什么是 数据仓库
概念
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented),集成的(Integrated)、相对稳定的(Nov-Volatile)、反映历史变化的(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
-- 数据仓库之父 比尔.恩门<br />**面向主题(Subject Oriented)**
传统数据库使用的是OLTP(联机事务处理方式)、进行数据组织时只需要考虑每一笔业务的情况,例如订单创建、付款。
- 数据仓库使用的是OLAP(联机分析处理方式),进行数据分析时,已主题为单位组织数据,例如商品用户。
- 面向主题的数据组织方式要求将数据按照一定的主题域进行关联,通过建模的方式将数据关联起来,如用户行为(浏览、交易、论坛等)通过用户ID将数据关联起来进行数据组织、分析用户特征、进行风险识别、商品推荐;各个主题域之间有明确的界定,各个主体域内部需要包含分析处理所需要的一些数据(完备性)。
数据源集成(Integrated)
- 数据仓库将不同的数据源,如数据源、日志、一般性数据文件,集成在一起。
- 多个系统数据进行计算、整理,保证数仓中对数据的定义是全局的、统一的,保证数据一致性。
相对稳定的(Nov-Volatile)
- 数据操作的方式主要是插入和查询,修改和删除操作较少;
- 数仓的数据与生产环境的数据是分离的,不需要生产操作环境下的事务处理和并发控制;
- 数据时效性要求不高,常用于T+1的离线分析场景:(当前的数据分析对时效性要求越来越高衍生出很多新的数据架构,如Lambda/Kappa架构)
反映历史变化的(Time Variant)
- 数据仓库记录从过去某一个时间点到当前的各个阶段信息,通过这些信息,可以分析出企业发展过程中的发展趋势,并对未来做出定量分析和预判;
- 数据仓库的数据隐式包含时间元素,并随着时间的累加数据长期积累,数据量也越来越大;
