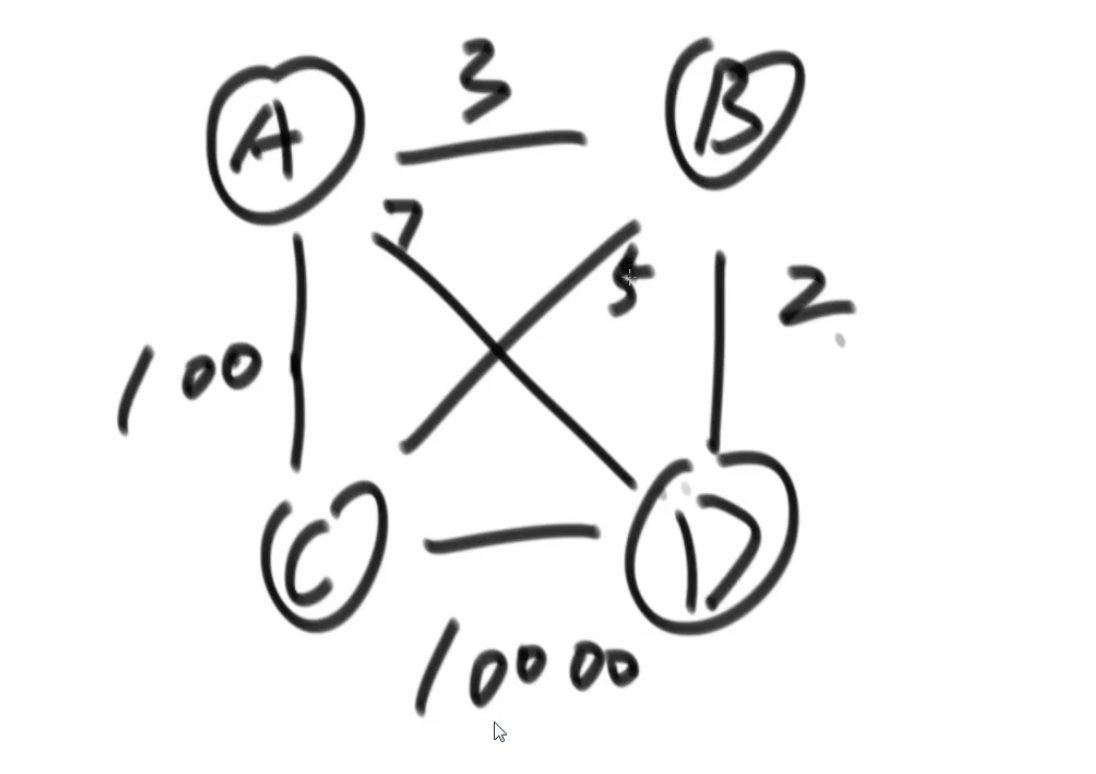
K算法和P算法,都是针对无向图的算法
首先保证连通性,
其次保证保留的边权重和最小
K和P算法里面有个比较恶心的结构: 并查集,可以用hashmap替代。
K算法:其实就是一种贪心。
step1 : 先按照边权重从小到大排序
