What is ETL & Data Sciencec
Data Pipeline
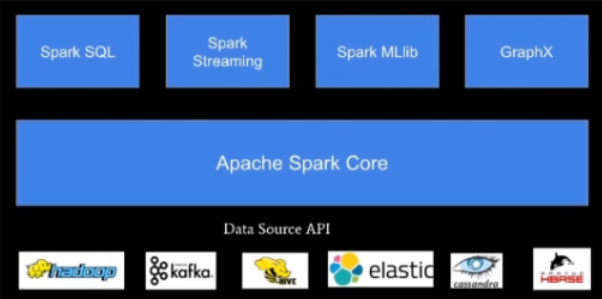
How to do ETL in Spark
What is ETL
- Extract
- Read raw data from single/multiple sources(no schema , uncompressed , dirty)
- Transfrom
- Transfrom raw data(Filter/Aggregation/Normalization/ Normalization/Join)
- Load
- Write raw into sinks(compressed , structured , cleaned ,well-organized)

What is ETL
- Architecture
- Performance
- Ecosystem
- API
ETL Example in Spark
spark.read.csv(“source_path”)
.filter(…)
.agg(…)
.write.mode(“append”)
.orc(“sink_path”)

Handing bad record
Text format(csv,json)supports 3 parsing mode
- PERMISSIVE
- set other fields to ‘null’ when it meets a corrupted record and puts the malformed string into a new field configured by
sqprk.sql,columnNameOfCorruptRecord.
- set other fields to ‘null’ when it meets a corrupted record and puts the malformed string into a new field configured by
- DORPMALFORMED
- ignores the whole corrupted records.
FALFAST
- throws an exception when it meets corrupted records.
Handing record corrupted
Keep in mindYou have no control on source data(format/scale/schema)
- You have no control on hardware/network(fault tolerance)
How to do Data Science inSpark
Data Science via Spark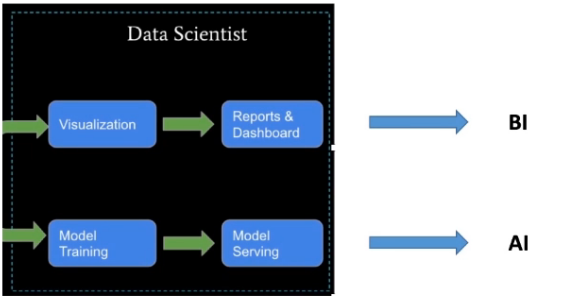
Spark SQL Operation
- Add or update columns
- Dorp column
- Where | Filter
- Group by
- Aggregation
- Join
- Union
- UDF
Visualization
- Zeppelin Notebook(SQL)
- PySpark(Python)
- Sparkr(R)
Zeppelin Notebook
PySpark
- Matplotlib
- Pandas
- Bokeh
- Seaborn
- Ploynine
- Holoviews
R
- R builtin
- ggplot2
googlevis
Three types of Machine LearningSupervised Learning
- Labeled data is available
- Classification / Regression
- Unsupervised Learning
- No labeled data is available
- Reinforcement Learning
- Model is continuously learned and relearn based on the action and effects/rewards based on the actions
Mechine Learning Basics
Spark ML Pipeline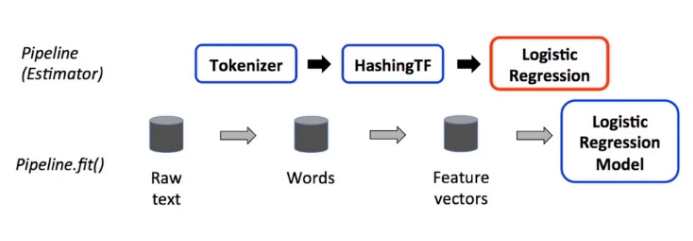
Demo via Spark on Zeppelin
Apache Zeppelin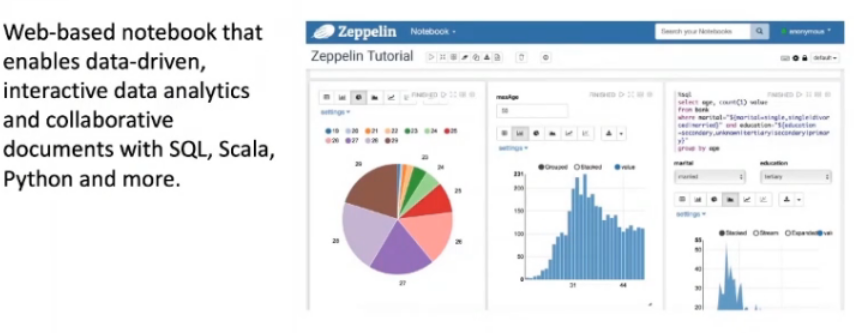
Dome代码截图




