实现前缀和问题
303. 区域和检索 - 数组不可变
class NumArray {private int[] sums;public NumArray(int[] nums) {sums = new int[nums.length + 1];for(int i = 1; i <= nums.length; ++i){sums[i] = nums[i-1] + sums[i-1];}}public int sumRange(int left, int right) {return sums[right + 1] - sums[left];}}
304. 二维区域和检索 - 矩阵不可变
class NumMatrix {
private int[][] sums;
public NumMatrix(int[][] matrix) {
sums = new int[matrix.length + 1][matrix[0].length + 1];
for(int i = 0; i < matrix.length; ++i){
for(int j = 0; j < matrix[0].length; ++j){
sums[i + 1][j + 1] = sums[i + 1][j] + sums[i][j + 1] - sums[i][j] + matrix[i][j];
}
}
}
public int sumRegion(int row1, int col1, int row2, int col2) {
return sums[row2 + 1][col2 + 1]
- sums[row1][col2 + 1]
- sums[row2 + 1][col1]
+ sums[row1][col1];
}
}
数据结构维护前缀和问题
几个经典问题
 上有没有一个区间,其和为target
上有没有一个区间,其和为target- HashSet
 上有多少个区间,其和为target
上有多少个区间,其和为target- HashMap
 上有没有一个区间,其和大于/小于target
上有没有一个区间,其和大于/小于target- 线段树
-
HashMap I — {前缀和 : 第一次出现的下标}
325. 和等于 k 的最长子数组长度
要想得到和为k的子数组,问题可转化为「当前位置之前是否存在和为
sums[i] - k的前缀和」
值得学习的点 new HashMap<Integer, Integer>(){{put(0, -1);}};map.putIfAbsent(sum, i);我们希望只有不存在这个键的时候才放入,有的话不修改原键值对public int maxSubArrayLen(int[] nums, int k){ //{sum:index} HashMap<Integer, Integer> map = new HashMap<Integer, Integer>(); map.put(0, -1); int ans = 0; int sum = 0; for (int i = 0; i < nums.length; ++i) { sum += nums[i]; if (map.containsKey(sum - k)) { ans = Math.max(ans, i - map.get(sum - k)); } map.putIfAbsent(sum, i); } return ans; }525. 连续数组
「相同数量的0和1的子数组」相当于「前缀和等于区间长度的一半」
我的思路
用一个hashmap保存前缀和出现的第一个索引,然后遍历到nums[i]时,查看map中有无前缀和等于长度的一半,即sum - key = (i - value) / 2,这样有个问题,就是连续的两个零对前缀和没影响,但是对长度有影响
题解
不妨将0转换成-1,那么当0和1数量相等时,区间的和就从「区间长度的一半」变成了「0」,这样就转换为上一题了1371. 每个元音包含偶数次的最长子字符串
题解
为每个元音维护一个前缀和数组,pre[i][k]表示前i个字符中,第k个元音出现的次数,则对于任意区间[l, r]是否满足条件,只需要对每个k计算pre[l+1][k] - pre[r][k]是否为偶数即可
同样,应该考虑使用hashmap来存储前缀和,但是首先每个元音需要一个状态计算次数,其次,哈希表应该满足的关系为sum - key % 2 == 0,除了遍历所有的key,我们没法在O(1)内确定这个key,从而找到他的下标。考虑将「偶数次」这个条件还能代表什么,如果pre[l+1][k] - pre[r][k]为偶数,那么pre[l+1][k]和pre[r][k]应该奇偶性相同。因此将前缀和从「元音出现的次数」修改为「元音出现次数的奇偶性」,如果当前前缀和是奇数,那么我们找到前缀和是奇数的最早出现的位置,即是符合条件的最大子串。
