能不报错.String[] dataArray = data.split(","); //切去逗号,分开字符//【没见过的API:asList——数组转成List】List<String> dataList = new LinkedList<String>(Arrays.asList(dataArray));return deserializeDfs(dataList);}//2.2 反序列递归public TreeNode deserializeDfs(List<String> dataList) {//(1)处理空字数if (dataList.get(0).equals("null")) {dataList.remove(0); //处理完就KO掉return null;}//(2)处理非空字符//每处理一个就remove,因此每次都处理开头元素TreeNode root = new TreeNode(Integer.valueOf(dataList.get(0)));dataList.remove(0);//从left出来的dataList,已经把左子树消去了root.left = deserializeDfs(dataList);root.right = deserializeDfs(dataList);//(3)return root;}}
并查集
特殊数据结构
二、算法思想
排序
import java.util.Scanner;import java.io.BufferedInputStream;public class Main{//二、输入输出public static void main(String[] args){Scanner br = new Scanner(new BufferedInputStream(System.in));//接收第一行int all = br.nextInt();//接收第二行int[] arr = new int[all];for(int c = 0; c < all; c++){arr[c] = br.nextInt();}//调用方法mergeSortTest(0,all-1,arr);//输出for(int c = 0; c < all; c++){System.out.print(arr[c] + " ");}}//一、归并排序public static void mergeSortTest(int m, int n, int[] arr){//【错误1】没有写返回值!//1.看看头尾是否相接,相接了就继续算if(m >= n) return;//2.分成两端,去递归归并排序,得到左右两端都是排好序的int b = (m + n) >> 1;mergeSortTest(m,b,arr);mergeSortTest(b+1,n,arr);//3.设定一些参数,然后进行合并//(1)定义些参数int i = m; //左半指针int j = b+1; //右半指针int k = 0;int[] temp = new int[n+1-m]; //单独开一个数组来记录排序结果//(2)两半对比填入while(i <= b && j <= n){if(arr[i] < arr[j]) temp[k++] = arr[i++];else temp[k++] = arr[j++];}//(3)没对比完的再加进去//【错误3/重要】这里和前面一样,用 while 控制循环,而非if//这里用 if 只会运行 1 次,得用循环!非要用if也可,但是会很麻烦。if(i <= b) temp[k++] = arr[i++];if(j <= n) temp[k++] = arr[j++];//4. 排好序 temp 中的数据的给弄回去//【错误2】这是 <= n 而非 < n;for(int t = m, r = 0; t <= n; t++,r++) arr[t] = temp[r];}}
148. 排序链表 【lc 100】【codetop 100】链表归并排序,板子题,背背背.
关键点.(1)核心:两重循环
一层循环枚举区间长度,二层循环枚举区间起点.
(2)二次循环为什么 j + i ?
就是判断 右半段是不是存在!
右半段存在,最后这两段需要归并;
如果不存在,就只有左半段,不归并了.
(3)循环中为什么怎么声明 dummy?之后区间的起点怎么得到的?
通过二层循环中的归并,更新节点得到的;
每个区间归并完了之后,还有个 cur.next = r 呢,就是代表 cur 更新为下一个区间的起点.
(4)比一般链表归并多了什么?
多了一个区间长度的计数。
本题中,最后一段的长度不一定满足 i ,所以需要单独记录一下.
class Solution {//Y总题解:https://www.acwing.com/solution/content/408/public ListNode sortList(ListNode head) {//0.计算链表长度,为后续提供依据int len = 0;ListNode tmp = head;while(tmp != null){tmp = tmp.next;len++;}//1.枚举每一轮递归区间的长度(自下而上归并)ListNode dummy = new ListNode(-1);dummy.next = head;for(int i = 1; i < len; i *= 2){ListNode cur = dummy;cur = dummy; //cur在dummy下面一层,我们操作cur这一层,往dummy这层排序//2.枚举 2i 个节点的 区间起点.//【特判】当n不是2的整次幂时,每次迭代只有最后一个区间会比较特殊,长度会小一些,遍历到指针为空时需要提前结束。// j+i就是右半区间的起点,如果>len了,说明没有右半段区间,那么就不进行归并了.//【重要】理解j+i可以看Y总题解下面老哥的详细总结的那张图:说白了,最后不是2^n的那段一定能执行到!for(int j = 1; j+i <= len; j += 2*i){ // j为每2i点区间的起点.//3. 遍历得到每一个 2i 区间的 左/右 区间起点.ListNode p = cur.next; //p是左半起点,cur在遍历后,成为是上一段2i区间的最后一个点.ListNode q = p; //q是右半起点for(int k = 0; k < i && q != null; k++) q = q.next; //q移动到2i的右半的起点.//5. 归并排序1:左右区间对比排序int l = 0; //记录左半区间遍历的个数int r = 0; //记录右半区间遍历的个数while(l < i && r < i && p != null && q != null){if(p.val <= q.val){// cur = cur.next = p; //cur始终在前一位cur.next = p;cur = cur.next;p = p.next;l++;}else{cur = cur.next = q;q = q.next;r++;}}//6. 归并排序2:左右对比后剩余区间排序while(l < i && p != null) {cur = cur.next = p;p = p.next;l++;}while(r < i && q != null) {cur = cur.next = q;q = q.next;r++;}//7. 记录新的起点cur.next = q;}}//8. 返回return dummy.next;}}
剑指 Offer 51. 数组中的逆序对 【codetop 100】归并排序板子题,就比模板多了一句
易错:考虑 res 时,不能包括等于 的情况!
215. 数组中的第K个最大元素 【lc 100】【codetop 100】 快排模板.
912. 排序数组 典型题目:就这个题,各种排序挨个拉进去试验吧,板子都背下来
补充题6:手撕堆排序 板子,背背背!
前缀和
560. 和为 K 的子数组 典型题目:前缀和 + 哈希表,当作板子题吧。
哈希函数
128. 最长连续序列 本题做法多,但是使用 hashset 是最容易理解的。思路有点小绕,建议背板。
347. 前 K 个高频元素 哈希表 + 计数排序。中间数组的含义一定要搞清楚!
双指针
15. 三数之和 【lc 100】【codetop100】
经典题目,必会好吧!注意 a b c 的重复值的跳过条件,别搞错了.
剑指 Offer 21. 调整数组顺序使奇数位于偶数前面 【codetop 200】
左程云两指针都是从左往右,Y总指针一前一后。
类似题目(左程云大厂刷题班):一个字符放左,一个字符放右的最少次数