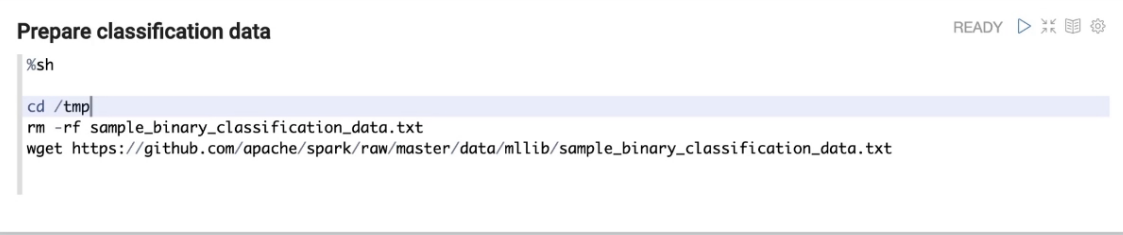
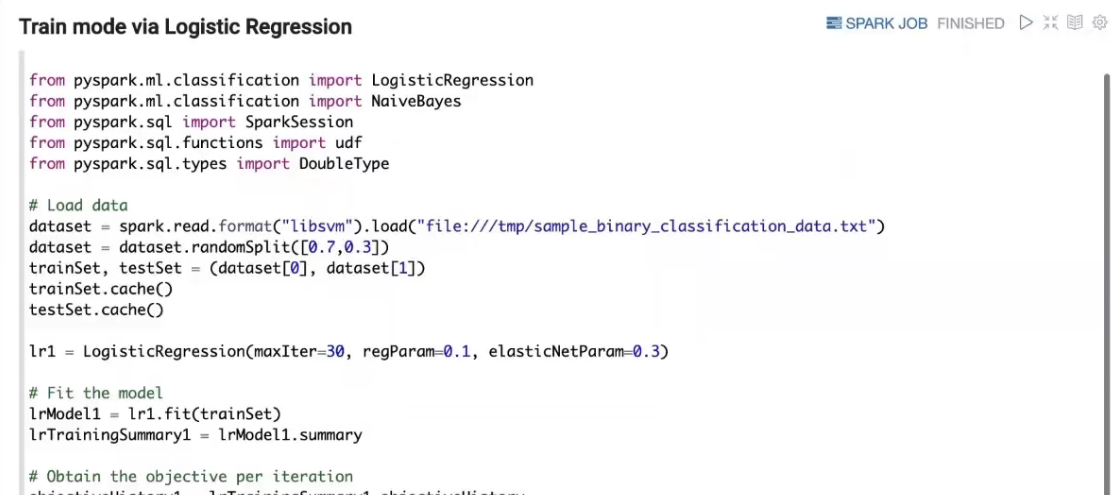