step2: 判断形成的有没有形成环 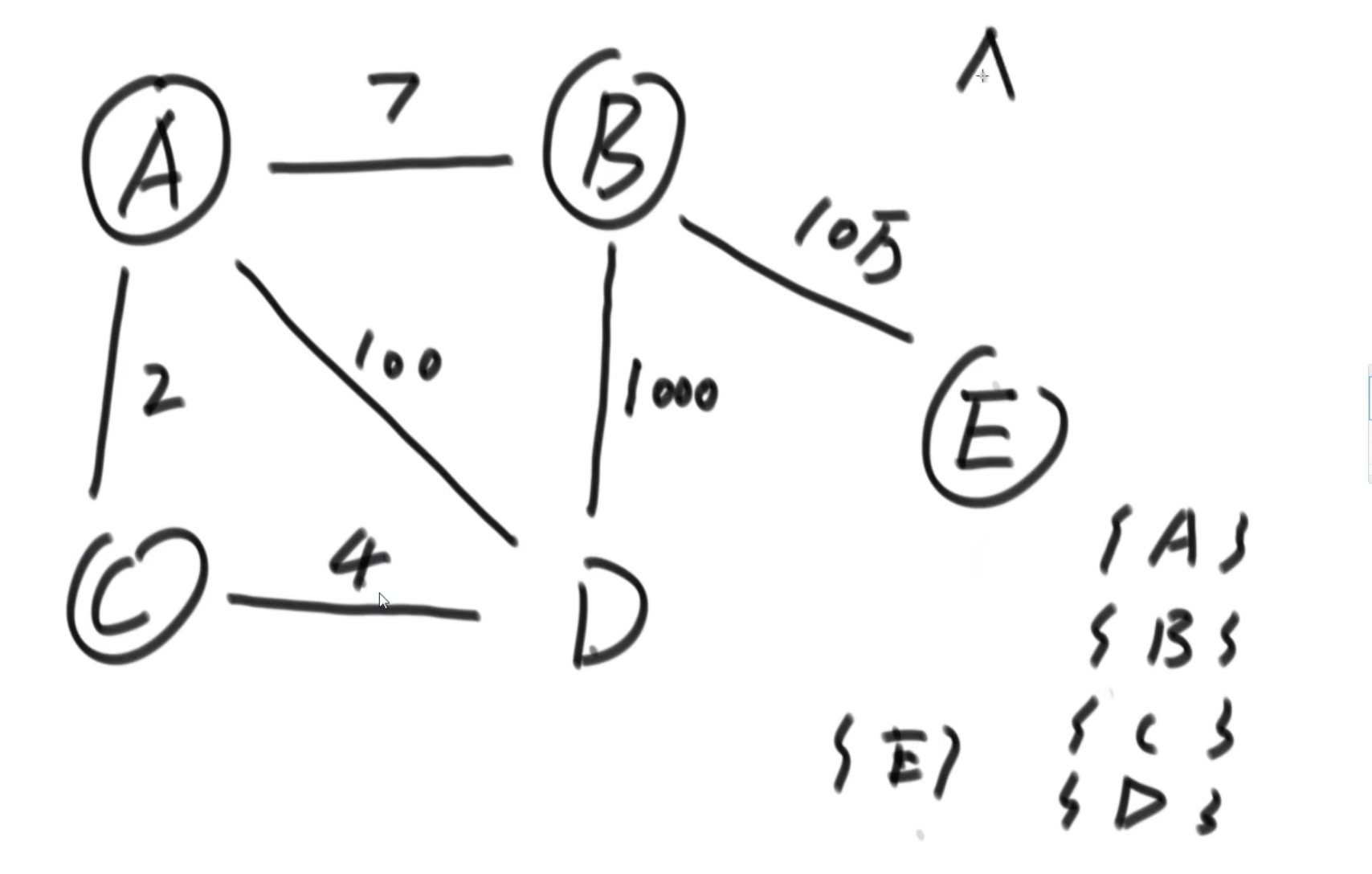
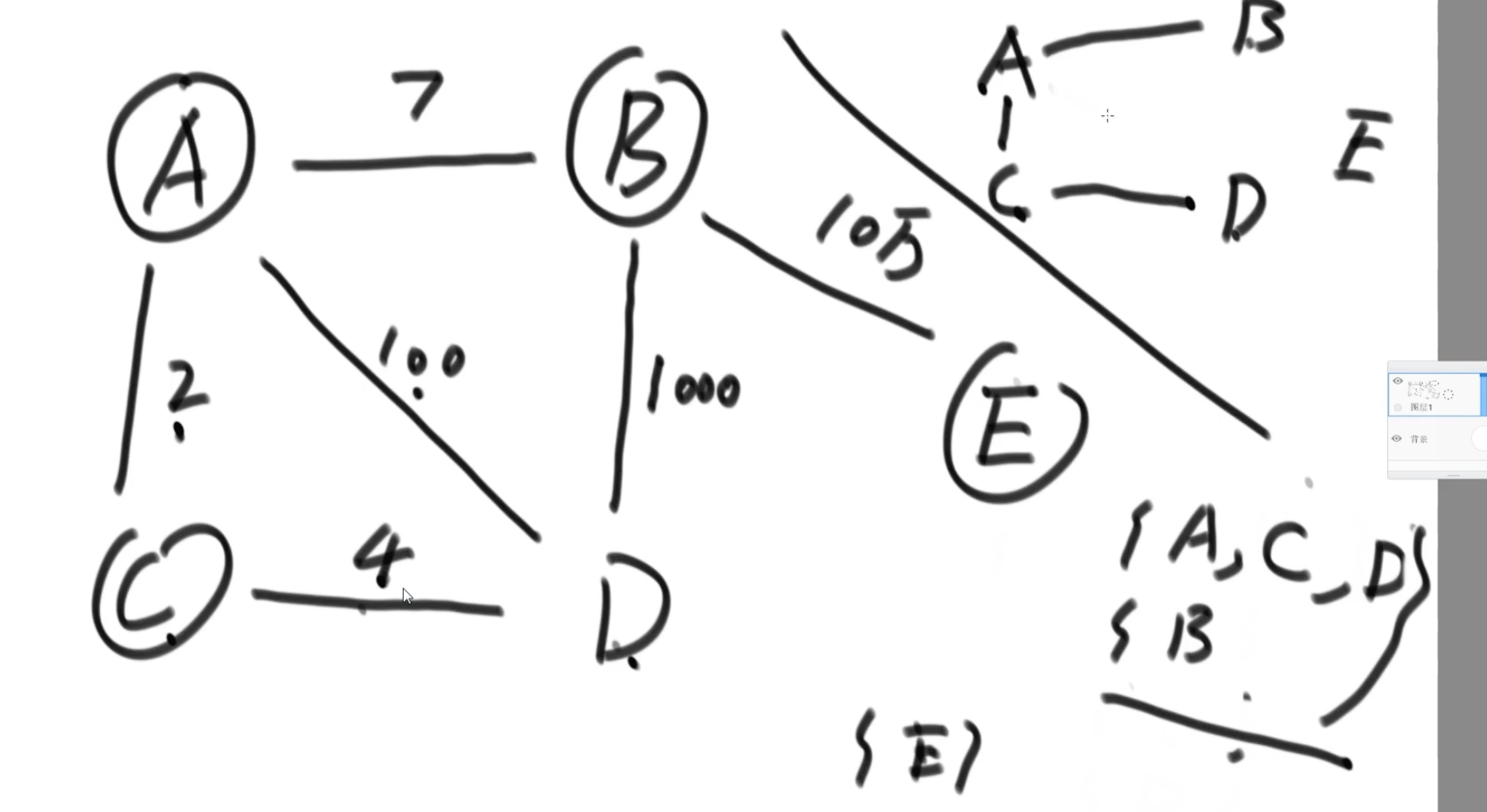
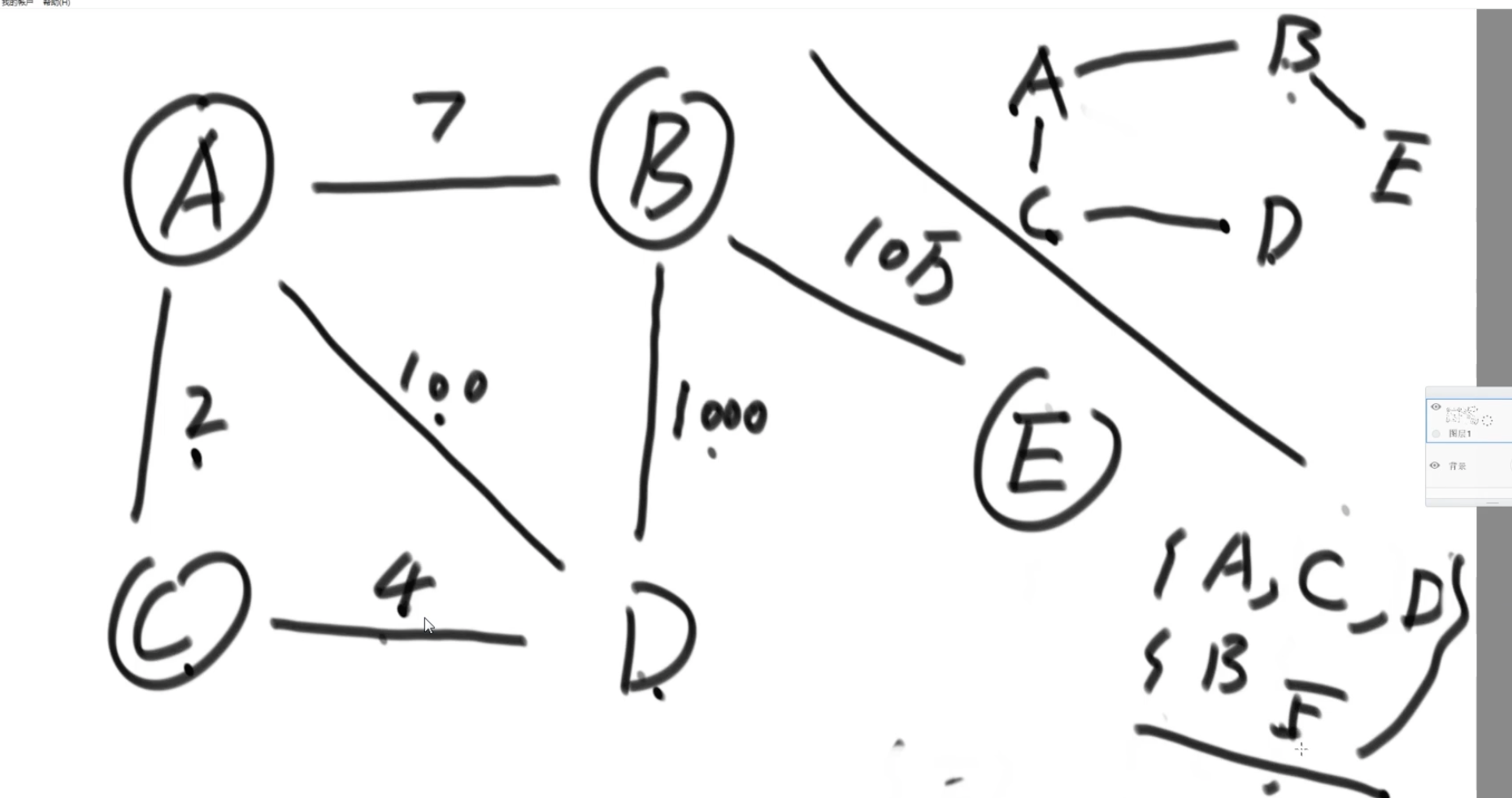
只要用某种机制做到集合查询和合并功能,就做到判断环了。
最优版本:并查集
