区间DP简介
区间 DP 是状态的定义和转移都与区间有关,其中区间用两个端点表示。
状态一般定义为dp[i][j] : 区间[i:j]上原问题的解,i变大,j变小,都可以得到更小规模的子问题。但是注意i <= j,也就是说,在dp这个二维状态数组中,只有其上三角矩阵才是有意义的,因此一般 i 从后向前遍历,j 从 i 向后
状态转移也分为两种情况,dp[i][j]只依赖O(1)个更小规模的子问题,dp[i][j]依赖O(n)个更小规模的子问题
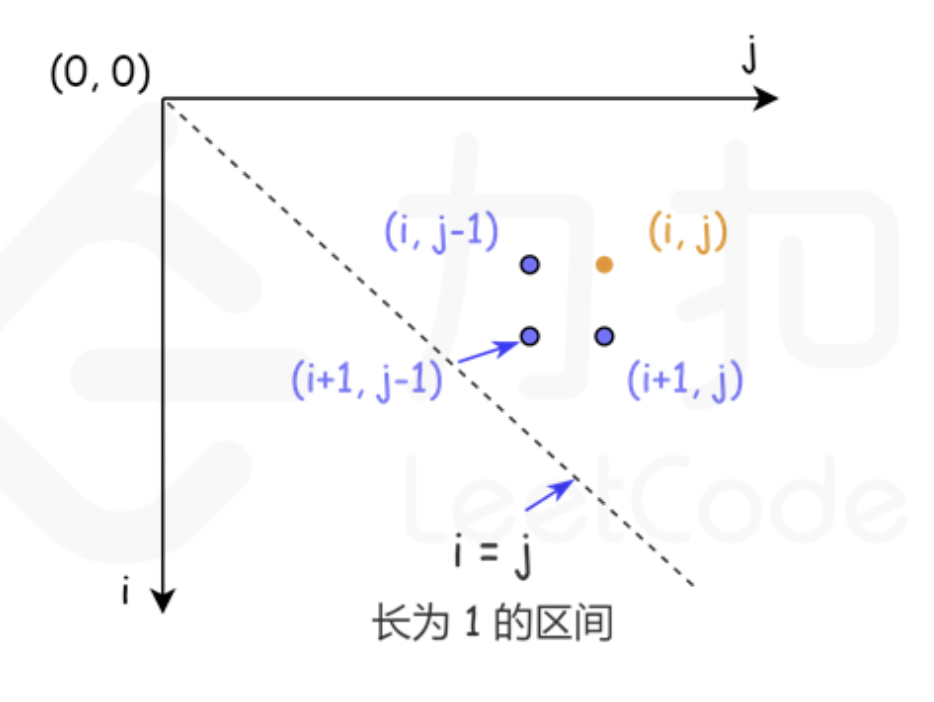
dp[i][j]只依赖O(1)个更小规模的子问题- 这几个子问题通常是
dp[i+1][j-1], dp[i+1][j], dp[i][j-1]
- 这几个子问题通常是
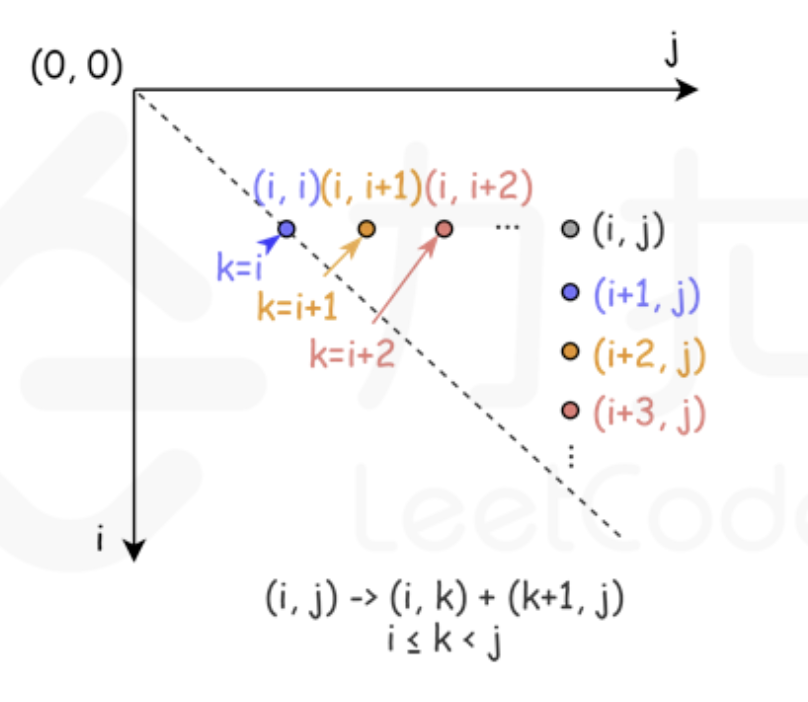
dp[i][j]依赖O(n)个更小规模的子问题- 这些子问题可以考虑枚举
[i:j]的分割点,将区间分开,再汇总
- 这些子问题可以考虑枚举
区间DP经典问题
516. 最长回文子序列
664. 奇怪的打印机
回文相关问题
516. 最长回文子序列
有点麻烦
public int longestPalindromeSubseq(String s) {int n = s.length();int[][] dp = new int[n][n];for (int len = 1; len <= n; ++len) {for (int i = 0; i + len - 1 < n; ++i) {int j = i + len - 1;if (len == 1) {dp[i][j] = 1;} else if (len == 2) {dp[i][j] = s.charAt(i) == s.charAt(j) ? 2 : 1;} else {if (s.charAt(i) == s.charAt(j)) {dp[i][j] = dp[i + 1][j - 1] + 2;} else {dp[i][j] = Math.max(dp[i + 1][j], dp[i][j - 1]);}}}}return dp[0][n - 1];}
精简
为什么这里就不用判断当长度等于2的时候了呢,因为当dp[i][j]中i = i, j = i + 1时,dp[i+1][j-1]则为dp[i+1][i],因为我们设置了左边界要小于等于右边界,而现在右边界小了,这是不符合常理的,但是他的初始值刚好是0,所以就用这个
public int longestPalindromeSubseq(String s) {
int len = s.length();
int[][] dp = new int[len][len];
for (int i = len - 1; i >= 0; i--) { // 从后往前遍历 保证情况不漏
dp[i][i] = 1; // 初始化
for (int j = i + 1; j < len; j++) {
if (s.charAt(i) == s.charAt(j)) {
dp[i][j] = dp[i + 1][j - 1] + 2;
} else {
dp[i][j] = Math.max(dp[i + 1][j], dp[i][j - 1]));
}
}
}
return dp[0][len - 1];
}
5. 最长回文子串
public String longestPalindrome(String s) {
int n = s.length();
if (n < 2) {
return s;
}
int maxLen = 1;
int begin = 0;
boolean[][] dp = new boolean[n][n];
char[] c = s.toCharArray();
for (int i = n - 1; i >= 0; --i) {
dp[i][i] = true;
for (int j = i + 1; j < n; ++j) {
if (c[i] != c[j]) {
dp[i][j] = false;
} else {
if (j - i < 3) {
dp[i][j] = true;
} else {
dp[i][j] = dp[i + 1][j - 1];
}
}
if (dp[i][j] && j - i + 1 > maxLen) {
maxLen = j - i + 1;
begin = i;
}
}
}
return s.substring(begin, begin + maxLen);
