- 第三章 通行证服务
- 2 设置会话与 cookie 信息
- 3 用户注册或者登陆以后,需要删除 redis 中的短信验证码,验证码只能使用一次,用过后删除
- 4 返回用户状态
- 三、用户账户信息完善
- 四、理论:缓存双写!
- 五、拦截器验证用户合法性
- 六、完善剩余功能
- 第四章 文件服务
- 第五章 admin 管理服务
- § 5.1.1 admin 账号登陆
- § 5.1.2 admin 账号创建(添加管理员)
- § 5.1.3 admin 账户列表
- § 5.1.4 admin 账号登出
- 【重要】疑问:admin登陆不用redis吗?寸的session、token这些怎么用的?前端处理还是后端处理?
- § 5.2 MongoDB & GridFS 介绍
- § 5.3.1 人脸入库
- § 5.3.2 人脸登录
- § 5.4 MongoDB 处理 友情链接
- § 5.5 文章分类管理
- § 5.6 用户管理
- 第六章 内容管理与AI自动审核
- 第七章 开发首页与作家页
- 粉丝关注
- 粉丝画像
- 第八章 详情页与评论模块
- 小结1
- END
第三章 通行证服务
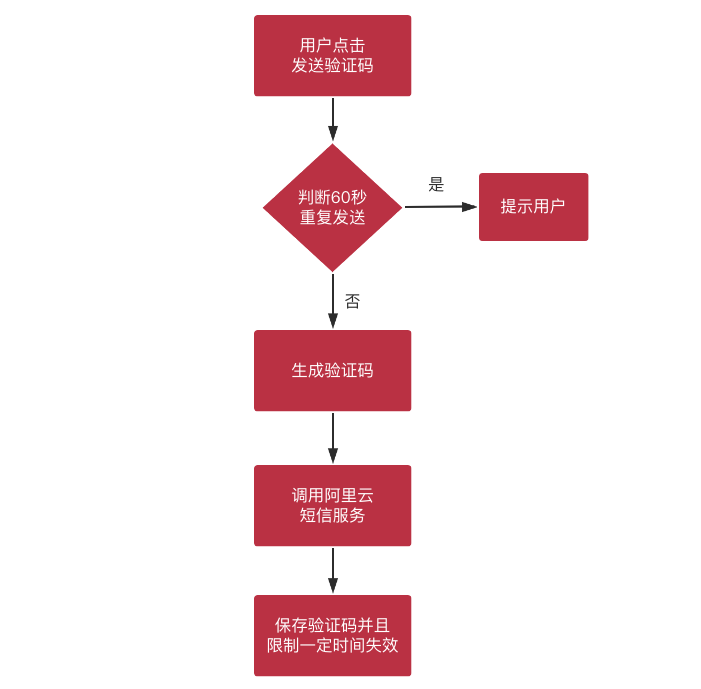
短信登陆:第三方短信收发,借助阿里云短信服务
短信验证码:限制用户60s内发起一次短信
分布式会话:用户登陆后,Redis 保存用户会话的 token,使用 Redis 管理
用户信息完善:涉及用户头像,则用到文件上传系统
流程
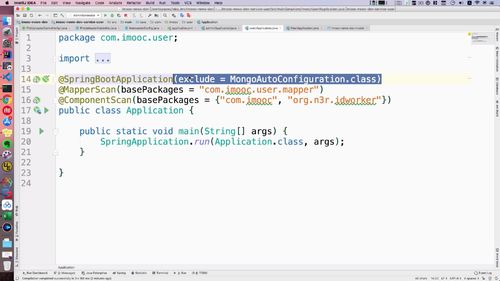
@Api(value = "用户注册登录", tags = {"用户注册登录的controller"})@RequestMapping("passport")public interface PassportControllerApi {@ApiOperation(value = "获得短信验证码", notes = "获得短信验证码", httpMethod = "GET")@GetMapping("/getSMSCode")public GraceJSONResult getSMSCode(@RequestParam String mobile, HttpServletRequest request);@ApiOperation(value = "一键注册登录接口", notes = "一键注册登录接口", httpMethod = "POST")@PostMapping("/doLogin")public GraceJSONResult doLogin(@RequestBody @Valid RegistLoginBO registLoginBO,BindingResult result,HttpServletRequest request,HttpServletResponse response);@ApiOperation(value = "用户退出登录", notes = "用户退出登录", httpMethod = "POST")@PostMapping("/logout")public GraceJSONResult logout(@RequestParam String userId,HttpServletRequest request,HttpServletResponse response);}
一、发送短信验证码
短信服务
(无需配置阿里云业务,发送验证码后直接在 redis 中查看即可)
阿里云短信功能,阿里云服务
AliyunResource 资源类,获取密钥,配置文件中配置
资源里注入容器
发送短信的SMSUtils类
完善短信发送接口:Redis 中存储 验证码 和 用户IP
验证码发出会会进行保存,单体项目用session保存也行;但是分布式项目中,还是用 Redis 保存.
在 getSMSCode 方法中补充形参
moblile为手机号,request获取 IP 便于判断是否发送 60 秒
public GraceJSONResult getSMSCode(String mobile, HttpServletRequest request) {// 获得用户ipString userIp = IPUtil.getRequestIp(request);// 根据用户的ip进行限制,限制用户在60秒内只能获得一次验证码redis.setnx60s(MOBILE_SMSCODE + ":" + userIp, userIp);// 生成随机验证码并且发送短信String random = (int)((Math.random() * 9 + 1) * 100000) + "";// smsUtils.sendSMS(MyInfo.getMobile(), random);// 把验证码存入redis,用于后续进行验证redis.set(MOBILE_SMSCODE + ":" + mobile, random, 30 * 60);return GraceJSONResult.ok();}
(2)保存发送验证码的用户信息
① 导入 IP 工具类
因为有了 request ,就可以根据用户 IP 限制60s内用户只能发送一次短信!ip 需要从 request 中获取,老师事先加入了一个 IPutil 在 common 工程中,用于获取用户 ip,直接使用即可。
② 注入redis操作对象,并建立baseController,提取公共代码
需要用到 Redis ,限制用户60s内只能获取一次验证码。把 redisoperator 注入进来,调用 setnx60x 方法(老师自己加的)(key不存在就会设置,超过60s就会消失).redis 里面存的信息有两部分:smscode(key值) + ip。其中key不会写死,会写在公共的地方!因此把 key 提取,写在 api 工程中.api 中,定义 baseController 这个 class 。方法中,注入 redis 操作类,声明一个 key 常量.
③ 继续完善 passportcontroller
回到 passportcontroller ,继承 baseController ,redis 就可以去掉了,redis 的60s方法中的形参改一改:这样,通过 "**常量 + IP**" 的方式,就组合成了 key ,只要这个 key 在,就不能再次发送!至于验证码,随便写一个:ip 即可<br />==> ?????是不是还没有设置,不足60s时不能再次发送的警告???
(3)生成随机验证码,并发送短信
然后就来设置验证码信息
验证码就在一开始那两节留下的代码上改就行验证码随机数就行,如下:(6位即可)
(4)验证码存入redis,用于后续验证
短信存在 redis 中(???啥时候存的???)==> 这应该就是个业务逻辑.
注意!图中37行,老师这里 sendSMS 中,我们自己形参得用方法形参 mobile 而非老师写的 myinfo.getMobile ,因为老师要隐藏自己手机号才这么写的,我们自己就和其他地方一样,用方法传进来的moblie ==> 这个mobile其实就是前端页面输入手机号以后传进来的.40行set时,加上时间设置,验证码有效时间为30min.
拦截并限制 60s 用户短信发送
1 问题分析:“60s内不可重复发送”的问题未解决
前端发送的验证码,按理说60s内不能重复发送。
但是,老师演示了以下,如果刷新了前端页面,发送按钮的也会被刷新,此时点击发送,仍然可以对同一用户发送信息,同时redis中的验证码会发生变更,这就与我们的初衷违背。
之前的代码,实现的只是,用户信息、验证码这些,到时间了自动消失。<br /> 本节课要写的,就是规定时间内,再次发送,会对请求进行拦截!<br /> 如下图,60s这个方法,补充判断,只要 key 存在,调用这个接口时,就进行拦截!
2 编写验证码拦截器类
如果要在方法之前进行拦截,那么就需要晚上preHandle这个方法。其他两个不用管
首先,我们得获得用户的 IP ,然后通过 Redis 获得key.<br /> 通过 keyExist 方法判断 key 是否存在. 不存在,放行即可.<br /> 如果存在,让前端做一个抛出,返回一个错误的 json,前端接收到后提示发送频率太高了.<br /> 所以这里需要构建 json。但是先用 sout 来过渡以下,下节课讲“自定义异常——统一异常处理”.
3 配置拦截器
interceptor写好以后,还需要进行配置,放到容器里面才能正常运作
在 api 工程中 config 包下加配置类
5 自定义异常,返回错误信息:60s内不可重复发送验证码
紧接上节课,完善要返回给前端的**报错 JSON 信息**!
==> 只要拦截到自己写的自定义异常,捕获以后,就会以 JSON 字符串的形式,抛给前端。不管是浏览器端,还是手机端,都可以拿到这个异常信息,然后再提示用户
视频 3-7 跨域问题???和cookie有关吗?
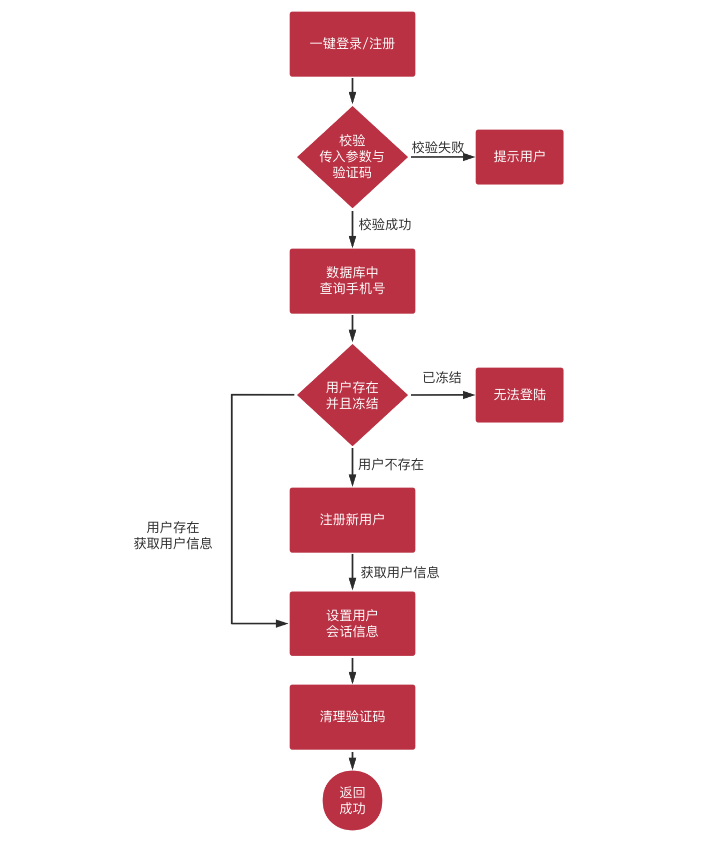
二、一键注册登录
API中定义接口名称:dologin.(还是那个passportAPI)。
**涉及到表单,注解为 PostMapping**(查询的话就是getMapping);注意,**ApiOperation 中的 httpMethod 是 POST** 而非 GET!
最终代码:doLogin
UUIDL:统一XX码,去了解下
@Overridepublic GraceJSONResult doLogin(@Valid RegistLoginBO registLoginBO,BindingResult result,HttpServletRequest request,HttpServletResponse response) {// 0.判断BindingResult中是否保存了错误的验证信息,如果有,则需要返回if (result.hasErrors()) {Map<String, String> map = getErrors(result);return GraceJSONResult.errorMap(map);}String mobile = registLoginBO.getMobile();String smsCode = registLoginBO.getSmsCode();// 1. 校验验证码是否匹配String redisSMSCode = redis.get(MOBILE_SMSCODE + ":" + mobile);if (StringUtils.isBlank(redisSMSCode) || !redisSMSCode.equalsIgnoreCase(smsCode)) {return GraceJSONResult.errorCustom(ResponseStatusEnum.SMS_CODE_ERROR);}// 2. 查询数据库,判断该用户注册AppUser user = userService.queryMobileIsExist(mobile);if (user != null && user.getActiveStatus() == UserStatus.FROZEN.type) {// 如果用户不为空,并且状态为冻结,则直接抛出异常,禁止登录return GraceJSONResult.errorCustom(ResponseStatusEnum.USER_FROZEN);} else if (user == null) {// 如果用户没有注册过,则为null,需要注册信息入库user = userService.createUser(mobile);}// 3. 保存用户分布式会话的相关操作int userActiveStatus = user.getActiveStatus();if (userActiveStatus != UserStatus.FROZEN.type) {// 保存token到redisString uToken = UUID.randomUUID().toString();redis.set(REDIS_USER_TOKEN + ":" + user.getId(), uToken);redis.set(REDIS_USER_INFO + ":" + user.getId(), JsonUtils.objectToJson(user));// 保存用户id和token到cookie中setCookie(request, response, "utoken", uToken, COOKIE_MONTH);setCookie(request, response, "uid", user.getId(), COOKIE_MONTH);}// 4. 用户登录或注册成功以后,需要删除redis中的短信验证码,验证码只能使用一次,用过后则作废redis.del(MOBILE_SMSCODE + ":" + mobile);// 5. 返回用户状态return GraceJSONResult.ok(userActiveStatus);}
0 验证BO信息
创建 BO 类
方法形参,**<u>如果要接收数据,一般都命名为“BO”,表示从业务层接收数据</u>**。**本质就是一个“entity”对象**<br />方法形参,**<u>如果要接收数据,一般都命名为“BO”,表示从业务层接收数据</u>**。<br />**本质就是一个“entity”对象**:**<u>主要接收:手机号 和 验证码</u>**。生成get/set方法,toString等.<br />因为是从前端过来的,可以**对BO类其属性进行一个验证**:两个属性加@notnull (message=...) 检测是否为空,如果为空,返回message中的信息==>后续**更正 @notnull 为 @notblank**。notnull只能看这个信息是不是null;如果这个信息是""这种blank类型,notnull不会报错!
blank 的话 null 和 blank 会一起检测。
当然,BO 需要加上 @Valid注解 表示内部需要验证;Bo 还要加上 @RequestBody 来表明:该形参和前端传过来的 JSON 串是匹配的(这个很重要,不加的话,里面数据获得不了);
(1) 补充处理BO验证错误信息的方法:getErrors
为了专门处理 BO 中的错误信息(因为有两类错误信息:手机号 / 短信验证码 不能为空),专门拿到 result 形参去重写一个方法。
我们之前在Bo类中,声明了 手机号 和 验证码 的属性,以及 notnull 中的错误信息 —> 我们就把 属性 和 message 匹配成一组 map 存储.
dologin方法 初步
<1> 判断 BindingResult 是否保存错误的验证信息
第一部分就是通过 result 和我们刚才重写的方法拿到了可能的手机号/验证码不存在的 错误信息。如果有,则直接return。有错的话返回即可.
<2> 获取前端信息,并“ 校验验证码是否匹配 ”
① 操作:从BO里获得 手机号 + 验证码
拿到了就可以校验了
②
对于验证码,我们要两个:前端传过来的 + redis中储存的∴需要redis。 但是redis我们已经创建过了:当前controller继承的baseController中创建了redis操作类
操作:用redis获得验证码
③ 拿到以后:先看看是否超时/失效了
然后再看匹不匹配
不匹配时,返回对应状态码枚举类sms_code_error
④ 代码如下:
1 Service层方法,一键注册登陆时:查询用户 + (用户不存在时)新用户注册
本节进入一键注册登录的流程!包含了两个数据库方面的操作,根据 mobile 查找数据库:①如果用户存在,可以**直接登陆**;②没有,则在数据库中**创建用户**;
看表
根据数据库中信息决定接口中用什么方法
查看“用户表”(激活状态这一项比较多,后面看看)
接口
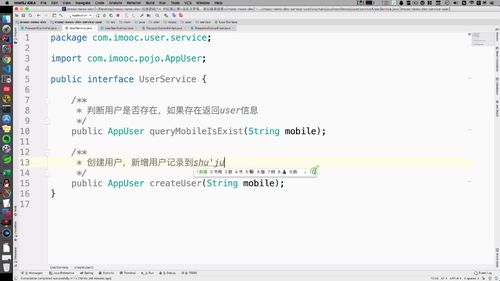
实现查询用户
①
对于查询的话,就要使用mapper了,第二章最后整合 mybatis 时这些我们已经弄好了(忘了回去复习).注入 appuserMapper ;(注意,如果appUserMapper下有红色波浪线,直接运行可能是可以的,不报错,只不过IDEA编译器有个检索的过程。 如果想要去掉波浪线,可以去原mapper类那里加一个数据层@repository的注解)<br />②然后继续操作. 实现类中还是先把 mapper 注入. 查询方法中,Example是针对 appuser 的一个“查询实例”(这个是自己写的还是框架提供的可以直接用???==>mybatis提供的吧)
③ Criteria可以封装“查询条件”。
封装“判断条件”:其andEqualTo方法中,左边那个是Appuser中的形参,右边那个moblile是当前查询方法传回的形参这个“判断条件”就被包含在example对象中了.
④
调用 select 方法,传入 example ,其中就包含了刚才写的 “判断条件” 。返回一个 Appuser(这个和我们创建 example 时传入的类对象是一致的),不存在时,appuser为null。
⑤ 写好后代码如下:
实现创建用户(个人信息初始化)
用户对象包含一些默认信息需要我们去构建. user 先 new 出来.
① ID
分布式环境中,业务量继续增多过程中,考虑“分库分表”。此时,自增主键的效率就非常差了,此时我们选择:“全局ID”;需要第三方组件,如下图:idworker 这个包,里面有个 Sid ,就用这个.(放在common工程中)
因此我们把sid注入到实现类中
此时调用sid,如下:通过 nextShort 拿到全局 ID,然后 setId 即可(可以看看图中老师的注释)
②mobile
③昵称:我们这里就用手机号作为昵称
但是呢,最好还是进行脱敏,别让别人直接拿到你的手机号.调用第三方工具,老师 已经导入utils包下,如下:
④用户头像:setFace
头像老师这里提供了3个,放在了他自己的服务器上。我们就按它的代码即可。
⑤生日
为了能把字符串转换成date类型:需要用到第三方工具:如图,已经添加到utils包中了(有自己的工具类也可以用自己的)<br />⑥性别为了提高通用性,用枚举类更好。老师已经把项目可能用到的枚举搞了一些进来了,如图:其中sex就是我们这里要用的.
⑦激活状态
同⑥,也是有对应的枚举,如下:使用未激活的状态.
3 一键注册登录 方法中,判断用户是否注册
2 设置会话与 cookie 信息
一、保存用户分布式会话的操作
上节课两个操作都是在service层. 本节完善这一部分.用户注册和登陆以后,会产生相应的会话。用户会话早期都是直接用 request 中的 session ;现如今使用**分布式会话,会话信息存入redis,任何节点都能获取;将 cookie 和后端的 token 结合起来**。
到这一步,用户要么注册,要么登陆.
(1)保存token到redis中(token是什么)
用user获取激活状态(只要和业务相关,就要进行“激活状态判断”,这是基本的)
**用户的会话一般都是用字符串形式的token**(???),这里使用随机的UUID(????)。<br /> 然后保存信息到 redis 。redis 这里set时需要一个key,在前面声明:
(2)保存用户id和token到cookie中1——补充setCookie方法
(??????其实没理解,咋拿到cookie的,也没调用request啊?)
① 接口方法补充形参
同时,因为前后端分离,token也应该保存在前端 .回到 PassportControllerApi 接口,doLogin 方法补充形参:response 和 request 都是获取 cookie 所需要的
④ 抽离另一种需求的 setCookie 方法 & 优化:编码不是utf-8时,直接设置即可(比上一个方法少了一个encode而已,此时异常也不需要了)
[注意]这里最后还补充了一个“把cookie存入reponse”的代码!!!
(3)保存用户id和token到cookie中2——完善Controller类中方法
超时时间 maxAge 在 BaseController 中统一设置:
(这里设置1个月)
3 用户注册或者登陆以后,需要删除 redis 中的短信验证码,验证码只能使用一次,用过后删除
4 返回用户状态
这里需要return的是user的状态而非user,
三、用户账户信息完善
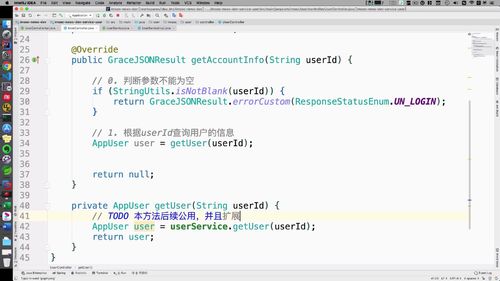
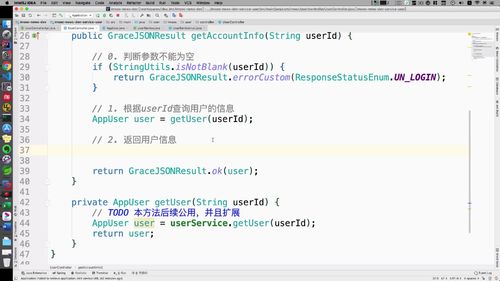
查询用户“详细”信息:getAccountInfo
代码
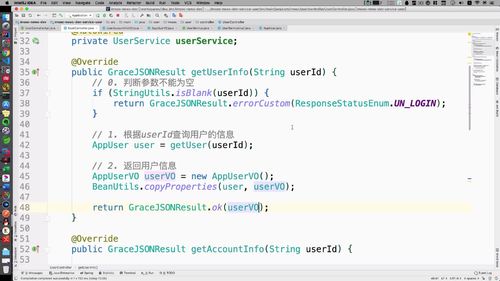
@Overridepublic GraceJSONResult getAccountInfo(String userId) {// 0. 判断参数不能为空if (StringUtils.isBlank(userId)) {return GraceJSONResult.errorCustom(ResponseStatusEnum.UN_LOGIN);}// 1. 根据userId查询用户的信息AppUser user = getUser(userId);// 2. 返回用户信息(VO类)UserAccountInfoVO accountInfoVO = new UserAccountInfoVO();BeanUtils.copyProperties(user, accountInfoVO);return GraceJSONResult.ok(accountInfoVO);}
分析
用户登陆注册完成后,需要用户信息进行更新。<br /> 当时就跳转到了这里:需要操作的就在这!<br />
更新前,当前页面中有一部分信息没有展示
所以先把用户信息展示出来,在页面中显示,然后就可以修改或提交.
通信证 / 用户注册登陆 的代码我们都写在了 PassportController 中。
用户信息,我们就创建一个新的Controller:【UserControllerApi】;
(位置和PassportController的接口一样)
实现 getAccoutnInfo 方法,根据 id 查用户信息,创建 VO 类
位置和 p..c.. 一样
判断参数不为空
id为空时,抛出“未登陆”的错误
根据 id 查用户信息
【需要service】==>补充user方法
之前有个userService,那么就在这里补充: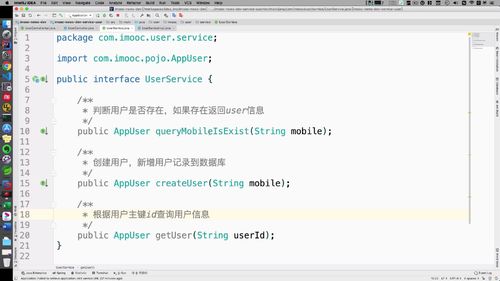
Service层 实现 getUser 方法, 后面会公用,所以将其抽取出来
新建Vo类
user是持久层的数据,并不是所有信息都需要.
一般是用什么,加载什么==>一般会构建一个视图层对象:VO类,让视图层渲染与加载.
∴ user对象一般是不会直接抛出的(假如user有密码,不也直接抛出了嘛)
因此,我们需要先搞一个Vo类!
先搞个vo包,位置: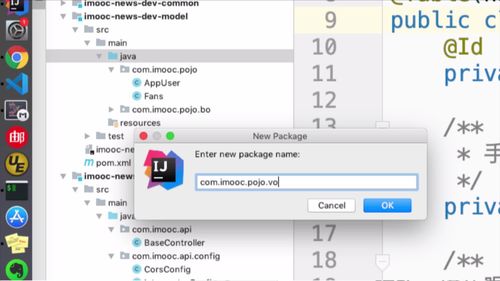
复制一个AppUser类,直接在这个基础上改!
保留以后的属性如下:
(激活状态,创建时间什么的就不要了)
然后什么get/set/toString就自己生成
(shfit + f6 快速修改文件名)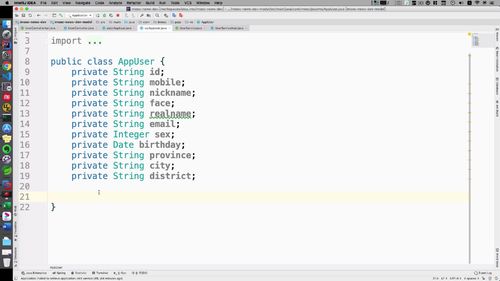
BeanUtils 工具类:拷贝 AppUser 信息到 Vo 类中
通过一个 BeanUtils 工具类进行属性拷贝!属性名匹配就能拷贝!!!<br /> ( BeanUtils 属于 package org.springframework.beans; 这个类不是我们自己导入的,靠依赖导入)<br />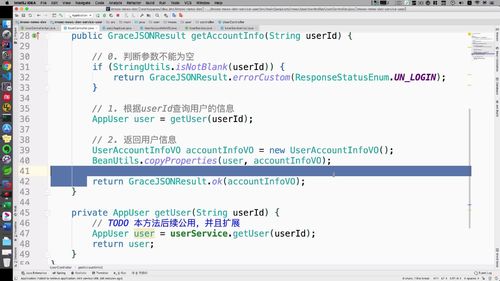
更新用户信息:updateUserInfo
更新用户信息代码
(后面 缓存双写 时,会优化 service 层的 updateUserInfo)
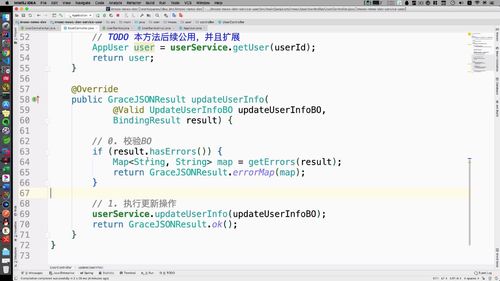
public GraceJSONResult updateUserInfo(@Valid UpdateUserInfoBO updateUserInfoBO,BindingResult result) {// 0. 校验BOif (result.hasErrors()) {Map<String, String> map = getErrors(result);return GraceJSONResult.errorMap(map);}// 1. 执行更新操作userService.updateUserInfo(updateUserInfoBO); //后面要更新补充redis的逻辑return GraceJSONResult.ok();}
提交信息前,信息校验(同登陆时的BO验证)
我们现在需要填写如下个人信息,并且提交。
登陆前需要对 手机号 和 验证码判空,这里提交信息前的信息校验也是同理!就是看看提交的信息是否合理!!
信息还是表单类的信息.
我们首先要做的就是【通过 VO 进行信息的验证】.
编写BO(包含判断信息合法性的注解)
涉及到了BO,我们专门去写一份。**Model 项目的 BO 包中**.<br /> 代码是准备好的,直接复制:@ length是用来判断长度的;@Email是用来判断右键类型格式的; 性别中 max 和 min 帮助限定可选值;日期中JSONFormate是用来格式化的(不太懂);
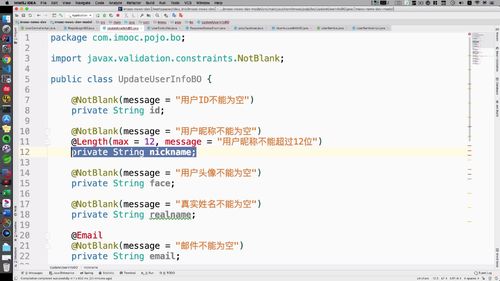
set 和 get 还是需要自己生成
(这里 JSONFormate 和 Length 都没有,都是我自己根据报的错引入的依赖,不知道对不对啊!!!)
updateUserInfo 方法:校验 BO + 执行更新操作
来到 UserController,先继承一下baseController
(1)校验 BO,写法和之前的一样
(2)执行更新操作
提交信息,激活用户,信息入库
本节课开始【完善更新操作】(如下图中,还没写呢)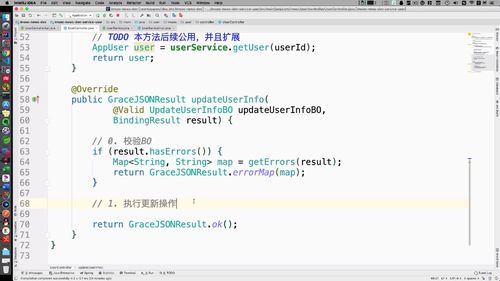
———————————————————————————————————-
1 调用 Service 传递BO信息
(1)UserService 中补充方法
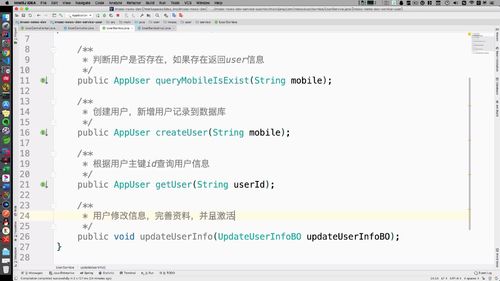
(2)Service实现类中实现方法
拿到主键,根据主键利用持久层对象拷贝数据(从BO搞到user对象中);
依然使用 BeanUtils 工具类;
BO中没有的,我们手动追加;
最后,就可以执行更新.
主键更新方法有两个,primarykey 这个方法会把没传值的数据覆盖(比如创建时间啥的,传入的数据没有,那么就是null,但是数据库中不是null,如果用这个方法,会覆盖);所以选择 selective 的方法,根据现有的数据覆盖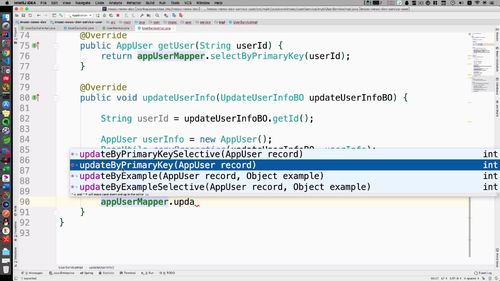
入库操作会返回一个结果,拿到这个结果,判断一下,看一下更新操作是否合法: 如果不合法,我们直接处理错误,吗,没有返回给controller让controller去处理,相当于一种解耦.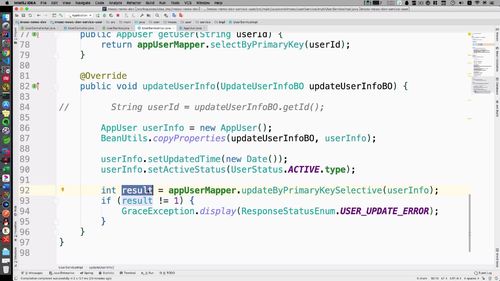
(3)回到controller,调用刚才写好的方法
查询用户“基本”信息:getUserInfo(只显示关键信息,后面用)
目前也已经更新了用户的信息到数据库,并已经做了激活.<br />按理说,用户激活后,左侧菜单可以点击:但是因为用于【基本信息接口】我们都还没有写,所以还点不了;<br />我们之前处理的只是“账户信息”:在 (§ 2.2 注册登录 五)中,我们已经完成了用户详细信息的查询.<br />(这块逻辑其实可以再听听)
代码
getUser 在下一部分需要通过 redis 优化!
@Overridepublic GraceJSONResult getUserInfo(String userId) {// 0. 判断参数不能为空if (StringUtils.isBlank(userId)) {return GraceJSONResult.errorCustom(ResponseStatusEnum.UN_LOGIN);}// 1. 根据userId查询用户的信息AppUser user = getUser(userId);// 2. 返回用户信息AppUserVO userVO = new AppUserVO();BeanUtils.copyProperties(user, userVO);// 3. 查询redis中用户的关注数和粉丝数,放入userVO到前端渲染userVO.setMyFansCounts(getCountsFromRedis(REDIS_WRITER_FANS_COUNTS + ":" + userId));userVO.setMyFollowCounts(getCountsFromRedis(REDIS_MY_FOLLOW_COUNTS + ":" + userId));return GraceJSONResult.ok(userVO);}
追加 “基本信息VO类”,只显示部分关键信息
保留属性如下:<br />
回到Controller,给前端抛出“基本信息VO类”即可
关注与粉丝
注:getAccountInfo & getUserInfo
==**>查询 用户信息 / 基本信息 代码逻辑基本一致,返回给前端内容不同,两者也实现了解耦**。
四、理论:缓存双写!
【理论】浏览器缓存介质
1 概述
(1)为什么要对“基本信息”优化?
基本信息在 “很多页面” 都会用到,一个重复的数据,可能会在很多页面重复调用。所以这个 getUserInfo 的接口方法压力其实挺大的.
有没有一种方式降低压力?
==> 因为“基本信息”改动频率很低,所以我们把它【存在服务器上】
(2)一种存储情形
如下,session stroage 存的就是基本信息:<br />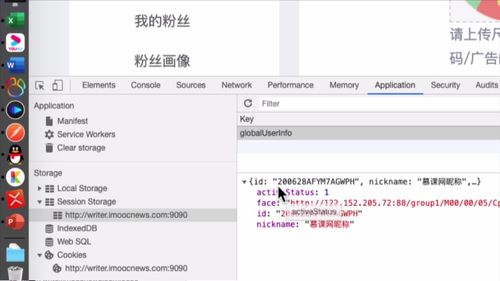<br /> 这一步,代码中也有体现:<br /> (注意看灰框中的注释,存到了“session stroage ”)<br />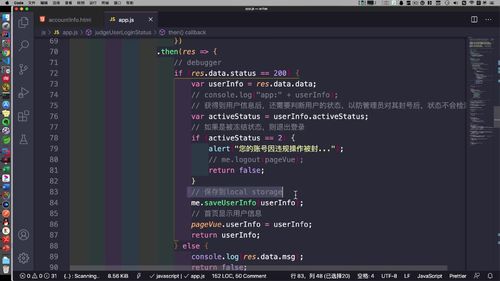
2 浏览器存储介质的几种方式
(1)cookie
浏览器存储介质其实本质上也可以称之为缓存,比如cookie,就是早期我们使用最多的,目前用户的 id 以及 token 也是保存在cookie 理的。<br /> 通过保存数据后,那么可以获得并且和后端服务器交互。<br /> Cookie是保存在浏览器的,如果不设置过期时间,那么cookie会保存到内存,如果浏览器关了,那么cookie就没了,这也起到了会话的作用。如果我们设置了过期时间,那么cookie会保存在硬盘,关闭浏览器cookie还会存在,直到过期,一般7天重新登录或者1个月免登录都是这样的。<br /> cookie 中只能存一些字符串类的内容,对象或list以json字符串去保存,但是需要注意,cookie有大小限制,4k左右,所以一般不会设置很大的数据放到cookie中。
(2)webStorage
在HTML5以后,那么浏览器可以使用 webStorage ,其实也是类似一种数据存储的表现形式,是对cookie的一种改良。
- sessionStorage:数据可以保存到session对象中。session是指用户在浏览某个网站时,从进入网站到浏览器关闭的这一段段时间,称之为会话。session中可以保存任何数据。
localStorage:数据可以保存在客户端本地磁盘中,就算浏览器关了,数据还是会存在的,重启电脑,下次打开网站,数据还是能获取。这相当于数据持久化的一种表现。
sessionStorag 和 localStorage 的区别就是,sessionStorage是临时保存,localStorage是永久保存持久化。
他们的数据存储在 5m 左右,比 cookie 大很多(能存4K左右)。
安全方面也比 cookie 好,因为不会被携带到请求中,通过 webStroage,大多网站数据进行缓存后,可以更快加载,也能为并发减轻一定压力。优化 getUser & updateUserInfo :在 Redis 中缓存用户信息 + 更新 mysql 时同步更新redis
之前虽然已经通过 sessionStorage 对“基本信息”进行了优化(这个操作是什么时候做的????前端做的吗???),但是用户如果已经知道地址,还是可以发起高频率的请求.