G和B分别算一遍,然后比较看那个更省事
24. 两两交换链表中的节点 双指针(其实不止,用了4个)。还是翻转节点类似的题目。
83. 删除排序链表中的重复元素 链表双指针.
203. 移除链表元素 链表最基础的题目,学习 双指针 与 虚拟头 结点配合删除节点.
剑指 Offer 22. 链表中倒数第k个节点 典型题目:双指针定位 倒数第k个节点.
27. 移除元素 典型题目:快慢指针的运用.
283. 移动零 数组双指针.
977. 有序数组的平方 双指针 + 二路归并.
141. 环形链表 【lc 100】【codetop 100】
高频考题。双指针,一个每次走2步,1个每次走1步,若有环,此两点必相遇。
142. 环形链表 II 【lc 100】【codetop 100】
典型题目,高频考题,记住结论,要会证明。lc 141 的写法就是本题第一部分。
202. 快乐数 这道题其实就是 包装后的环形链表.
lc 202 双指针法 分析.
其中:
慢指针就是每次把数字各位求一次平方和.
快指针就是每次把数字各位求两次平方和.
有两种情况:
是快乐数:最后两个指针都会变成1,重合在一起
不是快乐数:相当于一个环,快慢指针总会在某个数处相遇
即:不管是不是快乐数,快慢指针最终都会汇聚到一个数上,我们只需要判断这个数是不是 1 即可.
注:使用 do-while 可以少一个次判断,因为:一开始 fast 和 slow 都是n,终止条件 fast != slow
287. 寻找重复数 【lc 100】【codetop 200】 本题是 lc. 142 环形链表 II 的数组版本,背板吧.
题解题解地址:https://leetcode.cn/problems/find-the-duplicate-number/solution/287xun-zhao-zhong-fu-shu-by-kirsche/
这个题解的图好理解,Y总那个讲的太抽象.
【注意】从 0 开始(代表 0 下标开始),0一定不在环内,0 只是下标,存的数没有是 0 的.
class Solution {//映射关系:下标i,的下一个数据是 nums[i] 对应的下标//本题基本完全同 lc. 142 环形链表 IIpublic int findDuplicate(int[] nums) {int slow = 0;int fast = 0;//1. 找到快慢指针相遇的位置.while(slow == 0 || slow != fast){ //slow 和 fast 为 0 的情况要跳过.slow = nums[slow];fast = nums[nums[fast]];}//2. 一个从相遇点出发,一个从起点出发.int res = 0;while(res != slow){res = nums[res];slow = nums[slow];}//return res;}}
11. 盛最多水的容器 经典面试题,思路难想,直接背过。
二分
34. 在排序数组中查找元素的第一个和最后一个位置 典型题目:二分模板题
153. 寻找旋转排序数组中的最小值 与 lc33.搜索旋转排序数组很类似,这个题是简化版,1次二分.
162. 寻找峰值 Y总面试辅导课,第一天 acwing.1462 矩阵极小值 简化版
704. 二分查找 【codetop 100】二分板子题,熟背。
while 中的 if 中,必须是 l = mid 或者 r = mid, = mid +- 1 这种不可以!!
剑指 Offer 53 - I. 在排序数组中查找数字 I 【codetop 200】二分查找板子题
递归
回溯
排列
46. 全排列 【lc 100】【codetop100】
要点:和组合题目进行对比,得 [全排列] 不同于 [组合] 的两大特点【重要】统计元素是否被使用过。
因为有顺序问题,不能像组合问题一样,用start规避顺序问题:boolean[] used.
【重要】不考虑start参数了,因为 ab ba 是不同的结果:void dfs(int[] nums){…}:
class Solution {//三、调用public List<List<Integer>> permute(int[] nums) {int len = nums.length;used = new boolean[len];dfs(nums);return res;}//一、声明变量List<List<Integer>> res = new ArrayList<>();List<Integer> tmpRes = new ArrayList<>();boolean[] used; //【重要】体现与组合问题的差异:统计元素是否被使用过//二、dfsvoid dfs(int[] nums){//【重要】与组合问题不同,不考虑start参数了,因为 ab ba 是不同的结果.//终止条件if(tmpRes.size() == nums.length){res.add(new ArrayList<>(tmpRes));return;}//循环递归for(int i = 0; i < nums.length; i++){//若已在排列中,就跳过if(used[i]) continue;//递归used[i] = true;tmpRes.add(nums[i]);dfs(nums);//回溯used[i] = false;tmpRes.remove(tmpRes.size() - 1);}}}
79. 单词搜索 【lc 100】【codetop200】
class Solution {//三、调用public boolean exist(char[][] board, String word) {for(int i = 0; i <board.length; i++){for(int j = 0; j <board[i].length; j++){dfs(board, word, i, j, 0);}}return res;}//一、声明变量 【注意】不需要声明sb,每次判断对应字母是否符合即可,不用专门拼接// StringBuilder<Character> sb = new StringBuilder<>();int[] dx = new int[]{-1,0,1,0};int[] dy = new int[]{0,1,0,-1};boolean res = false;//二、递归与回溯void dfs(char[][] board, String word, int startX, int startY, int u){//1. 如果第u个字符,与word不匹配,直接跳过.if(board[startX][startY] != word.charAt(u)) return;//2. 到这第u个字符应该是匹配的,若所有字符都匹配了,就可以返回结果了!if(u == word.length() - 1){res = true;return;}//3. 至此,说明需要继续判断. 对当前点进行标记,便于判断,也便于回溯char t = board[startX][startY]; //用于回溯board[startX][startY] = '.'; //标记,表示已经匹配过了//4. 向各个方向递归for(int i = 0; i < 4; i++){int x = startX + dx[i];int y = startY + dy[i];if(x < board.length && y < board[0].length && x >= 0 && y >= 0 && board[x][y] != '.')//【细节】board[x][y] != '.' 其实可以无需判断,改成'.'以后,之后递归一定匹配不上// if(x < board.length && y < board[0].length && x >= 0 && y >= 0)dfs(board, word, x, y, u + 1);}//5. 回溯board[startX][startY] = t;}}
组合
77. 组合 基础题目。组合类型题目的入门题目。 关键在于:不重复。因此,dfs 的 start 形参很关键!
组合问题中 startIndex 的理解如图,取完1后,取2的时候,只考虑 3 4,1就不考虑了.
依次取 1 2 3 4,取到 x 时,x 之前得就不要了!x 就是start.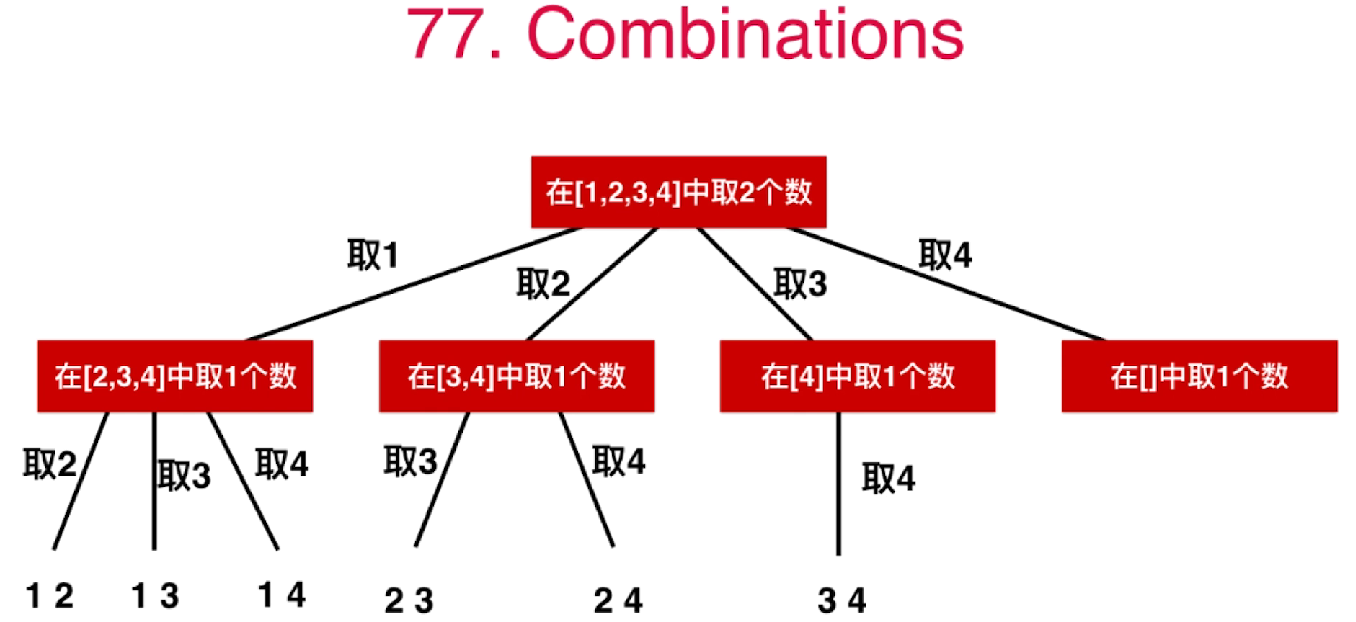 “剪枝”优化
“剪枝”优化
39. 组合总和 【lc 100】【codetop100】 注意与 lc.77 的对比:本题递归时 start 不用再 +1,因为可重复.
本题要点(代码随想录做法)一、组合问题的特点:
组合问题的经典问题,特点:每个数值可选次数“无限”.
==> 不像一般的组合问题,递归的 start 从 start 开始,而非 start+1,因为不限次数.
易错1:需要事先对数组排序.
易错2:循环中加一个 target 和 can..[i] 的判断,仅凭外面的 == 无法终止递归,因为有 != 的情况,如果出现,可能一直递归.
二、思考:carl哥做法中,为何“剪枝”写法需要“事先排序”?
重点理解这里剪枝,前提是候选数组已经有序。