同时,如果在上面的思路中,我们对字符串的某个前缀进行计算,产生的结果,即哈希表的键,应该是每个元音出现的奇偶性,有些冗余,且得需要一个新的数据结构,比如数组int[char - 'a'] = 0 or 1,而且如果题目扩大字符集,问非元音,则键会更冗余且不以维护。因为奇偶性无非就两个值,考虑使用一个k位二进制数,第k位表示第k个字符出现的奇偶性,例如u o i e a :1 1 0 1 1,因此可以讲hashmap优化成一个int数组,我们只需要查找数组中之前是否出现过该奇偶状态即可public int findTheLongestSubstring(String s) { int n = s.length(); int[] pos = new int[1 << 5]; Arrays.fill(pos, -1); int ans = 0, status = 0; pos[0] = 0; for (int i = 0; i < n; i++) { char ch = s.charAt(i); if (ch == 'a') { status ^= (1 << 0); } else if (ch == 'e') { status ^= (1 << 1); } else if (ch == 'i') { status ^= (1 << 2); } else if (ch == 'o') { status ^= (1 << 3); } else if (ch == 'u') { status ^= (1 << 4); } if (pos[status] >= 0) { ans = Math.max(ans, i + 1 - pos[status]); } else { pos[status] = i + 1; } } return ans; }HashMap II—{前缀和 : 出现的次数}
560. 和等于K 的子数组数量
public int subarraySum(int[] nums, int k) { Map<Integer, Integer> map = new HashMap<>(); map.put(0, 1); int sum = 0; int ans = 0; for (int i = 0; i < nums.length; ++i) { sum += nums[i]; if (map.containsKey(sum - k)) { ans += map.get(sum - k); } map.put(sum, map.getOrDefault(sum, 0) + 1); } return ans; }1248. 统计「优美子数组」
「优美」 == 「恰好 k 个奇数」,k是指定的
偶数累加一定是偶数,奇数累加取决于奇数的个数,这样只能判断有奇数个奇数还是偶数个奇数,这个思路不行。
思路一:
将偶数转换为0,奇数转换为1,出现k次奇数就变成了「和为k的子数组数量」,转换为上一题
思路二
将前缀的思想变成「前i个字符中奇数的个数」,则pre[i] = pre[i-1] + (nums[i]&1),因此区间的奇数恰好为k个可以转化为pre[i] - pre[j-1] == k,跟思路一类似,但是可以使用数组代替hashmapHashMap III—同时需要前缀和、后缀和
238. 除自身以外数组的乘积
构造一个前缀数组、一个后缀数组、一个答案数组
构造一个答案数组,从前往后遍历第一遍将前缀积填入,从后往前遍历第二遍,不断更新答案数组,用一个额外的空间保存当前元素右边的后缀积
724. 寻找数组的中心下标
1477. 找两个和为目标值且不重叠的子数组
二维前缀和
自己编的. 元素和为目标值的最大子矩阵面积
根据下一题,可能会出现的题目,因为 325. 和等于 k 的最长子数组长度 和
560. 和等于K 的子数组数量,分别问了数组长度和数组个数。
