
一、递归行为的merge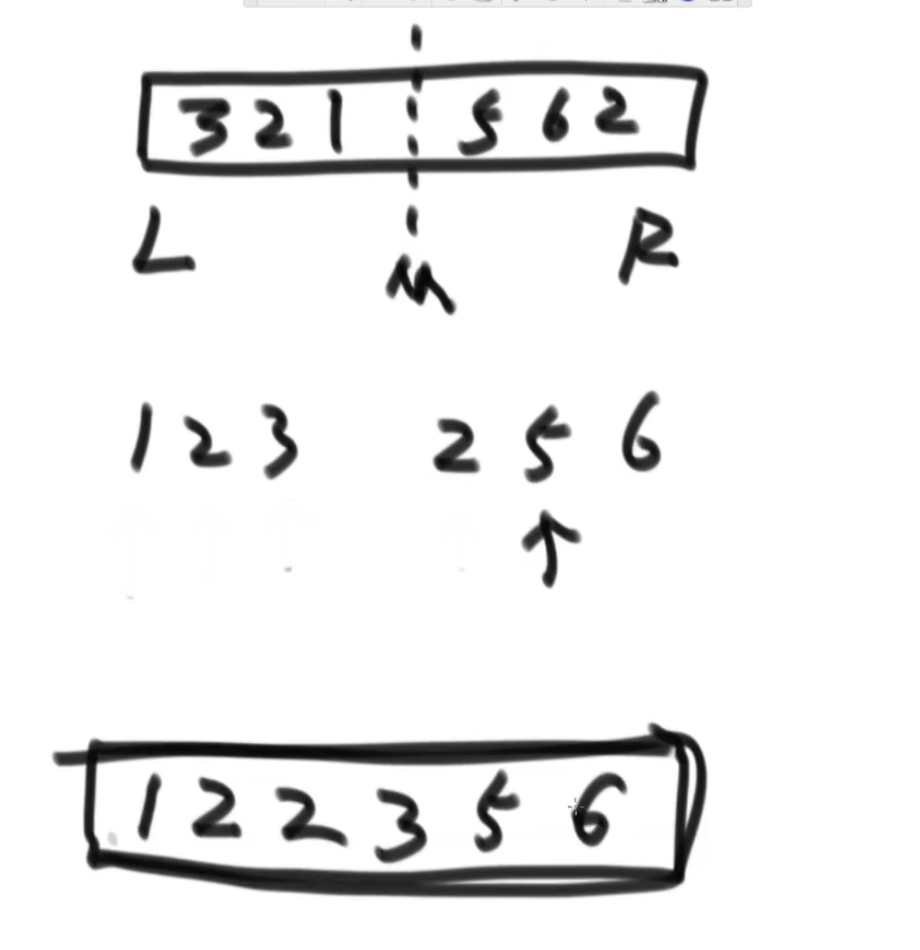
整体的过程有点像树形dp套路
先左右两部分进行归并排序,然后将这两部分进行整理得到新的数组。
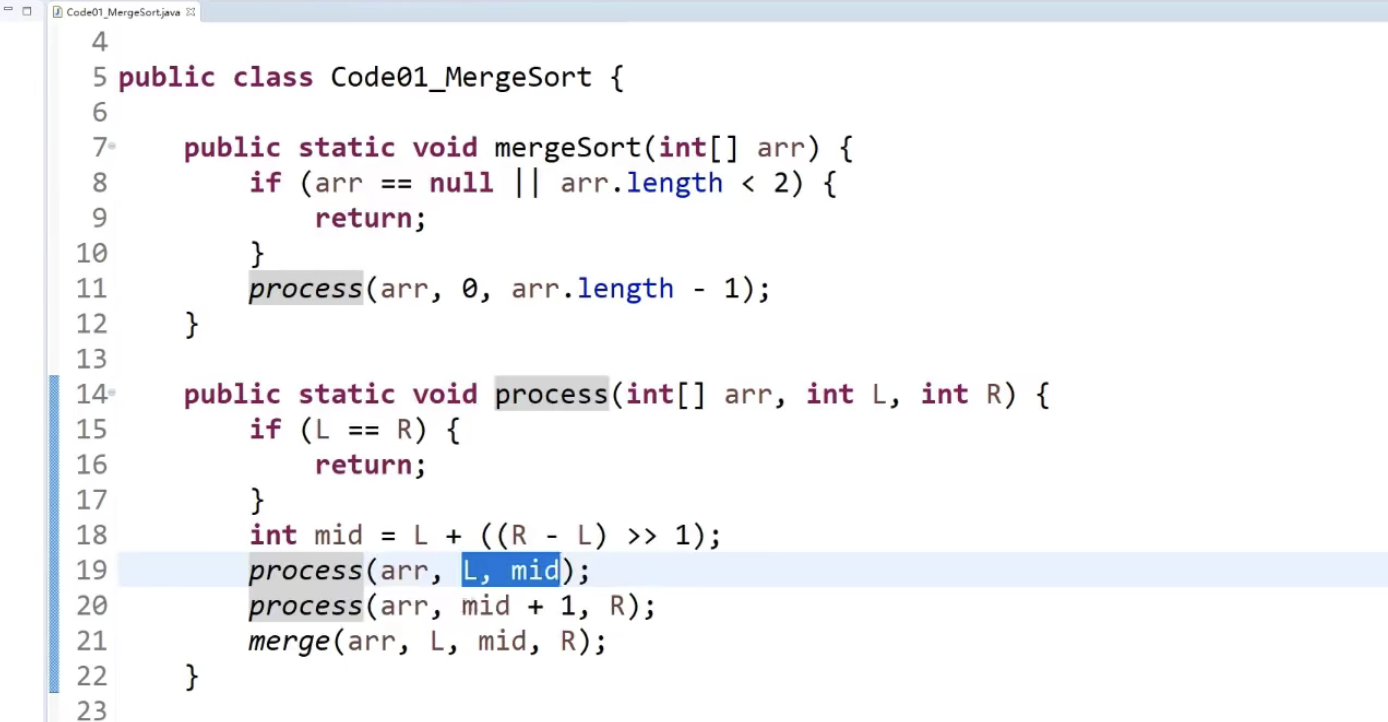
process(int[] arr ,int l , int r){
int mid;
process(arr ,l , mid);
process(arr , mid+1, r);
