Spark支持部署模式
- local
- Standalone
- Yarn
- Mesos
- Kubernetes
Spark Application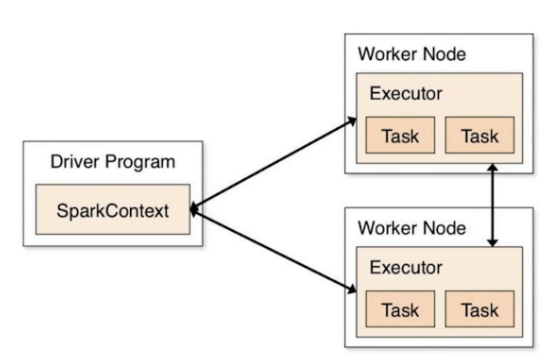
Spark Deploy Mode
Spark Standalone-Client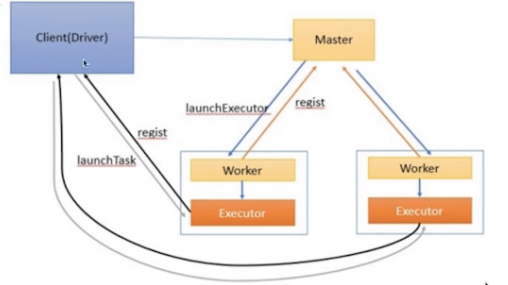
Spark Standalone-Cluster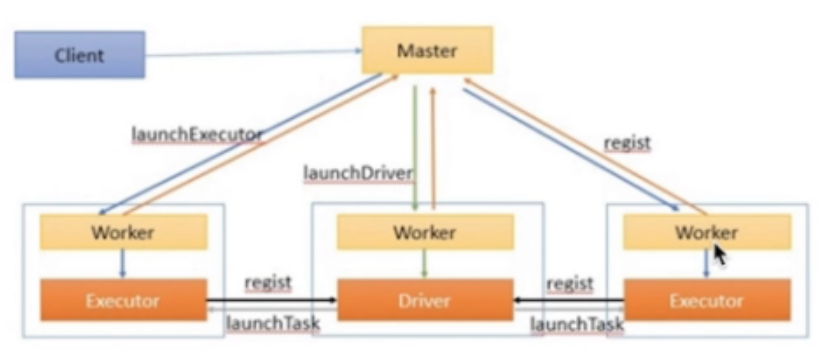
Yarn Application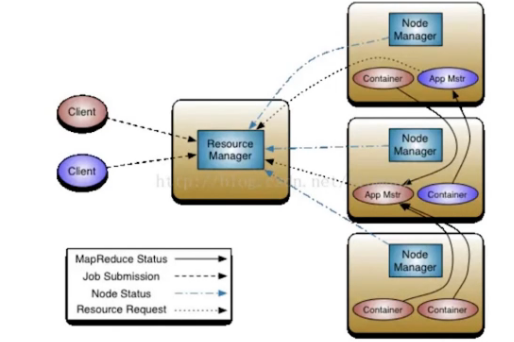
Spark Yarn-Client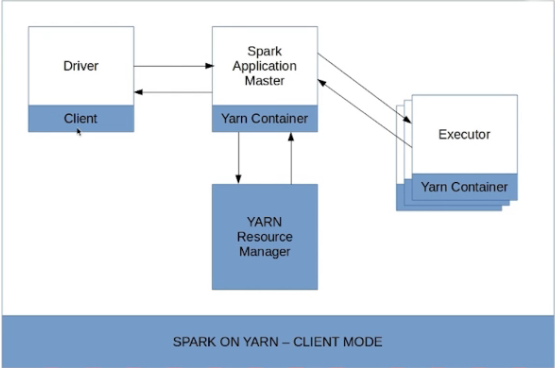
Spark Yarn-Cluster
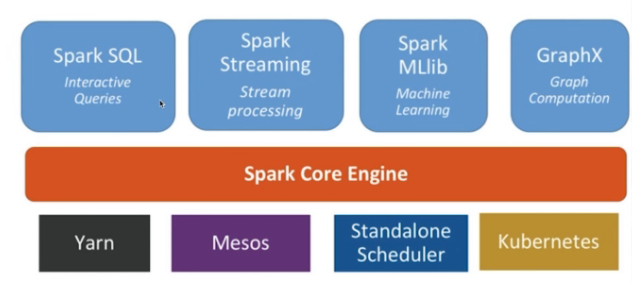
Spark 各功能模块
- Spark-Core-RDD 相关
- Spark-SQL/Hive: DataFrame API
- Spark-ML: 机器学习API
- Spark-Graphx: 图计算
- Spark-Yarn/Messos/k8s: 调度相关

添加mvn依赖
打包
- 分为设置main.class打包和不设置main.class打包,需要注意依赖

简单的wordcount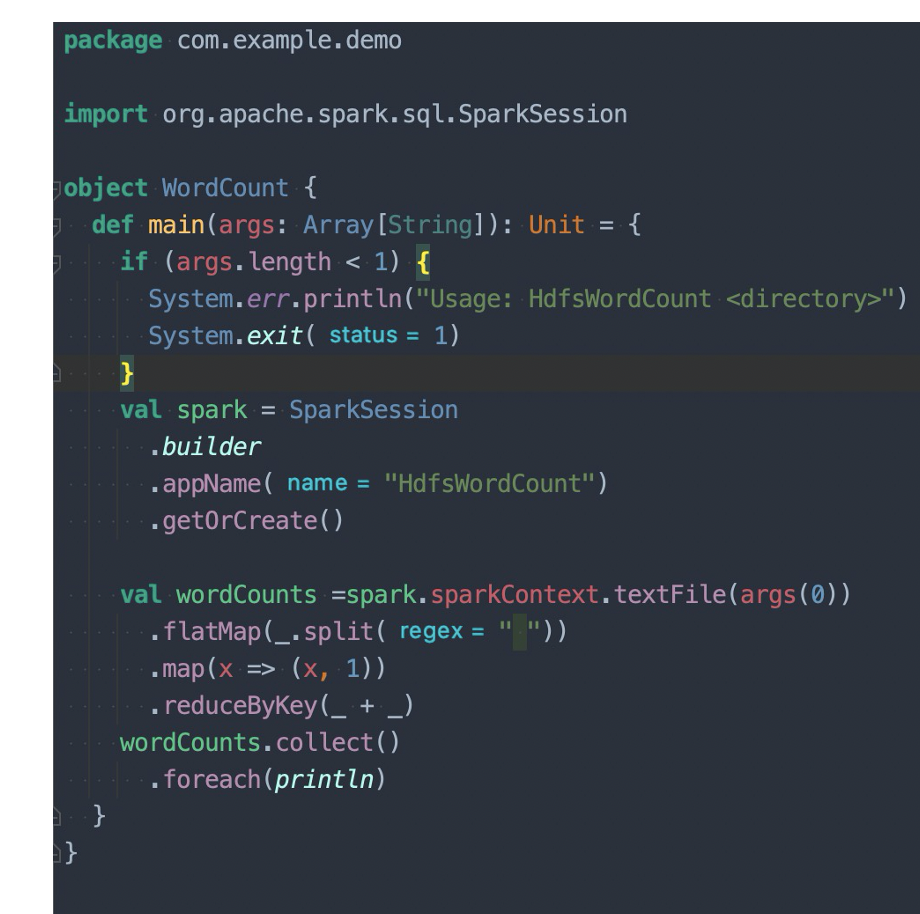
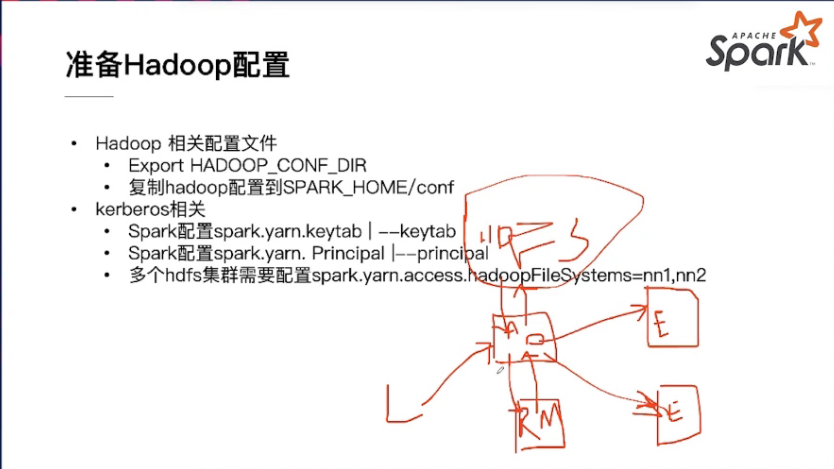
准备Hadoop配置
- Hadoop相关配置文件
- Export HADOOP_CONF_DIR
- 复制hadoop配置到SPARK_HOMe/conf
kerberos相关
