概述
ServiceMesh 最核心的价值之一在于能够尽可能的提升微服务之间流量访问的可靠性。
而提升流量访问可靠性的最主要的方式就是配置超时和重试机制了。
在本文中,我们将会讲解如何在 Istio 中配置超时和重试等相关的功能。
首先,我们来看看为什么需要超时机制:
通过超时机制,我们可以有效的控制故障范围,避免故障扩散。
那重试呢?
重试可以帮助我们解决网络抖动时导致的通信失败的问题。
二者分别如下图所示: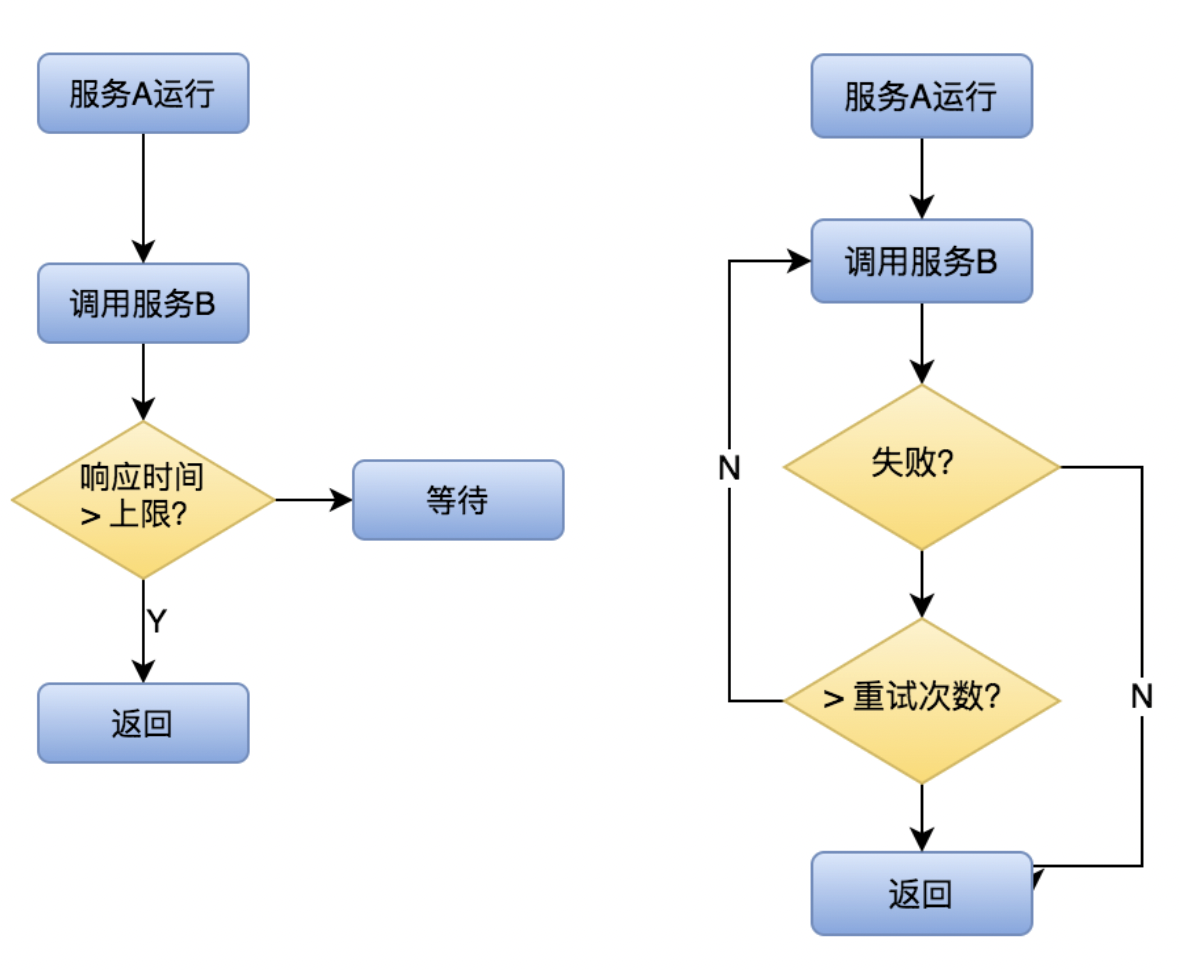
实战
场景描述
在本文中,我们将会依次添加超时和重试策略。
希望通过本文的学习,你能够:
- 学会在 VirtualService 中添加超时和重试的配置项
- 理解超时和重试对提升应用健壮性的意义
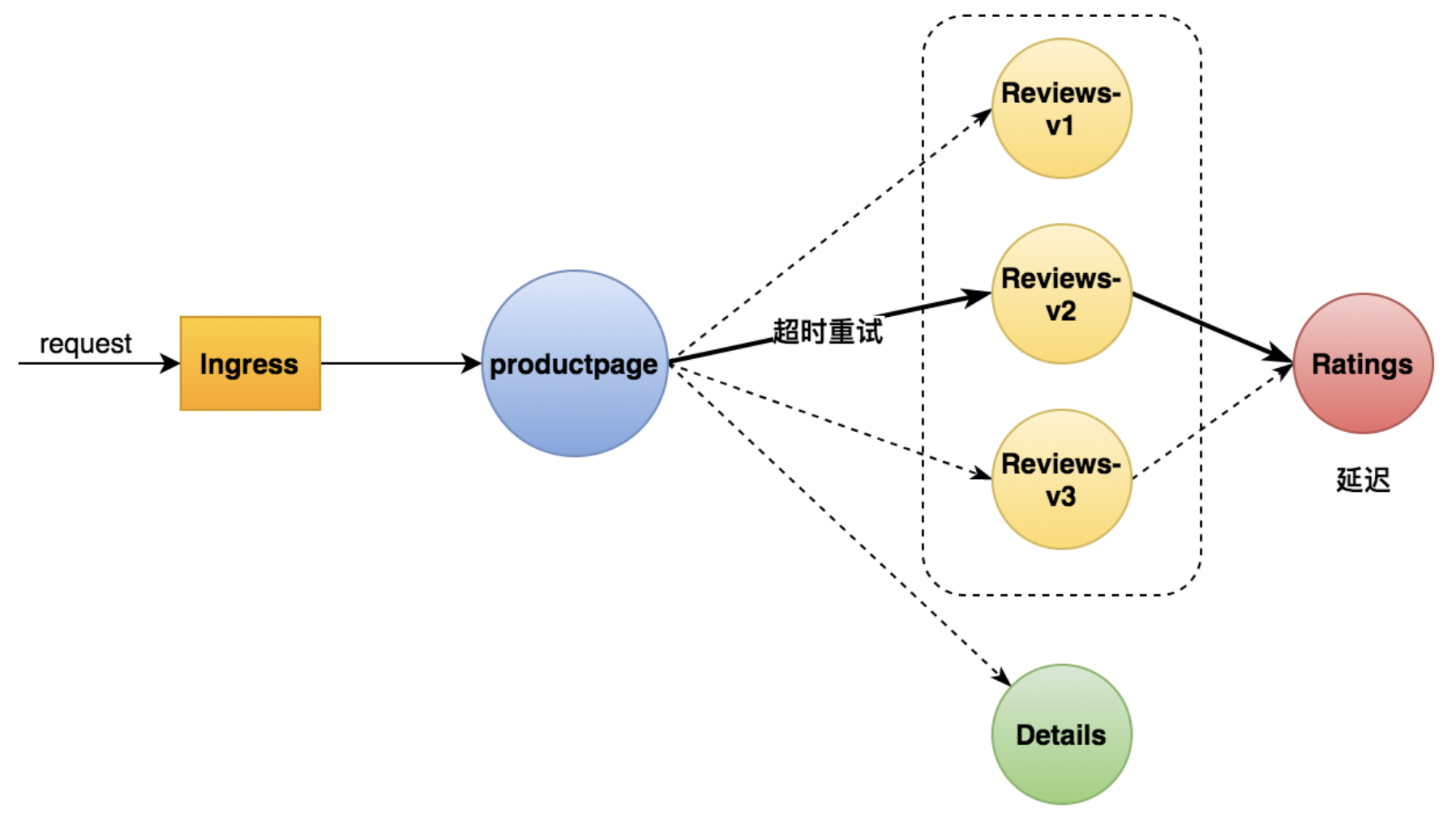
如上图所示,我们会将请求转发至 Reviews 服务的 v2 版本并在 Ratings 服务中添加一个延迟,模拟一个故障的情况,从而验证我们的超时和重试策略是否能够正常生效。
StepByStep
Step1:将 reviews 流量转到 v2 版本
创建 vs.yaml 文件:
apiVersion: networking.istio.io/v1alpha3kind: VirtualServicemetadata:name: reviewsspec:hosts:- reviewshttp:- route:- destination:host: reviewssubset: v2
使之生效:
kubectl apply -f vs.yaml -n istio-demo
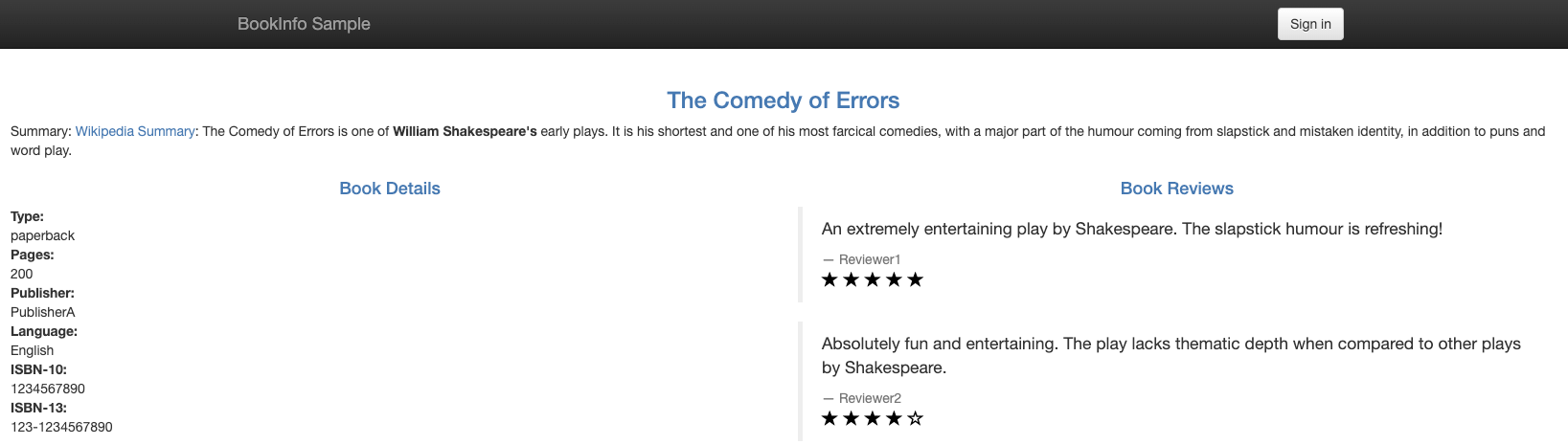
可以看到,现在流量已经成功的发送到了 reviews 的 V1 版本啦!
Step2:给 ratings 服务添加延迟
