在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。
重排序的类型
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统的重排序。由于CPU使用缓存和读/写缓冲区(store buffer),这使得加载和存储操作看上去可能是在乱序执行

重排序的原则
- 不影响代码执行的最终结果
- 编译器和处理器不会改变存在数据依赖关系的两个
数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。
例如: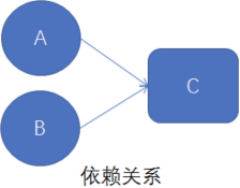
很明显,A和C存在数据依赖,B和C也存在数据依赖,而A和B之间不存在数据依赖,如果重排序了A和C或者B和C的执行顺序,程序的执行结果就会被改变。
很明显,不管如何重排序,都必须保证代码在单线程下的运行正确,连单线程下都无法正确,更不用讨论多线程并发的情况,所以就提出了一个as-if-serial的概念。as-if-serial
as-if-serial语义的意思是: :::tips 不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。 ::: 编译器、runtime和处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。(强调一下,这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。)但是,如果操作之间不存在数据依赖关系,这些操作依然可能被编译器和处理器重排序。
A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。
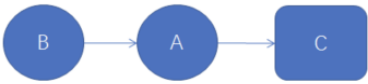
as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器、runtime和处理器可以让我们感觉到:单线程程序看起来是按程序的顺序来执行的。asif-serial语义使单线程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。控制依赖性

上述代码中,flag变量是个标记,用来标识变量a是否已被写入,在use方法中变量i的赋值依赖if (flag)的判断,这里就叫控制依赖,如果发生了重排序,结果就不对了。
考察代码,我们可以看见,
操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。操作3和操作4则存在所谓控制依赖关系。
在程序中,当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测(Speculation)执行来克服控制相关性对并行度的影响。以处理器的猜测执行为例,执行线程B的处理器可以提前读取并计算a*a,然后把计算结果临时保存到一个名为重排序缓冲(Reorder Buffer,ROB)的硬件缓存中。当操作3的条件判断为真时,就把该计算结果写入变量i中。猜测执行实质上对操作3和4做了重排序,问题在于这时候,a的值还没被线程A赋值。
在单线程程序中,对存在控制依赖的操作重排序,不会改变执行结果(这也是as-if-serial语义允许对存在控制依赖的操作做重排序的原因)。
但是对多线程来说就完全不同了:这里假设有两个线程A和B,A首先执行init ()方法,随后B线程接着执行use ()方法。线程B在执行操作4时,能否看到线程A在操作1对共享变量a的写入呢?答案是:不一定能看到。
让我们先来看看,当操作1和操作2重排序,操作3和操作4重排序时,可能会产生什么效果?操作1和操作2做了重排序。程序执行时,线程A首先写标记变量flag,随后线程B读这个变量。由于条件判断为真,线程B将读取变量a。此时,变量a还没有被线程A写入,这时就会发生错误!
所以在多线程程序中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。

若有收获,就点个赞吧
0 人点赞