- 顶起进行数据归档,按天/周/月进行数据归档 ,降低历史数据分析的成本;
数据决策(Decision Making Support)
- 整合公司所有的业务数据,建立统一的数据中心;
- 生成数据报表,用于决策,也可为运营提供数据上的支持;
- 分析用户行为数据,通过数据挖掘来降低投入成本,提高投入效果
数据分层
- 源数据
- 数据仓库
- 数据应用

- AMD Application Data Mart, 面向应用的数据集市层,承担个性化的标签加工,以及基于应用需要的数据组装,主要是大宽表。
- DWS Data Warehouse Summary,数据仓库汇总数据层;构建命名规范,口径一致的公共统计指标;
- DWS Data Warehouse Detail,数据仓库明细数据层;基于维度建模,建设明细表,复用频繁关联,减少数据扫描;
- DIM Dimension , 维度表,包含分析数据的维度和属性;建立一致性维度,降低数据计算口径不统一的风险;
- ODS Operational Data Store , 操作型数据存储:1、承担结构化数据增量或者全量同步到数据仓库系统;2、非结构化数据结构化并存储到数据仓库系统;3保存历史数据和清洗数据;
数据模型(多维数据模型)
- 这个模型把数据看成是数据立方体形式。多维数据模型围绕中心主题组织,该主题用事实表表示,事实表是数值度量的。
- 数据立方体允许多维数据建模和观察,它有维和事实定义。
- 维是关于一个组织想要记录的视角或观点,每个维都有一个表与之关联,称为维表。
- 事实表包括事实的名称和度量,一个n维的数据立方体叫基本方体。给定一个维的集合,可构造一个方格,每个都在不同的汇总级或不同的数据子集显示数据,方体的格称之为数据立方体。0维方体存放在最高层的汇总,称之为顶点方体;存放在最底层的汇总的方体则称之为基本方体。
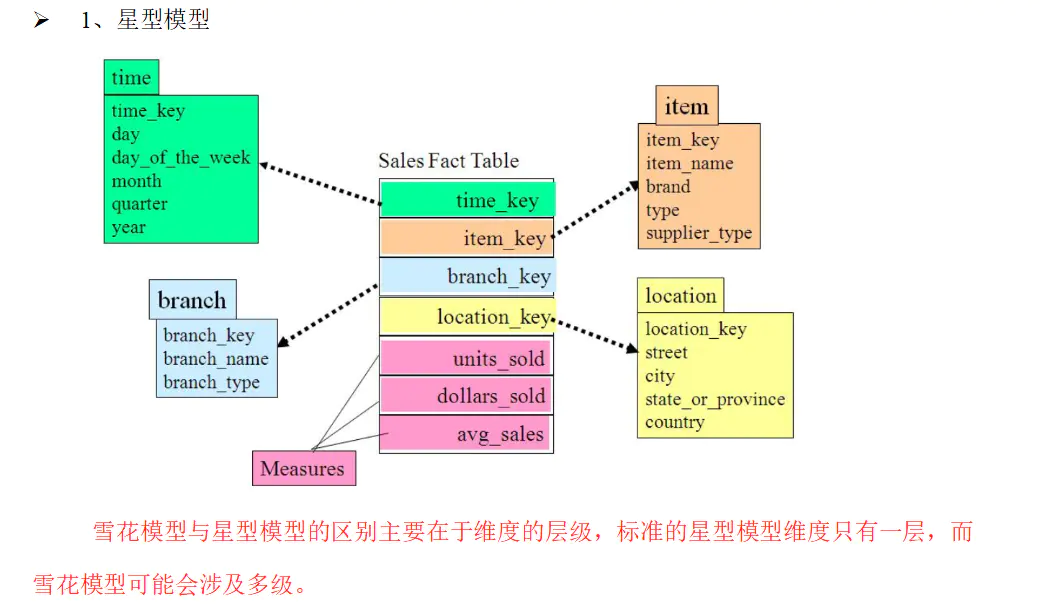