在下一题中,哈希表中保存的是前缀面积:出现的次数,则这个问题应该保存的是前缀面积:第一次出现的左边界,没有题目检验对不对,大体思路是这样的public int maxSubMatrixLen(int[][] matrix, int target) { int n = matrix.length, m = matrix[0].length; int[][] pre = new int[n + 1][m + 1]; for (int i = 0; i < n; ++i) { for (int j = 0; j < m; ++j) { pre[i + 1][j + 1] = pre[i][j + 1] + pre[i + 1][j] - pre[i][j] + matrix[i][j]; } } int ans = 0; for (int top = 0; top < n; ++top) { for (int bot = top; bot < n; ++bot) { int cur = 0; Map<Integer, Integer> map = new HashMap<>(); map.put(0, -1); for (int right = 0; right < m; ++right) { cur = pre[bot + 1][right + 1] - pre[top][right + 1]; if (map.containsKey(cur - target)) { ans = Math.max(ans, (bot - top + 1) * (right - map.get(cur - target))); } map.putIfAbsent(cur, right); } } } return ans; }1074. 元素和为目标值的子矩阵数量
前缀和暴力解
注意里面的那个边界,即(p, q)是枚举左上角的位置,他是可以取到(i, j)的,跟(i, j)本身从 0 开始还是从 1 开始无关public int numSubmatrixSumTarget(int[][] matrix, int target) { int n = matrix.length, m = matrix[0].length; int[][] pre = new int[n + 1][m + 1]; for (int i = 0; i < n; ++i) { for (int j = 0; j < m; ++j) { pre[i + 1][j + 1] = pre[i][j + 1] + pre[i + 1][j] - pre[i][j] + matrix[i][j]; } } int ans = 0; for (int i = 0; i < n; ++i) { for (int j = 0; j < m; ++j) { for (int p = 0; p <= i; ++p) { for (int q = 0; q <= j; ++q) { int temp = pre[i + 1][j + 1] - pre[p][j + 1] - pre[i + 1][q] + pre[p][q]; if (temp == target){ ans++; } } } } } return ans; }哈希表优化—抽象一维
在一维数组中,我们枚举点,判断该点左边,是否存在某个前缀和等于pre - target,哈希表保存前缀和:第一次出现的下标/出现的次数。如何扩展到二维数组?在二维数组中,取一个子矩阵数组,如果上边界==下边界,那么他就是一个一维数组。我们考虑,枚举上下边界,确定一个大的子矩阵,然后枚举右边界,相当于一维中枚举点,然后判断该边的左边,是否存在某个前缀和等于pre - target,则找到了左边界,因此哈希表应该保存面积:第一次出现的坐标/出现的次数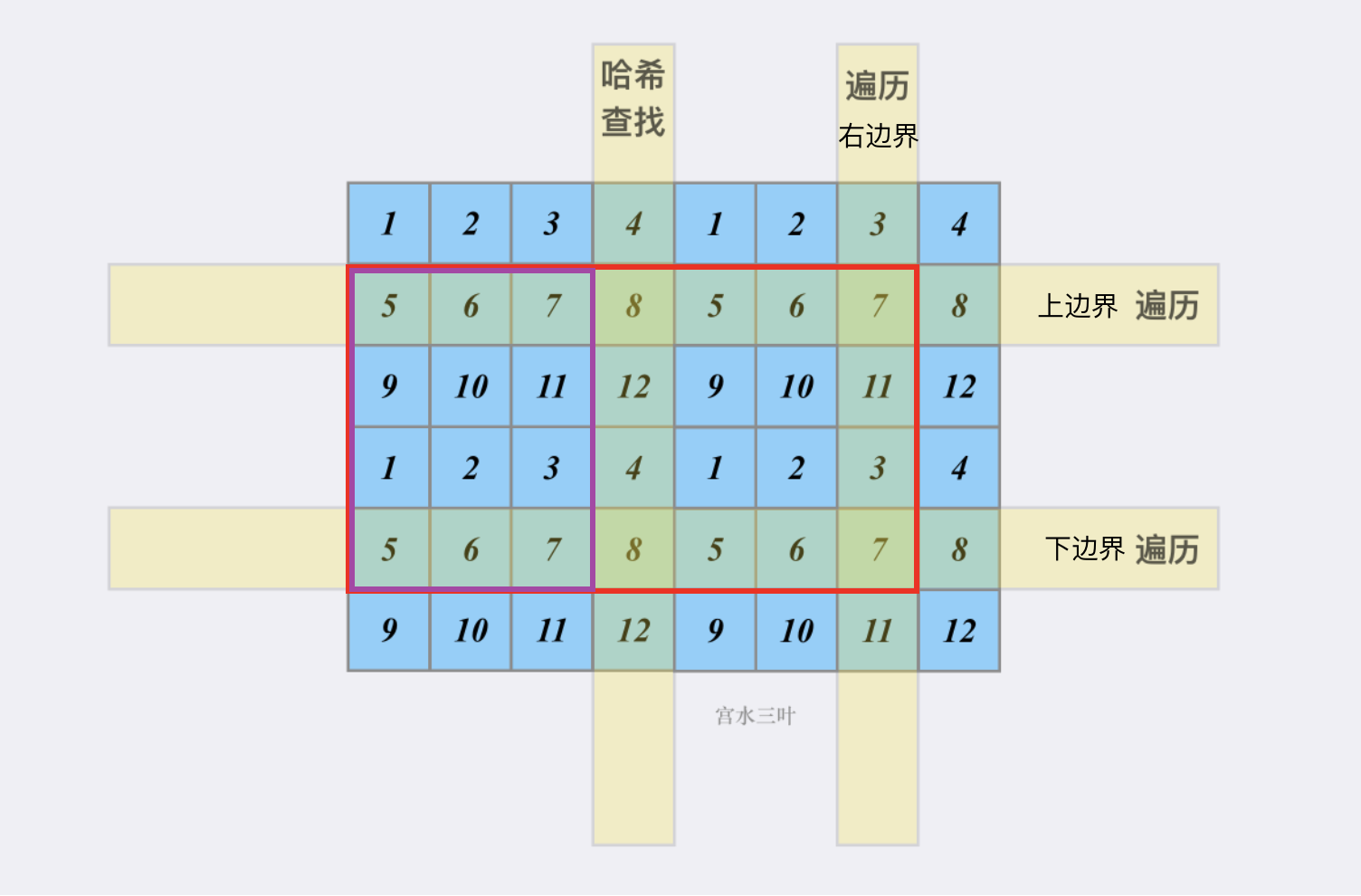
public int numSubMatrixSumTarget(int[][] matrix, int target) { int n = matrix.length, m = matrix[0].length; int[][] pre = new int[n + 1][m + 1]; for (int i = 0; i < n; ++i) { for (int j = 0; j < m; ++j) { pre[i + 1][j + 1] = pre[i][j + 1] + pre[i + 1][j] - pre[i][j] + matrix[i][j]; } } int ans = 0; for (int top = 0; top < n; ++top) { for (int bot = top; bot < n; ++bot) { int cur = 0; Map<Integer, Integer> map = new HashMap<>(); map.put(0, 1); //效果等同于注释部分 for (int right = 0; right < m; ++right) { cur = pre[bot + 1][right + 1] - pre[top][right + 1]; // if (cur == target) { // ans ++; // } if (map.containsKey(cur - target)) { ans += map.get(cur - target); } map.put(cur, map.getOrDefault(cur, 0) + 1); } } } return ans; }363. 矩形区域不超过 K 的最大数值和