因为“基本信息”基本不更改的特性 ==> 我们可以把基本信息存入到 Redis 中去!这样用户查询时,直接去缓存Redis中查询即可,不用再进入数据库了代码
由于用户信息不怎么会变动,对于千万级别的网站,这类信息数据不会去查询数据库,完全可以把用户信息存入redis。
哪怕修改信息,也不会立马体现,这也是弱一致性。在这里有过期时间,比如1天以后,用户信息会更新到页面显示,或者缩短到1小时,都可以; 基本信息在新闻媒体类网站是属于数据一致性优先级比较低的,用户眼里看的主要以文章为主,至于文章是谁发的,一般来说不会过多关注.
private AppUser getUser(String userId) {String userJson = redis.get(REDIS_USER_INFO + ":" + userId);//1 尝试从redis获取AppUser user = null;//2 查询判断redis中是否包含用户信息,如果包含,则查询后直接返回,就不去查询数据库了if (StringUtils.isNotBlank(userJson)) {user = JsonUtils.jsonToPojo(userJson, AppUser.class);} else {// 3 说明 redis无,去 mysql 中搞user = userService.getUser(userId);// 由于用户信息不怎么会变动,对于一些千万级别的网站来说,这类信息不会直接去查询数据库// 那么完全可以依靠redis,直接把查询后的数据存入到redis中redis.set(REDIS_USER_INFO + ":" + userId, JsonUtils.objectToJson(user));}return user;}
...//缓存双写那里还要更新!!这就不展示了!
1 扩展 UserController 的 getUser 方法:增加初次查询放入缓存的功能
(1)定位 getUser
打开 UserController 里获取“基本信息”的方法,里面有一个getUser;找到这个方法,进行扩展!
(2)设置 redis 所需的 key 值
这里 redisController 用到一个key,这个玩意我们去BaseController中去设置一下,如下:<br /> redis_user_info
(3)导入第三方工具类
把 user 信息放到 value 的位置,需要 **JSON 转换类 ,把对象转成 str**.<br /> 这个类从老师源码中拿即可,放入 common 中的 utils 包中即可<br />
2 更改 userServiceImpl 中的 updateUserInfo 方法:补充修改信息时,同步更新缓存的逻辑(未完待续)
( 注意是 service 层 而不是 controller 层,虽然两层方法同名)
(之前只更新在了数据库,现在为了配合查询的方法,现在还要更新到Redis中)
(1)为什么
之前用户修改了信息以后,**只是存在了数据库中**!<br /> **如果不同步覆盖 redis 中的数据,那么 1 中的方法从 redis 中读取的可能就是脏数据了!**
(2)怎么做
这个方法,我们最后“补充一个查询”.<br /> “把最新的信息放入redis中”.<br /> 补充后代码如下: userId 得从 BO 中获取,这句代码也别忘了.<br />
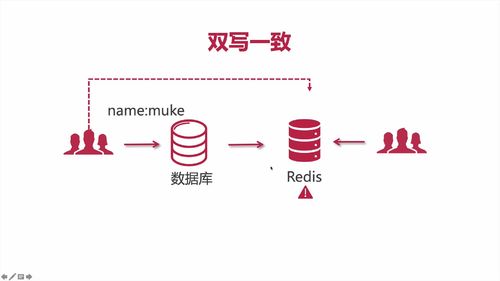
【理论/重要】双写数据不一致的情况
1 啥是:缓存双写
由于分布性系统,不能保证每个节点都可用,所有可能引起 redis 在极限情况下数据没有写入成功。那么此时缓存中的数据和数据库数据不一致。
这样的情况,同步存入 redis 的过程就可能产生问题:数据没放进redis中!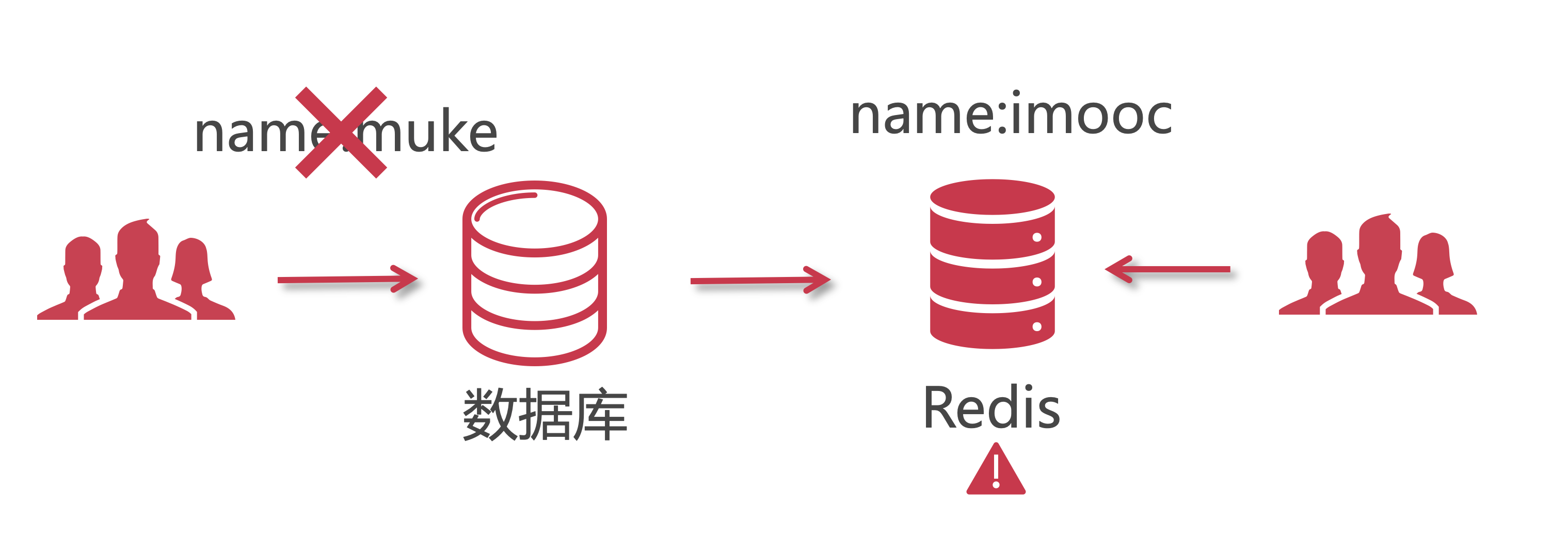
具体见老师笔记:拓展阅读https://www.imooc.com/wiki/imoocnewsarchitect/BothWriteEqual.html
如下图,“数据库中修改成功了,但是redis修改失败了”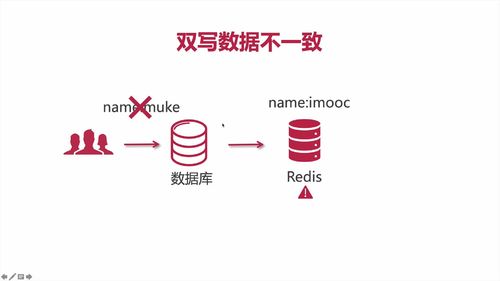
优化 updateUserInfo:双写缓存不一致 + 缓存双删
本节开始解决上节课提到的“双写不一致的情况”。
代码
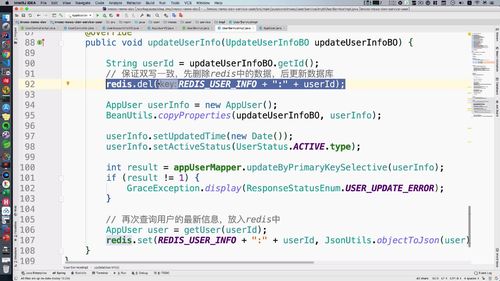
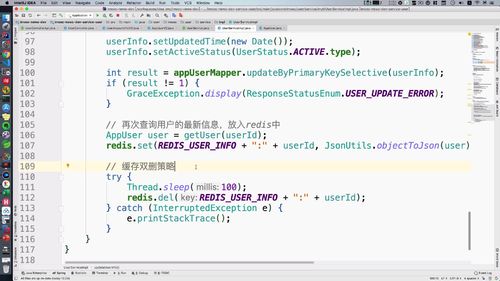
@Overridepublic void updateUserInfo(UpdateUserInfoBO updateUserInfoBO) {String userId = updateUserInfoBO.getId();// 【本节继续优化1】保证双写一致,先删除redis中的数据,后更新数据库.redis.del(REDIS_USER_INFO + ":" + userId);AppUser userInfo = new AppUser();BeanUtils.copyProperties(updateUserInfoBO, userInfo);userInfo.setUpdatedTime(new Date());userInfo.setActiveStatus(UserStatus.ACTIVE.type);int result = appUserMapper.updateByPrimaryKeySelective(userInfo);if (result != 1) {GraceException.display(ResponseStatusEnum.USER_UPDATE_ERROR);}// 【上一部分刚优化】再次查询用户的最新信息,放入redis中AppUser user = getUser(userId);redis.set(REDIS_USER_INFO + ":" + userId, JsonUtils.objectToJson(user));// 【本节继续优化2】缓存双删策略try {Thread.sleep(100);redis.del(REDIS_USER_INFO + ":" + userId);} catch (InterruptedException e) {e.printStackTrace();}}
1 双写不一致:更新 mysql 时删除 redis,使得 redis 必须去 mysql 读取数据再存入
(1) 思路分析
如何避免“双写不一致”的呢?
<1> 发起修改请求时,【先删除 redis 中过的数据】
<2> 删除后才更改数据库
<3> …后续就是再写入redis
redis中数据删除后,在重新写入前,如果用户此时访问了,【就和我们之前写的逻辑一样:redis中没有时,去数据库中查询】
(2) 代码实现:补充删除代码
2 缓存双删:优化双写不一致
(1) 问题反思
此时,分析一下,还有什么遗漏的问题。假如,用户的请求在 “ redis删除之后,mysql更新之前 ”,那么此时 redis 去 mysql 中拿到的数据,还是旧数据。如何避免?
==> 引入【缓存双删】:mysql “更新时”删一次,”等一会”再删除一次
我们在 mysql 更新后,【所在线程休眠半分钟左右,然后再次删除redis中的数据】,然后再更新。
注:这样的做法仍然是不能完全解决“脏数据的问题”,只是【很大程度上压缩脏数据的存在时时间】!!!因为对于用户来说,做到这样其实也已经足够了,这个业务并不是说,用户晚几秒看到用户信息就不能接受之类的。
(2) 代码实现
【理论】业务角度分析:为何可以容许脏数据存在?
一些情况下,业务不能受到并发影响,如果出现了 1~2秒 的脏数据,我们在首页展示的用户信息可能是错的,但是这个对整个系统的完整性是没有什么影响的,所以“保证系统可用性即可!!!”
——> 不能把太多的请求放在数据库.
从业务角度分析:并发请求绝大多数在首页和新闻详情页,用户的查询是很多的。如果出现了1-2秒的脏数据缓存,那么首页展示的用户昵称或者用户头像可能是老数据,但是对于整个系统来讲无所谓,没有太大的影响,而且用户的注意力是在新闻上,而不是新闻发布者,所以有几秒的不一致是无所谓的,因为热点数据的并发读是很大的,一旦删除,那么这个时候由于缓存击穿,数据库可能会瞬间被炸了,直接宕机。所以务必以系统可用性为优先考虑。
(????什么是缓存击穿????????)
(卧槽,感觉挺重要的,但是没听懂啊,啥叫“并发读”)
==> 因为对于这个项目,重点在于“看文章”,发布者如果信息有1-2秒错误的话,没有什么关系。
因为热点数据的 “并发读” 是非常大的,一旦删除之后,用户有大量的并发请求进来,可能造成“缓存击穿”,数据库可能瞬间爆炸。所以保证系统更可用性更加重要,几秒的脏数据没什么关系。
【理论】CAP理论
上节课最后提到了CAP理论,本节详解。
———————————————————————-
1 CAP 简介
分布式系统由多个组成部分共同构成,**用户的请求通过不同节点的多次运算后才能把结果响应给用户,也意味着请求经过了多个系统**。<br /> **分布式系统,都有CAP的情况。**<br />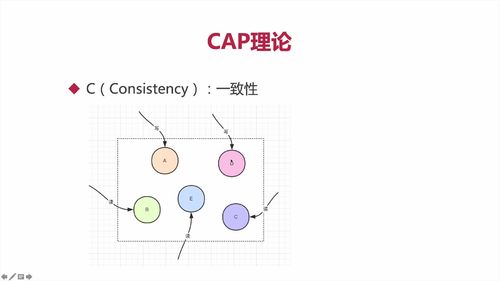<br />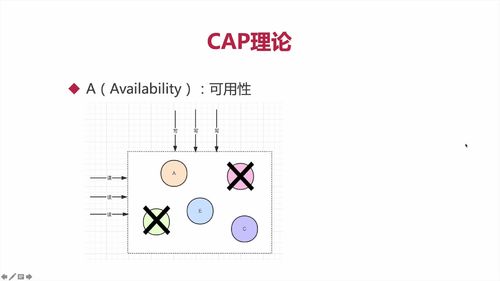<br /> 云服务器在不同地方,这就是“网络分区”。<br /> 分区之间有通信。部分系统故障不影响整体。即考虑“分区容错”<br /><br />理论上应该都满足,但实际上,因为人开发了系统,难免有错,**所以一般【只能满足CAP中任意两个】**<br />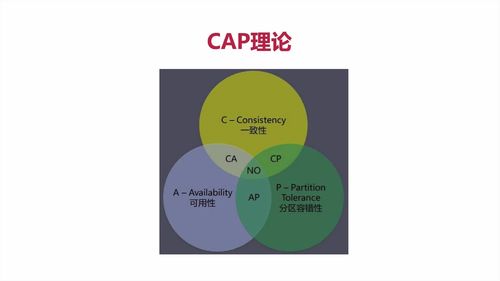
2 为何无法同时满足CAP?
(看视频讲解即可)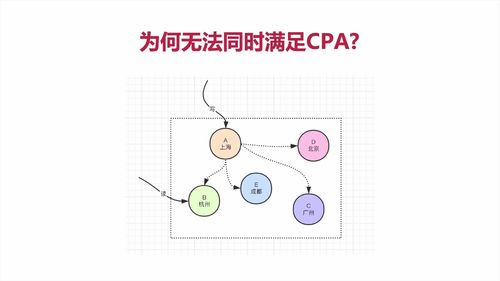
==> 开发中,都是保证好P(分区容错性)以后,采取抉择保证C(一致性)还是A(可用性)
3 各搭配分析
1 介绍
CP:效率低
redis mongoDB这种都是CP,强一致性,效率低
AP:多用(可用性 + 分区容错性)
CA:一般都是关系型数据库才用,一些单体的数据库
日常中,一般都关注“弱一致性”,强一致性难满足,用户对一般的业务也不太关注一致性。
但是数据服务一定要满足强一致性。
2 项目首页体现“弱一致性”
首页高访问,所以“优先保证可用性”,一致性可以延后处理。
(???这个为啥刷新了还不出来,不是已经重写了那个方法码?为啥非得重开一个会话才读取后端数据???==>最后老师讲了,如下,首页基本信息这里有一句“数据存入seesion storage”,估计更改信息的页面没有这句话,估计实时获取)
4 弱一致性(具体见老师笔记)
五、拦截器验证用户合法性
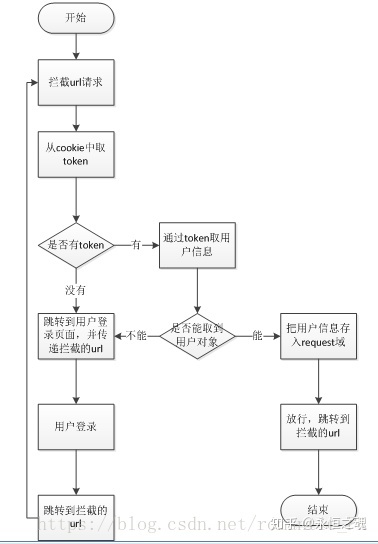
**有些接口是需要用户登录以后才能操作**,比如用户发布文章。如果随随便便一个用户调用接口,会有问题。**所以我们需要构建拦截器来验证一下用户是否合法,只有合法用户才能放行**。
用户会话拦截器
目前我们已经写了几个接口,只要涉及到接口,我们就需要考虑到 “**有些接口在用户登录时才能去访问**” <br />==> 这就需要设置拦截器。<br /> 本节,我们就给现有接口配置拦截器.其实我们之前已经配置过拦截器了,位置如下:这个就是控制短信的<br /> 现在我们需要控制“用户会话”的。只有用户在登陆,或者注册完毕以后,相应的有了**token、会话信息**,则相应的接口必须在被访问时进行拦截,必须在“用户登陆以后”才能调用这些接口!
1 创建“用户拦截类”
创建如下:UserTokenInterceptor<br />
2 实现拦截方法1
**拿到 id 和 token.**<br /> 注意,这里我们**直接从 header 里面获取**。为什么不从 cookie 里获取?因为就 H5 端有 cookie ,IOS 或者安卓端没这个东西,所以为了提高泛用性,我们就从这里面获取。(header和cookie共有的数据有哪些呢????)<br /> 拿到以后,判断是否放行,根据 id 和 token 到 redis 中去做查询和验证。因此,我们这里写一个共用的方法:**专门验证 id 和 token!!**见(3)
3 编写“验证放行的方法”
当前包下再创建一个类:**BaseInterceptor**,在里面写验证方法。<br /> **传入id token 和 key** (key就是我们以前写的常量,复制过来)。<br /> ......<br /> 需要用到redis,注入一下.<br /> ......<br /> 不空时,拿到 redis 里的 token 以后,里面还要判空,因为可能过期了;如果还不是空的,才去判断是不是相等. <br /> ......<br /> 编写好后,如下:<br /><br />(这个方法后面 admin 管理系统也会调用,所以抽出来了)
4 实现拦截方法2
拦截器继承刚刚写好的这个类:<br /><br /> 补充判断放行的逻辑:<br /> (第三个形参是前缀,BaseInterceptor 中也已经声明了,拿来用)<br />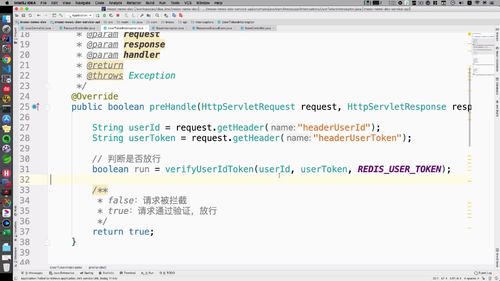
5 配置拦截器
打开 interceptorConfig<br /> ①配置Bean<br /> ②注册拦截器(add方法中)<br />想一下哪些接口目前需要被拦截到?<br /> <1>如下这个更新<br /><br /> <2> 获得账户信息的请求.<br /> <3> **获得用户基本信息需要被拦截吗?==> 这个信息不需要,这些基础信息就是给别人看的;**<br />另外,从首页头像点进去看到的是别人的个人中心页面首页,看人家文章信息啥的,这都是基本信息,这些别人不登陆,你也可以查看!<br />(点首页那个头像进去)<br /><br /><br />...<br />写好后如下:<br />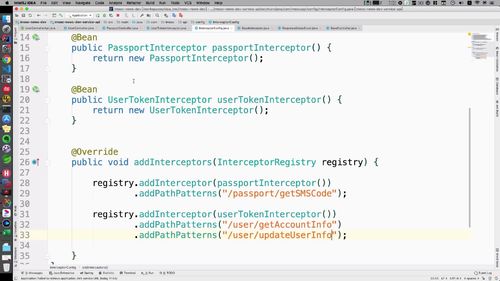
用户状态激活拦截器
本节扩展新的拦截器。
用户发表文章、修改文章、修改评论这些接口(和网站 有交互性动作),需要用户处于激活状态才可以调用!
1 创建拦截器类:UserActiveInterceptor
如下图:<br />
2 完善拦截器
要去验证用户的信息,用户登陆注册以后本身需要进行查询(即getUser方法),此时信息已经存入 redis 中了.<br /> ∴ 这里直接通过redis获取(写法参考之前)<br /> 为了能够在这里直接调用 redis,需要回去 BaseInterceptor 中,把 private 改成 public.<br /> 然后Key的前缀也复制过来:<br /> (两处改动如下)<br />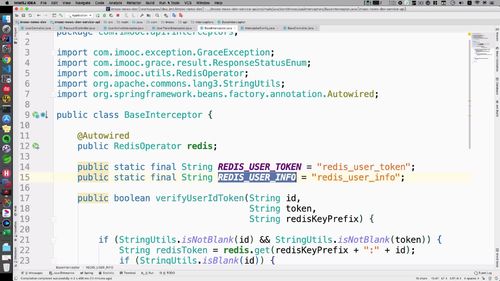<br />-----<br /> preHandler中拿到信息后,进行判断:先看看激活信息是否为空,再看看是否激活。状态如果有问题,直接抛出异常<br />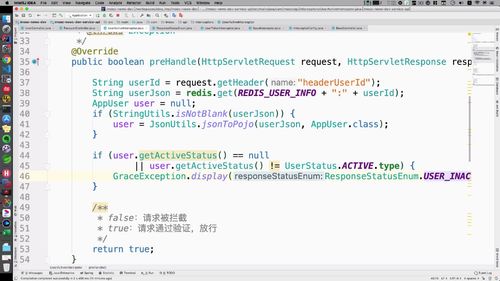<br />至此,该拦截器初步完成.
3 思考(5:20)
这里讲了一下preHandle判空后是否需要加 else 进行额外的查询<br /> ==> 这里的意思是:**如果 redis 中没有数据,是否有必要向 mysql 发起请求,把这个信息拿到,并储存到 redis 中去**?(之前的缓存双删部分的内容)<br />回答:<br /> 没有必要!**用户注册和登陆执行了以后,必然会保证 redis 中有数据**!<br /> 如果不放心,可以把向 redis 存储数据的请求放到dologin中!如下图,登陆成功且不是冻结状态,99行,执行这个存储redis的操作:即保存了用户的会话信息以后,再次保存了用户本身的信息!<br />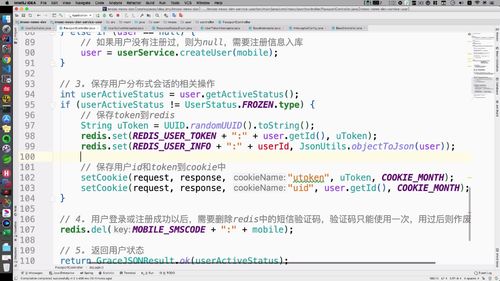
4 补充用户没登陆时的报错
if 的 else 里.<br />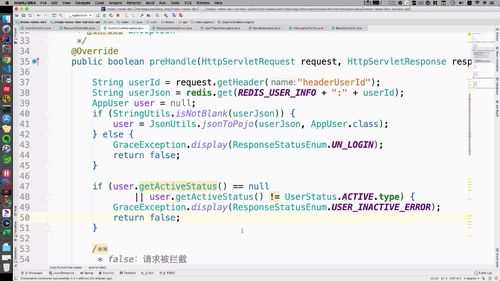
5 拦截器配置文件中注册
激活拦截这里,先注释掉!后续我们如果有需要,再回来添加!<br />
六、完善剩余功能
AOP警告日志监控
1 引
目前,项目有一个service:UserService
这里有一些相应的方法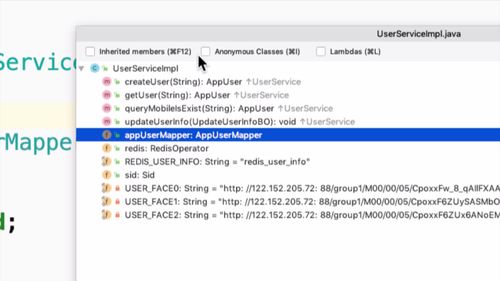
现在我们有一个需求:
想知道service在执行某一个方法的时候,花了多久的时间,根据时间输出不同的日记.
比如,如果执行时间长,我们就爆出一个警告…
==>需要用到AOP切面编程
2 AOP编程
(1)确定 AOP 作用范围
我们要拦截的就是 com.imooc.*.service.impl 包的所有类,其中 * 就是不同的业务会在后续创建不同的包。<br /> 为了在所有后续添加的服务中都可以进行切面编程,进行拦截判断,我们就需要把“**切面配置在 api 工程**”<br />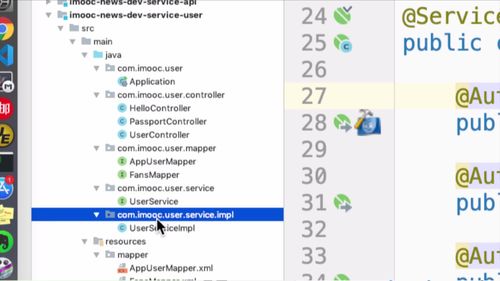
(2)创建日志切面类
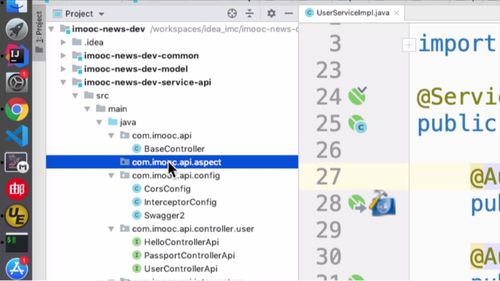
(3)去 common 的 pom 添加 aop 的依赖
(4)创建日志切面类
加aspect,标明是切面<br /> 加component,可以被注入容器<br /> 写一个日志:<br />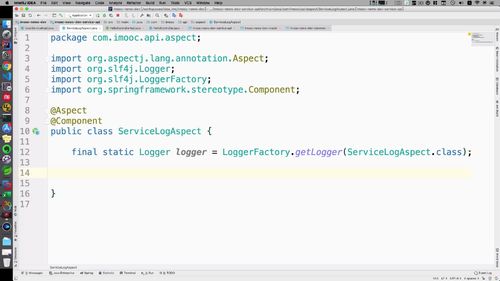<br />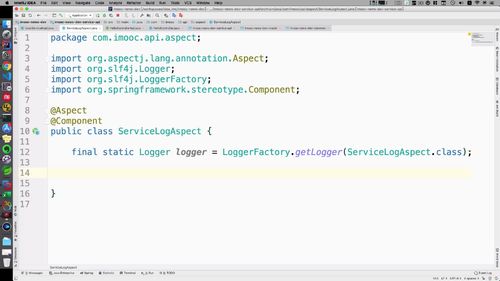
(5)回忆AOP通知:5种
(6)环绕通知1:切面表达式
首先需要正确书写“切面表达式”<br /> 表达式写在around注解的execution中<br /> 写法如下: * 根据业务改变; <br /> 最后 `..` 代表impl当前包及其子包中的所有.<br /> <br /> 最后还有:`*.*(..)` <br /> 第一个 * 代表类名;<br /> . 代表类的某一个方法,*代表所有方法;<br /> 最后 (..):方法形参任意
(6)环绕通知2:验证切面表达式
写出方法轮廓后,左侧又出一个“红色的M”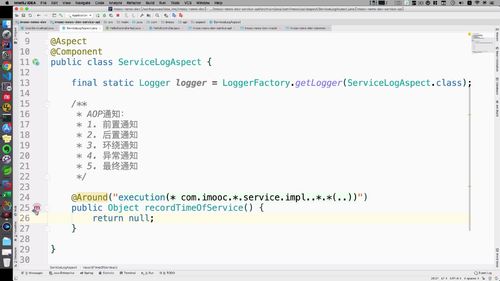
点击这个m,里面有4个方法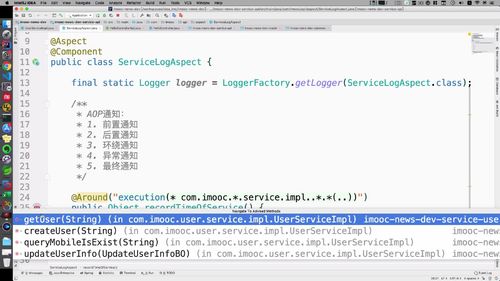
这4个方法就是我们写在service中的方法,如下图: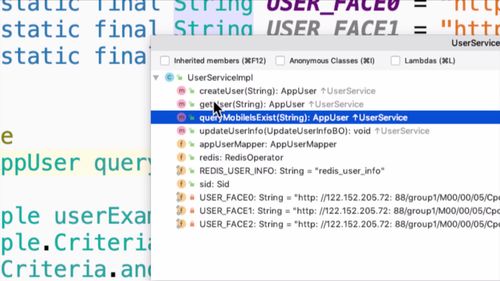
这就说明我们的切面表达式写的是正确的,有问题的话,点这个出不来
(7)环绕通知3:实现方法
形参为“切入点”.
①
开始写打印 log 的方法;其中 通过 切入点对象 获取类名,方法名等信息……
② 开始时间,结束时间,得花费时间,时间超过3s,暴一个高级别错误;大于2s时,暴一个警告;
③ 中间调用 proceed 方法表示方法执行;
返回一个object对象,我们最后直接return出去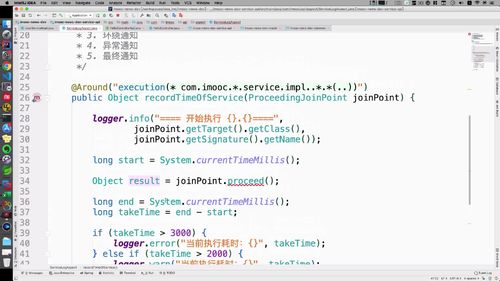
(看return)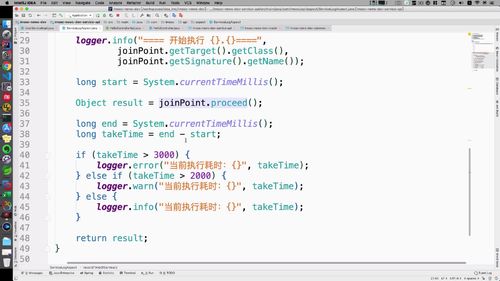
④ proceed报出异常,我们在方法上抛出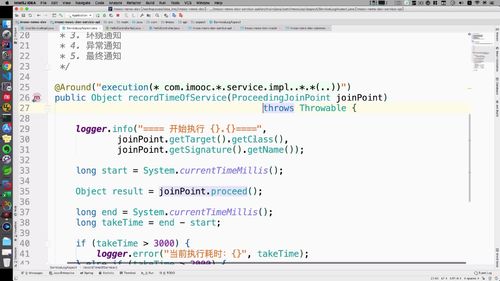
至此,方法写的差不多了..
SQL打印
Service 层的另一种调试方式:针对执行的 sql 语句
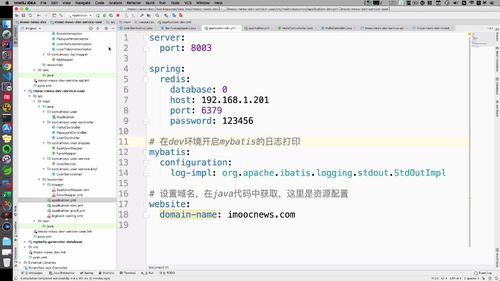
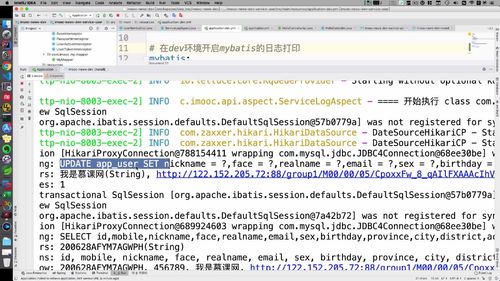
(1)开启 dev 环境 mybatis 日志打印
这个需求主要是在 dev 环境,prod环境没必要.编写如下:
(2)重启测试(18:30)
跟着老师学怎么看结果
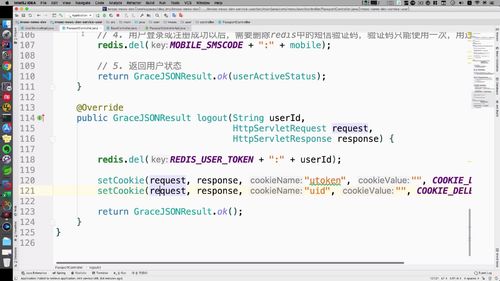
退出登录 并 注销会话
通行证服务的最后接口:退出登录。首页这里就能退出登陆:
退出登录主要就是:清除登陆信息,包括 redis 中的和 cookie 中的.这两块内容清除就退出登陆了.(??cookie是自动就配好的吗?redis确实是我们自己设置的 ==> cookie也是在dologin方法中设置的)
1 PassportControllerApi 中补充接口
需要传入一个参数:userId,有这个才能找到要删除的信息.这个形参别忘了加上 @RequestParam,否则不好执行.
2 Controller中实现接口
(1)删除 redis 中的信息
首先清除redis中的数据,根据 常量属性 和 id 拼接出 用户的 token.删除这个之后,思考一下 ...USER_INFO 有必要删除吗? 没必要,这个是没有必要的,因为其他应用可能还会用到基本信息。而token这个只与登陆相关,所以推出登陆时删掉就完事了.
(2)删除 cookie 中的信息
然后清除 cookie。这个没有del方法,所以通过设置过期时间为0的方法来达到删除的目的。之前在 BseController 中有一个 COOKIE_MONTH ,我们这里来定义一个 COOKIE_DELELTE,设置为0。在 setCookie 方法中传入即可。cookievalue这个形参直接用一个空字符串来替换即可.
第四章 文件服务
分布式文件系统
什么是分布式文件系统
- 随着文件数据的越来越多,通过 tomcat 或 nginx 虚拟化的静态资源文件在单一的一个服务器节点内是存不下的,如果用多个节点来存储也可以,但是不利于管理和维护,所以我们需要一个系统来管理多台计算机节点上的文件数据,这就是分布式文件系统。
- 分布式文件系统是一个允许文件通过网络在多台节点上分享的文件系统,多台计算机节点共同组成一个整体,为更多的用户提供分享文件和存储空间。比如常见的网盘,本质就是一个分布式的文件存储系统。虽然我们是一个分布式的文件系统,但是对用户来说是透明的,用户使用的时候,就像是访问本地磁盘一样。
- 分布式文件系统可以提供冗余备份,所以容错能力很高。 系统中有某些节点宕机,但是整体文件服务不会停止,还是能够为用户提供服务,整体还是运作的,数据也不会丢失。
- 分布式文件系统的可扩展性强,增加或减少节点都很简单,不会影响线上服务,增加完毕后会发布到线上,加入到集群中为用户提供服务。
- 分布式文件系统可以提供负载均衡能力,在读取文件副本的时候可以由多个节点共同提供服务,而且可以通过横向扩展来确保性能的提升与负载。
为什么要使用分布式文件系统
使用分布式文件系统可以解决如下几点问题:
- 海量文件数据存储
- 文件数据高可用(冗余备份)
- 读写性能和负载均衡
以上3点都是我们之前使用tomcat或nginx所不能够实现的,这也是我们为什么要使用分布式文件系统的原因.
文件存储的形式
- 传统服务器存储
- FastDFS
- OSS
- GridFS
阿里云 OSS
文件上传
图片自动审核
第五章 admin 管理服务
本章节主要包含内容为如下:
- 包含分类管理
- 管理员账号管理
- 友情链接管理
- 文章内容人工审核
- 网站用户管理
创建 module:imooc-news-dev-service-admin
文章内容这里先不做:后续会完善自动审核,自动审核不通过的人工再审核.
admin管理人员账号这里是“需要分配的”,一开始有一个admin账号,然后就可以给新的admin账号分配权限。同时除了通过用户名和密码登陆,还可以实现人脸识别登陆,人脸对比后,先让人脸入库,后续可以用人脸进行对比.