你要是无序,不能保证循环后面的元素不满足要求!你目标是5,你没排序,6在1前,结果你6不符合要求,直接跳出循环了,那么后面1参与的方案就被忽略了!
class Solution {//三、调用public List<List<Integer>> combinationSum(int[] candidates, int target) {Arrays.sort(candidates);//【易错/重要】需要排序,配和“剪枝”dfs(candidates, target, 0);return res;}//一、声明变量List<List<Integer>> res = new ArrayList<>();List<Integer> tmpRes = new ArrayList<>();//二、构建dfs方法 组合问题标志性性的形参:startvoid dfs(int[] candidates, int target, int start){//(1)终止条件1if(target == 0){res.add(new ArrayList<>(tmpRes));return;}//(2)遍历起始元素,递归for(int i = start; i < candidates.length; i++){//【易错/重要】(2)终止条件2:(同样也是“剪枝”操作)// 不加这个条件,那么只要遇到!=0的情况,会死循环if (candidates[i] > target) break;//(3)递归tmpRes.add(candidates[i]);//【不同于lc.77】不用i+1了,表示可以重复读取当前的数dfs(candidates, target - candidates[i], i); //target的处理为“剪枝”//(4)回溯tmpRes.remove(tmpRes.size() - 1);}}}
子集
78. 子集 【lc 100】【codetop100】 与 lc .77 组合 对比理解有奇效.
子集问题的特点,与“组合问题”对比.(子集问题可以看作是组合问题,不过是“注重过程”的组合问题)【重要辨析】和 lc.77 组合最大的区别:终止条件改成这个添加到结果
「遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合」。
//组合问题:dfs中,上来是终止条件if(tmpRes.size() == k){res.add(new ArrayList<>(tmpRes));return;}//子集问题:dfs中,一上来直接存入结果()
class Solution {//三、调用public List<List<Integer>> subsets(int[] nums) {dfs(nums, 0);return res;}//一、声明List<List<Integer>> res = new ArrayList<>();List<Integer> tmpRes = new ArrayList<>();//二、递归与回溯void dfs(int[] nums, int start){//【重要辨析】和 lc.77 组合最大的区别:终止条件改成这个添加到结果//「遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合」。res.add(new ArrayList<>(tmpRes));for(int i = start; i < nums.length; i++){tmpRes.add(nums[i]);dfs(nums,i+1);tmpRes.remove(tmpRes.size() - 1);}}}
分割
其他
22. 括号生成 【lc 100】【codetop 100】
非常重要的一道题:回溯 + 自己做的 + 根据 Y 总的纯递归;
讨论 “ 括号序列问题 ” + “ 回溯与递归却别 ” + “ 回溯中的 for 循环讨论问题 ”.
394. 字符串解码 递归(貌似用堆也行,没试过),细节多,易出错
DFS 和 BFS
200. 岛屿数量 【lc 100】【codetop 100】
【flood fill/“洪水灌溉” 算法模板题】该算法“经典”且“easy”两种实现方式:dfs 和 bfs,一般写 dfs,因为可以不用写队列.
【思路】
① 先依次枚举原图每个位置(两重循环)
② 当前格子没被遍历且是 1 ,则从这个格子开始遍历.
③ 每次遍历时,搜索上下左右四个格子(dfs的情况),搜到的格子我们将其“从1标记为0”。
如果某个格子是没有走过的格子且为 1,就会递归继续搜,直到找出所有与一开始相连的所有 1 为止。
(bfs的话,就是把上下左右没走过的1都放在队列里面)
宗旨就是:把当前 1 所有与之相连的1都找出来,并标记.那么这里其实每次是相当于找一个连通块!
这就是flood fill算法的经典逻辑.
class Solution {//为了方便调用,这里把数组搞成 [全局变量]char[][] g;public int numIslands(char[][] grid) {g = grid;int res = 0;for(int i = 0; i < g.length; i++){for(int j = 0; j < g[0].length; j++){//【易错】本题中,1不是int而是charif(g[i][j] == '1'){dfs(i,j);res++;}}}//return res;}//dfsvoid dfs(int i, int j){//进行标记,表示搜索过了g[i][j] = 0;//遍历上下左右4个方向,如果==1,那么就递归for(int k = 0; k < 4; k++){ //【细节】k代表次数的同时,还做了下标// 上下左右(【细节】这里得诚信声明变量,不能把传进来的 i j 覆盖了)int ii = i + dx[k];int jj = j + dy[k];// 如果下标是否合法,判断是否为1,进而决定是否递归if(ii > -1 && ii < g.length && jj > -1 && jj < g[0].length && g[ii][jj] == '1'){dfs(ii,jj);}}}//【重要】补充两个向量,用来表示上下左右(这种方式就背会)int[] dx = new int[]{-1,0,1,0};int[] dy = new int[]{0,-1,0,1};}
236. 二叉树的最近公共祖先 【lc 100】【codetop 100】 递归
左程云:p/q一个是另一个的祖先 + p q 公共祖先是另一个节点.
662. 二叉树最大宽度 感觉是蛮特殊的一道 BFS宽度求解
剑指 Offer 62. 圆圈中最后剩下的数字 【codetop 200】约瑟夫环问题
递推公式分析忘了去看Y总讲解, 表示 n 个数,数m个剔除一个数,结束时的编号
表示 n 个数,数m个剔除一个数,结束时的编号 ,与
,与 存在递推关系,第 m 个数(m-1)KO后,重新编号,编号 m 的从 0 开始,所以新老序号之间差一个 m 。
存在递推关系,第 m 个数(m-1)KO后,重新编号,编号 m 的从 0 开始,所以新老序号之间差一个 m 。
public int lastRemaining(int n, int m) {if(n == 1) return 0;return (lastRemaining(n-1, m) + m) % n;}
贪心
55. 跳跃游戏 【lc 100】贪心经典题目,思路背过,熟悉代码.
贪心:保证(能够到达的最远位置)能够覆盖(当前位置)
179. 最大数 定义了新的比较规则,思路难想,证明是必须的,直接背过。
动态规划
基础问题
70. 爬楼梯 【lc 100】【codetop 100】 DP 入门题目,经典的 .
.
62. 不同路径 【lc 100】【codetop 100】 DP 入门题目,初始化很重要
剑指 Offer 10- I. 斐波那契数列 【codetop 200】 注意要求取模
剑指 Offer 10- II. 青蛙跳台阶问题 【codetop 200】 基本同 剑指 Offer 10- I. 斐波那契数列.
【背包问题】 01背包
套路分析
01背包:每件物品最多用 1 次。一、集合定义
(1)集合
f [ i , j ]:所有只考虑前 i 个物品,且总体积不超过 j 的选法的集合。
(2)属性
max / min / count / …
二、状态方程
(以求 max 为例)
状态分析:(i, j)一共可以分为 2 个集合:包含 / 不包含 第 i 件物品的。
三、优化思路
做法:二维数组变一维数组,内存循环从往前遍历。
一维数组中, 层的
层的 需要用到
需要用到  层的
层的 ,如果【从后往前】遍历,那么
,如果【从后往前】遍历,那么  层的
层的 会被
会被  层的覆盖掉,这样结果就错了!
层的覆盖掉,这样结果就错了!
四、做题细节
(1)一般 声明大小时,会 +1,0 索引初始化集合,内外层 dp 遍历都从 索引 1 开始 而非 0 开始。
声明大小时,会 +1,0 索引初始化集合,内外层 dp 遍历都从 索引 1 开始 而非 0 开始。
(2)易错细节1
