计算机运算速度进步巨大,从早期 1 秒 1 次运算,到现在有千赫甚至兆赫的CPU。
早期计算机提速方式
早期,通过减少晶体管的切换时间,来提升 CPU 速度。
- 晶体管组成了逻辑门,ALU 以及前几集的其他组件
- 碰到了瓶颈
提升 CPU 性能的新技术
提升 CPU 性能,不但让简单指令运行更快,也让它能进行更复杂的运算。
专门电路处理复杂操作(复杂度 vs 速度的平衡)
- 现代 CPU 直接在硬件层面设计了除法,可以直接给 ALU 除法指令
- 缺点:让 ALU 更大也更复杂一些
- 优点:但是运算速度更快(用一连串减法代替除法的操作要多个时钟周期,很低效)
- 现代处理器有专门电路来处理图形操作, 游戏、解码压缩视频, 加密文档 等等
- 优点:速度快,而如果用标准操作来实现,要很多个时钟周期
- 缺点:指令不断增加,人们一旦习惯了它的便利就很难删掉,所以为了兼容旧指令集,指令数量越来越多
- 英特尔 4004,第一个集成CPU,有 46 条指令
- 但现代处理器有上千条指令,有各种巧妙复杂的电路
缓存 Cache
问题引入:超高的时钟速度带来另一个问题,如何快速传递数据给 CPU? ——给 CPU 加缓存
缓存的作用
- 提高数据存取速度,更快喂给 CPU
解决CPU运算速率与内存读写速率不匹配的矛盾
处理器里空间不大,所以缓存一般只有 KB 或 MB
缓存工作的原则,就是“引用的局部性”,这可以分为时间局部性和空间局部性。
- CPU 从 RAM 拿数据时, RAM 不只传一个,可以传一批,虽然花的时间久一点,但数据可以存在缓存加快之后的访问速度。
- 以 计算餐馆销售额 为例:
- 算餐厅的当日收入,先取 RAM 地址 100 的交易额。
- RAM 与其只给 1 个值,不如直接把地址 100 到 200 的一批值都复制到缓存
- 当处理器要下一个交易额时,交易额原本存储在 RAM 地址 100,但现在已经存储在缓存中,就不需要去 RAM 中取了
- 缓存离 CPU 近, 一个时钟周期就能给数据;而去 RAM 读取数据可能要多个时钟周期
- 因此,从缓存中读取数据,比反复去 RAM 拿数据快得多,让 CPU 不用空等
- 如果想要的数据已经在缓存,叫 缓存命中
- 如果想要的数据不在缓存,叫 缓存未命中
- 缓存也可以当临时空间,存一些中间值,适合长/复杂的运算
- 以 计算餐馆销售额 为例:
- 假设 CPU 算完了一天的销售额,想把结果存到 RAM 地址 150
- 但是现在先不让它存到 RAM 里,而是存在缓存,这样不但存起来快一些,后续运算取值也更快
- 问题:缓存和 RAM 不一致
- 解决办法:脏位 Dirty bi**t**
- 脏位用来记录缓存和 RAM 的不一致
- 当缓存满了,而 CPU 又要从 RAM 读取新的数据放入缓存,就要先进行同步
- 同步时,检查脏位,如果是”脏”的, 在加载新内容之前, 会把数据写回 RAM
- 以 计算餐馆销售额 为例:
指令流水线
并行处理 parallelize
假设指令执行分为 3 个阶段:取指 → 解码 → 执行。
- 若按序处理:
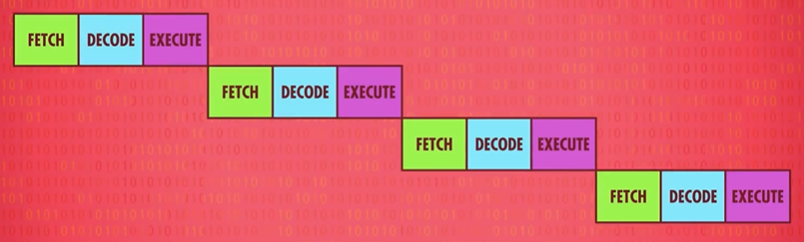