§ 5.1.1 admin 账号登陆
手动创建第 1 个 admin 账户
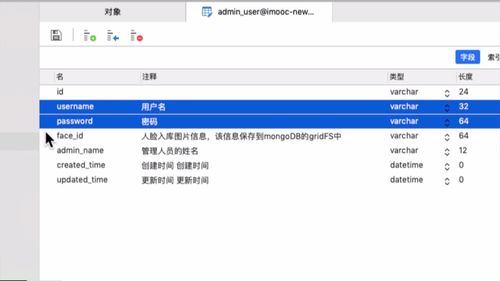
1 查看 admin 表结构
开发业务前,看看数据库列表.
我们这里 admin 和 app 用户是两张表:
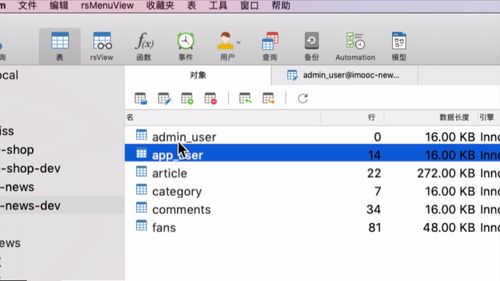
字段如下:
faceId 对应 mogoDB 中的人脸文件,搞到 mongoDB 里去.
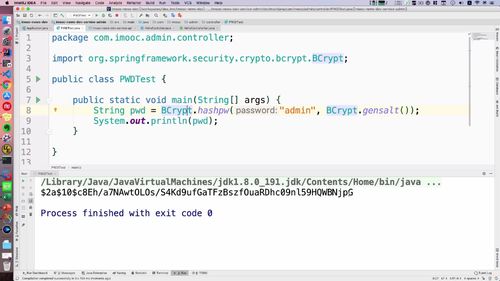
2 创建初始 admin 账号 + 加密密码
因为 admin 没有 “注册” 这一概念,都是 “预分配”:手动创建admin账号。然后通过 admin 再创建一些其他的账号.
密码需要涉及加密,去 java 里面写一下.
controller 城里面创建 PWDTest 类,api工程中加入spring的一个依赖(看笔记或者视频),然后就可以调用 BCrypt 这个类了。
我们并不是直接加密密码,而是先搞一个【salt】(hashpw中第二个形参),然后和密码(hashpw中第一个形参)一起放到 hashpw 方法中。当然老师这里用的是 “明文:admin作为密码”,实际上的话,这里最好把密码先用 【md5 加密】,然后再作为形参传入,再加盐。
这里,编写完代码并打印,如下:
String pwd = BCrypt.hashpw("admin", BCrypt.gensalt());
我们把这段拷贝到数据库中去:
ID1001,用户名admin,密码刚才生成,然后其他的如图:

持久层查询管理员:mapper和service
看看admin登陆页,人脸识别先不管,我们需要先写相应的 service 和 controller。<br />
一、创建mapper
打开项目,打开如下 admin.xml 文件:<br /><br /> 需要配置对应的表:如下改成mysql中的表名即可.<br /> 生成即可,这里都生成好了.<br />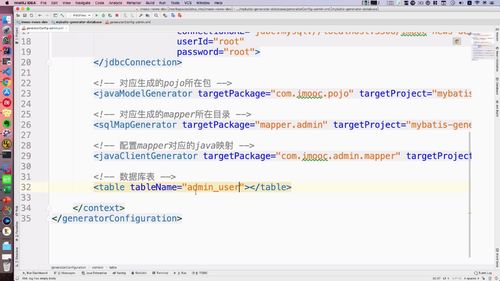<br />运行如下位置的 adminJava 类:<br /><br /> 运行成功后,相应的 mapper 啥的就都生成好了,我们都拷贝到 admin 项目中去.。宝库mapper(放到admin项目) + pojo类(放到model层) + mapper.xml文件(admin中的resource)
二、创建service:【根据用户名查询】(业务上,用户名唯一)
写对应方法:用来查询:【根据用户名查询】(业务上,用户名唯一).
查询后,把 adminUser 对象返回给 controller 层,然后在 controller 层就可以密码校验.
Example是针对 adminUser 的一个“查询实例”(==>mybatis提供的吧)。Criteria可以封装“查询条件”。Example ,其中就包含了刚才写的 “判断条件” 。返回一个 Appuser(这个和我们创建 example 时传入的类对象是一致的),不存在时,AdminUser 为 null。
@Overridepublic AdminUser queryAdminByUsername(String username) {Example adminExample = new Example(AdminUser.class);Example.Criteria criteria = adminExample.createCriteria();criteria.andEqualTo("username", username);AdminUser admin = adminUserMapper.selectOneByExample(adminExample);return admin;}
用户密码登陆:controller层
紧接上节,编写controller
登陆界面的 用户名 和 密码 是在表单里面的,可以作为 BO 传入.
当然只是这样 是不行的,用户登陆以后,cookie 和 token 这种我们也都是要设置的!
登陆信息BO验证
@Overridepublic GraceJSONResult adminLogin(AdminLoginBO adminLoginBO,HttpServletRequest request,HttpServletResponse response) {// 0. TODO 验证BO中的用户名和密码不为空// 1. 查询admin用户的信息AdminUser admin =adminUserService.queryAdminByUsername(adminLoginBO.getUsername());// 2. 判断admin不为空,如果为空则登录失败if (admin == null) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_NOT_EXIT_ERROR);}// 3. 判断密码是否匹配// 判断存在时,从数据库中获得密码,与输入的BO中的密码匹配一下.boolean isPwdMatch =BCrypt.checkpw(adminLoginBO.getPassword(), admin.getPassword());if (isPwdMatch) {//如果数据库中有,则登录成功,并且设置admin的会话以及cookie信息即可。doLoginSettings(admin, request, response);return GraceJSONResult.ok();} else {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_NOT_EXIT_ERROR);}}
登陆成功时,设置 redis token cookie 信息
/*** 用于admin用户登录过后的基本信息设置* @param admin* @param request* @param response*/private void doLoginSettings(AdminUser admin,HttpServletRequest request,HttpServletResponse response) {// 保存token放入到redis中String token = UUID.randomUUID().toString();redis.set(REDIS_ADMIN_TOKEN + ":" + admin.getId(), token);// 保存 admin 登录基本 token 信息到 cookie 中setCookie(request, response, "atoken", token, COOKIE_MONTH);setCookie(request, response, "aid", admin.getId(), COOKIE_MONTH);setCookie(request, response, "aname", admin.getAdminName(), COOKIE_MONTH);}
§ 5.1.2 admin 账号创建(添加管理员)
【业务介绍:添加管理员】
之前已经完成了admin的用户名密码登陆,登陆完后,可以设置管理员!
这个登陆名啊,我们之前说过,应该保证唯一性。
在配置这个之前,可以测试一下:输入不合理时,前端这里也是有一些事件可以触发的.
如下:
所以,这款一块是需要我们编写接口的.
校验 admin 账号“唯一性”
代码
该代码原来不是单独就有的,这里为了以后方便调用,单独抽出来了.
@Overridepublic GraceJSONResult adminIsExist(String username) {checkAdminExist(username);return GraceJSONResult.ok();}//得到用户名,判断是否存在,为方便调用,解耦出来private void checkAdminExist(String username) {AdminUser admin = adminUserService.queryAdminByUsername(username);if (admin != null) {GraceException.display(ResponseStatusEnum.ADMIN_USERNAME_EXIST_ERROR);}}
补充拦截器
我们现在已经登陆了,那么相关的操作,必须由【拦截器】进行拦截!保持用户是登陆的状态.
大家参考之前写的拦截器userTokenInterceptor,自己完成adminTokenInterceptor.
创建了interceptor,后面别忘了注册.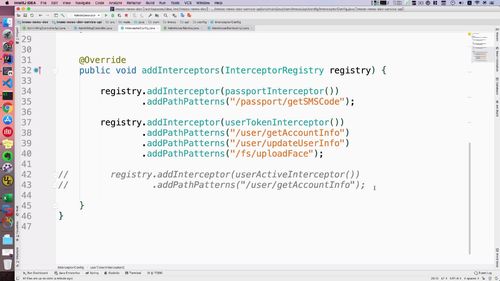
(代码老师直接提供在工程中)
创建 admin 账号
看到下面的确认添加了吗?本节就完成这个功能!
说白了就是把这里的数据发到后端,也可以将其作为一个BO的数据将其传过去。人脸数据现在还涉及不到,是以一个 img64(没听懂)的字符串传入的,这个后面再说.
添加BO
直接拷贝。里面的img64就是老师说的啥啥64那玩意。img64和faceId暂时用不上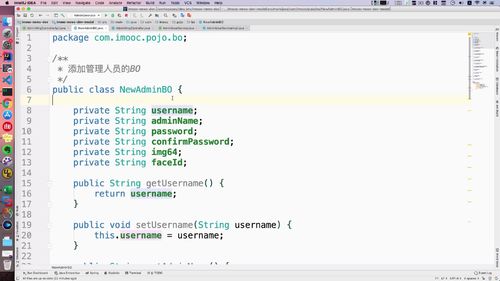
创建 admin :controller 层
@Overridepublic GraceJSONResult addNewAdmin(NewAdminBO newAdminBO,HttpServletRequest request,HttpServletResponse response) {// 0. TODO 验证BO中的用户名和密码不为空// 1. base64不为空,则代表人脸入库,否则需要用户输入密码和确认密码if (StringUtils.isBlank(newAdminBO.getImg64())) {if (StringUtils.isBlank(newAdminBO.getPassword()) ||StringUtils.isBlank(newAdminBO.getConfirmPassword())) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_PASSWORD_NULL_ERROR);}}// 2. 密码不为空,则必须判断两次输入一致if (StringUtils.isNotBlank(newAdminBO.getPassword())) {if (!newAdminBO.getPassword().equalsIgnoreCase(newAdminBO.getConfirmPassword())) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_PASSWORD_ERROR);}}// 3. 校验用户名唯一 (上部分的逻辑,直接到用单独写的那个方法)checkAdminExist(newAdminBO.getUsername());// 4. 调用 service 存入admin信息adminUserService.createAdminUser(newAdminBO); //代码在下边return GraceJSONResult.ok();}
创建 admin :service 层
@Transactional //别忘了加“事务注解”@Overridepublic void createAdminUser(NewAdminBO newAdminBO) {//①(sid主键生成啥的??==>嘶,是不是之前讲过分布式系统中的全局唯一ID那讲的???)String adminId = sid.nextShort();AdminUser adminUser = new AdminUser();adminUser.setId(adminId);adminUser.setUsername(newAdminBO.getUsername());adminUser.setAdminName(newAdminBO.getAdminName());//② 密码这里需要判空,不空时才加入//(?不是那啥,前面,难道没有判空吗?你这写了密码判空,那我前面还需要密码判空吗?)// 如果密码不为空,则需要加密密码,存入数据库if (StringUtils.isNotBlank(newAdminBO.getPassword())) {String pwd = BCrypt.hashpw(newAdminBO.getPassword(), BCrypt.gensalt());adminUser.setPassword(pwd);}//③ 设置faceID,前端提交信息的时候其实还有人脸信息的,不为空时需要设置这个,后面详细说.// 如果人脸上传以后,则有faceId,需要和admin信息关联存储入库if (StringUtils.isNotBlank(newAdminBO.getFaceId())) {adminUser.setFaceId(newAdminBO.getFaceId());}//④ 设置时间adminUser.setCreatedTime(new Date());adminUser.setUpdatedTime(new Date());//返回int result = adminUserMapper.insert(adminUser);if (result != 1) {GraceException.display(ResponseStatusEnum.ADMIN_CREATE_ERROR);}}
讨论:为什么这里不能直接存入 人脸信息?
用户人脸信息为什么不存入数据库,要存入mogoDB?
这个 base64 字符串太长了,存到数据库不适合,会放到 gridFS 去(这啥?).
也不能存入OSS,不然会公网暴露URL(???).
==>需要“私有读”,gridFS这方面好一些
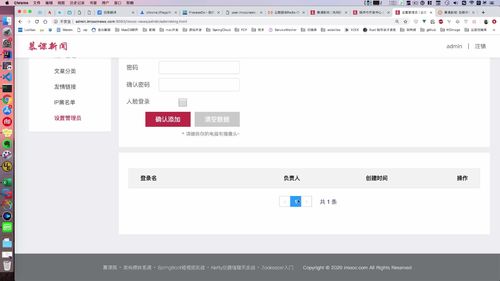
§ 5.1.3 admin 账户列表
本节做【查询admin列表】。页面下方有个列表:我们发现还需要分页
controller :getAdminList 方法
@Override// 涉及到分页,传入“第几页” “每一页要显示的数量”.public GraceJSONResult getAdminList(Integer page, Integer pageSize) {// 首先判断一下这俩形参,因为这俩是“非必填选项”,所以空的时候,来一波默认赋值.if (page == null) {page = COMMON_START_PAGE;//常数,因此我们把这俩抽离出来放到 baseControlller中}if (pageSize == null) {pageSize = COMMON_PAGE_SIZE;}PagedGridResult result = adminUserService.queryAdminList(page, pageSize);return GraceJSONResult.ok(result);}
BaseService 中分页数据封装方法:setterPagedGrid
前端这里分页组件,需要后端提供数据,计算这回才在这显示这些数字链接供我们点击。如当前第几页,查询了多少条记录。
这些功能都要封装,然后返回给前端,让前端进行相应的渲染:列表和分页组件效果.
Service层封装分页数据,这里写一个统一的方法,因为后面不仅仅是这里使用分页的方法。
其中这个rows,就是我们查询出来的数据,与在 controller 中调用 service 返回的查询结果 list 是匹配的。
// 形参这个List就是对应我们从service层查询返回的结果,为了通用性这里使用泛型.public PagedGridResult setterPagedGrid(List<?> list,Integer page) {//PageInfo里面的属性很多,我们用不了那么多. (老师提供的工具类)PageInfo<?> pageList = new PageInfo<>(list); //PageInfo类//PagedGridResult,于下部分.//这里 getPage getTotal 都是插件内部的一些方法,会帮我们计算页码.PagedGridResult gridResult = new PagedGridResult();gridResult.setRows(list);gridResult.setPage(page);gridResult.setRecords(pageList.getTotal()); // getTotalgridResult.setTotal(pageList.getPages()); // getPagereturn gridResult;}
/*** @Title: PagedGridResult.java* @Package com.imooc.utils* @Description: 用来返回分页Grid的数据格式* Copyright: Copyright (c) 2019*/public class PagedGridResult {private int page; // 当前页数private long total; // 总页数private long records; // 总记录数private List<?> rows; // 每行显示的内容...get/set...}
AdminUserServiceImpl 中 分页查询:queryAdminList 方法
相比于之前,我们这没啥查询条件,所以 criteria 这个条件介质我们就不要了。
针对 example 可以增加一个额外属性:ordeby 这个可以根据某一个属性进行排序。这里就用创建时间了.
这个返回了一个List,这是查询分页.
@Overridepublic PagedGridResult queryAdminList(Integer page, Integer pageSize) {Example adminExample = new Example(AdminUser.class);adminExample.orderBy("createdTime").desc(); //用创建时间排序PageHelper.startPage(page, pageSize); //使用分页工具:PageHelperList<AdminUser> adminUserList =adminUserMapper.selectByExample(adminExample); //返回查询分页.return setterPagedGrid(adminUserList, page); //上部分封装好的方法.}
//接口如下@ApiOperation(value = "查询admin列表", notes = "查询admin列表", httpMethod = "POST")@PostMapping("/getAdminList")public GraceJSONResult getAdminList(//这里使用了swagger2的注解对两个形参进行解释。这里required表示是否必要,true就表示必要@ApiParam(name = "page", value = "查询下一页的第几页", required = false)@RequestParam Integer page,@ApiParam(name = "pageSize", value = "分页查询每一页显示的条数", required = false)@RequestParam Integer pageSize);
拦截器:拦截分页配置插件 PageHelper
service 层方法补充分页拦截器
(1)分页插件使用介绍:使用拦截器
分页其实已经设置好了,是在项目中做了配置.
admin 项目中的 yml 文件打开,里面有一个 pagehelper(啥时候高进来的???).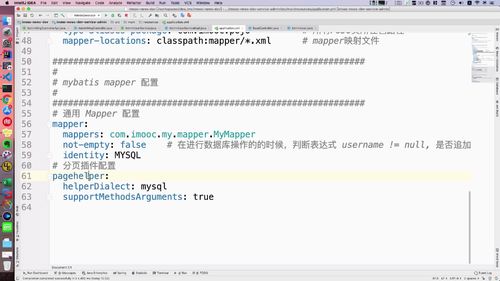
若想使用插件,搞个拦截器就好。当调用如下框起来的查询时,拦截器会追加分页信息
(2)实现:补充pageHelper的方法(这个类哪个包到进来的????)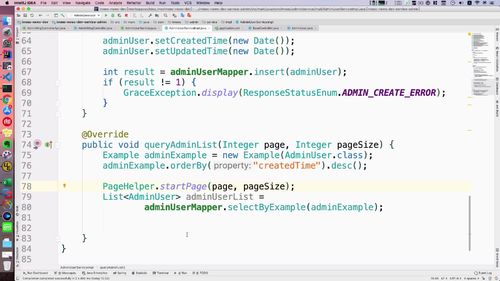
§ 5.1.4 admin 账号登出
会话 和 cookie 删掉即可.
(1)redis中删除会话token
(2)coolie中删除admin登陆信息
① 为此,我们专门去写一个deleteCookie方法:BaseController中追加
如下:通过设置cookie存在时间为0的方式来删除cookie
1)cookieValue这里进行encode(????这一步是啥意思????)
encode这里有异常,处理一波
2)存在实际设置为0,只能删除了
② 处理controller
@Overridepublic GraceJSONResult adminLogout(String adminId,HttpServletRequest request,HttpServletResponse response) {// 从redis中删除admin的会话tokenredis.del(REDIS_ADMIN_TOKEN + ":" + adminId);// 从cookie中清理adming登录的相关信息deleteCookie(request, response, "atoken");deleteCookie(request, response, "aid");deleteCookie(request, response, "aname");return GraceJSONResult.ok();}
public void deleteCookie(HttpServletRequest request,HttpServletResponse response,String cookieName) {try {String deleteValue = URLEncoder.encode("", "utf-8"); //置空,表示删除.//调用 setCookieValuesetCookieValue(request, response, cookieName, deleteValue, COOKIE_DELETE);} catch (UnsupportedEncodingException e) {e.printStackTrace();}}
public void setCookieValue(HttpServletRequest request,HttpServletResponse response,String cookieName,String cookieValue,Integer maxAge) {Cookie cookie = new Cookie(cookieName, cookieValue);cookie.setMaxAge(maxAge);// cookie.setDomain("imoocnews.com");cookie.setDomain(DOMAIN_NAME);cookie.setPath("/");response.addCookie(cookie);}
【重要】疑问:admin登陆不用redis吗?寸的session、token这些怎么用的?前端处理还是后端处理?
seesion token 不是不维护登陆状态用的?一个网站不用进入一个模块就查数据库,而是直接看token就行?
那查看redis的代码在哪呢?(包括第三章)==>在拦截器中呢,拦截器那里判断redis里若是有数据,对比完了直接放行
那redis没有token代表什么?没登陆?还是得去mysql中获取???
§ 5.2 MongoDB & GridFS 介绍
MongoDB 介绍
简介
人脸入库需要用到这个。MongoDB 可以存储 JSON。
MongoDB 是非关系型数据库,也就是nosql,存储json数据格式会非常灵活,要比数据库mysql/MariaDB更好,同时也能为 mysql/MariaDB 分摊一部分的流量压力。
对于经常读写的数据他会存入内存,如此一来对于热数据的并发性能是相当高的,从而提升整体的系统效率。另外呢,对于非事务的数据完全可以保存到MongoDB中,这些数据往往也是非核心数据。
一般来说,我们可以把一些非重要数据但是读写却很大的数据存储在MongoDB,比如我们自己的物流运输的车辆运行轨迹,GPS坐标,以及大气监测的一些动态指标等数据。又或者说咱们实战中的友情链接,友情链接在首页,这数据本身不重要,但是在首页里会经常被读到,并发读很大,所以放mongoDB中没毛病。
此外,mongodb 提供的 gridfs 提供小文件存储,可以自己把控接口读取的权限,这一点也是有优势的,比如存储一些身份证信息啊,人脸信息啊都是可以的。

术语
以下是MongoDB和数据库以及ElasticSearch(es没接触过的,待后续整合es后可以回过头来对比看看)的术语对比: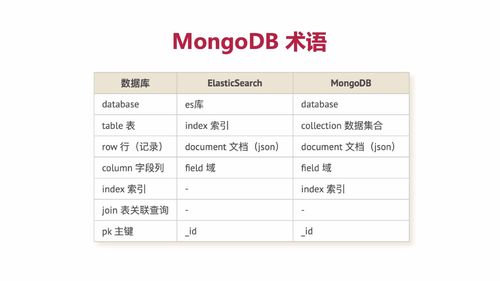
数据结构演示
一个 {} 就是一个大对象 / 一个document / 一个JSON对象.
MongoDB 是 Nosql 数据库,一个 {} 三个结构,另一个可以是四个结构.

- MongoDB可以创建多个数据库(同mysql)
- 一个数据库可以创建多个collection(同mysql创建多表)
- 一个集合可以包含很多文档数据(同mysql一张表包含很多行记录)
我们可以通过如下代码片段来更好的理解MongoDB的数据对比,假设这张表中总记录有3条
UserList: [{userId: "1001",username: "lee",age: 18,sex: "boy"},{userId: "1002",username: "jay",age: 20,sex: "boy"},{userId: "1003",username: "jolin",age: 19,sex: "girl"}]
如上述代码中:
- UserList是一个collection,在mysql中可以当做是一张表
- UserList中的每个{}都是一个json对象,他们称之为document文档,在mysql中称之为行记录
- userId、username、age、sex 这些都是field 域,在MySQL中称之为column列字段
GridFS
一、介绍
一般软件中,bucket相关的都是和“文件存储”挂钩.
为了实现人脸识别,我们需要用到gridFs Buckets这个模块.
这个也算是一个“对象”,我们需要将其放到spring容器中去,随后才能使用它进行文件的上传,传到 mongodb 中去.
二、整合 SpringBoot
1 定义接口
file 工程中的文件上传 controller 的 api 中:这样的话,前端那里手机号图像,点击确定后,就会触发这里的方法.
==>【其实不仅仅可以上传人脸文件,其他文件都可以通过这个方法上传】!!!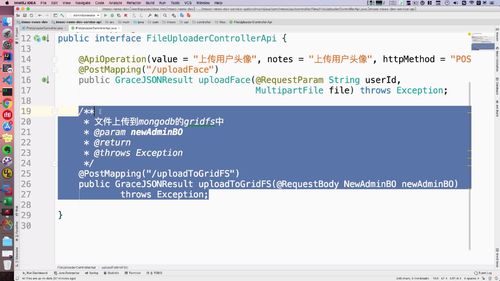
2 引入依赖
…
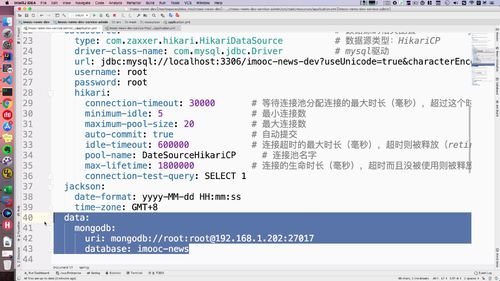
3 mogodb配置信息
打开当前项目的 yml 文件:
spring的下面加: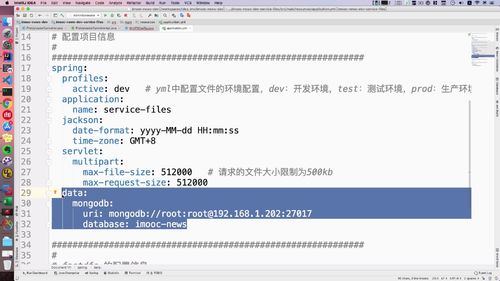
这里数据库这个imooc-news数据库中没有,得先去创建一下.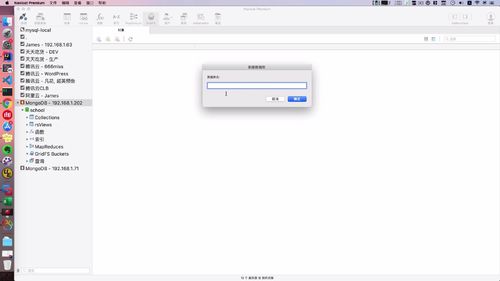
4 编写 GridFS 配置类
file包下搞一个配置类.
str 这个 mongodb 就是获取配置文件中 mongodb 信息的。gridFS Bucket 这个方法就是我们之前引入以后才可以调用的;其他一些没见过的形参基本也都是输入mongodb的依赖的.
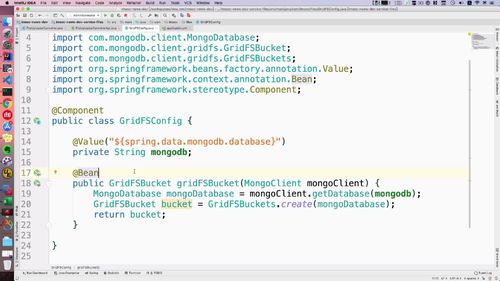
————————
至此,mogodb 和 gridfs 就算是整合到项目中去了.
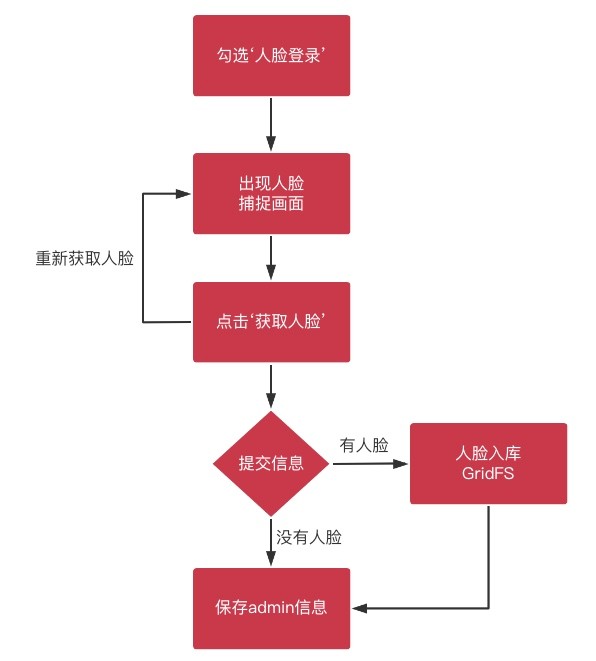
§ 5.3.1 人脸入库
流程
入库
Chrome开启视频调试模式
实现人脸存入MongoDB 【GridFS】
人脸入库,我们会把用户的人脸信息保存到 gridfs 中,当然如果使用oss或者fastdfs也可以,只不过gridfs可以控制在内部访问,其他的相对不是很方便,而且做好内部资源和外部资源的解耦也是一种不错的选型。(???不是很懂,什么内部资源外部资源的???)
接下来,我们就需要去实现我们写的 api 中的文件上传至 GridFS 的方法了。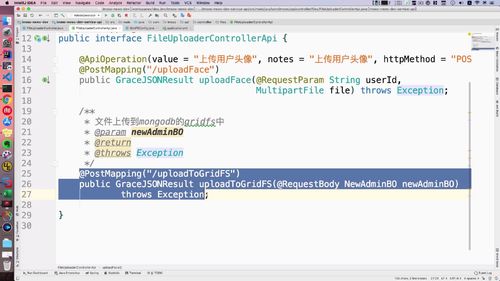
前端拿到 文件ID 以后,会在下次提交时把这个 id 提交到后端,这样的话,【mongodb 就和 Mysql 建立了关联】.
思考:mysql 和 mongodb 怎么建立联系的 ???
==> 注意,mongodb 只存了 用户文件 的 fileId 和 头像 img64,所以注定了若想查询这里的数据,都必须是【根据用户 id,去 mysql 中拿到 fileId,然后用fileId 去 MongoDB 中查询头像】.
@Overridepublic GraceJSONResult uploadToGridFS(NewAdminBO newAdminBO)throws Exception {// ① 通过 bo 获得 base64 的字符串String file64 = newAdminBO.getImg64();// ② 通过decodeBuffer把这个字符串转成byte数组,中间使用trim去除两边的空格byte[] bytes = new BASE64Decoder().decodeBuffer(file64.trim());// ③ byte[] 就可以转成输入流ByteArrayInputStream inputStream = new ByteArrayInputStream(bytes);// ④ 上传成功以后,我们通过 fileId 拿到其再 gridfs 中的 id,这个就可以返回给前端了。// 上传到gridfs中,需要注入 gridFSBucket 这个类.ObjectId fileId =gridFSBucket.uploadFromStream(newAdminBO.getUsername() + ".png", inputStream);// 获得文件在 gridfs 中的主键 fileIdString fileIdStr = fileId.toString();return GraceJSONResult.ok(fileIdStr);}
查看admin人脸信息【GridFS】(人脸登录模块要调用)
分析:需要建立起 mysql 的 id 和 mongodb 的 faceId 的联系
目前实现了:人脸入 mongodb 库 。admin 列表中,可以点击查看人脸,如果有人脸的话,就可以显示了。目前点开还是什么都没有. 本节课就实现这个.
我们点击人脸,有一个参数的传递,点击的时候拿到了数据库的【 admin表 的 faceId】 ,传给后端。后端接收到这个id,我们【去 mongodb 获得这个文件】,然后传给前端输出即可.(和咱之前分析的逻辑一致)
readGridFSByFaceId:从mongoDB获得文件,保存一个temp文件,然后下载到本地
(1)(2)
mongodb中,ID 才是主键,实际上调用时候得用 _id;
find 方法返回值是一个列表,所以结果用 GridFSFindIterable(不是,都说了主键是唯一的,为什么还能查出来多个值???是这个意思吗?)
==> 这个find 可以查各个字段的吧,只不过 id 这个比较特殊,虽然查出来是列表,但是必然就 1 个元素。同时,也正因为就 1 行数据,那么就可以调用 first 方法,第一个必然就是结果了,当然,也就只有这 1 个数据。
(4)
拿到 文件 以及 文件名 就可以输出了,我们其实可以把当前这个文件在服务器上进行保存,然后写到临时目录(???什么现在本地,linux的话就临时目录啥的???),然后可以通过 response 展现给前端。所以,file 这里我们就把目录写死了;可以判断一下这个目录有没有,如果没有的话就创建这个目录.
==> 我们一般做法都会在机子上留存temp文件,方便排查问题。定时删除就行的哈。
(7)
return 的是个 file,这个 file 在 new 的时候制定了 “文件路径” + “fileName”,这样的话,直接能跟着这个找到我们存储的文件了?是这个意思吗??
(….说实话,这一段好多血继不懂,那个gridFS不是文件吗?咋最后除了得个名字也没见用到呢?还是说之前那个gridFS只是获得文件名,最后文件的落地还是得靠这个gridFSBucket调用过的download方法吗???)
//【核心】查询的时候就和 数据库传过来的 faceId 进行匹配.private File readGridFSByFaceId(String faceId) throws Exception {//(1)这里调用 mongodb 包里面的 filters 类进行过滤查询,这个就是和mongodb里机制一样.GridFSFindIterable gridFSFiles= gridFSBucket.find(Filters.eq("_id", new ObjectId(faceId)));//(2)通过first文件保证得到第一个,返回一个文件类;GridFSFile gridFS = gridFSFiles.first();//(3) 再判空一下,不空时,拿到文件.if (gridFS == null) {GraceException.display(ResponseStatusEnum.FILE_NOT_EXIST_ERROR);}// 我们先或得一下filename,为了方便测试,我们这里先写一个sout;String fileName = gridFS.getFilename();System.out.println(fileName);// (4)获取文件流,保存文件到本地或者服务器的临时目录File fileTemp = new File("/workspace/temp_face");if (!fileTemp.exists()) {fileTemp.mkdirs();}File myFile = new File("/workspace/temp_face/" + fileName);// (5)创建文件输出流OutputStream os = new FileOutputStream(myFile);// (6)下载到服务器或者本地gridFSBucket.downloadToStream(new ObjectId(faceId), os);// (7)return myFile;}
readInGridFS :从gridfs中读取文件,然后输出给浏览器
刚才写的方法返回了一个file,接受一下.
然年后把图片输出到浏览器即可,这里需要用到一个工具类:FileUtils。包含了两个方法:下载文件 和 输出成base64。我们用的就是这个下载文件这个方法,这个方法就是把图片搞到了response中。因为需要用到response,我们去api中补充一下形参.
@Overridepublic void readInGridFS(String faceId,HttpServletRequest request,HttpServletResponse response) throws Exception {// 0. 判断参数if (StringUtils.isBlank(faceId) || faceId.equalsIgnoreCase("null")) {GraceException.display(ResponseStatusEnum.FILE_NOT_EXIST_ERROR);}// 1. 从gridfs中读取File adminFace = readGridFSByFaceId(faceId); //该方法见下面// 2. 把人脸图片输出到浏览器FileUtils.downloadFileByStream(response, adminFace);}
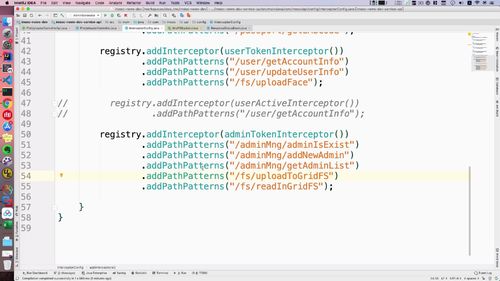
拦截器中补充 本节以及上一节 的路径
此时,我们可以控制 admin 登陆时才能访问到数据.
OSS这种在代码层就控制不了(why???)
疑问:这里说的OSS控制不了是啥意思???之前就对比了GridFS,OSS啥的,区别在哪呢??
Mongodb 依赖共享问题:去除Mongo自动装配
启动其他工程时报错了:model中 的 Mongodb 依赖被共享,导致其他工程启动时也会扫描 mongodb,但是只有file工程中的 yml 配置了了 Mongodb 的信息
==> 两种方案:
① 需要去其他两个工程的 yml 文件中配置这些信息. —-> 但是其他两个工程确实用不到这个,显然这个方法不是很好.
② 其他两个项目排除自动装配(卧槽!!!我刚做这个项目的时候,查的方法好像就是这个!!) 如下,俩工程都加一下.
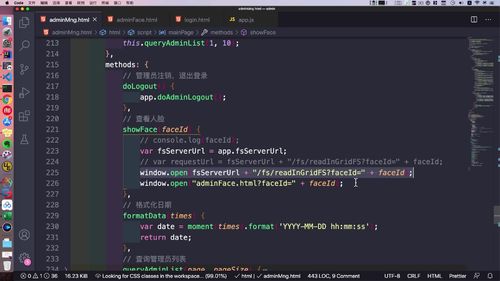
(没懂)思考:如果前端留坑,header 无法传到后端怎么办?
后端扩展拦截器,可以读取cookie即可。
(1)
如下图,showFace中,如果前端写成了open第一行那个代码,直接把后端 的地址卸载了这里,一旦做了预发布,此时更改都做不了;此时后端还没写好,咋办??
