Spark SQL介绍
Spark SQL is Apache Spache Spark’s module for working with structured data.
- 灵活易用
- 功能强大
- 生态丰富
Spark演进的基础模块

hadoop与spark接口设计代码复杂度对比
RDDs、SQL、DataFrames 介绍
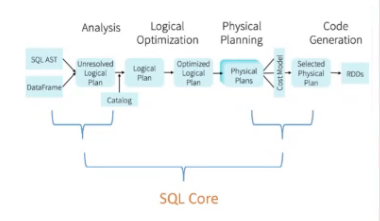
Spark SQL/任务执行流程

Catalyst介绍**
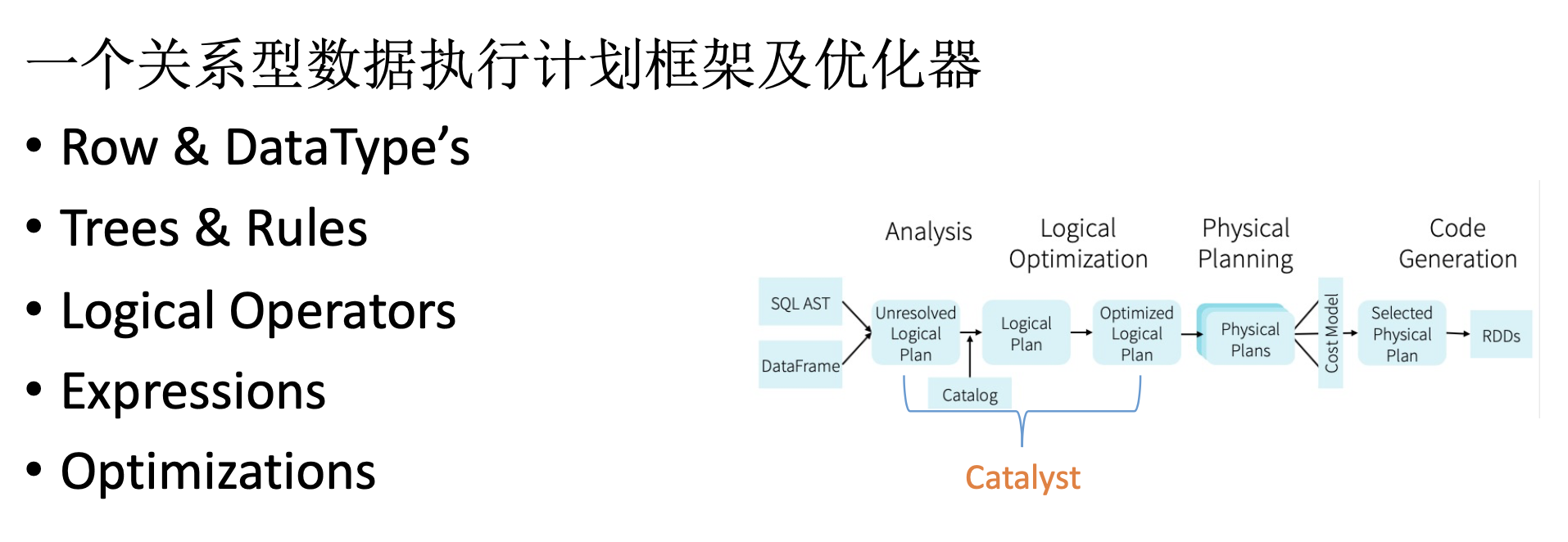
一个关系型数据执行计划框架及优化器
- Row & DataType’s
- Trees & Rules
- Logical Operators
- Optimizations
Catalyst介绍:Row & DataType’s
o.a.s.sql.catalyst.types.DataType
- Long,Int,Short,Byte,Float,Double,Decimal
- String,Binary,Boolean,Timestamp
- Array,Map,Struct
o.a.s.sql.catalyst.expressions.Row
- Represents a single row.
- Can contain coomplex.
Catalyst介绍:Tree & Rules
- o.a.s.sql.catalyst.tree.TreeNode
- 一系列的针对树的转换操作。
- foreach,map,flatMap,collect
- transform,transformUp,transformDown
- 包括operator,tree,expression tree.