替代版本:hash字典保存某个节点和集合的对应关系。
判断两个集合是不是一个:根据内存地址是否相等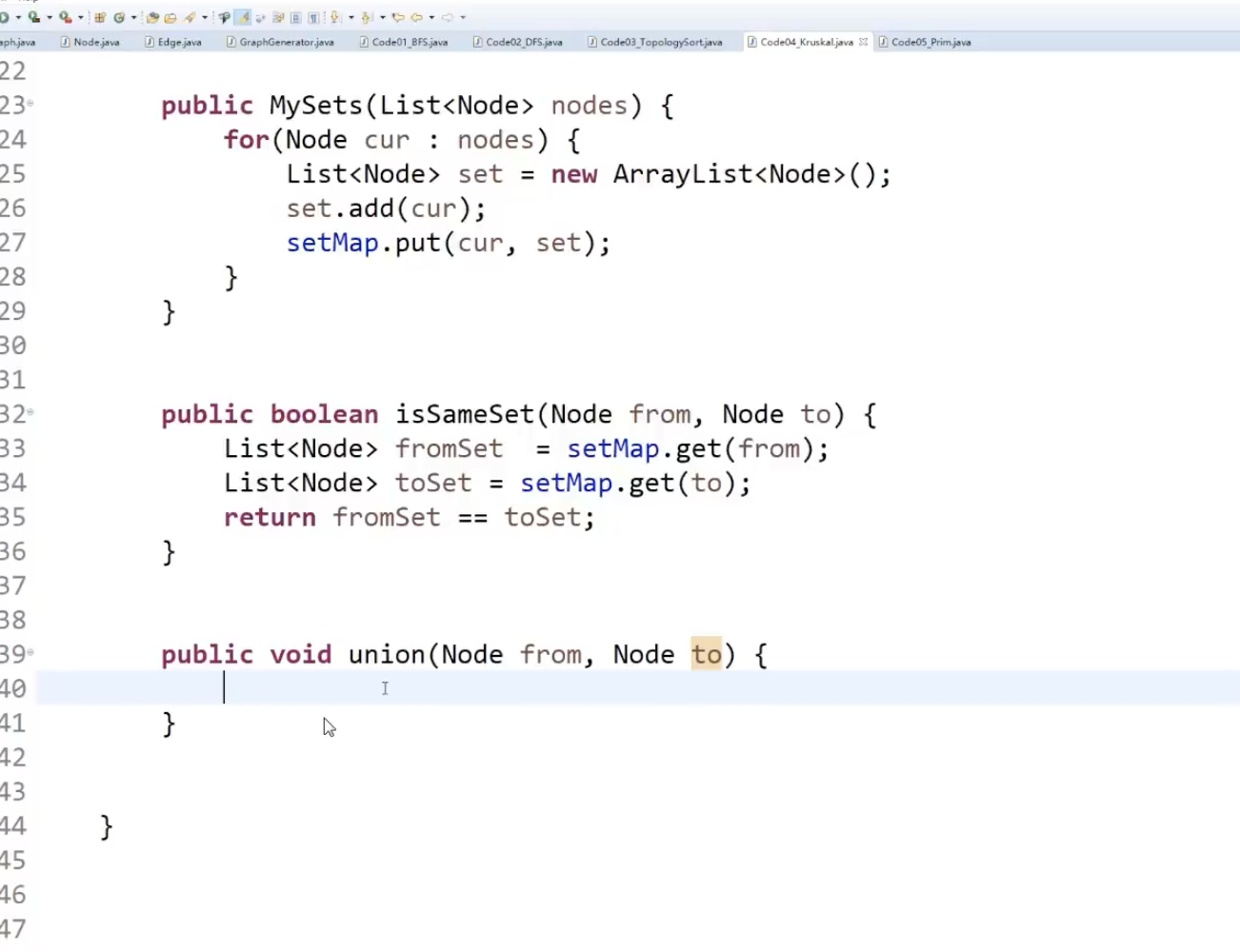
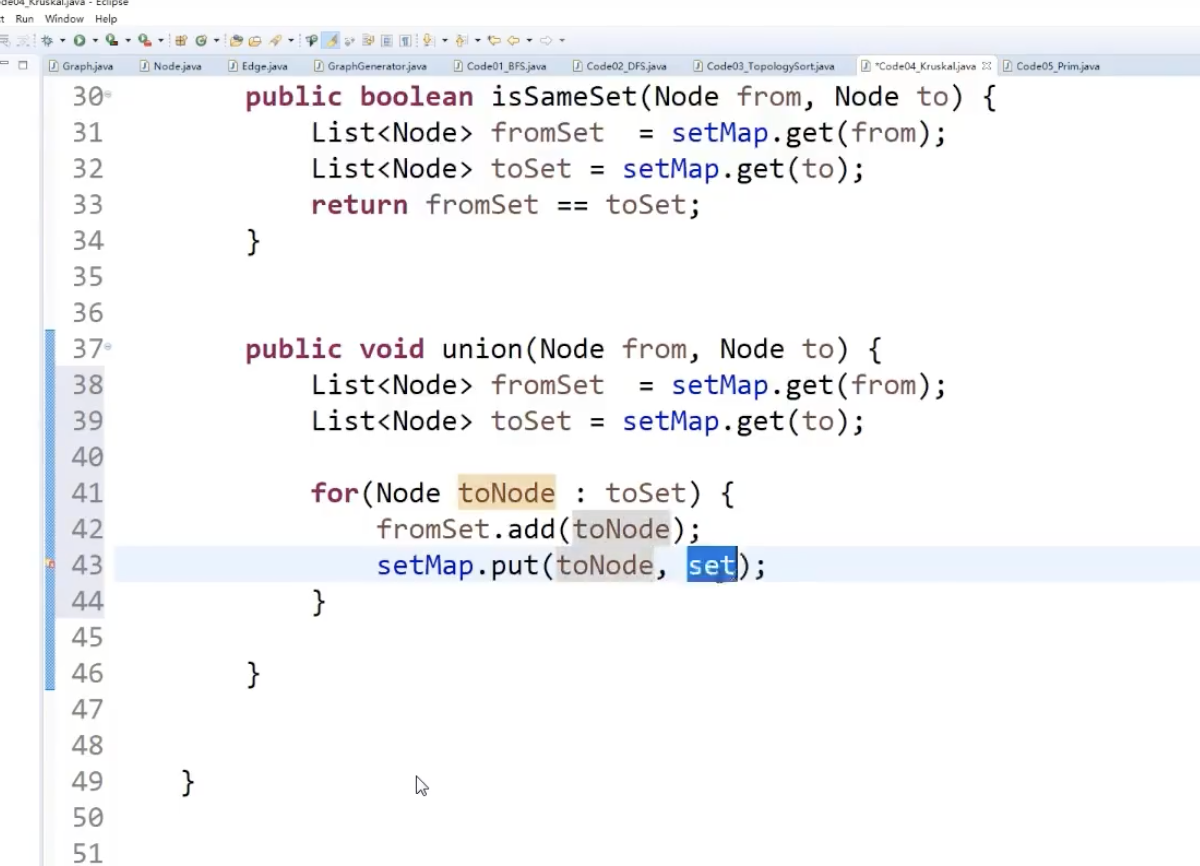
注意⚠️:这里的Union合并过程,最终目的是将from 和 to 