什么是 Delta Lake
传统做法(Lambda架构)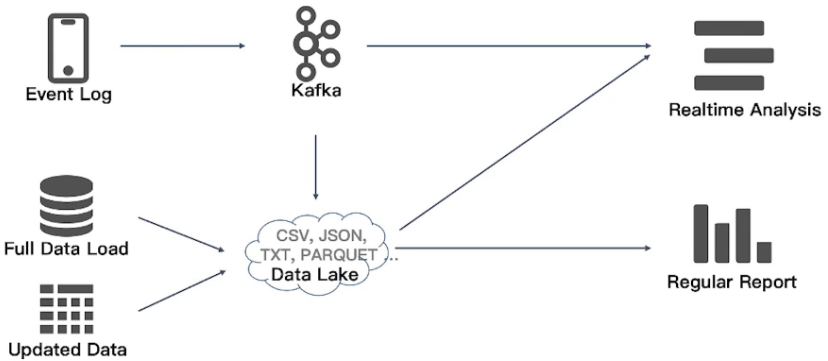
面临的问题
- 数据一致性
- 作业失败,多任务并发
- 数据演化
- Schema变化
- 数据质量保证
- 脏数据的处理
- 流批割裂
- Lambda架构 vs 流批一体架构
如何解决
基本原理
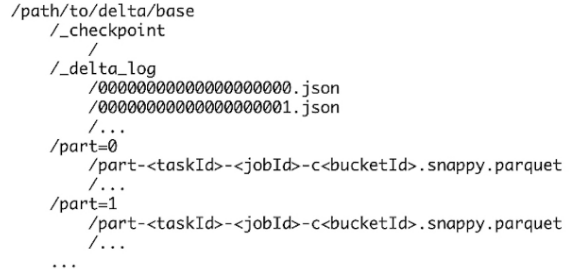
典型架构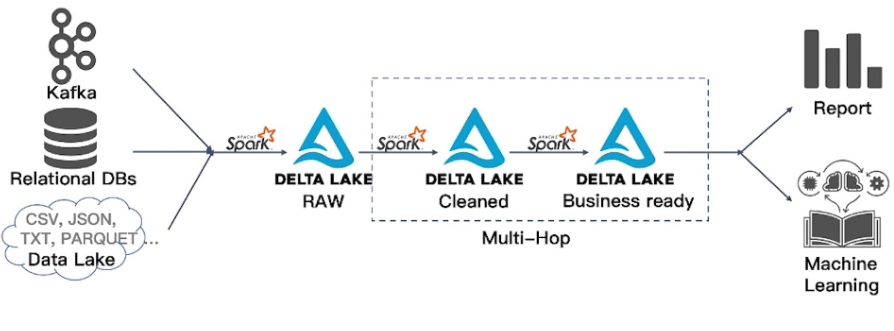
Delta Lake基本功能
数据集 https://www.kaggle.com/wendykan/lending-club-loan-data/data,
loans.csv: 145Cols, 1.11GB unzipped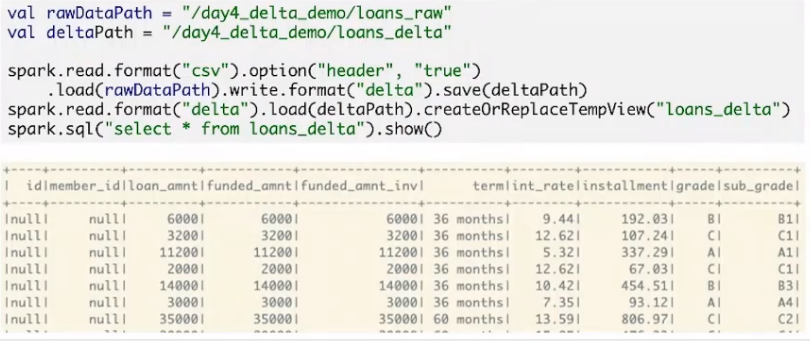
建表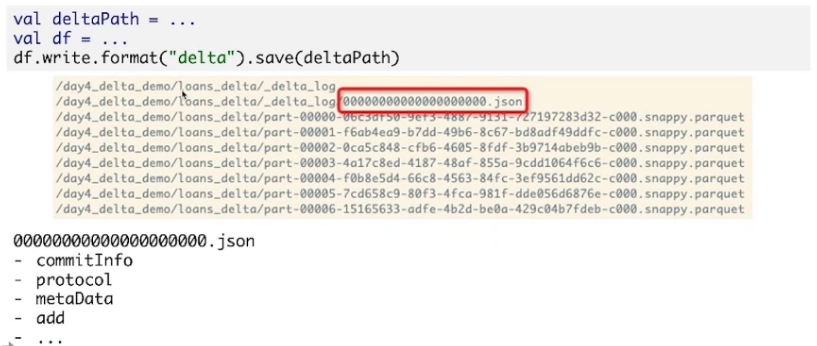
追加
覆盖
Delta Lake API:删除、更新、合并
时间旅行
使用Delta Lake构建分析管道
流读
流写
目标
- 将DB中的表实时同步至数据湖(入湖)
- 对数据湖中的数据计算实时结果并实时更新线上缓存(实时计算)