- 并行处理:
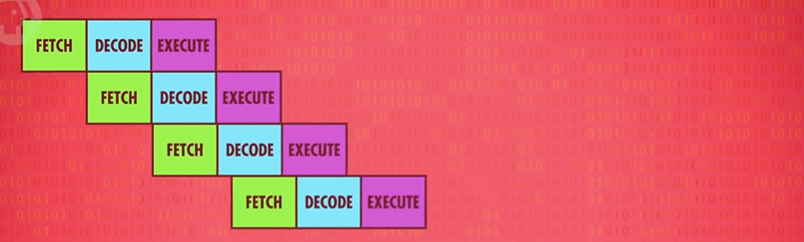
可以看到,使用并行处理,每个阶段利用 CPU 的不同部分,不同任务重叠进行,同时用上 CPU 里不同部分。
这样的流水线,使得指令吞吐量 x 3
问题一:指令之间的依赖关系——>乱序执行
eg. 第二条指令读某个数据,而并行正在执行的第一条指令会改这个数据,那并行执行第二条指令的话,这个数据还没被改,也就是说拿的是旧数据。
因此流水线处理器 要先弄清数据依赖性,必要时停止流水线,避免出问题。
解决方案:乱序执行 out-of-order execution
- 定义:高端 CPU,比如笔记本和手机里那种,会更进一步,动态排序 有依赖关系的指令,最小化流水线的停工时间,即乱序执行
- 缺点:这种电路非常复杂
- 优点:流水线非常高效,几乎所有现代处理器都实现了流水线
问题二:条件跳转——>推测执行 & 分支预测
条件跳转指令指令会改变程序的执行流。
解决方案:
- 简单的流水线处理器,看到 JUMP 指令会停一会儿,等待条件值确定下来,再继续流水线。
- 缺点:造成延迟
- 推测执行 speculative execution
- 定义:可以把 JUMP 想成是 “岔路口”,高端 CPU 会猜哪条路的可能性大一些,然后提前把指令放进流水线,这叫 “推测执行”
- 分支预测 branch prediction
- 定义:推测执行如果如果 CPU 猜错了,就要清空流水线。为了尽可能减少清空流水线的次数,CPU 厂商开发了复杂的方法,来猜测哪条分支更有可能,叫”分支预测”
- 现代 CPU 的正确率超过 90%
优化 1 个指令流的吞吐量
超标量处理器
如果只有一个单核 CPU ,且 CPU 中各个部件(例如 ALU、缓存等)只有一套,则使用流水线时,理想情况下,一个时钟周期完成 1 个指令。
而超标量处理器,使得一个时钟周期完成多个指令。
工作原理:
即便有流水线设计,在指令执行阶段,处理器里有些区域还是可能会空闲。比如,执行一个 “从内存取值” 指令期间,ALU 会闲置。所以一次性处理多条指令(取指令+解码) 会更好,如果多条指令要 ALU 的不同部分,就多条同时执行。
多个相同电路/部件(eg. ALU)
超标量处理其更进一步,加多几个相同的电路执行出现频次很高的指令,eg. 很多 CPU 有四个, 八个甚至更多 完全相同的 ALU ,可以同时执行多个数学运算。
同时运行多个指令流
多核 CPU
一个 CPU 芯片里,有多个独立处理单元。
它们整合紧密,可以共享一些资源,比如缓存,使得多核可以合作运算。
多个独立 CPU
多核不够时,可以用多个 CPU,提升性能。
超级计算机
如果要做怪兽级运算,比如模拟宇宙形成,你需要强大的计算能力,给普通台式机加几个 CPU 没什么用。需要成千上万个 CPU !
神威·太湖之光有 40960 个CPU,每个 CPU 有 256 个核心,总共超过1千万个核心,每个核心的频率是 1.45GHz,每秒可以进行 9.3 亿亿次浮点数运算,也叫 每秒浮点运算次数 (FLOPS)。

若有收获,就点个赞吧
0 人点赞
