预备知识:左程云初级班p9

功能:
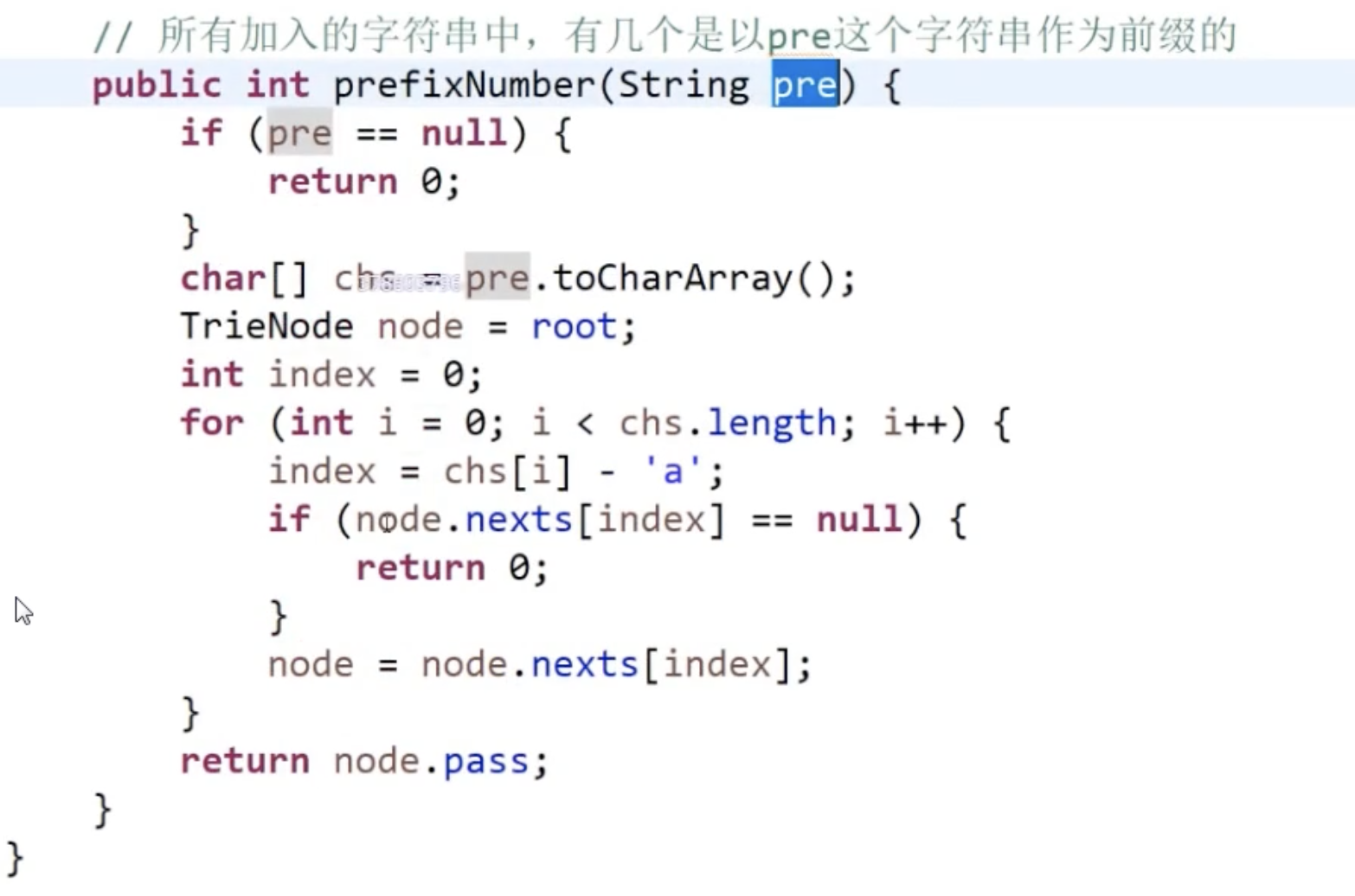
- 找字符串的公共前缀,可以用来做检索
- ac自动机中应用了kmp和前缀树的思想。
- 可以利用前缀树思想做一些贪心策略,这个印象中有一道难题。
具体建树过程:
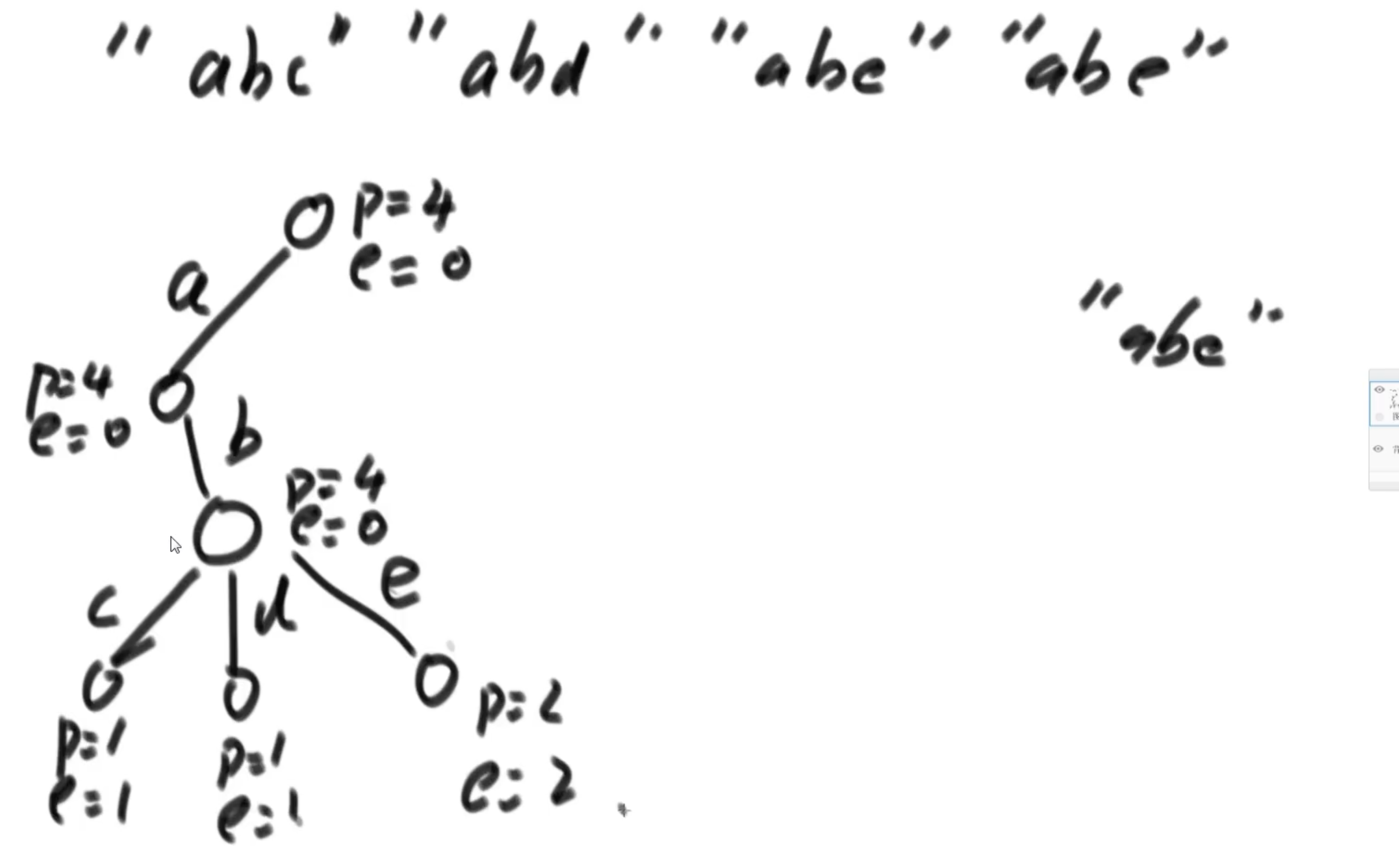
- 用语料构建一颗多叉树(字符就26,更多的话用treeMap来做),比如上图例子中的arr1
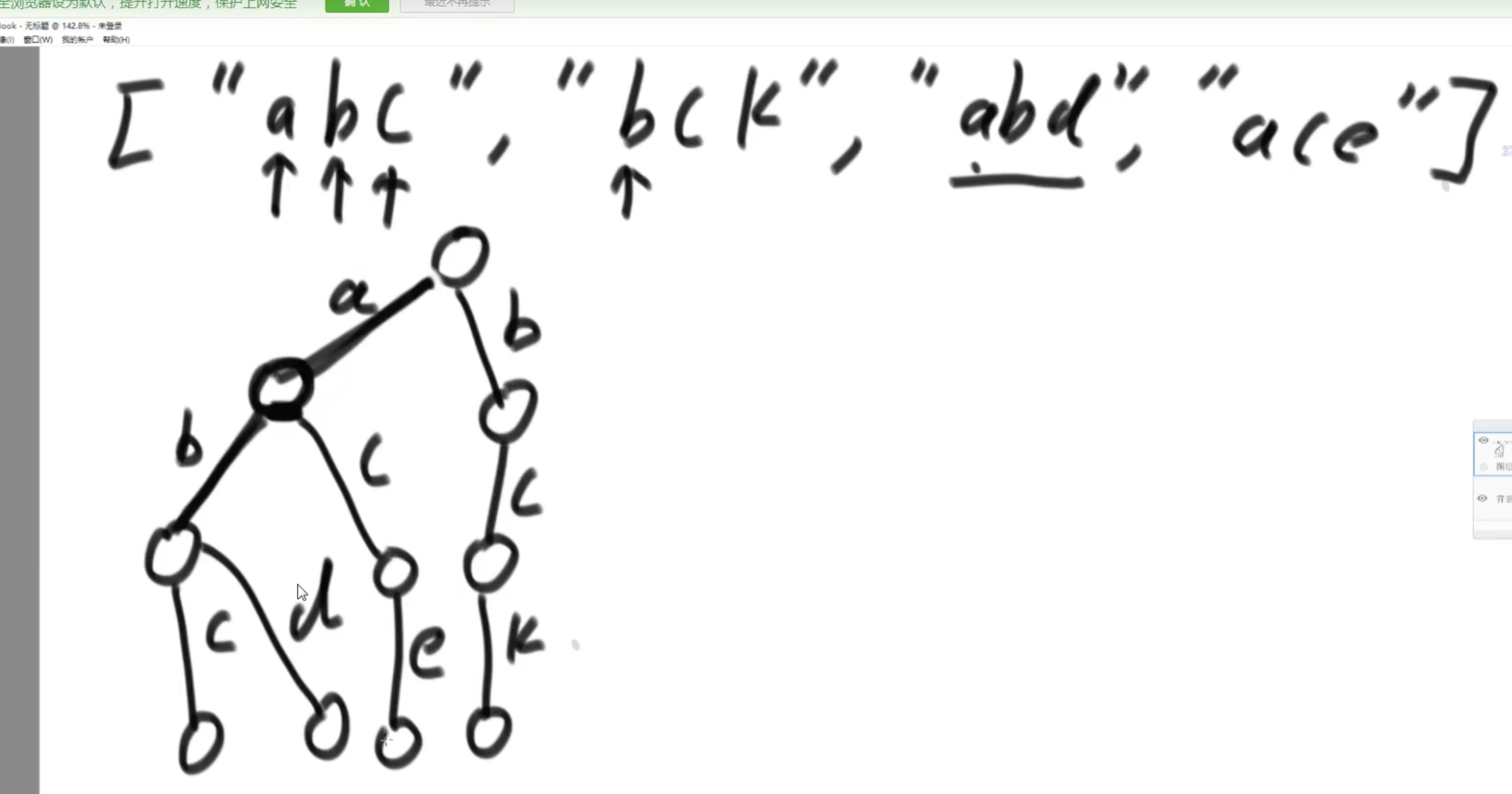
一道例题:
找几个字符串的公共前缀,从这道题给的四种题解看出复杂度还是MN级别的。