入湖
- 利用Debeziumn/Canal/DTS 等工具读取 MYSQL binlog 并实时同步至Kafka
- 编写解释binlog格式的UDF(格式与binlog同步工具有关)
- 利用Spark Streming 集合编写的UDF读取Kafka binlog 并实时同步至Delta Lake
Binlog格式(工具相关)
Binlog格式解析UDF
入湖任务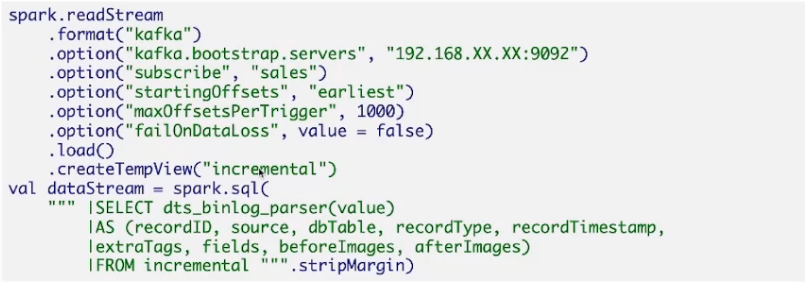

Delta Lake高级功能
Schema校验
- Schema校验是自动进行的,需满足如下条件,否则抛出异常
- 被写入DataFrame的列必须在表中存在
- 被写入的数据列类型必须与表对应列类型匹配
- 被写入的数据列名与表对应列必须相符(大小写不敏感)
- 目前尚没有对于异常数据忽略处理的机制
Schema演化
- 自动Schema更新
- 在write/writeStream中使用.option(“mergeSchema”,”true”)//高优先级
- spark.databricks.deltaschema.autoMerge.enabled 设置为 true //全局设置
- Schema覆盖
- 使用 .option(“overwriteSchema”,”true”)
- 一般在overwrite table时使用
- ADD/CHANGE/REPLACE columns(SQL,需Spark 3.0 配合Delta 0.7以上版本)
- ADD cols支持指定位置,支持struct类型
- CHANGE cols支持更改 col 的 comment,以及调整col顺序
- 如果CHANGE cols的name/type,则需要重写整张表,同时覆盖schema
小文件问题
- 社区并未实现OPTIMZM算子
- OPTIMZM 实际上比较复杂
- DB的OPTIMZM 绑定与DBR(DataBricks Runtime)
- 如果仅仅是合并小文件则可以:

历史审计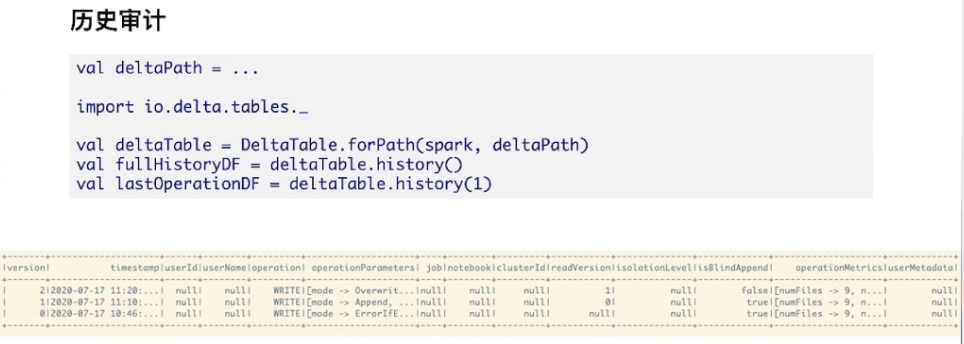
历史清理
- 运行时检查:retention必须大于安全期(delta.deletedFileRetentionDuration,默认7天)
- 强烈不建议关闭运行时检查,或者设置delta.deletedFileRetentionDuration为很小的值!
- Delta Log的清理自动进行(安全期设置delta.logRetentionDuration,默认30天)