//通过朴素写法分析-------------------------for(int i = 1; i < len; i++){for(int j = 0; j <= sum; j++){res[i][j] = res[i-1][j]; //【正确写法】f[i-1][j]不用判断就能算if(j >= nums[i])res[i][j] = Math.max(res[i][j], res[i-1][j-nums[i]] + nums[i]);}}--------------------------for(int i = 1; i < len; i++){for(int j = nums[i-1]; j <= target; j++){//【错误写法】这么写的话,f[i-1][j] 有时候根本算不了!f[i][j] = Math.max(f[i-1][j], f[i-1][j - nums[i-1]] + nums[i-1]);if(f[i][j] == target) return true;}}
题目
416. 分割等和子集 dp 中,不同子集可以计算的时机不同,要学会拿捏!(理论部分易错细节1)。
奇偶别忘了特判。
【背包问题】 完全背包
套路分析
完全背包:每件物品可用无数次。一、集合定义(同01背包)
(1)集合
f [ i , j ]:所有只考虑前 i 个物品,且总体积不超过 j 的选法的集合。
(2)属性
max / min / count / …
二、状态方程
(以求 max 为例)
(中间是有推导过程的,结果来看,和 01 背包差在:第二项是 而非
而非 )
)
状态分析:划分成若干子集;① 第 i 个物品不要; ② 第 i 个物品 要 k 个(k > 1)。
三、优化思路
做法:二维数组变一维数组,内存循环【从前往后】遍历。(与 01 刚好相反!)
一维数组中, 层的
层的 需要用到
需要用到  层的
层的 ,需要提前算出来,这样结果就错了!
,需要提前算出来,这样结果就错了!
四、做题细节
…
题目
279. 完全平方数 【codetop 100】
和 lc 322 几乎一样的,初始化方式也是一样的.
322. 零钱兑换 【lc 100】【codetop 100】
注意除了 f[0] 都初始化成 amout + 1 (max不太行,操作完了容易越界),
初始化使用 Arrays.fill(dp, amout + 1) ;
518. 零钱兑换 II 非常经典的 完全背包DP 问题,算是模板题了。
【线性DP】
连续子序列
53. 最大子数组和 【lc 100】【codetop 100】连续子序列DP模板题。这个题用贪心也行。
剑指 Offer 42. 连续子数组的最大和 【codetop 100】完全同 lc.53
674. 最长连续递增序列 典型题,简单题,可用 int 变量优化掉数组。
718. 最长重复子数组 基本同 lc53,也是考虑 “区间长度” 为集合划分依据。
lc 53 分析:Y氏DP法 ==> “ [ 连续 ] 子序列问题 ”(1) 状态表示
 :以第
:以第 个元素为 “右边界” 的区间中,所有最大和的连续子数组的集合。
个元素为 “右边界” 的区间中,所有最大和的连续子数组的集合。
(2)状态计算
【分类方式/非常重要】以”区间的长度”进行划分!
① 长度  :仅包含第
:仅包含第 个元素.
个元素. 
② 长度 :第
:第 个元素必包含,考虑
个元素必包含,考虑 为右边界的区间即可!
为右边界的区间即可! 
==>  (以求max举例)
(以求max举例)
(3)优化:因为递归中只涉及 和
和 ,所以不用开辟数组,直接用【一个变量】存储即可.
,所以不用开辟数组,直接用【一个变量】存储即可.
不连续子序列
1035. 不相交的线 和 lc1143. 最长公共子序列 代码基本一模一样。
1143. 最长公共子序列 【codetop 100】
【重要/题型分析】以 lc 1143. 最长公共子序列为例。Y总:最长子序列 (可以不连续,DP好做),最长子数组 (得连续,有更优的做法)。
(1)状态分析
 :数组 A 的
:数组 A 的 ,数组 B 的
,数组 B 的 ,的公共的 、长度最长的子数组的长度
,的公共的 、长度最长的子数组的长度
==> 求max
(2)状态计算 <br /> ① 字串含 A 的,含 B 的: <br /> ② 字串不含 A 的,含 B 的: <br /> ③ 字串含 A 的,不含 B 的: <br /> ④ 字串不含 A 的,不含 B 的: 其中,④包含于②③;②③有重复。<br />①②③保证集合不漏,虽有重复,但是因为求的是max,有重复也没关系;<br /> ==> 
300. 最长递增子序列 【lc 100】【codetop 100】
非典型的 DP 思路,常考,需要背板。(代码还有细节,见提交的注释)。
本题没想到怎么从Y总的解题思路去理解,他也没讲; 看carl哥得了。
lc 300. 题目分析(1)状态分析:假设 是第
是第 号位的数字中,【包含第
号位的数字中,【包含第 位】的“最长严格递增子序列的长度”.
位】的“最长严格递增子序列的长度”.
(2)状态计算: .
.
 是
是 中的“最长严格递增子序列的长度”.
中的“最长严格递增子序列的长度”.
==> 其实第一次看到这个状态计算,其实挺难理解的,因为这个思考方式不符合“自底向上”.
我们没有根据 i 去分类,而是直接默认“包含第i位”.
代码中,对于每一个 i,上来都要用“ ”,这行代码非常棒关键,是帮助我们理解状态计算的关键!==> 【每次我们都是先默认第 i 位已经在这个序列中,初始长度就是1】+
”,这行代码非常棒关键,是帮助我们理解状态计算的关键!==> 【每次我们都是先默认第 i 位已经在这个序列中,初始长度就是1】+
【然后再去 中找比它小的】
中找比它小的】
(3)Y总思路套不上
但是确实,从Y总那种思路不好处理:
 表示 1~i 中的max; 假设分为“含第i位”和“不包含第i位”,那么分别是
表示 1~i 中的max; 假设分为“含第i位”和“不包含第i位”,那么分别是 和
和 ;然后呢?想不到怎么处理了.
;然后呢?想不到怎么处理了.
/*(本题没想到怎么从Y总的解题思路去理解,他也没讲; 看carl哥得了)状态分析:假设f[i]是第1~i号位的数字中,【包含第i位】的“最长严格递增子序列的长度”状态计算:f[i] = max( f[i] , f[j] + 1 ). j是1~i-1中的“最长严格递增子序列的长度”.==>其实第一次看到这个状态计算,其实挺难理解的,因为这个思考方式不符合“自底向上”.我们没有根据i去分类,而是直接默认“包含第i位”.--->代码中,对于每一个i,上来都要用“f[i]=1”,这行代码非常棒关键,是帮助我们理解状态计算的关键!【每次我们都是先默认第i位已经在这个序列中,初始长度就是1】+【然后再去1~i-1中找比它小的】-------------------------------------------------但是确实,从Y总那种思路不好处理:f[i]表示1~i中的max;假设分为“含第i位”和“不包含第i位”,那么分别是f[i-1]+1和f[i-1];然后呢?想不到怎么处理了..*/public int lengthOfLIS(int[] nums) {//1.int len = nums.length;int[] f = new int[len + 1];//2. DPfor(int i = 1; i <= len; i++){f[i] = 1;for(int j = 1; j < i; j++){/*理解这句话很重要\U0001f447nums[i] 必然要大于nums[j],才能将 nums[i] 放在nums[j] 后面以形成更长的上升子序列!==>即 1~j已经自成“最长严格递增子序列的长度”,只要保证nums[i] > nums[j],则【1~j中的子序列 和 i 就能组成新的子序列】!!==>再一次体现了本题的不同:【不是完全的“自底向上”】,而是确定了后面某个值,再“自底向上” !*/if(nums[i-1] > nums[j-1]) //考虑偏移量f[i] = Math.max(f[i], f[j] + 1);}}//3. 【易错】// return f[len];/*为什么这里还要再遍历一遍?DP的话,dp[n]难道不是结果吗?==>因为本题dp[i]定义是:【包含i号位】的最长子序列!这个集合,【不包含所有情况!】因为子序列最长时,其实“不一定要包含第i号位”∴ 最后需要遍历dp[i]找max==>再次体现出了,本题与【之前DP思路的差异】,不能算是完全的“自底向上”!*/int res = 0;for (int i = 1; i <= len; i++) {res = Math.max(res, f[i]);}//4. 返回return res;}}
回文
编辑距离
72. 编辑距离 【lc 100】【codetop 100】
Y氏分析 编辑距离 【经典DP题目】
(1) 状态分析
 :把 A的
:把 A的 操作成与 B的
操作成与 B的 相等时 的最少操作次数.
相等时 的最少操作次数.
(2) 共识
① 操作顺序不影响最终结果,所以我们只考虑“按顺序的情况”,我们就按“自底向上”考虑.
② 一个字符一般就操作一次,操作两次就是多余的,绝不是最优!如:加上a再删掉a,就没啥必要.
(3) 状态计算
情况1:A删掉i后,与 B的1-j 一致.

