什么是Apache Spark
Apache Spark是一个开源集群运算框架,最初由加州大学柏克莱分校AMPLab开发。
- 开源
- 高性能,基于内存进行数据处理的
- 易用,支持R、Scala、Java等
- 通用,支持批处理、流处理、机器学习等多种场景
Apache Spark生态
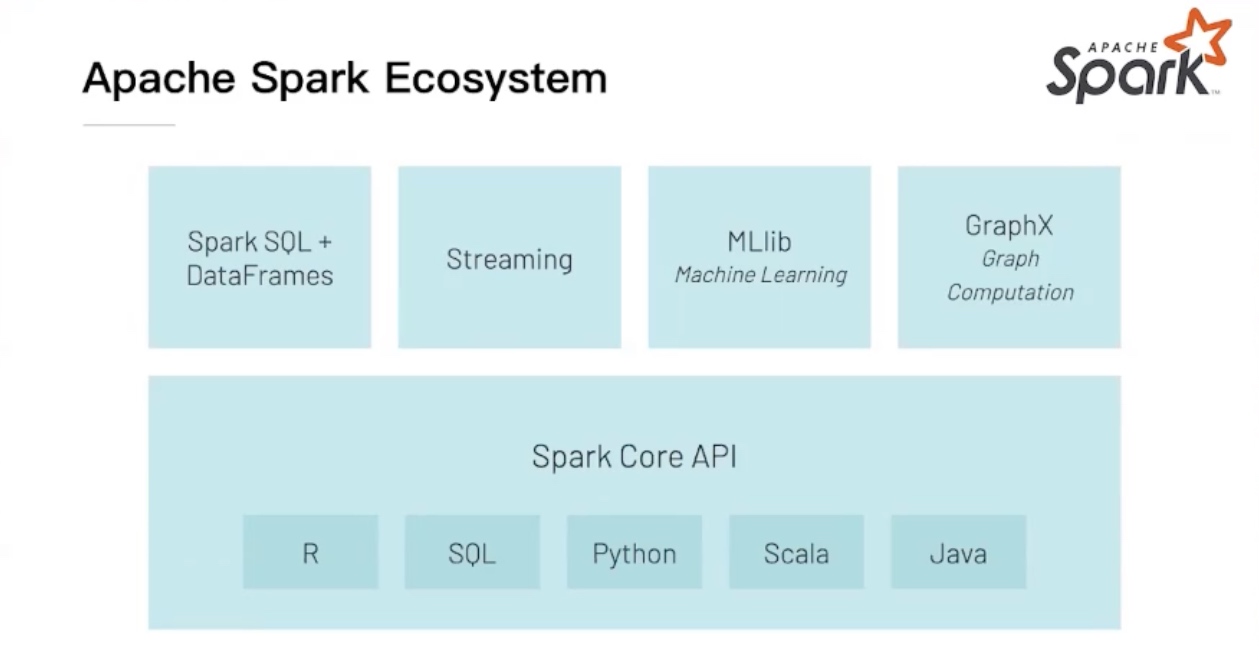
上层模块,根据场景来设计:
- Spark SQL + DataFrames 处理结构化数据的
- Streaming 支持流式场景的模块
- MLlib 机器学习模块
- GraphX 图计算模块
底层模块,Spark Core API,所有的场景模块都是基于这一核心进行设计的,也是Spark最原始的模块,多语言支持便由它来提供。
Apache Spark架构
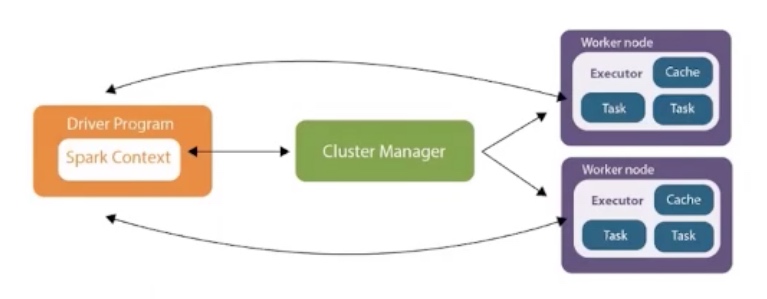
在Spark中,比较核心的有三块
- Driver
- 运行作业主函数
- 创建SparkContext(SparkContext的作用是:帮助程序使用spark提供的一些功能)
- Cluster Manager(目前为止支持以下四种,主要的作用有两个:分配资源、把Driver要执行的任务分配到对应的Executor)
- Standalone
- Mesos
- K8S
- Yarn
- Executor(执行任务的实际进程)
- 执行task
- 处理rdd一个分区的数据
整个执行流程:
写好程序 -> 在Driver端跑起来了 -> 通过Cluster Manager申请到了资源 -> 将任务调度到了Executor上