两个结合中所有的 节点 合并成一个集合,我们要在map中修改其中每一个元素的对应关系,
所以这里的for循环不能用简单的fromSet.addAll替代,深度利用内存地址,将字典所有相关的指针指向一个
为爱发电,不错,找点事情干,买个触摸板挺好的。
K算法:
用优先队列实现边的权重排序。小根堆,Arrays.sort都可以,有序表应该都可以。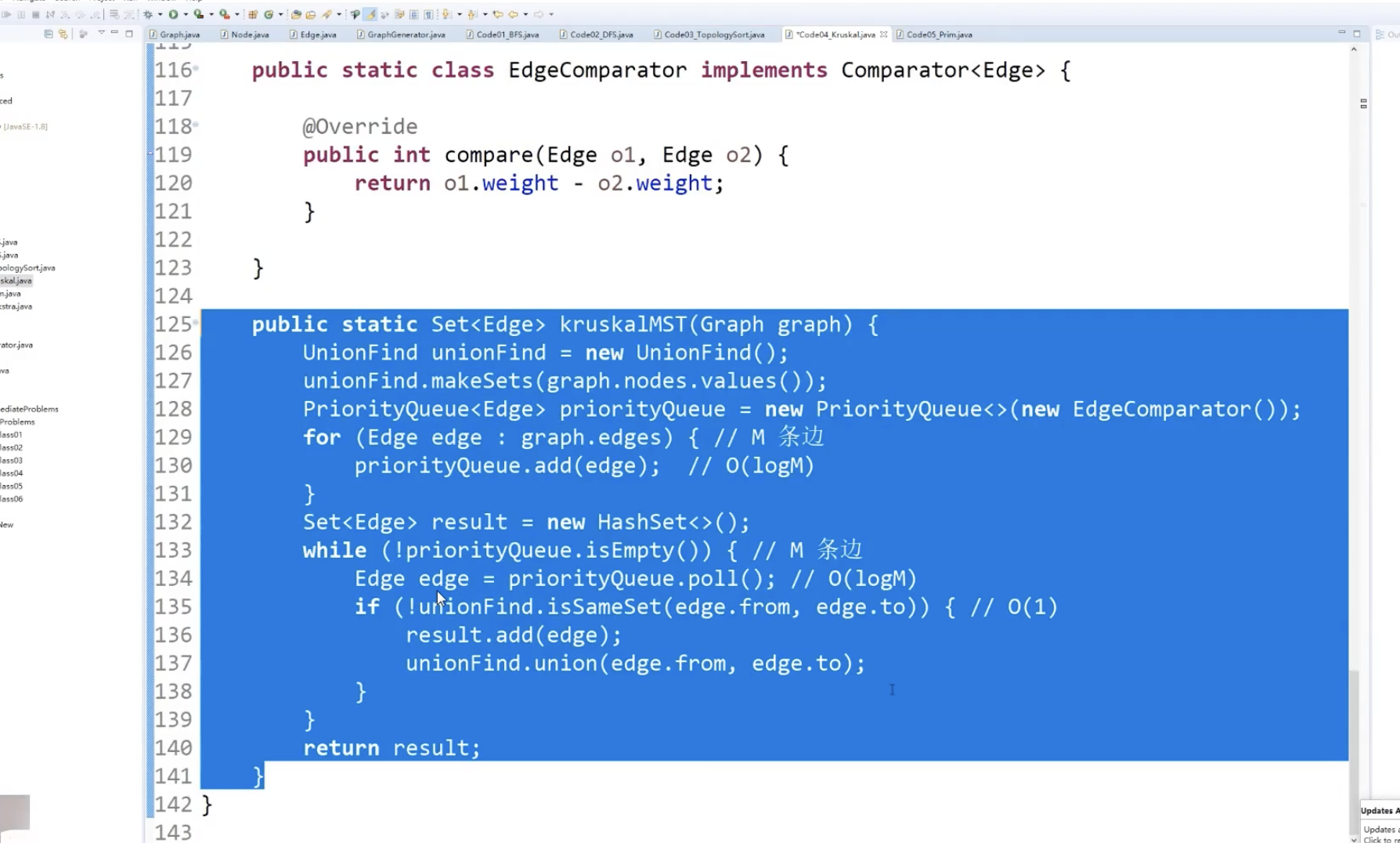
P算法:从点的角度来实现。
从哪个点出发都无所谓
不需要想K算法那样需要一个并查集结构,因为k算法里面是以边为考虑对象,可能形成不同的联通区域,需要合并咋i一起
而k算法这个每次拿进来一个点,
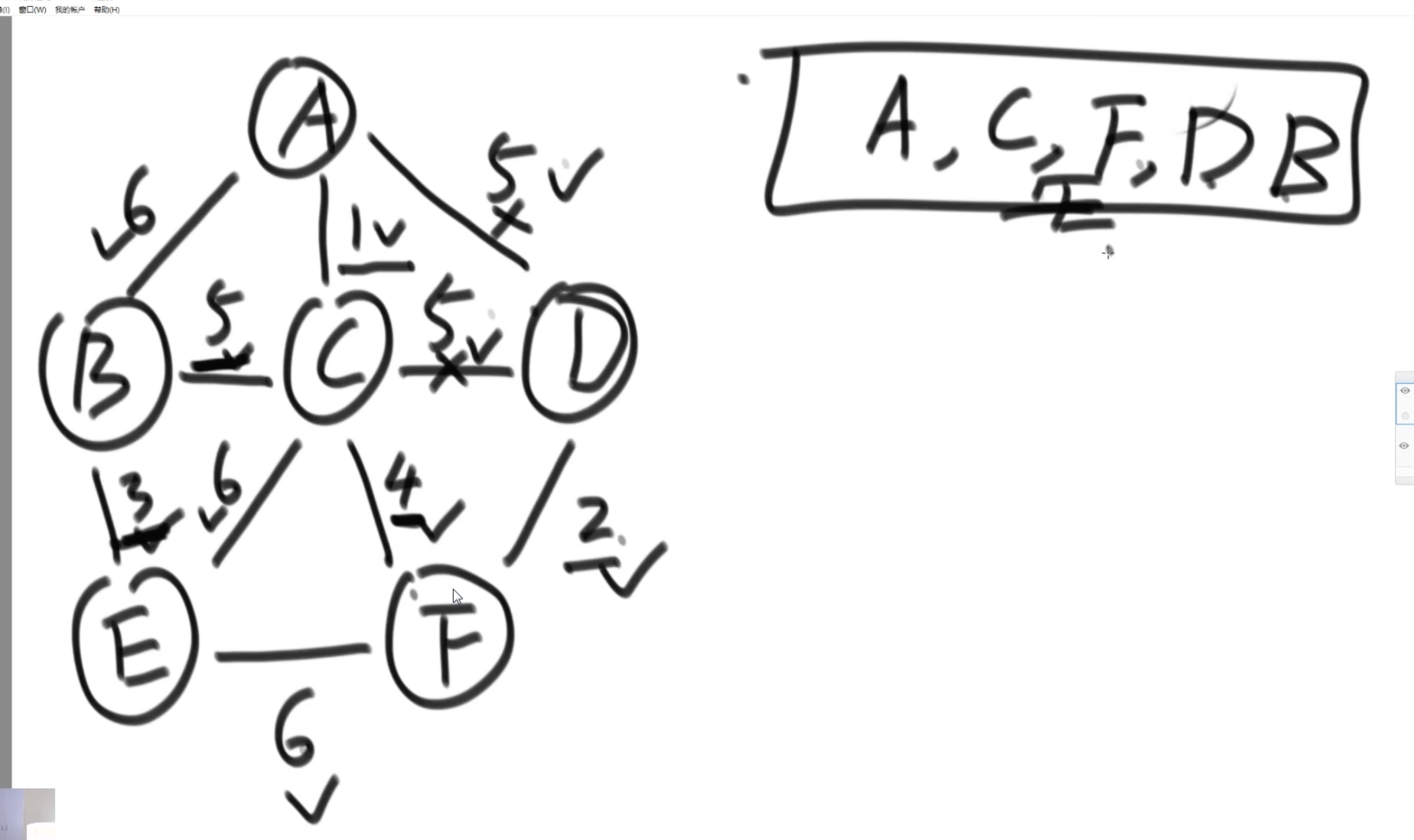