此时前端不可以把 header 携带过去,后端就需要进行兼容和扩展。
之前的方式拦截器可以拦截。
(2)老师提供了新的拦截器进行匹配(老师最后也没用,就展示了一下,拦截器都没注册)
(没看清,应该是common工程,位置如下)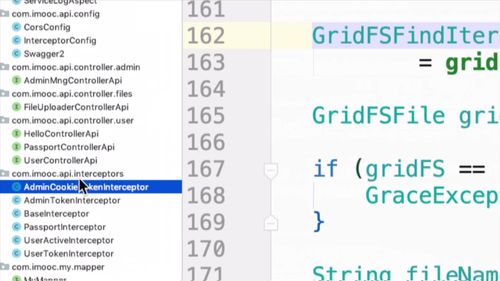
通过token的方式获得 id 和 token。
此时前端不需要修改代码,下一个版本迭代时就可以修改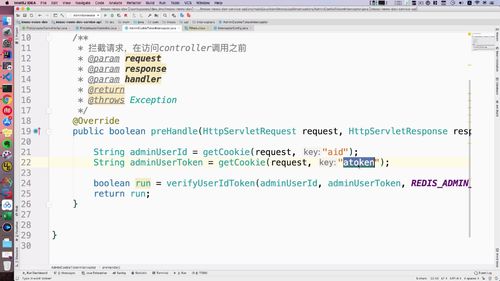
当然,这段代码还是注释掉。
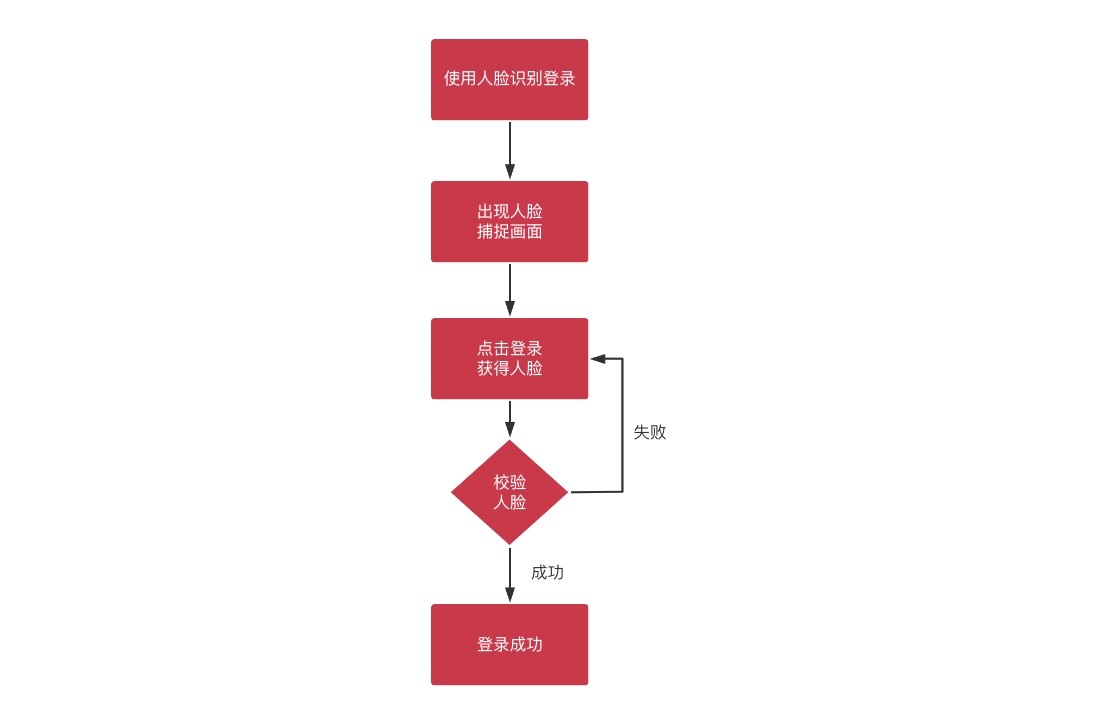
§ 5.3.2 人脸登录
流程
登陆
阿里人脸识别
人脸识别一般都可以借助第三方来实现,比如阿里只能AI/百度AI/腾讯云AI等来进行实现。
如下是阿里AI的相关资料,可以打开进行参考,内容介绍也是分详细。并且他也提供了很详细的api代码进行直接的对接。
- 人脸识别 Face Recognition: https://www.aliyun.com/product/bigdata/product/face
- 介绍:https://help.aliyun.com/document_detail/146428.html
- api:https://help.aliyun.com/knowledge_detail/53535.html
- api示例:https://help.aliyun.com/document_detail/67818.html
- 演示端:https://data.aliyun.com/ai?spm=a2c0j.14094218.813079.11.16022fd5Ii0wRk#/face-detect
完整代码
编码还是跟着页面走.
图片1:点击人脸识别登陆,拿到 faceId,然后就可以调用文件服务,把对应数据从 mongodb 中拿出来,并且转换成base64
图片2:下图左(没搞懂),人脸提交过去进行对比
注意,这里不是在 admin 工程中直接搜索人脸信息,我们是微服务,文件相关的业务都放到 file 工程中去,admin 这里远程调用 file 的方法即可。服务之间要保证边界的存在.
@Override//形参 BO 就包含了 img64 这个属性;public GraceJSONResult adminFaceLogin(AdminLoginBO adminLoginBO,HttpServletRequest request,HttpServletResponse response) {// 0. 判断用户名和人脸信息不能为空if (StringUtils.isBlank(adminLoginBO.getUsername())) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_USERNAME_NULL_ERROR);}String tempFace64 = adminLoginBO.getImg64(); //【拿到前端收集的 faceId】if (StringUtils.isBlank(tempFace64)) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_FACE_NULL_ERROR);}// 1. 从数据库中查询出faceIdAdminUser admin = adminUserService.queryAdminByUsername(adminLoginBO.getUsername());String adminFaceId = admin.getFaceId();if (StringUtils.isBlank(adminFaceId)) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_FACE_LOGIN_ERROR);}// 2. 请求文件服务,获得人脸数据的base64数据//远程调用的 url 拼接String fileServerUrlExecute= "http://files.imoocnews.com:8004/fs/readFace64InGridFS?faceId=" + adminFaceId;//这个就是 远程调用 方法ResponseEntity<GraceJSONResult> responseEntity= restTemplate.getForEntity(fileServerUrlExecute, GraceJSONResult.class);//拿到返回的对象,就可以调用 getBody 返回了.GraceJSONResult bodyResult = responseEntity.getBody();//最后需要将 getData 得到的 object 类型强转成 String 类型.String base64DB = (String)bodyResult.getData(); //【拿到后端存储的 faceId】// 3. 调用阿里ai进行人脸对比识别,判断可信度,从而实现人脸登录boolean result = faceVerifyUtils.faceVerify(FaceVerifyType.BASE64.type,tempFace64, //1 中拿到了 前端收集的 faceIdbase64DB, //2 中拿到了 后端存储的 faceId60);if (!result) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_FACE_LOGIN_ERROR);}// 4. admin登录后的数据设置,redis与cookiedoLoginSettings(admin, request, response);return GraceJSONResult.ok();}
第 0 步:用户名 / 人脸信息 不能为空(密码没关系)
第 1 步:admin服务中,获得 faceId
根据用户名,从 mysql 查到admin对象.
通过admin对象拿到 faceId。
// 1. 从数据库中查询出faceId//根据用户名,从 mysql 查到admin对象AdminUser admin = adminUserService.queryAdminByUsername(adminLoginBO.getUsername());//通过admin对象拿到 faceIdString adminFaceId = admin.getFaceId();//判断 faceId 是否存在if (StringUtils.isBlank(adminFaceId)) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_FACE_LOGIN_ERROR);}
第 2 步:file服务中,请求文件服务,获得人脸数据的 base64 数据
我们首先得发起请求,但是首先我们需要对应的接口。对应的接口 getMapping 中的路径可以随便取,因为这里的话只是后端内部调用,不反馈给前端( 那干脆直接不要这个注解不就行了??)
这里 readGridFSByFaceId 是我们之前写过的,直接调用即可.
返回值字符串也行;我们这里用这个的话,调用端也能拿获取.(????)
@Overridepublic GraceJSONResult readFace64InGridFS(String faceId,HttpServletRequest request,HttpServletResponse response)throws Exception {// 0. 获得 gridfs 中人脸文件//readGridFSByFaceIdFile myface = readGridFSByFaceId(faceId);// 1. 转换人脸为 base64String base64Face = FileUtils.fileToBase64(myface);return GraceJSONResult.ok(base64Face);}
整合 restTemplate 服务通信,在 admin 中调用 file 中的方法
分析:服务间发起调用
现在目标是:调用编写的的 “文件获取并且转换类型” 方法.
这里 admin 和 file 工程之间是没有关系的,是并列的,都是继承于api工程的,所以 admin 不能直接调用 file 的API.
服务间发起调用其实有多种方式,比如 RPC 通信;这里选择 HTTP 通信( 这一步分后期可以通过spring cloud微服务的方式进行进一步的优化 )。使用 HTTP 的话,就得用到 restTemplate 这个类了。需要进行相应的配置。
不同服务之间的通信可以采用restTemplate来进行通信调用,当然使用httpClient来构建也是可以的。
Api 工程中 config 包下构建 CloudConfig 类(没搞懂这狗玩意咋用的)
OKHttp3 这个玩意好像是 sb 框架中提供的
@Configurationpublic class CloudConfig {/*** 基于OkHttp3配置RestTemplate* @return*/@Beanpublic RestTemplate restTemplate() {return new RestTemplate(new OkHttp3ClientHttpRequestFactory());}}
(有疑问,参数传递不太懂)编写调用方法所需的 url
可以调用的方法不少,我们选用第二个。第二个方法里面后面有一个Object urlVariables 。我们之前的方法是请求参数的形式,只需要在请求后面加上 faceId 就能传递过来(??这种带有 getMapping 的方法自动拆分路径和形参的吗??),所以我们调用的时候,不需要写这个urlVar这个形参的
不管咋样,先写个url的地址。url这里是写死的(后面会改);url需要用到下面的这个:
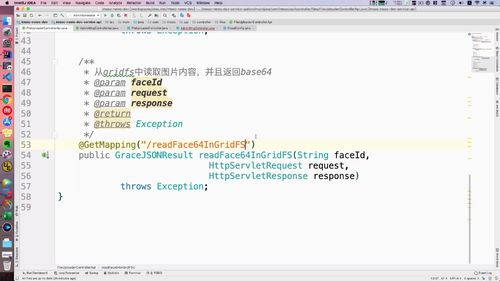
路由的参数就是 file 中那个 getMapping(之前不懂啥意思,还想着给人家删掉呢),faceId这里直接通过 ? 进行拼接。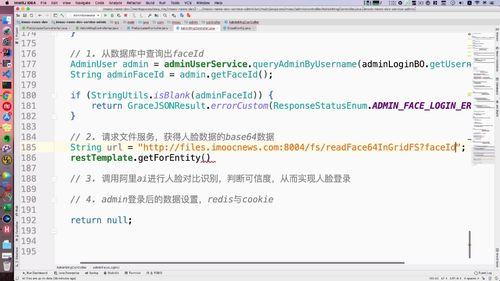
调用 restTemplate 的方法
第二个形参就是“返回的类型”.
拿到返回的对象,就可以调用 getBody 返回了.
这次,就可以获得 base64 的数据了 .
最后需要将 getData 得到的 object 类型强转成 String 类型.
...// 2. 请求文件服务,获得人脸数据的base64数据//远程调用的 url 拼接String fileServerUrlExecute= "http://files.imoocnews.com:8004/fs/readFace64InGridFS?faceId=" + adminFaceId;//这个就是 远程调用 方法ResponseEntity<GraceJSONResult> responseEntity= restTemplate.getForEntity(fileServerUrlExecute, GraceJSONResult.class);//拿到返回的对象,就可以调用 getBody 返回了.GraceJSONResult bodyResult = responseEntity.getBody();//最后需要将 getData 得到的 object 类型强转成 String 类型.String base64DB = (String)bodyResult.getData();...
第 3 步:调用阿里ai API进行人脸对比,判断可信度,实现人脸登陆
代码
// 3. 调用阿里ai进行人脸对比识别,判断可信度,从而实现人脸登录// 返回结果boolean,表示成功与失败.boolean result = faceVerifyUtils.faceVerify (FaceVerifyType.BASE64.type,tempFace64, //face1base64DB, //face260); //可信度if (!result) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ADMIN_FACE_LOGIN_ERROR);}
引入工具类:FaceVerifyUtils
工具类中有属性: 阿里云的 resource,如下图。ataway 就是网关
调用现有的人脸工具类,进行两张人脸的信息对比,工具类就是阿里文档中所提供的 sdk 与 api ,比较丰富,也可以参考官方的进行修改都可以。
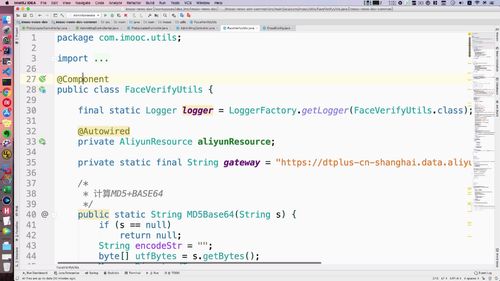
AdminMngController.java 中注入工具类 FaceVerifyUtils
调用方法 FaceVerifyUtils 的 faceVerify 方法
faceVerify 方法的 四个形参 和我们在阿里 AI 官网那里介绍的一样,回去看,最后一个形参就是“可信度”。
faceVerify 方法第一个形参这里 FaceVerifyType 是老师自己加的枚举类,没加自己就加一下.(包名图中有)
第 4 步:admin登陆后的数据设置,redis和cookie
(好像,没专门设置 cookie 和 redis 啥的吧….)
// 4. admin登录后的数据设置,redis与cookiedoLoginSettings(admin, request, response);
§ 5.4 MongoDB 处理 友情链接
目前管理员模块已经完成,现在呢,我们看左侧列表:我们从下往上去做.
黑名单先不做.
友情链接用 mongodb 做 ————- 再次介绍使用场景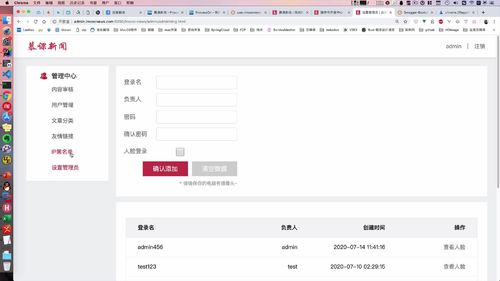
MongoDB 使用场景

① GridFS 用来存储一些隐私小文件:人脸 ,身份证这种以也可以.
② 历史数据快照:例如,你在商城买了一个东西100元,没给钱,明天涨价到150,你的订单里的数据不会涨价到150,该商品数据不会随着商户的更改而更改,这就是快照数据,此时订单里的这个就是一个快照。而快照数据对于每个用户来说有很多,所以往往把他们剥离出来放到MongoDB中去,我们就不存在MYSQL中了。
③ 用户浏览记录:用户在电商系统会浏览很多商品,那么如果存到数据库,那么该张表的数据就是指数级增长了,mysql 压力相当大,所以可以剥离放入到mongodb中。
④ 客服聊天记录:虽然我们对外称聊天记录不存保存,但是我们还是会存储一下,而聊天记录都是非关键数据,哪怕没有也无所谓,所以完全可以放到mongodb中去。
==> 后面三个,本身也是“非必要数据”,为数据库分担了大数据量的存储压力
Q:能不能把这些数据都存 redis 中呢?
A:不行,Redis是持久化的,存储到内存的,都存到 redis 成本顶不住,内存太贵了。如果你们公司老板土豪,可以无限购买内存的话,无所谓。但是需要考虑内存成本的时候,这就需要使用 mongodb 了。所以说,Redis主要用来分摊读压力,提供缓存机制。而 MongoDB为数据库分摊大数据量的存储压力,此外这些都是非核心业务数据,哪怕全部丢失了,也无所谓,不会造成整个系统崩溃。
==> 存在Redis中行吗?Redis是持久化的,存储到内存的,都存到 redis 成本顶不住,内存太贵了.
友情链接保存与更新:Controller 层 保存 BO 到 MO(Service 层下部分处理)
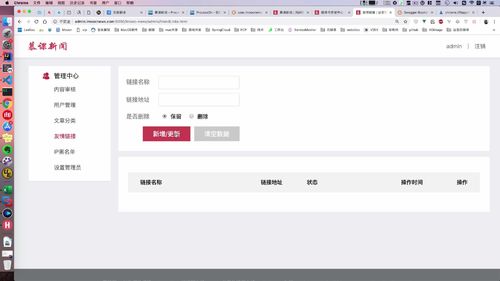
友情页面如上图
(1)新增和修改:[ 无id,新增;有id,修改. ]
同时也是表单页面,需要把这些放到 BO 里面去
(2)是否删除(说是“逻辑删除”,没懂啥意思)
(3)下面那个查询列表先不管.
1 admin 工程中配置 Mongondb(之前是在 file 模块中配置的)
(1)补充配置文件
友情链接的增删改查和 mongodb 都是相关的,这块业务在admin中,所以 admin 中需要补充这块 mongodb 相应的配置。从file那边复制过来粘贴到如下位置即可:
(2)恢复注释
不用排除 mongodb 了.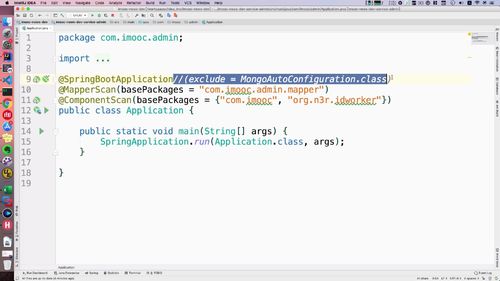
2 导入 friendBO
方法中用到的 friendBO 老师写好的,直接导入即可.
① id 作为我们判断“更新/增加”等的依据.
② BO中属性的 自定义校验注解:关于url的校验
linkurl 上面 checkurl 注解是用来校验其url格式是否正确的。也属于工具类。
(老师自己写的还是导入的?看包名好像是导入的)
(好像 有个 urlUtil 需要自己导入一下.)
(这里点了很多层看这个注解底层啥的,最后还是通过正则表达式判断的)
==> 没有这个注解的话,只能去 controller 层进行校验了(因为BO是前端搞过来的,直接接触的就是BO层)!
有了这个注解以后,就可以精简代码!
public class SaveFriendLinkBO {private String id;@NotBlank(message = "友情链接名不能为空")private String linkName;@NotBlank(message = "友情链接地址不能为空")@CheckUrl //@CheckUrl 用来校验其url格式是否正确的。也属于工具类private String linkUrl;@NotNull(message = "请选择保留或删除")private Integer isDelete;...set/get......}
(4)作业,参考(3),写一个@Name来校验用户名
要求:not blank 无空格 + not empty 非空 + length 6-12
去理解一下自定义注解的使用方式(操,其实还是不太懂,得专门去复习注解的知识)
3 创建 controller 的接口:saveOrUpdateFriendLink(新增或者修改友情链接)
(5)完善接口方法如下
@ valid是为了提示内部进行校验
(??BindingResult这个类封装的啥?啥时候讲过???==>一键注册登陆时候讲过)
@ApiOperation(value = "新增或者修改友情链接", notes = "新增或者修改友情链接", httpMethod = "POST")@PostMapping("/saveOrUpdateFriendLink")public GraceJSONResult saveOrUpdateFriendLink(@RequestBody @Valid SaveFriendLinkBO saveFriendLinkBO,BindingResult result);
4 补充MO交互对象(为了保存BO信息)
数据库中没有 友情链接 的内容,友情链接应该保存到 mongodb 中去。和持久层做交互,需要有对应的持久层对象。命名上,与 mongodb 交互的对象我们一般都命名为 *MO。
现在:和 DB 交互的映射对象叫 BO ,和 mogodb 交互的叫 MO .
① 去 model 工程中的pojo中创建一个新的包:mo。
② id 前加 @id 代表其是 Mongodb中 的主键**。注解选择 springframework 包下的,而非 javax下的.
③ 对于 linkname,需要 @field 注解,配置后使用
实际上mongodb中对应字段是link_name,所以需要 @field 注解帮我们进行处理。这个注解注入mogodb相关配置以后才能使用,去搞一搞。打开model里面的配置文件,如下:属于一个spirngboot和Mongodb的整合包:
这个时候就可以添加 field 注解了
不想加这个也米有关系:表中属性名“驼峰式命名”即可.
④ 增加创建时间和更新时间
⑤ 类名别忘了改成MO的
5 实现 controller 接口方法: BO属性拷贝到MO中
保存BO信息2:BO属性拷贝到MO中
( 注意,这里回去把接口形参和方法形参都改成 saveFriendLinkBO )
至此,controller 中基本的设置都没啥问题了.
只不过,“ 保存到mongodb的操作 ”还没有写.
下节课讲解“mongodb”持久层操作!
代码
@Overridepublic GraceJSONResult saveOrUpdateFriendLink(@Valid SaveFriendLinkBO saveFriendLinkBO,BindingResult result) {//1 校验 result,判断 BindingResult 是否保存错误的验证信息if (result.hasErrors()) {Map<String, String> map = getErrors(result);return GraceJSONResult.errorMap(map);}// saveFriendLinkBO -> ***MO//2 BO属性拷贝到MO中FriendLinkMO saveFriendLinkMO = new FriendLinkMO();BeanUtils.copyProperties(saveFriendLinkBO, saveFriendLinkMO); //BO拷贝至MOsaveFriendLinkMO.setCreateTime(new Date()); //创建时间saveFriendLinkMO.setUpdateTime(new Date());//3 存入 MongoDB(具体下部分处理)friendLinkService.saveOrUpdateFriendLink(saveFriendLinkMO);return GraceJSONResult.ok();}
友情链接保存与更新:Service 层 MO 到 MongoDB(MO 信息来自前端传来的 BO)
(紧接上节)
上节课,把 前端表单 填入并提交 到 后端 的 BO 信息,存入了MO.
本节课补充进一步的存储操作:完成与持久层的交互,把 MO 信息存入mongodb
从 mapper 到 Repository
MongoDB中操作持久层可以使用JPA(???JPA???)的方式来操作,主要实现Repository即可,相关代码参考如下:
com.imooc.admin.repository.FriendLinkRepository.java
public interface FriendLinkRepository extends MongoRepository<FriendLinkMO, String> {}
创建Service接口,调用 MongoRepository 中的API
public interface FriendLinkService {/*** 新增或修改友情链接*/public void saveOrUpdateFriendLink(FriendLinkMO friendLinkMO);}
创建Service实现类,实现方法
admin的service.imp包下
@Servicepublic class FriendLinkServiceImpl implements FriendLinkService {@Autowiredprivate FriendLinkRepository friendLinkRepository;@Overridepublic void saveOrUpdateFriendLink(FriendLinkMO friendLinkMO) {friendLinkRepository.save(friendLinkMO);}}
Controller中注入service实现类,并调用
友情链接列表查询
查看路由
F12查看地址。蓝框部分可以直接作为路由的地址。
补充controller的 api 方法
回到 API,postMapping 就写刚才的路由
@PostMapping("getFriendLinkList")@ApiOperation(value = "查询友情链接列表", notes = "查询友情链接列表", httpMethod = "POST")public GraceJSONResult getFriendLinkList();
service层补充接口
友情链接也不会放很多,不需要进行分页
/*** 获得友情链接列表*/public List<FriendLinkMO> queryFriendLinkList();
controller层调用
@Overridepublic GraceJSONResult getFriendLinkList() {List<FriendLinkMO> list = friendLinkService.queryFriendLinkList();return GraceJSONResult.ok(list);}
友情链接删除(感觉不是很重要???)
(删除mongodb中的数据也非常简单,因为内置api已经继承了,直接调用接口)
开始讲列表中后面那个删除,这个删除才是真正的删除,上面那个只是“逻辑删除”(??逻辑删除??)
这个地方有两个删除:一个是上面的逻辑删除,一个是下面列表中的删除.
controller 层 api
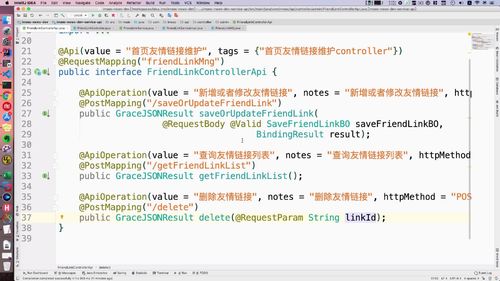
service接口调用删除
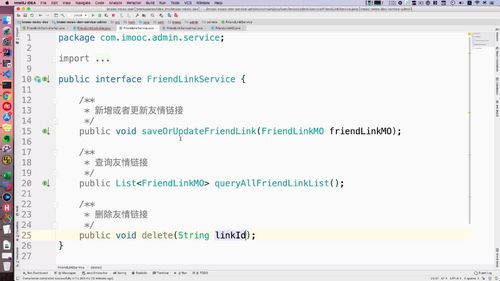
service实现
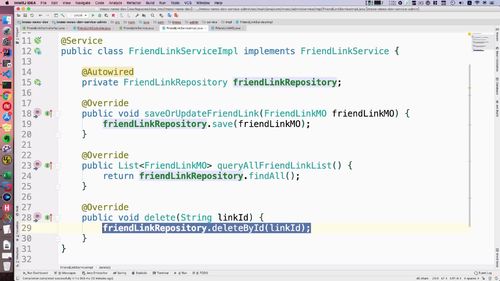
controller层实现接口并调用service方法
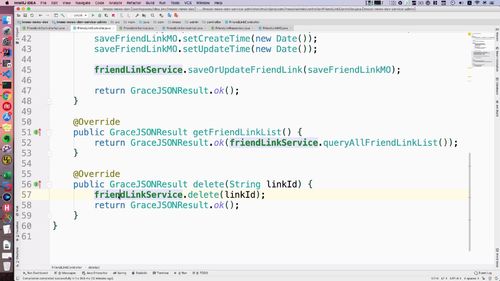
前几节的controller都往这个“拦截器”搞一搞(共三个)
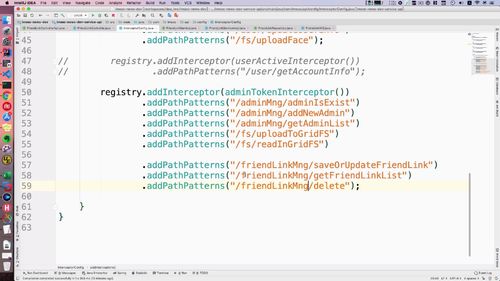
§ 5.5 文章分类管理
§ 5.6 用户管理
第六章 内容管理与AI自动审核
本章和“文章业务开发”相关,与文章表 article 交互.
—————————————-
首先 构建文章服务
作者中心,发布文章 ==> 富文本编辑器(没听过)
内容管理:文章发布后,文章列表的查询等操作.
审核:对于网站,审核是必不可少的一块,分为“自动/手动审核”。自动用阿里的,第一轮审核;手动的用admin审核,作为第二轮.
—————————————-
打开数据库看这个article表.
构建文章服务工程
本章涉及页面展示.
(1-1)用户中心内容管理:
(1-2)进入上图发头条页面
图中按键功能需要一一实现。
(2-1)admin管理中心有一个“内容审核”
包括自动审核/人工审核
(3-1)首页
中间白色区域就是文章列表,需要进行相应的展示.
构建“文章服务”工程
1 创建工程
2 参考之前工程,补充必要配置,并微调
<1>配置文件
(1)pom中补充service
(2)resource文件都需要,mapper不需要
yml文件端口号 8001.
其他不动.
(3)微调主yml文件
application name改掉,应为article
(4)微调logback文件
admin的位置都改成article
<2>项目结构
(1)启动类
(2)controller和mapper
(看左侧目录结构)这里是直接从article复制过来的,内容还没修改.
发头条
summernote 与 多文件上传需求
【发头条】发表一篇文章,把相应文章给你内容保存到数据库.
一、summernote(开源富文本编辑器)介绍
(这块内容偏向前端,不敢兴趣听一听就行了)
如上图,页面主区域用来编辑文章,使用到了fu文本编辑器,这个更加偏向于前端。老师选的是:summernote作为“富文本编辑器”。
这个是开源的,进入官网即可下载。官网上面getting started可以去看看文档。如下就是安装的文章(老师说了哪些需要哪些不用,做的时候回来听)。
看看老师提供的前端页面:最后两个导入的包就是summernote,官网没有汉化,所以图中老师引入了中文汉化包。
这里是样式初始化,这些在文档中都有.
富文本编辑器,如图中位置关联:
二、多文件上传功能 介绍
可以上传1张,可以上传多张。
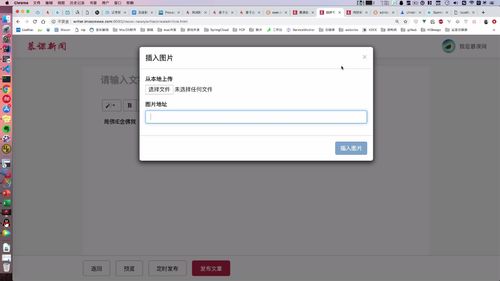
但是多图上传接口目前无法满足(老师演示了拖拽4张图片进入该页面,但是没成功)
==> 多图上传需要在前端构建成 “ list/数组 ”,然后发送到后端,随后进行相应的处理。
所以这里先看看前端的处理:如下,回调函数中的“图片上传”。这里在监听 “ files ”,这就是数组。这里把 files 的内容都 append 到 mutiForm 表单中去了。
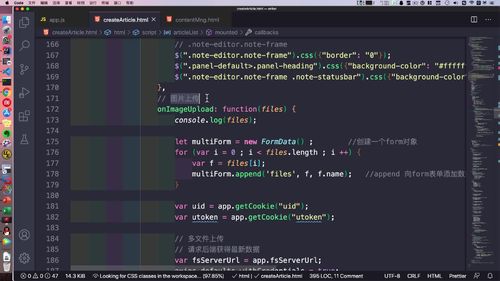
翻到如下位置代码,可以看到 后端的地址了,然后用post进行了多文件上传请求。
要是发送成功(状态码200),就能得到一个 imageList,然后调用summernote的接口拼接组装这些图片,这些图片会循环插入富文本编辑器中。
有错的话有也相应的处理,如213行,会提示上传失败。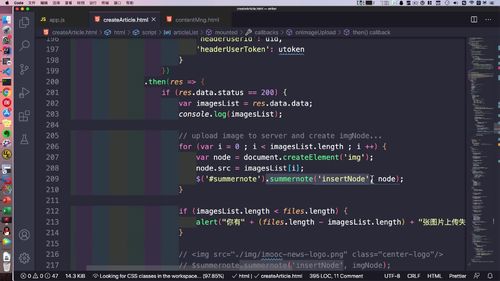
一、实现 富文本编辑器中 多文件上传
多图上传需要在前端构建成 “ list/数组 ”,然后发送到后端,随后进行相应的处理。
要是发送成功(状态码200),就能得到一个 imageList,然后调用summernote的接口拼接组装这些图片,这些图片会循环插入富文本编辑器中。
直接在上传头像 的方法了,我们直接扩展这个方法.
补充1:声明 list,存储多个图片的保存地址并返回给前端。
补充2:return ok 拿出来,把补充1中的 list 从这里返回给前端
补充3:中间不再抛出异常
我们现在是多文件扫描,所以遇到问题直接抛出不太好。
124/131/135/143行代码处,改成一个continue即可,不抛出异常了。
147行返回异常直接删掉。
补充4:搞到单个文件的 Path 后,直接放入补充补充 1 的 list
(其实图片放入之前应该做一个审核。就是之前 doAliImagerReview 这个方法,单文件也用过。
但是这里最后还是没写代码)
==>总结
主要还是在之前的基础上进行修改,“套了一层循环”。
@Override//0. 这里形参补充数组,形参名和前端一样是files.public GraceJSONResult uploadSomeFiles(String userId,MultipartFile[] files)throws Exception {// 【补充1】声明 list,存储多个图片的保存地址并返回给前端。List<String> imageUrlList = new ArrayList<>();//写一个循环,之前复制的“头像上传”的代码放到这个循环中去。//(之前的代码只针对1个文件,现在要处理的是一组文件,所以要每个都取出来这么处理一遍)if (files != null && files.length > 0) {for (MultipartFile file : files) {String path = "";if (file != null) {// 获得文件上传的名称String fileName = file.getOriginalFilename();// 判断文件名不能为空if (StringUtils.isNotBlank(fileName)) {String fileNameArr[] = fileName.split("\\.");// 获得后缀String suffix = fileNameArr[fileNameArr.length - 1];// 判断后缀符合我们的预定义规范if (!suffix.equalsIgnoreCase("png") &&!suffix.equalsIgnoreCase("jpg") &&!suffix.equalsIgnoreCase("jpeg")) {continue;}// 执行上传// path = uploaderService.uploadFdfs(file, suffix);path = uploaderService.uploadOSS(file, userId, suffix);//} else {continue;}} else {continue;}String finalPath = "";//【补充4】搞到单个文件的 Path 后,直接放入补充补充 1 的 listif (StringUtils.isNotBlank(path)) {// finalPath = fileResource.getHost() + path;finalPath = fileResource.getOssHost() + path;// FIXME: 放入到imagelist之前,需要对图片做一次审核imageUrlList.add(finalPath);} else {continue;}}}//【补充2】return ok 拿出来,把补充1中的 list 从这里返回给前端return GraceJSONResult.ok(imageUrlList);}
1 确定该业务所在的服务:不放在 article 服务中,而是放在 files 服务中.
2 编写“多文件上传”接口方法:在 “上传头像” 基础上改
之前已经写过一个 上传头像 的方法了,我们直接扩展这个方法.
老师这里把之前这个上传头像的注释重新写了一下,把 swagger2 的注解去掉了,这个业务和swagger2不好交互。
初步修改如下,下面那个准备修改成“多文件上传”。
上节课前端页面的接口已经看过了,复制过来;
加上注释;
这里形参补充数组,形参名和前端一样是files.
3 编写“多文件接口”实现方法
随后进入之前上传头像所在的实现类,把这个多文件上传的接口方法实现一下。方法内容直接复制上传单个头像的,然后进行微调即可。
4 补充拦截器
因为是针对用户的操作,所以拦截器是必要的。
在userToken这里去加。
[注意] 别忘了把之前注释的用户激活的这个拦截器打开(48行)。用户激活的前提下才能调用这个接口。
二、发布文章入库
业务介绍
进行本部分前,需要先 文章分类的维护(先完成文章分类部分).
本节课 针对当前页面进行数据的保存。
从页面上也能看出了,这里的内容是封装成表单后提交的,那么后端可以使用BO去接受数据,并验证,然后就可以入库了。
创建 包 和 api
打开api工程,创建包和api如下:article的这个,一个包和一个类.
创建 BO,接收前端表单
categoryId (文章领域)这个必须填!如果填入的值和后端不一致,需要专门处理。这一块我们放到 controller 中去验证。
articleType 是封面类型,可以是文件,可以是图片。
publishUserId不能为空,这是登陆状态。
/*** 用户发文的BO*/public class NewArticleBO {@NotBlank(message = "文章标题不能为空")@Length(max = 30, message = "文章标题长度不能超过30")private String title;@NotBlank(message = "文章内容不能为空")@Length(max = 9999, message = "文章内容长度不能超过10000")private String content;@NotNull(message = "请选择文章领域")private Integer categoryId;@NotNull(message = "请选择正确的文章封面类型")@Min(value = 1, message = "请选择正确的文章封面类型")@Max(value = 2, message = "请选择正确的文章封面类型")private Integer articleType;private String articleCover;@NotNull(message = "文章发布类型不正确")@Min(value = 0, message = "文章发布类型不正确")@Max(value = 1, message = "文章发布类型不正确")private Integer isAppoint;@JsonFormat(timezone = "GMT+8", pattern = "yyyy-MM-dd HH:mm:ss") // 前端日期字符串传到后端后,转换为Date类型private Date publishTime;@NotBlank(message = "用户未登录")private String publishUserId;...}
Controller 层的实现方法
@PostMapping("createArticle")@ApiOperation(value = "用户发文", notes = "用户发文", httpMethod = "POST")public GraceJSONResult createArticle(@RequestBody @Valid NewArticleBO newArticleBO,BindingResult result);
(1)BO校验:
“死部分”:这个和之前内容一样(没看清从哪个方法copy过来的);
“活部分”:articleType,封面类型.
如果是图片类型,articleCover必须有.(如下图)
逻辑如下(34行开始);纯文字的话,直接设置为空即可。
(2)分类:利用 categoryId
26行的这个,因为这个可能乱写,所以需要判断一下其合理性。
因为这里也需要查询数据库,为了提升性能,这里直接在 redis 中查询了。
为空就不许发表文章了。一般为空是系统个错误,所以这里报错选择相应的。
(话说,发表文章这里,List里是不是就1个对象?