}
647. 统计回文子串个数
730. 统计不同回文子序列
三维DP
- 状态定义
dp[x][i][j]: 区间s[i:j]上不同回文子序列数,其中s[i]==s[j] == 'a'+x,因为只包含四个字符abcd,所以0 <=k < 4
状态转移
- 如果
s[i] != 'a' + x,则dp[x][i][j] = dp[x][i+1][j] - 如果
s[j] != 'a' + x,则dp[x][i][j] = dp[x][i][j-1] 如果
s[i] == s[j] == 'a' + x,则dp[x][i][j] = 2 + dp[0][i+1][j-1] + dp[1][i+1][j-1] + dp[2][i+1][j-1] + dp[3][i+1][j-1]public int countPalindromicSubsequences(String S) { int n = S.length(); int mod = 1000000007; int[][][] dp = new int[4][n][n]; for (int i = n-1; i >= 0; --i) { for (int j = i; j < n; ++j) { for (int k = 0; k < 4; ++k) { char c = (char) ('a' + k); if (j == i) { if (S.charAt(i) == c) dp[k][i][j] = 1; else dp[k][i][j] = 0; } else { // j > i if (S.charAt(i) != c){ dp[k][i][j] = dp[k][i+1][j]; } else if (S.charAt(j) != c){ dp[k][i][j] = dp[k][i][j-1]; } else { // S[i] == S[j] == c if (j == i + 1) { dp[k][i][j] = 2; // "aa" : {"a", "aa"} } else { // length is > 2 dp[k][i][j] = 2; for (int m = 0; m < 4; ++m) { // count each one within subwindows [i+1][j-1] dp[k][i][j] += dp[m][i+1][j-1]; dp[k][i][j] %= mod; } } } } } } } int ans = 0; for (int k = 0; k < 4; ++k) { ans += dp[k][0][n-1]; ans %= mod; } return ans; }二维DP
- 如果
状态定义
dp[i][j]: 区间s[i:j]上不同的回文子序列个数
状态转移
- 如果
s[i] == s[j],dp[i][j] = 2*dp[i+1][j-1] + 2。*2是因为字符串s[i]s[i+1:j-1]s[j]中间部分s[i+1:j-1]本身就有dp[i+1][j-1]个回文子序列,而每个子序列再结合s[i],s[j]又能组成一个新的回文串,所以得*2。+2是因为单独考虑s[i],s[j],不一定非要结合其他的字符,仅考虑这两个字符,也可以组成两个新的回文序列s[i]和s[i]s[i]。但是还需要考虑s[i+1:j-1]区间上有几个等于s[i]的字符s[i+1:j-1]区间上有 1 个等于s[i]的字符,那说明回文序列s[i]已经在*2的时候被计算过了,因此+2得变成+1s[i+1:j-1]区间上有 >=2 个等于s[i]的字符,那说明回文序列s[i]和s[i]s[i]都被计算过了,所以+2得变成+0。同时还有重复,我们从左i+1和从右j-1同时找第一个等于s[i]的索引,假设分别为l, r,则s[l+1:r-1]与s[l]s[r]构成的所有子序列情况,和s[l+1:r-1]与s[i]s[j]构成的子序列情况完全相同,因此要减掉这部分,s[l+1:r-1]与s[i]s[j]构成的子序列数量为dp[l+1][r-1]
如果