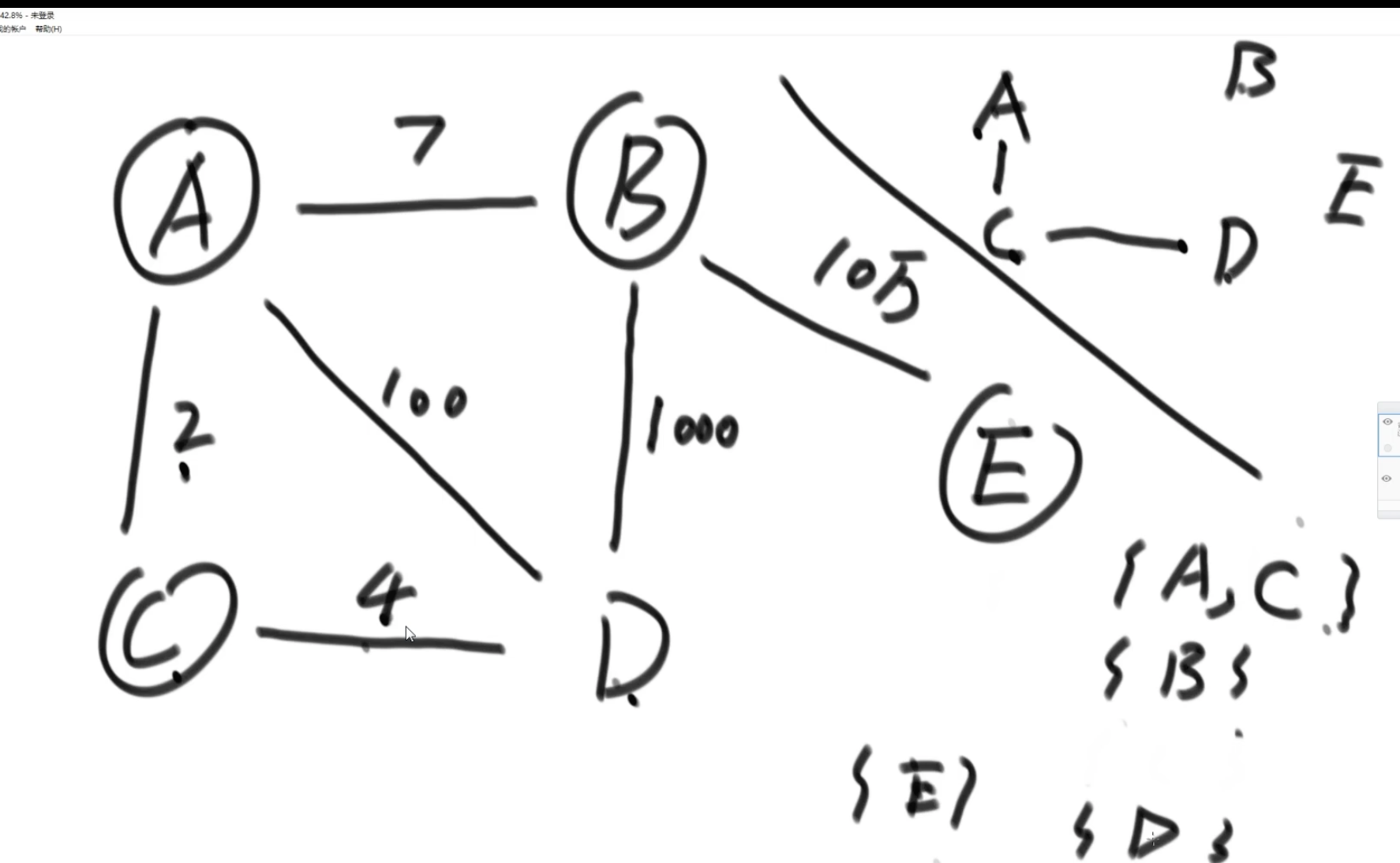
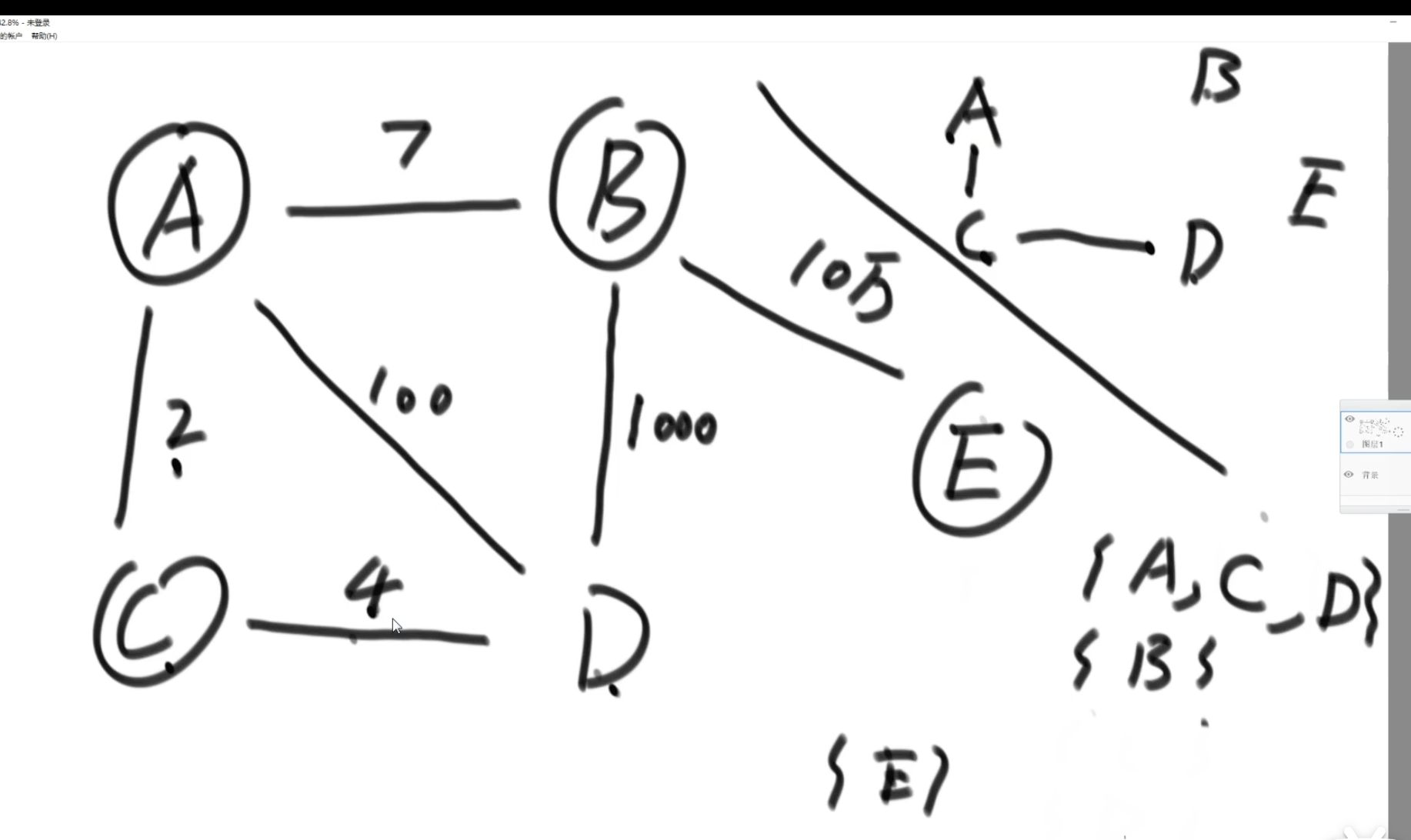
解法:
step1:任意选一个点,准备一个hashSet,将点介入hashSet中,并将相邻的边加入到一个小根堆中
