一、Reids数据类型
1、字符串值(String操作)
- set key value : 修改/新增数据
- setnx key value :只可以新增键值
- get key :获得指定key对应值
- exists key :判断指定键值是否存在
- del key 删除指定key-value
- incr key给指定key对应value值新增1但是注 意值必须是数字类型字符串
- incrby key 5给指定key对应value值新增5 但是注 意值必须是数字类型字符串
- ttl查询指定k-V的有效时间
- expire key 20给指定K-V设 置有效时间单位是秒
- setex key 20 value新建一个K-V并 且设置有效时间是20s
- keys *查询所有的key
- type key查询指定key对应Value的类型
- dbsize查询K-V的数量
-
2、哈希表(Hash)
hset key field value 给key中field设置值。
- hget key field 获取key中某个field的值
- hmset key field value field value …… 给key中多个filed设置值
- hmget field field field …… 一次获取key中多个field的值
- hvals key 获取key中所有field的值
- hgetall key 获取所有field和value,返回值为field和value交替显示列表
hdel key field field …… 删除key中任意个field,返回删除的数量
3、列表(list)
rpush key value value 向列表末尾中插入一个或多个值
- lrange list 0 -1 返回列表中指定区间内的值。可以使用-1代表列表末尾
- lpush key value value 将一个或多个值插入到列表前面
- llen key 获取列表长度
lrem key count value 删除列表中元素。count为正数表示从左往右删除的数量。负数从右往左删除的数量。
4、集合(Set)
sadd key value value value 向集合中添加内容。不允许重复。
- scard key 返回集合元素数量
-
5、有序集合(Sorted Set)
zadd key score value score value 向有序集合中添加数据
zrange key 区间 [withscores] 返回区间内容,withscores表示带有分数
6、流类型(Stream)
xadd key id field value [field value] id可以使用固定值,也可以使用(自动生成)。新添加的ID值必须大于已经存在的ID值 示例:xadd sxt name “sxt” age 12
- xrange key ID开始值 ID结束值 - 代表最小值+ 代表最大值ID的取值为大于零的整数。
二、Redis持久化策略
Redis不仅仅是一个内存型数据库,还具备持久化能力。
Redis每次启动时都会从硬盘存储文件中把数据读取到内存中。运行过程中操作的数据都是内存中的数据。
一共包含两种持久化策略:RDB 和 AOF1、RDB(Redis DataBase)
rdb模式是默认模式,可以在指定的时间间隔内生成数据快照(snapshot),默认保存到dump.rdb文件中。当redis重启后会自动加载dump.rdb文件中内容到内存中。
用户可以使用SAVE(同步)或BGSAVE(异步)手动保存数据。
可以设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令,可以通过save选项设置多个保存条件,但只要其中任意一个条件被满足,服务器就会执行BGSAVE命令。