然后对arr的左右两部分进行合并操作
merge(arr , l , mid ,r);
}
merge过程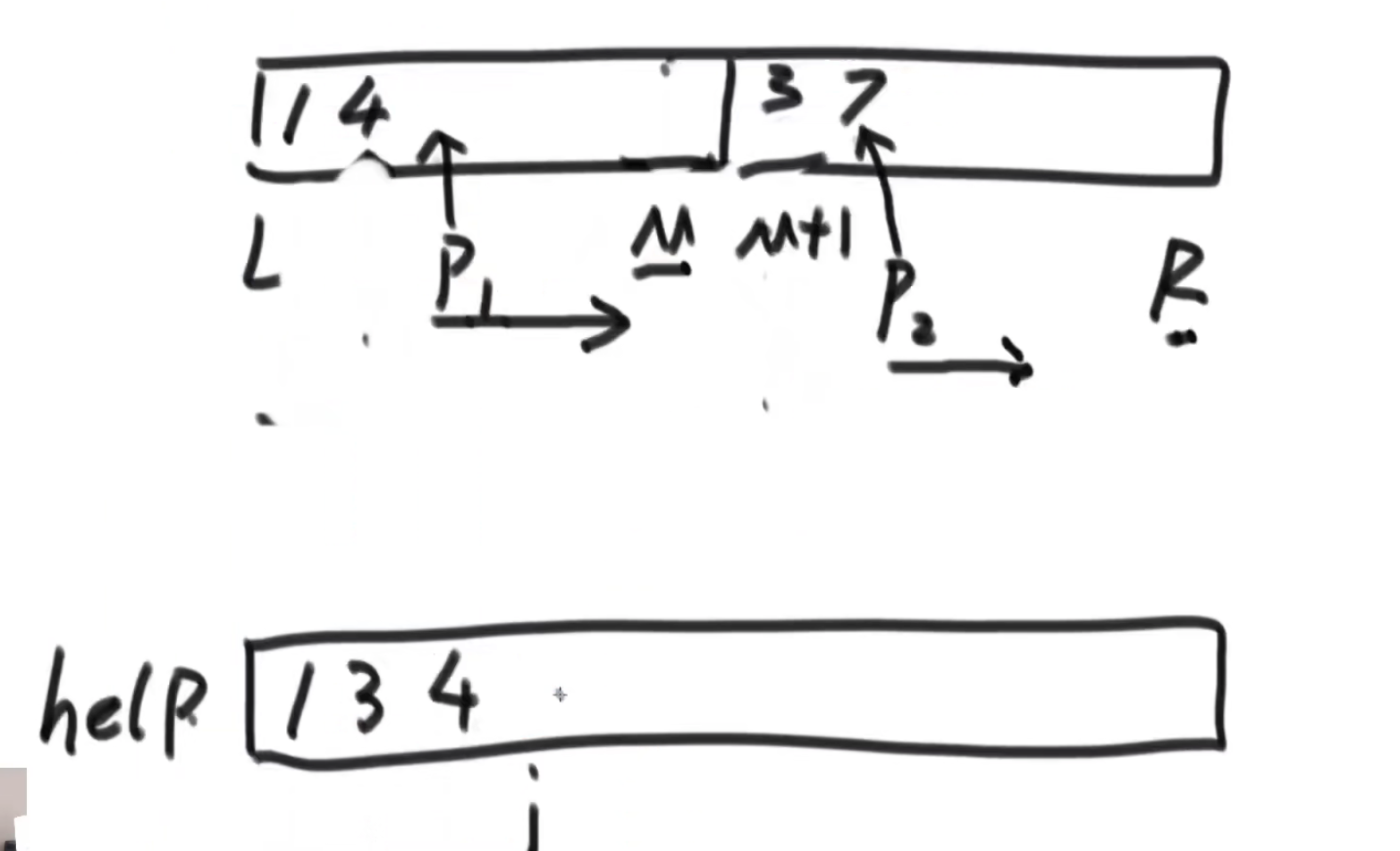
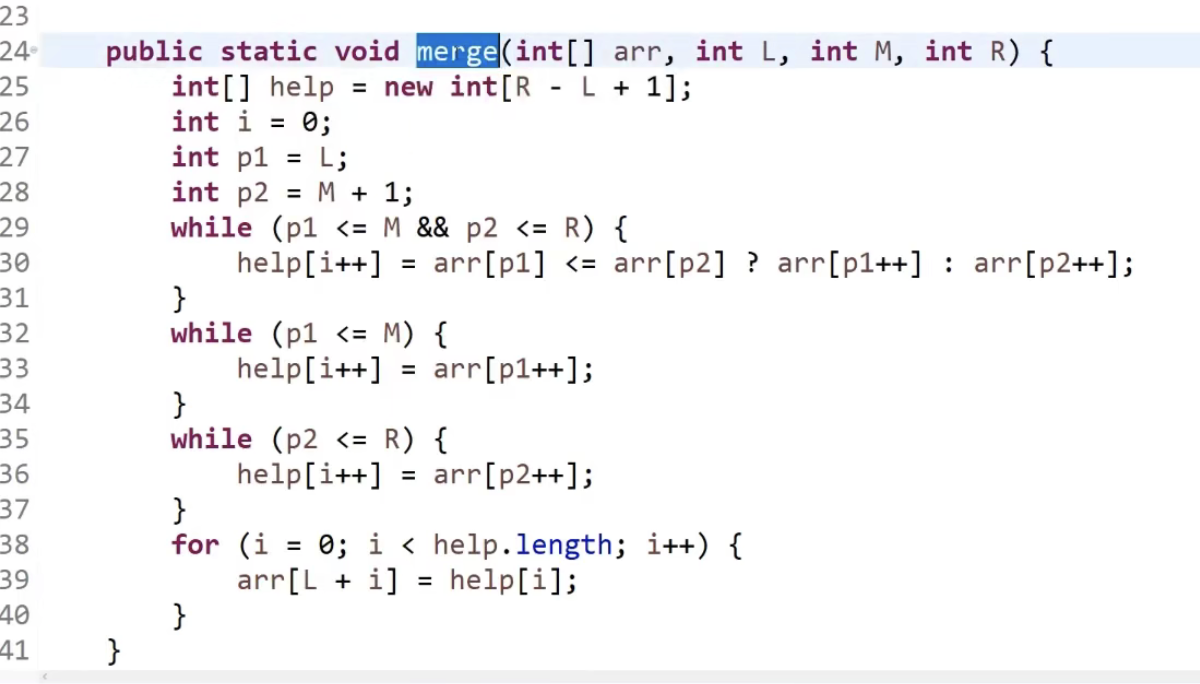
tips:注意30行这种写法的精炼。
时间复杂度估计
T(N) = 2* T(N/2) + O ( N )
log(b, a ) =1 = d;
所以整体复杂度就是N