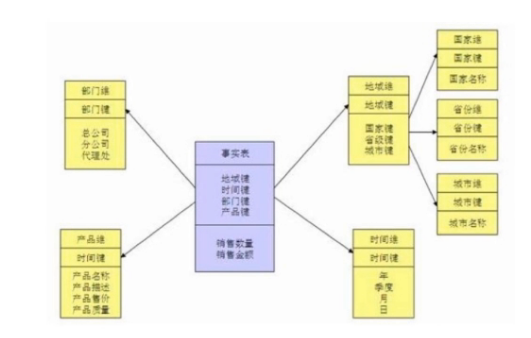
星型数据模型
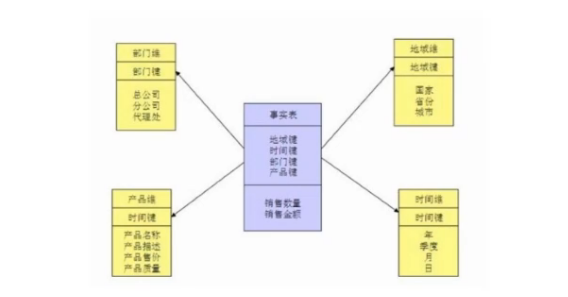
- 星型模型是多维的数据关系,它由事实表(Fact Table)和维表(Dimension Table)组成。每个维表中都会有一个维作为主键,所有这些维的主键结合成事实表的主键。事实表的非主键属性称为事实,他们一般都是数值或其他可以进行计算的数据
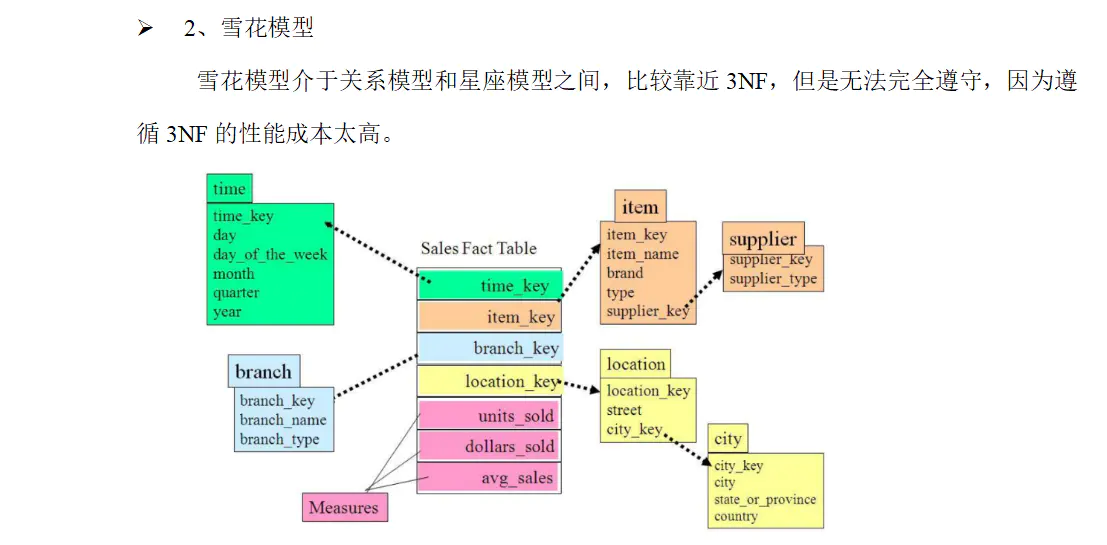
星型数据模型
- 雪花模型是有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。
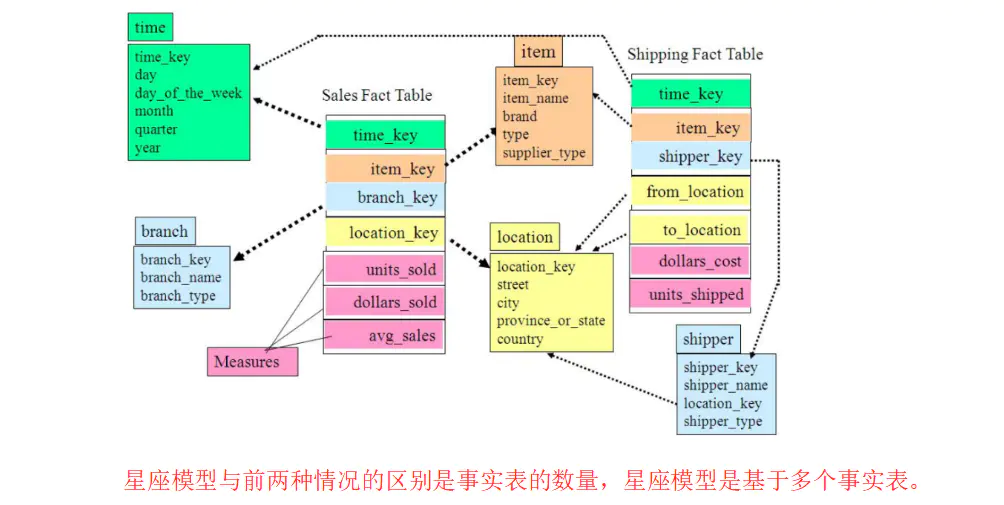
星座模型(补充)
- 星座模型需要多个事实表共享维度表,因而可以视为星形模型的集合,故亦被称为星系模型。
基于SQL的数据分析模型
- SQL丰富的语义表达能力+UDF扩展能力
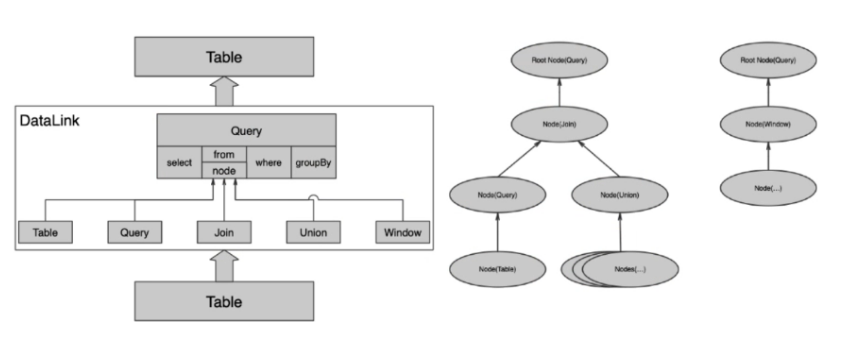
数据血缘关系
- 通过血缘分析实现数据融合处理的可追溯。
- 通过血缘分析提高数据复用率,降低成本。
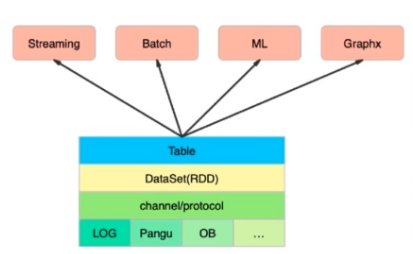
数据仓库的体系结构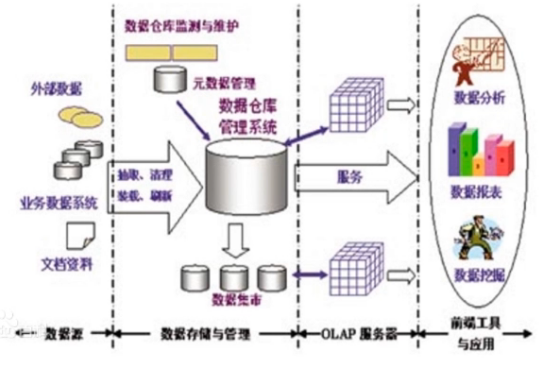
数仓的技术体系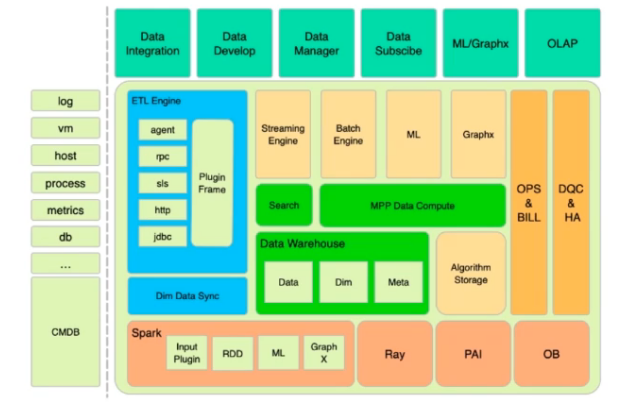
基于Spark集成数据源(ETL)
与数仓的Match的Spark技术栈(ETL/SQL/OLAP)
E(Extract)T(Transform)L(Load)
- E:数据抽取,将数据从原始数据中抽取出来;
- T:数据转换,将数据结构化;
- L:数据加载,将数据加载到目的端(存储);
Word count

What happens ?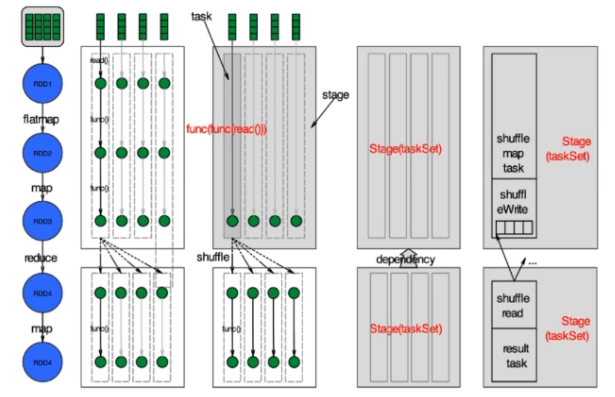