例如:
save 900 1
save 300 10
save 60 10000
那么只要满足以下三个条件中的任意一个,BGSAVE命令就会被执行。计时单位是必须要执行的时间,save 900 1 ,每900秒检测一次。在并发量越高的项目中Redis的时间参数设置的值要越小。
服务器在900秒之内,对数据库进行了至少1次修改
服务器在300秒之内,对数据库进行了至少10次修改
服务器在60秒之内,对数据库进行了至少10000次修改。
1.1 优点
rdb文件是一个紧凑文件,直接使用rdb文件就可以还原数据。
数据保存会由一个子进程进行保存,不影响父进程做其他事情。
恢复数据的效率要高于aof
总结:性能要高于AOF
1.2 缺点
每次保存点之间导致redis不可意料的关闭,可能会丢失数据。
由于每次保存数据都需要fork()子进程,在数据量比较大时可能会比较耗费性能。
2、 AOF(AppendOnly File)
AOF默认是关闭的,需要在配置文件redis.conf中开启AOF。Redis支持AOF和RDB同时生效,如果同时存在,AOF优先级高于RDB(Redis重新启动时会使用AOF进行数据恢复)
AOF原理:监听执行的命令,如果发现执行了修改数据的操作,同时直接同步到数据库文件中,同时会把命令记录到日志中。即使突然出现问题,由于日志文件中已经记录命令,下一次启动时也可以按照日志进行恢复数据,由于内存数据和硬盘数据实时同步,即使出现意外情况也需要担心。
2.1 优点
2.2 缺点
2.3 开启办法
修改redis.conf中。这个文件需要自己创建放到 /usr/local/redis目录下
appendonly yes 开启aof
appendfilename 设置aof数据文件,名称随意。
| # 默认no appendonly yes # aof文件名 appendfilename “appendonly.aof” |
|---|
三、高并发下Redis可能存在的问题以及解决方法
1、缓存穿透
在实际开发中,添加缓存工具的目的,减少对数据库的访问次数,提高访问效率。
肯定会出现Redis中不存在的缓存数据。例如:访问id=-1的数据。可能出现绕过redis依然频繁访问数据库的情况,称为缓存穿透,多出现在数据库查询为null的情况不被缓存时。
解决办法:
如果查询出来为null数据,把null数据依然放入到redis缓存中,同时设置这个key的有效时间比正常有效时间更短一些。
| if(list==null){ // key value 有效时间 时间单位 redisTemplate.opsForValue().set(navKey,null,10, TimeUnit.**_MINUTES); }else{ redisTemplate.opsForValue().set(navKey,result,7,TimeUnit.DAYS**); } |
|---|
2、缓存击穿
实际开发中,考虑redis所在服务器中内存压力,都会设置key的有效时间。一定会出现键值对过期的情况。如果正好key过期了,此时出现大量并发访问,这些访问都会去访问数据库,这种情况称为缓存击穿。
解决办法:
ReentrantLock性能和synchronized没有区别的,但是API使用起来更加方便。
2.1.1 重入锁和非重入锁?
无论是重入还是非重入都是在一个线程中(直接体现一定出现一个方法(A)调用另外一个方法(B)。)当A方法获取锁后,调用的B方法是否能获取锁就是他们区别。如果B方法能获取到锁对象就叫重入锁。如果B方法无法获取锁对象就叫非重入锁。