==>这里list装的是“文章类别吧”?所以才需要循环判断,匹配到就停下 )
(3)65行sout测试与语句,把bo输出一下
(4)service的调用(干嘛的)下节课讲!
其中,下面这一段内容(判断文章类型的)可以提取出来:这个功能可能其他地方也会用
==>提取到baseController,作为作业
@RestControllerpublic class ArticleController extends BaseController implements ArticleControllerApi {final static Logger logger = LoggerFactory.getLogger(ArticleController.class);@Overridepublic GraceJSONResult createArticle(NewArticleBO newArticleBO, BindingResult result) {// 0. 判断BindingResult是否保存错误的验证信息,如果有,则直接returnif (result.hasErrors()) {Map<String, String> errorMap = getErrors(result);return GraceJSONResult.errorMap(errorMap);}// 1. BO校验:判断文章封面图类型,单图必填,纯文字设置为空,考虑后续扩展用 else if.if (newArticleBO.getArticleType() == ArticleCoverType.ONE_IMAGE.type) {if (StringUtils.isBlank(newArticleBO.getArticleCover())) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ARTICLE_COVER_NOT_EXIST_ERROR);}} else if (newArticleBO.getArticleType() == ArticleCoverType.WORDS.type) {newArticleBO.setArticleCover("");}// 2. 判断分类id是否存在String allCategoryJson = redis.get(REDIS_ALL_CATEGORY);//从redis中查List<Category> categoryList =JsonUtils.jsonToList(allCategoryJson, Category.class);Category category = null;for (Category c: categoryList) {if (c.getId() == newArticleBO.getCategoryId()) {category = c;break;}}if (category == null) {return GraceJSONResult.errorCustom(ResponseStatusEnum.ARTICLE_CATEGORY_NOT_EXIST_ERROR);}// 3. 测试输出System.out.println(newArticleBO.toString());return GraceJSONResult.ok();}}
使用 service 前,生成mapper
继续编写 AritcleController 的 createArticle 方法。
上节课完成了 BO验证 和 文章类别id 的验证。
接着上节课 (4)其他 补充后面service的部分,给它入库!
打开article这个,配置一下:
数据库名字搞上就行:32行
运行这个:
拷贝article的
xml(article模块resoures的mapper包)
pojo(放在model模块)
Mapper(article模块mapper包)
service开发
① 先去创建service包,再搞一个service.
名字和controller对应,形参也是BO,category就是上节课“文章类型判断”用的,记不起来可以看看上节课代码。
② 创建实现类的 包和类
路径和代码壳子如下. (sid干嘛的来着?忘了)
③ 完善实现类的代码:
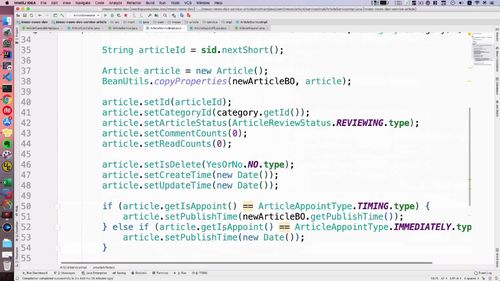
所以这个定时发布得用下这个来进行判断(这都是之前赋值进来的吧?)。
这块代码见下图54-58行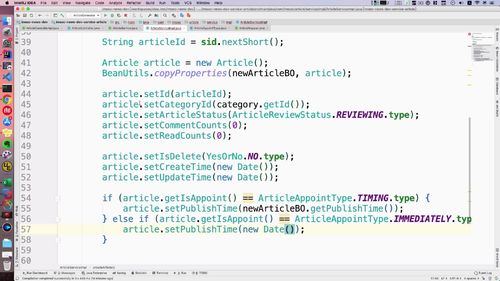
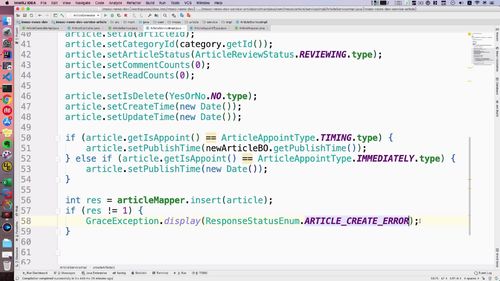
最终代码:controller中补充service逻辑
注意两个点:
ArticleService 需要注入;
temp 这个形参需要换个地方,话电脑判断逻辑外声明,不然这里传不进这个方法.
@Overridepublic GraceJSONResult createArticle(@Valid NewArticleBO newArticleBO,BindingResult result) {// 判断BindingResult是否保存错误的验证信息,如果有,则直接return...// 判断文章封面类型,单图必填,纯文字则设置为空...// 判断分类id是否存在...// System.out.println(newArticleBO.toString());//4. 文章入库//temp是第 2 步创建 id 时得到的 Category 对象的实例.articleService.createArticle(newArticleBO, temp);return GraceJSONResult.ok();}
三、预览文章:不经过后端,保存到 sessionStorage
(1)上节把发布文章大体KO了,这节搞搞 预览文章。
预览没有经过后端,有两种方式可以去做:
①保存到数据库(扩展性更好,视频中说的比较详细,有需要可以再听)
② 保存到sessionStorage。
我们选第二种.
(2)可以看看前端页面:
从 storage 获取.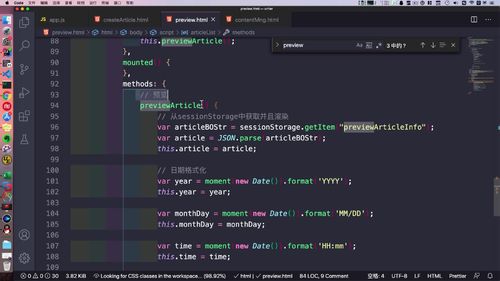
丢到 storage 中去.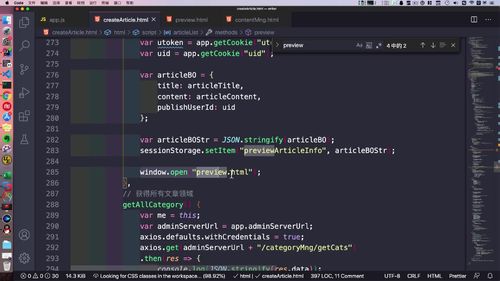
文章分类/领域
【用户端】 [发布文章时的分类选择] + [首页高频显示]
1 了解业务:文章分类功能
我们看看当前页面,最底下:【文章领域/分类】。我们现在需要 “显示出相应的文章分类,提供给用户进行选择”
这个功能不止再发文章最底下能看,在首页也能看到文章分类。
这个地方的显示特点:用户高频访问,但是内容基本不变 ==> 放入redis.
2 回顾 admin管理员模块中的 文章分类功能
§ 5.5 文章分类管理 中,写过两个方法,属于 admin 管理员模块的。
getCatList() 方法:查询分类列表,这个主要就是给 admin 对接。这里我们需要 “额外写一个接口,提供给用户端”==>用户 和 管理员这里解耦
@Api(value = "文章分类维护", tags = {"文章分类维护controller"})@RequestMapping("categoryMng")public interface CategoryMngControllerApi {@PostMapping("saveOrUpdateCategory")@ApiOperation(value = "新增或修改分类", notes = "新增或修改分类", httpMethod = "POST")public GraceJSONResult saveOrUpdateCategory(@RequestBody @Valid SaveCategoryBO newCategoryBO,BindingResult result);@PostMapping("getCatList")@ApiOperation(value = "查询分类列表", notes = "查询分类列表", httpMethod = "POST")public GraceJSONResult getCatList();}
3 (初步)单独编写 用户端发文章时 的 文章分类查询功能(与admin的方法实现解耦)
如下,补充API接口第三个方法。注意请求是GET类型。
@Api(value = "文章分类维护", tags = {"文章分类维护controller"})@RequestMapping("categoryMng")public interface CategoryMngControllerApi {@PostMapping("saveOrUpdateCategory")@ApiOperation(value = "新增或修改分类", notes = "新增或修改分类", httpMethod = "POST")public GraceJSONResult saveOrUpdateCategory(@RequestBody @Valid SaveCategoryBO newCategoryBO,BindingResult result);@PostMapping("getCatList")@ApiOperation(value = "查询分类列表", notes = "查询分类列表", httpMethod = "POST")public GraceJSONResult getCatList();// 新增@GetMapping("getCats")@ApiOperation(value = "用户端查询分类列表", notes = "用户端查询分类列表", httpMethod = "GET")public GraceJSONResult getCats();}
然后去 CategoryMngController 中实现这个接口:
如图中,getCatList(admin中用)和getCats(面向用户)代码几乎一样,为什么分开写(解耦)?区别在哪里?
代码角度看是一样的,但是只当前业务场景下一样;同时,其路由是不一样的,说明服务于不同的业务。
如下图:主要是这两个方法属于“两个不同的模块”,为了方便模块化,或者将来的扩展性,这里最好拆分出来!
(这块讲的其实挺详细的,有需要可以再过来听听)
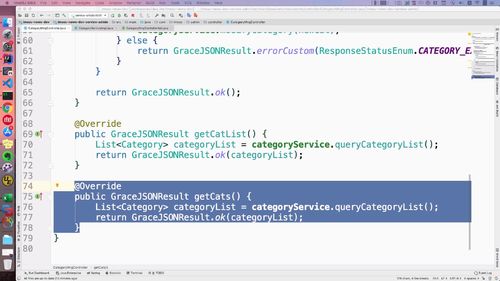
4 辨析:admin的获得分类列表和用户获得分类列表为啥是两个接口?
- 从代码角度来看,两个接口内容完全一样,但是为啥不合并呢?因为主要会从业务角度来看,两个接口是在不同的系统里了,虽然我们在同一个微服务,但是如果说系统再一次的拆分,把当前微服务拆了2个,那么这个接口就不好归类了,并且 admin 和用户端业务不同,考虑到未来的扩展性也会拆分,耦合度越大,那么当代码量越来越多的时候就越难维护。如果以后增加 is_delete 字段,那么两个业务功能的查询肯定都是不一样的,一个是全部,一个是只查未删除的。
- 如果是这个接口都是在同一个业务中调用的,比如都是在用户端调用,那么公用一个接口则是没有问题的。
- 此外,admin端查询直接查数据库更有效,而用户端并发更高直接查缓存更好。
- 还有一点就是由于前后端分离的部署,接口的改定必定影响前端,所以如果初期定义好解耦的接口,那么后续修改的时候只需要修改后端,而前端则不需要做改动,这样影响的面积更少。
5 (优化)用户首页访问时 文章分类 的显示
四、扩展
拓展如下:就是 看看redis有没有,没有就从数据库中拉出来存到redis中,存的时候转成json字符串。
@Overridepublic GraceJSONResult getCats() {// 先从redis中查询,如果有,则返回,如果为空,则查询数据库后先放缓存再返回。String allCategoryJson = redis.get(REDIS_ALL_CATEGORY);List<Category> categoryList = null;if (StringUtils.isBlank(allCategoryJson)) {// 如果redis没有数据,则从数据库中查询categoryList = categoryService.queryCategoryList();// 存入redisredis.set(REDIS_ALL_CATEGORY, JsonUtils.objectToJson(categoryList));} else {// 否则,redis有数据,则直接转换为list返回,保证减少数据库压力categoryList = JsonUtils.jsonToList(allCategoryJson, Category.class);}return GraceJSONResult.ok(categoryList);}
【admin 端】 维护数据缓存
要干什么:补充 admin 管理员对于文章分类的 “增加 和 删除” 功能
上节课做的就是 文章分类的展示,使用了redis,但只是查询。后面必然会涉及 “增加 和 删除”.
看看之前的作业:新增和修改都已经写好了。但是“redis”那块还没有这个功能!应该和这边对接一下。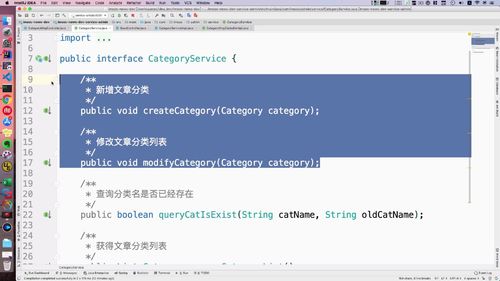
实现:创建分类方法 的代码
不建议如下做法:不要从redis读出来改了,直接删了,下次读取时再去mysql中加载.
1. 查询 redis 中的 categoryList
2. 转化 categoryList 为 list 类型
3. 在 categoryList 中 add 一个当前的 category
4. 再次转换 categoryList 为 json,并存入 redis 中
推荐做法:【直接把redis中的文章分类删掉(仅1行代码)】即可,那么当其他地方有需要的时候,会根据我们我上节课的逻辑:redis中没数据时,直接从数据库读取数据,并存入redis中,从而达到更新redis的效果。
@Transactional@Overridepublic void createCategory(Category category) {// 分类不会很多,所以id不需要自增;// 这个表的数据也不会多到几万甚至分表,数据都会集中在一起int result = categoryMapper.insert(category);if (result != 1) {GraceException.display(ResponseStatusEnum.SYSTEM_OPERATION_ERROR);}// 直接使用redis删除缓存即可// 用户端在查询的时候会直接查库,再把最新的数据放入到缓存中redis.del(REDIS_ALL_CATEGORY);}
实现:修改分类方法 的代码
@Transactional@Overridepublic void modifyCategory(Category category) {int result = categoryMapper.updateByPrimaryKey(category);if (result != 1) {GraceException.display(ResponseStatusEnum.SYSTEM_OPERATION_ERROR);}/*** 不建议如下做法:* 1. 查询redis中的categoryList* 2. 循环categoryList中拿到原来的老的数据* 3. 替换老的category为新的* 4. 再次转换categoryList为json,并存入redis中*/// 直接使用redis删除缓存即可,用户端在查询的时候会直接查库,再把最新的数据放入到缓存中redis.del(REDIS_ALL_CATEGORY);}
定时任务
构建定时任务
本节专门处理一下 定时发布 的问题。
在 springboot 中做定时的配置
article模块下创建 包 和 类,如下,名为“task”(路径看package即可)
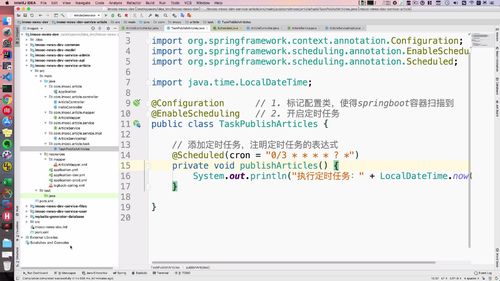
任务分为两类,一类“定时用”,另外一部分为“异步任务”.
开启定时功能,并把 任务类 需要放入springboot容器中用.
所以 configuration 注解是一定需要的.
通过 enableScheduling 注解开启定时任务。类中添加一个方法,@scheduled用于执行定时任务,这里需要配置一个表达式。测试这个方法,里卖弄sout一下即可。
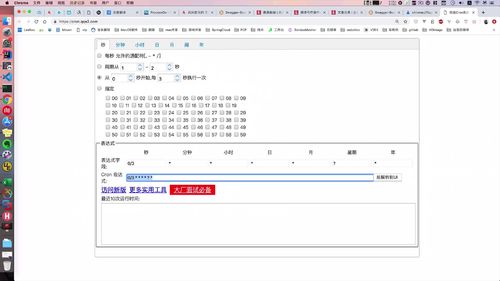
定时任务表达式
表达式可以使用生成器直接生成,地址如下:
cron这块生成的表达式就是我们需要的:
代码
@Configuration // 1. 标记配置类注入容器@EnableScheduling // 2. 开启定时任务public class TaskPublishArticle {@Autowiredprivate ArticleService articleService;//3. 添加定时任务@Scheduled(cron = "0/10 * * * * ?") // 4. 定时任务表达式private void publishArticle() {// System.out.println("执行定时任务: " + LocalDateTime.now());}}
定时发布文章
紧接上节:继续完善 “定时任务”.
目前数据库中只有 1 条数据,我们之前设置了定时时间:当前时间 > 发布时间 时,就可以发送了。主要得去把这个状态从 1 改成 0 .
写一下数据层的 sql
使用自定义 mapper 实现,自己写 sql 语句。不建议在逆向生成的xml中直接编写sql语句,可能有被覆盖的风险(没太懂…)所以我们这里自己创建xml,自己写!
如下:
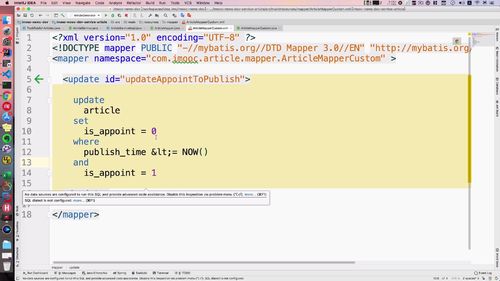
namespace这里的类得改一下。因为mapper类也不能用之前自定义生成的了,自己重新写一个mapper:
编写sql语句:(这块有些小细节,后面实操的时候再听听)(小于号得用转移符号<写)
然后就可以去service层调用了.
serviceAPI 创建方法
实现接口(ArticleServiceImpl)
自定义的mapper类得注入进来吧:(29行)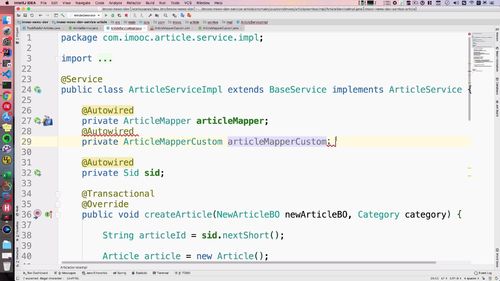
方法里调用mapper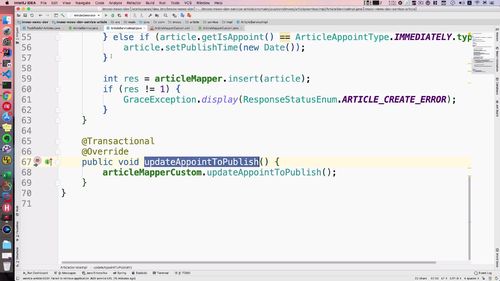
回到上节课最后的地方,补充调用 service 方法.
调用前注入service,如下25行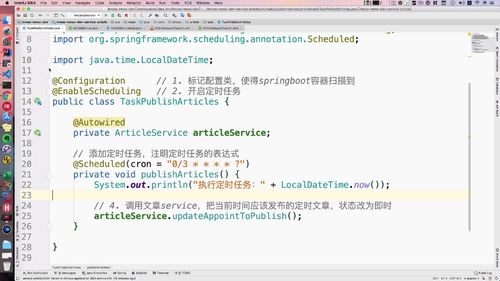
目前定时任务存在的问题
定时任务在不停的运行,并且扫描我们的数据库,一直在做全表扫描,数量多了的话,对性能很不好。
因此,后期会使用MQ进行优化!
(老师最后把定时任务的注解注释了,暂时用不到,就别让它运行了)
admin 的 内容管理模块.
文章列表显示
1 编写Controller接口——查询用户所有文章列表
需要接收什么参数可以去前端看看:339行开始拼接路由,这些都得加上.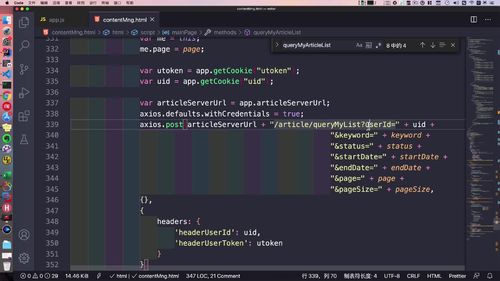
如下图中第二个方法:(注意所在接口)
(@RequestParam干啥的来着?)
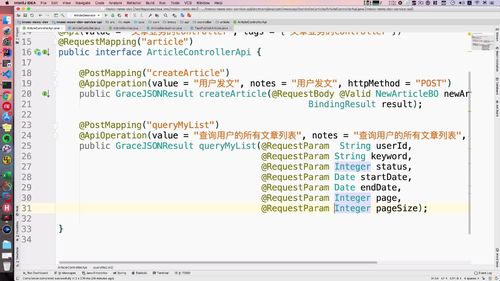
2 构建所需的service,并实现
(1)接口
所在位置与方法如下图(25行这个方法)
形参和接口的保持一致
(2)实现
仍然是一个拼接,进行条件设置.
调用 orderBy 方法排一下序:根据时间排序(使用创建时间).
先写好如下部分:
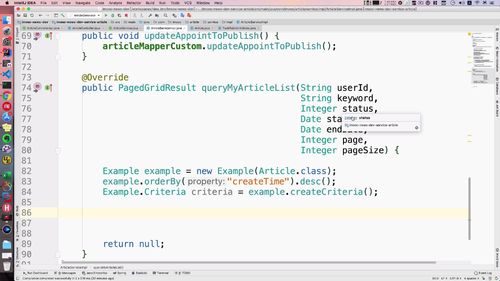
————————————————————-
继续完善.。
userId 通过 andEqualTo(这个方法干嘛的?) 进行外键匹配(外键???).
keyword 调用模糊查询方法 andLike,左右加上 %。
状态也判断一下,看他是不是有效。如果无效,直接查询所有(???),也是是由 andEqualTo
————————-
这里看一下审核状态:这里这个 1 2状态,对于用户来说,都是审核中,但是对于后端来说,还是有区别的。
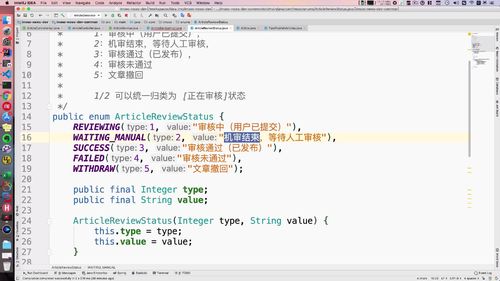
前端这里,你看:已经定义好了一个12的状态(99行),就是1和2拼接起来的,反馈给用户: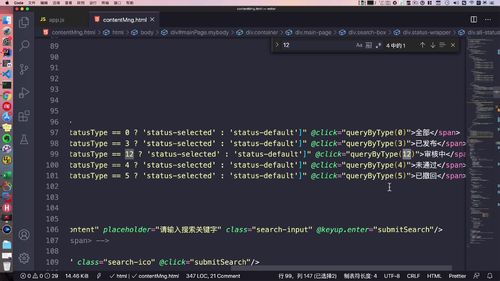
所以这里额外判断:这里的话,如果发现前端来的是1 2,那么这里判断 1也行,2也行。orEqualTo就是这么个意思!保证后端分开对待.
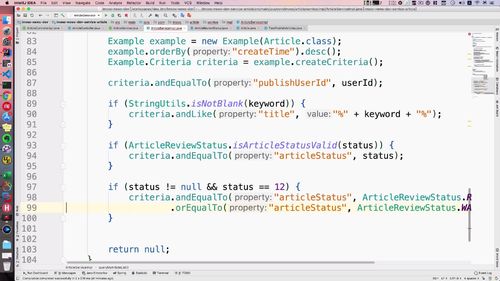
——————————————————-
对于表来说,还有一个逻辑删除:用户的话可以把相应的文章删除,用户删了那对他就不可见了。对于管理员还是能看到相关的数据的。(这是个什么狗把业务?人家都删了,你还给人家整出来?)
——————————-
开始和结束的日期,也判断一下,如果为空,调用andG/L…T..orE..T方法创建符合要求的日期.
———————-
最后就可以执行分页了.
———————————————————
然后根据以上封装的数据做一个查询.
返回一个 list 和 page(为啥是这俩,忘了).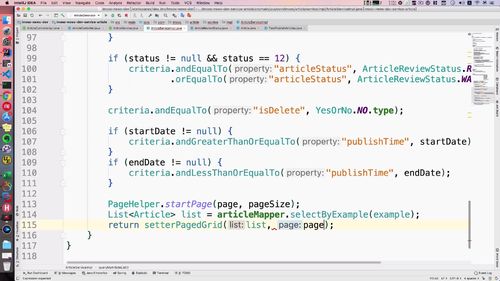
3 实现Controller
(1)基本判断
page 和 pageSize 需要判断一下,可能为空(why?)。
为空时初始化:第一页开始,每页查询10条
user的判断:不可为空
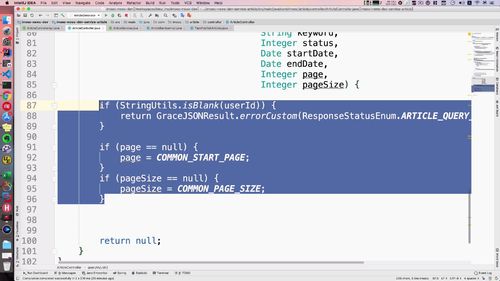
(2)发起查询,调用service
调用service,返回的结果抛给前端处理.
阿里AI文本检测 简介
目前,在当前用户中心实现了【内容管理 的 列表查询.】
【发头条的功能也做好了】.
==> 文章入库后,审核就要介入了!分为“机身”和“人工审核”
(1)
之前图片审核也用的这个吧?
(2)
如下图:左侧 SDK 参考的 JAVA SDK 的文本反垃圾.
包含了文档的介绍,就按这个做就行.
(3)密钥我们是有的,需要装java依赖(这些以来我们之前都配置过,所以不用再管了)
(4)api说明
textScanRequest
示例代码可以自己拷贝测试
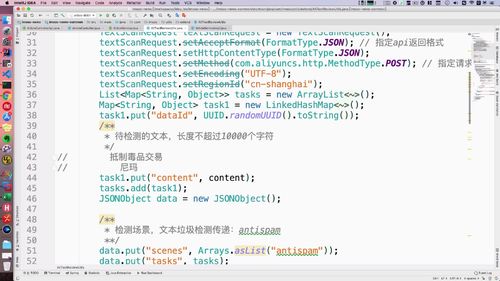
(5)熟悉api的原理(这块不太熟悉,复习时再了解一下)
老师提供了这个类:如下选中的,这个就是做文章检测的
构建身份.
构建request请求.
构建数据,list中多个map.
(文本不超过1000,超过的话得分段检查)
后面就是检查的过程了.
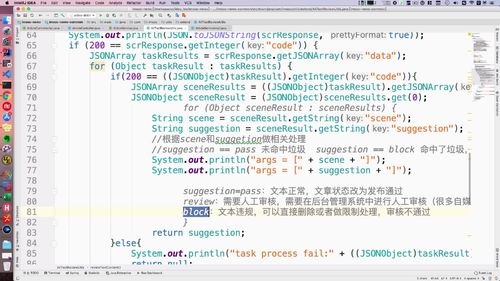
最重要的是这里的 suggestion,这里有三种情况:(79-81行)
review的话,就需要人工审核了.
==>要使用这个的话,直接复制到controller或者service,都是可以的.
实现阿里AI自动审核文章:在createArticle方法最后,【应该发起调用,请求检测文章】
上节课介绍了阿里的这个自动审核AI.
本节课主要就把这个功能集成到项目中.
1 我们要干什么?——自动审核代码
在createArticle方法最后,【应该发起调用,请求检测文章】
2 注入阿里的AI审核方法,并调用
42,注入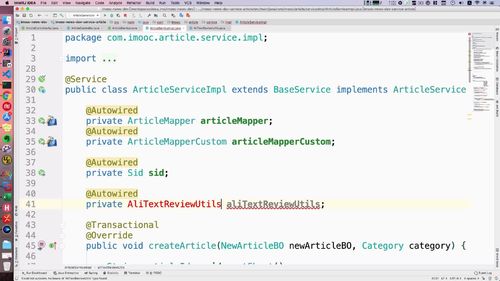
77,调用,拿到结果。
判断结果类型,每一类型对应的操作注释如图:(79-88)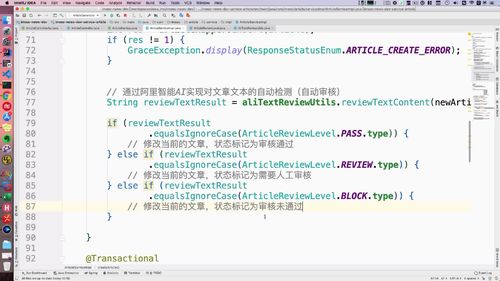
显然,这里需要修改状态的方法.
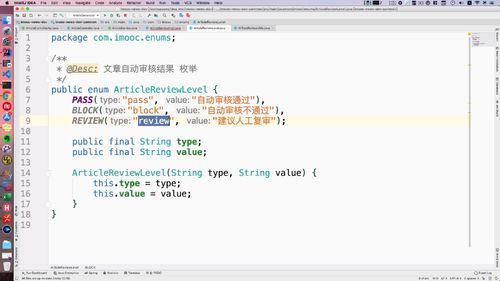
(对应的枚举类已经复制进项目了)
3 补充修改状态的service方法,完善审核代码
新增service接口方法. 36行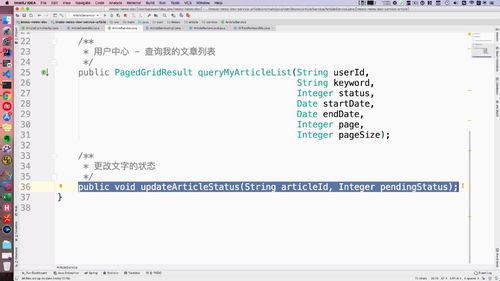
返回实现类,实现该方法:还是需要 example。(93行开始)
(其实这里为啥要new一个article,我没懂)
(该方法需要@Transcational注解,图中忘了写)
@Autowiredprivate AliTextReviewUtils aliTextReviewUtils;public void createArticle(NewArticleBO newArticleBO, Category category) {/*** FIXME: 只测试正常的,非正常词汇课后大家自己去测试*/// 阿里智能AI进行文本自动检测String reviewResult = aliTextReviewUtils.reviewTextContent(newArticleBO.getTitle() + newArticleBO.getContent());// 写死,需要人工审核// String reviewResult = ArticleReviewLevel.REVIEW.type;logger.info("检测结果:" + reviewResult);if (ArticleReviewLevel.PASS.type.equalsIgnoreCase(reviewResult)) {logger.info("审核通过");// 修改文章状态为审核通过this.updateArticleStatus(newArticleId, ArticleReviewStatus.SUCCESS.type);} else if (ArticleReviewLevel.REVIEW.type.equalsIgnoreCase(reviewResult)) {logger.info("需要人工复审");// 修改文章状态为需要人工复审this.updateArticleStatus(newArticleId, ArticleReviewStatus.WAITING_MANUAL.type);} else if (ArticleReviewLevel.BLOCK.type.equalsIgnoreCase(reviewResult)) {logger.info("审核不通过");// 修改文章状态为审核不通过this.updateArticleStatus(newArticleId, ArticleReviewStatus.FAILED.type);}}
4 完善审核代码:
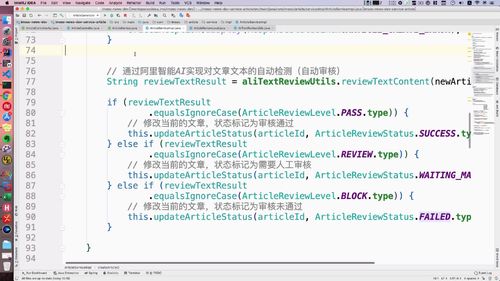
补充:(75行)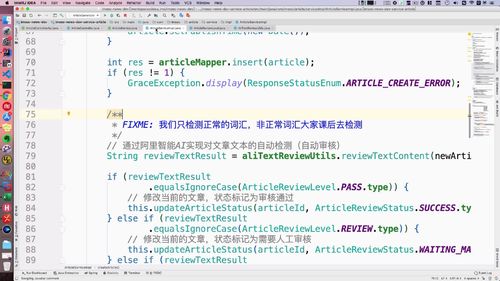
5 测试(9:00)
(1)
自动审核通过了,直接发布了
可以去阿里云后台管理看看:
(2)
代码这写死,强行不通过,再测试: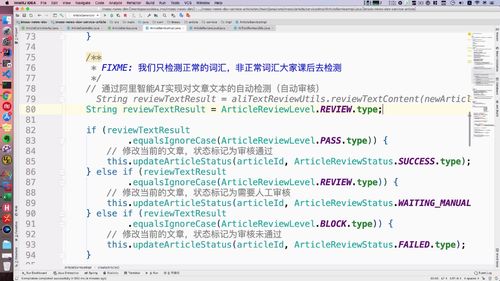
==>这里设置成人工审核,方便我们后面课程操作.
内容审核
admin 文章管理列表
我们之前实现的是“用户中心”的列表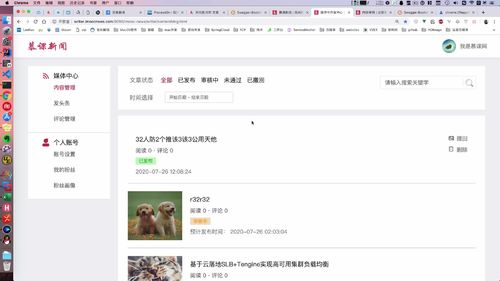
为了能够完成人工审核,还需要实现“admin中心”的文章管理列表.
这块是作业,自己做一下.
加载的页面基本一样。
(时间选择,关键字模糊查询没有的)
右侧还有审核通过,审核失败的按钮 ==> 这个后面搞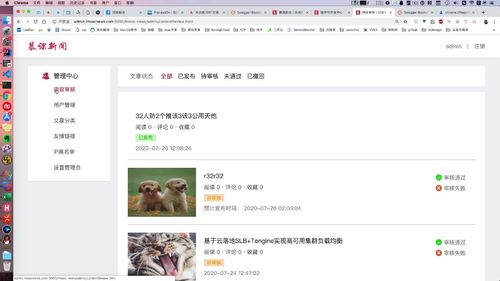
35行开始,老师已经写好,可参考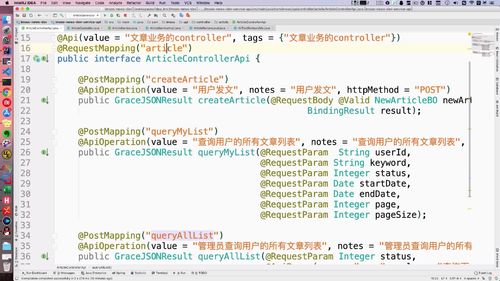
人工审核
审核通过/失败 是一个接口。
审核是在前端进行的,管理员审核后点击 通过/不通过,后端接收到前端的指令,然后 文章状态 进行相应的更新即可.
1 编写controller接口方法
接受两个参数:文章id,代表通过与否的数值(该形参与前端对应).
post请求.
(45行)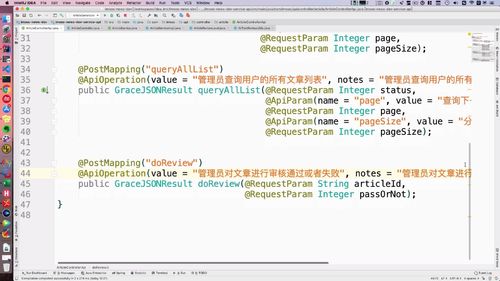
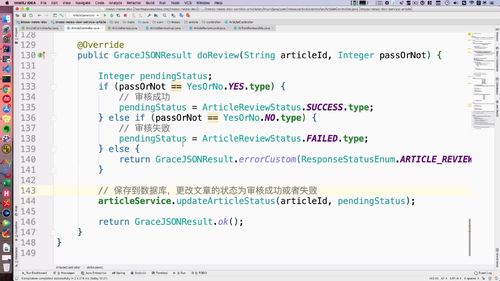
2 实现
判断这个passOrNot,只有1和0,其他都算非法.
更改状态方法之前已经写过了,直接调用.
撤回&删除文章作业
“用户中心” 的撤销和删除,审核中的不能操作。
如右侧.
判断逻辑是在前端实现的.
这次对应的就是2个接口了.
(继续写哪些部分视频中有提及,源码老师已经提供)
第七章 开发首页与作家页
业务介绍
本章节开始,进行 “门户端” 的开发.