其他基本概念
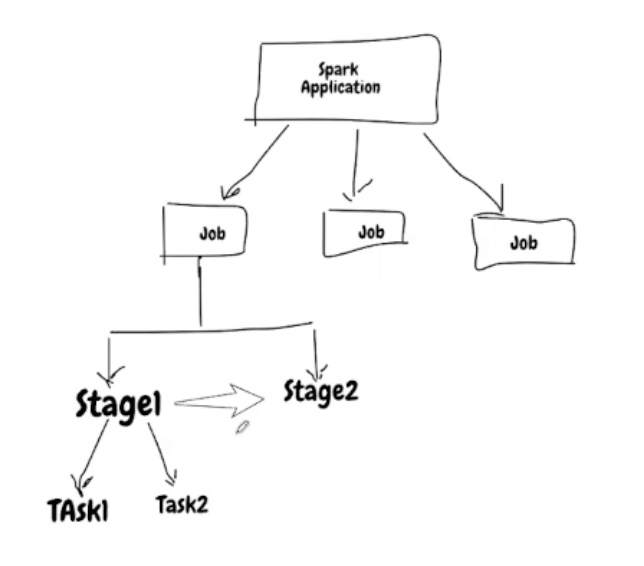
- Spark Application
- 用户写的Spark应用程序
- Job
- 一个application会生成多个job
- Job直接可以有依赖关系
- 可以并行执行
- Stage
- 一个job会有多个Stage
- Stage之间可以有依赖关系
- 可以并行执行
Task
- 任务执行的最小单元
SparkContext & SparkSessionSparkContext是Spark2.0以前应用运行入口
- 一个进程只能有一个
- SparkSession是Spark2.0之后的应用运行入口
- 支持SparkContext的特性
- 支持操作dataframes

Spark API的历史

RDD
RDD是Spark最核心概念,基础数据结构,全称:弹性分布式数据集(Resilient Distributed Datasets)
其特点是:
- 基于内存
- 延时计算
- 容错
- 只读
只分区(实现分布式计算)
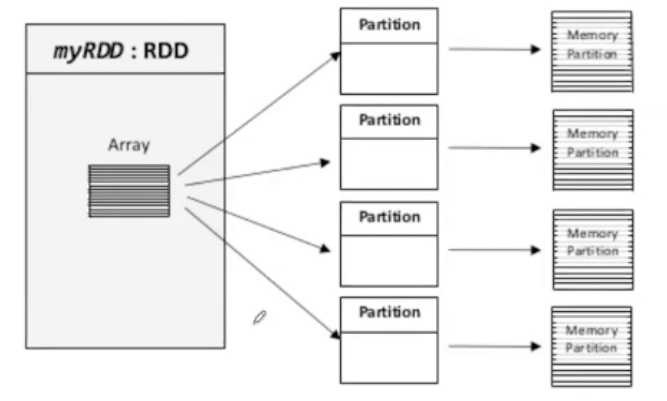
创建RDD的两种方式
- 在driver中对已有集合进行并行化
- 基于外部数据源生成



RDD :Operations
- RDD操作类型1:Transformations 基于已有的RDD生成新的RDD
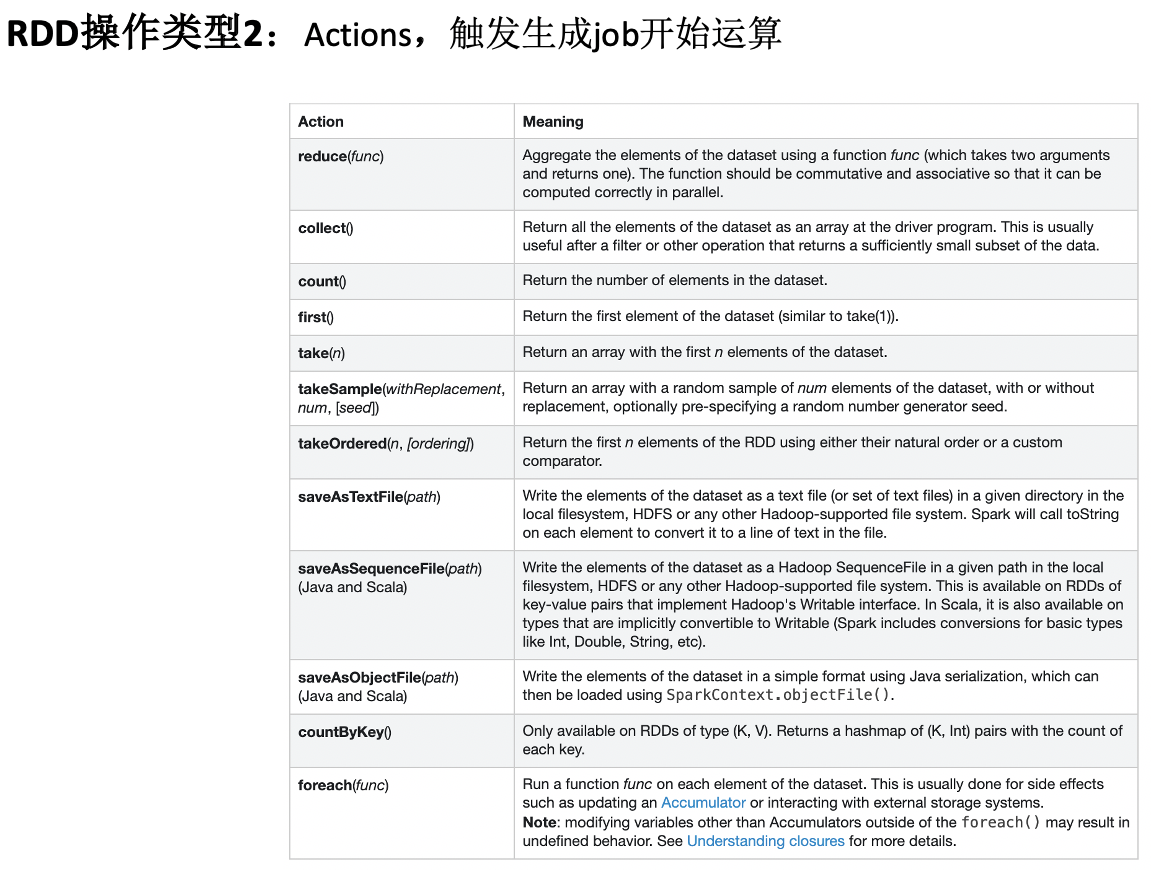