在Java JDK中提供的锁都是重入锁。
2.2 解决缓存击穿实例代码
只有在第一次访问时和Key过期时才会访问数据库。对于性能来说没有过大影响,因为平时都是直接访问redis。
| private ReentrantLock lock = new ReentrantLock(); @Override public Item selectByid(Integer id) { String key = “item:”+id; if(redisTemplate.hasKey(key)){ return (Item) redisTemplate.opsForValue().get(key); } lock.lock(); if(lock.isLocked()) { Item item = itemDubboService.selectById(id); // 由于设置了有效时间,就可能出现缓存击穿问题 redisTemplate.opsForValue().set(key, item, 7, TimeUnit.**_DAYS); lock.unlock(); return item; } // 如果加锁失败,为了保护数据库,直接返回null _return null**; } |
|---|
3、缓存雪崩
在一段时间内容,出现大量缓存数据失效,这段时间内容数据库的访问频率骤增,这种情况称为缓存雪崩。
解决办法:
- 永久生效。
- 自定义算法,例如:随机有效时间。让所有key尽量避开同一时间段。
| int seconds = random.nextInt(10000);
redisTemplate.opsForValue().set(key, item, 100+ seconds, TimeUnit.SECONDS); | | —- |
4、边路缓存
cache aside pattern 边路缓存问题。其实是一种指导思想,思想中包含:
1. 查询的时候应该先查询缓存,如果缓存不存在,在查询数据库
2. 修改缓存数据时,应先修改数据库,后修改缓存。
5、Redis脑裂
Redis脑裂主要是指因为一些网络原因导致Redis Master和Redis Slave和Sentinel集群处于不同的网络分区。Sentinel连接不上Master就会重新选择Master,此时就会出现两个不同Master,好像一个大脑分裂成两个一样。
Redis集群中不同节点存储不同的数据,脑裂会导致大量数据丢失。
方案一:
解决Redis脑裂只需要在Redis配置文件中配置两个参数
| min-slaves-to-write 3 //连接到master的最小slave数量 min-slaves-max-lag 10 //slave连接到master的最大延迟时间 |
|---|
方案二:
在不同机房中部署多个Sentinel,配置时配置数量大一些,必须绝大多数哨兵都认为Master宕掉后才选择主。这样会在一定程度上避免脑裂现象。
方案三:
如果不希望配置很多哨兵,可以吧哨兵和客户端项目部署到同一个机房(主要是为了让哨兵和客户端项目走同一个网络),项目访问主从和哨兵的架构时,必须链接哨兵,由哨兵返回主的信息,所以即使出现脑裂现象,客户端项目和哨兵要不就都能访问某个主,要不就都不能访问某个主,不会影响项目的正常运行。
6、Redis缓存淘汰策略/当内存不足时如何回收数据/保证Redis中数据不出现内存溢出
6.1 何时淘汰数据
- 消极方法(passive way):在读取数据时先判断是否过期,如果过期删除他。例如:get、hget、hmget等
2. 积极方法(active way):周期性判断是否有失效内容,如果有就删除。
3. 主动删除:当超过阈值时会删除。