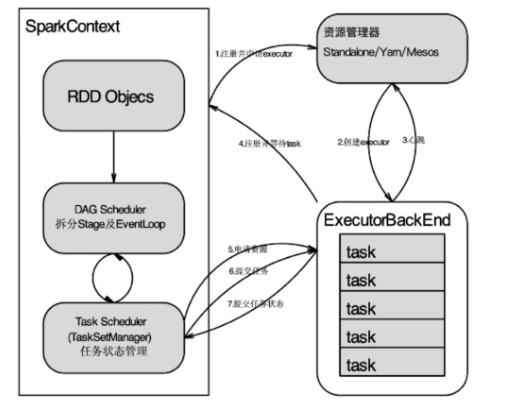
RDD如何抽取数据(jdbc RDD):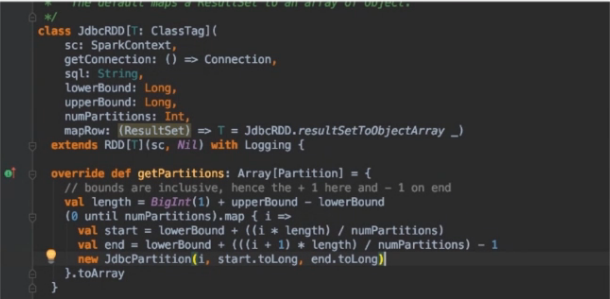

RDD如何抽取数据:
- org.apache.spark.rdd.JdbcRDD#getPartitions
- 构建数据分片信息
- org.apache.spark.rdd.JdbcRDD#compute
- 根据分片信息加载对应分片的数据
- org.apache.spark.rdd.JdbcRDD#getPreferredLocations
- 根据分区信息选择合适的执行节点(executor)
思考 —自定义RDD:
- N个分区
- 每个分区返回 100partitionid~100partitionid-1之间的数据集合
Custom Spark Steaming
- Receiver模式
- Direct模式
Spark Steaming 调度流程

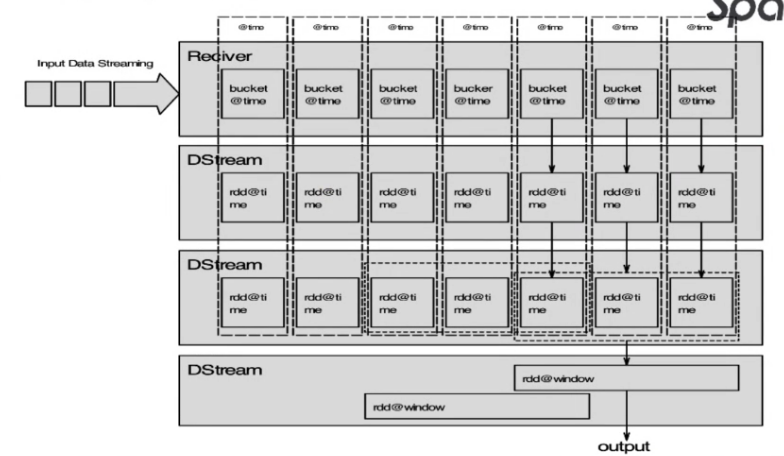

Receiver模式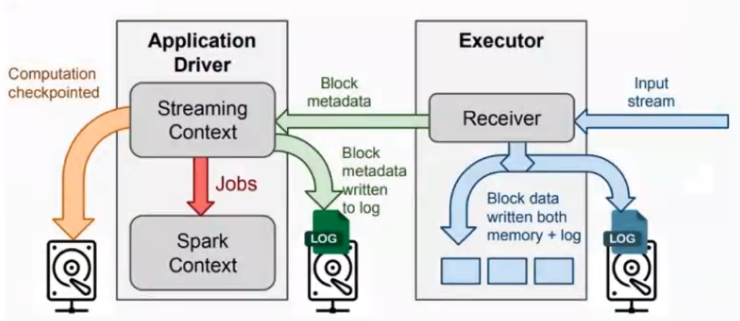
Receiver Mode Example
// Create the context with a 1 second batch size SparkConf sparkConf = new SparkConf().setAppName(“JavaCustomReceiver”); JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, new Duration(1000)); // Create an input stream with the custom receiver on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by ‘nc’) JavaReceiverInputDStream