s[i] != s[j],则左右两端无法同时构成子序列,则考虑分别构成子序列,由容斥原理,中间多算了一部分,即dp[i][j] = dp[i+1][j] + dp[i][j-1] - dp[i+1][j-1]public int countPalindromicSubsequences(String s) { int len = s.length(); int mod = (int) (1e9+7); int dp[][] = new int[len][len]; for (int i = 0; i < len; i++) { dp[i][i] = 1; } for (int i = len-2; i >= 0; i--) { for (int j = i+1; j < len; j++) { if(s.charAt(i) != s.charAt(j)) dp[i][j] = dp[i+1][j] + dp[i][j-1] - dp[i+1][j-1]; else{ // +2 是因为两边的两个元素可以成为两个不重复的子序列 dp[i][j] = dp[i+1][j-1] *2 + 2; //去掉重复的子序列 int l=i+1,r=j-1; while(l<=r && s.charAt(l)!=s.charAt(i)) l++; while(l<=r && s.charAt(r)!=s.charAt(i)) r--; // 第2.1种情况 中间有1个s[i] if(l == r) dp[i][j]--; // 第2.2种情况 中间有≥2个s[i] else if(l < r) dp[i][j] -=2+dp[l+1][r-1]; } dp[i][j] = (dp[i][j]>=0) ? dp[i][j] % mod : dp[i][j]+mod; } } return dp[0][len-1]; }1147. 段式回文
字符串哈希
BASE用于计算哈希值,关于BASE取什么值无所谓,而字符串哈希值的计算,
有点类似于将一个整数数字字符串转为整数的思路。比如说”12345”转为整数,我们可以这样处理:从左往右依次遍历字符c,每个字符都表示一个数字,那么最后的表达式可以写为
res=res*10+c;- 从右往左依次遍历字符c,那么
res=c*bias+res,而这里的bias其实是从右往左遍历了count位,然后,其值bias=count*10。
- 如果
而我们的BASE相当于这里的10,把他看成进制就好了。
public int longestDecomposition(String s) {
int BASE = 131;
int n = s.length(), hash1 = 0, hash2 = 0, count = 1;
int len = n/2;
int ans = 0;
int maxi = 0;
for(int i = 1;i <= len;i++){
hash1 = hash1 * BASE + s.charAt(i - 1);
hash2 = hash2 + s.charAt(n - i) * count;
count = count * BASE;
if(hash1 == hash2){
ans += 2;
count = 1;
hash1 = 0;
hash2 = 0;
maxi = i;
}
}
if (maxi == len) {
ans = len * 2 < n ? ans + 1 : ans;
} else {
ans++;
}
return ans;
}
让字符串成为回文串的最少插入次数
dp[i][j] = min(dp[i + 1][j] + 1, dp[i][j - 1] + 1), if s[i] != s[j]dp[i][j] = min(dp[i + 1][j] + 1, dp[i][j - 1] + 1, dp[i + 1][j - 1]), if s[i] == s[j]
区间DP其他问题
664. 奇怪的打印机
312. 戳气球
假设区间[i:j]上的气球如下
假设这个区间是一个开区间(i:j),也就是说左右边界i,j的气球是不能戳的,我们只能戳[i+1:j-1]内的气球,假设这个开区间上最后一个被戳破的气球的下标为k,假设他是粉色的那个,那么在它被戳爆之前,气球的排列应该是这样的
因此我将气球k戳爆,所能获得的即时收益为val[i] * val[k] * val[j],还没完,还没计算戳爆其他气球的收益,k将本来的开区间(i:j)分成了两个开区间(i:k)和(k:j),因此在两个开区间上各自戳爆其中的总收益分别为dp[i][k]和dp[k][j],所以最后戳爆气球下标为k的时候的总收益为total = dp[i][k] + val[i]*val[k]*val[j] + dp[k][j]
而开区间(i:j)上可以选择的k有多个,我们遍历这些k,找一个最大值,即为开区间(i:j)能获得的最大收益。
因此,状态的定义为dp[i][j]: 开区间(i:j)上戳气球能获得的最大收益
首先对原数组进行预处理,在头和尾各添加一个元素值为1,方便处理边界。我们从开区间长度为3开始计算,慢慢扩展区间长度。