所以不妨用前缀树来实现这道题。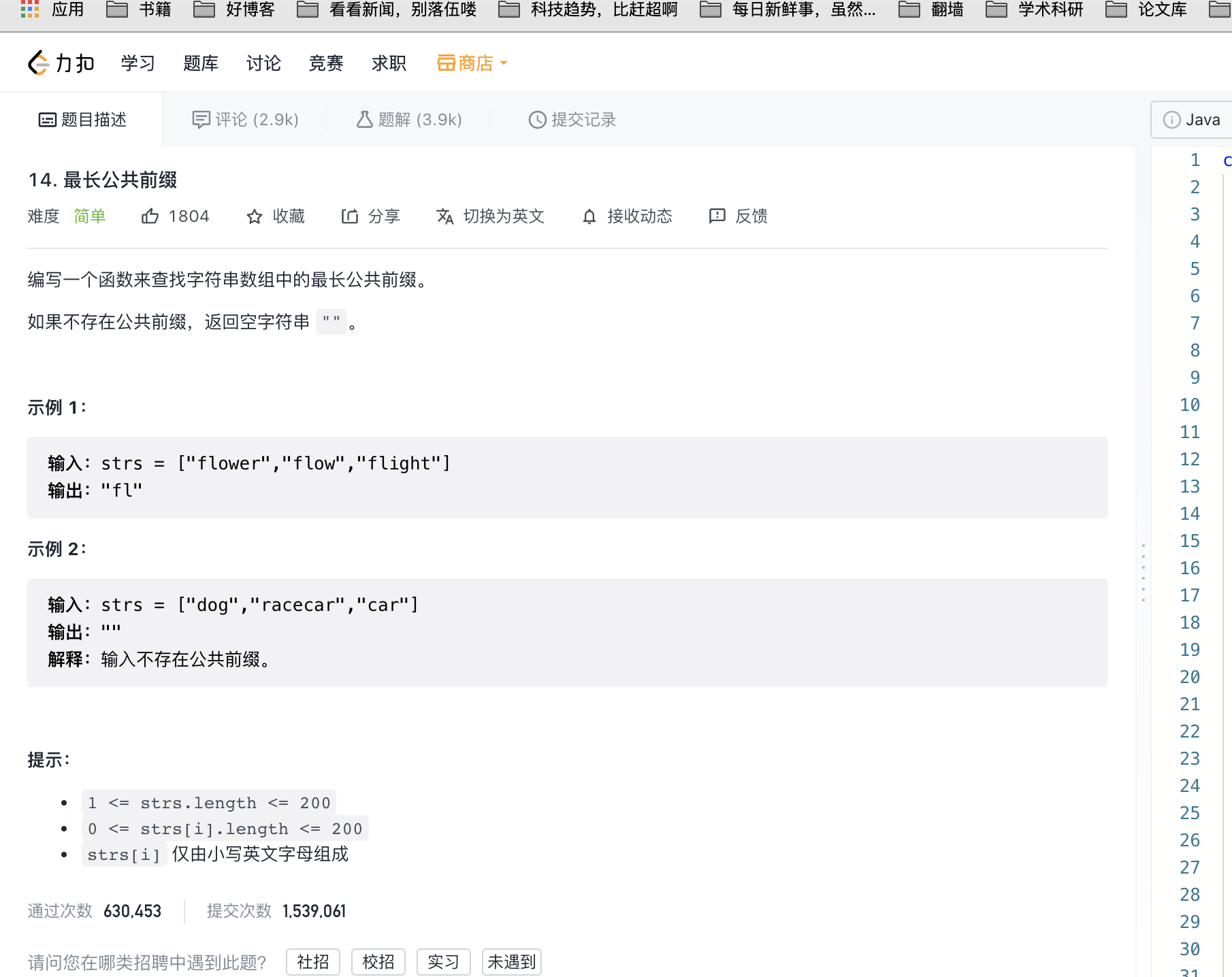
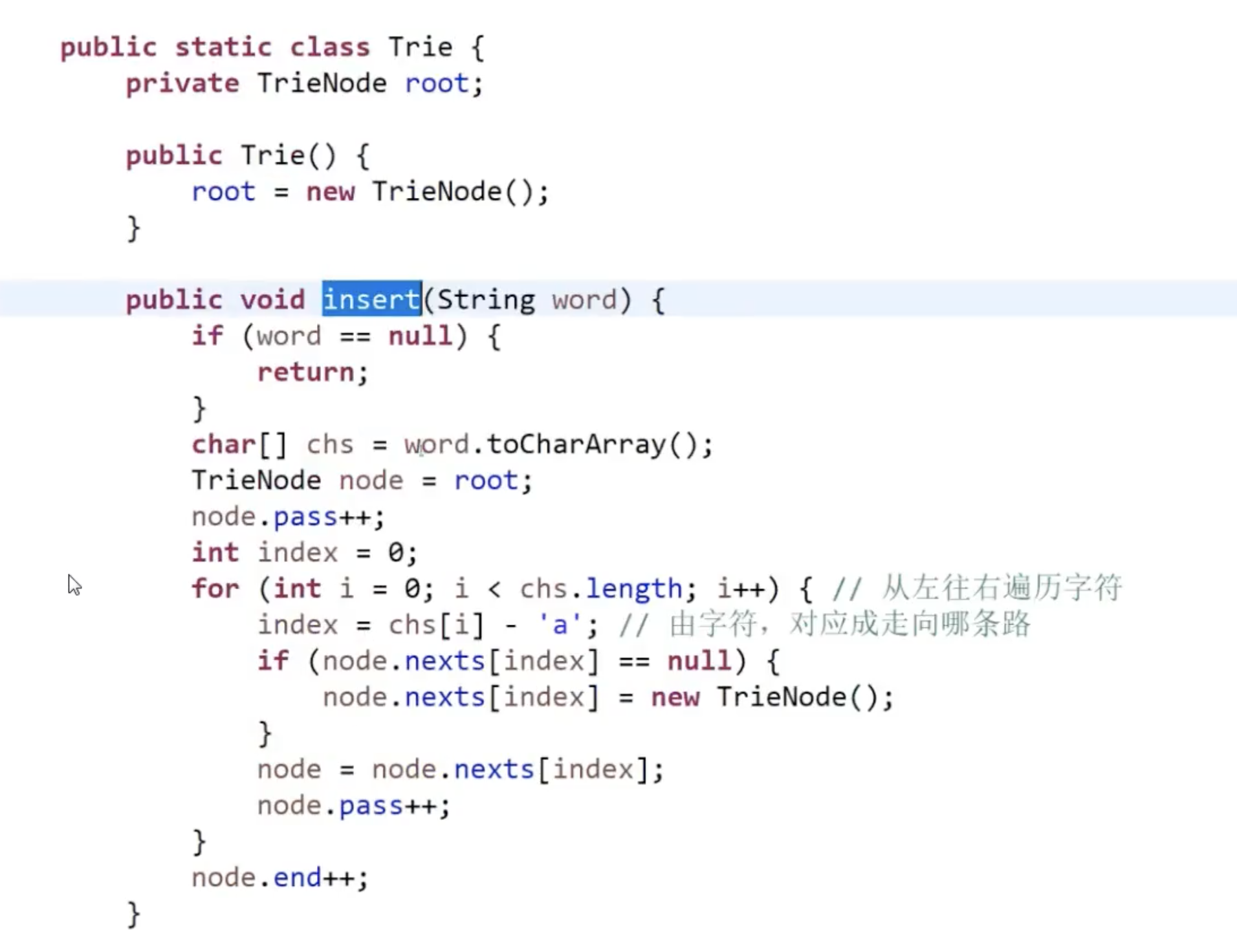
对比我写的和 左程云版本,思考在工程上如何封装组件
- 这里我的变量全用了public,没有提供set方法,不安全。
Tie树初始化的时候用了一个没有实际意义,或者说代表空串的root节点来创建。
public static void main(String[] args) {String[] strs = {"flower","flow","flight"};String[] strs2 = {"dog","racecar","car"};System.out.println(longestCommonPrefix(strs));System.out.println(longestCommonPrefix(strs2));}public static String longestCommonPrefix(String[] strs) {Node node = new Node(0,0);Trie trie = new Trie(node);for(String str : strs){char[] chs = str.toCharArray();trie.add(chs);}String str0 = strs[0];char[] chs0 = str0.toCharArray();int index=0;Node cur = node;StringBuilder sb = new StringBuilder();while(index< chs0.length){if(cur.nodes[chs0[index]-'a'] == null) return "";if(cur.nodes[chs0[index]-'a'].p == strs.length){sb.append(chs0[index]);cur = cur.nodes[chs0[index]-'a'];index++;}else {break;}}return sb.toString();}public static class Node{int p;int e;Node[] nodes;public Node(int p, int e) {this.p = p;this.e = e;this.nodes = new Node[26];}}public static class Trie{Node root;public Trie(Node root) {this.root = root;}public void add(char[] chs){Node cur = root;int index = 0;while(index < chs.length){if(cur.nodes[chs[index]-'a'] == null ){if(index == chs.length-1){cur.nodes[chs[index]-'a'] = new Node(1,1);}else {cur.nodes[chs[index]-'a'] = new Node(1,0);}}else {cur.nodes[chs[index]-'a'].p++;if(index == chs.length-1){cur.nodes[chs[index]-'a'].e++;}}cur = cur.nodes[chs[index]-'a'];index++;}}}
与左程云版本对比
考虑的细节:命名边,用的nexts数组语义好一些