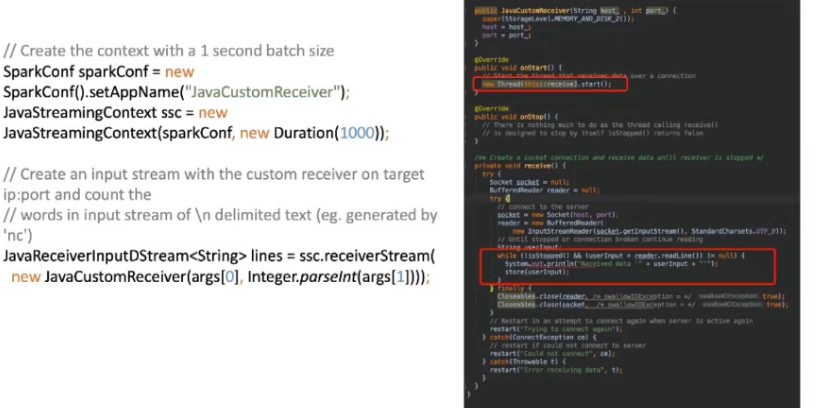
Receiver 核心接口:
- org.apache.spark.Streaming.receiver.Receiver#onStart
- Executor上执行,启动Receiver接收数据
- org.apache.spark.Streaming.receiver.Receiver#store
- 将数据写入缓存,Transform从缓存中获取数据
- org.apache.spark.Streaming.receiver.Receiver#preferredLocation
- Receiver执行Executor列表
Direct 模式下的运行架构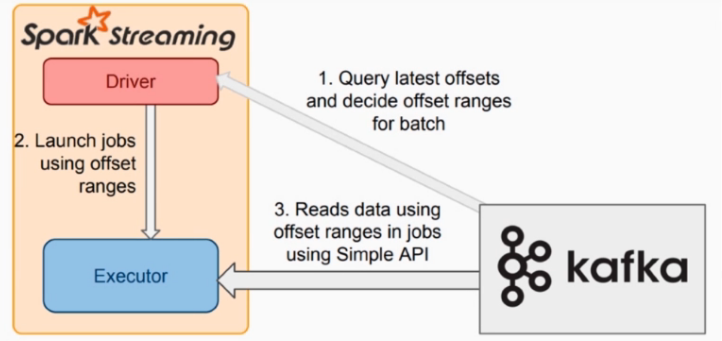
Direct Mode Example
InputDSteam核心接口:
- org.apache.spark.streaming.kafka010.DirectKafkaInputDStream#compute
- Direct上执行,Stream Scheduler按照时间驱动调度该方法,获取执行周期的RDD对象
基于Spark SQL 进行OLAP分析
常见OLAP开源引擎
- Hive、Hawq、Presto、Kylin、Impala、Druid、Clickhouse、Greeplum等等。
Spark SQL的优势
- 与Spark无缝体系,不需要额外的学习成本。
- Spark SQL可复用Spark RDD 各种数据源,扩展性高,能够对各种数据源进行OLAP分析;
- 支持UDF
- 智能算法/图计算
- Executor上执行,启动Receiver接收数据
Example
Spark SQL执行过程
总结
1. 数据仓库解决了什么业务问题,它和传统数据库的区别是什么?