- Spark配置spark.yarn.keytab | — keytab
- Spark配置spark.yarn.Principal| — principal
- 多个hdfs集群需要配置spark.yarn.access.hadoopFileSystems=nn1,nn2
准备Hive配置
- Driver CLASS_PATH需要有hive-site.xml
- 复制hive-site.xml 到SPARK_HOMe/conf
- 打包的时候带入hive-site,xml(不推荐)
- Spark打包的时候hive版本和集群版本需要一致
- 通过设置spark.sql.hivemetastore.jars=/hive/jar/*
常用进阶配置
- 设置启动时的JVM参数
- spark.yarn.am.extraJavaOptions
- spark.driver.extraJavaOptions
- spark.executor.extraJavaOptions
- 设置spark.yarn.dist.files 可以把executor代码运行需要文件分发
- eventing相关配置,可以方便诊断
- spark.eventLog.enabled
- spark.eventLog.dir(hdfs路径必须带上schema,否则默认访问本地文件系统)
Spark读取配置优先级
- 读取代码设置
- 提交任务使用 -conf设置
- spark-defaults.conf
Demo
- 相关资源
- 集群环境
- Spark2.4.5 , .Hadoop2.8.5 , Hive2.3.4 . 可自建或阿里云EMR3.38.2版本。
- 部署相关模板:https://github.com/hn5092/spark_package_template
问题答疑
多个hdfs配置是啥意思?