本章节开发核心:【首页】【作家个人展示页】
1 首页
(1)首页空白这里应该是有文章例表的.
(2)上面的分类点进去应该是有文章的.
(3)右侧的搜索应该是可用的.
前期开发时,都是在数据库文章。后续课程升级为 ES 来进行海量查询.
底部应该应该随着当前页的滚动来加载.
(4)右侧友情链接,用mongoDB,这里有些是写死的
(5)最新热文也显示几条.
(6)点击头像应该进入作家首页
2 作家个人展示页
(1)可以对所有人开放.
(2)可以点击关注和取消关注.
(3)文章列表的展示也需要.
(4)粉丝列表和粉丝画像.
(5)结合后面的查询统计操作,搞一个数据可视化.
后期还是会使用ES来优化.
首页
首页功能1:友情链接
使用mogodb起到了一个优化的作用,不用去查数据库了.
友情链接:根据 MongoDB 字段查询 友情链接
1 业务梳理
mogodb中已经有一个友情链接的数据了:§ 5.4 MongoDB 处理 友情链接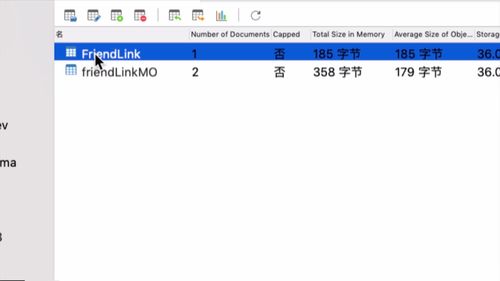
这个是在 admin 中心友情链接部分做的 crud 操作.
(老师这里又添加了几条)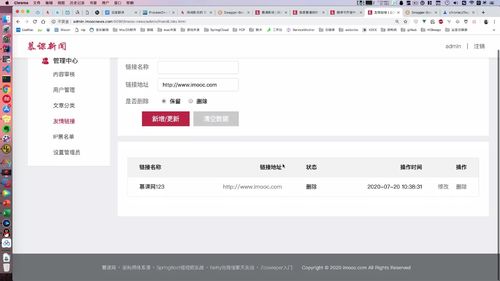
注意:用户端只能查询出状态为“保留”的。
(状态是删除的为什么还在啊?)
如下,此时前端应该仅展示3条数据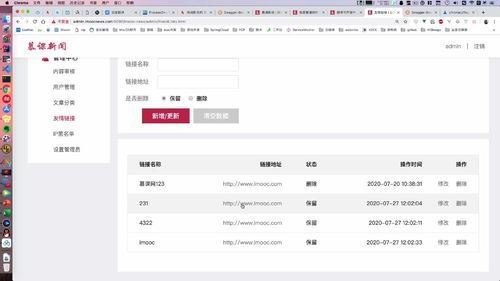
2 Mapper 层交互方法:根据 MO 的某一个字段进行查询,我们选择isDelete
friendlink 相关的我们写在了 admin 模块.
找到如下类,之前写过的.(前面章节有说过要在这里补充吗??)
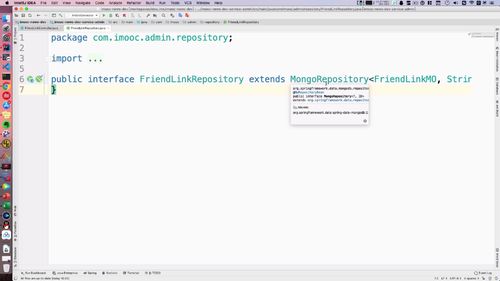
现在要 “根据其中的一个字段进行查询”:根据 MO 的某一个字段进行查询,我们选择isDelete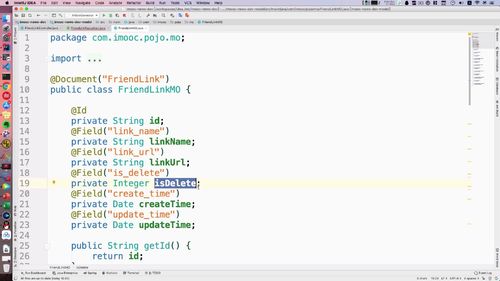
(每块没太懂)这里这个方式和 JPA(这啥啊?)的方式一样,mogodb数据层交互有一些自定义封装规则.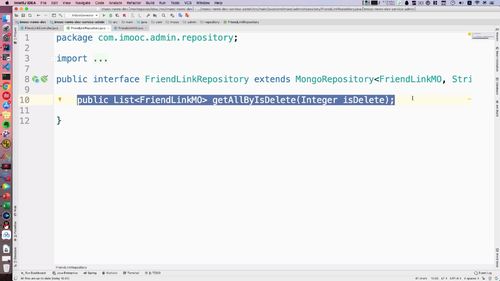
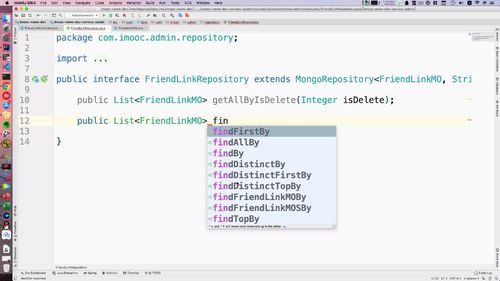
如下,这里方法还不少呢.(这里演示了一下,其实这里封装了很多方法供我们去查询)
3 Service 层交互
接口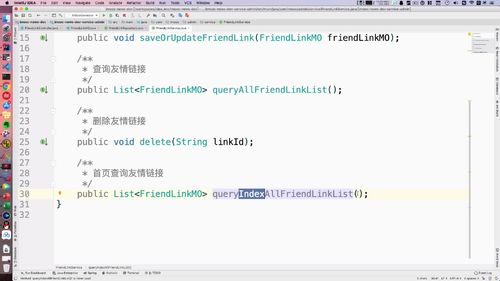
实现: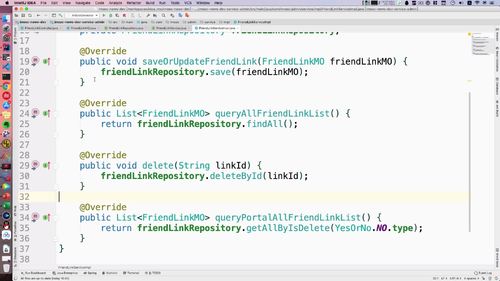
4 Controller 编写
()接口
和之前写的查询友情链接列表合并成 1 个友情链接了.
这里改成了get方法.
39行.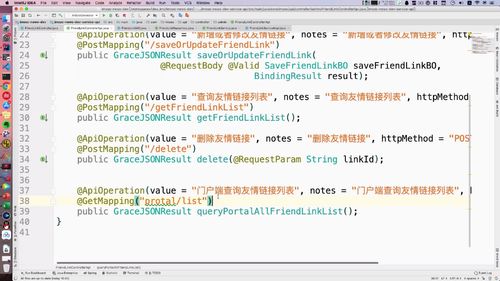
()实现
查询的结果抛给前端.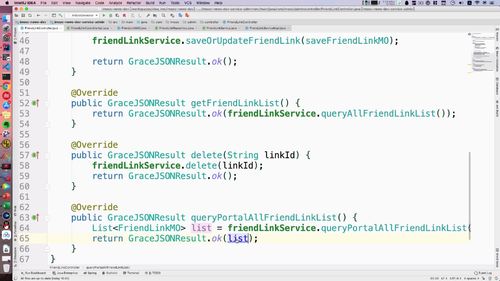
首页文章列表 1:显示文章列表
普通查询之外,还要携带一些相应的参数:
首先是文章分类的 id,如果有,去对应类别查找;如果没有,那就查询所有.
此外,右上角的这里,输入关键字进行搜索,支持“滚动分页.”.
代码写在article文章服务.
1 创建 Controller 层 api:新建 门户端 controller 实现解耦,对首页文章列表进行查询
我们重新创建一个api,这样就能解耦了.
@Api(value = "门户站点文章业务controller", tags = {"门户站点文章业务controller"})@RequestMapping("portal/article")public interface ArticlePortalControllerApi {@GetMapping("list")@ApiOperation(value = "首页查询文章列表", notes = "首页查询文章列表", httpMethod = "GET")public GraceJSONResult list(@RequestParam String keyword,@RequestParam Integer category,@RequestParam Integer page,@RequestParam Integer pageSize);}
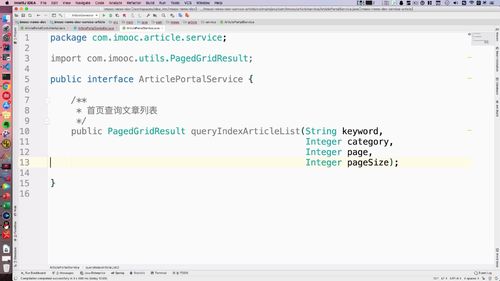
2 实现 Service 层:专门针对门户端创建新的service
这里的service也需要重新创建,这里的 service 同时涉及“用户中心”“admin中心”的业务.
所以我们专门针对门户端创建新的service.
实现1:添加 隐性查询条件
需要根据发布时间进行排序。增加几个“文章自带隐性查询对象”(去 Article.java 的实体类中找)
实现2:添加 keyword 和 category 查询条件
keyword 关键词吗,有的话模糊查询.
category 分类,没的话查询所有.
实现3:分页查询,并返回
@Servicepublic class ArticlePortalServiceImpl extends BaseService implements ArticlePortalService {@Autowiredprivate ArticleMapper articleMapper;@Overridepublic PagedGridResult queryIndexArticleList(String keyword, Integer category, Integer page, Integer pageSize) {Example articleExample = new Example(Article.class);articleExample.orderBy("publishTime").desc();/*** 自带隐性查询条件:* isPoint为即时发布,表示文章已经直接发布,或者定时任务到点发布* isDelete为未删除,表示文章不能展示已经被删除的* status为审核通过,表示文章经过机审/人审通过*/Example.Criteria criteria = articleExample.createCriteria();criteria.andEqualTo("isAppoint", YesOrNo.NO.type);criteria.andEqualTo("isDelete", YesOrNo.NO.type);criteria.andEqualTo("articleStatus", ArticleReviewStatus.SUCCESS.type);// category 为空则查询全部,不指定分类// keyword 为空则查询全部if (StringUtils.isNotBlank(keyword)) {criteria.andLike("title", "%" + keyword + "%");}if (category != null) {criteria.andEqualTo("categoryId", category);}/*** page: 第几页* pageSize: 每页显示条数*/PageHelper.startPage(page, pageSize);List<Article> list = articleMapper.selectByExample(articleExample);return setterPagedGrid(list, page);}}
3 调用Service,实现controller.
同样。重新写一个实现类.
@RestControllerpublic class ArticlePortalController extends BaseController implements ArticlePortalControllerApi {final static Logger logger = LoggerFactory.getLogger(ArticlePortalController.class);@Autowiredprivate ArticlePortalService articlePortalService;@Overridepublic GraceJSONResult list(String keyword, Integer category, Integer page, Integer pageSize) {if (page == null) {page = COMMON_START_PAGE;}if (pageSize == null) {pageSize = COMMON_PAGE_SIZE;}//调用service层查询PagedGridResult gridResult = articlePortalService.queryIndexArticleList(keyword, category, page, pageSize);return GraceJSONResult.ok(gridResult);}}
首页文章列表 2:文章列表显示发布者需求
业务分析
有一个小细节:文章的发布者现在都显示的是用户id,而不是“昵称”.
另外,发布者 头像 都是一样的,都是写死的.
数据库中,发布者数据里有publish_user_id。如果要显示 头像 和 昵称 的话,一般就是去做 “多表关联”的查询。
上节课只是做了单表数据的查询。其实访问量特别大的话,对于表查询,就尽量减少多表查询,一般限制在3张表以下。
一种做法:我们通过文章查到 发布者id,用这个 id 去查 user表,查到后,我们在 controller 或者 service 曾进行 list合并,把相应的用户信息匹配到 文章列表 中去,让其作为一个对象放入文章列表中,然后再到前端进行对应的渲染。
另一个角度来讲,我们现在有两个系统——user 服务 和 article 服务。我们后期会把这些做成微服务(???)。对于微服务,不同的系统存在边界,各自职责不同,只能查询自己对应的表。从这一角度说,也不应该进行 多表查询!
==> 我们应该发起一个新的远程调用,【在文章服务中请求用户服务】,把从用户服务得到的信息拼接到下图的 PagedGridResult 中去,这样再由前端进行渲染。
因此,最后我们确定方案:【单表查询 + 拼接】
一、从 文章列表 得到 id 列表:使用 set 集合去重
list 可以从下面这个 gridResult 里面拿出来。重新查询这个List,得到所有用户id。
这个时候就有一个问题:首页文章中每一个文章的 id 都要查吗?
No,可能有一个人发布的,因此我们这里要做去重!==> 使用 set 集合!从而去重.
完成以上步骤的代码如下:我们把这个 idSet 发到 user 服务中去进行查询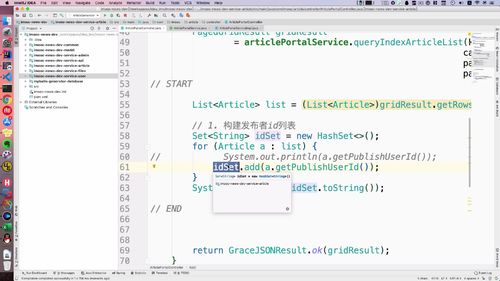
...// START/*** FIXME:* 并发查询的时候要减少多表关联查询,尤其首页的文章列表。* 其次,微服务有边界,不同系统各自需要查询各自的表数据* 在这里采用单表查询文章以及用户,然后再业务层(controller或service)拼接,* 而且,文章服务和用户服务是分开的,所以持久层的查询也是在不同的系统进行调用的。* 对于用户来说是无感知的,这也是比较好的一种方式。* 此外,后续结合elasticsearch扩展也是通过业务层拼接方式来做。*/List<Article> list = (List<Article>)gridResult.getRows();// 1. 构建用户id列表Set<String> idSet = new HashSet<>();for (Article a : list) {// System.out.println(a.getPublishUserId());idSet.add(a.getPublishUserId());}// 2. 发起restTemplate请求查询用户列表// 3. 重组文章列表// END...
二-1、远程调用:完善 artcile 远程调用的 user 服务中的方法
紧接上节!我们已经得到了 id列表,用这个远程调用获取 user 服务的用户信息,拿回来后重组文章列表,从而显示文 用户头像 和 昵称.
打开用户userController,里面定义一个查询接口,Get 请求方法,形参是userIds,现在是字符串类型,后面要类型转换。
(1)先特判 id,是否为空.
查询业务中,构建基本信息列表,我们之前构建过:当前类翻到上面有个AppUser 和对应的 VO,我们就用这个。
(2)getUser 我们以前封装过,是先查redis的.
拿到 userVO 放入需要重组的 List 中去。
(3)循环中的1 2 这两步之前的方法中也有,和之前重复了。我们现在把它抽象出来。
(之前那里就不改了,就在当前类)
(4)最终如下:把这个list返回去.
至此,user模块的处理的差不多了.
@Overridepublic GraceJSONResult queryByIds(String userIds) {//1. 判空if (StringUtils.isBlank(userIds)) {return GraceJSONResult.errorCustom(ResponseStatusEnum.USER_NOT_EXIST_ERROR);}List<AppUserVO> publisherList = new ArrayList<>();List<String> userIdList = JsonUtils.jsonToList(userIds, String.class);for (String uid : userIdList) {// 2. 获得用户基本信息:getBasicUserInfo 内封装查询 redis 的 getUser 方法AppUserVO userVO = getBasicUserInfo(uid);// 添加到发布者listpublisherList.add(userVO);}//3. 返回return GraceJSONResult.ok(publisherList);}/*** 获得用户基本信息* @return*/private AppUserVO getBasicUserInfo(String userId) {// 1. 根据userId查询用户的信息AppUser user = getUser(userId);// 2. 返回用户信息AppUserVO userVO = new AppUserVO();BeanUtils.copyProperties(user, userVO);return userVO;}
二-2、远程调用:回到文章服务,发起 restTemplate 请求查询用户列表
发起远程调用需要restTemplate,注入:33行
补充之前的方法(首页文章列表):(???这个地址真的不太清楚哪里规定的….)
restTemplate需要地址,也需要设置返回对象。返回ResponseEntity。
然后getBody拿到对象。如果状态=200,说明收到了,我们拿到数据,转成json字符串,再把 json 转成 list 对象。(??为什么非得转成json)
————————
下节课进行两个List的拼接:
@Autowiredprivate RestTemplate restTemplate;...// 2. 发起restTemplate请求查询用户列表String userServerUrlExecute= "http://user.imoocnews.com:8003/user/queryByIds?userIds=" + JsonUtils.objectToJson(idSet);ResponseEntity<GraceJSONResult> responseEntity= restTemplate.getForEntity(userServerUrlExecute, GraceJSONResult.class);GraceJSONResult bodyResult = responseEntity.getBody();List<AppUserVO> publisherList = null;if (bodyResult.getStatus() == 200) {String userJson = JsonUtils.objectToJson(bodyResult.getData());publisherList = JsonUtils.jsonToList(userJson, AppUserVO.class);}for (AppUserVO u : publisherList) {System.out.println(u.toString());}...
三、List 拼接
进阶上节,已经完成了 远程调用,现在需要拼接两个list了(文章 和 用户)
一个 publishList(用户的),一个 articleList.
构建新的 List
为了拼接,我们需要 “构建1个新的对象,能存入这两个List的信息”.
老师预先已经构建了一个新的VO:除了这个AppUserVO,其他属性和ArticleVo基本都一样!
代码
...// 3. 重组文章列表List<IndexArticleVO> indexArticleList = new ArrayList<>();for (Article a : list) {IndexArticleVO indexArticleVO = new IndexArticleVO();BeanUtils.copyProperties(a, indexArticleVO);// 3.1 从userList中获得publisher基本信息AppUserVO publisher = getUserIfEqualPublisher(a.getPublishUserId(), publisherList);// 3.2 把文章放入新的文章list中indexArticleVO.setPublisherVO(publisher);indexArticleList.add(indexArticleVO);}gridResult.setRows(indexArticleList);...
查询热闻
1 业务介绍
前面几节课完善了“文章列表”,
本节课搞搞右边这个最新热闻:展示文章列表最新发布的5篇文章!
直接查数据库,这块的话,后面会进行优化,“根据文章的阅读数和评论数做排名,根据排名从高到低显示前五名”。(体验迭代的过程)
2 编写Controller接口
get请求,注意接口啥的别写错了.
无需形参,因为没有分页,也没有搜索条件.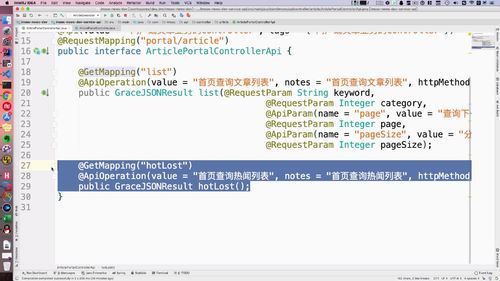
3 编写Service接口并实现
(1)接口.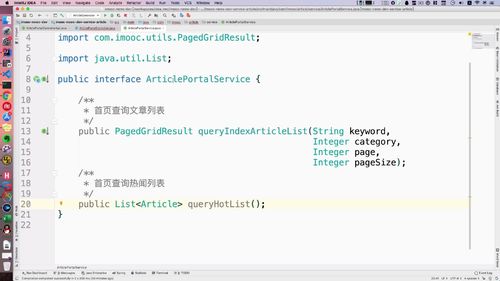
(2)实现
① 实现前注意一下,这里做查询也要满足隐性条件(之前首页文章列表方法中有提到),如下: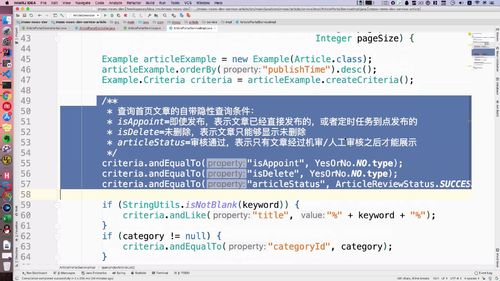
这块内容抽出来,单独作为一个方法:
(前面的抽取的那部分也不删除了,留着作为参考)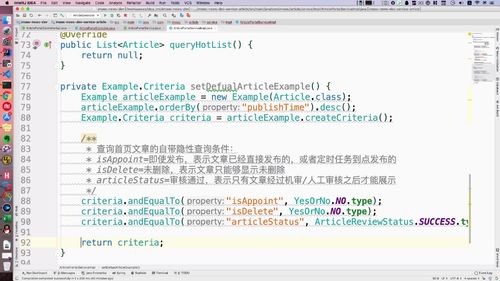
② 调用这个隐形条件的方法.
拿到这个 Criteria 就可以进行查询了.
(73行这个方法)
(为啥还分页???PageHelper杂合这个List作用的???)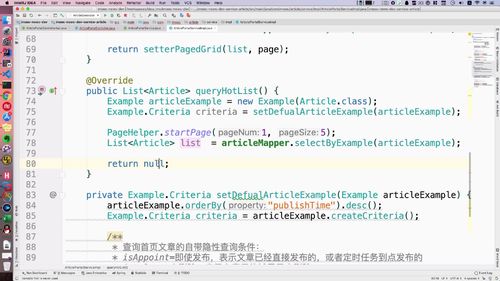
4 实现Controller接口
5 测试(6:00)
(1)排错
报错:前端这有个404的hostList ==>前后端url可能不匹配.
老师这里写错了:list写成了lost,然后这里方法名,后面调用时候的方法名都得改成 hotList 而非 hotLost.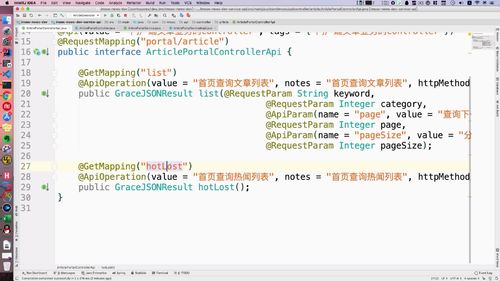
(2)再测试
5条数据.
等着后期更新,现在显示的5个和左边这个列表一样的.
基本信息展示&历史文章列表【作者主页】(作业)
- 用户基本信息采用之前写过的接口,直接调动即可。
- 作家页面和首页的文章列表接口可以采用共用的方式,只需要增加用户id判断即可。但是往往我们会采用解耦的方式来做,因为门户端的3个页面,在未来如果考虑可扩展的话,那么首页,作家页以及详情页都会独立处理啊拆出来作为3个不同的网站,由3个不同的二级域名来部署,所以对于接口来说,最好事先解耦。所以我们在这里采用的方式为解耦。大家也可以共用,两种方式都可以尝试做一下,体验一下不同的区别。各有各的好处。
- 注意:发起调用获得用户列表的方法可以抽出来公用
1 业务介绍
作家个人页面:
首页这里点击头像就可以进入;点击文章的作者头像也能跳转.
讲一下个人页面:包含用户头像,用户昵称。
调用了我们之前写过的接口:获取用户基本信息.
UserController 中的 getUserInfo 方法.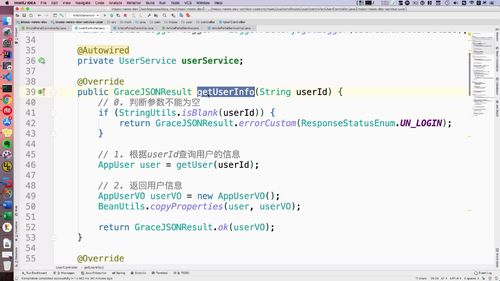
前端也可以去找接口,如下图299行: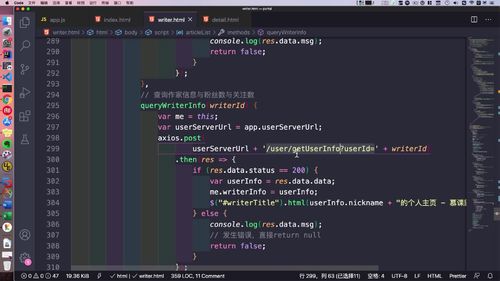
当然了,关注数和粉丝数也是有的。讲完关于以后,在来讲这部分如何进行显示。
里面还有用户历史文章数据,右侧有历史佳文。这两块业务和首页的一样的,首页是查询所有,作家页面只查询自己的,所以需要传入作家id。这里作为作业自己去做。
2 老师做的修改
当然,虽然和首页差不多,但是还是解耦好一点,前端。当然,这么写的话,代码会冗余.
作家页的接口老师已经写好了,是解耦的:
如下,detail index writer 如果要分开考虑扩展性的话,就都会独立出来,使用二级域名单独发布,所以需要解耦.
代码老师已经写好了:
对应的service需要额外加上用户id:
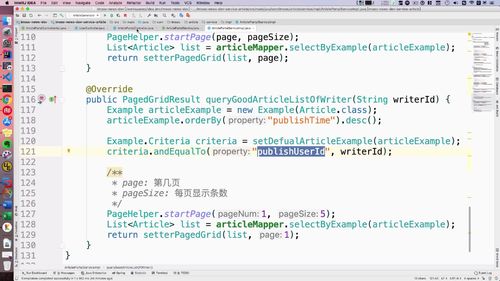
3 老师修改了之前的代码:前几节首页列表拼接list的操作抽离出来了!之前写的都注释掉了。
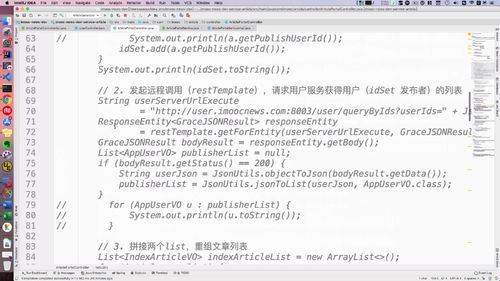
只需要调用抽离出来的:rebuildArticleGrid即可:
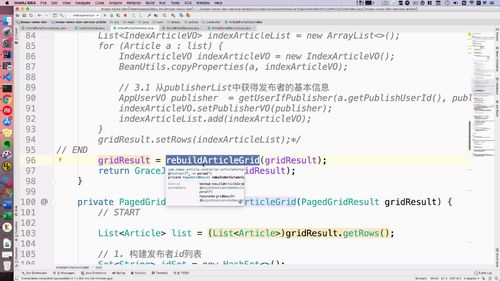
抽离的方法如下:基本就是前几节课写的代码.
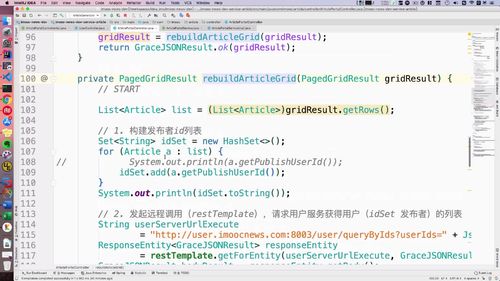
粉丝关注
业务介绍:关注、取关、redis 单线程计数
上节课的作业做的时候需要注意一个问题:文章的“阅读数”,这块后面都会讲的,暂时不用管。
1 业务介绍
现在来搞 粉丝关注.
如下图,昵称下面有个“关注我”,点击关注以后,右侧这里的粉丝数就会累加。这个人关注了别人,这里的关注数也会显示。
2 redis进行粉丝数量统计
粉丝数这块呢有两种做法.
做法一是使用数据库,使用 count 函数查询数量,但是如果访问的多的话,数据的压力会很大,我们不选择这种方式。
我们使用redis,把它当作数据库来使用。因为它是单线程的,安全,累加或者累减都是可以的。
(这里讲解了一些,但是还不能深刻理解使用redis的理由 ==> redis这么好用,都用redis不就行了?).
如何进行redis的累加/累减呢?(2:30,看视频,在linux上演示)
(进入redis)
使用 INCR / DECR 命令来.
查询用户关注状态( mysql 中的数据 )
本节开发【关注我】这块相关的业务.
1 粉丝表的设计思路:冗余设计 + 保存粉丝的关键性信息
打开数据库,看看fans表:
表中,包含了如下数据:
作家 id 和 粉丝 id 都属于用户信息。
至于粉丝的头像,昵称这些,后面进行粉丝画像等数据处理时会涉及到。其实都算是“冗余设计”,也叫“宽表设计”。你不设置这些东西,也可以通过粉丝 id 来查到这些信息,但是呢,这就涉及 多表查询 了,会影响到性能。
==> 因此,我们这里的表的涉及都是为了能够 避免多变查询。这一部分后买你还会使用 ES 来进行优化,都会存入ES中。
比如你想问这里的粉丝信息更新了怎么办?我们使用 “被动查询” 解决这一问题。因为对于被关注者,大部分时候不会去关心粉丝的这些信息,他最关心的是“粉丝量”,“男女比”这种,所以采用被动更新。
==> 因此,我们这里要做的就是保存粉丝的关键性信息而已,其他的后面再说。
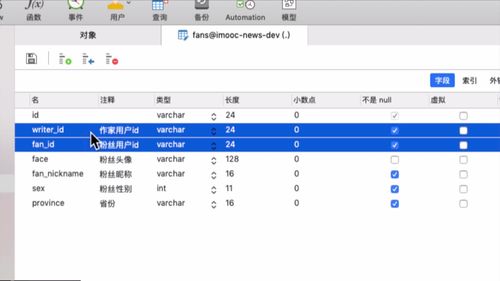
2 检查现有 粉丝相关的类
实体类:
Mapper:(这个业务的话,写在user模块中的)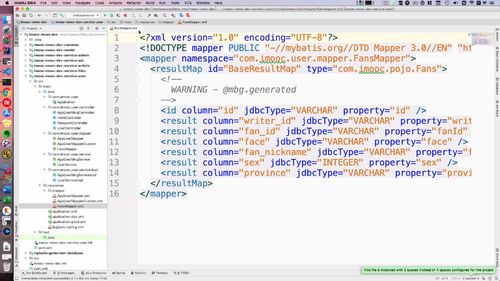
3 开发 Controller 层 api 功能:用户关注状态,表示当前用户 与 被浏览作家的关系
当前用户 与 被浏览作家的关系.==> 若没关注,显示“关注我”;否则,显示“已关注”
所以,涉及 “关注” “取消关注” 这两个接口.
去前端看看:70-73行
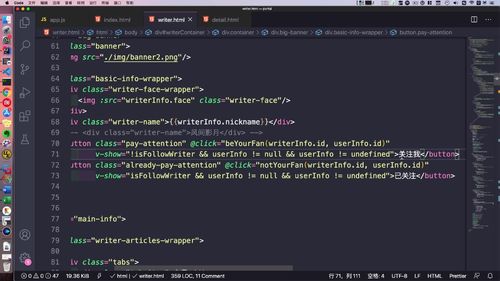
老师这里通过手法先把已关注显示出来了:
后端这里 地址 和 post 已经写的很明确了.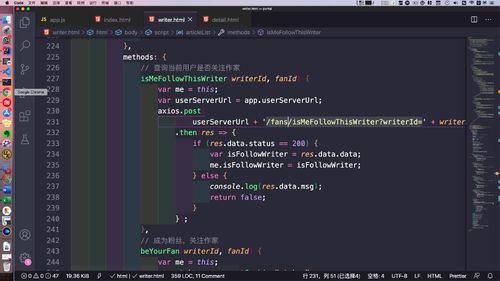
到 api 工程中去,找到user,在user服务中去写。
如下:这个接口就来显示 writerId 和 fanId 的关系,这俩也就作为方法参数传进去。
注意理解 返回值 和 形参注解 的含义(这俩干啥的,忘了)。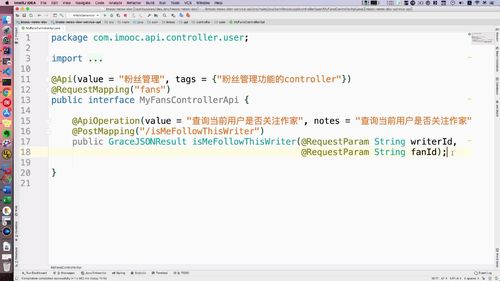
4 编写 controller 所需的 service:查询当前用户是否关注作家
定义接口:返回 boolean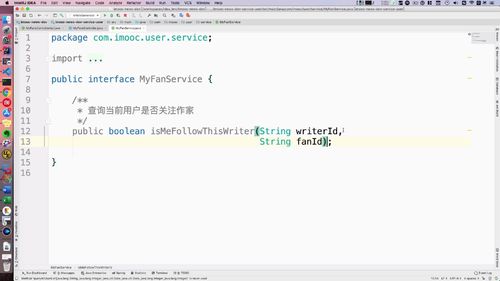
实现方法.
Mapper已经有了,直接注入.
fanMapper里把查询方法已经写好了,这个方法需要传入1个对象,我们搞个fan对象,作者id和浏览者id都放进去,它俩都在一个对象里,这样就存在联系了。
可以看到,这里的操作还是针对数据库的,后面这些东西我们都会放到es中去,就可以不再用这个count函数了。
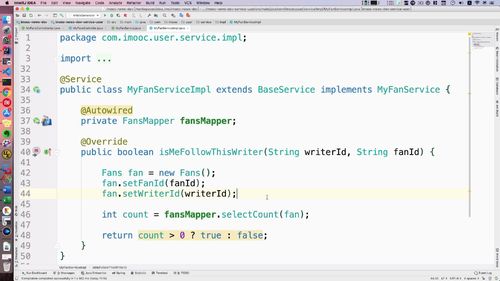
5 实现 controller
user 服务中的 service 类去写.
新建一个contoller,实现接口,继承baseController.
对我们刚写的service发起调用。使用前注入service.
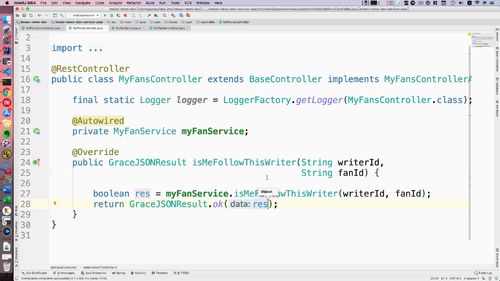
关注 & 粉丝累加
**我们退出登录时,作者界面的关注选项就没有了,这个是前端做的。
**
演示完了重新登陆。然后我们来做下一个接口:【关注】【取关】!
上节课做的其实是“是否关注的状态”。注意一下,自己也可以关注自己,不过老师这块没有处理.
service 层实现:通过 fanId 查到粉丝基本数据,关注数/粉丝数 存入redis
粉丝模块一开始介绍过 “宽表”,我们需要 通过 fanId 查到粉丝基本数据,所以把 userService 注入进来,用这个查询 即可。查询到用户信息以后,就需要“构建粉丝关系”。首先定义表的id,用 Sid获取。(fans里的这个主键id,为啥用fanPKId???回去看看之前的业务)
然后呢,需要进行粉丝数的累加,需要和 redis 建立联系(??怎么mysql 就和 redis 累加关联起来了?)关注数/粉丝数 存入redis:(这个好像也没有建立redis和mysql的联系?怎么保证redis的累加最后可以存到mysql?还是这个关注数/粉丝数干脆就不存在mysql,只存在redis????)
==>这个联系,是不是只是说,从mysql拿到作者id和粉丝id,就能去redis查数量了???