二、拓展,
出现视频p3认识NlogN的排序

第一问; 求数组的小和
小和定义:数组前面每个比自己小的数构成小和集, 求所有小和集的总和。
解法分析:
暴力解 : 从数组下标0出发,碰到一个值,遍历前面比他小的数,求和,复杂度是N平方
优化1:
举个例子: arr数组 { 4,5,1,3,2};
小和的定义是 依次看
遍历值 前面比他小的
4, 无
5 4
1, 无
3, 1
2, 1
根据定义, 小和 = 4 + 1 + 1 = 6
转化一下:
遍历值 后面有哪些比他大的
4 {5}
5 {}
1 {3,2}
3 {}
2 {}
所以4 对整体和贡献了1次,要计算 1 次, 1 要计算2次
小和 = 4 1 + 1 2 = 6;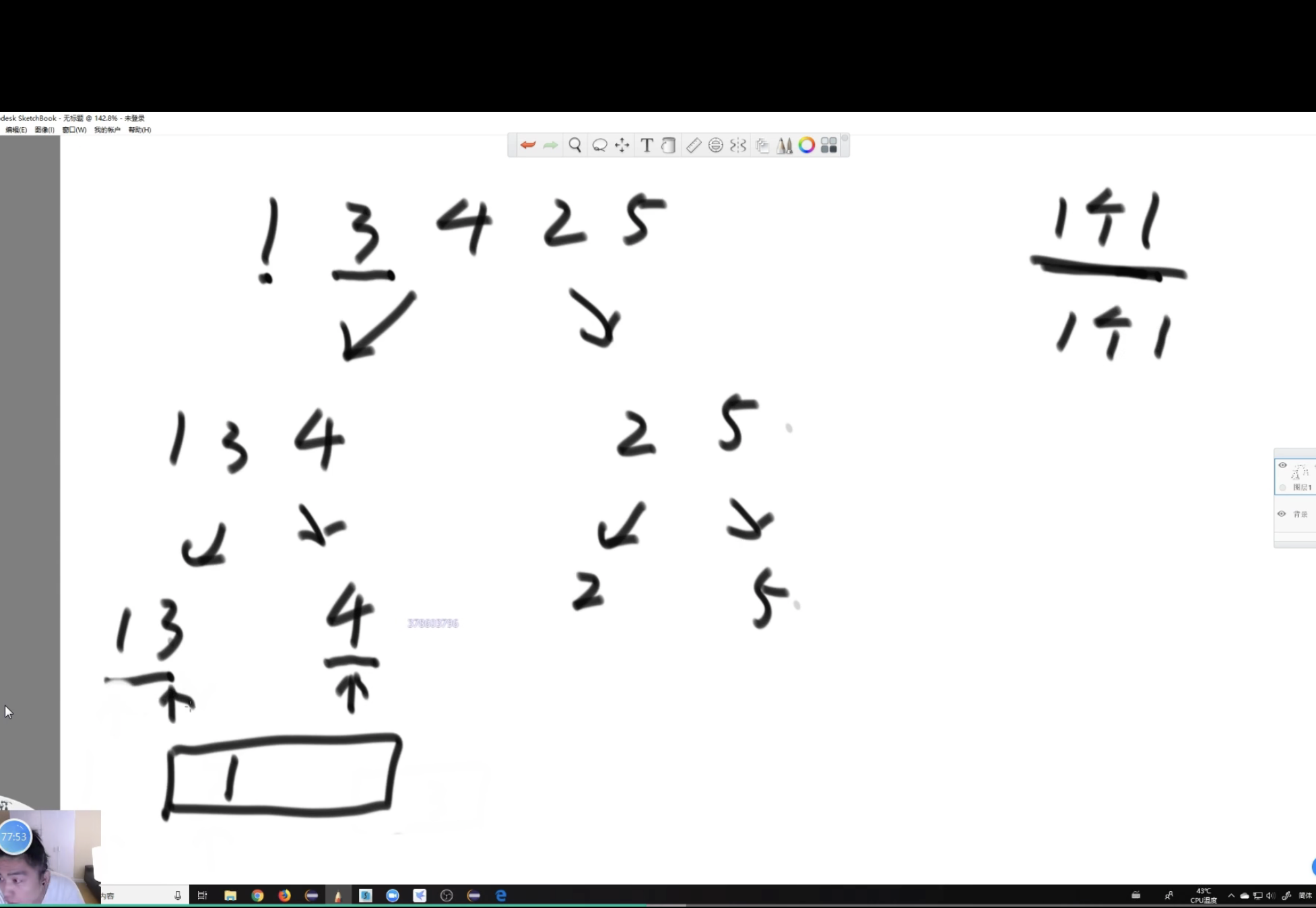
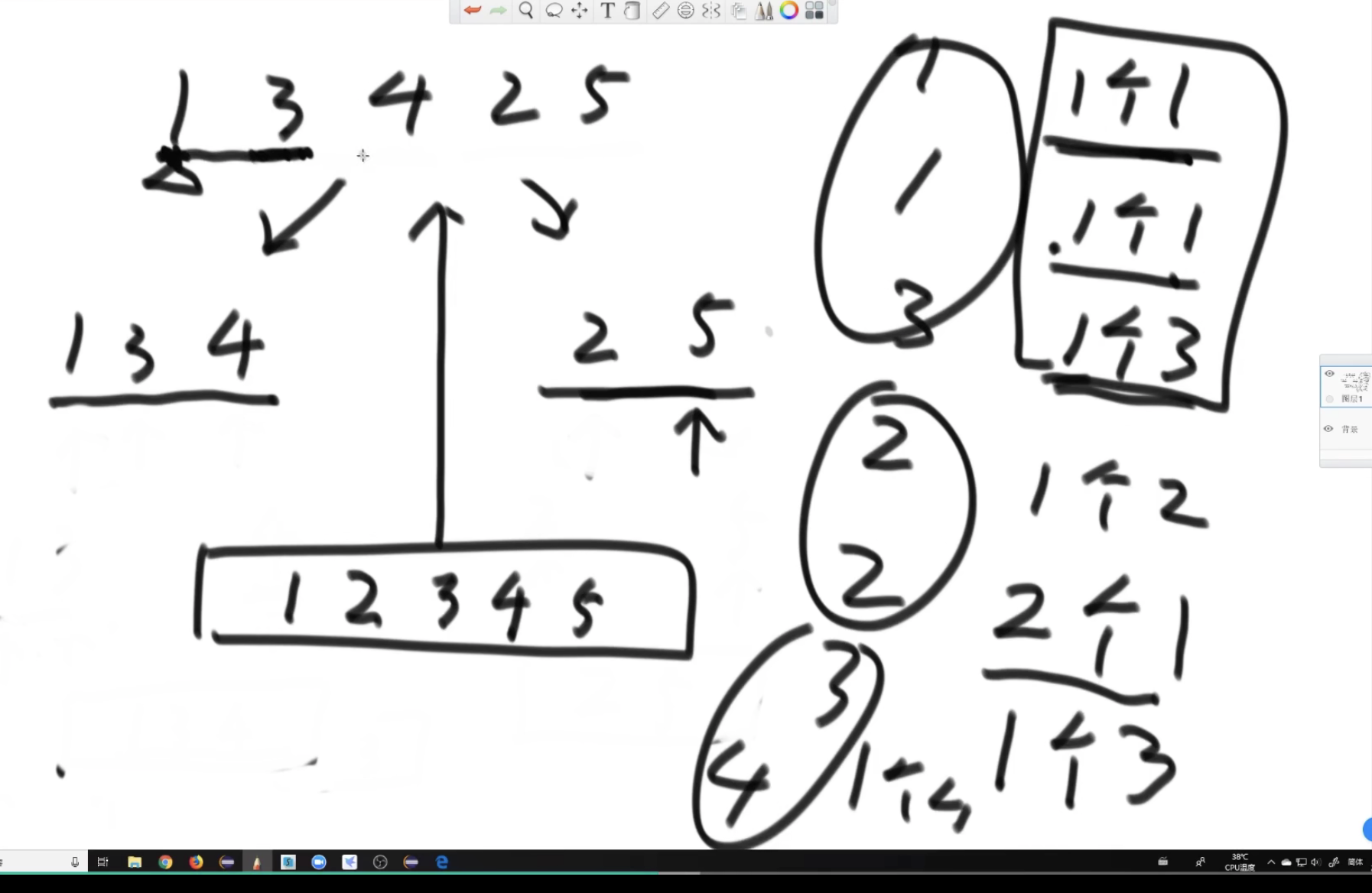
step1 : 所以问题可以转化为求每一个数字后面有多少比他大的,这个频次就代表对结果的贡献次数。