创建一个 delay.yaml 的文件:
apiVersion: networking.istio.io/v1alpha3kind: VirtualServicemetadata:name: ratingsspec:hosts:- ratingshttp:- fault:delay:percent: 100fixedDelay: 2sroute:- destination:host: ratingssubset: v1
在该配置中,我们修改了 ratings 服务的 virtualservice 配置,注入了一个 2s 的请求延迟。
Ps: 关于故障注入的内容,本文不做展开介绍,后续会有专门的文章展开分析。
让它生效一下吧:
kubectl apply -f delay.yaml -n istio-demo# virtualservice.networking.istio.io/ratings configured
再次访问 Web 页面,你有没有觉得 Web 页面的响应时间变长了呢?
Step3:给 reviews 服务添加超时策略
下面,我们来给 reviews 服务添加一个超时策略 timeout.yaml :
apiVersion: networking.istio.io/v1alpha3kind: VirtualServicemetadata:name: reviewsspec:hosts:- reviewshttp:- route:- destination:host: reviewssubset: v2timeout: 1s
我们让它生效一下:
kubectl apply -f ./timeout.yaml -n istio-demo# virtualservice.networking.istio.io/reviews configured
下面,我们在打开浏览器看一下,我们会发现,右侧 reviews 已经无法正常显示了: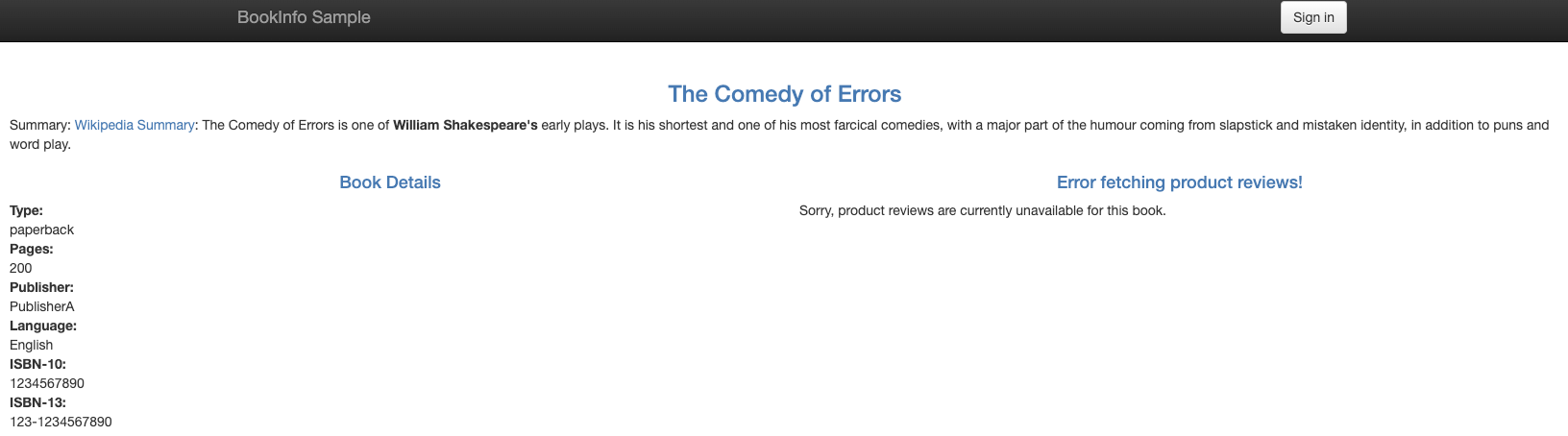
原因是因为 ratings 服务的延迟时间是 2s,而访问 reviews 服务的超时时间是 1s,因此每次访问 reviews 服务都会由于超时而导致失败。
Step4:添加重试策略
下面,我们以之前 Ingress 一文中的 httpbin 服务为例来演示重试策略。
我们删除之前残留的 httpbin 的 VirtualService 配置:
kubectl delete vs httpbin -n istio-demo
然后我们观察 httpbin Pod 下 istio-proxy 的 access log:
kubectl logs -f $(kubectl get pod -l app=httpbin -o jsonpath={.items..metadata.name} -n istio-demo) -c istio-proxy -n istio-demo | grep "/status/500"
我们从 sleep 容器发送 curl 请求给 httpbin 服务。
export SLEEP_POD_NAME=$(kubectl get pod -l app=sleep -o jsonpath={.items..metadata.name} -n istio-demo)export HTTPBIN_POD_NAME=$(kubectl get pod -l app=httpbin -o jsonpath={.items..metadata.name} -n istio-demo)kubectl exec -it $SLEEP_POD_NAME -n istio-demo -c sleep curl http://httpbin:8000/status/500
观察日志可以发现,每次请求时,httpbin 的 Pod 中 istio-proxy 都会收到一条对应的日志:
现在,我们来创建一个 retry.yaml 配置相关的重试策略:
apiVersion: networking.istio.io/v1alpha3kind: VirtualServicemetadata:name: httpbinspec:hosts:- httpbinhttp:- route:- destination:host: httpbinretries:attempts: 10perTryTimeout: 1sretryOn: 5xx
我们让其生效一下:
kubectl apply -f retry.yaml -n istio-demo# virtualservice.networking.istio.io/httpbin created
再次从 sleep 容器发送 curl 请求给 httpbin 服务。
export SLEEP_POD_NAME=$(kubectl get pod -l app=sleep -o jsonpath={.items..metadata.name} -n istio-demo)export HTTPBIN_POD_NAME=$(kubectl get pod -l app=httpbin -o jsonpath={.items..metadata.name} -n istio-demo)kubectl exec -it $SLEEP_POD_NAME -n istio-demo -c sleep curl http://httpbin:8000/status/500
观察 httpbin 的 istio-proxy 的 access log 可以看到: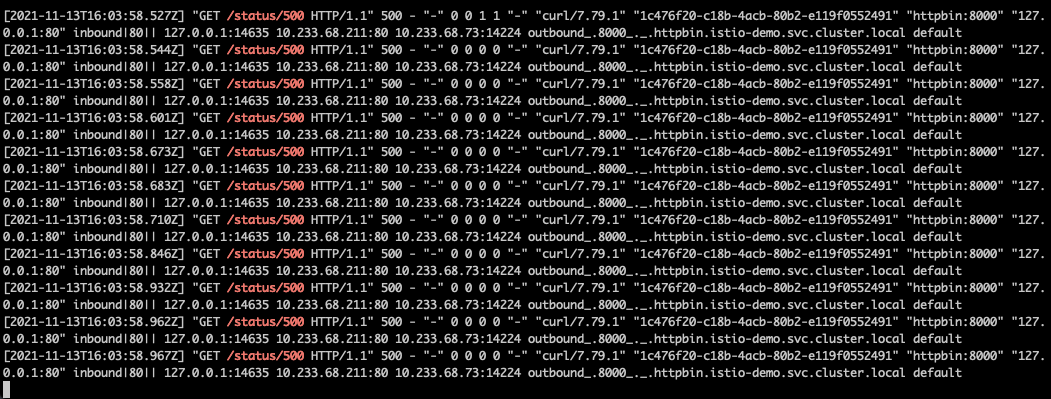
httpbin实际上收到了11个请求(1个原始请求+10次重试请求)。
我们的重试策略已经正常生效啦!