@Autowiredprivate UserService userService;@Transactional@Overridepublic void follow(String writerId, String fanId) {// 获得粉丝用户信息AppUser fanInfo = userService.getUser(fanId); //根据粉丝Id拿到粉丝基本信息String fanPkId = sid.nextShort(); //定义表的id// 保存作家粉丝关联关系,字段冗余便于统计分析,并且只认成为第一次成为粉丝的数据Fans fan = new Fans();fan.setId(fanPkId);fan.setFanId(fanId);fan.setWriterId(writerId);// 以下4个为冗余信息fan.setFace(fanInfo.getFace());fan.setFanNickname(fanInfo.getNickname());fan.setProvince(fanInfo.getProvince());fan.setSex(fanInfo.getSex());fansMapper.insert(fan);// redis 作家粉丝数累加redis.increment(REDIS_WRITER_FANS_COUNTS + ":" + writerId, 1);// redis 我的关注数累加redis.increment(REDIS_MY_FOLLOW_COUNTS + ":" + fanId, 1);}
实现contoller
这里补充一下,这几节课的这个方法,writerId 和 fanId 都需要判空的,但是老师这里没写这个逻辑,提醒一下,有需要自己补充。
(什么情况下为空呢???)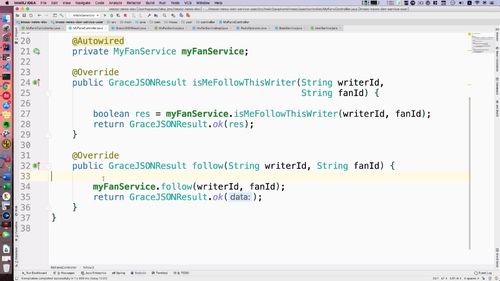
测试(10:00)
(???这里自己关注了字节,怎么页面上粉丝数量没变化???数据库里倒是有了)
(redis好像也没看?自己做了看看吧)
取关 & 粉丝累减
Service 层实现
这里说了一段没听懂:什么 多对多 的?所以 关注 里的 fanPKId 这里可以不写了??什么fanId 和 writerId 联合Id ???
==> 查询的时候,只要匹配 fanId 和 writerId 就行了的意思?fanPKId只是作为主键,查询的时候不用在意这个?
这里是累减方法.
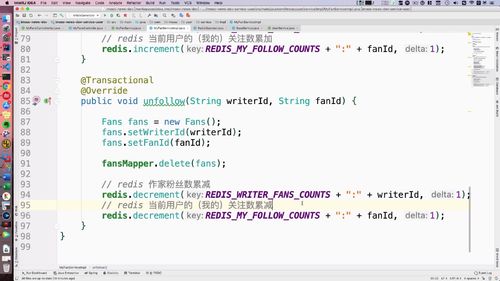
实现controller
(写这个的时候service还没实现)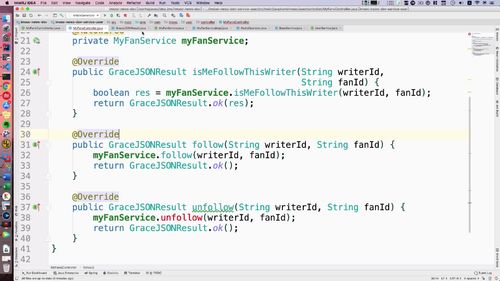
4 拦截(上节课的 关注 也需要拦截)
userToken 和 userActive 两处地方都需要拦截!
47/48 52/53 这几行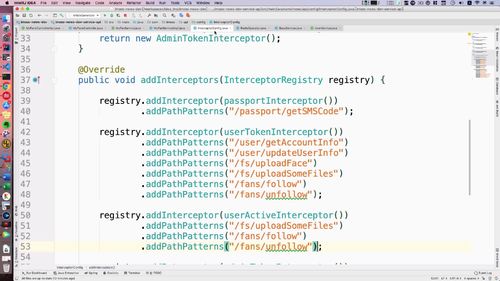
粉丝数与关键页面显示
熟悉业务
右侧这俩.
首页这俩.
前端调用这个getUserInfo来查询的.
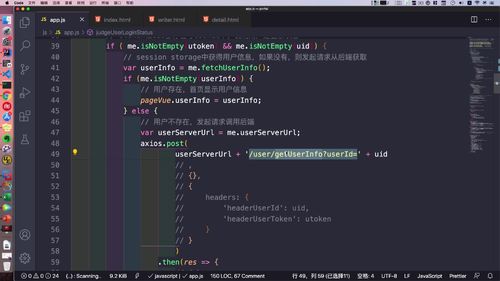
(2)补充 用户信息类 的属性
看看getUserInfo:
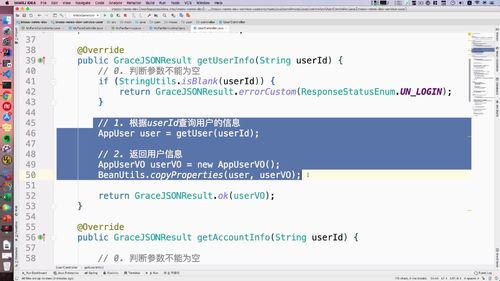
修改 AppUserVO:补充 关注数量 和 粉丝数量 的属性
为了实现 关注数/粉丝数 的查询,我们直接在 AppUserVO 中补充这两个属性:9和10行.
生成getset方法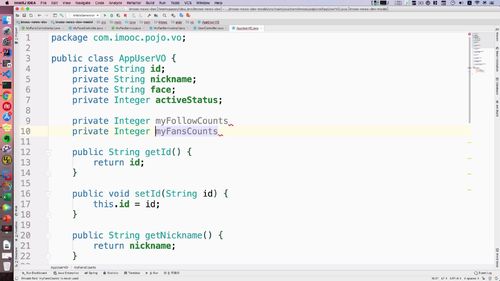
BaseController 补充公用“获取数量的”的方法
用key查到count。
这个值可能不存在,比如刚创建的用户。手段复制为0(其实这里前端也有判断)==>(???为什么前后端都要进行处理???)
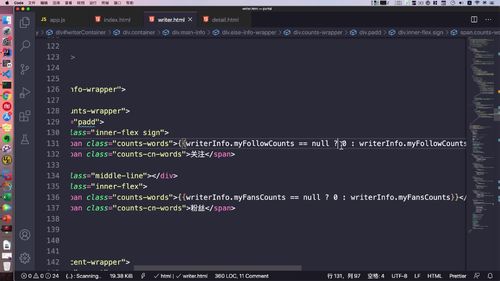
方法写好如下:(102行)
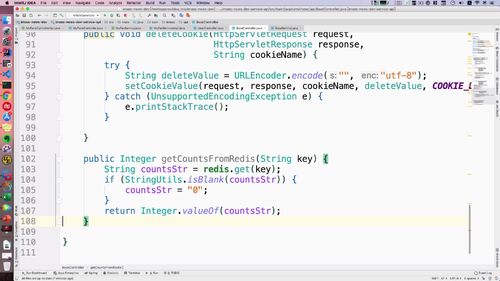
补充 getUserInfo,获取 关注数,粉丝数
去getUserInfo中补充第三部分的查询前,先去baseController中加上两个key的常量名:32/33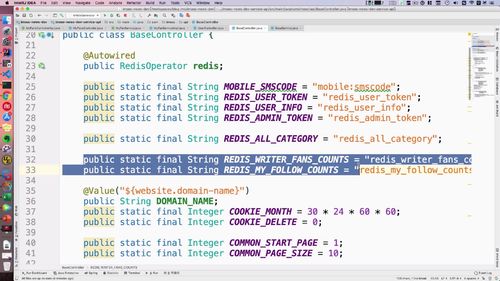
去getUserInfo,现在想用这两个key进行拼接:(52注释).
为此,我们去BaseController中补充一个公用方法,获取数量。吊钟这个方法分别得到 关注数/粉丝数即可.
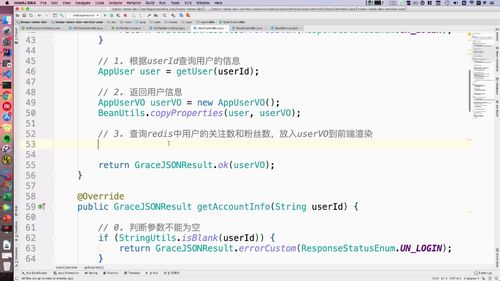
写好如下: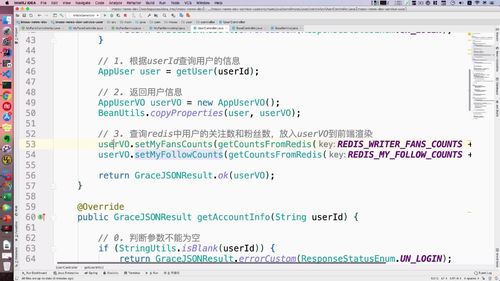
之后前端姐可以得到 关注数/粉丝数了.
3 测试:(5:20)
(userVO在 article user 模块都会使用到,所以测试前至少这俩都得重启)
粉丝画像
后端粉丝查询 & 我的粉丝列表
1 介绍:作家中心有个“我的粉丝”,需要展示粉丝列表,单表查询一波即可.
针对的就是这张表:
2 controller接口
看看前端:182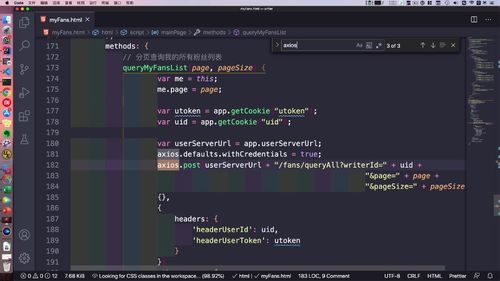
接口:登陆用户id别忘了,就是writerId.
其他基本和一般的分页查询一个样.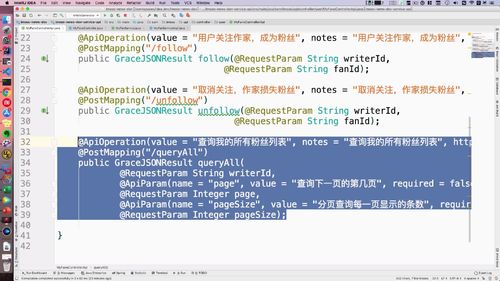
2 Service 接口
@Overridepublic PagedGridResult queryMyFansList(String writerId, Integer page, Integer pageSize) {Fans fan = new Fans();fan.setWriterId(writerId);/*** page: 第几页* pageSize: 每页显示条数*/PageHelper.startPage(page, pageSize);List<Fans> list = fansMapper.select(fan);return setterPagedGrid(list, page);}
3 Controller 实现
writerId 判空 自己写一下.
@PostMapping("queryAll")@ApiOperation(value = "查询我的所有粉丝", notes = "查询我的所有粉丝", httpMethod = "POST")public GraceJSONResult queryAll(@RequestParam String writerId,@ApiParam(name = "page", value = "查询下一页的第几页", required = false)@RequestParam Integer page,@ApiParam(name = "pageSize", value = "分页的每一页显示的条数", required = false)@RequestParam Integer pageSize);
@Overridepublic GraceJSONResult queryAll(String writerId, Integer page, Integer pageSize) {if (page == null) {page = COMMON_START_PAGE;}if (pageSize == null) {pageSize = COMMON_PAGE_SIZE;}PagedGridResult gridResult = myFansService.queryMyFansList(writerId, page, pageSize);return GraceJSONResult.ok(gridResult);}
粉丝画像:工具介绍
1 看一下成品,熟悉我们要做什么
这个页面是动态页面,目前没有展示(??这个逻辑是什么意思?就是我们现在还没写接口,查不到数据吗)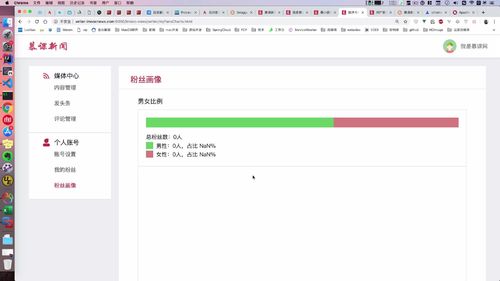
去前端看啊可能:这里有个静态页面.
(动态有数据才能看,静态是写死的吧,当作例子看看)
打开这个: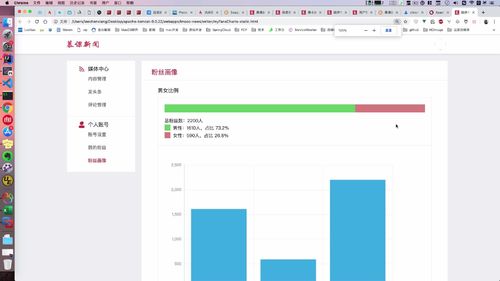
还有饼状图: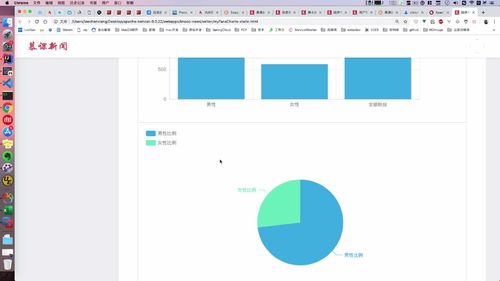
地域分布:
有些小特效,这都是前端需要做的.
2 前端插件:echarts
前端负责渲染,后端负责接口对接,把男女粉丝的数量传给前端即可。前端通过echarts (https://echarts.apache.org/zh/index.html) 来进行数据可视化的渲染。
前端使用了这个插件:

常用的主要就是前四个图:折线柱状/饼图/地理图。当然我们项目用的不是这几个。我们还用到了 地理坐标.
至于用法,可以首部查找文档.
==> 最主要的是引入官方的一些包(都是在前端用)
这里就是小样例.
最主要得有这个:option
3 分析静态页面
去看看刚才的静态页面中怎么写的: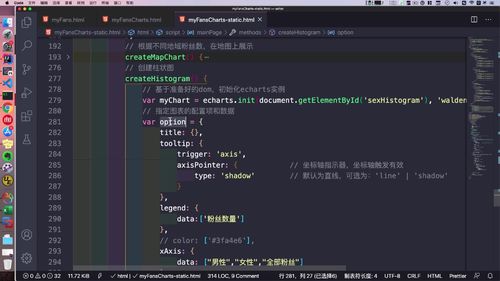
再来看看,后端要传什么数据?
柱状图和饼状图 主要就是 男女粉丝数据,然后通过这个option进行渲染.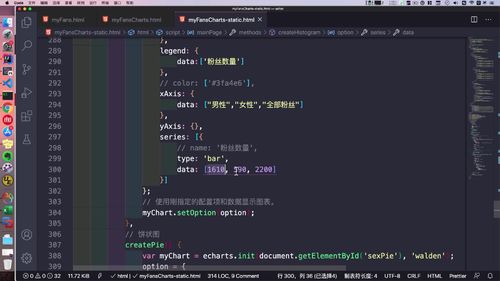
粉丝画像:男女比例
查看动态页面,分析后端需要什么工作:作家id传入,开始查询.
231,发起后端请求.
作家id传入,开始查询.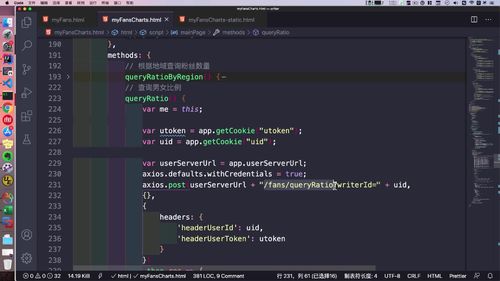
243 244 接受 男女数量 的数据: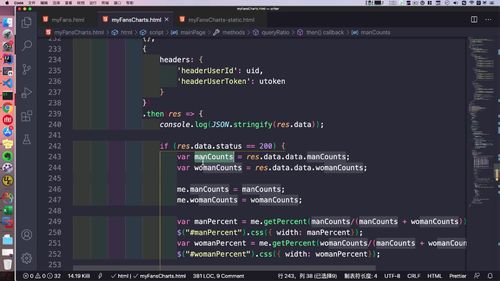
Controller 接口:作家id传入,开始查询.
service 接口
Sex是已经提供的枚举类.
实现 service :男女分开查
(这个sex不太懂啊?意思是,这里只查男女中一类的意思吗?controller里查男女分开?)
@Overridepublic Integer queryFansCounts(String writerId, Sex sex) {Fans fan = new Fans();fan.setWriterId(writerId);if (sex == Sex.man) {fan.setSex(Sex.man.type);} else if (sex == Sex.woman) {fan.setSex(Sex.woman.type);} else {return 0;}int count = fansMapper.selectCount(fan);return count;}
实现 Controller
分别查询男女数量(那我前面的说法没错),存入VO!
@Overridepublic GraceJSONResult queryRatio(String writerId) {// 查询男的多少人int manCounts = myFansService.queryFansCounts(writerId, Sex.man);// 查询女的多少人int womanCounts = myFansService.queryFansCounts(writerId, Sex.woman);FansCountsVO fansCountsVO = new FansCountsVO();fansCountsVO.setManCounts(manCounts);fansCountsVO.setWomanCounts(womanCounts);return GraceJSONResult.ok(fansCountsVO);}
测试
(1)
这里男女比例是前端计算的,我们传入男女粉丝数量即可.
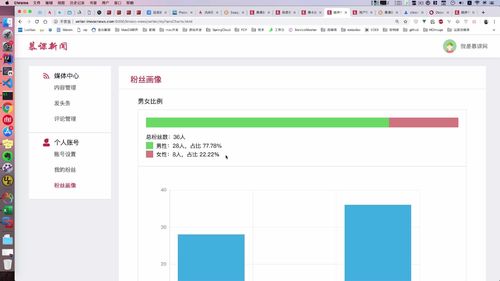
比例,柱状图,饼图 都有显示.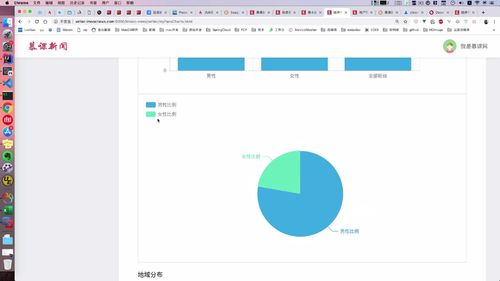
(2)看看前端
这里有个初始化图表,一个饼状图一个柱状图:255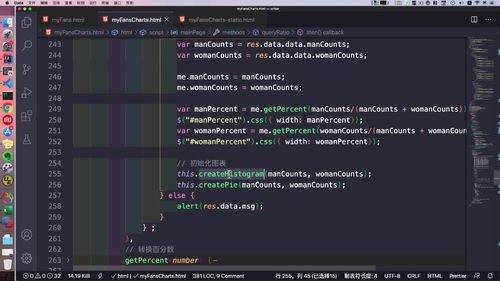
292柱状图这里有个相加.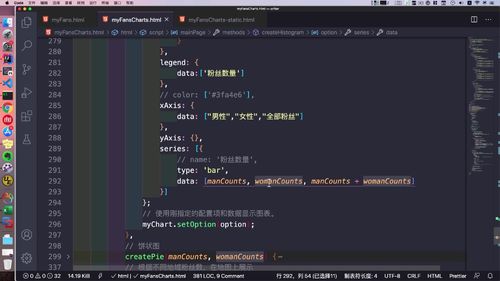
饼状图:322,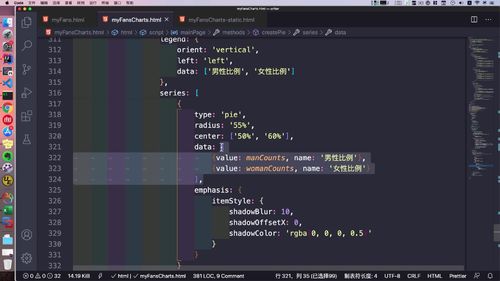
这里是个数组,还可以自己添加更多内容:(324)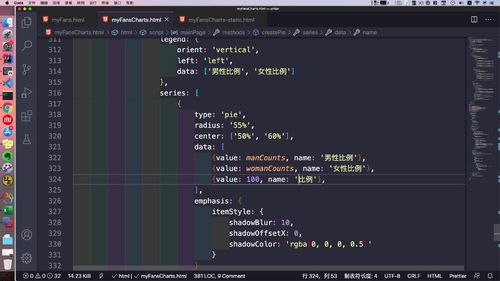
如下,就多了个随意
粉丝画像:地域分布
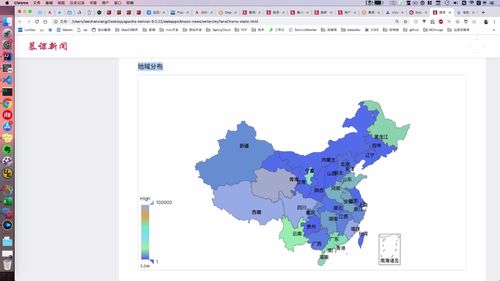
1 了解业务
(1)数据库
数据库里,有这么一列属性:34个省级行政区.
(2)参考静态页面
192开始.
数组里有很多对象,
对于我们后端主要就是传递这一部分的数据.
最后放入了 274行 myChart
(3)动态页面分析.
201行,发起请求,传入作者id.
(这里省份不要加“省”,“江苏”而非“江苏省”,这都是省略数据)
(这里串了一下数据的流程,就不做笔记了)
controller 接口
接口名称从前端复制过来.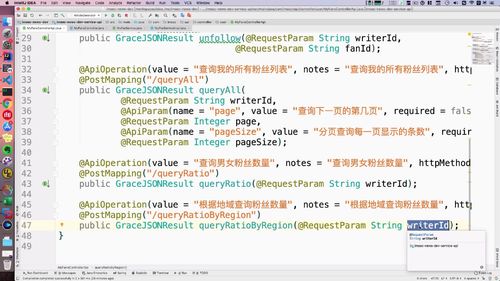
Servcie 接口:创建 VO 类,返回 RegionRatioVO 的 List
接口:返回对象老师专门搞了一个 RegionRatioVO,记录了各个省份.
返回一个泛型是RegionRatioVO的List(前端那边也是list,匹配上)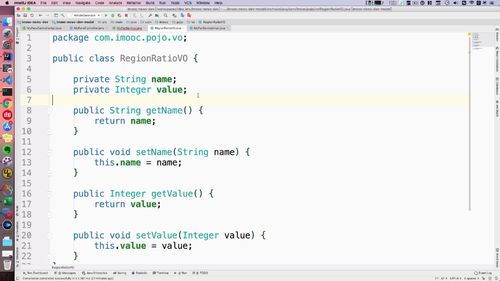
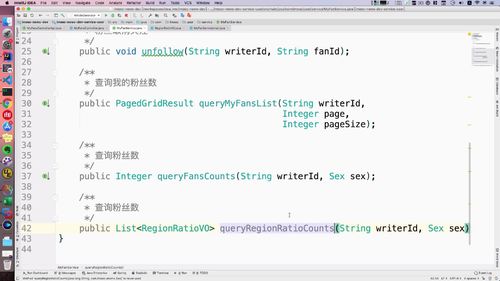
Servcie 接口实现:根据数组名查到 count,然后构建VO,最后放入 List 中
查询前,构建regions数组:120行,直接复制老师的,用这个来循环查询.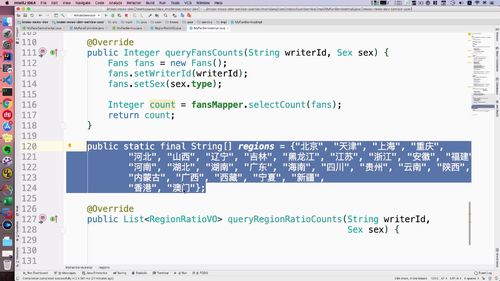
(说是后面采用rest???来进行优化???)
根据数组名查到 count,然后构建VO
最后放入 List 中,list 在循环外声明.
124行.(这里形参多写了sex,删掉,接口那没写错)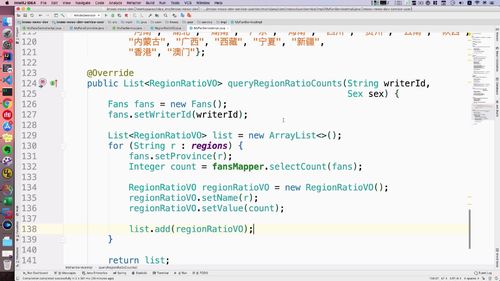
实现 controller 接口
测试
蓝色的没数据.
为精确测试,数据库中改改数据即可
第八章 详情页与评论模块
本章内容简介
本章开始开发“详情页面”,涉及如下三部分:
文章详情页 和 文章评论模块 这两个在同一个页面上.
详情页如下:
左侧有文章发布时间,作家名称
左下和社交相关,这个是前端的插件,后端不用管(去看detail页面)
中间为主体部分:文章标题,文章内容,下面是留言区域,最下面是评论区.
评论管理主要在后端:
文章详情
文章详情展示
一、本节目标:查询文章详情内容,并在详情页进行展示.
该部分在 ArticlePortalController(文章服务模块)编写.
Controller接口:传入文章 id 即可
发起查询是get请求,形参传入文章 id 即可.
Service定义:专门去搞了一个VO类,ArticleDetailVO,就比 article 类多了一个 “用户名” 这样的属性.
(1)接口
这里和之前的内容相似,文章信息中只有发布者的id,其他信息没有,所以为了整合,老师专门去搞了一个VO类:ArticleDetailVO。
这里就比 article 类多了一个 “用户名” 这样的属性.
接口:返回这个VO对象即可.(38行)
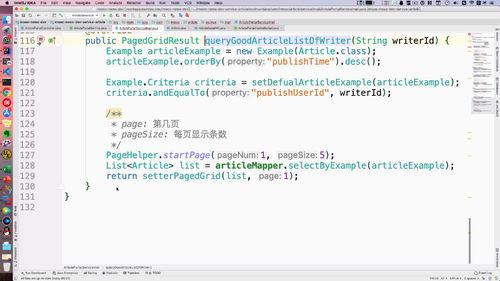
Service 实现
和上一章一样,这里也需要设置“隐形条件”,这三个条件是默认带着的:93-95.
这是之前查询列表的时候加的,查询单个的话也要加上!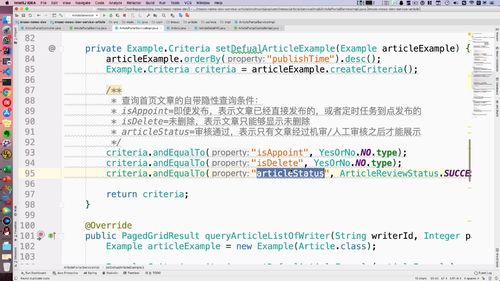
如下:
appoint??这个干啥的来着??
状态选的是审核通过.
(这里没有通过多表查询来获取昵称,在后面用redis来获取)
实现Controller接口1:抽离远程调用方法.
类似上一章首页文章拼接,这里也进行拼接,为了增加通用性,把之前这部分代码抽离出来.
如下: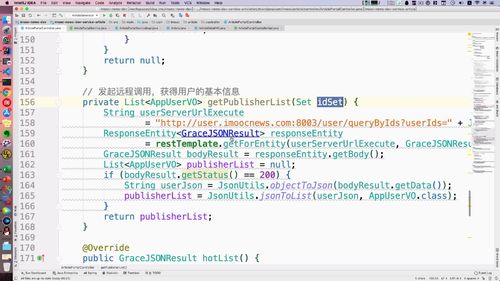
前面的这块可以注释掉了:改成调用抽离出的这个远程调用方法即可.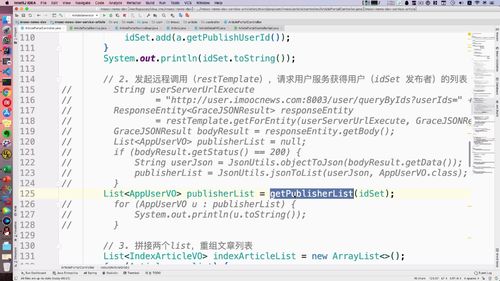
实现Controller接口2:拼接redis查到的数据和文章数据.
不是,一个文章一个作者吧?你表里看起来也不是多个作者,为什么这里要用 list ?????
方法结构体里这么写的?
==>??? id还用set存的,然后查的时候传入的set,返回了list???看看之前的方法
==>这个从 redis 查用户的方法,是通过远程调用先拿到了整个用户列表吧,所以是list。 然后再用文章里的作者id去这个表里面查询(至于为什么用set,后面复习了再看看吧—->保证唯一性)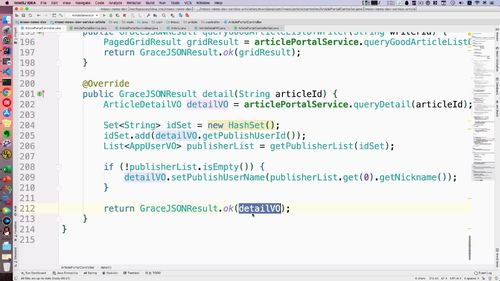
阅读文章 & 阅读量累加
上节课完成了“文章详情的展示”.
这里提一个东西:文章首页列表的“阅读量”,阅读时进行数据的累加。(总感觉这个功能,因该放在上一章节)
看看数据库:已经设计 了这个东西。但是呢,和之前一样,这个数据在首页展示,并发很大,所以不放在数据库,放在redis中。所以表这里这个设计就没啥用了。
后面还会有“评论数”,这个也一样会放进redis中。
(这里看了下前端,说了个result没做处理,能删掉啥的,用户无感知,没懂)
不用 Service了,直接操作redis.
完善detailVo,补充 阅读数 属性
①
阅读量不仅在首页列表有体现,详情列表也有,所以进行一些补充。
不过,首先需要去vo中扩展再扩展一个属性(之前扩展了作者昵称)
属性名别乱写,和前端对应:17行,写了以后生成 get set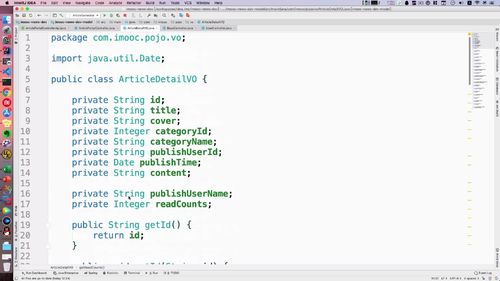
Controller层调用
② baseController中写过这么一个方法:164行,就用这个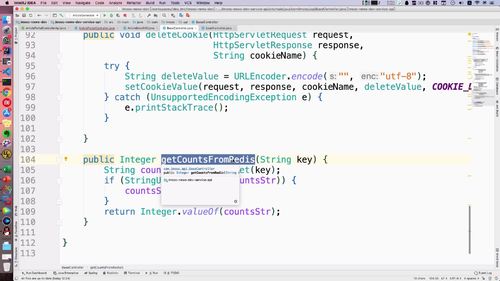
③ 调用:219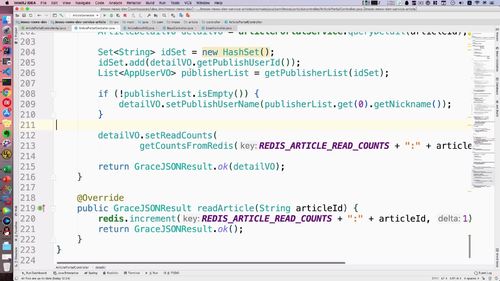
文章阅读数防刷:通过 request 的 ip 来进行拦截
一个用户可以多次浏览一篇文章,但是这个阅读数不能每次都增长吧,不然你1个人能给刷个几十万。
为此应该对这个行为进行限制与拦截,一个用户贡献过阅读量后,再看文章的话,阅读数不应该再增加。
==>利用 拦截器
Controller层创建 已阅读用户的key,便于拦截器拦截
找到上节课写的这个方法:readArticle。
找到它的api,加上一个request:通过这个得到用户ip,后面就可以根据这个ip进行拦截。
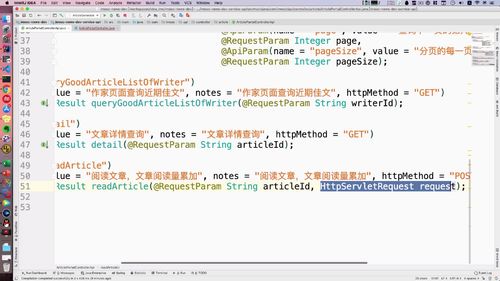
回到实现类,得到ip。根据ip拼接出对应的redis所需的key,以后识别到这个key,那么月的时候就不能累加了(会面改错的时候还得加上文章id,这样才能作对对于每篇文章都防刷)。
不过在那之前,先去创一个redis key的常量前缀:如下,baseController的36行
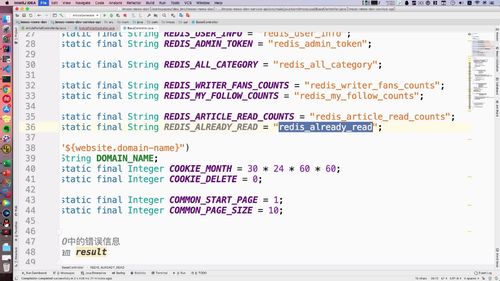
然后去controller实现类拼接:223-225行。
以后拦截器要是拦截到这里创建到的key,那么就不允许进入这个方法了!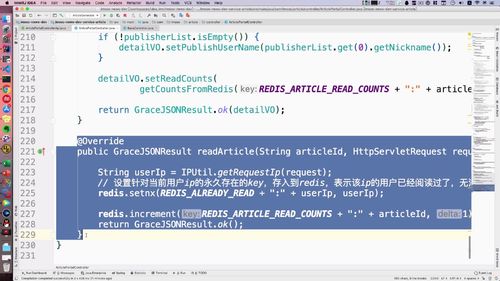
创建拦截器
创建拦截器如下:路径看package,类名自取.
我们就使用 preHandle 这个咯!
(老师article拼错了,自己写的时候注意下)
当然了,之前写在baseController的key复制一个放在这里用于拼接;
redis工具类要注入进来.
编写方法如下.
(这里又说啥不需要XXX的,用户无感,错误不给用户看啥的)
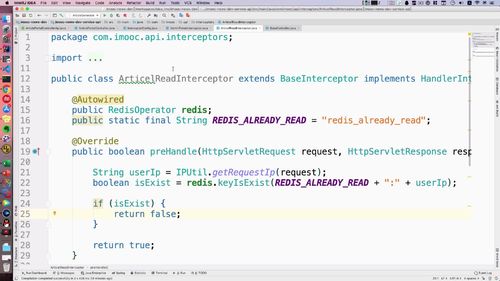
注册拦截器
进入interceptorConfig.
先注入我们刚才写的蓝机器:24
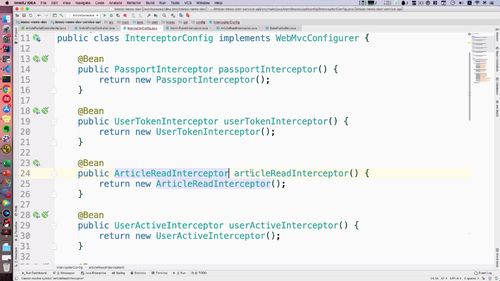
然后注册一下:69行
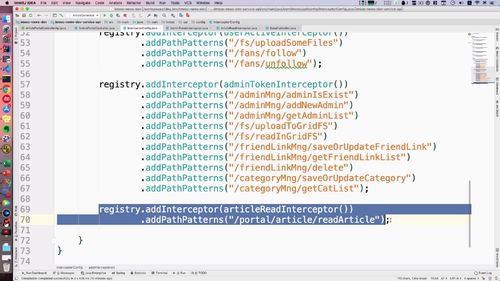
测试
(1)错误:
只有一篇文章的阅读数增加了,看其他文章没有阅读数的.