问题答疑
参考阅读:https://developer.aliyun.com/article/768353
砖厂孵化,现已开源 https://github.com/delta-io/delta
多个hdfs配置是啥意思?
比如你程序涉及到同时访问多个hdfs集群
这种方式属于单表点对点的采集,多表同时采集,是否消费kafka多次?
是的,如果是多表的话,需要在 kafka 内建多个 topic
那如果源端MySQL是做的DDL alter rename column岂不是会将schema污染?
delta lake 有 schema 更新的功能,但是 schema 更新目前还不支持 rename column。而且,目前这套基于 binlog 的方案也不支持将上游的 rename column 反应到 delta lake 中。
delta lake如何保障事务一致性这块能细说一下吗
事务一致性是说数据库中表内的数据满足一定的约束条件,这块内容属于 OLTP 的范畴,delta 并不支持。delta 支持的事务是说保证并发事务之间不相互污染。您说的一致性是不是分布式存储的一致性?如果是这个的话,是靠底层存储(HDFS,OSS)等来保证的,这两个一致性的含义不一样。
没听懂这块的逻辑,上下游删除更新数据,delta lake 怎么保证啊
上游删除数据,删除数据的动作会被传递到 delta lake 中,delta lake 会同步删除数据。但是以 delta lake 为数据源的 streaming 作业,并不能处理该删除数据的动作,因为删除之前的数据已经被 streaming 处理过了。对于这种情况,以 delta lake 为数据源的 streaming 作业会抛异常。如果要 streaming 作业不抛异常,可以设置忽略 delta lake 中的 delete 事件
delta lake的写出还仍然是文件目录,如果要见hive表的话还得单独建是吗?
是这样的,需要在 hive metastore 中建表。
deltaLake是怎么处理并发读写的问题的?
delta lake 有乐观机制的事务保证,读事务和写事务之间不存在冲突。写写之间可能会有冲突。这个时候先提交的事务会成功,另外一个失败
这个delta lake是要在在这些小文件流批处理场景下替代hive吗?
hive 对流不怎么支持,小文件,如果用 hive 事务功能的话,也会有小文件,但是 delta 的小文件更多的是流产生的,量要比 hive 大。你说在这个场景下替代 hive,我觉着这个说法不太准确。delta 的卖点是对湖中的数据做好管理,支持流批一体。与 hive 还是有区别的。当然 delta 可以代替 hive,反之不行。
delta lake的输出和普通parquet输出目录会多metastote,log灯信息,那么这个输入spark.read.parquet()也可以直接处理吧,需要有什么注意的地方吗?
spark.read.format(“delta”), 不能直接 spark.read.format(“parquet”), 虽然底层是 parquet 文件,但是是两种 datasource。delta 维护了历史版本,因此数据目录下会有多个版本的 parquet 文件。如果把它当成 parquet 直接读的话,数据就不准确了
Delta Lake 是阿里开发的还是开源的 可以读取mysql 数据源 写入到阿里的dataworks吗?
开源的。读取数据库的 binlog,写入到 delta lake
多个topic,那岂不是streaming采集作业也要启动多个?
是的
请问如果mysql中有事务,涉及到修改多张表,采集binlog到kafka消费要怎么可以保持消费的顺序呢?
这个没有办法保证,只能保证最终一致性
在追问下哈,如果是这样的话,那么创建hive表,导入delta lake输出数据的话有什么注意的吗?delta lake产生的数据源怎么能解开耦合呢?不会只能delta lake处理吧
你是要把 delta lake 的数据导入 hive 吗?其实不用这么做,可以直接建 hive 表,然后使用 delta 特定的 storage handler,就可以用 hive 查 delta 了。具体参考 https://github.com/delta-io/connectors

若有收获,就点个赞吧
0 人点赞