public int maxCoins(int[] nums) {
int n = nums.length;
//创建一个辅助数组,头尾各添加1
int[] temp = new int[n+2];
temp[0] = 1;
temp[n+1] = 1;
for (int i = 1; i <= n; ++i) {
temp[i] = nums[i - 1];
}
int[][] dp = new int[n + 2][n + 2];
//枚举区间长度
for (int len = 3; len <= n + 2; ++len) {
for (int i = 0; i <= n + 2 - len; ++i) {
int j = i + len - 1;
int res = 0;
for (int k = i + 1; k < j; ++k) {
int left = dp[i][k];
int right = dp[k][j];
res = Math.max(res, left + temp[i] * temp[k] * temp[j] + right);
}
dp[i][j] = res;
}
}
return dp[0][n + 1];
}
546. 移除盒子
错误思路dp[i][j]: 闭区间[i:j]上所能取得的最大分数,然后探索某种移除盒子的策略来进行状态的转移。但是这种思路其实是错误的,因为移除了一个相同颜色的连续子串,那剩下的两部分并不是独立考虑的,有可能接起来中间又有相同的部分了。也就是说,这个分数不仅仅依赖于子序列,也依赖于之前的操作对当前数组的影响
正确思路dp[l][r][k]: 闭区间[l:r] 以及 该区间右边的等于boxes[r]的k的元素 组成的序列所能获得的最大分数,举个例子[l, l+1, ..., r-1, r, 值同r的下标, 值同r的下标, 值同r的下标],这种情况下r右边有三个和boxes[r]想等的值,即k==3,这样dp[l][r][3] = dp[l][r-1][0] + 4*4,即直接把右边的三个连同右边界的一个一起删除,所能获得的点数即为4*4。
因此初始化条件dp[l][r][k] = dp[l][r-1][0] + (k+1)(k+1)。但是这需要boxes[l:r-1]上没有与boxes[r]相等的值了,如果有,还是假设上面那个例子里,存在某个boxes[i] == boxes[r], l<=i<=r-1,即[l, l+1, ..., i, ..., r-1, r, 值同r的下标, 值同r的下标, 值同r的下标],那么就应该先删除boxes[i+1:r-1]之间的元素,让相等的几个元素靠在一起再一起删了,删掉boxes[i+1:r-1]之间的元素能获得的积分为dp[i+1][r-1][0],而剩下的元素能获得的积分为dp[l][i][k+1],因此最终的状态转移公式为dp[l][r][k] = max(dp[i+1][r-1][0] + dp[l][i][k+1])
最终的答案即为dp[0][n-1][0]
class Solution {
int[][][] dp;
public int removeBoxes(int[] boxes) {
int length = boxes.length;
dp = new int[length][length][length];
return calculatePoints(boxes, 0, length - 1, 0);
}
public int calculatePoints(int[] boxes, int l, int r, int k) {
if (l > r) {
return 0;
}
if (dp[l][r][k] == 0) {
dp[l][r][k] = calculatePoints(boxes, l, r - 1, 0) + (k + 1) * (k + 1);
for (int i = l; i < r; i++) {
if (boxes[i] == boxes[r]) {
dp[l][r][k] = Math.max(dp[l][r][k], calculatePoints(boxes, l, i, k + 1) + calculatePoints(boxes, i + 1, r - 1, 0));
}
}
}
return dp[l][r][k];
}
}
1039. 多边形三角剖分的最低得分
1000. 合并石头的最低成本
486. 预测赢家
471. 编码最短长度的字符串

若有收获,就点个赞吧
0 人点赞