step2 :
归并的时候我们所进行的两部分的merge操作,如果前半部分的小于后面部分的就输出外部数组,那么这时候,右半部分的个数实际上就是这次合并途中左边较小的数对小和的贡献次数。而这个次数可以直接根据遍历的下标和右边界直接得到,不用遍历就知道,所以这个问题就能在归并排序的过程中顺道解决
tips:每次合并都是左半区和右半区的合并,不会冲突,重复计算贡献频次。(看某个数比如1,3的心路历程,不遗漏,不重算)
同一组不会重算,不断扩不同的右组不会漏算。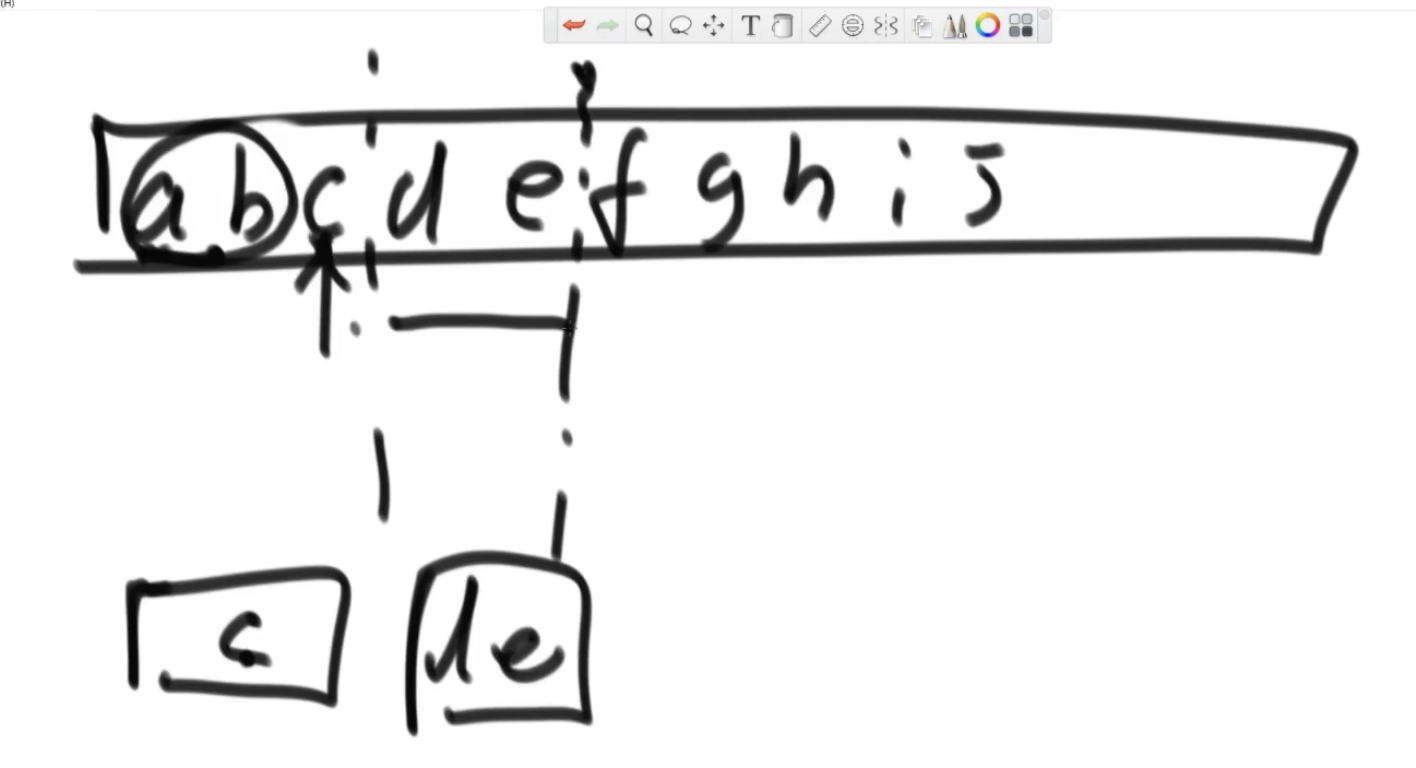
step3(这是和经典排序不一样的一点): 注意当左右两个数相同的时候,要把右边这个数抛到临时数组,这样才能保证左边每次抛出的时候能计算得出正确的频次。
如果拷贝左组的数,我不知道右边有多少个比自己大的数字。
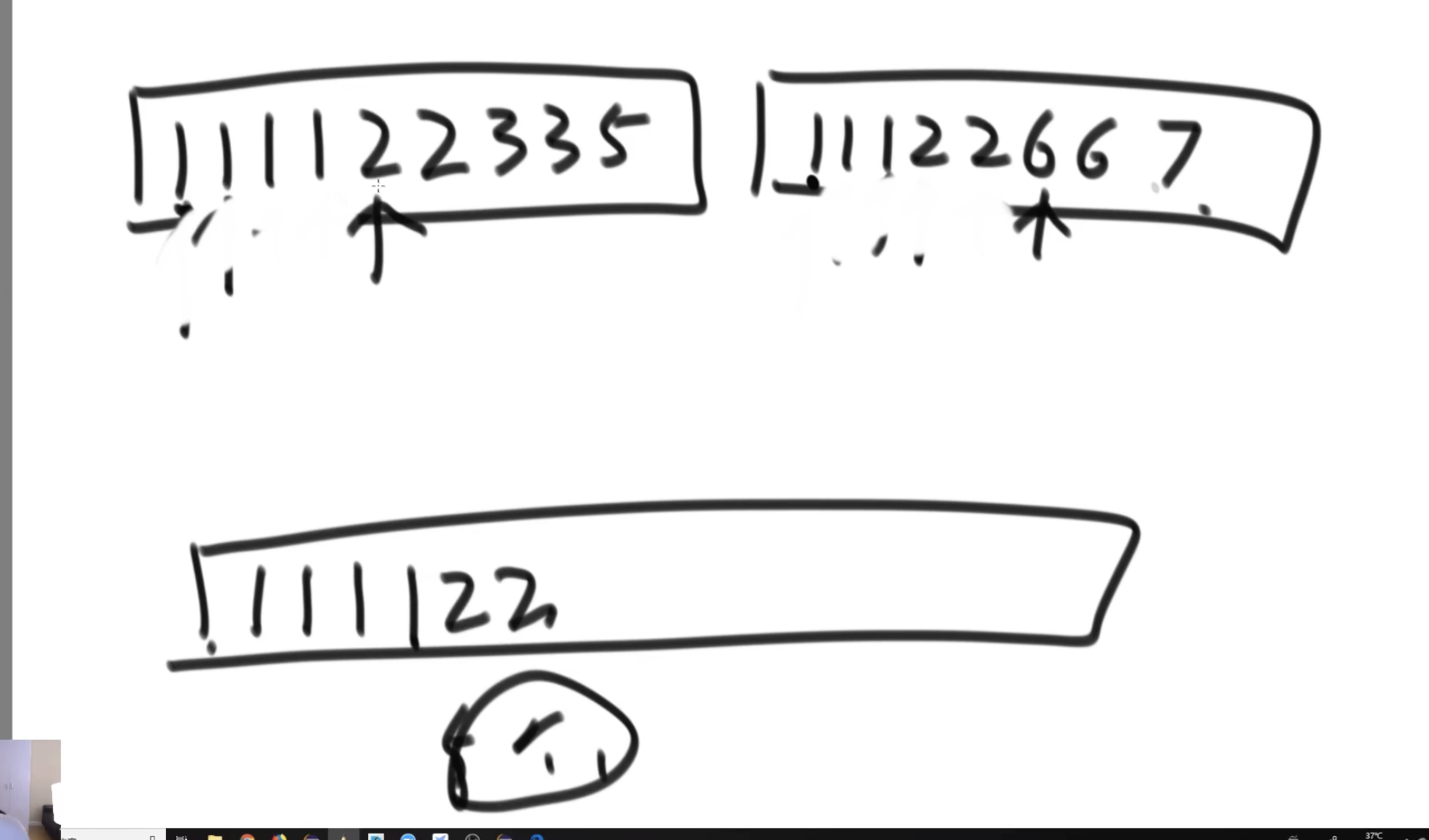