错因:拦截的是当前ip,那么你这个ip无论看多少文章,阅读量只会+1;
==> 改错方案:redis 的 key 再加上文章 id,这样的话一个 Ip 看不同文章,阅读量是分开计算的。
(2)修改:
Controller的225加上articleId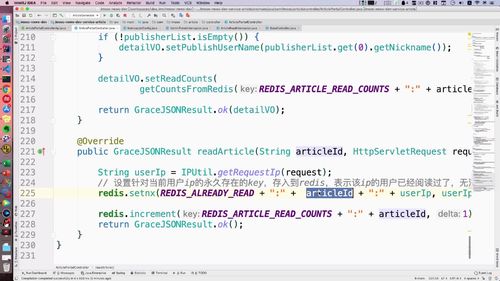
Interceptor也写一下:24
这个article通过request来获取:21
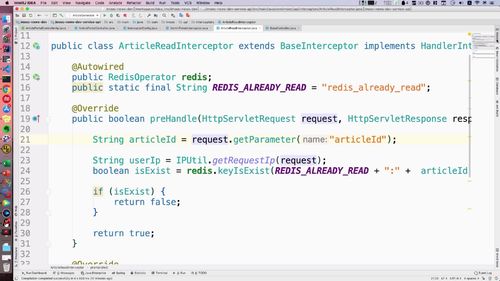
(3)重新测试(10:10)
测试阅读数
看看redis:一个文章id嵌套了其他key,代表不同ip用户的已访问.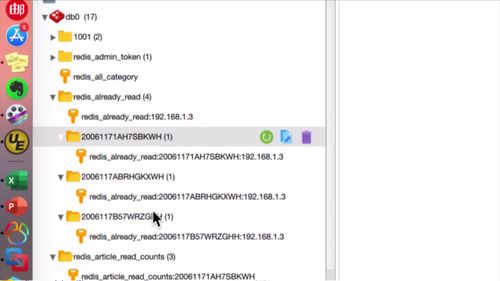
文章列表
上节课说了,首页列表 和 详情页 都需要展示 阅读量,上节课搞了 详情页,这节课搞首页列表。
暂时使用上节查询阅读量的方法。
我们先找到上一章 首页文章列表list拼接的方法 rebuildArticleGrid: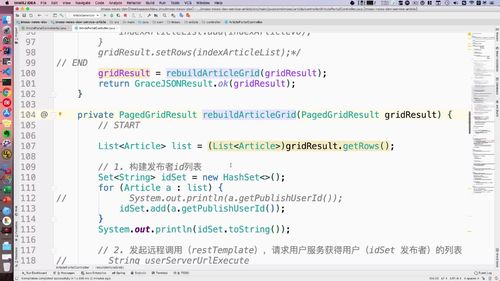
找到最后:我们在3.1之后补充3.2步骤,把阅读数传进去:
如下143-145.
这里是写在“循环”里的,记住这个,待会优化围绕这个展开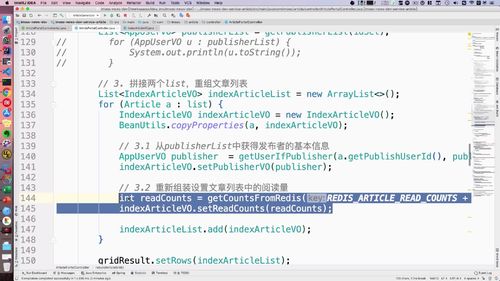
能直接传的原因在于:IndexArticleVO里面已经又这个readCounts属性了.
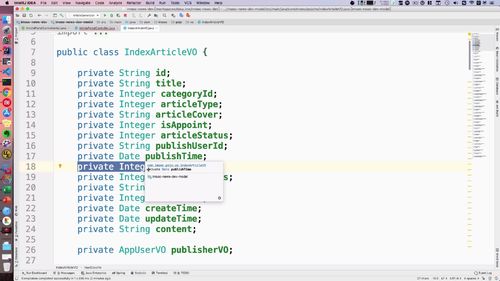
(2)测试
问题在哪里? for 中的 get 是单次调用
使用 redis的 mget 批量查询 优化,替换单个查询.
(1)1中的方式有什么问题?
redis的 get 调用写在了 for 循环中,每次都是“单次调用”,每一次都要“建立连接并且断掉连接”当请求很多时,不断地连接与断开对性能影响很大!
(!!感觉这一块的底层分析很重要啊,面试可能深挖,去了解一下redis请求的连接原理是不是这样的!!)
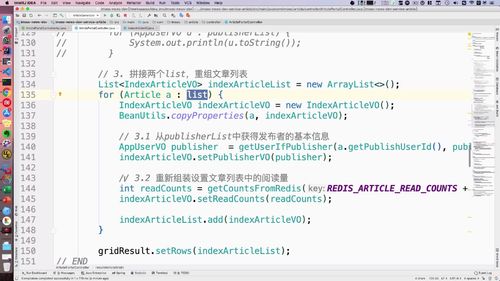
(上图144行方法如下106,单次get调用)
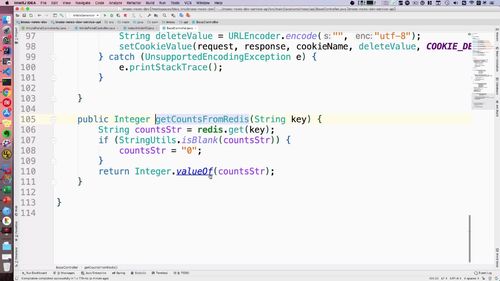
使用什么优化?——mget,批量读取
使用 get 就是“一来一回”,建立了还要关闭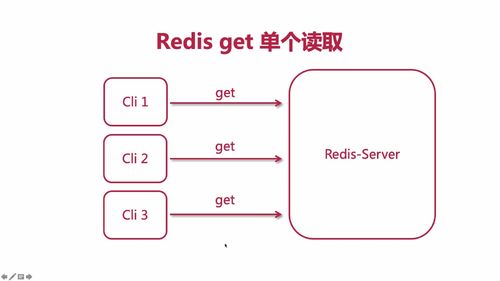
但是呢,这些个get都差不多,所以我们想办法一次都给读取,不用频繁建立连接与断开连接。
==>当key多时,且比较重复,可以用Redis mget 批量读取:我们把请求放在 mget。
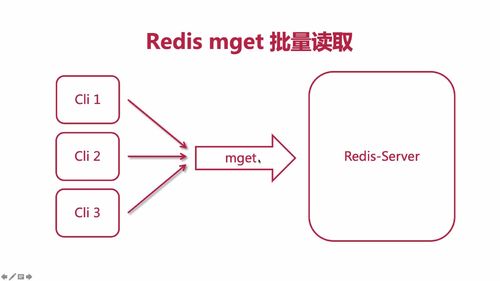
加入mget功能,优化代码:redisOperator 里封装了mget方法
我们不再使用与for中调用redis get的方式: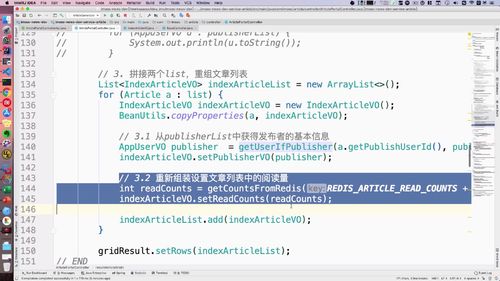
(1)查看mget方法
redisOperator里又mget方法:已经封装好了,是一个批量查询。
形参 List
内部调用了 multiGet 方法 。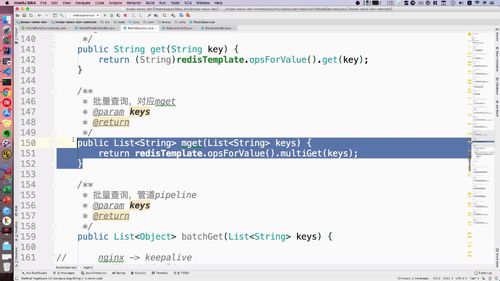
(2)构建所需形参:List keys
回到 首页列表构建 方法:
111创建1个list,然后在117拿到 首页列表文章的 id。用这个key和阅读量前缀拼接出 key值。
这样就得到了mget所需的形参。
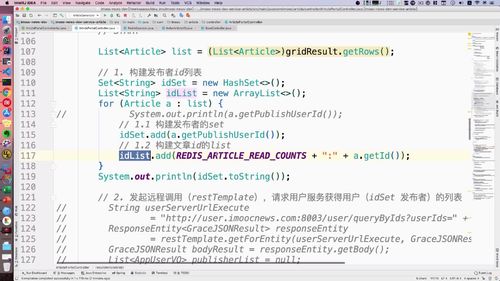
(3)发起mget请求,拿到返回结果
121行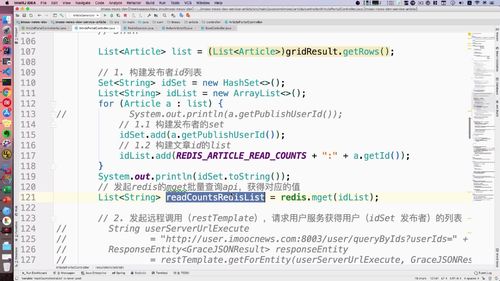
(4)重写for循环
之前的for注释掉,不采用这种方式了.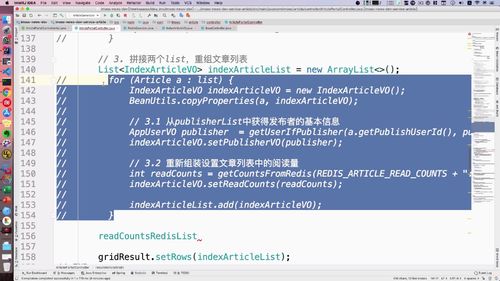
重写与155-173
使用如下for循环方式,重点重写3.2部分.
之前:一个一个从redis中获取阅读量;
现在:已经从redis中得到了所有,返回了list,从这个list获取阅读量;
(list里是i,老师一开始写的0,后面改回来了)
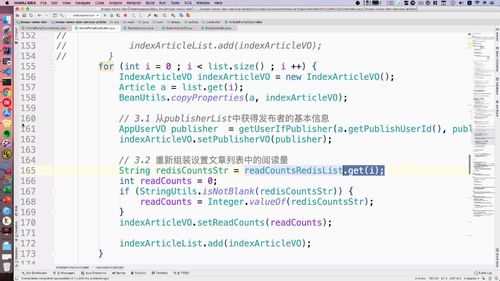
文章评论
用户评论入库保存
本节开始【文章评论】.
—————————————
零、业务介绍
入口在性情页的下方,在这里可以发表一些文字:
点击发表评论,评论进入数据库。
下边还有个所有评论的列表,可以分页展示。评论里面还有回复。
代开数据库,comments就是评论: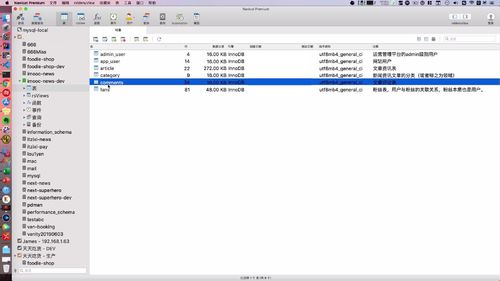
点击进入后:表结构如下.
评论主键.
father_id 感觉是 评论回复者的 id?comment_user_id是留言/评论者的id。writer_id是文章作者的id,别搞混了。
文章标题和封面是冗余数据,计算没有也可以用 article id 查询。
用户昵称也是冗余数据,是宽表处理。用户修改昵称你用同步。后面会讲 ES 会涉及“被动更新”。之前也提到过。
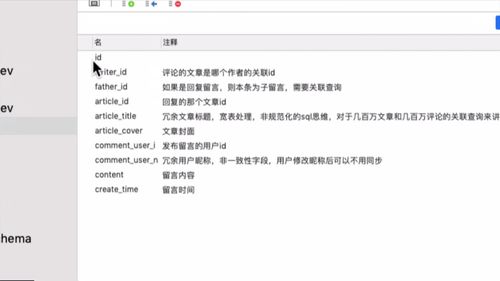
————————————————————————————
一、评论的逆向生成文件(pojo类,mapper这些,4:00)
生成好了,拷贝到对应的文件夹即可。
pojo是在model模块.
二、Controller 和 Service
1 评论Bo类
(搞清楚什么时候VO,什么时候BO)
注解用来验证.,空的时候对应message填充.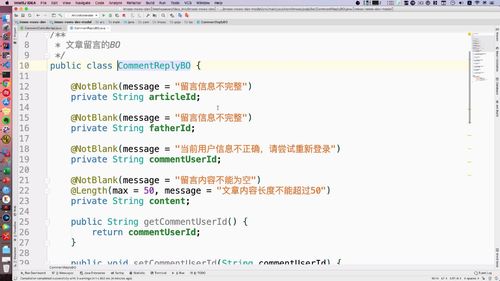
2 Controller接口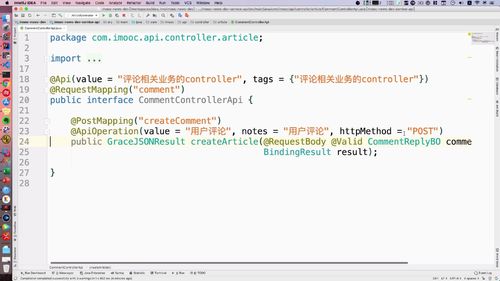
3 实现接口1:远程调用,得到用户昵称
继承BaseController.
VO的错误信息抛出返回,直接用之前业务的写法。
(1)把之前的 远程调用 放入baseController中
这个在articleportal的类中,把这个方法复制到baseController中去!
原来方法那里就不做删除处理啥的,有兴趣可以自行优化
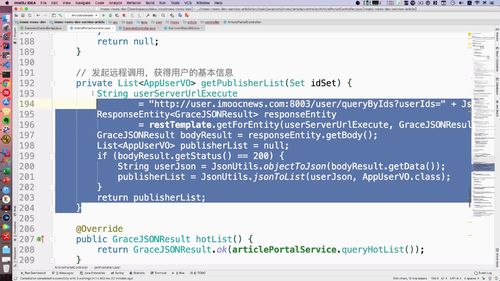
复制到b..c..时,方法名和用户list的名称做一个修改:122 128 131 133 ,可以使用IDEA的批量修改功能。
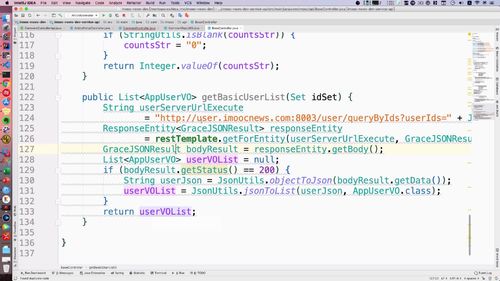
这样其他controller就能调用这个方法了
(2)远程调用,得到评论用户的昵称.
根据BO拿到用户id,用来 远程调用 (restTemplate,就是(1)中复制到baseC…中的方法) 拿到用户昵称,存入数据表来冗余处理,从而避免多表查询。后面这些都会放入es中。
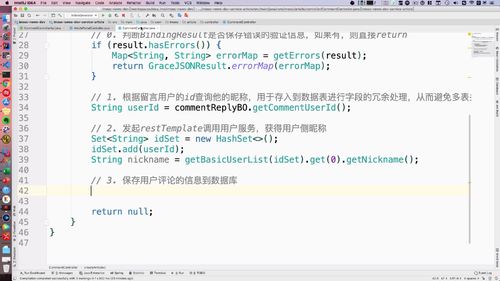
————————以上为8.5节的笔记——————————-
————————8.6开始编写“评论入库的操作”———-
4 实现接口2:评论入库
(1)创建新的Service,先创建接口
无需返回值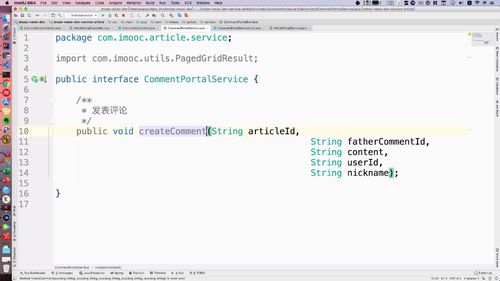
(2)实现Service
注入commentMapper,之后需要使用它的Insert方法,把评论插入数据库。
有了article可以查询到文章的具体信息,标题封面这些.。现在需要的就是:在当前service调用另外的service——注入ArticlePortalService。
当前方法加上事务,别忘了。
注入Sid,用这个得到评论主键。47行.
方法里主要就是设置comment的值: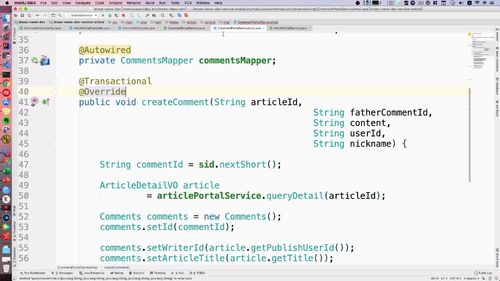
(3)完善controller
注入service. 26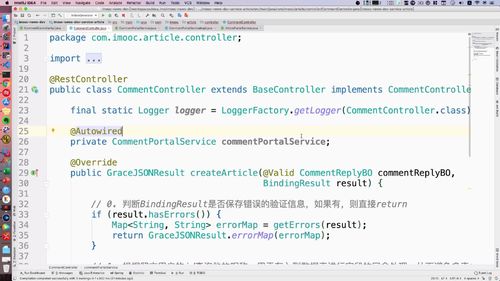
完善,为service传入形参: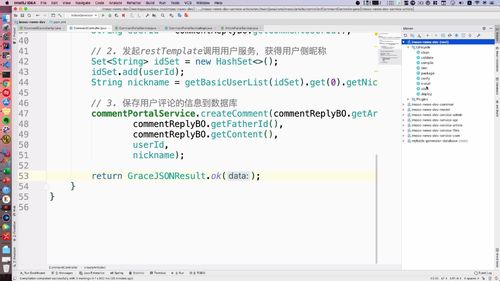
5 测试(8:10)
(1)
入库成功,fatherid默认是0.
但是有个小错误:没有封面article_cover.
(2)分析
打断点:查询的时候就没有查到.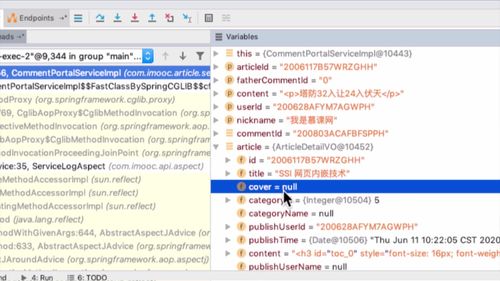
错因:字段不匹配!
articleDetailVO中叫cover.
Article中叫articleCover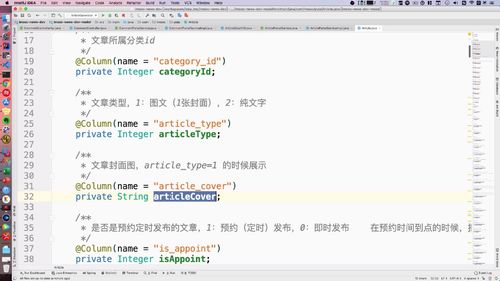
∴不匹配
(3)修改
方式1:手动加,147行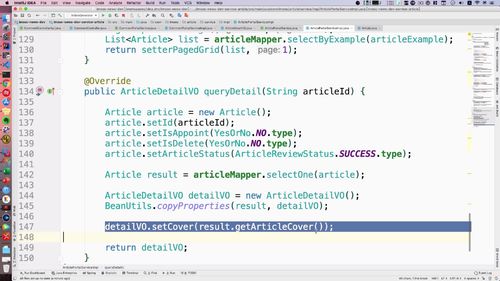
方式2:
改VO,然后会自动匹配.
==>方式2不采用,你这VO一改,万一涉及其他地方,前端全都要改,不好。就方法1这种特事特办即可。
(4)重测(12:30)
评论数累计与显示
仔细看这个 评论区域 右上角,有个“x条评论”,本节就处理这个:显示评论,并累计!
涉及“累计”,都采用 Redis !

1 Service中,评论入库时,就需要 累加 了!
(1)定义key值:18行
(2)调用redis方法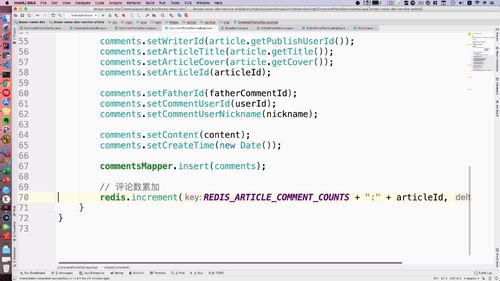
文章评论sql关联查询
2 Controller 中,处理 评论数 的返回.
评论数的获取可以跟之前的阅读量一起查出并返回,但是这样耦合度太高。如果以后想对 评论 文章 进行模块拆分,那么就不太好。
这里采用的方式是“解耦”的方式,“评论功能单独设置接口”!
(1)单独创建 评论数 查询接口
确认前端路由.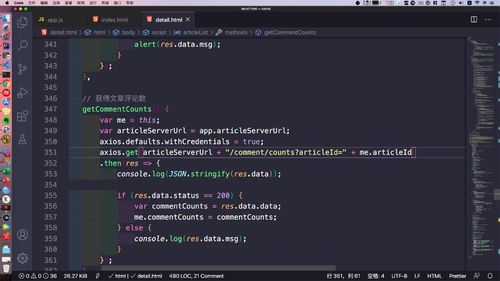
接口传入文章 id 即可.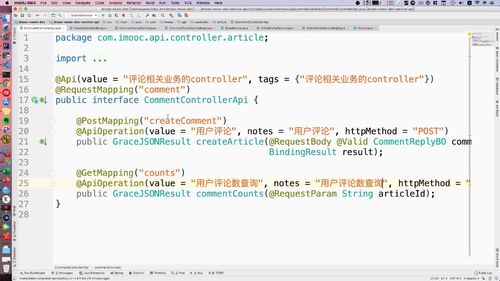
(2)实现controller 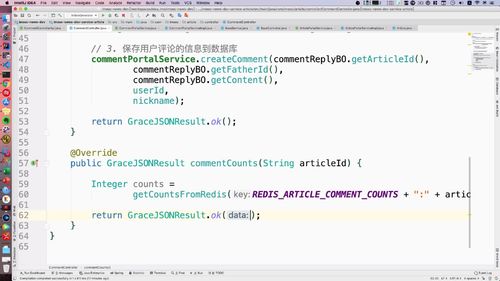
3 测试(5:10)
显示评论列表
本节课开始搞“所有评论的列表”,包括8.8 8.9
如图,最下边这个“所有列表”.
这里就需要“多表关联”了,因为涉及到不同的用户id,如这里的 father_id。
(怎么个关联法,感觉也不是讲的很清楚啊)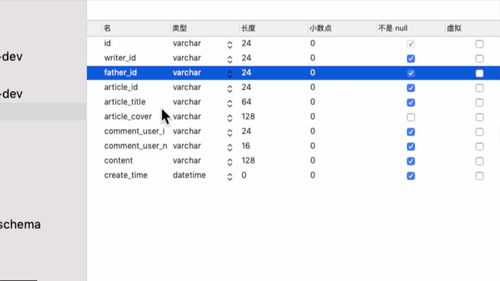
一、sql关联查询文章评论
(1)这里先把对应的sql写一下.(复习下sql语法咯)
这里都要设置别名,后面好跟VO,前端匹配.
写好以后放在自己的mapper里.(这部分sql语句还得再熟悉一下)
对应的VO已经写好了:属性和sql语句的别名都对上了
——————以上为8.8节内容:sql语句—————————-
——————以下为8.9节内容:评论列表—————————-
(2)实现自定义Mapper文件
当前的commentsMapper.xml拷贝一份新的:commentsMapperCustomer
namespace改掉.
写上select方法.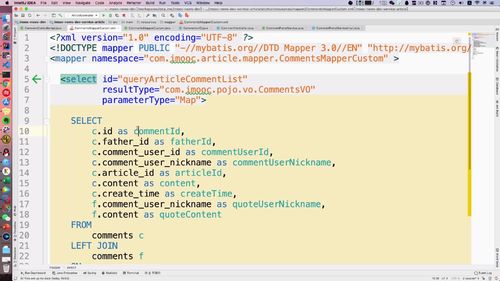
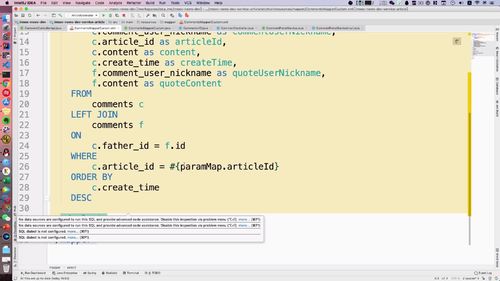
这里文章id写上#{} (26行),即写上占位符,就可以冬天获取数据。这个参数会从待会接口方法的形参注解@Param属性的属性传进来。
(3)映射也搞一份过去:这个不需要继承myMapper。
@Param注入动态变量.
形参是Map,和xml文件中select的parameterType一致.
二、编写Controller层
(1)controller层接口
369行看路由:
27行接口方法,传入文章id和分页参数.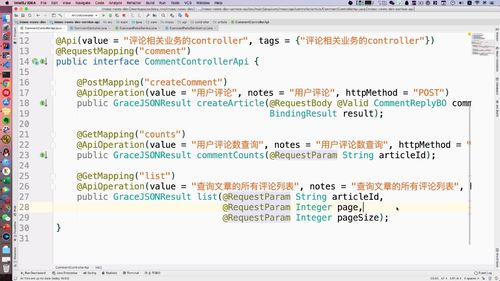
(2)service调用
①接口: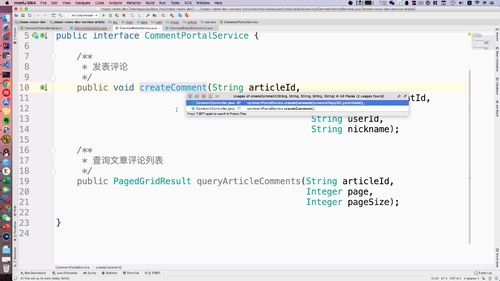
②实现:
因为设定了Map作为dao层方法的参数,所以得设置一下这个 文章id.
使用mapper前注入一下:
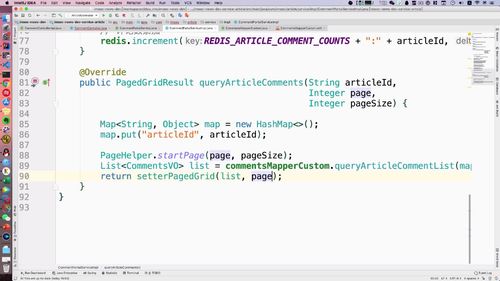
(3)实现controller接口
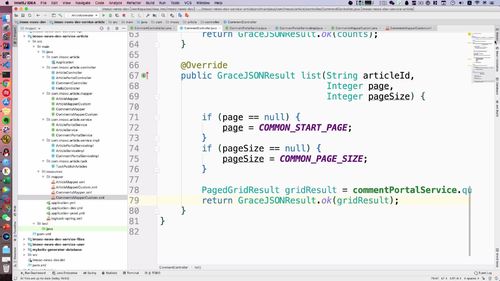
三、测试(10:30)
这里就可以理解一下fatherId是什么意思了:
A评论了B,那么显示B再A中就是红框显示(如下图),B的id就是father_id,之前都理解错了!就是作为一种引用关系,B能在A中显示,表明A是回复B的。
上图中,本业务:A可以评论A,这个允许的。
但是如果你的业务不允许,就要去判断了。
管理评论列表以及删除评论
作家中心有个 评论管理 :这里可以删除评论.
包含两个业务:【查询评论列表】+【删除评论】
1 API接口如下:
controller接口.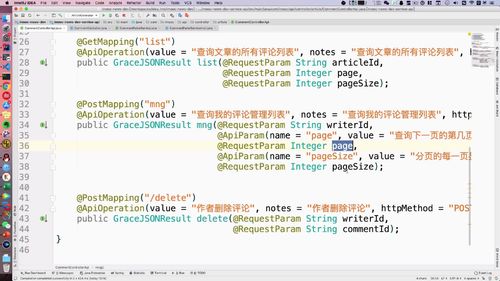
service接口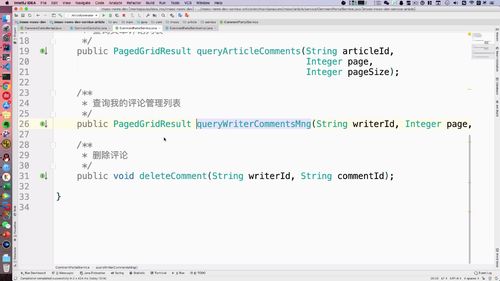
2 实现:
Service实现:查询方法中传入 writerId 就可以查到作者文章里的所有评论.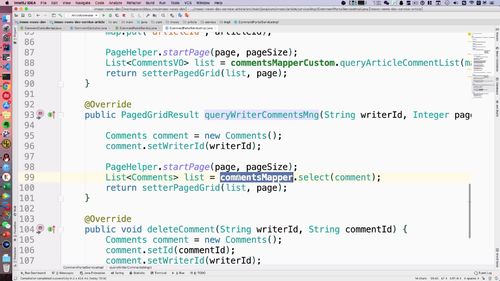
这里不是逻辑删除,是直接从数据库删掉.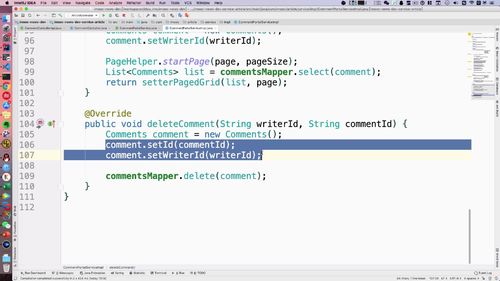
增加评论者头像展示功能
一、本节要点介绍
“评论列表的头像显示”并没有去实现:
本节课主要体验【如何补充后期的功能拓展】
去前端瞅瞅:166,我们现在还是写死的.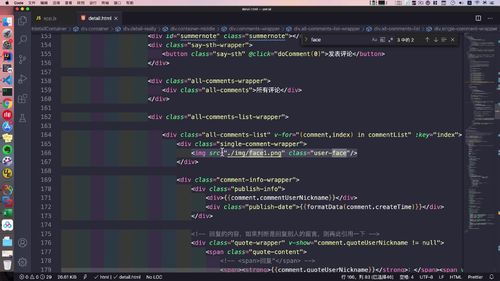
业务知识:企业开发过程中,可能在早期业务分析阶段,会漏掉一些“字段”,比如我们这里的“头像”。因此,需要在后期进行一个表数据的扩展,进行更新迭代!这种情况在企业中是常常遇到的.
如下图:我们的评论表里“没有头像字段”!因此,我们需要进行 宽表处理
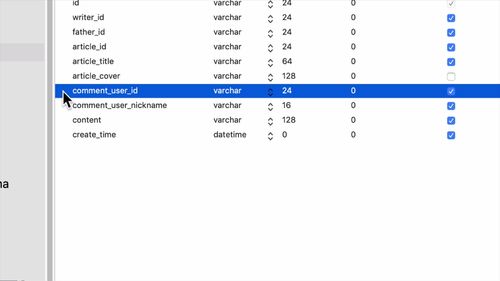
二、字段扩充
(1)修改数据库表的字段
我们对头像进行宽表的处理: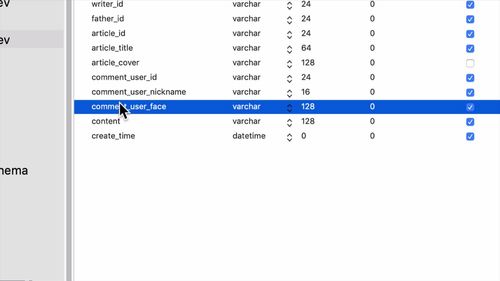
(2)重新生成逆向文件
新的字段生成后,应该“逆向生成到项目中去”。如下三个文件:
找到model模块中的comments类.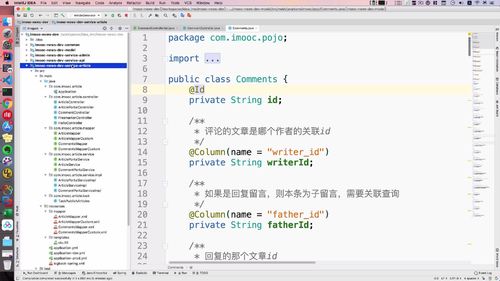
找到article模块的commentsMapper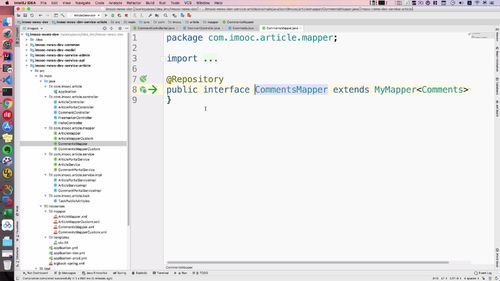
还有xml文件:
这三个就按以前的步骤重新生成即可。
生成前把自己创建的都删掉。因为这里的生成方式是“追加式”,不删除就生成文件会多出一些内容,导致项目报错.
生成后覆盖回去即可!
…
三、补充获取用户头像的逻辑
用户头像跟着之前的 用户昵称 和 用户id 一起保存即可。
主要涉及“评论创建” “评论查询”
1 评论创建 的完善
(1)CommentController的用户评论方法:
46行拿到头像. 54行补充形参
形参也补充上.
写好后去改改service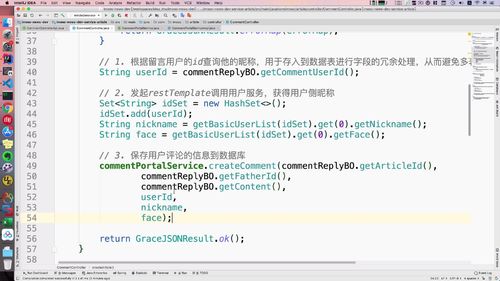
(2)service接口 创建评论 补充字段:15行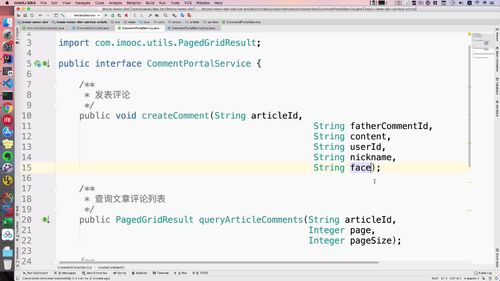
(3)完善service 实现类 创建评论:
53补充形参.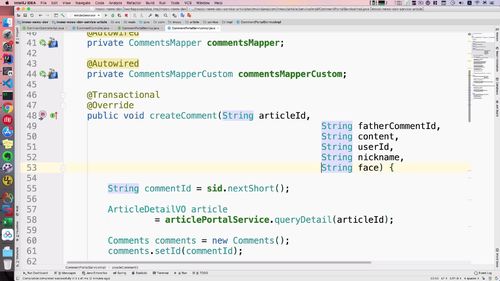
71。设置查询到的头像到comments中去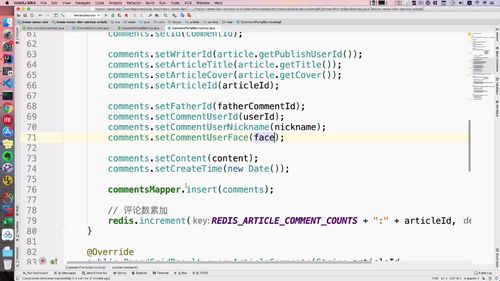
2 评论查询 的完善
(1)完善 评论查询 方法
头像保存好.
xml的14行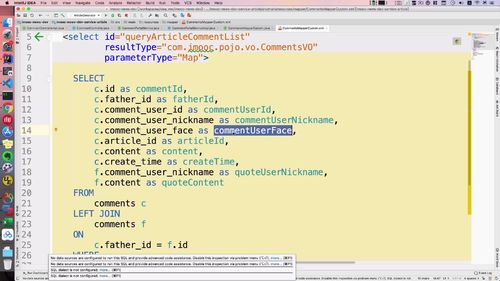
对应的VO也要去加:12,然后生成get/set方法
(2)前端也改改:167
四、测试 8:40
model一定要install的,
图片都不显示了,因为没有.
小结1
截至目前,基础篇开发完毕~~.
(本节课复习完了,可以再来听一听)
—————————————————-
Redis这三个很重要,面试高频.
熟悉一下基于MongoDB的CRUD
这个是本项目的核心业务,毕竟是“新闻网站”.

END

若有收获,就点个赞吧
0 人点赞