- RDD操作类型2:Actions 触发生成job开始运算

Local Cluster
Spark UI :http://localhost:4040
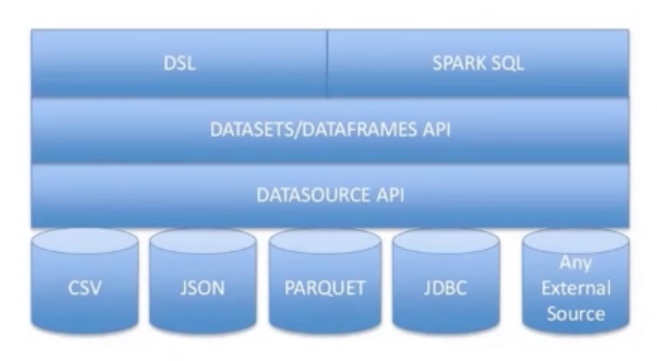
Spark SQL(DataFrames)
Spark SQL
Spark SQL是一个用来处理结构化数据的Spark组件。它提供了一个叫做DataFrames的可编程抽象数据模型,并可以视为一个分布式的SQL查询引擎。
DataFrames
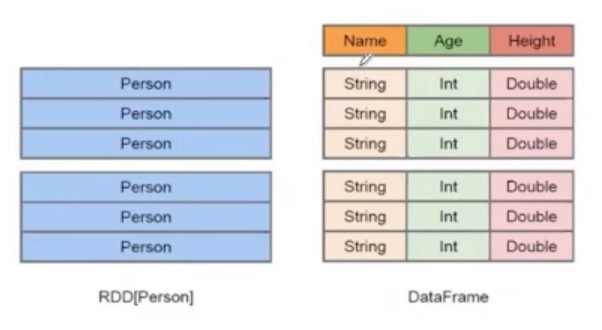
DataFrame是类似于关系表的分布式数据集。其特点是:
- 分布式
- 只读
- SQL查询
- Schema
Catalyst优化
DataSet
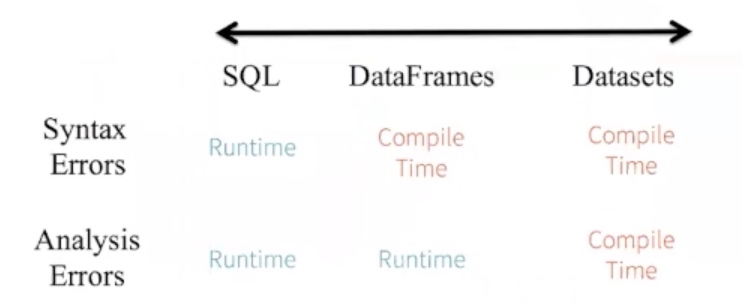
DataSet 是结合DataFrame和RDD优势的分布式数据集
- Scale & Java(目前只支持这两种语言)
- 类型安全(RDD)
- 关系型模型(DF)
查询优化(DF)
例子
进阶指南**
Structured Streaming(SS)
SS是构建于Spark SQL的流处理引擎。特性是:
- 可扩展
- 容错
- 无限增长的表格(把数据流视为无限增长的表格)
- SQL
DataFrame
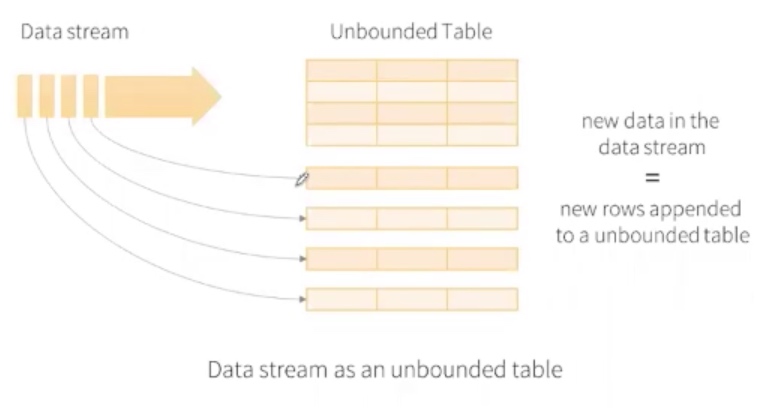
例子./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost 9999