tips:排序的动作不能省略,右组有多少个数比左数大,是排好序后根据下表计算出来的。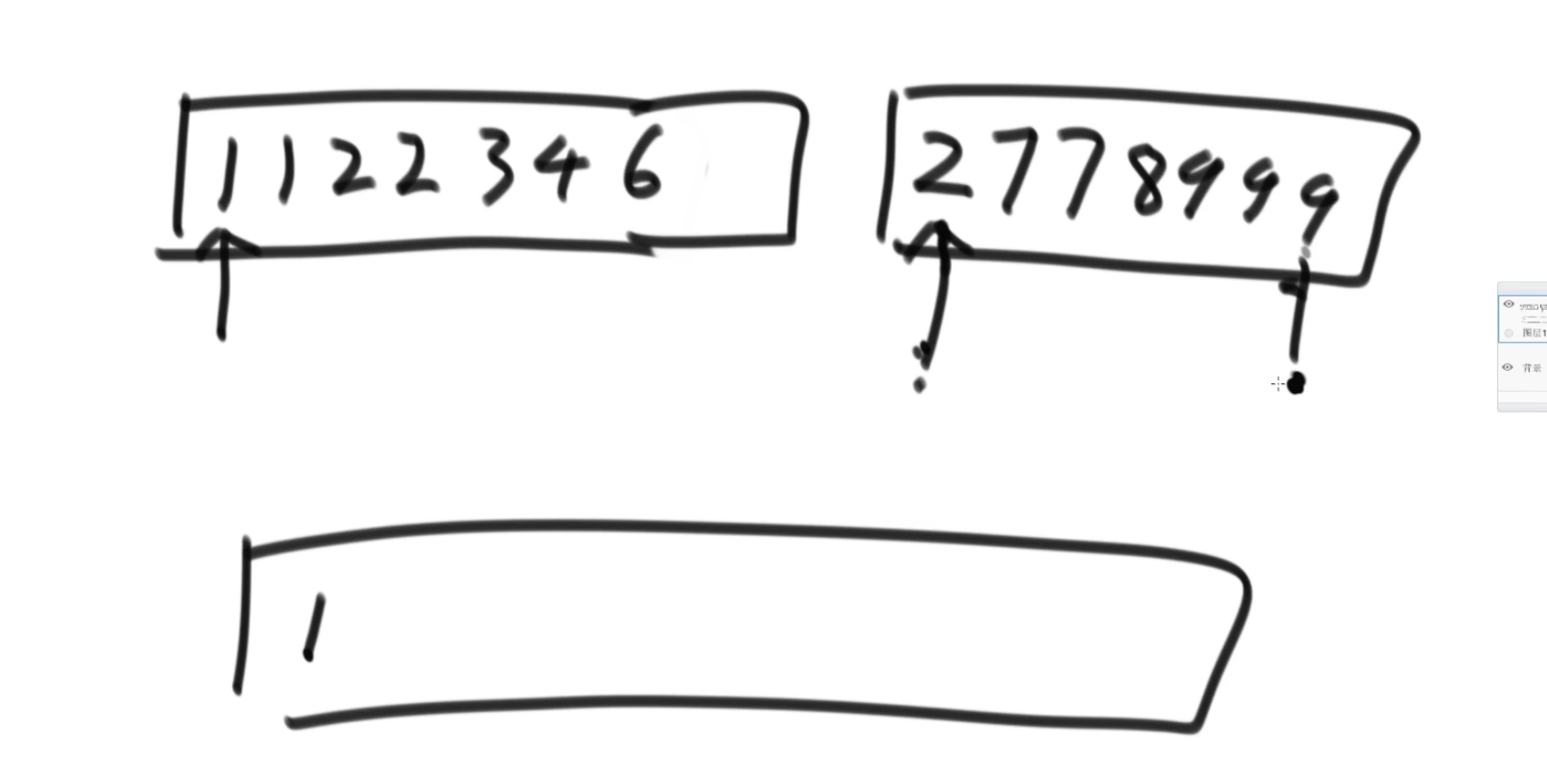
代码: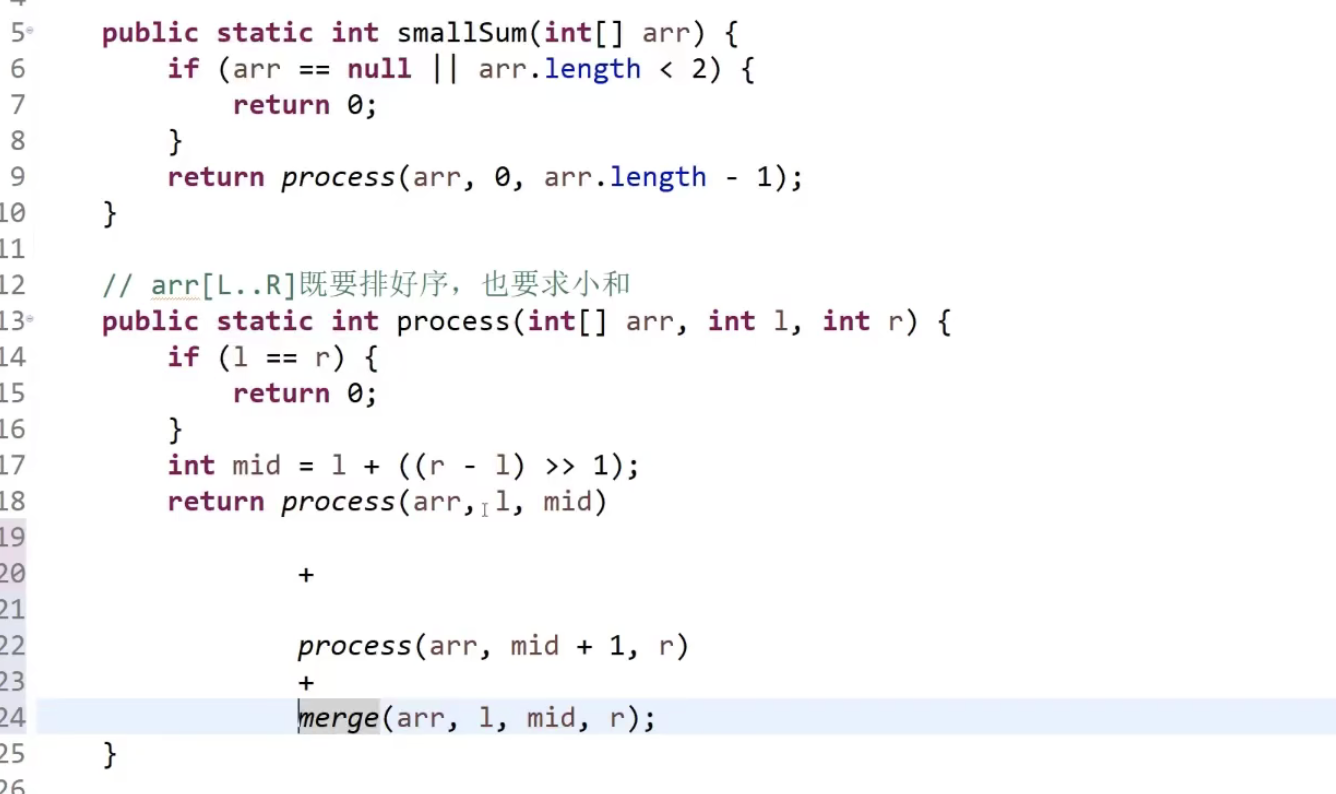

优化2(自己想到的) :
如果有序表treeMap的tailMap(fromkey) 的时间复杂度是logN的话,那么可以从右到左遍历,求出treeMap中大于当前值的size,然后再将当前值加进去,但是为了避免重复值的出现,要加一个版本号+0.1比如。