情况2:A在i后加上数字后,与 B的1-j 一致. 说明A的1-i和B的1-j-1一致

情况3:A修改i后,与 B的1-j 一致. 说明,至少,A的1-i-1和B的1-j-1一致.
当 时:
时:

当A[i] == B[j] 时:

———————————————————-
其实Y总讲的时候,分了6种情况,A三种和B三种;
但是因为B的推出来和A的一样,所以最后就是三种.
==> 但是题目说了只操作word1,所以我感觉没必要这样!
class Solution {public int minDistance(String word1, String word2) {//int len1 = word1.length();int len2 = word2.length();int[][] f = new int[len1 + 1][len2 + 1];char[] A = word1.toCharArray();char[] B = word2.toCharArray();//初始化for(int i = 1; i <= len1; i++) f[i][0] = i; //A中的i个字符全删掉for(int j = 1; j <= len2; j++) f[0][j] = j; //A中对着B的j个字符挨个加//DPfor(int i = 1; i <= len1; i++){for(int j = 1; j <= len2; j++){f[i][j] = Math.min( f[i-1][j] , f[i][j-1] ) + 1;if(A[i-1] != B[j-1]){f[i][j] = Math.min( f[i][j] , f[i-1][j-1] + 1 );}else{f[i][j] = Math.min( f[i][j] , f[i-1][j-1] );}}}//return f[len1][len2];}}
【树形DP】
【区间DP】
【状态压缩DP】
【状态机DP】
特殊DP
152. 乘积最大子数组 不是知道啥类型的DP,反正Y总也没用Y氏DP法分析。
221. 最大正方形 特殊的DP,不太能用Y总的分析方式,dp表达式背过即可,不太好想.
滑动窗口
3. 无重复字符的最长子串 【lc 100】【codetop 100】
典型题目:滑动窗口 + 双指针,同时使用 哈希表 统计次数.
76. 最小覆盖子串 lc3 的升级版.
单调栈
42. 接雨水 【lc 100】【codetop100】 背就完事了,想啥呢.
class Solution {public int trap(int[] height) {//声明栈Deque<Integer> st = new ArrayDeque<>();st.addFirst(0);//计算长度int len = height.length;//声明结果int res = 0;//遍历每一个柱子for(int i = 0; i < len; i++){//情况1:【单调栈的形成】如果新柱子矮,那就入栈if(height[i] < height[st.peek()]) st.addFirst(i);//情况2:(可以和情况1合并)//当前柱子等于前一根柱子,不形成水槽,为避免后续影响,之前的pop,这里再加入else if (height[i] == height[st.peek()]){st.removeFirst();//不写这个不影响结果,因为到时候情况三计算h会为0,写着不过是容易理解st.addFirst(i);}else{//情况3:当前柱子比之前柱子高,那就有可能形成水槽//【st.size()】就是为了判断栈中还有没有柱子,没有柱子了就没有水槽了!while(st.size() > 0 && height[i] > height[st.peek()]){int idx = st.removeFirst();//取出左边的柱子,水槽的底部if(st.size() > 0){ //【细节】取出后再看看还有没有柱子.int left = st.peek(); //水槽左边界:左侧高柱的右边界,这个值=index.int right = i - 1; //水槽右边界:右侧/当前高柱的左边界,这个值=index - 1.int width = right - left;//求高度:左右柱子的min - 水槽底部高度 = 水槽高度int h = Math.min(height[left],height[i]) - height[idx];res += h * width;}}st.addFirst(i);}}return res;}}
739. 每日温度 典型题目:单调栈模板题.
(感觉和Y总讲的板子不一样啊,我从题解吴师兄视频看的这个更好理解)
拓扑排序
前缀和 & 差分
三、系列问题
N 数之和
1. 两数之和 【lc 100】【codetop100】
经典题目,不会就丢人啊。 当然 nums[i] 存为 key,下标 i 存为 value,反着来.
15. 三数之和 【lc 100】【codetop100】
经典题目,必会好吧!注意 a b c 的重复值的跳过条件,别搞错了.
N 数相加
2. 两数相加 【lc 100】【codetop 100】
典型题目:属于“模拟题”,学会利用 % / 等计算符号.
注意:别忘了最后单独判断 进位是否为0!
股票买卖(不都是 DP 问题)
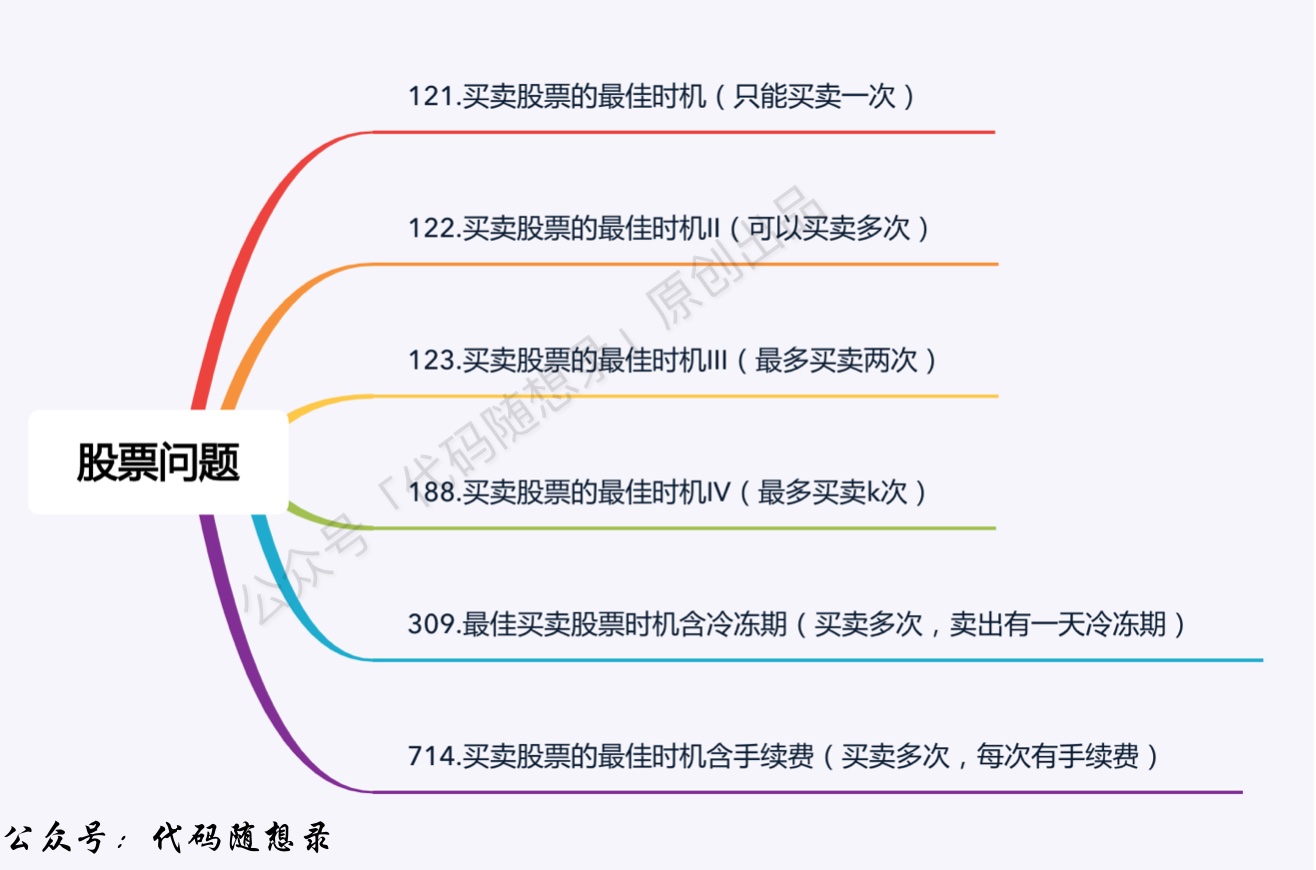
121. 买卖股票的最佳时机 一次买卖。 一次遍历,遍历时维护 res 和 minPrice .
122. 买卖股票的最佳时机 II 多次买卖。 可 DP,可贪心. DP时别忽略了初始化.
lc 122. DP法(结合Carl哥的思路):(1)状态表示:
假设 表示:第
表示:第 天,股票持有状态为
天,股票持有状态为 【仅0和1】时,所得的利润【买入就
【仅0和1】时,所得的利润【买入就 ,卖出就
,卖出就 】.
】.
(2)状态计算:0表示不持有,1表示持有(和Carl哥相反)
(1)第 天“持有”股票:
天“持有”股票:
① 第 天“已经持有”股票;
天“已经持有”股票;