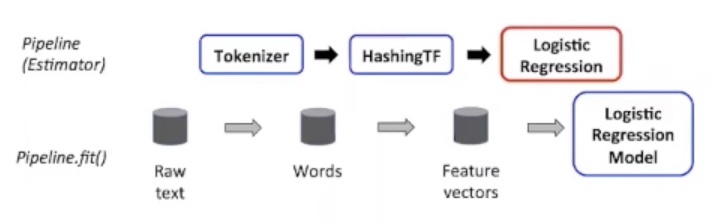
ML Pipeline
ML pipelines 是基于DataFrame抽象的,用于构建机器学习工作流的API
- DataFrame:表示数据集
- Transformer:DataFrame转换的算法
- Estimatior:作用于DataFrame生成Transformer
- Pipeline:ML工作流
Parameter:指定Transformer和Estimator的参数
阿里云EMR
https://help.aliyun.com/product/28066.html?spm=a2c4g.11186623.6.540.673b79e27ut1hR
问题答疑
同样的数据处理,Spark相对Hive消耗的内存比值大概是多少?
spark发展到现在版本,内存使用做了非常多的优化。所以,其实总体还好。建议能上spark就上spark。hive毕竟慢。综合下来,spark成本肯定要低的。
现在spark3,0版本的话,shuffle用的是sorted shuffle吗?
默认还是sort based
如果立马处理几亿条数据。大约能好久出结果。还是在流中慢慢处理结果感觉快?
看逻辑和资源量了。如果是离线数据,走batch模式就好了。
在sparksql里面,对计算的分区是不是更多交给spark内部去优化?在学习rdd算子,还要自己设置分区的数量。感觉shuffle这块,分区和reduce个数一直没搞懂什么关系?
3.0有了ae(自适应执行)框架,会更自动化一些

若有收获,就点个赞吧
0 人点赞