感觉是可行的,因为treepMap的tailMap返回的是地址引用,不是深拷贝,所以复杂度应该和查询一样logN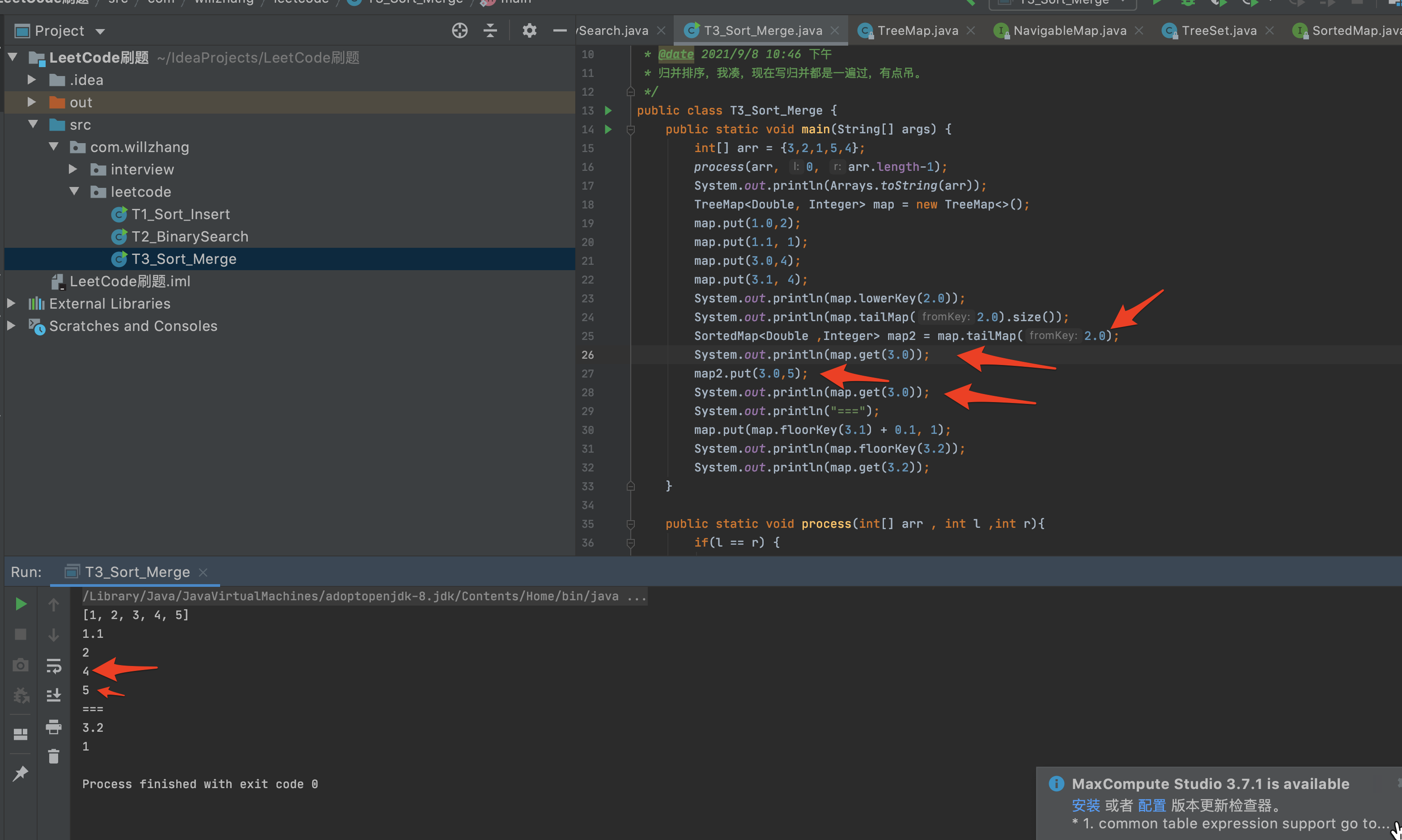
第二问:逆序对的数量,跟上面思路一样,不知不过比较变成了左边右边的时候统计,然后由左侧提供,相等出现的时候要拷贝左侧。
感受: 如果碰到左边比他小的或者大的这种有序数对的问题,利用归并过程能提速获得不重复的解。

若有收获,就点个赞吧
0 人点赞