该题无法由 325. 和等于 k 的最长子数组长度 和 560. 和等于K 的子数组数量一维提升为二维,因为这是一个全新的问题,转换为一维应该描述为「和不超过K的子数组最大和」
前缀和暴力解
跟上题一样public int maxSumSubmatrix(int[][] mat, int k) { int m = mat.length, n = mat[0].length; int[][] sum = new int[m + 1][n + 1]; for (int i = 1; i <= m; i++) { for (int j = 1; j <= n; j++) { sum[i][j] = sum[i - 1][j] + sum[i][j - 1] - sum[i - 1][j - 1] + mat[i - 1][j - 1]; } } int ans = Integer.MIN_VALUE; for (int i = 1; i <= m; i++) { for (int j = 1; j <= n; j++) { for (int p = i; p <= m; p++) { for (int q = j; q <= n; q++) { int cur = sum[p][q] - sum[i - 1][q] - sum[p][j - 1] + sum[i - 1][j - 1]; if (cur <= k) { ans = Math.max(ans, cur); } } } } } return ans; }哈希表+二分—抽象一维
class Solution { public int maxSumSubmatrix(int[][] mat, int k) { int m = mat.length, n = mat[0].length; // 预处理前缀和 int[][] sum = new int[m + 1][n + 1]; for (int i = 1; i <= m; i++) { for (int j = 1; j <= n; j++) { sum[i][j] = sum[i - 1][j] + sum[i][j - 1] - sum[i - 1][j - 1] + mat[i - 1][j - 1]; } } int ans = Integer.MIN_VALUE; // 遍历子矩阵的上边界 for (int top = 1; top <= m; top++) { // 遍历子矩阵的下边界 for (int bot = top; bot <= m; bot++) { // 使用「有序集合」维护所有遍历到的右边界 TreeSet<Integer> ts = new TreeSet<>(); ts.add(0); // 遍历子矩阵的右边界 for (int r = 1; r <= n; r++) { // 通过前缀和计算 right int right = sum[bot][r] - sum[top - 1][r]; // 通过二分找 left Integer left = ts.ceiling(right - k); if (left != null) { int cur = right - left; ans = Math.max(ans, cur); } // 将遍历过的 right 加到有序集合 ts.add(right); } } } return ans; } }1314. 矩阵区域和
面试题 17.24. 最大子矩阵
还是使用前缀和+抽象一维,在使用TreeMap在O(1)的时间复杂度内找到最小的左边界