2. 对数据仓库的基础架构有大致的了解。
3. 使用 Spark 可以构建数据仓库的哪些核心能力?
4. 如何使用 Spark Core/Streaming 扩展数据源?
5. 如何使用 Spark 进行 OLAP?
问题答疑
spark sql适合复杂的ETL分层的逻辑么。我看好多都是用hive写的。
答:你指的分层具体指什么,中间表临时表嘛
问:是的,ODS->DWD->DWS-ADM中的处理逻辑。
答: ODS->DWD->DWS->ADM 描述的是数据的分层,是为了方便进行数据管理的,更偏理论;实际应用的时候其实概念并不是 太强;SQL 只是用来连接表与表之间的计算关系,和实现这个数据分层并没有直接关系
现在经常提到的数据中台和数仓之间是怎样的关系?
侧重点不一样,中台更强调服务,是业务和数据的连接层
从etl到事实表维表过程中,etl的结果也会在数仓中吗? 那对于数据源表新增字段等ddl,有什么解决办法吗?
其实你问了一个比较细节的技术问题,表结构变化了,原始数据怎么处理;其实这个要看具体的存储模块能不能解决了;新增字段这种场景下,如何能够兼容老的数据结构(新增字段自动填充null),就可以解决;
那碰到复杂的ETL逻辑的时候,比如说生成大宽表的时候,通常都是上百个字段,那spark sql适用这类的复杂逻辑么?
看你自己接受程度吧,理论上SQL是能够表达的,但是处理太过复杂;我们自己的场景下就有100+字段的数据,但是我们不是用的SQL,我们自己定义的一套计算模型;
模型化的数据可以使用程序自动生成,对于这种上百列的数据任务处理起来会更容易一点;
Spark sql能否实现表结构的合并、基于原有属性派生新属性等较复杂的数据转换操作?
自定义 UDF 能解决你的这个问题吗
在spark中能基于ETL后的数据构建多维数据集吗?
答:多维数据集具体是指什么样的形式呢,能具体解释一下吗
问:微软的SSAS能构建多维数据集,多维数据集的形式就是您前面讲的星型模型或雪花模型,多维数据集中的数据以多维的形式而不只是二维的形式展示
答:时间+多维+事实列 构成了多维数据模型,数据处理的方式还是用 SQL 进行的
关于元数据管理,有哪些比较好的方案吗?
答: 你指的是维表数据,还是表信息相关的元数据
问:表信息相关的元数据。
答:spark 默认提供了 Hive 的元数据,可以直接基于 Hive 管理元数据;
如果你是想自己管理元数据的话,很复杂,看你们自己的业务需要,投入产出比;
增量ETL时,处理源数据删除的数据有什么思路吗?
答: 这是个数据建模的问题;如果你的数据是操作型的数据,可以把操作类型作为一个维度进行管理;计算分析的时候把操作类型作为选择分析方式的一个条件
问: 这个可以理解为,要修改etl处理source部分的处理逻辑吗?
答: 我没实际处理过这种问题;只能是探讨一下,原始数据是操作类型的数据,包含了删除等动作,在构建 明细表的时候,就可以是 以这种流水型的数据进行建模;创建一条记录->更新有一条记录->删除一条记录;根据行为进行数据的计算分析;

若有收获,就点个赞吧
0 人点赞