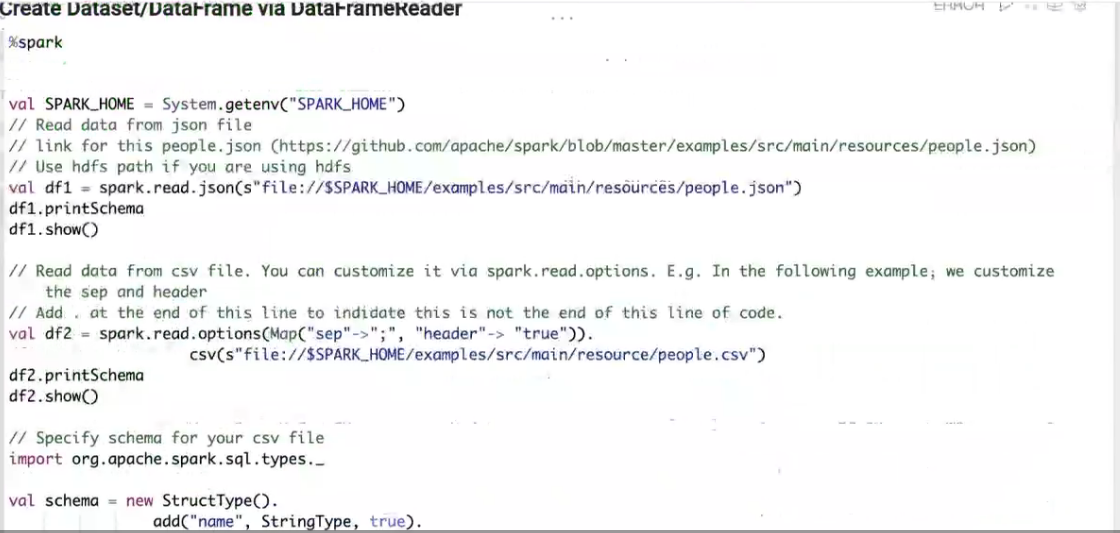

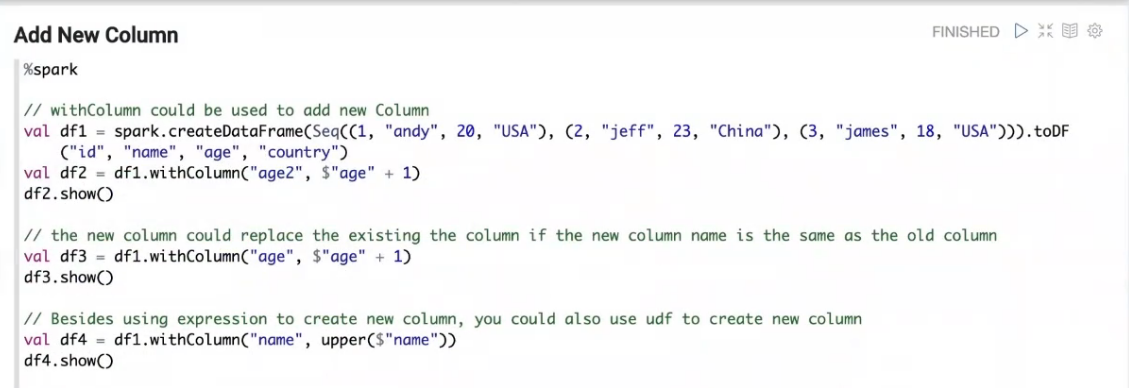
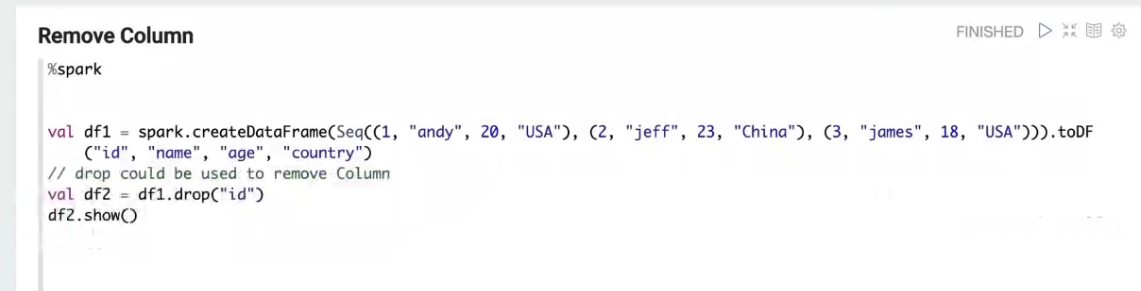




问题答疑
今天问答部分因为个人的聊天缓存被清掉了没法做记录,有相应记录的兄弟可以发给我我补充上

若有收获,就点个赞吧
0 人点赞