public int[] getMaxMatrix(int[][] matrix) { int n = matrix.length, m = matrix[0].length; int[] ans = new int[4]; //pre sum int[][] pre = new int[n + 1][m + 1]; for (int i = 0; i < n; ++i) { for (int j = 0; j < m; ++j) { pre[i + 1][j + 1] = pre[i + 1][j] + pre[i][j + 1] - pre[i][j] + matrix[i][j]; } } int sum = Integer.MIN_VALUE / 2; for (int top = 0; top < n; ++top) { for (int bot = top; bot < n; ++bot) { TreeMap<Integer, Integer> tm = new TreeMap<>(); tm.put(0, 0); for (int right = 0; right < m; ++right) { int rightSum = pre[bot + 1][right + 1] - pre[top][right + 1]; Map.Entry<Integer, Integer> firstEntry = tm.firstEntry(); int leftSum = firstEntry.getKey(); if (rightSum - leftSum > sum) { sum = rightSum - leftSum; ans[0] = top; ans[1] = firstEntry.getValue(); ans[2] = bot; ans[3] = right; } tm.put(rightSum, right+1); } } } return ans; }运算推广
前缀积
「前缀积」==「取对数后前缀和」,有时为了避免超限制可以这么操作152. 乘积最大子数组
713. 乘积小于K的子数组
前缀积
超时且越限制,因为我把所有数的乘积都算出来了,实际上没必要,随时更新就好了,如果他大于k,跳出循环即可,是一种暴力方法public int numSubarrayProductLessThanK(int[] nums, int k) { int len = nums.length; int ans = 0; for(int i=0; i<len; i++) { int preMul = 1; for(int j=i; j<len; j++) { preMul = preMul * nums[j]; if(preMul < k) { ans++; } else { break; } } } return ans; }前缀对数和
将所有数取对数,然后将前缀积转换为前缀对数和,这样可以不超限制,这样我们可以用二分,在logn时间复杂度内找出符合条件的最大的前缀,然后这个前缀对应的下标之后的所有下标,都可以作为数组的左边界
双指针
上面的暴力还可以优化,无须遍历左边界,设置一个指针如果积大了,那就移动左指针,直到积小于k,然后答案加上左右指针的距离
代码中条件**left <= right**是为了防止k为0的情况,可以在前面添加判断条件if k <= 1, return 0public int numSubarrayProductLessThanK(int[] nums, int k) { int n = nums.length; int ans = 0; int left = 0; int pre = 1; for (int right = 0; right < n; ++right) { pre *= nums[left]; while (left <= right && pre >= k) { pre /= nums[left++]; } ans += right - left + 1; } return ans; }1352. 最后 K 个数的乘积
维护一个前缀积,遇到零就清空数组,最后求结果的时候如果数组长度小于k,说明里面有0,返回0即可
其实还有进阶问题,如果是任意区间的乘积怎么算,可以考虑维护一个0的前缀和,如果区间右端点-左端点的前缀和无变化,那么说明没有0,不然就是有0前缀异或
1310. 子数组异或查询
pre[i] = arr[0]^...^arr[i-1]pre[j+1] = arr[0]^...^arr[i-1]^arr[i]^...^arr[j]ans[i:j] = pre[j+1] ^ pre[i]
即a^b = c, 那么a^b^b = a = c^b1442. 形成两个异或相等数组的三元组数目
三重循环
居然过了a == b <==> pre[j] ^ pre[i] == pre[k + 1] ^ pre[j]