② 第 天“并未持有”股票,而在第
天“并未持有”股票,而在第 天才买入;
天才买入;

(2)第 天“未持有”股票:
天“未持有”股票:
① 第 天“已经不持有”股票;
天“已经不持有”股票;

② 第 天“持有股票”股票,而在第
天“持有股票”股票,而在第 天卖出;
天卖出;

123. 买卖股票的最佳时机 III 两次买卖。
法1:一般DP,就是在 股票II 延申思路(需要表示更多状态)即可,根据 第 i 天处于什么状态来分类讨论.
【法 1 要点】注意,这里的 对应的买入卖出,不是第
对应的买入卖出,不是第 天必须买入卖出,而是一种 “持续的状态”.
天必须买入卖出,而是一种 “持续的状态”.
==> 即处于“第1/2次买入/卖出的这种状态”,理解这点很重要!
所以结果返回 ,表示最后一天已经处于第二次交易完成的状态!
,表示最后一天已经处于第二次交易完成的状态!
==> 这一点的理解,直接影响 dp表达式 的书写:
只有当你认为这是一种“持续的状态时”,例如:
前一天第一次买入你才能写成 而非
而非 !!
!!
(当然,都是 和
和 的关系,可以通过滚动数组原理简化空间)
的关系,可以通过滚动数组原理简化空间)
【难懂】初始初始化还是难理解啊,一开始居然就能初始化第二次
0 没有什么操作:

1 第i天第一次买入:第一次已经买入 or 今天才第一次买入

2 第i天第一次卖出:第一次已经卖出 or 今天刚第一次卖出

3 第i天第二次买入:第二次已经买入 or 今天刚第一次卖出

4 第i天第二次卖出:第二次已经卖出 or 今天刚第二次买入

法2:对于 两次交易 的,以及类似的题目,可以采用另一种方法“前后缀分解”. 【法 2 要点】前后缀分离
打家劫舍(DP系列)
198. 打家劫舍 【lc 100】【codetop 100】
Y总是双状态做法(因为不许相邻),我的和他不同
四、其他题型
技巧题
11. 盛最多水的容器 经典面试题,双指针,思路难想,直接背过。
32. 最长有效括号 括号字串问题,非典型题,需要背板。
41. 缺失的第一个正数 【codetop 100】背就完事了.
细节.题解视频地址:https://www.bilibili.com/video/BV1XK411n7tf?spm_id_from=333.337.search-card.all.click
代码中两处细节:
(1)while 中的 nums[nums[i] - 1] != nums[i] 怎么推出来的?
去看看 idx = nums[i] - 1 对应的值是否符合要求,符合咱就不换了.nums[idx] == idx + 1
==> nums[nums[i] - 1] != nums[i]
(2)最后返回 len + 1
如果for没返回,说明数组是123…len,这些数,那么结果就是len+1.
public int firstMissingPositive(int[] nums) {//1. 置换:正数放到其对应的位置上去,比如 3 就放到第 3 个位置(下标为2)int len = nums.length;for(int i = 0; i < len; i++){//【易错】这里是while而非if,因为换过来的数,可能还是val和index不匹配,因此这里换到满足val与Index匹配为止!while(nums[i] > 0 && // 这个数是正数才可能交换,负数放原地nums[i] != i+1 && // val与index不对应的需要交换nums[i] <= len && // 正数超过数组长度不用换,最大的可能才是len+1.nums[nums[i] - 1] != nums[i]) //index和val不匹配的话,才需要交换swap(nums, i, nums[i] - 1);}//2. 找for(int i = 0; i < len; i++) if(nums[i] != i+1) return i+1;return len + 1; //如果for没返回,说明数组是123...len,这些数,那么结果就是len+1}//置换函数:把当前索引curIndex处的nums[curIndex],放回值val为索引的位置上去.void swap(int[] nums, int curIndex, int val){int tmp = nums[curIndex];nums[curIndex] = nums[val];nums[val] = tmp;}
48. 旋转图像 【lc 100】【codetop 100】
脑经急转弯:对角翻转 + 上下翻转 即可,思路直接背过.
240. 搜索二维矩阵 II 【lc 100】【codetop 100】
每次判断右上角的元素,分三类情况讨论,要么找到结果,要么删掉一行/列。
剑指 Offer 04. 二维数组中的查找 【codetop 200】完全同 lc 240. 搜索二维矩阵II
75. 颜色分类 要按lc要求做,只能背过了,非常规思路 —— 三指针。
面试时若是无要求,就是个大水题!设三个变量,分别统计0 1 2 的个数即可!
169. 多数元素 【lc 100】【codetop 100】理想做法难想,直接背过。
利用 多数元素数量一定比其他元素数量总和多 的性质。
模拟题
2. 两数相加 【lc 100】【codetop 100】
典型题目:属于“模拟题”,学会利用 % / 等计算符号.
注意:别忘了最后单独判断 进位是否为0!
8. 字符串转换整数 (atoi) 【codetop 100】
溢出判断 ==> ans × 10 容易溢出,所以这里用MAX/10处理!
class Solution {public int myAtoi(String s) {int sign = 1, ans = 0, index = 0;char[] array = s.toCharArray();//1. 去除前导空格while (index < array.length && array[index] == ' ') {index ++;}//2. 判断正负号,只有第一个+/-有效; 只有是+/-时,这里index才++,否则无符号不++,当正数处理if (index < array.length && (array[index] == '-' || array[index] == '+')) {sign = array[index++] == '-' ? -1 : 1;}//3. 判断数字串:第一个不是数字的地方停止//3.1 数字截取,溢出判断//【注意】负号最后处理即可!前面计算全按“正数”计算while (index < array.length && array[index] <= '9' && array[index] >= '0') {int digit = array[index++] - '0';//【重要】溢出判断 ==> ans × 10 容易溢出,所以这里用MAX/10处理!!if (ans > (Integer.MAX_VALUE - digit) / 10) {//根据正负号,判断溢出时返回MAX还是MINreturn sign == 1 ? Integer.MAX_VALUE : Integer.MIN_VALUE;}ans = ans * 10 + digit;}//3.2 正负号处理return ans * sign;}}
43. 字符串相乘 Y总取巧优化,忘了可看视频。也属于模拟题了,模拟小学“列数式”的过程.
415. 字符串相加 【codetop 100】基本同 lc.2.
468. 验证IP地址 【codetop 100】思路不难,就是繁琐,细节多,要善于使用 API.
split() 是否忽略首尾分隔符的验证:首分隔符不忽略,尾分隔符忽略
首分隔符没被忽略:
尾分隔符被忽略:
class Solution {public String validIPAddress(String ip) {if (ip.indexOf('.') != -1 && ip.indexOf(':') != -1) return "Neither"; //:和.同时有,必然不合格if (ip.indexOf('.') != -1) return checkIPv4(ip); //只有'.',那么就去判断是否是IPV4if (ip.indexOf(':') != -1) return checkIPv6(ip); //只有':',那么就去判断是否是IPV6return "Neither"; //到这说明,比不是IPV4/6}//一、判断是不是IPV4private String checkIPv4(String ip) {//0. 使用.来切分//【易错】split() 方法中注意: . 、 $、 | 和 * 等转义字符,必须得加 \\。String[] items = ip.split("\\.");//1. 如果不是 4 段,或者(?) 不写后半部分的反例:"1.1.1.1."//【易错】split() 方法,会忽略尾部分隔符,首部不会,所以尾部分隔符需要单独判断!if (items.length != 4 || ip.charAt(ip.length() - 1) == '.') return "Neither";//2. 遍历这 4 段,不合格情况如下:for (String item : items) {//2.1 如果这一项是空的,或者 数组长度大于3(0-255,最多 3 位)的不合格if (item.isEmpty() || item.length() > 3) return "Neither"; //不写item.isEmpty()的反例:12..33.4//2.2 存在前导零的不合格:长度 > 1 且首位是 0,说明必是前导零.if (item.length() > 1 && item.charAt(0) == '0') return "Neither";//2.3 判断每段数字的每一个数字,看看是否合法(比如你是个 a b 这种,就不合法了)for (int i = 0; i < item.length(); i++)if (item.charAt(i) < '0' || item.charAt(i) > '9') return "Neither";//2.4 看看这个数是否在 0-255,否则不合格int t = Integer.parseInt(item);if (t > 255) return "Neither";}//3. 至此,说明合适的return "IPv4";}//二、判断是否是IPV6private String checkIPv6(String ip) {String[] items = ip.split(":");//1. 不是 8 段就不是 IPV6.if (items.length != 8 || ip.charAt(ip.length() - 1) == ':') return "Neither";//2. 遍历这 8 段,看看是否合法(相较于IPV4,可以包含前导零!)for (String item : items) {//2.1 若是空的,而且长度还 > 4,必不是 IPV6if (item.isEmpty() || item.length() > 4) return "Neither";//2.2 判断每一段的每一个字符是否合法for (int i = 0; i < item.length(); i++)if (!check(item.charAt(i))) return "Neither";}return "IPv6";}//二.X,(2.3)辅助 IPV6 判断字符的合法性private boolean check(char c) {if (c >= '0' && c <= '9') return true;if (c >= 'a' && c <= 'f') return true;if (c >= 'A' && c <= 'F') return true;return false;}}
224. 基本计算器 典型题目:表达式求值模板题。与 lc 227 侧重略有不同。
样例增强后,Y总代码过不了了。根据三叶大大建议补充3点细节才能过。
227. 基本计算器 II 典型题目:表达式求值模板题。比较难想,记住思路与分类,背过即可。
补充Y总在笔试面试辅导课里讲过:day8 acwing454.表达式求值,有例子。
Y总在 acwing151.表达式计算4 中详细讲解,有例子。这个版本太复杂了,先不用考虑。
[注意] lc 224 仅 + - ( ),无 /;lc 227 考虑了 + - /,无 ( )。因此,两题应该结合!
498. 对角线遍历 模拟题目演示过程即可。题目的关键特点,起终点的求法,最好背过!
设计题
146. LRU 缓存 【lc 100】【codetop 100】 多看吧,多熟悉.
需要自建两个数据结构(map 和 双向链表),和两个方法(remove 和 insert)
思路与实现细节
题目要求考虑 O(1) 级别的算法.
1. 逻辑分析
对于本题,我们存储的是“键值对:int key, int value”,我们需要实现的内容如下:
get:如果 key 存在,那么得到其 value 值;
put:如果 key 存在,那么变更其value值;
如果key不存在,且缓存没有达到上限,那么向缓存中插入对应的 k-v;
如果key不存在,且缓存达到了上限,那么根据 LRU机制,删除最早操作的k-v,并插入新的 k-v;
==> 每次都需要同步维护 map 和 链表
2. 数据结构选择:<br /> (1) 使用 **hash表 维护 k-v** 时,可以在 CRUD 过程中实现O1<br /> (2) 使用 **双链表 维护 LRU机制 **,可以在 “记录时间戳” 和 “快速查找最早/小” 中达到O1<br /> ==> 假设双链表从左向右添加:<br /> 没用到一组k-v,将其从链表中del,并放到最右侧(最新),此时最左侧的就是最早操作的k-v