step2,从小根堆中选一个权重最小的边,判断end节点是否在hashSet中,如果没有,将该点加入到hashset中,并将该点相邻的所有边(通过判断end节点是否在hashSet中保证不要重复加入)
step3:继续小根堆中查找权重最小且不形成环的边。
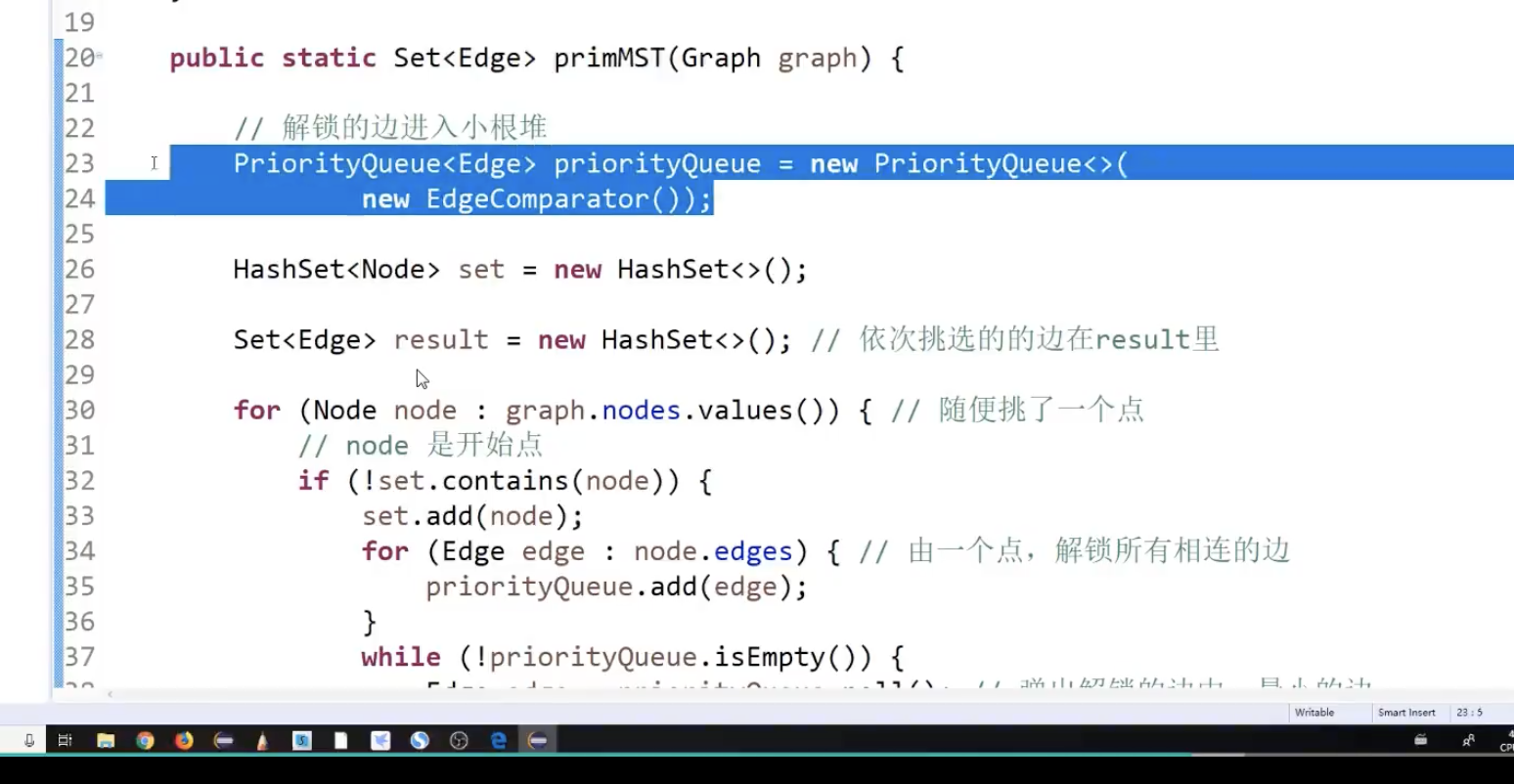
最外层的循环是为了找不同的各自独立的联通区域。