即pre[i] == pre[k + 1]public int countTriplets(int[] arr) { int n = arr.length; if (n < 2) { return 0; } int[] pre = new int[n + 1]; for (int i = 0; i < n; ++i) { pre[i + 1] = pre[i] ^ arr[i]; } int ans = 0; for (int i = 0; i < n; ++i) { for (int j = i + 1; j < n; ++j) { for (int k = j; k < n; ++k) { int a = pre[j] ^ pre[i]; int b = pre[k + 1] ^ pre[j]; if (a == b) { ans++; } } } } return ans; }二重循环
由上面a == b <==> pre[i] == pre[k + 1],可知,只要两个前缀相等,j是无关紧要的,换句话说[i+1 : k]中的任何一个j都可以,也就是说有k-i个三元组,只需要枚举i、k即可public int countTriplets(int[] arr) { int n = arr.length; int[] s = new int[n + 1]; for (int i = 0; i < n; ++i) { s[i + 1] = s[i] ^ arr[i]; } int ans = 0; for (int i = 0; i < n; ++i) { for (int k = i + 1; k < n; ++k) { if (s[i] == s[k + 1]) { ans += k - i; } } } return ans; }一重循环
接着上面分析,对于下标k,若下标i = i1,i2,i3...,im时都满足pre[i] == pre[k + 1],因此这些下标对答案的贡献为(k-i1)+(k-i2)+...+(k-im) = m*k - (i1 + i2 +...+im),也就是说,在遍历下标k的时候,pre[i] == pre[k + 1]时,我们需要知道「下标i出现的次数m」和「下标i之和」public int countTriplets(int[] arr) { int n = arr.length; // 预处理前缀异或数组 int[] sum = new int[n + 1]; for (int i = 1; i <= n; i++) sum[i] = sum[i - 1] ^ arr[i - 1]; int ans = 0; // 记录出现过的异或结果,存储格式:{ 异或结果 : [下标1, 下标2 ...] } Map<Integer, List<Integer>> map = new HashMap<>(); for (int k = 0; k <= n; k++) { List<Integer> list = map.getOrDefault(sum[k], new ArrayList<>()); for (int idx : list) { int i = idx + 1; ans += k - i; } list.add(k); map.put(sum[k], list); } return ans; }差分
370. 区间加法
public int[] getModifiedArray(int length, int[][] updates) { int[] ans = new int[length]; int[] diff = new int[length]; //构造差分 // diff[0] = ans[0] - 0; // for (int i = 1; i < length; ++i) { // diff[i] = ans[i] - ans[i - 1]; // } for (int[] update : updates) { diff[update[0]] += update[2]; if (update[1] + 1 < length) diff[update[1] + 1] -= update[2]; } ans[0] = diff[0]; // for (int i = 1; i < length; ++i) { // ans[i] = ans[i - 1] + diff[i]; // } // return ans; //直接原地修改即可 for (int i = 1; i < length; ++i) { diff[i] += diff[i - 1]; } return diff; }


若有收获,就点个赞吧
0 人点赞