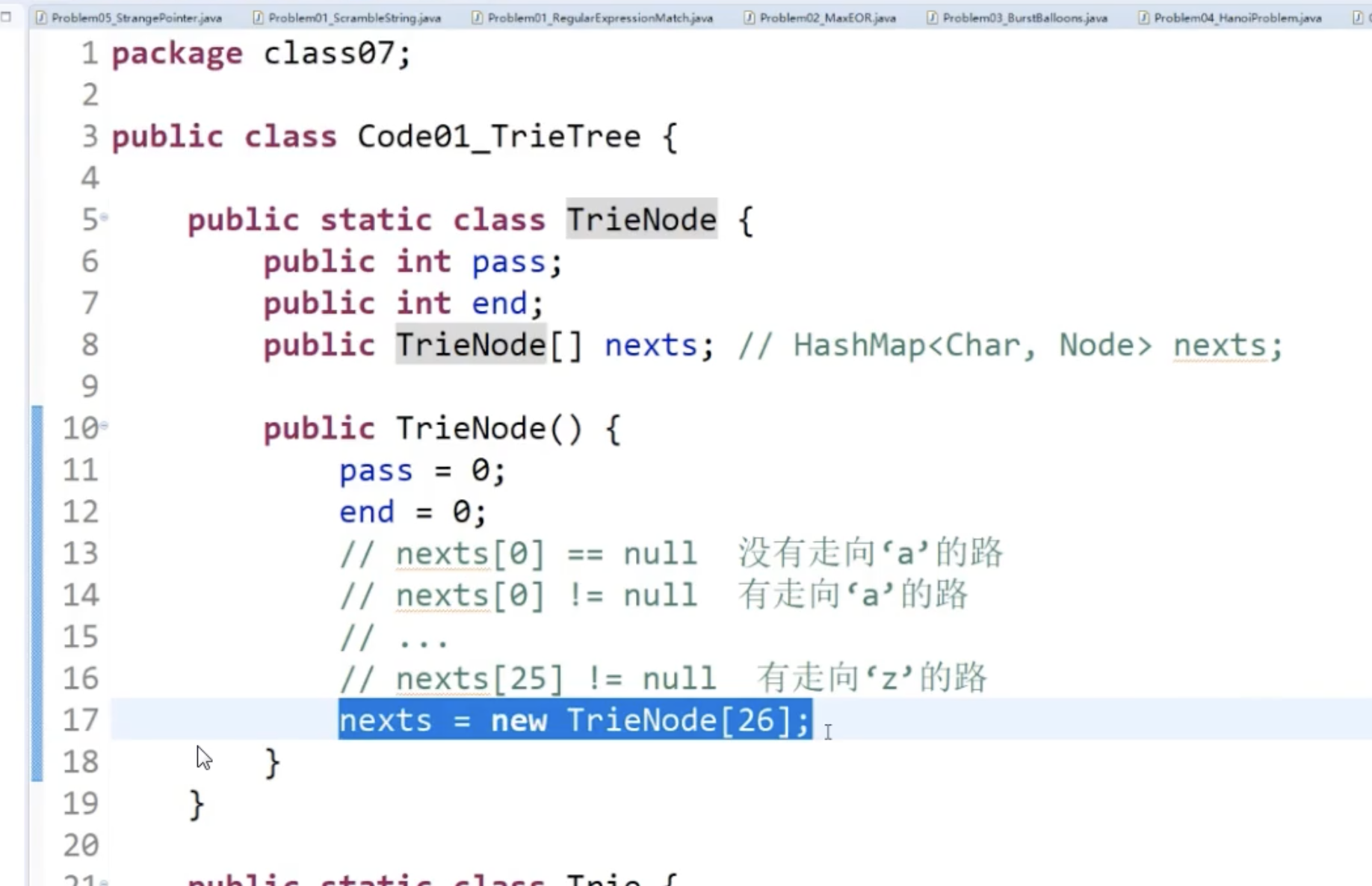
- 当新字符串引入的时候,为root节点p赋值,可以表示当前前缀树维护的语料数量。同时,支持语料中出现“空串”
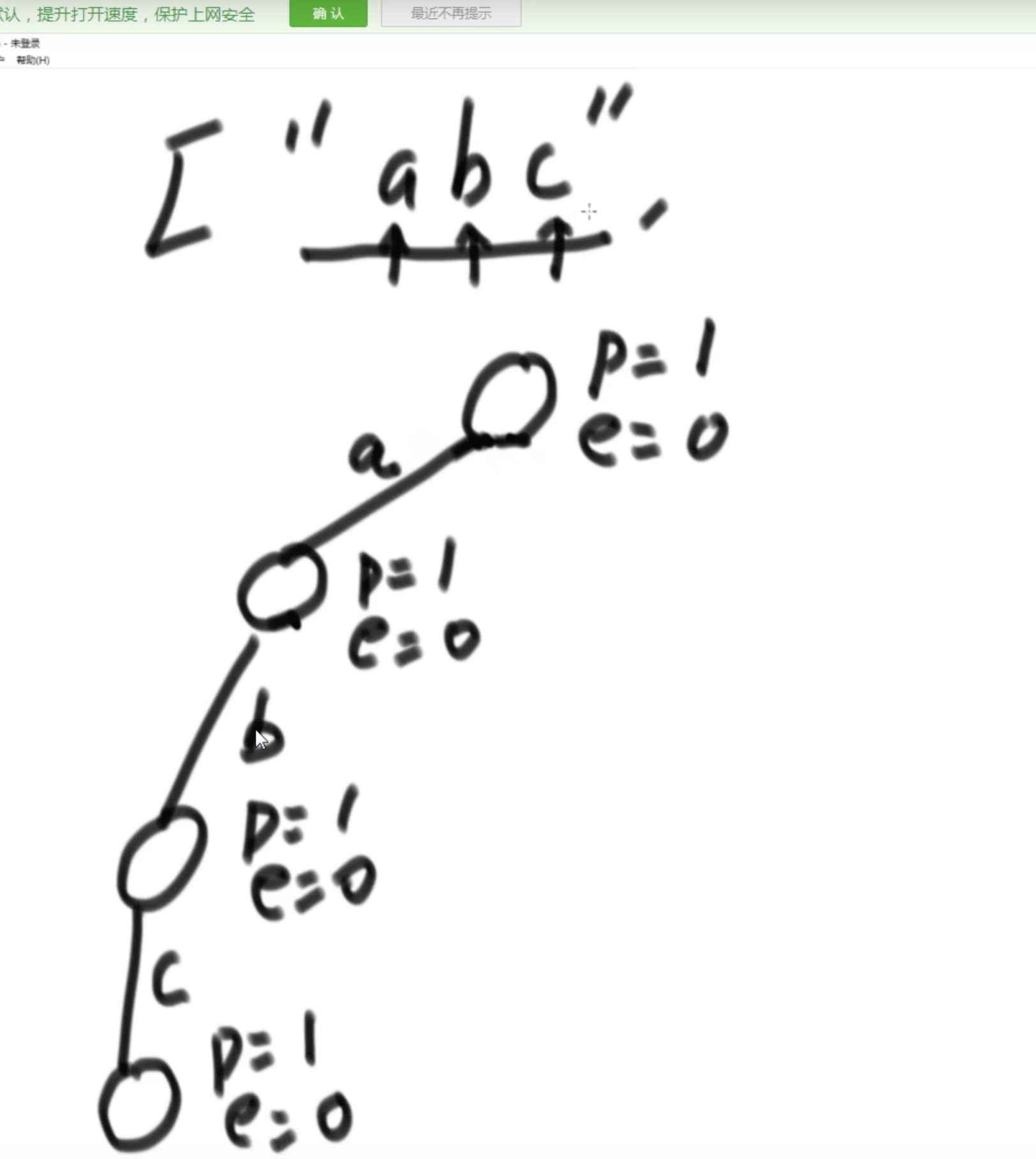
- 根节点是私有变量,这样的话,如果判断str2是不是str1的前缀,需要Trie类提供方法。而不是自己在调用端书写
- Node类中变量对Trie是完全开放的,这个跟我写法一致
- 最后末端end++ 的判断直接放到for循环外,因为i到达chs.length的时候当前节点指的就是末端节点。
其他:
1、工程上,当字符种类特别多的时候,比如java,字符总共有6万多。
用哈希,有序哈希等。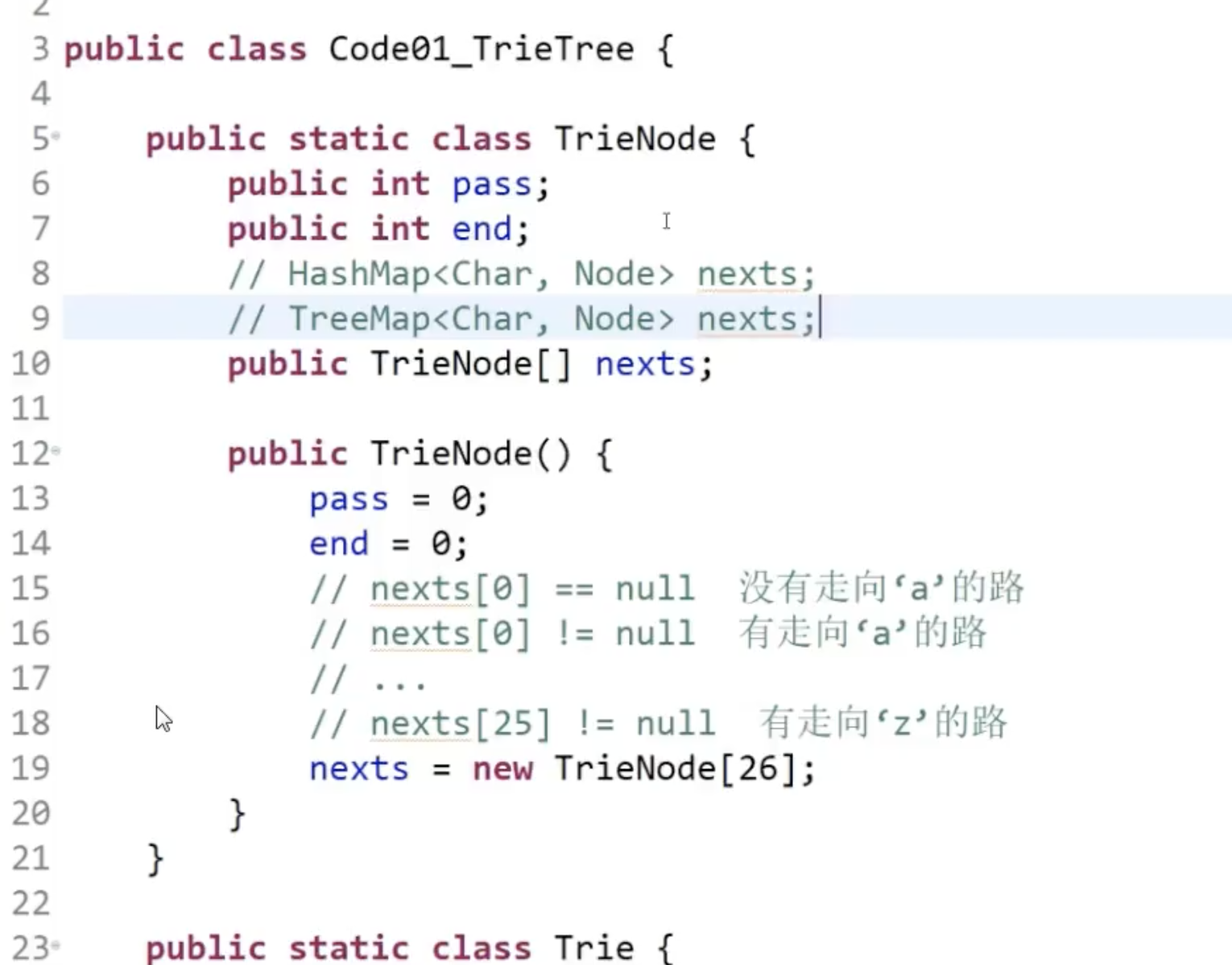
2、查询、准确查询,模糊查询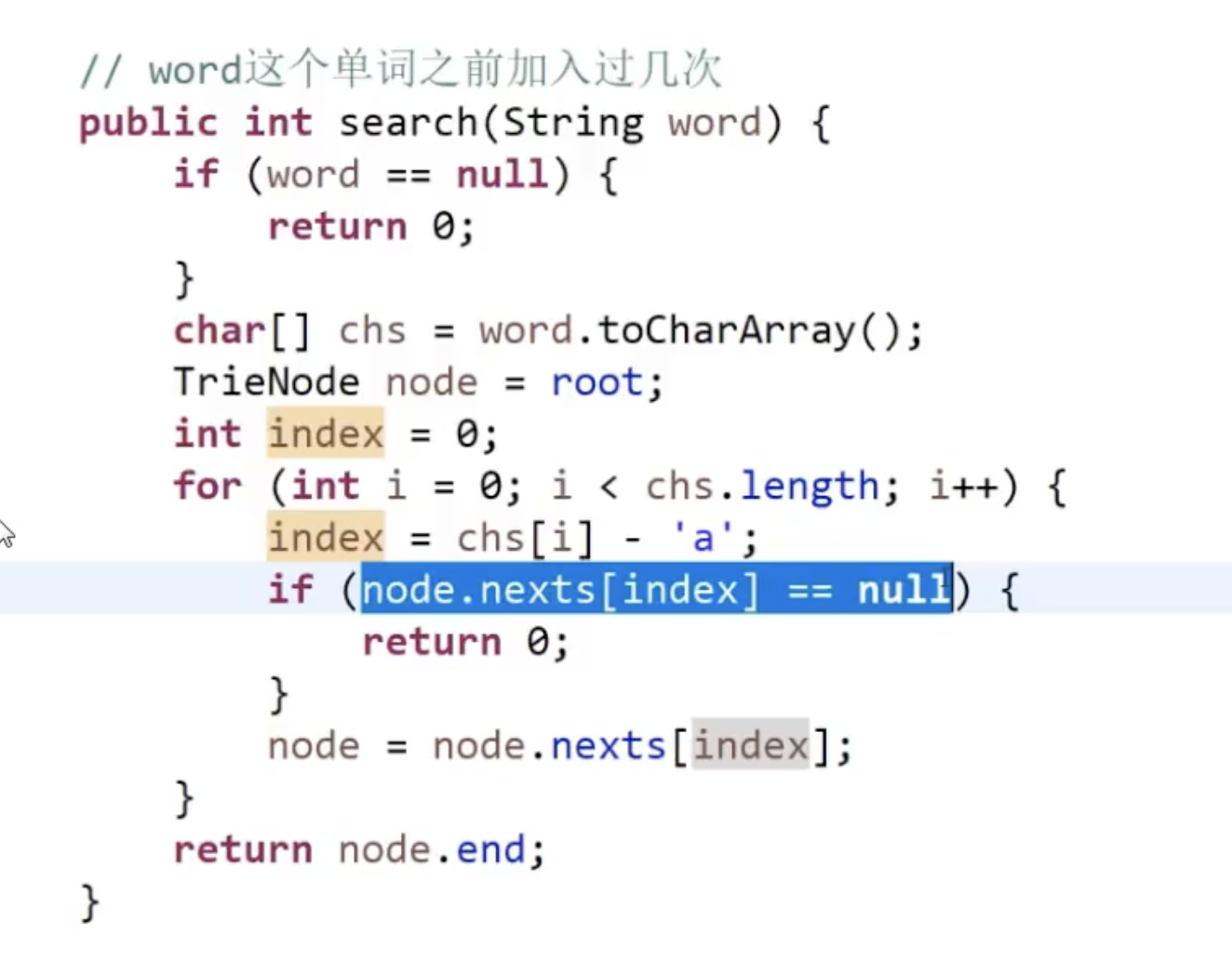
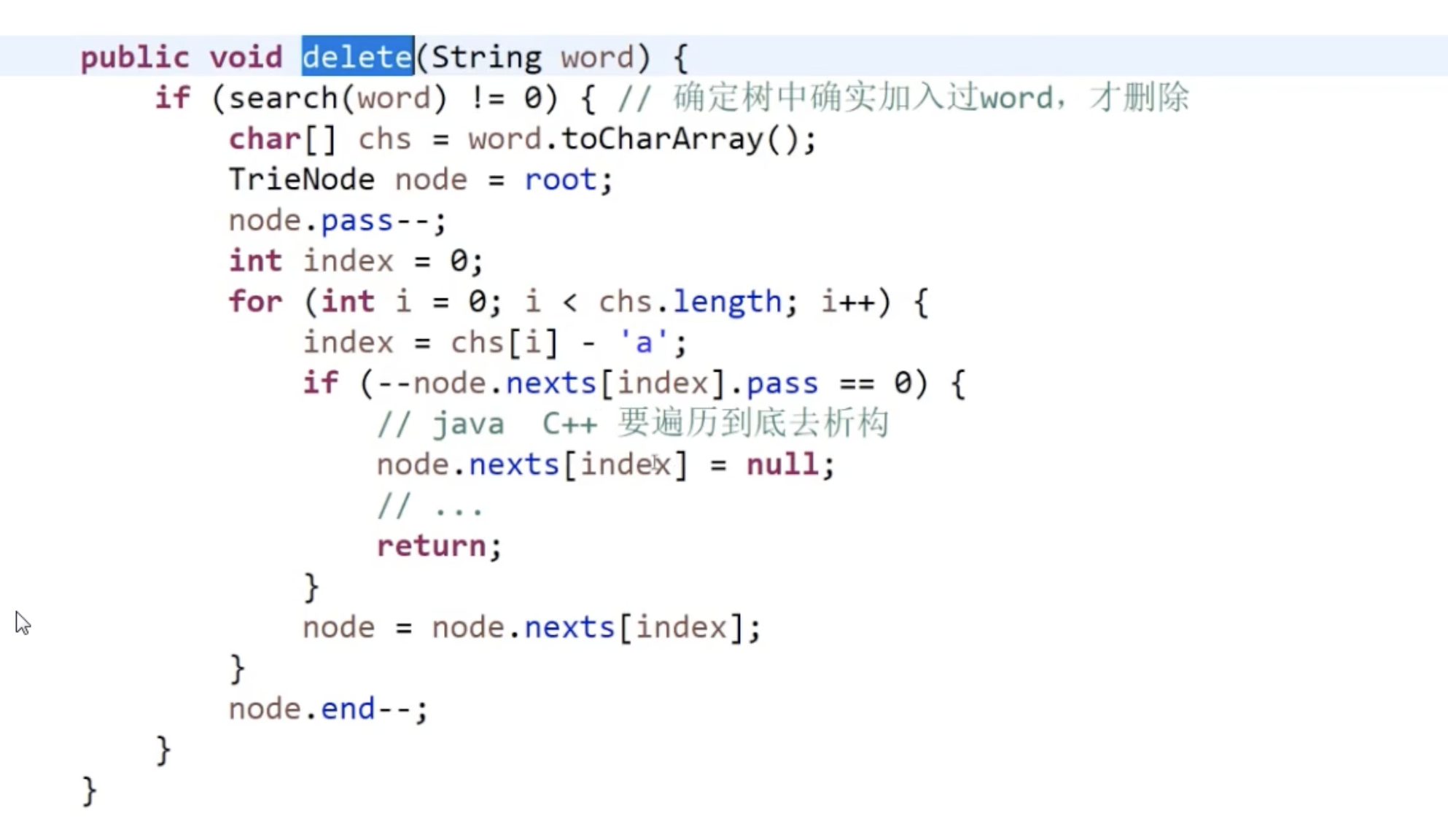
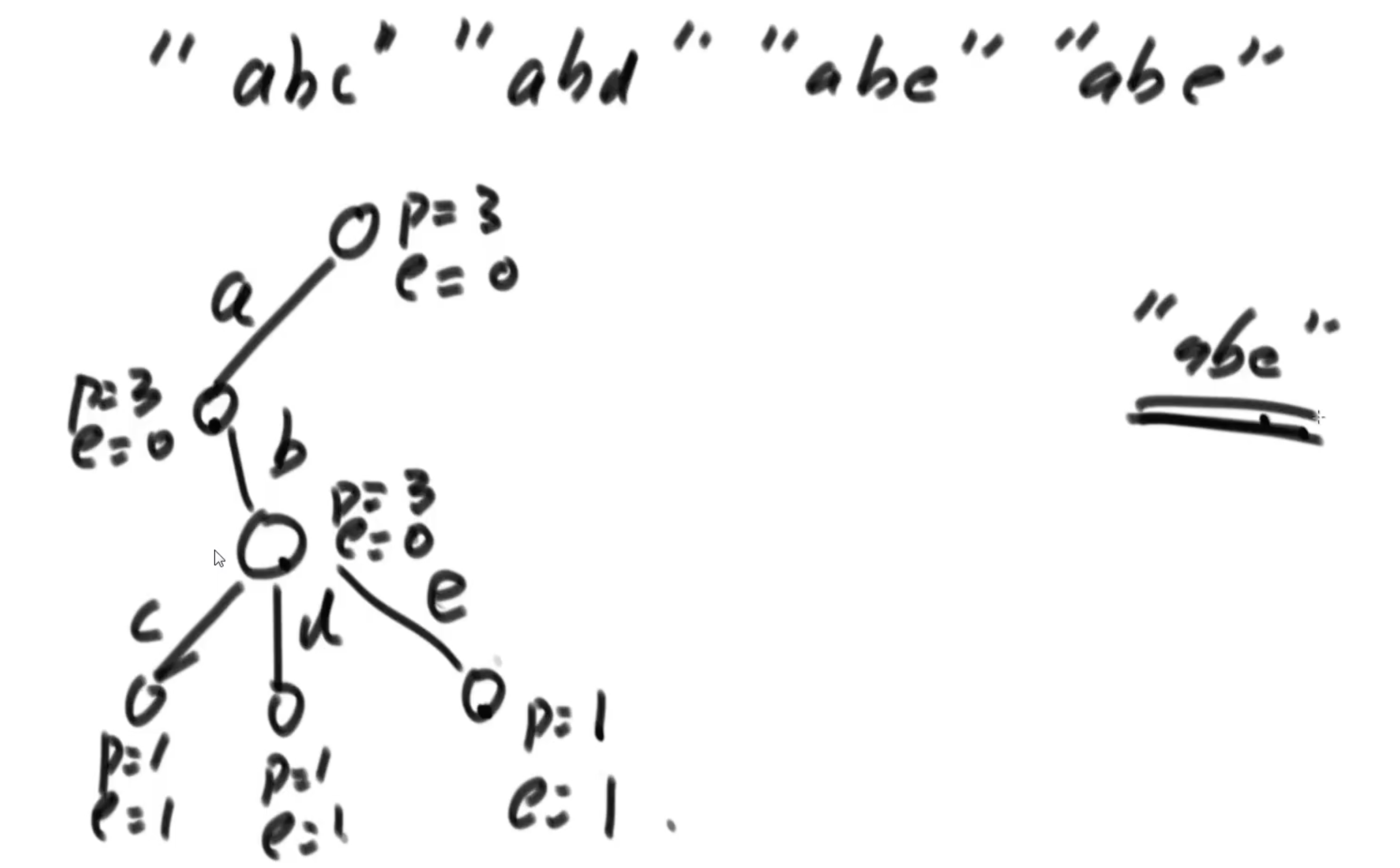
3、删除、如果c++需要考虑析构。
- 删除之前先查询,注意是准确查询语料中是否存在,感觉能用在检索时候的模糊搜索的地方,从语料中过滤掉不合法、不健康的的字符

若有收获,就点个赞吧
0 人点赞