比如你程序涉及到同时访问多个hdfs集群
eventlog主要是记录什么来的?
spark是基于事件机制设计得, 这event log 相当于会记录这个程序运行得状态 hisotry相当于把这个状态replay一遍,就可以看到类似运行时候spark-ui得样子得
spark.yarn.dist.files 和spark-submit的—files 有什么区别么?
都是一样得 只是设置方式不一样
如果访问带kerberos的多个集群 需要手动指定 kerberos选项
Session不需要制定master地址吗?
一般master都是 spark-submit —master 来动态选择得 很少会写死
spark部署找机器资源。自己调度那怎么看日志?
答: 这个问题不是很明白
问:这个提交到yarn上可以看日志吧。spark集群模式部署。那怎么知道看日志信息?
答:看driver还是executor
driver日志可以看 yarn 里面的 application master 日志, executor日志 spark-ui/executors可以看,
运行结束得程序可以yarn logs -applicationId
spark在涉及读取hdfs上数据的时候是把数据加载到worker节点上,还是在数据所在的节点上启动计算的进程?
spark里面task读取文件一般是通过filesystem的流来读取得, 可以读取本机器hdfs或者其他文件系统得文件 也可以读取其他机器的文件.spark 的schedule会优先把task调度到这个task需要读取文件的机器上,这样的话就不会产生网络流量,减少集群带宽压力,而且读取当前机器的文件这个行为在不同的文件系统可能还会有更多的优化
问:这应该是rdd的其中的一个特性吧。
这个就是任务的locality 基本计算框架都有类似优化

若有收获,就点个赞吧
0 人点赞