- o.a.s.sql.catalyst.rules.Rule
- 通过Rule将一个执行计划转换成另外一个逻辑等价的执行计划。
- o.a.s.sql.catalyst.rules.RuleExecutor
- 一个执行Rule的引擎,根据配置的规则,确定执行rule的顺序,批次,收敛条件等。
Catalyst介绍:Operators
- Basic Operators
- Project,Filter,…
- Binary Operators
- Join,Except,Intersect,Union,…
- Aggregate
- Generate,Distinct
- Sort,Limit
- InsertInto,WriteToFile

Catalyst介绍:Expressions
- Literal
- Arithmetics
- UnaryMinus,Sqrt,Maxof
- Add,Subtract,Multiply,…
- Predicates
- EqualTo,LessThan,LessThanOrEqual,GreaterThan,GreaterThanOrEqual
- Not,And,Or,In,If,Case When
- Cast
- Getltrm,GetField
- Coalesce,IsNull,IsNotNull
- StringOperations
- Like,Upper,Lower,Contains,StartsWith,EndsWith,Substring,…
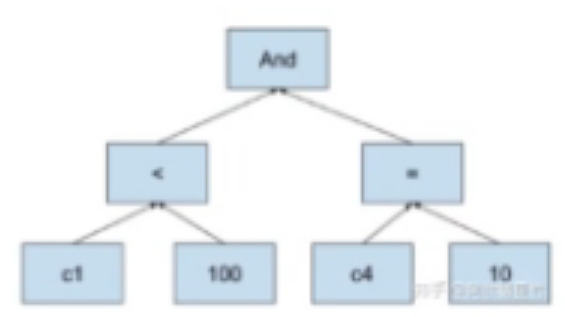
Catalyst介绍:Optimization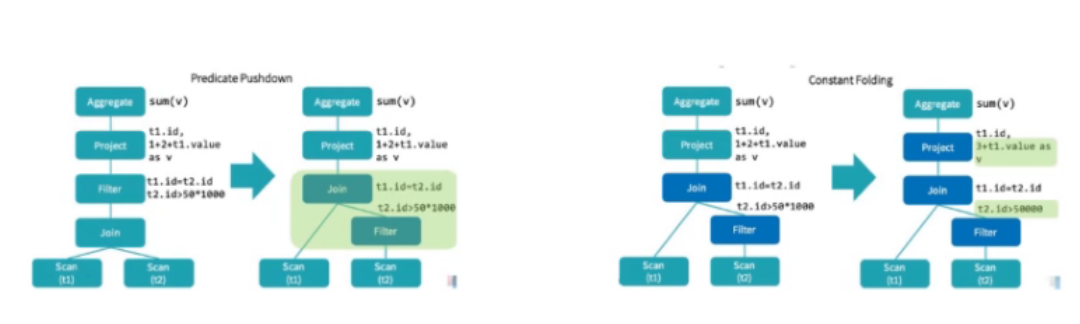
SQL Core**
- DataFrame/DateSet DSL
- SQL Analyzer
- Catalog/Data source
- 物理执行计划及优化
SQL Core:DataFrame API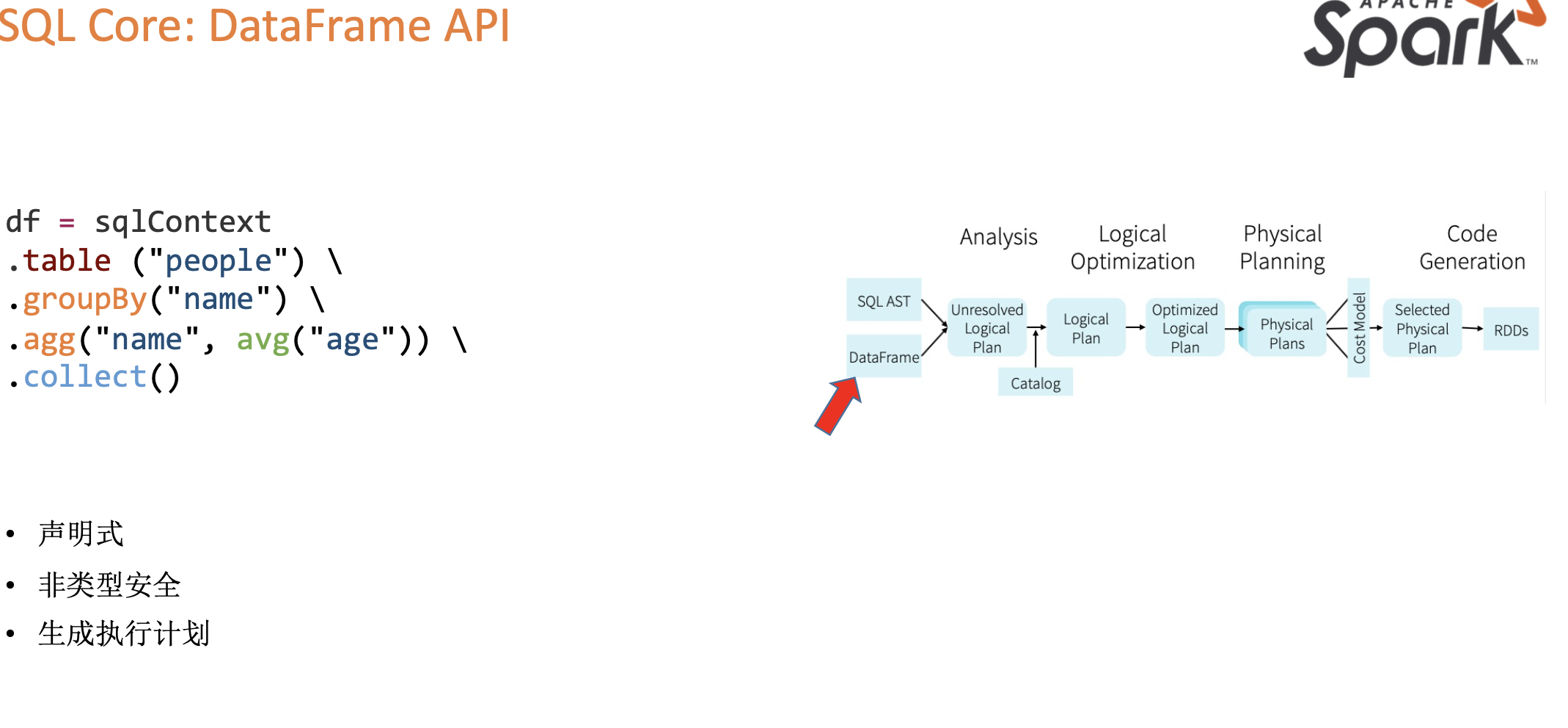
SQL Core:Analyzer
SELECT name,AVG(age) FROM people GROUP BY name;
- 基于Antlr4的词法解析。