在Redis中每次新增数据都会判断是否超过阈值。如果超过了,就会按照淘汰策略删除一些key。6.2 淘汰策略
Redis中数据都放入到内存中。如果没有淘汰策略将会导致内存中数据越来越多,最终导致内存溢出。在Redis5中内置了缓存淘汰策略。在配置文件中有如下配置
| # maxmemory-policy noeviction 默认策略noevication # maxmemory # volatile-lru -> 在设置过期key集中选择使用数最小的。 # allkeys-lru -> 在所有key中选择使用最小的。 # volatile-lfu -> 在设置过期时间key集中采用lfu算法。 # allkeys-lfu -> 在所有key中采用lfu算法。 # volatile-random -> 在设置过期key集中随机删除。 # allkeys-random -> 在所有key中随机删除。 # volatile-ttl -> 在设置了过期时间key中删除最早过期时间的。 # noeviction -> 不删除key,超过时报错。 |
|---|
6.2.1 LRU
LRU (Least recently used) 最近最少使用,如果数据最近被访问过,那么将来被访问的几率也更高。LRU算法实现简单,运行时性能也良好,被广泛的使用在缓存/内存淘汰中。
- 新数据插入到链表头部
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部
- 当链表满的时候,将链表尾部的数据丢弃
6.2.2 LFU
Least Frequently Used(最近最不经常使用)如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰。
6.2.3 LRU和LFU的区别
LRU淘汰时淘汰的是链表最末尾的数据。而LFU是一段时间内访问次数最少的。
6.3 每次删除多少
四、Redis双写一致
1、实现逻辑
当系统中增加了缓存服务器,读写操作都需要针对缓存数据实现管理逻辑,其中当写数据的时候(增删改)必须保证缓存中数据和数据库中数据的一致,至少保证绝对没有脏数据。这种缓存的管理被称为双写一致。
访问数据库,增删改的时候,同时访问缓存,实现增删改或者淘汰缓存。
双写不是MySQL数据库和Redis数据库,是RDBMS关系型数据和其他。
其他可以是Redis、ElasticSearch、MongoDB等任何看可以保存数据的数据源。
2、如何保证书写一致
保证双写一致有一个原则,称为Cache Aside Pattern。即边路缓存思想(适用于Redis)。
定义了读和写的时候有缓存数据的时候缓存该如何执行。
读:
- 访问缓存,查询数据,如果有缓存直接返回缓存内容
- 如果缓存没有数据,访问数据库(RDBMS)查询数据。
- 把RDBMS中的数据保存到缓存中。
写:
- 写入数据库RDBMS
- 淘汰缓存(删除缓存)
3、缓存淘汰
原因:写操作缓存淘汰的原因:同步缓存(新增或者修改缓存),有时间代价和数据不一致的冲突。
举个栗子:
多线程情况下有A和B两个线程同时操作一组数据。设A和B对数据M进行操作,当前两个线程读取M的值均为20 。A对M的值进行了修改,修改为10,但是CPU时间片到了,A线程进入阻塞的状态。这时B对M的值也进行了修改,修改为30。然后进行写入缓存的操作,缓存中的M为30。这时A线程分配到了时间片执行到写入缓存的操作,更新缓存中M的值为10 。
这个时候数据库中M的值为30,但是缓存中M的值为10 。10即为脏数据,实际的值应该为30 。这是同步缓存导致的数据不一致冲突。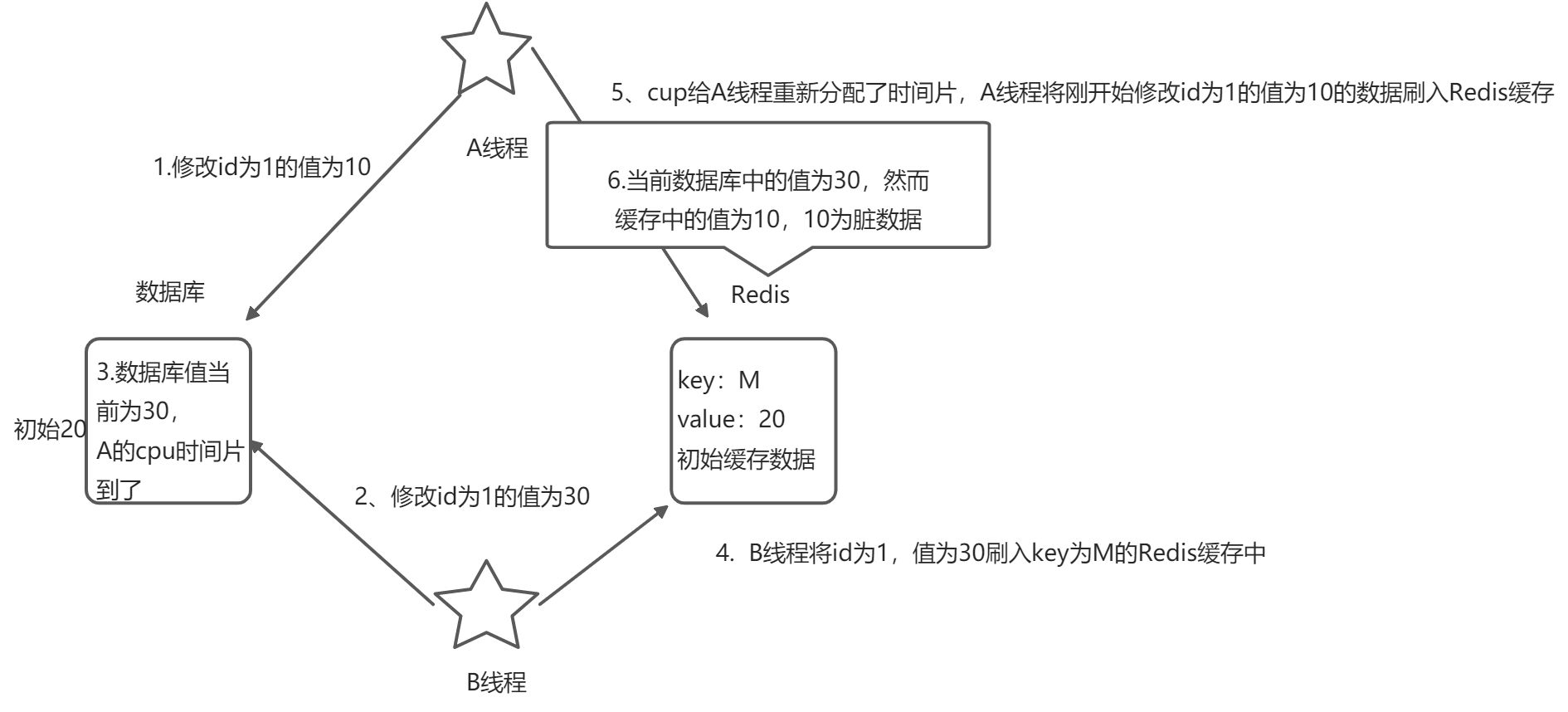

若有收获,就点个赞吧
0 人点赞