原理说明
配置分析
下面,我们来对超时和重试的配置进行一些相关的说明。
http:- route:- destination:host: reviewssubset: v2timeout: 1s
timeout 位于 http 块下的配置,单位支持 ms, s, m, h 等,表示单次访问该服务时的最长等待时间。
spec:hosts:- httpbinhttp:- route:- destination:host: httpbinretries:attempts: 10perTryTimeout: 1sretryOn: 5xx
retries 同样位于 http 块下的配置。其中,包含了:
- attempts:尝试次数
- perTryTimeout:每次尝试的超时时间
- retryOn:表示在哪些场景下需要触发重试逻辑
资源配置项
关于 timeout 和 retry 的完整配置项可以参考下图所示: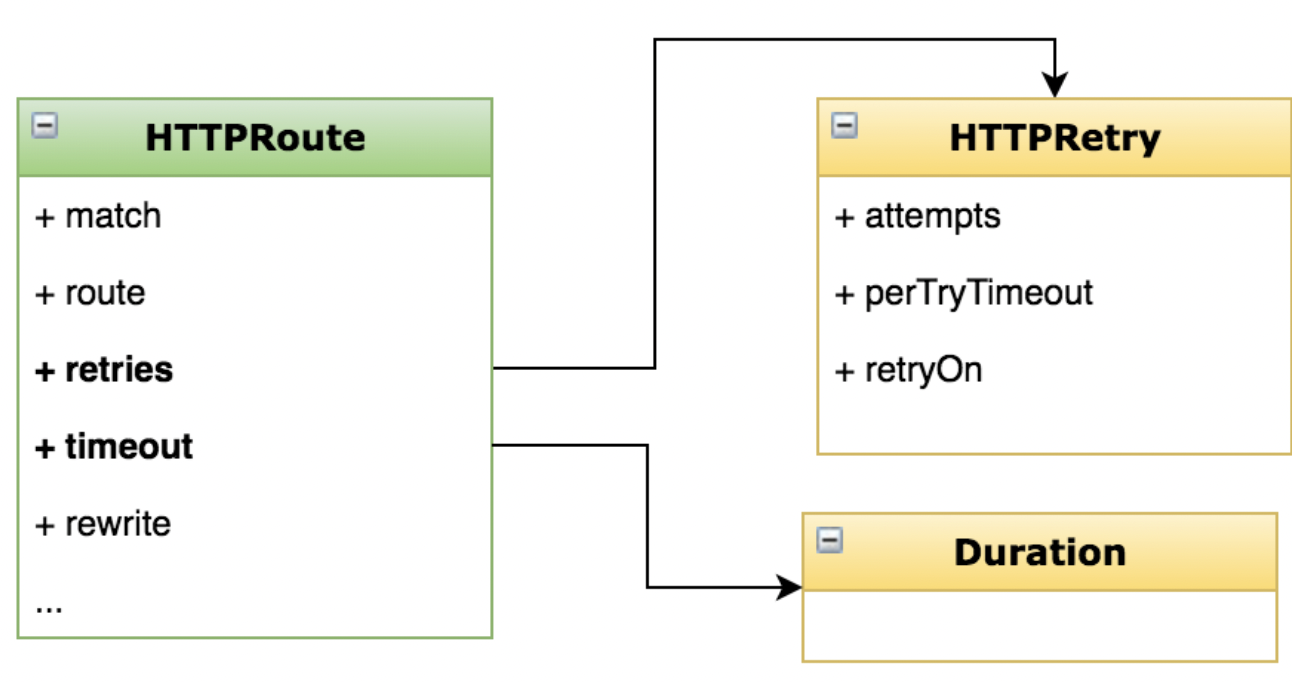
其中,retryOn 可以设置在哪些条件下触发重试逻辑。

若有收获,就点个赞吧
0 人点赞