SQL Core:Source
df = sqlContext.read \ .format(“json”) \ .option(“samplingRatio”, “0.1”) \ .load(“/home/user/data.json”) df.write \ .format(“parquet”) \ .mode(“append”) \ .partitionBy(“year”) \ .saveAsTable(“fasterData”)

https://spark.apache.org/docs/latest/sql-data-sources.html
SQL Core:Physical Plan
- 由SparkPlanner来对Optimized Logical Plan进行转换,生成Physical Plan
- 转换Operator到Sparklan。
- 插入Exchange。
- 生成执行计划
问题答疑
能在讲讲RDD和dataframe/date set吗?有点模糊
不要把RDD看作存放特定数据的数据集,把每个RDD当作我们通过转化操作构建出来的、记录如何计算数据的指令列表
请问一下刚才说的那个优化,是说把小表可以广播到每个节点,再进行join吗
是的,大表就不用shuffle了
请问老师后面讲到阈值大小的问题,把阈值从10M调高到20M的主要目的是什么?
为了能实现broadcast吧,把小表的限制阈值调大
演示这个阈值是怎么控制jion策略的
是本来有一个默认的上限么?
默认值就是10M,调太大了会oom,和executor内存配置配合调整
想问下老师,比如需要统计某个时间范围内,客服对用户的消息回复率,用sparksql这块处理是否合适呢,老师可以提供一下大概思路吗
怎么写mysql,就怎么写sparksql,业务逻辑的表达都是一样的
dataframe和dataset,这两个区别
dataframe=dataset[row],始终特殊类型的dataset,专门处理关系型数据,处理的数据有schema信息,所以可以优化执行计划
explain 通用的吧
是的,可以加在所有query前面
能讲一下这四种Broadcast Hash join Shuffle Hash Join Sort-Merge Join Shufffle Nested Loop Join 对应的应用场景吗
按shuffle类型分为map, shuffle,bucket join.按执行算子可以分为sortmerge, hash, nestedloop,这两种是正交的
Catalyst 会进行sql的优化,那么是否sql可以不必优化只要表达出想做的的操作就可以么?@李呈祥(司麟)(李呈祥(司麟)) 大佬,能麻烦看看这个问题么?还有就是sparksql既然通过优化以后会转化成RDD去执行计划,是否RDD在处理速度上会更有优势?尤其是面对复杂的逻辑的时候。
SQL就是个表达是的语言,具体一个SQL怎么变成一个高效的分布式spark任务就是catalyst做的事情。理论上自己基于rdd可以做到最优,但是绝大部分人没有这个水平,不如用sparkSQL,简单高效
spark 的输出的 INFO信息太多了
sparkSession.sparkContext.setLogLevel(“warn”) //设置日志级别

若有收获,就点个赞吧
0 人点赞