感觉可以用来找音符的不同小符号。
左程云:森林问题
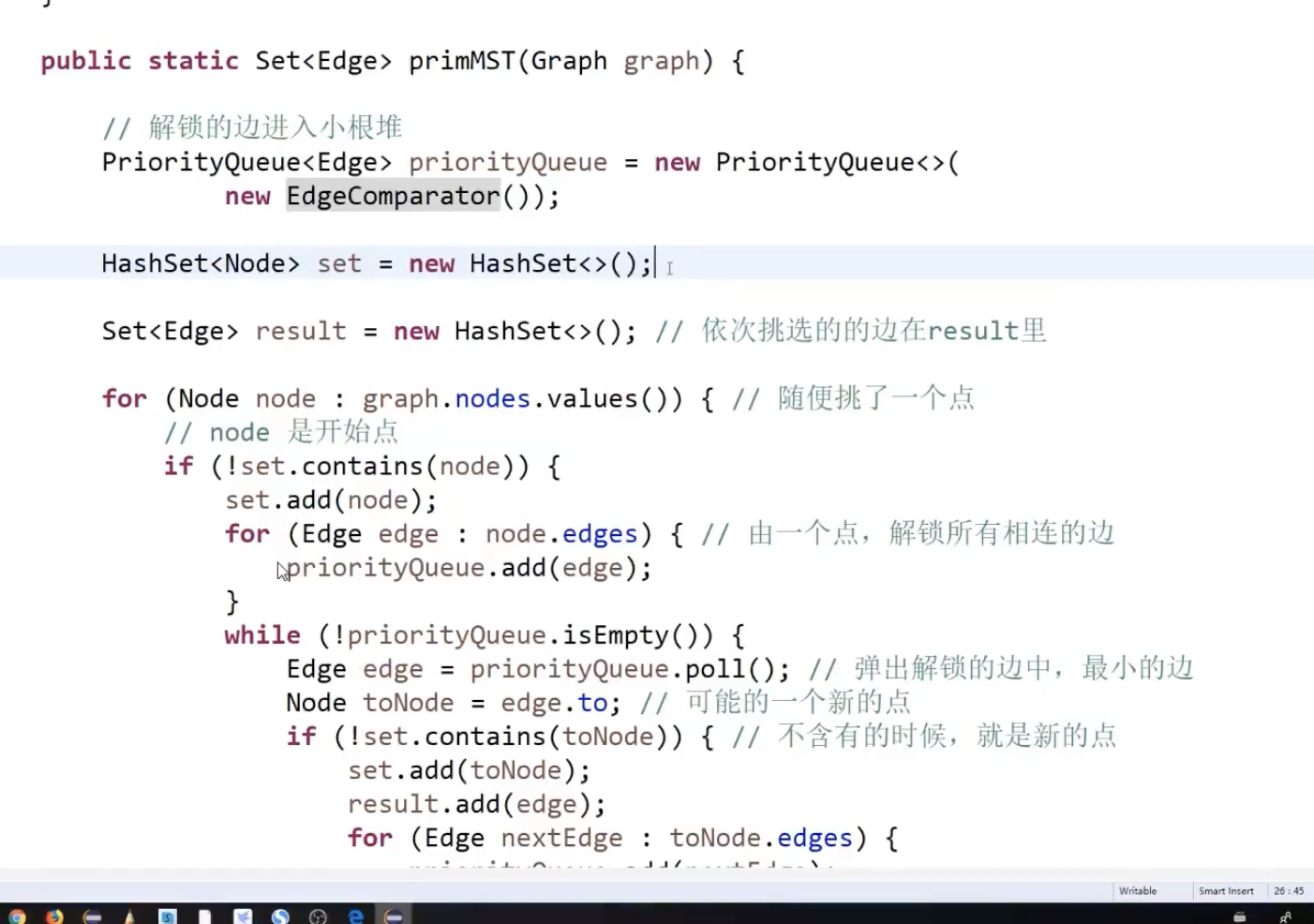
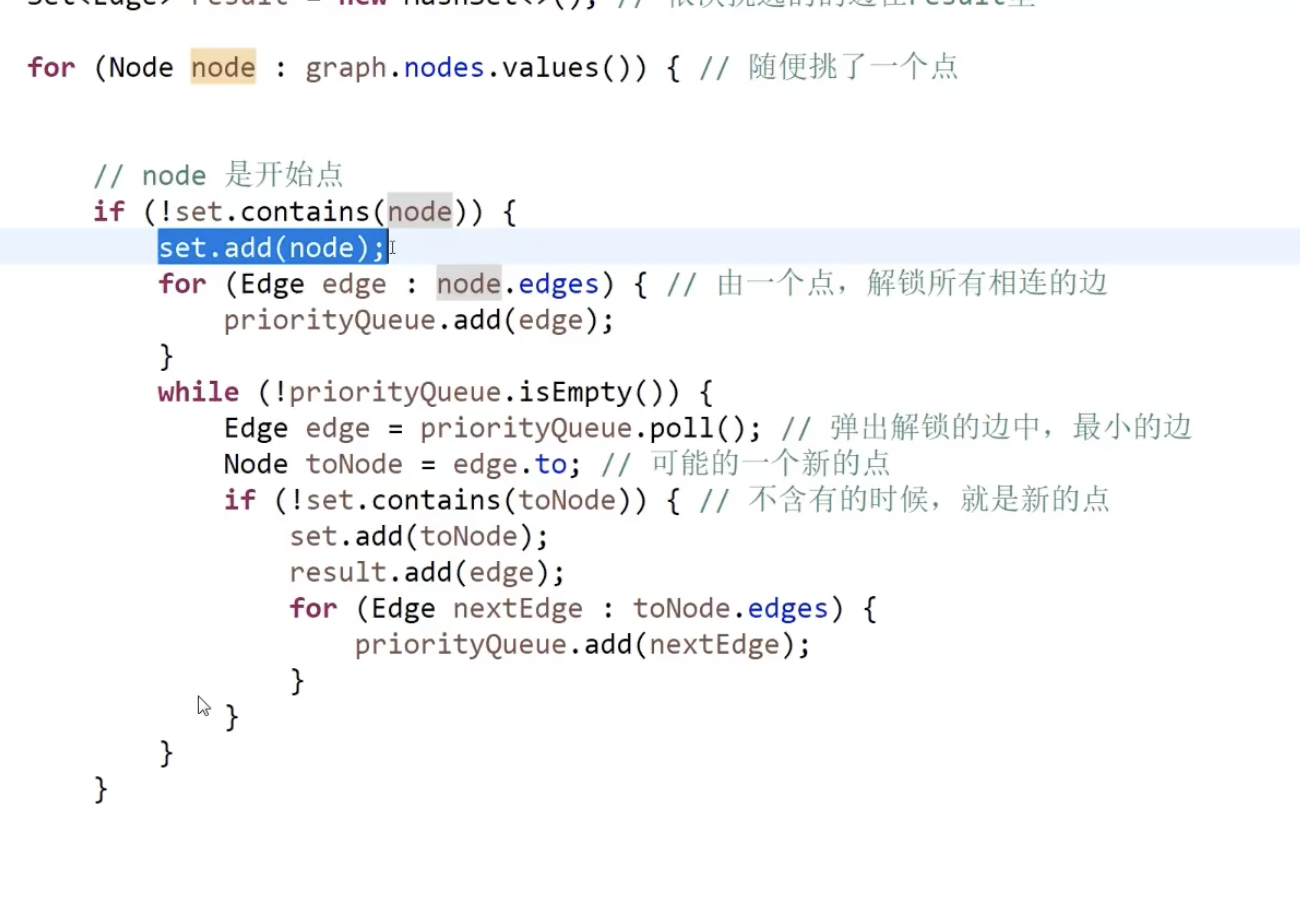
最优这行代码应该要优化一下,因为边会重复进队列。增加了常熟时间

若有收获,就点个赞吧
0 人点赞