class LRUCache {//一、LRU缓存的构造类public LRUCache(int capacity) {//初始化上限n = capacity;//初始化双链表oldEst.right = newEst;newEst.left = oldEst;}//二、实现 get 方法public int get(int key) {if(map.containsKey(key)){//【易错】containsKey而非containKey,注意那个s//hash表中拿到结果Node cur = map.get(key);//维护双链表remove(cur);insert(cur);// System.out.println(newEst.left.val);return cur.val;}// System.out.println(newEst.left.val);return -1; //找不到就返回-1}//三、实现 put 方法public void put(int key, int value) {//1. k-v存在时,修改其v即可if(map.containsKey(key)){Node node = map.get(key);node.val = value;remove(node);insert(node);// System.out.println(newEst.left.val);}else{Node cur = new Node(key,value);//2. k-v不存在时,且达到上限:删除最早的,if(map.size() == n){//[细节]不需要n--之类的,直接用map的API即可//维护双链表Node old = oldEst.right;remove(old);//维护哈希表map.remove(old.k);//【改错】这里是old而非cur,别搞错了}//3. 缓存未满时,或者满了但是删除了最早节点的之后insert(cur); //维护双链表map.put(key,cur); //更新哈希表}}//零、创建LRU机制的属性//1. 创建【hash表】private Map<Integer, Node> map = new HashMap<Integer, Node>();//【重要】v以node.val的形式存在!而非hash直接存value,不这样很难建立hash和双链表的联系.//2. 维护【双链表】//2.1 创建节点内部类class Node{int k;int val;Node left = null;Node right = null;Node(){}//[细节]可能有不存k-v的节点,这个必须有.Node(int k, int val){//存k-v的节点this.k = k;this.val = val;}}//2.2 初始化双链表Node newEst = new Node(-1,-1);//放在最右边Node oldEst = new Node(-1,-1);//放在最左边//【细节】这俩互指的初始化放到LRU的初始化中去// oldEst.right = newEst;// newEst.left = oldEst;//3. 维护缓存上限int n = 0;//二、补充实现get和set必需的remove和insert方法//4-1.//remove 每用到一个节点(put/get),我们就把这个节点从双链表中删除,然后insert到双链表最右边去,表示最新的状态。//并不需要更新链表的存储数量的状态.因为我们执行完 reomve 就行执行 insert 操作。//【注】对于达到上限以后删除点的操作,也是这个操作private void remove(Node node){node.left.right = node.right;node.right.left = node.left;}//4-2.//insert 这个insert是我们配合remove一起使用的,直接插入到双链表的最右侧(最新的),不需要考虑中间情况//【注】对于达到上限后,删除最早 Node 后的添加,也是这个insert,直接插在最新的位置private void insert(Node node){//[细节]以下顺序不能反,newEst.left 要被使用,就得先指定//node 与 newEst.leftnewEst.left.right = node;node.left = newEst.left;//newEst 与 node;node.right = newEst;newEst.left = node;}}
位运算
位运算符介绍 http://c.biancheng.net/view/784.html
Y总介绍技巧:求10进制n的2进制的第k位 (n >> k) & 1
==> 第 k 位移动到 个位(2进制0号位),然后用 1 去 与运算
136. 只出现一次的数字 【lc 100】【codetop 100】 典型题目:考察 “异或” 性质。
异或是机器码运算,相同为0不同为1.
不管数字先后,只要两个数字相同对应的二进制都会被异或为00000000,最后剩下的就是所要找的值。
这样最后的结果就是,只出现过一次的元素(0^任意值=任意值)。
代码演示```java
public int singleNumber(int[] nums) {
int res = 0; // 0^任意值=任意值
for(int t : nums) res = res ^ t; //随便搞,反正“交换律”
return res;
}
[461. 汉明距离](https://leetcode.cn/problems/hamming-distance/) 经典题目,一定要会!<a name="hWzMX"></a>## [<br />](https://leetcode.cn/problems/multiply-strings/)数学[470. 用 Rand7() 实现 Rand10()](https://leetcode.cn/problems/implement-rand10-using-rand7/) 看标签是“拒绝采样”,不知道是个啥东西...有机会再了解吧...<a name="ogVSQ"></a># 刷题常用 API<a name="LrTeT"></a>## ArrayDeque 模拟 栈(不推荐使用Stack)ArrayDeque 是基于 (循环)数组 的方式实现双端队列<br />LinkedList 基于 双向链表 实现的双端队列<br />==>经过性能对比,更倾向于【使用ArrayDeque来表达Java中的栈功能】(API参考:[https://zhuanlan.zhihu.com/p/261397170](https://zhuanlan.zhihu.com/p/261397170))ArrayDeque 作为 **队列(FIFO)** 使用时的方法:<br />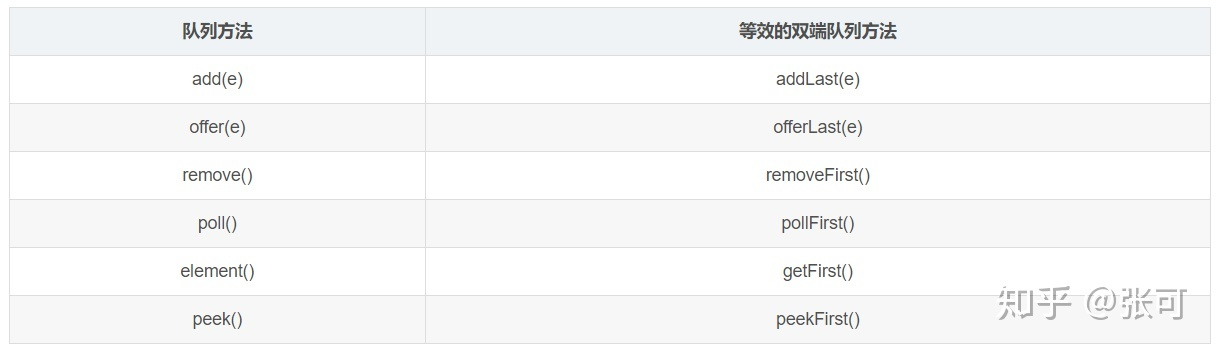<br />ArrayDeque 作为 **堆栈(FILO)** 使用时的方法:<br /><a name="Q6r6R"></a>## ArrayList 的使用```java//经典应用:lc 77. 组合List<List<Integer>> res = new ArrayList<>();List<Integer> tmpRes = new ArrayList<>();res.add(new ArrayList<>(tmpRes)); //拷贝一个新的 ArrayList,避免add相同的引用.tmpRes.remove(tmpRes.size() - 1); //根据index删除最后一个元素.
LinkedList 模拟 队列
https://blog.csdn.net/huyang0304/article/details/82389595
Queue<E e> q = new LinkedList();add()/offer(); //加入链表尾部.isEmpty();poll(); //链表头部弹出.size();
【注意】用 Queue
==> 参考题目: lc 622 二叉树最大宽度
增加:add(E e):在链表后添加一个元素; 通用方法addFirst(E e):在链表头部插入一个元素; 特有方法addLast(E e):在链表尾部添加一个元素; 特有方法push(E e):与addFirst方法一致offer(E e):在链表尾部插入一个元素 add(int index, E element):在指定位置插入一个元素。offerFirst(E e):JDK1.6版本之后,在头部添加; 特有方法 offerLast(E e):JDK1.6版本之后,在尾部添加; 特有方法删除:remove() :移除链表中第一个元素; 通用方法remove(E e):移除指定元素; 通用方法removeFirst(E e):删除头,获取元素并删除; 特有方法removeLast(E e):删除尾; 特有方法pollFirst():删除头; 特有方法pollLast():删除尾; 特有方法pop():和removeFirst方法一致,删除头。poll():查询并移除第一个元素 特有方法查:get(int index):按照下标获取元素; 通用方法getFirst():获取第一个元素; 特有方法getLast():获取最后一个元素; 特有方法peek():获取第一个元素,但是不移除; 特有方法peekFirst():获取第一个元素,但是不移除;peekLast():获取最后一个元素,但是不移除;pollFirst():查询并删除头; 特有方法pollLast():删除尾; 特有方法poll():查询并移除第一个元素 特有方法
HashSet 的使用
//典型应用:lc 349. 两个数组的交集Set<Integer> s = new HashSet<>();s.add(..);s.contains(..);s.size();
HashMap 的使用
Map<Obj1, Obj2> h = new HashMap<>();//典型应用:lc 3. 无重复字符的最长子串//h.put(o1, o2);//h.get(o1);// 对于第一次使用的 map 初始化h.getOrDefault(o1, o2);//h.containsKey(key); //o1//------------------------------------------------//典型应用:lc 344. 前K个高频元素//获取key集合,用于遍历:map.values()for(Integer t : map.values()) {//需求};//获取value集合,用于遍历:map.keySet()for(Integer t : map.keySet()){//需求}
StringBuilder的使用
StringBuilder res = new StringBuilder();//一、典型应用:lc 43. 字符串相乘//(1)用来拼接字符串res.append(obj);//(2)转换成String,相关题目会要求返回Stringres.toString();//二、典型应用:lc 179. 最大数//(1)得到sb对应string的字符数int newLen = sb.length();//(2)得到sb序号k的字符char c = sb.charAt(k);//(3)从k号位开始截取.sb.substring(k);sb.substring(a,b); // 从序号a到序号b-1,左开右闭//三、典型应用:lc 22. 括号生成//(1)移除在此序列中的指定位置的char值;// index -- 要删除字符的索引。 这个方法返回这个对象。public StringBuilder deleteCharAt(int index)
比较器排序,lambda表达式写法-
//典型应用:lc 452. 用最少数量的箭引爆气球 ====> 默认//排序(按照右端点从小到大的顺序)// 使用 lambda表达式 和 比较器 按“左端点”,方法体就是调用Integer里的compare方法。// 所以points的元素是int[];则oi[0]就是气球i左端点;oi[1]就是气球i的右端点。Arrays.sort(points, (o1, o2) -> Integer.compare(o1[1], o2[1]));------------------------------------------------------------------------------------//典型应用:lc 179. 最大数 ====> 构造排序对象Arrays.sort(ss, (a,b)->{String sa = a + b, sb = b + a;return sb.compareTo(sa);});

若有收获,就点个赞吧
0 人点赞
